
Dataflow est un modèle de programmation unifié et un service géré permettant de développer et d'exécuter une large gamme de modèles de traitement des données (ETL, calcul par lots et calcul continu, par exemple). Puisque Dataflow est un service géré, il peut allouer les ressources à la demande pour réduire la latence tout en maintenant une haute productivité.
Le modèle Dataflow combine le traitement par lots et par flux afin que les développeurs n'aient pas à faire de compromis entre exactitude, coût et temps de traitement. Dans cet atelier de programmation, vous allez apprendre à exécuter un pipeline Dataflow qui compte le nombre d'occurrences de mots uniques dans un fichier texte.
Ce tutoriel est adapté de https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-maven.
Points abordés
- Créer un projet Maven à l'aide du SDK Cloud Dataflow
- Exécuter un exemple de pipeline dans la console Google Cloud Platform
- Supprimer le bucket Cloud Storage associé et son contenu
Prérequis
Comment allez-vous utiliser ce tutoriel ?
Quel est votre niveau d'expérience avec les services Google Cloud Platform ?
Configuration de l'environnement au rythme de chacun
Si vous ne possédez pas encore de compte Google (Gmail ou Google Apps), vous devez en créer un. Connectez-vous à la console Google Cloud Platform (console.cloud.google.com) et créez un projet :



Mémorisez l'ID du projet. Il s'agit d'un nom unique permettant de différencier chaque projet Google Cloud (le nom ci-dessus est déjà pris ; vous devez en trouver un autre). Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
Vous devez ensuite activer la facturation dans la console Cloud pour pouvoir utiliser les ressources Google Cloud.
Suivre cet atelier de programmation ne devrait pas vous coûter plus d'un euro. Cependant, cela peut s'avérer plus coûteux si vous décidez d'utiliser davantage de ressources ou si vous n'interrompez pas les ressources (voir la section "Effectuer un nettoyage" à la fin du présent document).
Les nouveaux utilisateurs de Google Cloud Platform peuvent bénéficier d'un essai sans frais avec 300$de crédits.
Activer les API
Cliquez sur l'icône de menu en haut à gauche de l'écran.

Sélectionnez API Manager dans le menu déroulant.

Saisissez "Google Compute Engine" dans le champ de recherche. Cliquez sur "API Google Compute Engine" dans la liste des résultats qui s'affiche.
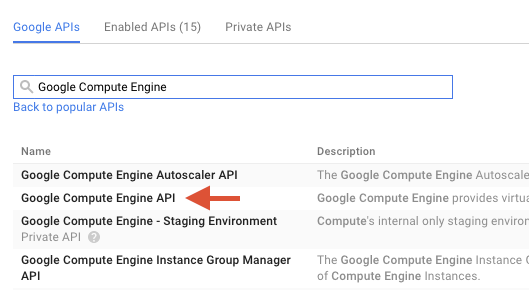
Sur la page Google Compute Engine, cliquez sur Activer.
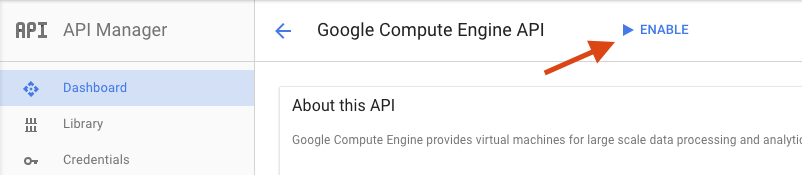
Une fois l'API activée, cliquez sur la flèche pour revenir à la page précédente.
Recherchez maintenant les API ci-dessous et activez-les :
- API Google Dataflow
- API Stackdriver Logging
- Google Cloud Storage
- API JSON Google Cloud Storage
- API BigQuery
- API Google Cloud Pub/Sub
- API Google Cloud Datastore
Dans la console Google Cloud Platform, cliquez sur l'icône Menu en haut à gauche de l'écran :
Faites défiler la page vers le bas et sélectionnez Cloud Storage dans la sous-section Stockage :
Vous devriez à présent voir le navigateur Cloud Storage. Si vous utilisez un projet qui ne comporte actuellement aucun bucket Cloud Storage, une boîte de dialogue vous invite à en créer un :
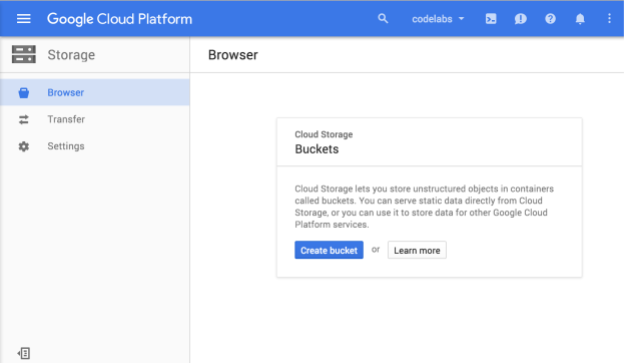
Appuyez sur le bouton Créer un bucket pour en créer un :
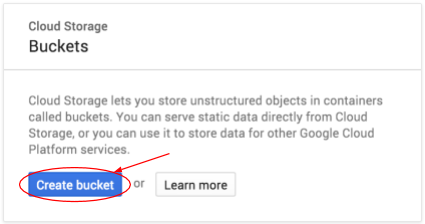
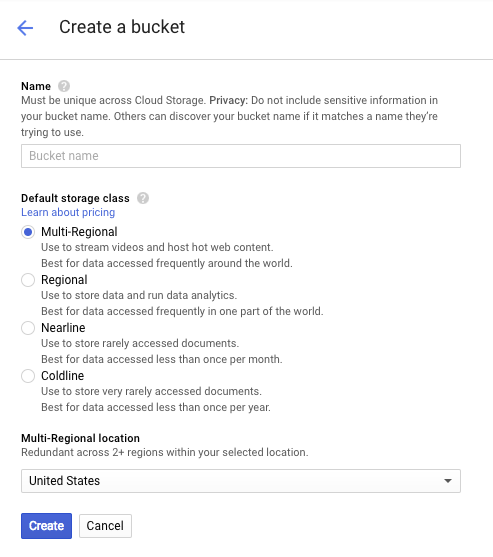
Saisissez un nom pour ce bucket. Comme indiqué dans la boîte de dialogue, les noms de bucket doivent être uniques dans l'ensemble de Cloud Storage. Par conséquent, si vous choisissez un nom évident, tel que "test", vous constaterez probablement qu'un autre utilisateur a déjà créé un bucket portant ce nom et vous recevrez un message d'erreur.
Il existe également des règles concernant les caractères autorisés dans les noms de buckets. Si vous commencez et terminez le nom de votre bucket par une lettre ou un chiffre, et que vous n'utilisez que des tirets au milieu, tout ira bien. Si vous essayez d'utiliser des caractères spéciaux, ou de commencer ou de terminer le nom de votre bucket par autre chose qu'une lettre ou un chiffre, la boîte de dialogue vous rappellera les règles.
Saisissez un nom unique pour votre bucket, puis cliquez sur Créer. Si vous choisissez un nom déjà utilisé, le message d'erreur ci-dessus s'affiche. Une fois le bucket créé, vous serez redirigé vers ce nouveau bucket vide dans le navigateur :
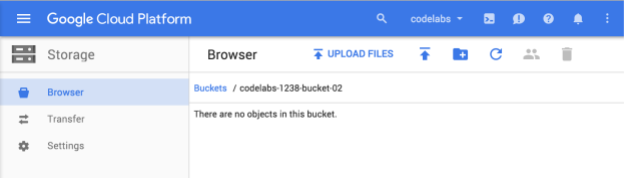
Le nom du bucket que vous voyez sera bien sûr différent, car il doit être unique dans tous les projets.
Activer Google Cloud Shell
Depuis la console GCP, cliquez sur l'icône Cloud Shell de la barre d'outils située dans l'angle supérieur droit :

Cliquez ensuite sur "Démarrer Cloud Shell" :

Le provisionnement de l'environnement et la connexion ne devraient pas prendre plus de quelques minutes :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle intègre un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez réaliser une grande partie, voire la totalité, des activités de cet atelier dans un simple navigateur ou sur votre Chromebook Google.
Une fois connecté à Cloud Shell, vous êtes en principe authentifié, et le projet est déjà défini avec votre PROJECT_ID.
Exécutez la commande suivante dans Cloud Shell pour vérifier que vous êtes authentifié :
gcloud auth list
Résultat de la commande
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Résultat de la commande
[core] project = <PROJECT_ID>
Si vous obtenez un résultat différent, exécutez cette commande :
gcloud config set project <PROJECT_ID>
Résultat de la commande
Updated property [core/project].
Une fois Cloud Shell lancé, commençons par créer un projet Maven contenant le SDK Cloud Dataflow pour Java.
Exécutez la commande mvn archetype:generate dans votre interface système, comme indiqué ci-dessous :
mvn archetype:generate \
-DarchetypeArtifactId=google-cloud-dataflow-java-archetypes-examples \
-DarchetypeGroupId=com.google.cloud.dataflow \
-DarchetypeVersion=1.9.0 \
-DgroupId=com.example \
-DartifactId=first-dataflow \
-Dversion="0.1" \
-DinteractiveMode=false \
-Dpackage=com.exampleAprès avoir exécuté la commande, vous devriez constater que votre répertoire actuel comporte un nouveau répertoire nommé first-dataflow. first-dataflow contient un projet Maven incluant le SDK Cloud Dataflow pour Java, ainsi que des exemples de pipelines.
Commençons par enregistrer l'ID de notre projet et les noms de nos buckets Cloud Storage en tant que variables d'environnement. Vous pouvez effectuer cette opération dans Cloud Shell. Veillez à remplacer <your_project_id> par l'ID de votre projet.
export PROJECT_ID=<your_project_id>Nous allons maintenant faire de même pour le bucket Cloud Storage. N'oubliez pas de remplacer <your_bucket_name> par le nom unique que vous avez utilisé pour créer votre bucket lors d'une étape précédente.
export BUCKET_NAME=<your_bucket_name>Accédez au répertoire first-dataflow/.
cd first-dataflowNous allons exécuter un pipeline intitulé WordCount, qui lit du texte, segmente les lignes en mots individuels et compte le nombre de fois où chacun de ces mots apparaît. Nous allons d'abord exécuter le pipeline, puis examiner chaque étape de l'exécution.
Démarrez le pipeline en exécutant la commande mvn compile exec:java dans la fenêtre de votre interface système ou de votre terminal. Pour les arguments --project, --stagingLocation, et --output, la commande ci-dessous fait référence aux variables d'environnement que vous avez configurées précédemment dans cette étape.
mvn compile exec:java \
-Dexec.mainClass=com.example.WordCount \
-Dexec.args="--project=${PROJECT_ID} \
--stagingLocation=gs://${BUCKET_NAME}/staging/ \
--output=gs://${BUCKET_NAME}/output \
--runner=BlockingDataflowPipelineRunner"Pendant que le job s'exécute, vérifiez qu'il apparaît dans la liste des jobs.
Ouvrez l'interface utilisateur de surveillance Cloud Dataflow dans la console Google Cloud Platform. La tâche "wordcount" s'affiche et son état indique Running (En cours d'exécution) :

Examinons maintenant les paramètres du pipeline. Commencez par cliquer sur le nom de votre tâche :
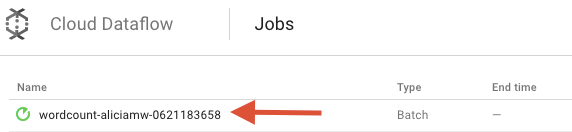
Lorsque vous sélectionnez un job, vous pouvez afficher le graphique d'exécution. Sur le graphique d'exécution d'un pipeline, chaque transformation est représentée sous la forme d'une case qui indique son nom et certaines informations sur son état. Vous pouvez cliquer sur la flèche en haut à droite de chaque étape pour afficher plus de détails :
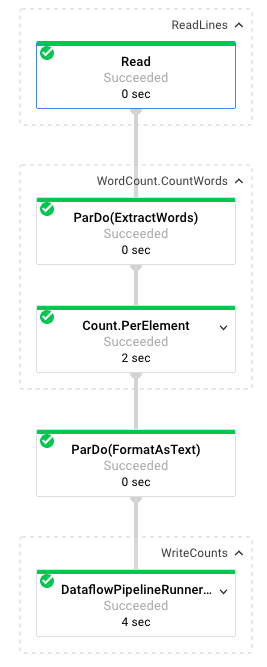
Nous allons à présent détailler les transformations apportées aux données par le pipeline à chaque étape :
- Lecture : lors de cette étape, le pipeline lit les données à partir d'une source d'entrée. Dans ce cas, il s'agit d'un fichier texte provenant de Cloud Storage et contenant l'intégralité de la pièce de Shakespeare Le Roi Lear. Notre pipeline lit le fichier ligne par ligne et génère une
PCollectionpour chacune d'elles. Chaque ligne de notre fichier texte est un élément de la collection. - CountWords : l'étape
CountWordss'effectue en deux parties. Tout d'abord, il utilise une fonction Do parallèle (ParDo) nomméeExtractWordspour segmenter chaque ligne en mots individuels. La sortie d'ExtractWords est une nouvelle PCollection où chaque élément est un mot. L'étape suivante,Count, utilise une transformation fournie par le SDK Dataflow qui renvoie des paires clé/valeur, où la clé est un mot unique et la valeur est le nombre de fois où il apparaît. Voici la méthode d'implémentation deCountWords. Vous pouvez consulter l'intégralité du fichier WordCount.java sur GitHub :
/**
* A PTransform that converts a PCollection containing lines of text
* into a PCollection of formatted word counts.
*/
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> apply(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}- FormatAsText : cette fonction permet de mettre en forme chaque paire clé/valeur dans une chaîne imprimable. Voici la transformation
FormatAsTextà implémenter :
/** A SimpleFunction that converts a Word and Count into a printable string. */
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}- WriteCounts : dans cette étape, nous écrivons les chaînes imprimables dans plusieurs fichiers texte fragmentés.
Nous allons examiner les résultats du pipeline dans quelques minutes.
Consultez maintenant la page Summary (Résumé) à droite du graphique, qui présente les paramètres de pipeline inclus dans la commande mvn compile exec:java.
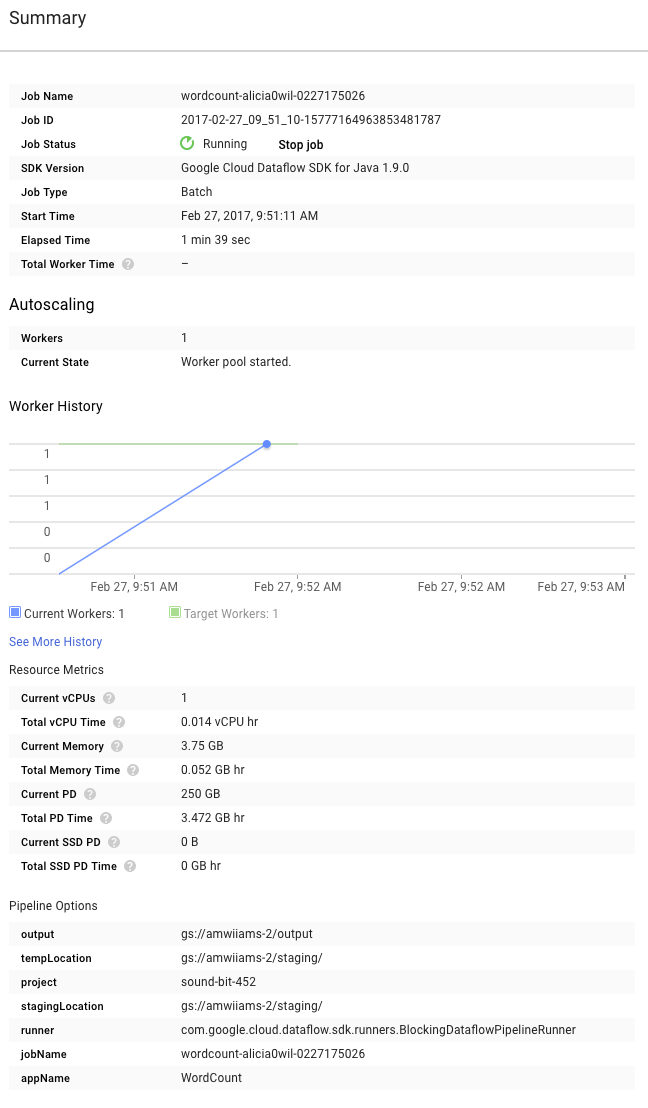
Les compteurs personnalisés pour le pipeline s'affichent également dans cette section. Dans notre exemple, ils indiquent le nombre de lignes vides détectées jusqu'à présent pendant l'exécution. Vous pouvez ajouter des compteurs à votre pipeline pour suivre des métriques spécifiques à l'application.
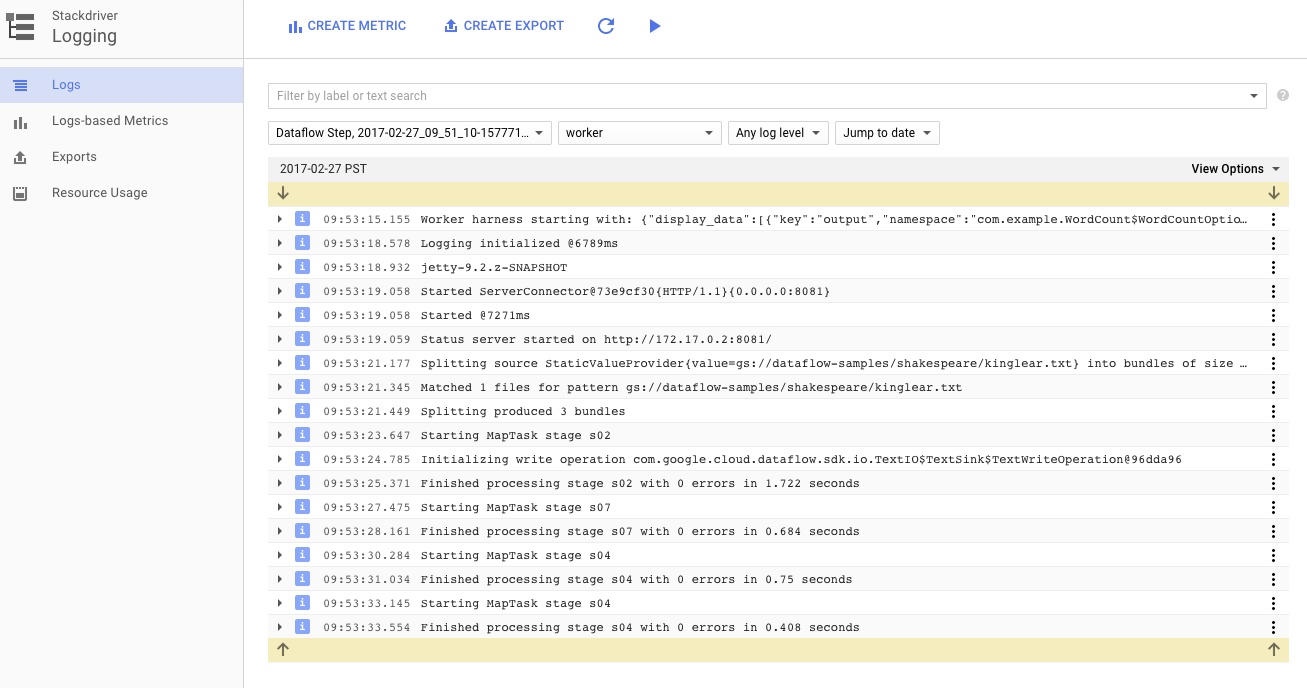
Vous pouvez cliquer sur l'icône Journaux pour afficher les messages d'erreur spécifiques.

Filtrez les messages qui apparaissent dans l'onglet "Job Log" (Journaux des tâches) à l'aide du menu déroulant "Minimum Severity" (Niveau de gravité minimal).

Vous pouvez utiliser le bouton Journaux des nœuds de calcul dans l'onglet "Journaux" pour afficher les journaux des nœuds de calcul des instances Compute Engine qui exécutent votre pipeline. Les journaux des tâches comportent des lignes de journal générées par votre code et le code Dataflow généré qui l'exécute.
Si vous essayez de déboguer un échec dans le pipeline, vous trouverez souvent des journaux supplémentaires dans les journaux du nœud de calcul qui vous aideront à résoudre le problème. N'oubliez pas que ces journaux sont agrégés pour tous les nœuds de calcul. Vous pouvez les filtrer et les rechercher.
À l'étape suivante, nous vérifierons que votre job a bien été exécuté.
Ouvrez l'interface utilisateur de surveillance Cloud Dataflow dans la console Google Cloud Platform.
Votre tâche "wordcount" présente au début l'état Running (En cours d'exécution), puis l'état Succeeded (Réussie) :

L'exécution de la tâche prend entre trois et quatre minutes.
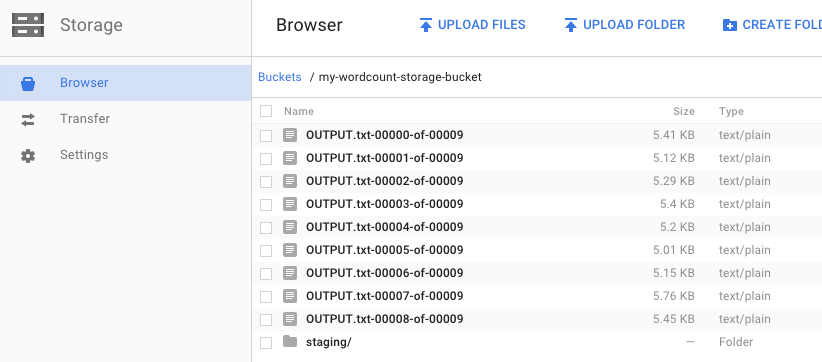
Vous vous souvenez de l'étape où vous avez exécuté le pipeline et spécifié un bucket de sortie ? Examinons le résultat, car nous voulons évidemment savoir combien de fois apparaît chaque mot de la pièce Le Roi Lear. Revenez au navigateur Cloud Storage dans la console Google Cloud Platform. Dans votre bucket, vous devriez voir les fichiers de sortie et les fichiers intermédiaires créés par votre tâche :
Vous pouvez arrêter vos ressources depuis la console Google Cloud Platform.
Ouvrez le navigateur Cloud Storage dans la console Google Cloud Platform.
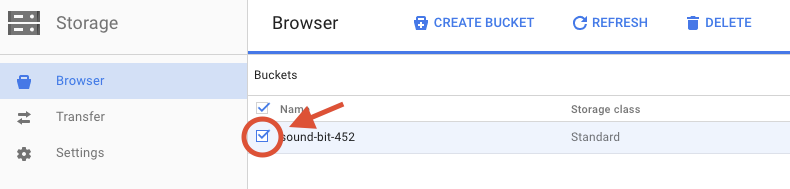
Cochez la case à côté du bucket que vous avez créé.
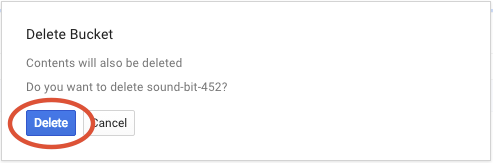
Cliquez sur SUPPRIMER pour supprimer définitivement le bucket et son contenu.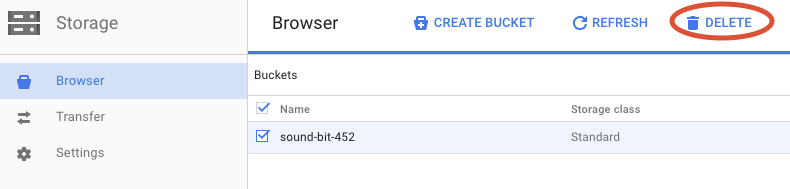
Vous avez appris à créer un projet Maven à l'aide du SDK Cloud Dataflow, à exécuter un exemple de pipeline dans la console Google Cloud Platform, ainsi qu'à supprimer le bucket Cloud Storage associé et son contenu.
En savoir plus
- Documentation Dataflow : https://cloud.google.com/dataflow/docs/
Licence
Ce contenu est concédé sous licence Creative Commons Attribution 3.0 Generic et Apache 2.0.