
L'API Cloud Natural Language vous permet d'extraire des entités à partir de texte, d'effectuer des analyses des sentiments et de la syntaxe, ainsi que de classer du texte selon des catégories.
Dans cet atelier, vous allez découvrir comment utiliser l'API Natural Language pour analyser les entités, les sentiments et la syntaxe d'un texte.
Points abordés
- Créer une requête pour l'API Natural Language et appeler l'API avec curl
- Extraire les entités et exécuter l'analyse des sentiments sur une chaîne de texte avec l'API Natural Language
- Effectuer l'analyse linguistique d'un texte avec l'API Natural Language
- Créer une requête pour l'API Natural Language dans une autre langue
Ce dont vous avez besoin
Comment allez-vous utiliser ce tutoriel ?
Quel est votre niveau d'expérience avec Google Cloud Platform ?
Configuration de l'environnement au rythme de chacun
Si vous ne possédez pas encore de compte Google (Gmail ou Google Apps), vous devez en créer un. Connectez-vous à la console Google Cloud Platform (console.cloud.google.com) et créez un projet :



Mémorisez l'ID du projet. Il s'agit d'un nom unique permettant de différencier chaque projet Google Cloud (le nom ci-dessus est déjà pris ; vous devez en trouver un autre). Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
Vous devez ensuite activer la facturation dans la console Cloud pour pouvoir utiliser les ressources Google Cloud.
Suivre cet atelier de programmation ne devrait pas vous coûter plus d'un euro. Cependant, cela peut s'avérer plus coûteux si vous décidez d'utiliser davantage de ressources ou si vous n'interrompez pas les ressources (voir la section "Effectuer un nettoyage" à la fin du présent document).
Les nouveaux utilisateurs de Google Cloud Platform peuvent bénéficier d'un essai sans frais avec 300$de crédits.
Cliquez sur l'icône de menu en haut à gauche de l'écran.

Sélectionnez API et services dans le menu déroulant, puis cliquez sur "Tableau de bord".
Cliquez sur Activer les API et les services.
Ensuite, recherchez "language" dans le champ de recherche. Cliquez sur Google Cloud Natural Language API :
Cliquez sur Enable (Activer) pour mettre en route l'API Cloud Natural Language :
Patientez quelques secondes jusqu'à ce qu'il soit activé. Une fois la fonctionnalité activée, vous verrez ceci :

Google Cloud Shell est un environnement de ligne de commande exécuté dans le cloud. Cette machine virtuelle basée sur Debian contient tous les outils de développement dont vous aurez besoin (gcloud, bq, git, etc.) et offre un répertoire de base persistant de 5 Go. Nous allons utiliser Cloud Shell pour créer notre requête à l'API Natural Language.
Pour commencer à utiliser Cloud Shell, cliquez sur l'icône  "Activer Google Cloud Shell" en haut à droite de la barre d'en-tête.
"Activer Google Cloud Shell" en haut à droite de la barre d'en-tête.

Une session Cloud Shell s'ouvre dans un nouveau cadre en bas de la console et affiche une invite de ligne de commande. Attendez que l'invite user@project:~$ s'affiche.
Étant donné que nous utiliserons curl pour envoyer une requête à l'API Natural Language, nous devons générer une clé API pour transmettre l'URL de notre requête. Pour créer une clé API, accédez à la section "Identifiants" d'API et services dans votre console Cloud :
Dans le menu déroulant, sélectionnez Clé API :
Ensuite, copiez la clé que vous venez de générer. Vous aurez besoin de cette clé plus tard dans l'atelier.
Vous disposez désormais d'une clé API. Enregistrez sa valeur dans une variable d'environnement afin d'éviter de l'insérer à chaque requête. Vous pouvez effectuer cette opération dans Cloud Shell. Veillez à remplacer <your_api_key> par la clé que vous venez de copier.
export API_KEY=<YOUR_API_KEY>analyzeEntities sera la première méthode de l'API Natural Language que nous utiliserons. Grâce à cette méthode, l'API peut extraire des entités (telles que des personnes, des lieux et des événements) d'un texte. Pour tester l'analyse des entités de l'API, nous utiliserons la phrase suivante :
Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series.
Nous allons construire notre requête pour l'API Natural Language dans un fichier request.json. Dans votre environnement Cloud Shell, créez le fichier request.json à l'aide du code ci-dessous. Pour ce faire, vous pouvez utiliser l'éditeur de ligne de commande de votre choix (nano, vim ou emacs) ou l'éditeur Orion intégré à Cloud Shell :
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
}Dans la requête, nous indiquons à l'API Natural Language le texte que nous allons envoyer. Les valeurs de type acceptées sont PLAIN_TEXT et HTML. Vous indiquez dans "content" la chaîne de texte à envoyer à l'API Natural Language pour analyse. L'API Natural Language permet également l'envoi de fichiers stockés dans Cloud Storage pour le traitement de texte. Pour envoyer un fichier à partir de Cloud Storage, nous devons remplacer content par gcsContentUri et lui attribuer la valeur de l'URI de notre fichier texte dans Cloud Storage. encodingType indique à l'API le type d'encodage de texte à utiliser lors du traitement du texte. L'API l'utilisera pour calculer l'emplacement d'entités spécifiques dans le texte.
Vous pouvez maintenant transmettre à l'API Natural Language le corps de votre requête, ainsi que la variable d'environnement de la clé API que vous avez sauvegardée précédemment, en exécutant la commande curl suivante (dans une seule ligne de commande) :
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonLe début de la réponse doit se présenter comme suit :
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
}Pour chaque entité de la réponse, nous obtenons le type, l'URL Wikipédia associée (le cas échéant), le salience et l'index des endroits où elle apparaît dans le texte. (la saillance est un chiffre compris dans la plage [0,1] et se rapportant à la centralité de l'entité par rapport au texte dans son ensemble) L'API Natural Language est également en mesure de reconnaître une même entité évoquée sous différentes formes. Observez la liste mentions de la réponse : l'API est capable de dire que "Joanne Rowling", "Rowling", "novelist" et "Robert Galbriath" font tous référence à une même entité.
Outre l'extraction d'entités, l'API Natural Language permet d'effectuer une analyse des sentiments dans une chaîne de texte. La requête JSON suivante comportera les mêmes paramètres que la requête ci-dessus, mais cette fois, nous modifierons le texte pour y inclure des éléments liés à des sentiments "plus forts". Remplacez votre fichier request.json par ce qui suit. Vous pouvez aussi remplacer le contenu de content ci-dessous par votre propre texte :
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
}Nous allons ensuite envoyer la requête au point de terminaison analyzeSentiment de l'API :
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
La réponse doit se présenter comme suit :
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
}Comme vous pouvez le remarquer, nous obtenons deux types de valeurs de sentiment : les sentiments pour le document dans son ensemble, et les sentiments exprimés dans chaque phrase. La méthode d'analyse des sentiments renvoie deux valeurs : score et magnitude. score est un nombre compris entre -1,0 et 1,0 qui indique le degré de positivité ou de négativité de la phrase. magnitude est un nombre compris entre 0 et l'infini représentant l'intensité des sentiments exprimés dans la déclaration, sans tenir compte de son aspect positif ou négatif. Les longues chaînes de texte exprimant des sentiments intenses ont des valeurs de magnitude plus élevées. Le score de la première phrase est positif (0,7), tandis que celui de la deuxième est neutre (0,1).
En plus de fournir des informations sur les sentiments exprimés dans l'ensemble du document texte que nous envoyons à l'API NL, celle-ci est également capable d'isoler les sentiments par entité dans notre texte. Prenons cette phrase comme exemple :
I liked the sushi but the service was terrible.
Ici, il ne sera peut-être pas utile de calculer le score de l'analyse des sentiments de l'ensemble de la phrase, comme nous l'avons fait plus haut. Imaginez qu'il s'agisse d'une critique de restaurant parmi des centaines d'autres : vous allez plutôt chercher à extraire des informations précises concernant les points positifs et négatifs soulevés par les clients. Heureusement, l'API Natural Language dispose d'une méthode appelée analyzeEntitySentiment, qui permet d'obtenir un sentiment pour chaque entité de la chaîne de texte. Modifiez votre fichier request.json pour y insérer la phrase ci-dessus et l'essayer :
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
}Envoyez ensuite une requête au point de terminaison analyzeEntitySentiment avec la commande curl suivante :
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
La réponse comporte deux objets d'entité : un pour "sushis" et l'autre pour "service". Voici la réponse JSON complète :
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
Vous pouvez voir que le score attribué à "sushi" est de 0,9, tandis que "service" obtient -0,9. C'est parfait ! Vous remarquerez également que deux objets de sentiment ont été attribués à chaque entité. Si l'un de ces deux termes avait été mentionné à plus d'une reprise, l'API aurait renvoyé un score de sentiment et de magnitude distinct pour chaque occurrence, ainsi qu'un sentiment global pour l'entité.
La troisième méthode de l'API Natural Language, l'annotation syntaxique, nous permet d'obtenir des informations linguistiques plus détaillées sur le texte. analyzeSyntax est une méthode qui fournit des données complètes sur les éléments sémantiques et syntaxiques du texte. Pour chaque mot du texte, l'API nous indique la classe de mots (nom, verbe, adjectif, etc.) et son rôle dans la phrase (s'agit-il du verbe principal ? d'un modificateur ?).
Essayons avec une phrase simple. Notre requête JSON sera similaire aux requêtes déjà envoyées, avec une caractéristique clé supplémentaire. qui indiquera à l'API que nous souhaitons effectuer une annotation syntaxique. Remplacez votre fichier request.json par ce qui suit :
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}Appelez ensuite la méthode analyzeSyntax de l'API :
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonLa réponse devrait renvoyer un objet semblable à l'exemple ci-dessous pour chaque jeton dans la phrase. Examinons la réponse pour le mot "utilise" :
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}Analysons la réponse obtenue. partOfSpeech nous fournit des informations linguistiques sur chaque mot (beaucoup sont inconnues, car elles ne s'appliquent pas à l'anglais ni à ce mot en particulier). tag indique la catégorie grammaticale de ce mot, en l'occurrence un verbe. Nous obtenons également des informations sur le temps, la modalité et le nombre (singulier ou pluriel) du mot. lemma est la forme canonique du mot (pour "utilisations", il s'agit de "utilisation"). Par exemple, les mots courir, court, courut et courant ont tous un lemme identique : courir. La valeur du lemme est utile pour comptabiliser au fur et à mesure les occurrences d'un mot dans une longue chaîne de texte.
dependencyEdge comporte des données que vous pourrez utiliser pour créer l'arbre syntaxique de dépendance du texte. Il s'agit d'un diagramme montrant les relations entre les termes dans le texte. L'arbre syntaxique de dépendance de la phrase ci-dessus ressemblerait à ceci :
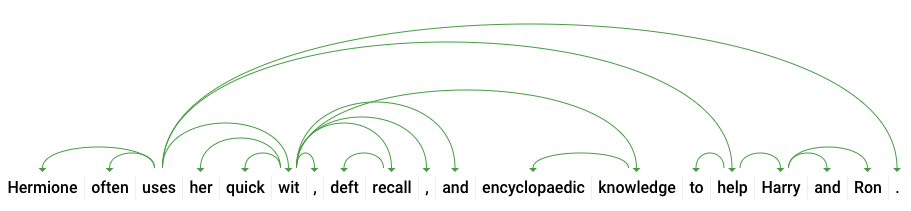
Le headTokenIndex dans notre réponse ci-dessus correspond à l'index du jeton dont l'arc pointe vers "utilise". On peut considérer chaque élément de la phrase comme un mot dans un tableau, et la valeur headTokenIndex de "uses" fait référence au mot "souvent", auquel il est associé dans l'arborescence.
L'API Natural Language accepte également d'autres langues que l'anglais (la liste complète est disponible ici). Essayons la requête d'entité suivante avec une phrase en japonais :
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}Vous remarquerez que vous n'avez pas à préciser à l'API la langue que vous utilisez, car elle la détecte automatiquement. Nous allons ensuite l'envoyer au point de terminaison analyzeEntities :
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonVoici les deux premières entités de notre réponse :
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}L'API extrait le Japon en tant que lieu et Google en tant qu'organisation, ainsi que les pages Wikipédia correspondantes.
Vous avez appris à effectuer une analyse de texte avec l'API Cloud Natural Language en extrayant des entités, en analysant des sentiments et en réalisant des annotations syntaxiques.
Points abordés
- Créer une requête pour l'API Natural Language et appeler cette dernière avec curl
- extrait les entités et exécuté l'analyse des sentiments sur une chaîne de texte avec l'API Natural Language ;
- effectué des analyses linguistiques sur des chaînes de texte pour créer des arbres syntaxiques de dépendance ;
- créé une requête pour l'API Natural Language en japonais.
Étapes suivantes
- Consulter les tutoriels de l'API Natural Language dans la documentation.
- Essayez l'API Vision et l'API Speech.