
Pengantar
Dokumen ini menjelaskan cara membuat solusi pemilihan lokasi dengan menggabungkan set data Places Insights, data geospasial publik di BigQuery, dan Place Details API.
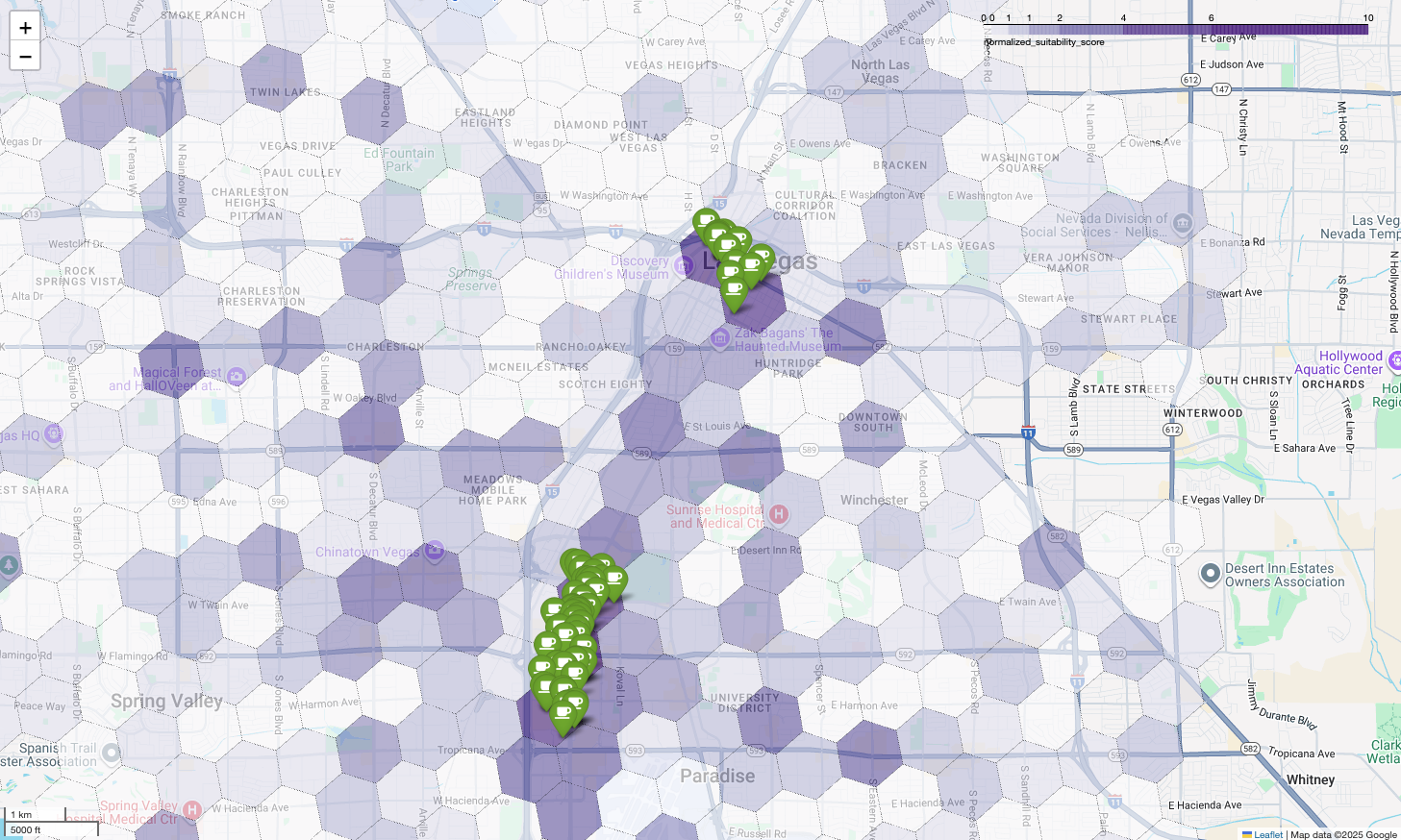
Peta di atas mengilustrasikan output demo yang diberikan di Google Cloud Next 2025, yang dapat ditonton di YouTube. Anda dapat menjalankan kode yang digunakan untuk menghasilkan hasil ini menggunakan contoh notebook.
 Lihat sumber di GitHub
Lihat sumber di GitHub
Tantangan Bisnis
Bayangkan Anda memiliki jaringan kedai kopi yang sukses dan ingin melakukan ekspansi ke negara bagian baru, seperti Nevada, tempat Anda belum memiliki kehadiran. Membuka lokasi baru adalah investasi yang signifikan, dan membuat keputusan berbasis data sangat penting untuk kesuksesan. Dari mana Anda harus memulai?
Panduan ini akan memandu Anda melakukan analisis berlapis untuk menentukan lokasi yang optimal bagi kedai kopi baru. Kita akan mulai dengan tampilan seluruh negara bagian, mempersempit penelusuran secara progresif ke wilayah dan zona komersial tertentu, dan terakhir melakukan analisis hiperlokal untuk memberi skor pada setiap area dan mengidentifikasi kesenjangan pasar dengan memetakan kompetitor.
Alur Kerja Solusi
Proses ini mengikuti funnel logis, dimulai dari yang luas dan menjadi semakin terperinci untuk menyempurnakan area penelusuran dan meningkatkan keyakinan dalam pemilihan situs akhir.
Prasyarat dan Penyiapan Lingkungan
Sebelum mempelajari analisis, Anda memerlukan lingkungan dengan beberapa kemampuan utama. Meskipun panduan ini akan membahas implementasi menggunakan SQL dan Python, prinsip umumnya dapat diterapkan ke stack teknologi lain.
Sebagai prasyarat, pastikan lingkungan Anda dapat:
- Jalankan kueri di BigQuery.
- Akses Places Insights, lihat Menyiapkan Places Insights untuk mengetahui informasi selengkapnya
- Berlangganan set data publik dari
bigquery-public-datadan US Census Bureau County Population Totals
Anda juga harus dapat memvisualisasikan data geospasial di peta, yang sangat penting untuk menafsirkan hasil setiap langkah analisis. Ada banyak cara untuk melakukannya. Anda dapat menggunakan alat BI seperti Looker Studio yang terhubung langsung ke BigQuery, atau menggunakan bahasa data science seperti Python.
Analisis Tingkat Negara Bagian: Menemukan County Terbaik
Langkah pertama kami adalah melakukan analisis luas untuk mengidentifikasi county yang paling menjanjikan di Nevada. Kami akan mendefinisikan menjanjikan sebagai kombinasi populasi yang tinggi dan kepadatan restoran yang sudah ada, yang menunjukkan budaya makanan dan minuman yang kuat.
Kueri BigQuery kami melakukannya dengan memanfaatkan komponen alamat
bawaan yang tersedia dalam set data Places Insights. Kueri menghitung restoran dengan terlebih dahulu memfilter data untuk hanya menyertakan tempat di negara bagian Nevada, menggunakan kolom administrative_area_level_1_name. Kemudian, kueri ini lebih lanjut
memperbaiki set ini untuk hanya menyertakan tempat yang array jenisnya berisi
'restaurant'. Terakhir, kueri ini mengelompokkan hasil ini menurut nama wilayah
(administrative_area_level_2_name) untuk menghasilkan jumlah untuk setiap wilayah. Pendekatan
ini memanfaatkan struktur alamat bawaan yang telah diindeks sebelumnya dari set data.
Cuplikan ini menunjukkan cara menggabungkan geometri wilayah dengan Insight Tempat dan memfilter
untuk jenis tempat tertentu, restaurant:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
Jumlah restoran mentah saja tidak cukup; kita perlu menyeimbangkannya dengan data populasi untuk mendapatkan gambaran yang sebenarnya tentang saturasi dan peluang pasar. Kami akan menggunakan data populasi dari US Census Bureau County Population Totals.
Untuk membandingkan dua metrik yang sangat berbeda ini (jumlah tempat versus jumlah populasi yang besar), kita menggunakan normalisasi min-maks. Teknik ini menskalakan kedua metrik ke rentang umum (0 hingga 1). Kemudian, kita menggabungkannya menjadi satu
normalized_score, dengan memberikan bobot 50% untuk setiap metrik agar perbandingan seimbang.
Kutipan ini menunjukkan logika inti untuk menghitung skor. Menggabungkan jumlah populasi dan restoran yang dinormalisasi:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
Setelah menjalankan kueri lengkap, daftar wilayah, jumlah restoran, populasi, dan skor yang dinormalisasi akan ditampilkan. Pengurutan berdasarkan normalized_score
DESC menunjukkan bahwa Clark County adalah pemenang yang jelas untuk diselidiki lebih lanjut sebagai pesaing teratas.
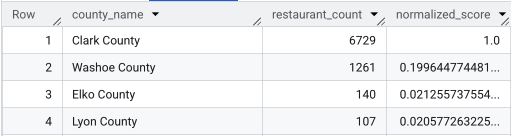
Screenshot ini menunjukkan 4 wilayah teratas berdasarkan skor yang dinormalisasi. Jumlah populasi mentah sengaja tidak disertakan dalam contoh ini.
Analisis Tingkat Kabupaten: Menemukan Zona Komersial Tersibuk
Setelah mengidentifikasi Clark County, langkah berikutnya adalah memperbesar untuk menemukan kode pos dengan aktivitas komersial tertinggi. Berdasarkan data dari kedai kopi yang sudah ada, kami tahu bahwa performa lebih baik jika berlokasi di dekat merek-merek besar dengan kepadatan tinggi, jadi kami akan menggunakan hal ini sebagai indikasi lalu lintas pejalan kaki yang tinggi.
Kueri ini menggunakan tabel brands dalam Insight Tempat, yang berisi informasi tentang merek tertentu. Tabel ini dapat
dikueri untuk menemukan daftar merek yang didukung. Pertama-tama, kita menentukan daftar merek target, lalu menggabungkannya dengan set data utama Places Insights untuk menghitung jumlah toko tertentu ini yang berada dalam setiap kode pos di Clark County.
Cara paling efisien untuk mencapai hal ini adalah dengan pendekatan dua langkah:
- Pertama, kita akan melakukan agregasi non-geospatial yang cepat untuk menghitung merek dalam setiap kode pos.
- Kedua, kita akan menggabungkan hasil tersebut ke set data publik untuk mendapatkan batas peta untuk visualisasi.
Menghitung Merek Menggunakan Kolom postal_code_names
Kueri pertama ini menjalankan logika penghitungan inti. Kueri ini memfilter tempat di Clark County, lalu memisahkan array postal_code_names untuk mengelompokkan jumlah merek menurut kode pos.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
Outputnya adalah tabel kode pos dan jumlah merek yang sesuai.
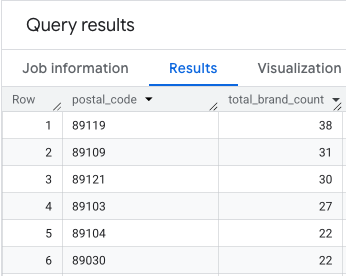
Melampirkan Geometri Kode Pos untuk Pemetaan
Setelah memiliki jumlahnya, kita bisa mendapatkan bentuk poligon yang diperlukan untuk
visualisasi. Kueri kedua ini mengambil kueri pertama kita, membungkusnya dalam Common Table Expression (CTE) bernama brand_counts_by_zip, dan menggabungkan hasilnya ke geo_us_boundaries.zip_codes table publik. Hal ini secara efisien melampirkan
geometri ke jumlah yang telah dihitung sebelumnya.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
Outputnya adalah tabel kode pos, jumlah merek yang sesuai, dan geometri kode pos.

Kita dapat memvisualisasikan data ini sebagai peta panas. Area merah yang lebih gelap menunjukkan konsentrasi merek target yang lebih tinggi, sehingga mengarahkan kami ke zona dengan kepadatan komersial tertinggi di Las Vegas.
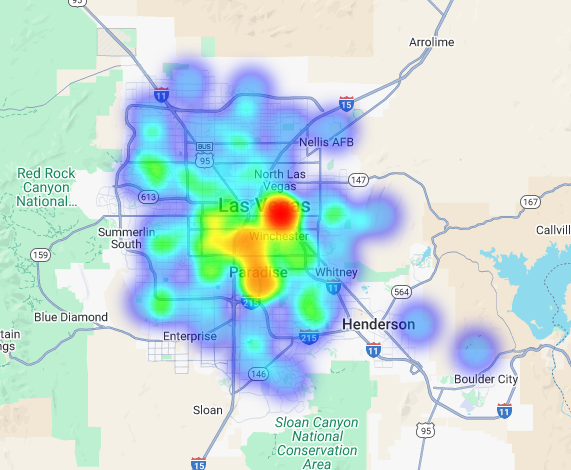
Analisis Hyper-Lokal: Memberi Skor pada Setiap Area Petak
Setelah mengidentifikasi area umum Las Vegas, saatnya melakukan analisis terperinci. Di sinilah kita menambahkan pengetahuan bisnis spesifik kita. Kami tahu bahwa kedai kopi yang bagus akan ramai di dekat bisnis lain yang ramai pada jam-jam sibuk kami, seperti pada pagi hari dan saat makan siang.
Kueri berikutnya akan menjadi sangat spesifik. Proses ini dimulai dengan membuat petak heksagonal dengan perincian tinggi di area metropolitan Las Vegas menggunakan indeks geospasial H3 standar (pada resolusi 8) untuk menganalisis area tersebut pada tingkat mikro. Kueri pertama-tama mengidentifikasi semua bisnis pelengkap yang buka selama periode puncak kami (Senin, pukul 10.00 hingga 14.00).
Kemudian, kami menerapkan skor berbobot ke setiap jenis tempat. Restoran di sekitar lebih berharga bagi kami daripada minimarket, sehingga restoran tersebut mendapatkan pengali yang lebih tinggi. Hal ini
memberi kita suitability_score kustom untuk setiap area kecil.
Kutipan ini menyoroti logika pemberian skor berbobot, yang mereferensikan flag yang telah dihitung sebelumnya (is_open_monday_window) untuk pemeriksaan jam buka:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
Luaskan untuk melihat kueri lengkap
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
Memvisualisasikan skor ini di peta akan mengungkapkan lokasi yang jelas menang. Ubin ungu paling gelap, terutama di dekat Las Vegas Strip dan Downtown, adalah area dengan potensi tertinggi untuk kedai kopi baru kami.
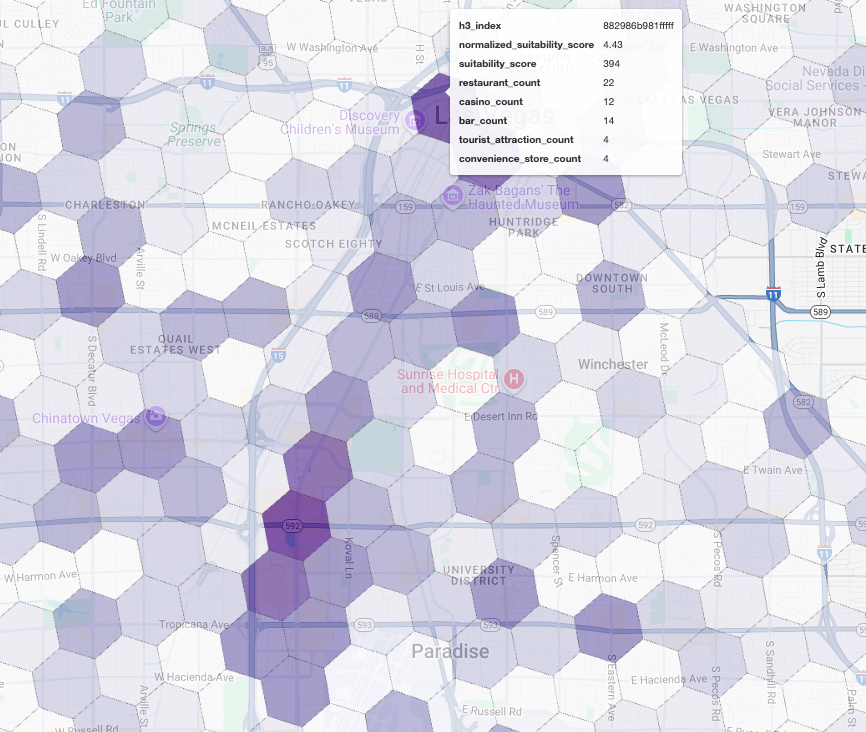
Analisis Kompetitor: Mengidentifikasi Kedai Kopi yang Ada
Model kesesuaian kami telah berhasil mengidentifikasi zona yang paling menjanjikan, tetapi skor yang tinggi saja tidak menjamin kesuksesan. Sekarang kita harus menempatkan data ini di atas data pesaing. Lokasi yang ideal adalah area berpotensi tinggi dengan kepadatan kedai kopi yang rendah, karena kami mencari celah pasar yang jelas.
Untuk melakukannya, kita menggunakan fungsi
PLACES_COUNT_PER_H3. Fungsi ini dirancang untuk menampilkan jumlah tempat secara efisien dalam geografi yang ditentukan, menurut sel H3.
Pertama, kita akan menentukan geografi secara dinamis untuk seluruh area metro Las Vegas.
Daripada mengandalkan satu lokalitas, kami membuat kueri set data Overture Maps publik untuk mendapatkan batas Las Vegas dan lokalitas utama di sekitarnya, lalu menggabungkannya menjadi satu poligon dengan ST_UNION_AGG. Kemudian, kita meneruskan area ini ke dalam fungsi, memintanya untuk menghitung semua kedai kopi yang beroperasi.
Kueri ini menentukan area metropolitan dan memanggil fungsi untuk mendapatkan jumlah kedai kopi di sel H3:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
Fungsi ini menampilkan tabel yang mencakup indeks sel H3, geometrinya, jumlah total kedai kopi, dan contoh ID Tempatnya:
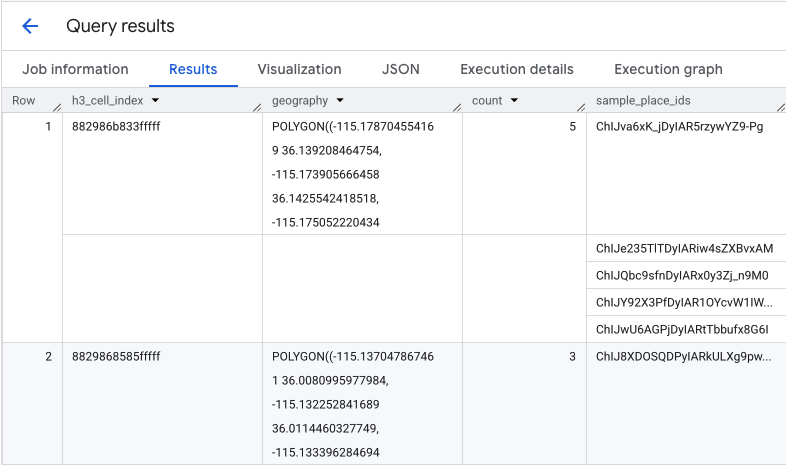
Meskipun jumlah gabungan berguna, melihat pesaing sebenarnya sangat penting.
Di sinilah kita bertransisi dari set data Places Insights ke Places API. Dengan mengekstrak
sample_place_ids dari sel dengan skor kecocokan yang dinormalisasi tertinggi,
kita dapat memanggil Place Details
API untuk mengambil detail lengkap
setiap pesaing, seperti nama, alamat, rating, dan lokasi mereka.
Hal ini memerlukan perbandingan hasil kueri sebelumnya, tempat skor kesesuaian dibuat, dan kueri PLACES_COUNT_PER_H3. Indeks Sel H3 dapat digunakan untuk mendapatkan jumlah dan ID kedai kopi dari sel dengan skor kecocokan yang dinormalisasi tertinggi.
Kode Python ini menunjukkan cara perbandingan ini dapat dilakukan.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
Sekarang kita memiliki daftar ID Tempat untuk kedai kopi yang sudah ada dalam sel H3 dengan skor kecocokan tertinggi. Detail lebih lanjut tentang setiap tempat dapat diminta.
Hal ini dapat dilakukan dengan mengirim permintaan ke Place Details API secara langsung untuk setiap Place ID, atau menggunakan Client Library untuk melakukan panggilan. Jangan lupa untuk menetapkan parameter
FieldMask
agar hanya meminta data yang Anda butuhkan.
Terakhir, kita gabungkan semuanya menjadi satu visualisasi yang efektif. Kita memetakan peta koroplet kesesuaian ungu sebagai lapisan dasar, lalu menambahkan pin untuk setiap kedai kopi yang diambil dari Places API. Peta akhir ini memberikan tampilan sekilas yang menyintesis seluruh analisis kita: area ungu tua menunjukkan potensi, dan pin hijau menunjukkan realitas pasar saat ini.
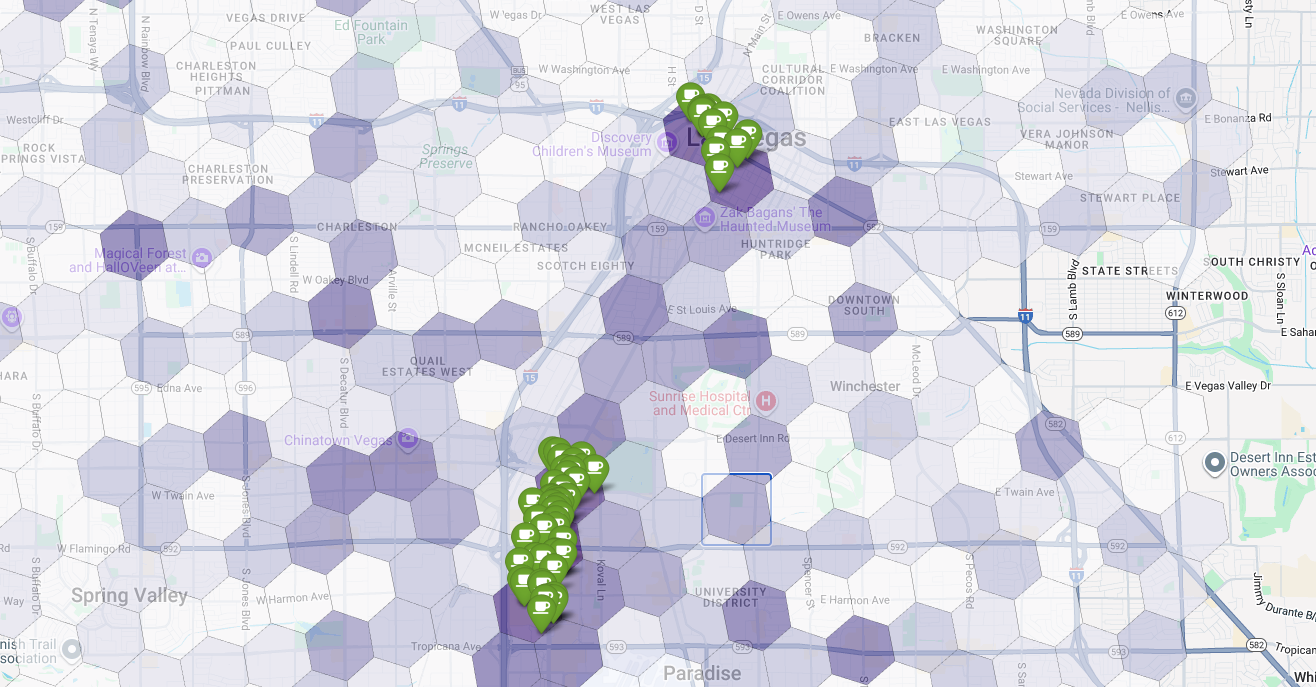
Dengan mencari sel berwarna ungu tua dengan sedikit atau tanpa pin, kita dapat dengan yakin menunjukkan area persis yang mewakili peluang terbaik untuk lokasi baru kita.
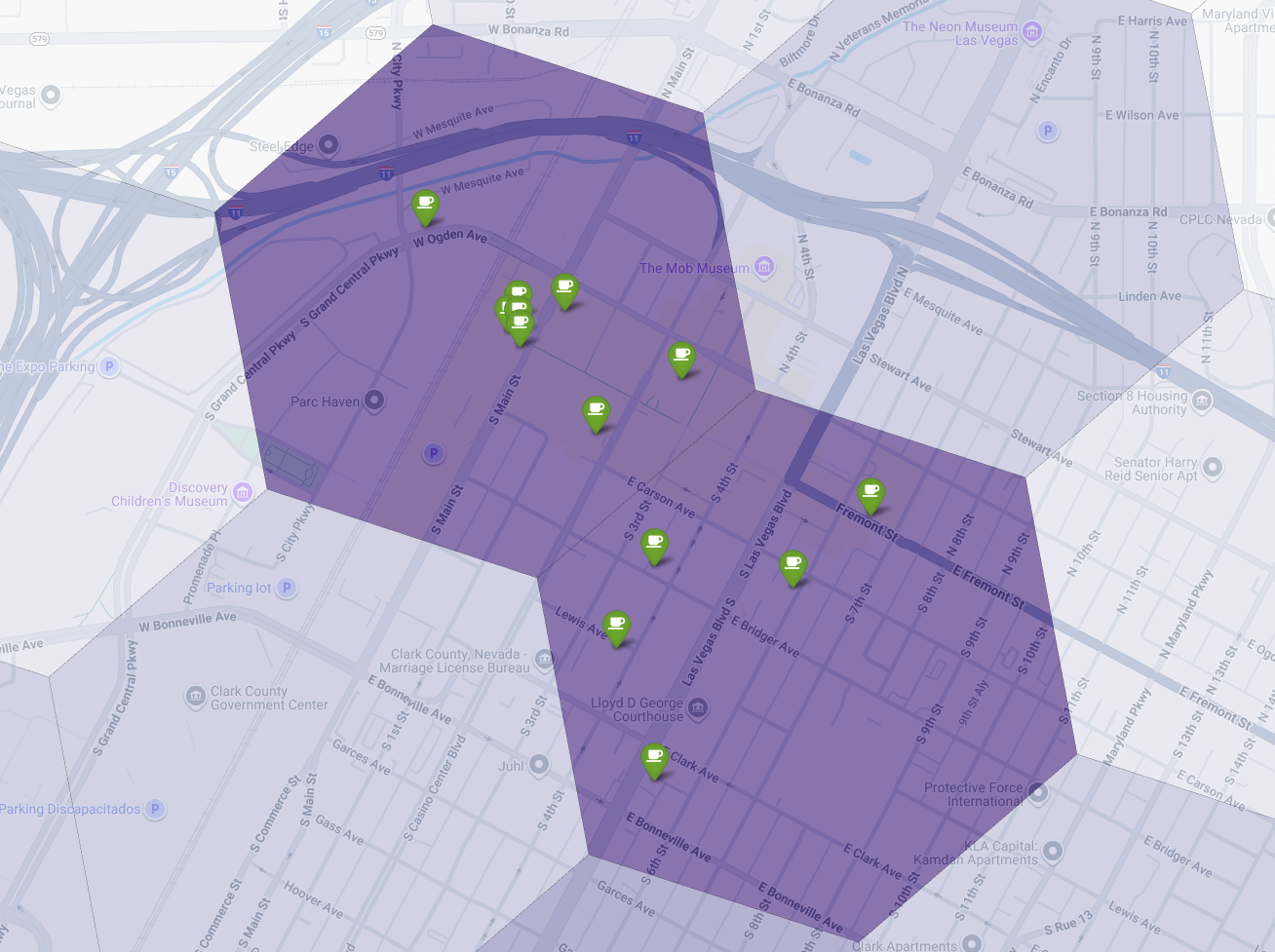
Dua sel di atas memiliki skor kesesuaian yang tinggi, tetapi beberapa celah yang jelas dapat menjadi lokasi potensial untuk kedai kopi baru kami.
Kesimpulan
Dalam dokumen ini, kami beralih dari pertanyaan di seluruh negara bagian tentang ke mana harus memperluas? menjadi jawaban lokal yang didukung data. Dengan menyusun berbagai set data dan menerapkan logika bisnis kustom, Anda dapat mengurangi risiko yang terkait dengan keputusan bisnis penting secara sistematis. Alur kerja ini, yang menggabungkan skala BigQuery, kekayaan Places Insights, dan detail real-time Places API, memberikan template yang efektif bagi organisasi yang ingin menggunakan analisis lokasi untuk pertumbuhan strategis.
Langkah berikutnya
- Sesuaikan alur kerja ini dengan logika bisnis, target geografi, dan set data eksklusif Anda.
- Jelajahi kolom data lainnya dalam set data Insight Tempat, seperti jumlah ulasan, tingkat harga, dan rating pengguna, untuk lebih memperkaya model Anda.
- Otomatiskan proses ini untuk membuat dasbor pemilihan situs internal yang dapat digunakan untuk mengevaluasi pasar baru secara dinamis.
Pelajari dokumentasi lebih lanjut:
Kontributor
Henrik Valve | DevX Engineer