
परिचय
इस दस्तावेज़ में, Places Insights के डेटासेट, सार्वजनिक जियोस्पेशल डेटा जो BigQuery में मौजूद है, और Place Details API को मिलाकर, साइट चुनने का समाधान बनाने का तरीका बताया गया है.
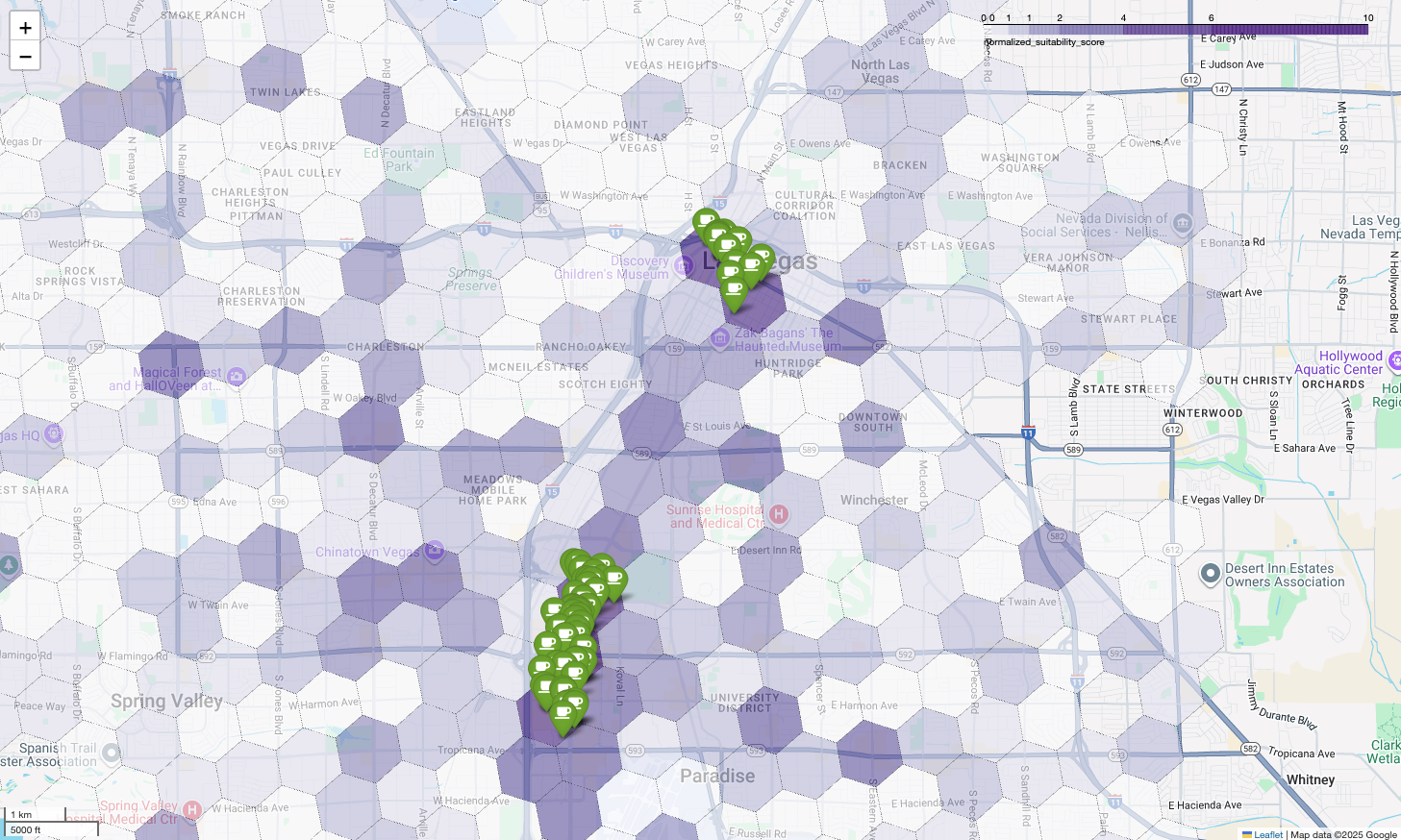
ऊपर दिए गए मैप में, Google Cloud Next 2025 में दिए गए डेमो का आउटपुट दिखाया गया है. इसे YouTube पर देखा जा सकता है. इन नतीजों को जनरेट करने के लिए इस्तेमाल किए गए कोड को, उदाहरण के तौर पर दिए गए नोटबुक का इस्तेमाल करके चलाया जा सकता है.
 GitHub पर सोर्स देखें
GitHub पर सोर्स देखें
कारोबार से जुड़ी चुनौती
मान लें कि आपकी कॉफ़ी शॉप की एक सफल चेन है और आपको नेवाडा जैसे किसी नए राज्य में कारोबार बढ़ाना है. हालांकि, इस राज्य में आपकी कोई कॉफ़ी शॉप नहीं है. नई जगह पर कॉफ़ी शॉप खोलना एक बड़ा निवेश है. ऐसे में, डेटा के आधार पर फ़ैसला लेना ज़रूरी है. ऐसे में, सबसे पहले क्या करना चाहिए?
इस गाइड में, नई कॉफ़ी शॉप के लिए सबसे सही जगह की पहचान करने के लिए, कई चरणों में विश्लेषण करने का तरीका बताया गया है. हम राज्य के लेवल पर विश्लेषण शुरू करेंगे. इसके बाद, धीरे-धीरे अपनी खोज को किसी खास काउंटी और कमर्शियल ज़ोन तक सीमित करेंगे. आखिर में, हर इलाके का स्कोर जानने और प्रतिस्पर्धियों की मैपिंग करके, मार्केट गैप की पहचान करने के लिए, हाइपर-लोकल विश्लेषण करेंगे.
समाधान का वर्कफ़्लो
यह प्रोसेस, लॉजिकल फ़नल के हिसाब से काम करती है. इसमें सबसे पहले, बड़े लेवल पर विश्लेषण किया जाता है. इसके बाद, खोज के दायरे को सीमित किया जाता है, ताकि साइट चुनने के फ़ैसले पर भरोसा किया जा सके.
ज़रूरी शर्तें और एनवायरमेंट सेटअप करना
विश्लेषण शुरू करने से पहले, आपको कुछ ज़रूरी सुविधाओं वाला एनवायरमेंट चाहिए. इस गाइड में, एसक्यूएल और Python का इस्तेमाल करके, लागू करने का तरीका बताया गया है. हालांकि, सामान्य सिद्धांतों को अन्य टेक्नोलॉजी स्टैक पर भी लागू किया जा सकता है.
ज़रूरी शर्त के तौर पर, पक्का करें कि आपका एनवायरमेंट ये काम कर सके:
- BigQuery में क्वेरी चलाना.
- Places Insights को ऐक्सेस करना. ज़्यादा जानकारी के लिए, Places Insights सेट अप करना लेख पढ़ें
bigquery-public-dataऔर अमेरिका के जनगणना ब्यूरो के काउंटी की कुल जनसंख्या के सार्वजनिक डेटासेट की सदस्यता लेना
आपको मैप पर जियोस्पेशल डेटा को विज़ुअलाइज़ भी करना होगा. यह हर चरण के नतीजों की व्याख्या करने के लिए ज़रूरी है. ऐसा कई तरीकों से किया जा सकता है. इसके लिए, Looker Studio जैसे बीआई टूल का इस्तेमाल किया जा सकता है. ये टूल, सीधे BigQuery से कनेक्ट होते हैं. इसके अलावा, Python जैसी डेटा साइंस की भाषाओं का भी इस्तेमाल किया जा सकता है.
राज्य के लेवल पर विश्लेषण: सबसे सही काउंटी ढूंढना
हमारा पहला कदम, नेवाडा में सबसे सही काउंटी की पहचान करने के लिए, बड़े लेवल पर विश्लेषण करना है. सबसे सही का मतलब है, ज़्यादा जनसंख्या और मौजूदा रेस्टोरेंट की ज़्यादा संख्या. इससे पता चलता है कि वहां खाने-पीने की संस्कृति मज़बूत है.
हमारी BigQuery क्वेरी, Places Insights के डेटासेट में मौजूद पते के कॉम्पोनेंट का इस्तेमाल करके, यह काम करती है. क्वेरी, रेस्टोरेंट की संख्या का पता लगाती है. इसके लिए, सबसे पहले डेटा को फ़िल्टर किया जाता है, ताकि सिर्फ़ नेवाडा राज्य में मौजूद जगहों को शामिल किया जा सके. इसके लिए, administrative_area_level_1_name फ़ील्ड का इस्तेमाल किया जाता है. इसके बाद, इस सेट को और बेहतर बनाया जाता है, ताकि सिर्फ़ उन जगहों को शामिल किया जा सके जहां टाइप ऐरे में 'restaurant' शामिल है. आखिर में, इन नतीजों को काउंटी के नाम (administrative_area_level_2_name) के हिसाब से ग्रुप किया जाता है, ताकि हर काउंटी के लिए रेस्टोरेंट की संख्या का पता लगाया जा सके. इस तरीके में, डेटासेट के पहले से इंडेक्स किए गए पते के स्ट्रक्चर का इस्तेमाल किया जाता है.
इस उदाहरण में दिखाया गया है कि हम काउंटी की ज्यामिति को Places Insights के साथ कैसे जोड़ते हैं और किसी खास जगह के टाइप, restaurant के लिए फ़िल्टर कैसे करते हैं:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
सिर्फ़ रेस्टोरेंट की संख्या काफ़ी नहीं है. हमें मार्केट में रेस्टोरेंट की संख्या और जनसंख्या के डेटा के बीच संतुलन बनाना होगा, ताकि मार्केट में रेस्टोरेंट की संख्या और अवसरों के बारे में सही जानकारी मिल सके. हम अमेरिका के जनगणना ब्यूरो के काउंटी की कुल जनसंख्या के डेटा का इस्तेमाल करेंगे.
इन दो अलग-अलग मेट्रिक (जगह की संख्या बनाम ज़्यादा जनसंख्या) की तुलना करने के लिए, हम मिन-मैक्स नॉर्मलाइज़ेशन का इस्तेमाल करते हैं. इस तकनीक से, दोनों मेट्रिक को 0 से 1 तक की सामान्य रेंज में स्केल किया जाता है. इसके बाद, हम इन दोनों को मिलाकर एक normalized_score बनाते हैं. इसमें, दोनों मेट्रिक को 50% वेट दिया जाता है, ताकि तुलना संतुलित हो.
इस उदाहरण में, स्कोर कैलकुलेट करने के लिए मुख्य लॉजिक दिखाया गया है. इसमें, नॉर्मलाइज़ की गई जनसंख्या और रेस्टोरेंट की संख्या को मिलाया गया है:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
पूरी क्वेरी चलाने के बाद, काउंटी की सूची, रेस्टोरेंट की संख्या, जनसंख्या, और नॉर्मलाइज़ किया गया स्कोर मिलता है. normalized_score
DESC के हिसाब से क्रम में लगाने पर, क्लार्क काउंटी सबसे सही काउंटी के तौर पर सामने आती है. इसलिए, आगे की जांच के लिए इसे
चुना जाता है.
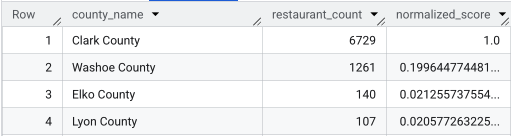
इस स्क्रीनशॉट में, नॉर्मलाइज़ किए गए स्कोर के हिसाब से टॉप चार काउंटी दिखाई गई हैं. इस उदाहरण में, जनसंख्या की संख्या को जान-बूझकर शामिल नहीं किया गया है.
काउंटी के लेवल पर विश्लेषण: सबसे ज़्यादा कमर्शियल गतिविधि वाले ज़िप कोड ढूंढना
अब हमने क्लार्क काउंटी की पहचान कर ली है. अगला कदम, सबसे ज़्यादा कमर्शियल गतिविधि वाले ज़िप कोड ढूंढना है. हमारी मौजूदा कॉफ़ी शॉप के डेटा के आधार पर, हमें पता है कि प्रमुख ब्रैंड के आस-पास होने पर, परफ़ॉर्मेंस बेहतर होती है. इसलिए, हम इसे ज़्यादा फ़ुट ट्रैफ़िक के प्रॉक्सी के तौर पर इस्तेमाल करेंगे.
इस क्वेरी में, Places Insights में मौजूद brands टेबल का इस्तेमाल किया जाता है. इसमें, खास ब्रैंड के बारे में जानकारी होती है. इस टेबल को
क्वेरी करके, काम करने वाले
ब्रैंड की सूची देखी जा सकती है. सबसे पहले, हम अपने टारगेट ब्रैंड की सूची तय करते हैं. इसके बाद, इसे Places Insights के मुख्य डेटासेट के साथ जोड़ते हैं, ताकि यह पता लगाया जा सके कि क्लार्क काउंटी के हर ज़िप कोड में, इनमें से कितने स्टोर मौजूद हैं.
इसे हासिल करने का सबसे सही तरीका, दो चरणों वाला तरीका है:
- सबसे पहले, हम हर पिन कोड में ब्रैंड की संख्या का पता लगाने के लिए, तेज़ और नॉन-जियोस्पेशल एग्रीगेशन करेंगे.
- इसके बाद, हम उन नतीजों को सार्वजनिक डेटासेट के साथ जोड़ेंगे, ताकि विज़ुअलाइज़ेशन के लिए मैप की सीमाएं मिल सकें.
postal_code_names फ़ील्ड का इस्तेमाल करके ब्रैंड की संख्या का पता लगाना
यह पहली क्वेरी, संख्या का पता लगाने के लिए मुख्य लॉजिक का इस्तेमाल करती है. यह क्लार्क काउंटी में मौजूद जगहों के लिए फ़िल्टर करती है. इसके बाद, पिन कोड के हिसाब से ब्रैंड की संख्या को ग्रुप करने के लिए, postal_code_names ऐरे को अननेस्ट करती है.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
इसका आउटपुट, पिन कोड और उनसे जुड़े ब्रैंड की संख्या वाली टेबल होती है.
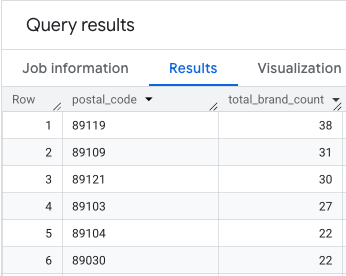
मैपिंग के लिए ज़िप कोड की ज्यामिति जोड़ना
अब हमारे पास संख्या है, इसलिए हम विज़ुअलाइज़ेशन के लिए ज़रूरी पॉलीगॉन शेप पा सकते हैं. यह दूसरी क्वेरी, हमारी पहली क्वेरी लेती है. इसके बाद, इसे brand_counts_by_zip नाम के कॉमन टेबल एक्सप्रेशन (सीटीई) में रैप करती है. साथ ही, इसके नतीजों को सार्वजनिक geo_us_boundaries.zip_codes table के साथ जोड़ती है. इससे, पहले से कैलकुलेट की गई संख्या के साथ ज्यामिति को आसानी से जोड़ा जा सकता है.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
इसका आउटपुट, पिन कोड, उनसे जुड़े ब्रैंड की संख्या, और पिन कोड की ज्यामिति वाली टेबल होती है.
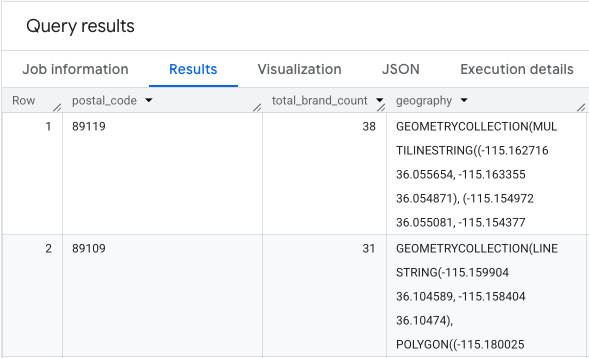
हम इस डेटा को विज़ुअलाइज़ हीटमैप के तौर पर कर सकते हैं. गहरे लाल रंग के इलाके, हमारे टारगेट ब्रैंड की ज़्यादा संख्या दिखाते हैं. इससे हमें लास वेगस में सबसे ज़्यादा कमर्शियल गतिविधि वाले ज़ोन के बारे में पता चलता है.
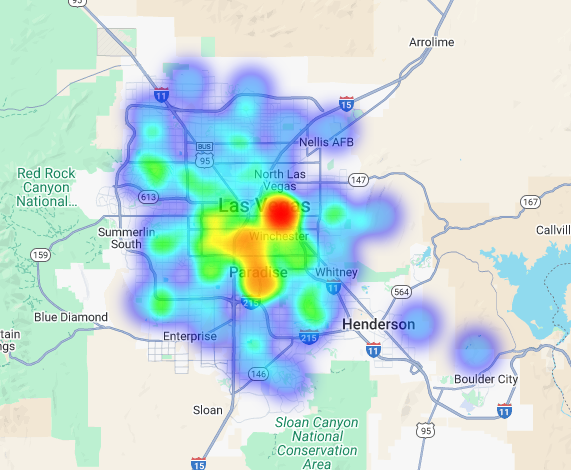
हाइपर-लोकल विश्लेषण: अलग-अलग ग्रिड एरिया का स्कोर जानना
लास वेगस के सामान्य इलाके की पहचान करने के बाद, अब बारी है बारीक विश्लेषण करने की. इसमें, हम अपने कारोबार की खास जानकारी शामिल करते हैं. हमें पता है कि एक अच्छी कॉफ़ी शॉप, उन अन्य कारोबारों के आस-पास अच्छी चलती है जो हमारे पीक आवर्स (जैसे कि सुबह के आखिर में और लंच के समय) के दौरान व्यस्त रहते हैं.
हमारी अगली क्वेरी, बहुत खास जानकारी देती है. यह माइक्रो-लेवल पर इलाके का विश्लेषण करने के लिए, स्टैंडर्ड H3 जियोस्पेशल इंडेक्स (रिज़ॉल्यूशन 8 पर) का इस्तेमाल करके, लास वेगस मेट्रोपॉलिटन इलाके पर बारीक हेक्सागोनल ग्रिड बनाती है. क्वेरी, सबसे पहले उन सभी पूरक कारोबारों की पहचान करती है जो हमारे पीक आवर्स (सोमवार, सुबह 10 बजे से दोपहर 2 बजे तक) के दौरान खुले रहते हैं.
इसके बाद, हम हर जगह के टाइप पर वेटेड स्कोर लागू करते हैं. हमारे लिए, आस-पास का रेस्टोरेंट, सुविधा स्टोर से ज़्यादा काम का है. इसलिए, इसे ज़्यादा मल्टीप्लायर मिलता है. इससे हमें हर छोटे इलाके के लिए, पसंद के मुताबिक suitability_score मिलता है.
इस उदाहरण में, वेटेड स्कोरिंग लॉजिक को हाइलाइट किया गया है. इसमें, खुलने के समय की जांच के लिए, पहले से कैलकुलेट किए गए फ़्लैग (is_open_monday_window) का रेफ़रंस दिया गया है:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
पूरी क्वेरी देखने के लिए, बड़ा करें
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
मैप पर इन स्कोर को विज़ुअलाइज़ करने से, सबसे सही जगहें साफ़ तौर पर दिखती हैं. सबसे गहरे बैंगनी रंग की टाइलें, मुख्य रूप से लास वेगस स्ट्रिप और डाउनटाउन के पास मौजूद इलाके दिखाती हैं. ये इलाके, हमारी नई कॉफ़ी शॉप के लिए सबसे सही हैं.
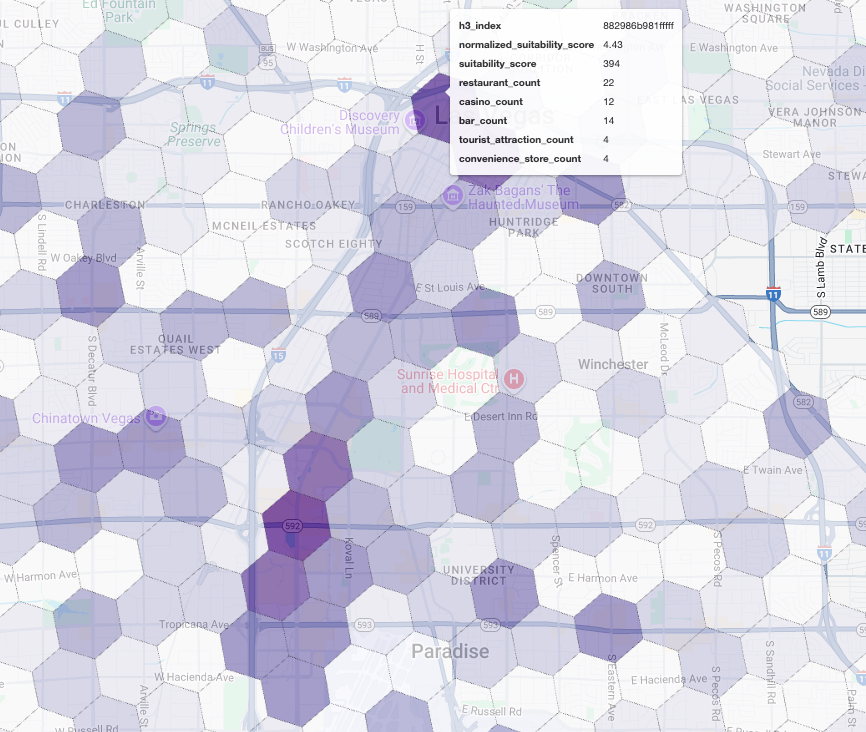
प्रतिस्पर्धी का विश्लेषण: मौजूदा कॉफ़ी शॉप की पहचान करना
हमारे सुटेबिलिटी मॉडल ने सबसे सही ज़ोन की पहचान कर ली है. हालांकि, सिर्फ़ ज़्यादा स्कोर से सफलता की गारंटी नहीं मिलती. अब हमें इसे प्रतिस्पर्धी के डेटा के साथ ओवरले करना होगा. सबसे सही जगह वह होती है जहां ज़्यादा संभावनाएं हों और मौजूदा कॉफ़ी शॉप की संख्या कम हो, क्योंकि हम मार्केट गैप की पहचान करना चाहते हैं.
इसके लिए, हम
PLACES_COUNT_PER_H3
फ़ंक्शन का इस्तेमाल करते हैं. इस फ़ंक्शन को, H3 सेल के हिसाब से, तय की गई जगह में मौजूद जगहों की संख्या को आसानी से दिखाने के लिए डिज़ाइन किया गया है.
सबसे पहले, हम लास वेगस के पूरे मेट्रो इलाके के लिए, डाइनैमिक तरीके से जगह तय करते हैं.
हम सिर्फ़ एक इलाके पर निर्भर रहने के बजाय, सार्वजनिक Overture Maps के डेटासेट को क्वेरी करके, लास वेगस और उसके आस-पास के मुख्य इलाकों की सीमाएं पाते हैं. इसके बाद, ST_UNION_AGG का इस्तेमाल करके, इन सीमाओं को एक पॉलीगॉन में मर्ज करते हैं. इसके बाद, हम इस इलाके को फ़ंक्शन में पास करते हैं और उससे सभी चालू कॉफ़ी शॉप की संख्या का पता लगाने के लिए कहते हैं.
यह क्वेरी, मेट्रो इलाके को तय करती है और H3 सेल में कॉफ़ी शॉप की संख्या का पता लगाने के लिए, फ़ंक्शन को कॉल करती है:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
फ़ंक्शन, एक टेबल दिखाता है. इसमें H3 सेल इंडेक्स, उसकी ज्यामिति, कॉफ़ी शॉप की कुल संख्या, और उनके Place आईडी का सैंपल शामिल होता है:
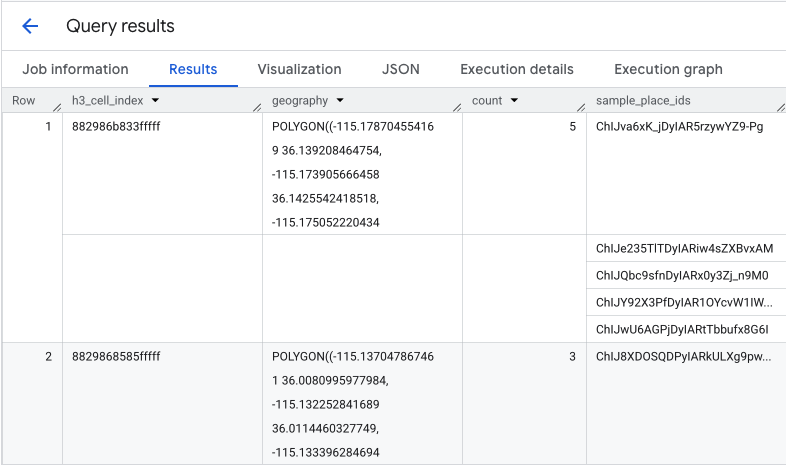
एग्रीगेट संख्या काम की है, लेकिन असल प्रतिस्पर्धियों को देखना ज़रूरी है.
इसके लिए, हम Places Insights के डेटासेट से Places
API पर ट्रांज़िशन करते हैं. नॉर्मलाइज़ किए गए सुटेबिलिटी स्कोर वाले सेल से
sample_place_ids निकालकर,
हम Place Details
API को कॉल करके, हर प्रतिस्पर्धी के बारे में ज़्यादा जानकारी पा सकते हैं. जैसे कि उनका नाम, पता, रेटिंग, और जगह.
इसके लिए, पिछली क्वेरी के नतीजों की तुलना करनी होगी. इसमें, सुटेबिलिटी स्कोर जनरेट किया गया था. साथ ही, PLACES_COUNT_PER_H3 क्वेरी के नतीजों की तुलना करनी होगी. नॉर्मलाइज़ किए गए सुटेबिलिटी स्कोर वाले सेल से, कॉफ़ी शॉप की संख्या और आईडी पाने के लिए, H3 सेल इंडेक्स का इस्तेमाल किया जा सकता है.
इस Python कोड में दिखाया गया है कि यह तुलना कैसे की जा सकती है.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
अब हमारे पास उन कॉफ़ी शॉप के Place आईडी की सूची है जो सबसे ज़्यादा सुटेबिलिटी स्कोर वाले H3 सेल में पहले से मौजूद हैं. हर जगह के बारे में ज़्यादा जानकारी का अनुरोध किया जा सकता है.
इसके लिए, हर
Place ID के लिए सीधे Place Details
API को अनुरोध भेजा जा सकता है या कॉल करने के लिए, Client
Library का इस्तेमाल किया जा सकता है. ज़रूरी डेटा का अनुरोध करने के लिए,
FieldMask
पैरामीटर सेट करना न भूलें.
आखिर में, हम सभी जानकारी को एक ही विज़ुअलाइज़ेशन में शामिल करते हैं. हम बेस लेयर के तौर पर, बैंगनी रंग का सुटेबिलिटी कोरोप्लेथ मैप बनाते हैं. इसके बाद, Places API से मिले हर कॉफ़ी शॉप के लिए पिन जोड़ते हैं. इस आखिरी मैप से, एक नज़र में पूरी जानकारी मिलती है: गहरे बैंगनी रंग के इलाके, संभावित जगहें दिखाते हैं. वहीं, हरे पिन, मौजूदा मार्केट की असल स्थिति दिखाते हैं.
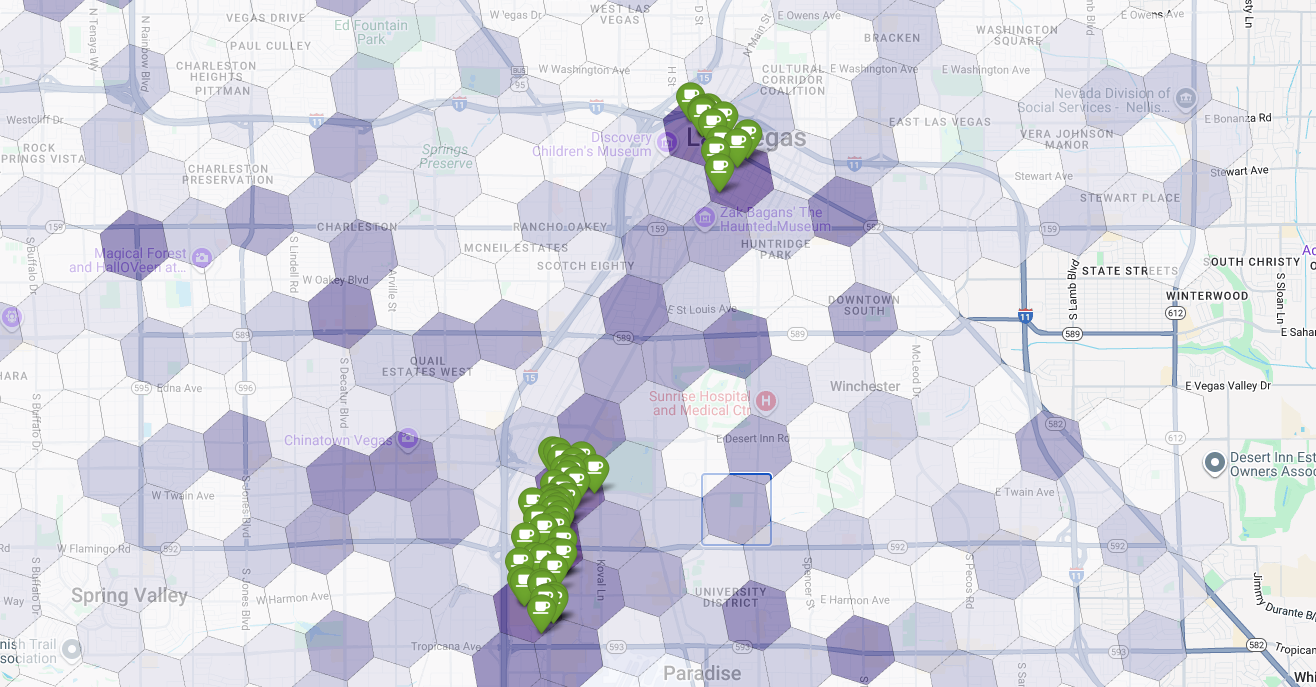
कम या बिना पिन वाले गहरे बैंगनी रंग के सेल देखकर, हम उन सटीक इलाकों की पहचान कर सकते हैं जो हमारी नई कॉफ़ी शॉप के लिए सबसे सही हैं.
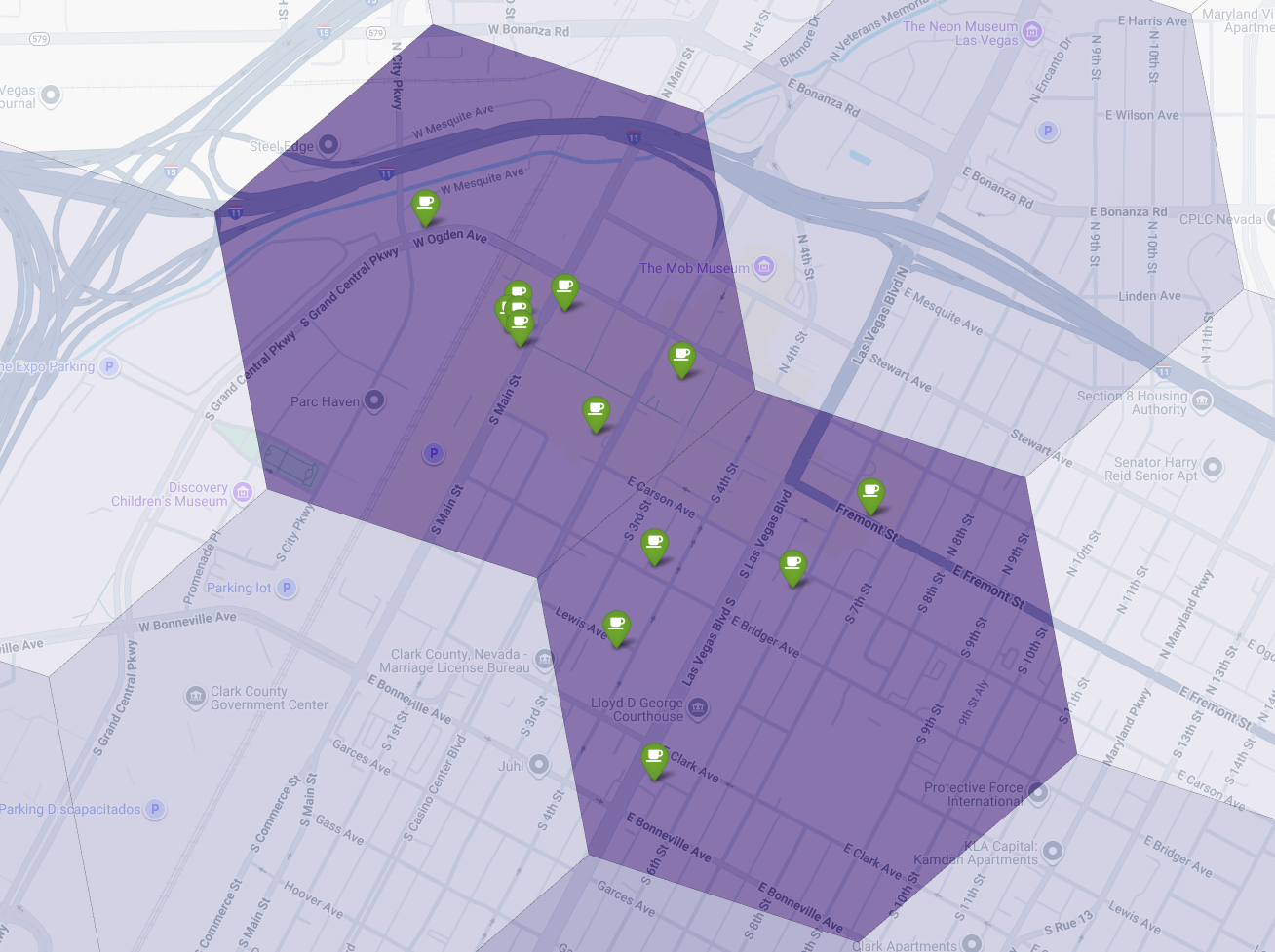
ऊपर दिए गए दोनों सेल का सुटेबिलिटी स्कोर ज़्यादा है. हालांकि, इनमें कुछ ऐसे गैप हैं जो हमारी नई कॉफ़ी शॉप के लिए संभावित जगहें हो सकती हैं.
नतीजा
इस दस्तावेज़ में, हमने कारोबार कहां बढ़ाया जाए? जैसे राज्य के लेवल के सवाल का जवाब, डेटा के आधार पर और स्थानीय लेवल पर दिया है. अलग-अलग डेटासेट को मिलाकर और कारोबार के लिए पसंद के मुताबिक लॉजिक लागू करके, कारोबार से जुड़े बड़े फ़ैसले से जुड़े जोखिम को कम किया जा सकता है. इस वर्कफ़्लो में, BigQuery के स्केल, Places Insights की ज़्यादा जानकारी, और Places API की रीयल-टाइम जानकारी को मिलाया गया है. इससे, रणनीतिक विकास के लिए जगह की जानकारी का इस्तेमाल करने वाले किसी भी संगठन के लिए, एक बेहतरीन टेंप्लेट मिलता है.
अगले चरण
- इस वर्कफ़्लो को अपने कारोबार के लॉजिक, टारगेट जगहों, और मालिकाना हक वाले डेटासेट के हिसाब से अडैप्ट करें.
- अपने मॉडल को और बेहतर बनाने के लिए, Places Insights के डेटासेट में मौजूद अन्य डेटा फ़ील्ड एक्सप्लोर करें. जैसे कि समीक्षाओं की संख्या, कीमत के लेवल, और उपयोगकर्ता की रेटिंग.
- इस प्रोसेस को ऑटोमेट करें, ताकि साइट चुनने के लिए एक इंटरनल डैशबोर्ड बनाया जा सके. इसका इस्तेमाल, नए मार्केट का डाइनैमिक तरीके से आकलन करने के लिए किया जा सकता है.
ज़्यादा जानकारी के लिए, दस्तावेज़ देखें:
- Places Insights की खास जानकारी
- Places Insights के फ़ंक्शन
- BigQuery का जियोस्पेशल विश्लेषण
- Places API
योगदानकर्ता
हेनरिक वाल्व | DevX इंजीनियर