
はじめに
このドキュメントでは、 Places Insights データセット、一般公開 BigQuery の地理空間データ、 および Place Details API を組み合わせて、サイト選択ソリューションを構築する方法について説明します。
上の地図は、Google Cloud Next 2025 で行われたデモの出力を示しています。 このデモは YouTube で視聴できます。 これらの結果を生成するために使用されたコードは、サンプル ノートブックを使用して実行できます。
 [View source on GitHub]
[View source on GitHub]
ビジネス上の課題
成功しているコーヒー ショップのチェーンを経営していて、ネバダ州など、まだ進出していない新しい州に拡大したいと考えているとします。新しい店舗の開店は大きな投資であり、データドリブンな意思決定を行うことが成功に不可欠です。どこから着手するのか?
このガイドでは、多層分析を行って、新しいコーヒー ショップに最適な場所を特定する手順について説明します。まず州全体のビューから始め、特定の郡と商業地区に検索範囲を絞り込み、最後にハイパーローカル分析を行って、個々のエリアをスコアリングし、競合他社をマッピングして市場のギャップを特定します。
ソリューションのワークフロー
このプロセスは、論理的なファネルに従って、広範囲から始まり、徐々に粒度を上げて検索範囲を絞り込み、最終的なサイト選択の信頼性を高めます。
前提条件と環境の設定
分析を開始する前に、いくつかの重要な機能を備えた環境が必要です。このガイドでは、SQL と Python を使用した実装について説明しますが、一般的な原則は他の技術スタックにも適用できます。
前提条件として、環境で次のことができることを確認してください。
- BigQuery でクエリを実行する。
- Places Insights にアクセスする。詳細については、Places Insights の設定をご覧ください。
bigquery-public-dataと 米国国勢調査局の郡別人口合計から一般公開データセットをサブスクライブする。
また、地図上に地理空間データを可視化できる必要があります。これは、各分析ステップの結果を解釈するうえで重要です。これにはさまざまな方法があります。BigQuery に直接接続する Looker Studio などの BI ツールを使用することも、Python などのデータ サイエンス言語を使用することもできます。
州レベルの分析: 最適な郡を見つける
最初のステップは、ネバダ州で最も有望な郡を特定するための広範な分析です。「有望」とは、人口が多く、既存のレストランの 密度が高いことを意味します。これは、食文化が 盛んであることを示しています。
BigQuery クエリでは、Places Insights データセット内で使用可能な組み込みのアドレス コンポーネントを活用して、これを実現します。このクエリでは、まず administrative_area_level_1_name フィールドを使用して、ネバダ州内の場所のみを含むようにデータをフィルタして、レストランの数をカウントします。次に、このセットを絞り込み、タイプ配列に 'restaurant' が含まれる場所のみを含めます。最後に、これらの結果を郡名(administrative_area_level_2_name)でグループ化して、郡ごとの数を生成します。このアプローチでは、データセットの組み込みの事前インデックス付きアドレス構造を使用します。
次の抜粋は、郡のジオメトリを Places Insights と結合し、特定の場所タイプ restaurant でフィルタする方法を示しています。
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
レストランの生カウントだけでは不十分です。市場の飽和度と機会を正確に把握するには、人口データとのバランスを取る必要があります。米国国勢調査局の郡別人口合計の人口データを使用します。
この 2 つの非常に異なる指標(場所の数と人口数)を比較するには、最小最大正規化を使用します。この手法では、両方の指標を共通の範囲(0 ~ 1)にスケーリングします。次に、これらを 1 つの normalized_score に結合し、バランスの取れた比較を行うために各指標に 50% の重みを付けます。
次の抜粋は、スコアを計算するためのコアロジックを示しています。正規化された人口とレストランの数を組み合わせます。
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
完全なクエリを実行すると、郡、レストランの数、人口、正規化されたスコアのリストが返されます。normalized_score
DESC で並べ替えると、クラーク郡が
上位候補としてさらに調査するのに適していることがわかります。
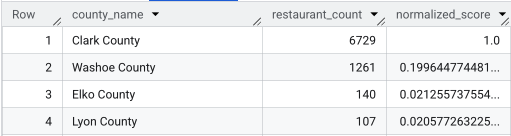
このスクリーンショットは、正規化されたスコアの上位 4 つの郡を示しています。この例では、人口の生カウントは意図的に省略されています。
郡レベルの分析: 最も活気のある商業地区を見つける
クラーク郡を特定したので、次のステップは、商業活動が最も活発な郵便番号を特定することです。既存のコーヒー ショップのデータに基づいて、主要ブランドの密度が高い場所のほうがパフォーマンスが高いことがわかっているため、これを来店数のプロキシとして使用します。
このクエリでは、特定のブランドに関する情報を含む Places Insights 内の brands テーブルを使用します。このテーブルに対して
クエリを実行して、サポートされているブランドのリストを
確認できます。まず、ターゲット ブランドのリストを定義し、これをメインの Places Insights データセットと結合して、クラーク郡の各郵便番号に該当する特定の店舗の数をカウントします。
これを実現する最も効率的な方法は、次の 2 つのステップで構成されるアプローチです。
- まず、高速で地理空間以外の集計を実行して、各郵便番号内のブランド数をカウントします。
- 次に、これらの結果を一般公開データセット と結合して、可視化用の地図の境界線を取得します。
postal_code_names フィールドを使用してブランドをカウントする
最初のクエリは、コアとなるカウント ロジックを実行します。クラーク郡の場所でフィルタし、postal_code_names 配列をネスト解除して、ブランド数を郵便番号でグループ化します。
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
出力は、郵便番号と対応するブランド数のテーブルです。
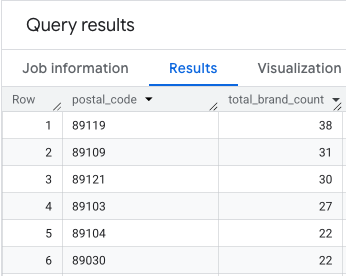
マッピング用の郵便番号ジオメトリを添付する
カウントを取得したので、可視化に必要なポリゴン形状を取得できます。2 番目のクエリは、最初のクエリを取得し、brand_counts_by_zip という名前の共通テーブル式(CTE)でラップして、その結果を一般公開の geo_us_boundaries.zip_codes table と結合します。これにより、事前に計算されたカウントにジオメトリが効率的に添付されます。
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
出力は、郵便番号、対応するブランド数、郵便番号ジオメトリのテーブルです。
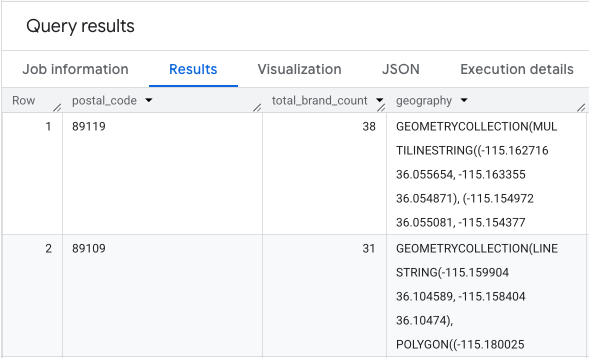
このデータをヒートマップとして 可視化できます。赤色が濃いほど、ターゲット ブランドの密度が高く、ラスベガス内の商業的に最も密度の高いゾーンを示しています。
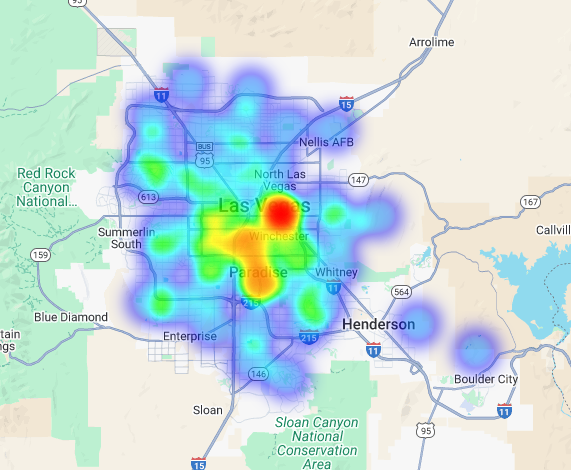
ハイパーローカル分析: 個々のグリッド領域をスコアリングする
ラスベガスのおおよその現在地を特定したので、詳細な分析を行います。ここで、特定のビジネス知識を重ね合わせます。午前中やランチタイムなど、ピーク時に忙しい他のビジネスの近くに、優れたコーヒー ショップが繁栄していることがわかっています。
次のクエリは非常に具体的です。まず、標準の H3 地理空間インデックス(解像度 8)を使用して、ラスベガス都市圏に細かい六角形のグリッドを作成し、エリアをマイクロレベルで分析します。このクエリでは、まずピーク時(月曜日の午前 10 時~午後 2 時)に営業しているすべての補完的なビジネスを特定します。
次に、各場所タイプに重み付きスコアを適用します。近くのレストランはコンビニエンス ストアよりも価値が高いため、乗数が高くなります。これにより、小さなエリアごとにカスタムの suitability_score が得られます。
次の抜粋は、重み付きスコアリング ロジックを示しています。このロジックは、営業時間チェック用に事前に計算されたフラグ(is_open_monday_window)を参照します。
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
完全なクエリを開く
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
これらのスコアを地図上に可視化すると、明確な勝者の場所がわかります。最も濃い紫色のタイルは、主にラスベガス ストリップとダウンタウンの近くにあり、新しいコーヒー ショップの可能性が最も高いエリアです。
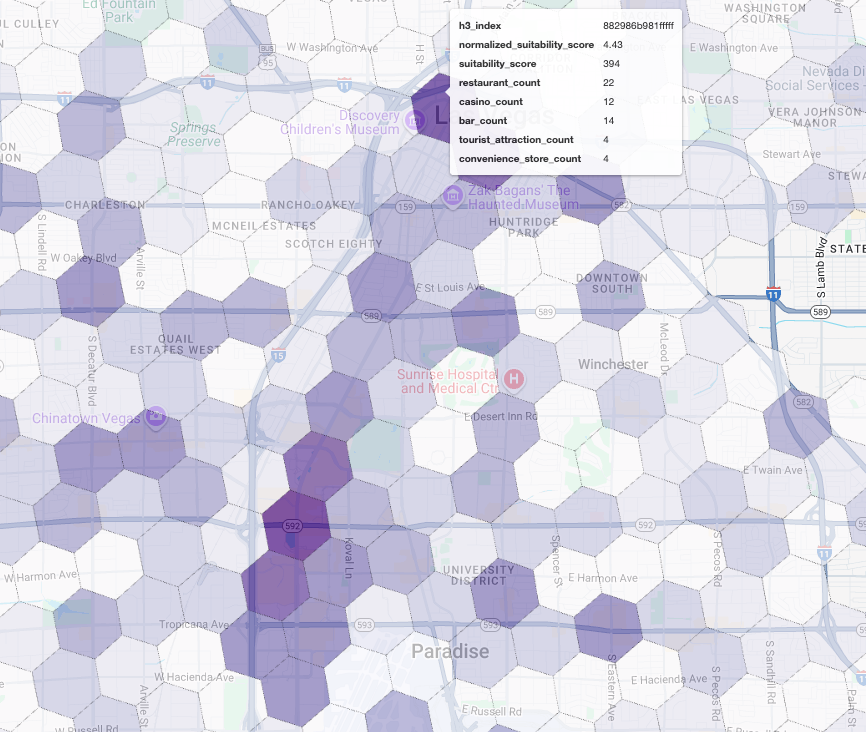
競合分析: 既存のコーヒー ショップを特定する
適合性モデルは最も有望なゾーンを特定しましたが、ハイスコアが高いだけでは成功は保証されません。ここで、競合他社のデータを重ね合わせる必要があります。明確な市場のギャップを探しているため、既存のコーヒー ショップの密度が低い、可能性の高いエリアが理想的な場所です。
これを行うには、
PLACES_COUNT_PER_H3
関数を使用します。この関数は、指定された地理的範囲内の場所の数を H3 セルごとに効率的に返すように設計されています。
まず、ラスベガス都市圏全体の地理的範囲を動的に定義します。
単一の地域区分に依存するのではなく、一般公開の Overture Maps データセットに対してクエリを実行して、ラスベガスとその周辺の主要な地域区分の境界線を取得し、ST_UNION_AGG を使用して 1 つのポリゴンに結合します。次に、このエリアを関数に渡し、営業中のすべてのコーヒー ショップをカウントするように指示します。
このクエリは都市圏を定義し、関数を呼び出して H3 セルのコーヒー ショップの数を取得します。
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
この関数は、H3 セルインデックス、そのジオメトリ、コーヒー ショップの総数、Place ID のサンプルを含むテーブルを返します。
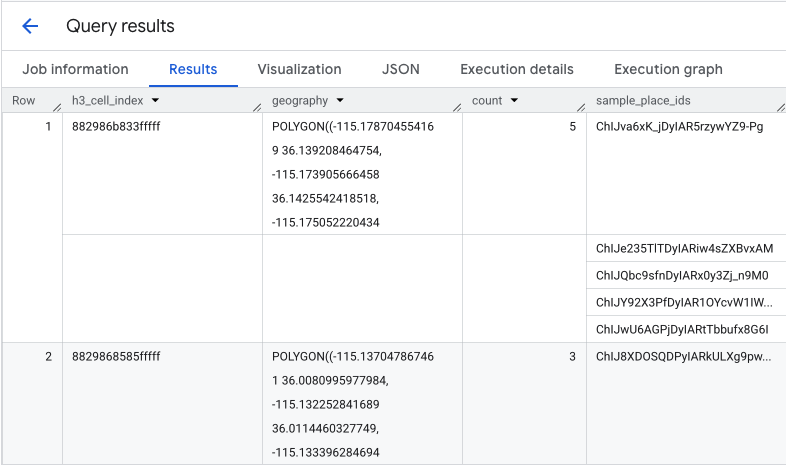
集計数は便利ですが、実際の競合他社を確認することが不可欠です。
ここで、Places Insights データセットから Places
API に移行します。正規化された適合性スコアが最も高いセルから
sample_place_idsを抽出することで、
Place Details
APIを呼び出して、名前、住所、評価、場所など、各競合他社の詳細情報を取得できます。
これには、適合性スコアが生成された前のクエリの結果と PLACES_COUNT_PER_H3 クエリの結果を比較する必要があります。H3 セルインデックスを使用して、正規化された適合性スコアが最も高いセルからコーヒー ショップの数と ID を取得できます。
次の Python コードは、この比較を実行する方法を示しています。
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
適合性スコアが最も高い H3 セル内にすでに存在するコーヒー ショップの Place ID のリストを取得したので、各場所の詳細情報をリクエストできます。
これを行うには、各
Place ID のPlace Details
API に直接リクエストを送信するか、Client
Library を使用して
呼び出しを行います。必要なデータのみをリクエストするように、
FieldMask
パラメータを設定してください。
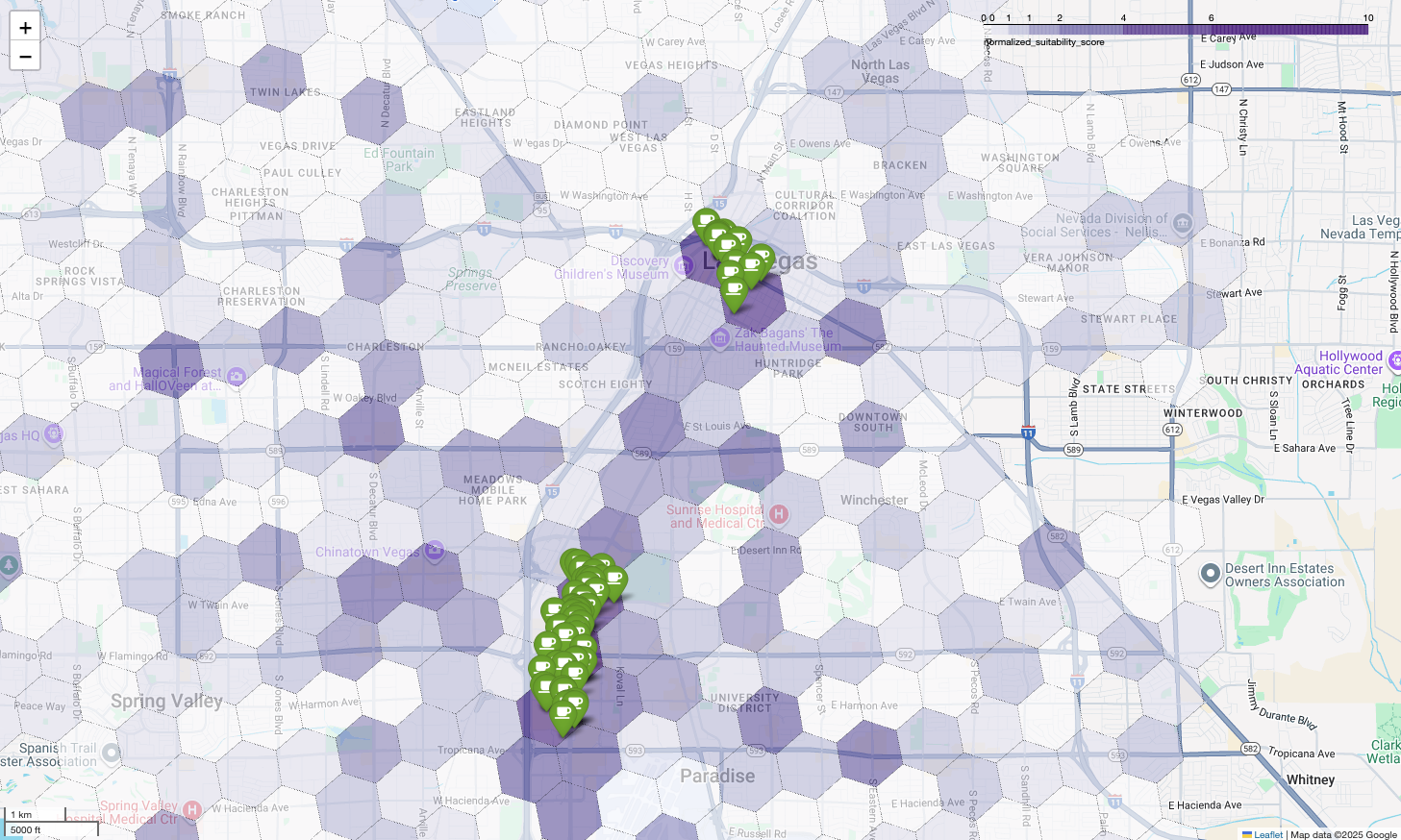
最後に、すべてを 1 つの強力な可視化にまとめます。紫色の適合性階級区分図をベースレイヤとしてプロットし、Places API から取得した個々のコーヒー ショップのピンを追加します。この最終的な地図は、分析全体をまとめた概要を示しています。濃い紫色のエリアは可能性を示し、緑色のピンは現在の市場の現実を示しています。
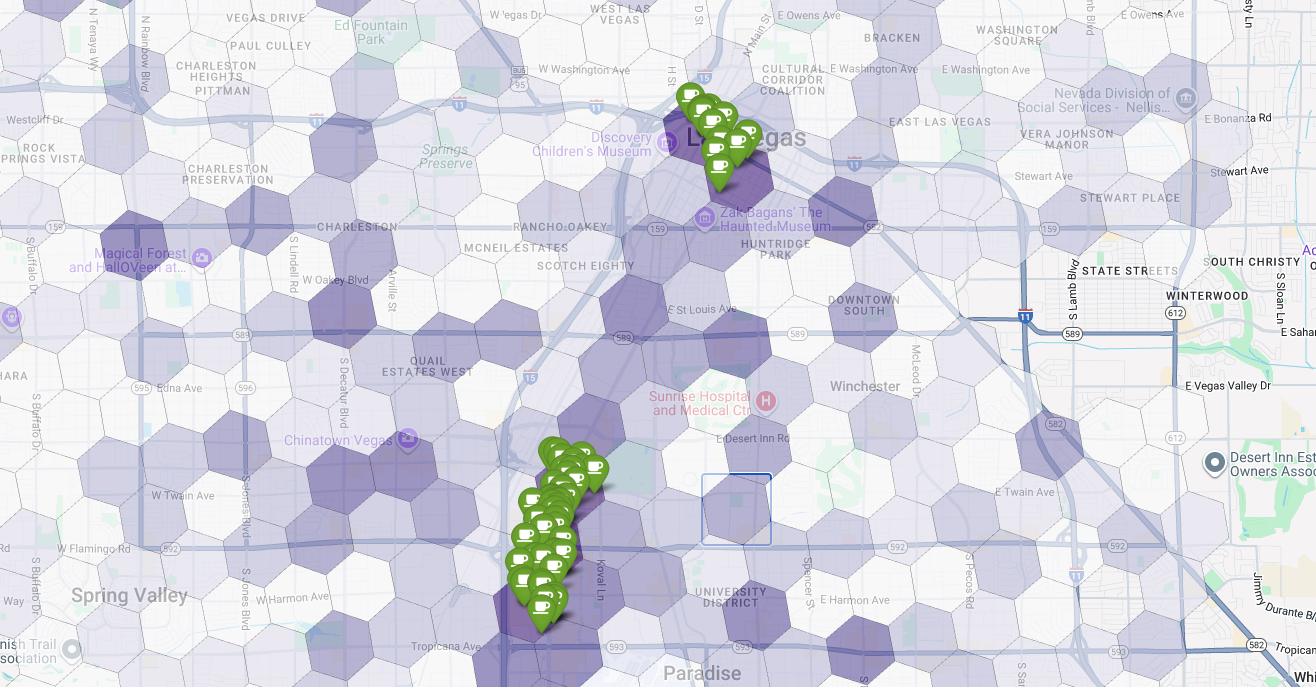
ピンがほとんどない、またはまったくない濃い紫色のセルを探すことで、新しい店舗に最適な場所を正確に特定できます。
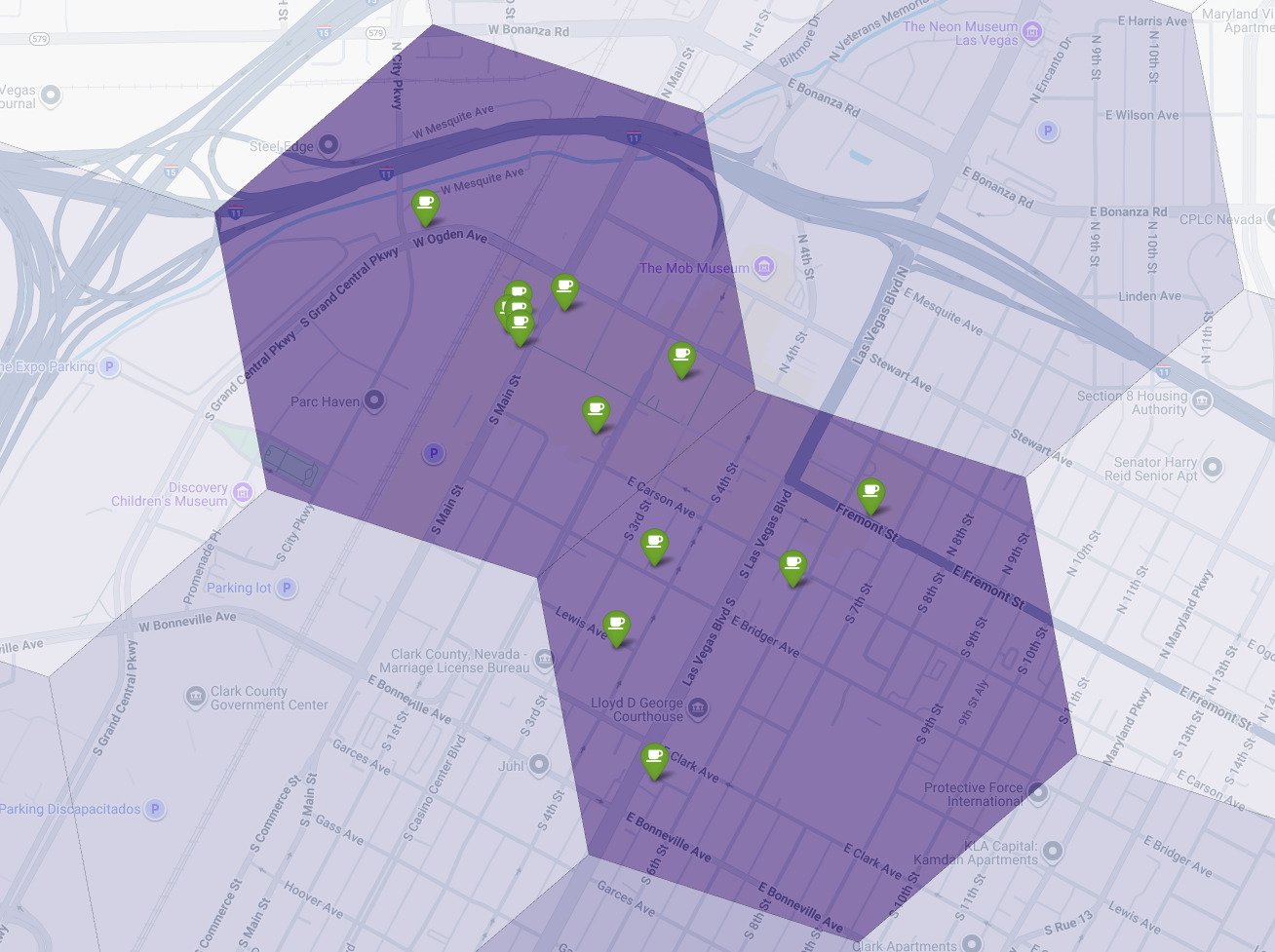
上記の 2 つのセルは適合性スコアが高いですが、新しいコーヒー ショップの候補地となる可能性のある明確なギャップがあります。
まとめ
このドキュメントでは、「どこに拡大すべきか?」という州全体の質問から、データに基づいたローカルな回答に移行しました。 さまざまなデータセットを重ね合わせ、カスタム ビジネス ロジックを適用することで、重要なビジネス上の意思決定に伴うリスクを体系的に軽減できます。BigQuery のスケール、Places Insights の豊富さ、Places API のリアルタイムの詳細を組み合わせたこのワークフローは、位置情報インテリジェンスを戦略的成長に活用しようとしている組織にとって強力なテンプレートとなります。
次のステップ
- 独自のビジネス ロジック、ターゲット地域、独自のデータセットを使用して、このワークフローを調整します。
- レビュー数、価格帯、ユーザー評価など、Places Insights データセットの他のデータ フィールドを調べて、モデルをさらに充実させます。
- このプロセスを自動化して、新しい市場を動的に評価するために使用できる内部サイト選択ダッシュボードを作成します。
ドキュメントの詳細:
コントリビューター
Henrik Valve | DevX エンジニア