
L'API Cloud Vision encapsule des modèles de machine learning performants dans une API REST facile à utiliser pour vous permettre de comprendre le contenu d'une image.
Dans cet atelier, nous allons envoyer des images à l'API Vision et observer comment elle détecte les objets, les visages et les points de repère.
Points abordés
- Créer une requête API Vision et appeler l'API avec curl
- Utiliser les méthodes de détection des thèmes, du Web, des visages et des points de repère de l'API Vision
Ce dont vous avez besoin
Comment allez-vous utiliser ce tutoriel ?
Quel est votre niveau d'expérience avec Google Cloud Platform ?
Configuration de l'environnement au rythme de chacun
Si vous ne possédez pas encore de compte Google (Gmail ou Google Apps), vous devez en créer un. Connectez-vous à la console Google Cloud Platform (console.cloud.google.com) et créez un projet :



Mémorisez l'ID du projet. Il s'agit d'un nom unique permettant de différencier chaque projet Google Cloud (le nom ci-dessus est déjà pris ; vous devez en trouver un autre). Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
Vous devez ensuite activer la facturation dans la console Cloud pour pouvoir utiliser les ressources Google Cloud.
Suivre cet atelier de programmation ne devrait pas vous coûter plus d'un euro. Cependant, cela peut s'avérer plus coûteux si vous décidez d'utiliser davantage de ressources ou si vous n'interrompez pas les ressources (voir la section "Effectuer un nettoyage" à la fin du présent document).
Les nouveaux utilisateurs de Google Cloud Platform peuvent bénéficier d'un essai sans frais avec 300$de crédits.
Cliquez sur l'icône de menu en haut à gauche de l'écran.

Sélectionnez API et services dans le menu déroulant, puis cliquez sur "Tableau de bord".
Cliquez sur Activer les API et les services.
Ensuite, recherchez "vision" dans le champ de recherche. Cliquez sur API Google Cloud Vision :

Cliquez sur Activer pour activer l'API Cloud Vision :

Patientez quelques secondes jusqu'à ce qu'il soit activé. Une fois la fonctionnalité activée, vous verrez ceci :
Google Cloud Shell est un environnement de ligne de commande exécuté dans le cloud. Cette machine virtuelle basée sur Debian contient tous les outils de développement dont vous aurez besoin (gcloud, bq, git, etc.) et offre un répertoire de base persistant de 5 Go. Nous allons utiliser Cloud Shell pour créer notre requête à l'API Speech.
Pour commencer à utiliser Cloud Shell, cliquez sur l'icône  "Activer Google Cloud Shell" en haut à droite de la barre d'en-tête.
"Activer Google Cloud Shell" en haut à droite de la barre d'en-tête.

Une session Cloud Shell s'ouvre dans un nouveau cadre en bas de la console et affiche une invite de ligne de commande. Attendez que l'invite user@project:~$ s'affiche.
Comme nous allons utiliser curl pour envoyer une requête à l'API Vision, nous devons générer une clé API pour transmettre l'URL de notre requête. Pour créer une clé API, accédez à la section "Identifiants" d'API et services dans votre console Cloud :
Dans le menu déroulant, sélectionnez Clé API :
Ensuite, copiez la clé que vous venez de générer.
Vous disposez désormais d'une clé API. Enregistrez sa valeur dans une variable d'environnement afin d'éviter de l'insérer à chaque requête. Vous pouvez effectuer cette opération dans Cloud Shell. Veillez à remplacer <your_api_key> par la clé que vous venez de copier.
export API_KEY=<YOUR_API_KEY>Créer un bucket Cloud Storage
Deux méthodes sont disponibles pour l'envoi d'une image pour analyse dans l'API Vision : l'envoi, à l'API, d'une chaîne d'image codée en base64 ou la transmission, toujours à l'API, de l'URL d'un fichier stocké dans Google Cloud Storage. Nous utiliserons une URL Cloud Storage. Nous allons créer un bucket Google Cloud Storage pour stocker nos images.
Dans la console cloud, accédez au navigateur de stockage de votre projet :
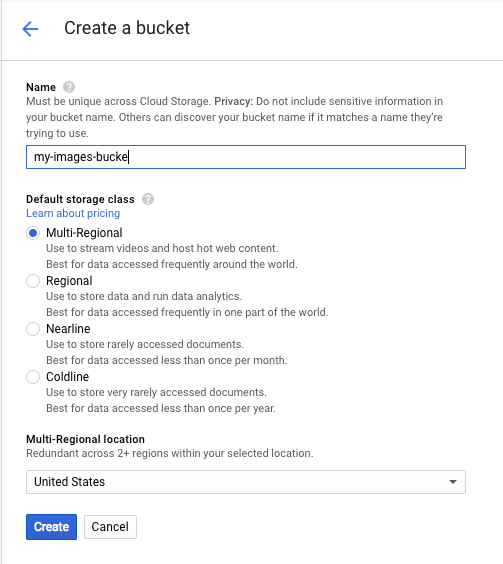
Cliquez ensuite sur Créer un bucket. Attribuez un nom unique à votre bucket (par exemple, l'ID de votre projet), puis cliquez sur Créer.
Importer une image dans votre bucket
Effectuez un clic droit sur l'image suivante représentant des donuts, puis cliquez sur Enregistrer l'image sous pour l'enregistrer dans votre dossier "Téléchargements" sous le nom donuts.png.

Accédez au bucket que vous venez de créer dans le navigateur de stockage et cliquez sur Upload files (Importer des fichiers). Ensuite, sélectionnez donuts.png.
Le fichier devrait apparaître dans votre bucket :

Ensuite, modifiez l'autorisation de l'image.
Cliquez sur Ajouter un élément.
Ajoutez une entité Group et un nom allUsers :
Cliquez sur Enregistrer.
Maintenant que le fichier est dans votre bucket, vous êtes prêt à créer une requête API Vision, afin de transmettre à cette dernière l'URL de cette image de donuts.
Dans votre environnement Cloud Shell, créez un fichier request.json avec le code ci-dessous, en veillant à remplacer my-bucket-name par le nom du bucket Cloud Storage que vous avez créé. Pour ce faire, vous pouvez utiliser l'éditeur de ligne de commande de votre choix (nano, vim ou emacs) ou l'éditeur Orion intégré à Cloud Shell :
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}La première fonctionnalité de l'API Cloud Vision que nous allons étudier est la détection de thèmes. Cette méthode renverra une liste de thèmes (mots) décrivant le contenu de votre image.
Nous sommes maintenant prêts à appeler l'API Vision avec curl :
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}La réponse doit en principe ressembler à ceci :
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}L'API a réussi à identifier le type de beignet représenté, à savoir des beignets. Cool ! Pour chaque libellé identifié, l'API Vision renvoie un description avec le nom de l'élément. Elle renvoie également un score, un nombre compris entre 0 et 100 représentant l'indice de confiance de la correspondance entre la description et ce qui est représenté sur l'image. La valeur mid correspond au MID de l'élément dans le Knowledge Graph de Google. Vous pouvez utiliser mid lorsque vous appelez l'API Knowledge Graph pour obtenir davantage d'informations sur l'élément.
En plus des thèmes représentés dans notre image, l'API Vision peut rechercher des informations supplémentaires sur Internet à propos de celle-ci. Ainsi, la méthode webDetection de l'API vous permet de récupérer de nombreuses informations intéressantes :
- Liste des entités représentées dans notre image, identifiées à partir du contenu de pages montrant des images semblables
- URL d'images trouvées sur le Web qui correspondent exactement ou partiellement à la vôtre, accompagnées des URL de ces pages
- URL d'images semblables, comme pour une recherche effectuée à l'aide d'une image
Pour essayer la détection sur le Web, nous allons utiliser la même image de beignets que précédemment. Il nous suffit donc de modifier une ligne de notre fichier request.json (vous pouvez également vous aventurer dans l'inconnu en utilisant une image totalement différente). Dans la liste des caractéristiques, remplacez simplement le type LABEL_DETECTION par WEB_DETECTION. request.json devrait désormais se présenter comme suit :
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}Pour l'envoyer à l'API Vision, vous pouvez utiliser la même commande curl que précédemment (appuyez sur la flèche vers le haut dans Cloud Shell) :
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Examinons à présent la réponse qui commence par webEntities. Voici quelques-unes des entités renvoyées par cette image :
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
Cette image a été réutilisée dans de nombreuses présentations sur nos API Cloud ML. C'est la raison pour laquelle l'API a trouvé les entités "Machine learning", "Google Cloud Platform" et "Cloud computing".
Si nous examinons les URL sous fullMatchingImages, partialMatchingImages et pagesWithMatchingImages, nous notons que nombre d'entre elles pointent vers le site de cet atelier (CQFD !).
Supposons que vous souhaitiez trouver d'autres images de beignets, mais pas exactement les mêmes. C'est là que la partie visuallySimilarImages de la réponse de l'API s'avère pratique. Voici quelques-unes des images visuellement semblables à la vôtre qu'elle a trouvées :
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]Vous pouvez accéder à ces URL pour afficher les images semblables à la vôtre :




C'est parfait ! À présent, vous avez probablement très envie d'un beignet (désolé). Cette méthode revient à effectuer une recherche à l'aide d'une image sur Google Images :
Avec Cloud Vision, nous pouvons accéder à cette fonctionnalité via une API REST simple à utiliser et l'intégrer dans nos applications.
Nous allons maintenant découvrir les méthodes de détection des visages et des points de repère de l'API Vision. Cette méthode renvoie des données sur les visages détectés dans une image, y compris les émotions et où ils se trouvent sur l'image. La détection des points de repère peut identifier des points de repère connus (ou plus obscurs). Elle renvoie le nom du point de repère, sa latitude et sa longitude, ainsi que son emplacement dans une image.
Importer une nouvelle image
Pour utiliser ces deux nouvelles méthodes, importons une nouvelle image comprenant des visages et des points de repère dans notre bucket Cloud Storage. Effectuez un clic droit sur l'image suivante, cliquez sur Enregistrer l'image sous, puis enregistrez-la dans votre dossier "Téléchargements" sous le nom selfie.png.

Importez ensuite cette image dans votre bucket Cloud Storage comme expliqué à l'étape précédente, en veillant à cocher la case "Partager publiquement".
Mise à jour de notre demande
Ensuite, nous allons mettre à jour notre fichier request.json pour inclure l'URL de la nouvelle image et utiliser la détection de visages et de points de repère, au lieu de la détection de thèmes. Veillez à remplacer my-bucket-name par le nom de votre bucket Cloud Storage :
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}Appeler l'API Vision et analyser la réponse
Vous pouvez maintenant appeler l'API Vision avec la même commande curl que précédemment :
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Commençons par examiner l'objet faceAnnotations dans notre réponse. Vous remarquerez que l'API renvoie un objet pour chaque visage trouvé dans l'image, trois dans le cas présent. Voici une version abrégée de notre réponse :
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly nous donne les coordonnées x,y autour du visage situé dans l'image. fdBoundingPoly est une zone plus petite que boundingPoly, qui représente la partie du visage couverte de peau. landmarks est un tableau d'objets représentant différentes caractéristiques du visage (dont certaines que vous ne connaissiez même pas). Cela nous indique le type de point de repère et la position en trois dimensions de cette caractéristique (coordonnées x, y et z), z correspondant à la profondeur. Les autres valeurs donnent d'autres indications sur le visage, comme la probabilité de joie, de tristesse, de colère et de surprise. L'objet ci-dessus correspond à la personne située au troisième plan de l'image, qui fait une sorte de grimace, ce qui explique la valeur joyLikelihood de POSSIBLE.
Examinons maintenant la partie landmarkAnnotations de notre réponse :
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]Ici, l'API Vision a réussi à déterminer que cette photo a été prise à Pétra. C'est assez impressionnant vu le peu d'indices visuels présents sur cette image. Les valeurs fournies dans cette réponse devraient être semblables à celles de la réponse labelAnnotations ci-dessus.
Nous obtenons le mid du point de repère, son nom (description) et un niveau de confiance (score). boundingPoly désigne la zone de l'image dans laquelle le point de repère a été identifié. La clé locations donne les coordonnées (latitude et longitude) de ce point de repère.
Vous connaissez maintenant les méthodes de détection des thèmes, des visages et des points de repère de l'API Vision, mais il en reste trois autres à découvrir. Reportez-vous à la documentation pour en savoir plus sur ces trois autres méthodes :
- Détection des logos : identifiez les logos courants et déterminez leur emplacement dans une image.
- Détection pour les recherches sécurisées : déterminez si une image présente un contenu explicite. Cette méthode est utile dans les applications autorisant les utilisateurs à générer du contenu. Vous pouvez filtrer les images selon quatre critères : contenus destinés aux adultes, médicaux, violents et parodiques.
- Détection de texte : extrayez du texte à partir d'images par reconnaissance optique des caractères. Cette méthode permet même d'identifier la langue du texte présent dans une image.
Vous avez appris à analyser des images avec l'API Vision. Dans cet exemple, vous avez transmis l'URL Google Cloud Storage de votre image à l'API. Cependant, vous pouvez également lui transmettre votre image sous la forme d'une chaîne encodée en base64.
Points abordés
- Appel à l'API Vision avec curl pour lui transmettre l'URL d'une image stockée dans un bucket Cloud Storage
- Utilisation des méthodes de détection des libellés, du Web, des visages et des points de repère de l'API Vision
Étapes suivantes
- Consultez les tutoriels de l'API Vision dans la documentation.
- Trouvez un exemple de l'API Vision dans votre langage favori.
- Essayez les ateliers de programmation Speech API et Natural Language API.