
이 Codelab에서는 다음을 비롯한 BigQuery의 일부 고급 기능을 사용하는 방법을 알아봅니다.
- 자바스크립트의 사용자 정의 함수
- 파티션을 나눈 테이블
- Google Cloud Storage 및 Google Drive의 데이터를 대상으로 쿼리를 직접 실행합니다.
미국 연방 선거 관리 위원회의 데이터를 가져와서 정리한 다음 BigQuery에 로드합니다. 또한 데이터 세트에 관해 흥미로운 질문을 할 수도 있습니다.
이 Codelab에서는 BigQuery를 사용해 본 경험이 없다고 가정하지만 SQL에 대한 이해를 바탕으로 BigQuery를 더 잘 활용할 수 있습니다.
학습할 내용
- 자바스크립트 사용자 정의 함수를 사용하여 SQL에서 실행하기 어려운 작업을 수행하는 방법
- BigQuery를 사용하여 Google Cloud Storage 및 Google 드라이브와 같은 다른 데이터 저장소에 있는 데이터에서 ETL (추출, 변환, 로드) 작업을 수행하는 방법
필요한 항목
- 결제가 사용 설정된 Google Cloud 프로젝트.
- Google Cloud Storage 버킷
- Google Cloud SDK 설치됨
본 가이드를 어떻게 사용하실 계획인가요?
BigQuery 사용 경험 수준을 평가해 주세요.
자습형 환경 설정
Google 계정 (Gmail 또는 Google 앱)이 아직 없다면 계정을 만들어야 합니다. Google Cloud Platform Console (console.cloud.google.com)에 로그인하여 새 프로젝트를 만듭니다.



모든 Google Cloud 프로젝트에서 고유한 이름인 프로젝트 ID를 기억하세요(위의 이름은 이미 사용되었으므로 사용할 수 없습니다). 이 ID는 나중에 이 Codelab에서 PROJECT_ID라고 부릅니다.
다음으로 Google Cloud 리소스를 사용하려면 Cloud Console에서 결제를 사용 설정해야 합니다.
이 codelab을 실행하는 과정에는 많은 비용이 들지 않지만 더 많은 리소스를 사용하려고 하거나 실행 중일 경우 비용이 더 들 수 있습니다(이 문서 마지막의 '삭제' 섹션 참조).
Google Cloud Platform의 신규 사용자는 $300 무료 체험판을 사용할 수 있습니다.
Google Cloud Shell
노트북에서 원격으로 Google Cloud와 BigQuery를 작동할 수 있지만, 이 Codelab에서는 Cloud에서 실행되는 명령줄 환경인 Google Cloud Shell을 사용할 것입니다.
이 Debian 기반 가상 머신에는 필요한 모든 개발 도구가 로드되어 있습니다. 영구적인 5GB 홈 디렉토리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 즉, 이 Codelab에 필요한 것은 브라우저뿐입니다(Chromebook에서도 작동 가능).
Google Cloud Shell을 활성화하려면 개발자 콘솔에서 오른쪽 상단의 버튼을 클릭하면 됩니다. 환경을 프로비저닝하고 연결하는 데는 몇 분 정도만 소요됩니다.

'Cloud Shell 시작' 버튼을 클릭합니다.


Cloud Shell에 연결되면 인증이 이미 완료되어 있고 프로젝트가 이미 PROJECT_ID으로 설정되어 있음을 확인할 수 있습니다.
gcloud auth list
명령어 결과
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
명령어 결과
[core] project = <PROJECT_ID>
Cloud Shell은 또한 향후 명령어를 실행할 때 유용할 수 있는 일부 환경 변수도 기본적으로 설정합니다.
echo $GOOGLE_CLOUD_PROJECT
명령어 결과
<PROJECT_ID>
어떤 이유로 프로젝트가 설정되지 않은 경우 다음 명령어를 실행하면 됩니다.
gcloud config set project <PROJECT_ID>
PROJECT_ID를 찾고 계신가요? 설정 단계에서 사용한 ID를 확인하거나 콘솔 대시보드에서 찾아보세요.

중요: 마지막으로 기본 영역 및 프로젝트 구성을 설정합니다.
gcloud config set compute/zone us-central1-f
다양한 영역을 선택할 수 있습니다. 리전 및 영역 영역 문서에서 자세히 알아보세요.
이 Codelab에서 BigQuery 쿼리를 실행하려면 자체 데이터 세트가 필요합니다. 이름(예: campaign_funding)을 선택합니다. 셸에서 다음 명령어를 실행합니다 (예: CloudShell).
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
데이터 세트가 생성되면 이제 준비가 완료되었습니다. 이 명령어를 실행하면 bq 명령줄 클라이언트 설정이 올바르고, 인증이 작동하는지, 작동 중인 클라우드 프로젝트에 대한 쓰기 액세스 권한이 있는지 확인할 수 있습니다. 프로젝트가 두 개 이상인 경우 목록에서 관심 있는 프로젝트를 선택하라는 메시지가 표시됩니다.

미국 연방 선거위원회 캠페인 데이터 세트가 압축 해제되어 GCS 버킷 gs://campaign-funding/에 복사되었습니다.
소스 파일 중 하나를 로컬에서 다운로드하여 어떤 모습인지 확인할 수 있도록 합니다. 명령 창에서 다음 명령어를 실행합니다.
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
이렇게 하면 개별 참여 파일의 콘텐츠가 표시됩니다. 이 Codelab에는 개별 참여(indiv*.txt), 후보(cn*.txt), 위원회(cm*.txt)와 같은 세 가지 유형의 파일이 있습니다. 관심이 있는 경우 동일한 메커니즘을 사용하여 다른 파일의 내용을 확인하세요.
원시 데이터를 BigQuery에 직접 로드하는 것이 아니라, Google Cloud Storage에서 쿼리하게 됩니다. 그러려면 스키마와 스키마에 관한 정보를 알아야 합니다.
데이터 세트는 연방 선거 웹사이트(여기)에 설명되어 있습니다. 확인할 테이블의 스키마는 다음과 같습니다.
테이블에 연결하려면 스키마를 포함하는 테이블 정의를 만들어야 합니다. 다음 명령어를 실행하여 개별 테이블 정의를 생성합니다.
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
원하는 텍스트 편집기로 indiv_dev.json 파일을 열고 콘텐츠를 확인합니다. FEC 데이터 파일을 해석하는 방법을 설명하는 json이 포함되어 있습니다.
csvOptions 섹션을 약간 수정해야 합니다. fieldDelimiter의 값\'&&t>; 및 quote 값("")(빈 문자열)을 추가합니다. 이는 데이터 파일이 실제로 쉼표로 구분되어 있지 않고 파이프로 구분되어 있기 때문에 필요합니다.
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
이제 indiv_dev.json 파일이 다음과 같이 표시됩니다.
"fieldDelimiter": "|",
"quote":"",
위원회와 후보 테이블의 테이블 정의 생성도 비슷하고 스키마에 상용구가 약간 포함되어 있으므로 파일을 다운로드하기만 하면 됩니다.
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
이러한 파일은 indiv_dev.json 파일과 유사합니다. 또한 올바른 값을 가져오는 데 문제가 있는 경우 indiv_def.json 파일을 다운로드할 수도 있습니다.
다음으로 BigQuery 테이블을 이러한 파일에 연결하겠습니다. 다음 명령어를 실행합니다.
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
이렇게 하면 트랜잭션, 커밋, 후보 세 가지 BigQuery 테이블이 생성됩니다. 이 테이블은 일반 BigQuery 테이블처럼 쿼리할 수 있지만, 실제로는 BigQuery에 저장되지 않고 Google Cloud Storage에 저장됩니다. 기본 파일을 업데이트하면 실행하는 쿼리에 즉시 반영됩니다.
이제 쿼리를 몇 번 실행해 보겠습니다. BigQuery 웹 UI를 엽니다.
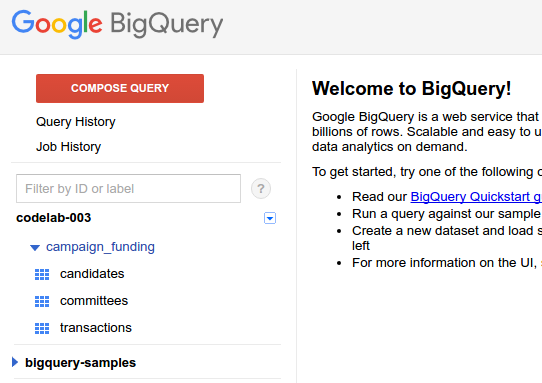
왼쪽 탐색창에서 데이터 세트를 찾아 (왼쪽 상단의 프로젝트 드롭다운을 변경해야 할 수도 있음) 큰 빨간색 큰 버튼 'COMPOSE QUERY'' 버튼을 클릭하고 상자에 다음 쿼리를 입력합니다.
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
그러면 Google 직원이 최근에 수행한 캠페인 기부금 100개가 표시됩니다. 원하는 경우 이곳저곳을 돌아다니며 우편번호 거주자의 캠페인 기부금을 확인하거나 거주 도시에서 가장 많은 기부금을 찾아보세요.
쿼리와 결과는 다음과 유사합니다.
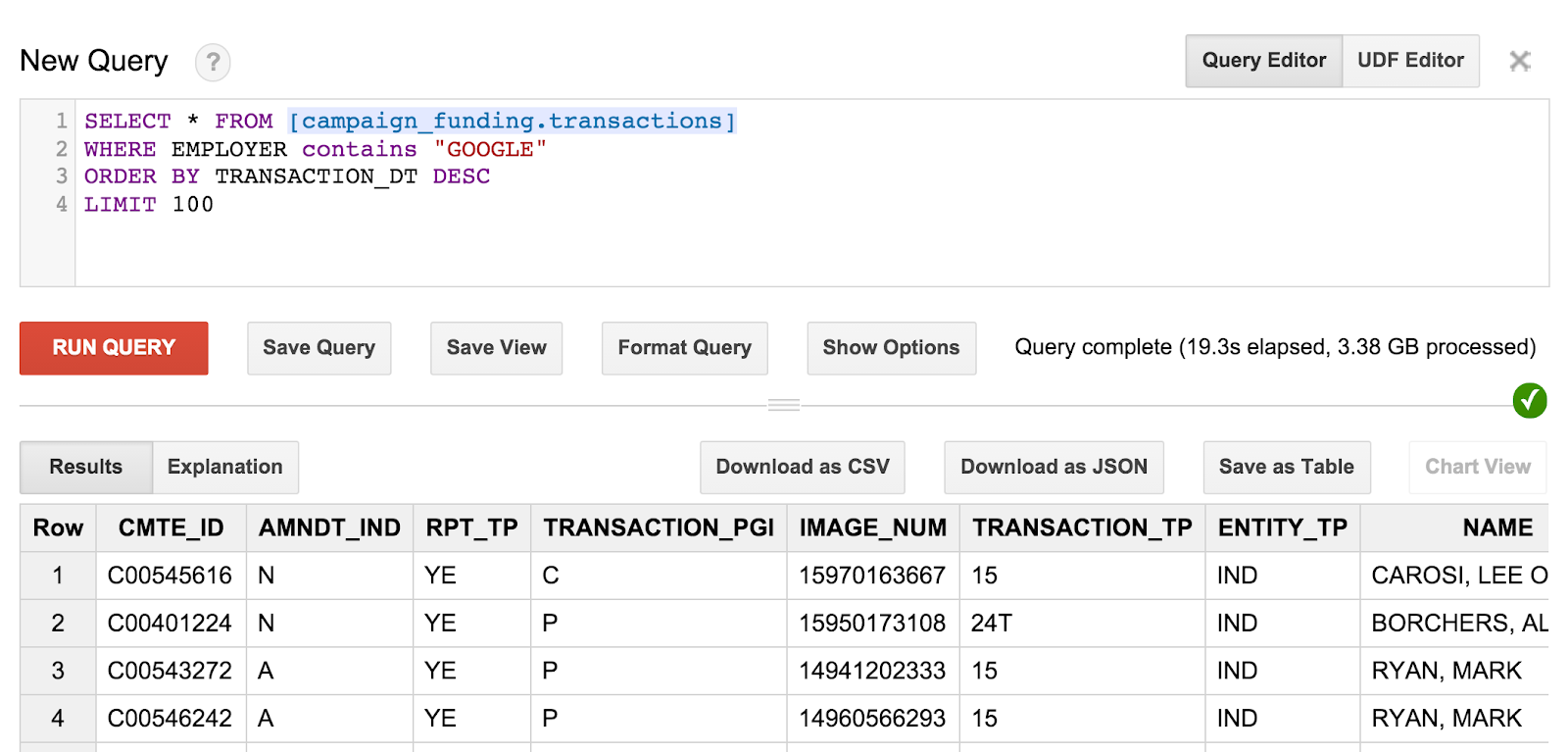
그러나 기증자가 누구로부터 받았는지는 정확히 알 수 없습니다. 이러한 정보를 얻으려면 더 흥미로운 쿼리를 만들어야 합니다.
왼쪽 창에서 트랜잭션 테이블을 클릭하고 스키마 탭을 클릭합니다. 아래의 스크린샷과 같습니다.
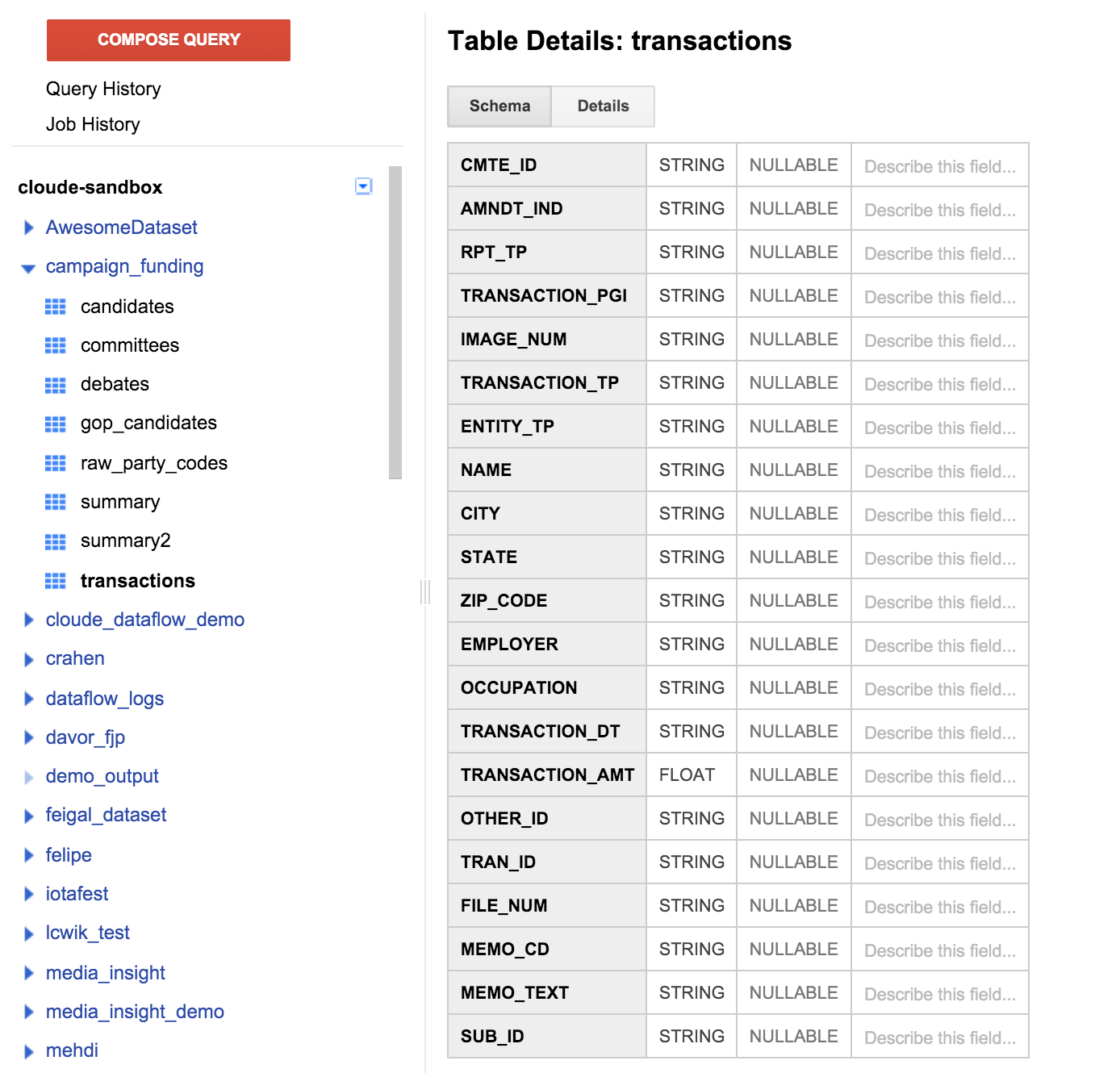
이전에 지정한 테이블 정의와 일치하는 필드 목록을 확인할 수 있습니다. 받는 사람 필드가 없거나, 기부가 지원되는 후보를 확인할 수 있는 방법이 없습니다. 그러나 CMTE_ID라는 필드가 있습니다. 그러면 기부금을 수령한 위원회가 기부금과 연결됩니다. 그다지 유용하지 않습니다.
그런 다음 커밋 테이블을 클릭하여 스키마를 확인합니다. 거래 표에 참여할 수 있는 CMET_ID을 확보했습니다. 다른 필드는 CAND_ID이며 후보 테이블의 CAND_ID 테이블과 조인할 수 있습니다. 마지막으로 위원회 표를 통해 트랜잭션과 후보를 연결합니다.
GCS 기반 테이블에는 미리보기 탭이 없습니다. BigQuery에서 데이터를 읽으려면 외부 데이터 소스에서 데이터를 읽어야 하기 때문입니다. 후보 테이블에서 간단한 SELECT *' 쿼리를 실행하여 데이터 샘플을 가져옵니다.
SELECT * FROM [campaign_funding.candidates] LIMIT 100
다음과 같은 결과가 표시됩니다.
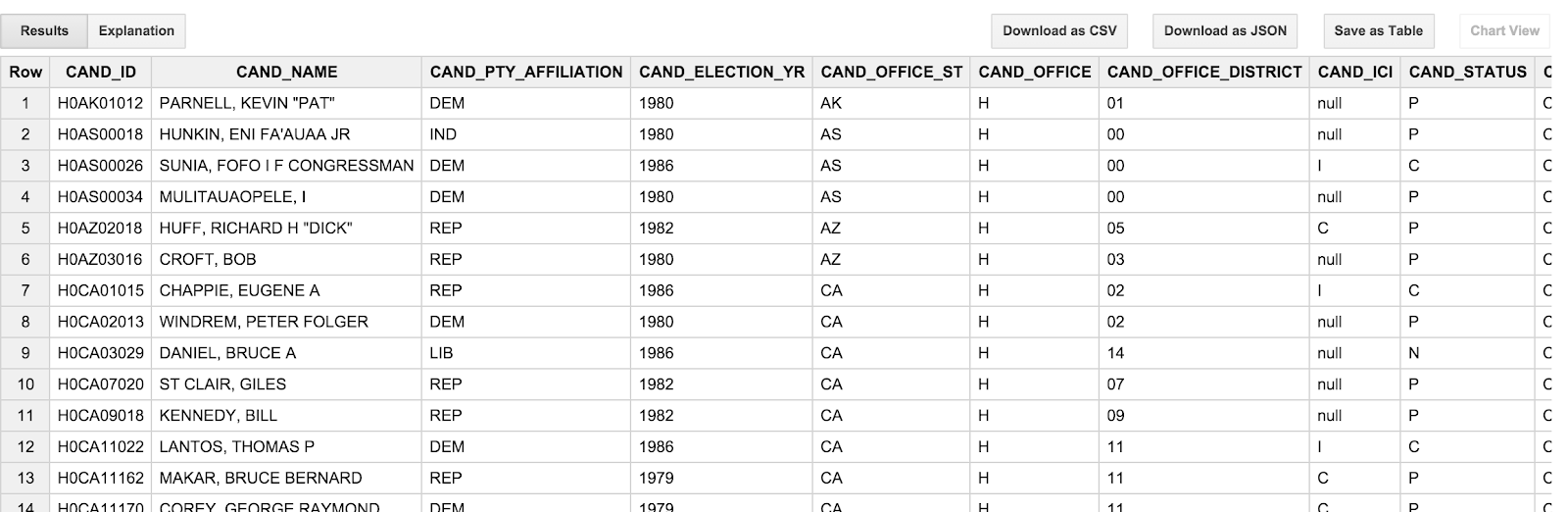
후보 이름이 모두 대문자로 되어 있고 "lastname, firstname" 순서로 표시됩니다. 후보작에 대한 우리의 생각과 다르기 때문에 약간 짜증이 납니다. 또한 트랜잭션 표의 트랜잭션 날짜 (TRANSACTION_DT)도 약간 불편합니다. YYYYMMDD 형식의 문자열 값입니다. 이러한 문제는 다음 섹션에서 해결하겠습니다.
지금까지 트랜잭션이 후보와 어떻게 관련되어 있는지 알아봤습니다. 이제 쿼리를 실행하여 누가 돈을 빌려주는지 알아보겠습니다. 다음 쿼리를 잘라 입력란에 붙여넣습니다.
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
이 쿼리는 트랜잭션 테이블을 커밋 테이블에 조인한 다음 후보 테이블에 조인합니다. 직업 직책에 'ENGINEER'가 포함된 사용자의 거래만 확인합니다. 이 쿼리는 준거 집단을 기준으로 결과를 집계합니다. 이를 통해 여러 정당에 대한 기부자 분포를 확인할 수 있습니다.
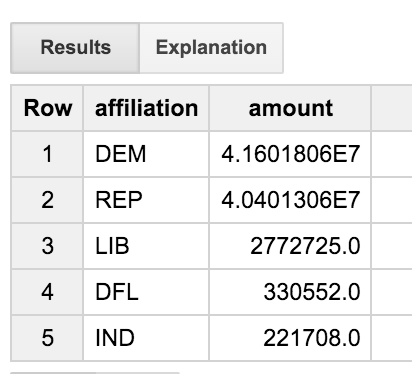
우리는 엔지니어들이 민주화와 공신력 있는 사람들에게 고르게 분산되어 있는 것을 볼 수 있습니다. 그런데 'DFL' 파티는 무엇일까요? 세 글자로 된 코드보다는 진짜 이름을 알려주는 것이 더 좋을까요?
당사자 코드는 FEC 웹사이트에 정의되어 있습니다. 당원 이름과 전체 이름이 일치하는 표가 나옵니다 (DFL/#39;; Democratic-Farmer-Labor'). 쿼리로 번역을 수동으로 할 수 있지만, 힘든 작업이 많아서 동기화하기가 어렵습니다.
HTML을 쿼리의 일부로 파싱할 수 있다면 어떻게 하나요? 페이지에서 아무 곳이나 마우스 오른쪽 버튼으로 클릭하고 '페이지 소스 보기'를 확인합니다. 소스에 많은 헤더 / 상용구 정보가 있지만 <table> 태그를 찾습니다. 각 매핑 행은 HTML <tr> 요소에 있으며 이름과 코드는 모두 <td> 요소에 래핑됩니다. 각 행은 다음과 같이 표시됩니다.
HTML은 다음과 같습니다.
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
BigQuery는 수천 명의 작업자에서 동시에 소스를 확인할 수 있으므로 BigQuery는 웹에서 직접 파일을 읽을 수 없습니다. 임의의 웹페이지에 대해 실행이 허용되었다면 기본적으로 분산 서비스 거부 (DDoS) 공격이 될 것입니다. FEC 웹페이지의 html 파일은 gs://campaign-funding 버킷에 저장됩니다.
캠페인 자금 지원 데이터를 바탕으로 표를 만들어야 합니다. 이 파일은 앞서 만든 다른 GCS 지원 테이블과 유사합니다. 여기서는 실제로 스키마가 없다는 차이가 있습니다. 행마다 단일 필드를 사용하고 이름을 'data''로 지정하겠습니다. CSV 파일인 것처럼 사용되지만 쉼표를 구분하는 대신 가짜 구분자(`)와 따옴표 문자를 사용하지 않습니다.
파티 조회 테이블을 만들려면 명령줄에서 다음 명령어를 실행합니다.
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
이제 자바스크립트를 사용하여 파일을 파싱합니다. BigQuery 쿼리 편집기의 오른쪽 상단에는 'UDF 편집기'를 나타내는 버튼이 있습니다. 클릭하여 자바스크립트 UDF 수정으로 전환합니다. UDF 편집기는 주석 처리된 상용구로 채워집니다.

포함된 코드를 삭제하고 다음 코드를 입력합니다.
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
여기에서 자바스크립트는 두 부분으로 나뉩니다. 첫 번째는 입력 행을 파싱한 출력을 내보내는 함수입니다. 다른 하나는 이 함수를 이름이 tableParser인 사용자 정의 함수 (UDF)로 등록하고 'data''라는 입력 열을 취하여 2개의 열과 코드와 이름을 출력하는 정의입니다. 코드 열은 세 글자로 된 코드가 되며, 이름 열은 정당의 전체 이름입니다.
"쿼리 편집기 탭"로 다시 전환하고 다음 쿼리를 입력합니다.
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
이 쿼리를 실행하면 원시 HTML 파일이 파싱되고 구조화된 값이 필드 값으로 출력됩니다. 멋지지 않나요? 'DFL'의 의미를 이해할 수 있는지 알아보세요.
이제 파티 코드를 이름으로 번역할 수 있습니다. 흥미로운 코드를 찾기 위해 이 코드를 사용하는 다른 쿼리를 시도해 보겠습니다. 다음 쿼리를 실행합니다.
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
이 쿼리에는 어느 캠페인에서 가장 많은 기부금이 모금되었는지, 정당의 이름은 어느 정도인지 표시됩니다.
이 테이블은 용량이 매우 크지 않으며 쿼리하는 데 30초 정도 걸립니다. 테이블을 많이 사용하는 경우 BigQuery로 가져오는 것이 좋습니다. 테이블에 대해 ETL 쿼리를 실행하여 쉽게 사용할 수 있는 데이터로 강제 변환한 다음 영구 테이블로 저장할 수 있습니다. 즉, 파티 코드를 번역하는 방법을 항상 기억할 필요는 없으며 번역 중에 잘못된 데이터를 필터링할 수도 있습니다.
'옵션 표시' 버튼을 클릭한 다음 'Destination Table' 라벨 옆의 '표 선택' 버튼을 클릭하세요. campaign_funding 데이터 세트를 선택하고 테이블 ID를 summary'로 입력합니다. ‘allow large results'’ 체크박스를 선택하세요.

이제 다음 쿼리를 실행합니다.
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
이 쿼리는 상당히 길며 추가 정리 옵션이 있습니다. 예를 들어 금액이 100만 달러 이상인 모든 값을 무시합니다. 또한 정규 표현식을 사용하여 "LASTNAME, FIRSTNAME"를 "FIRSTNAME LASTNAME"로 변환합니다. 모험을 해보고 싶다면 UDF를 작성하여 훨씬 더 효과적으로 대문자를 사용하도록 시도해 보세요 (예: "Firstname Lastname").
마지막으로 campaign_funding.summary 테이블에 대해 몇 가지 쿼리를 실행하여 해당 테이블에 대한 쿼리가 더 빠른지 확인합니다. 대상 표 쿼리 옵션을 먼저 삭제하세요. 그렇지 않으면 요약 테이블을 덮어쓸 수 있습니다.
이제 FEC 웹사이트의 데이터를 정리하여 BigQuery로 가져왔습니다.
학습한 내용
- BigQuery에서 GCS 기반 테이블 사용
- BigQuery에서 사용자 정의 함수 사용
다음 단계
- 몇 가지 흥미로운 쿼리를 통해 이 선거 주기의 누구에게 기부하고 있는지 알아보세요.
자세히 알아보기
- 사용자 정의 함수로 수행할 수 있는 작업을 자세히 알아보세요.
- 제휴 데이터 소스(GCS 포함)에 대해 알아보세요.
- google-bigquery 태그에서 StackOverflow에 대한 질문을 게시하고 답변을 확인할 수 있습니다.
Google에 의견 보내기
- 언제든지 이 페이지 왼쪽 하단에 있는 링크를 사용하여 문제를 신고하거나 의견을 보내 주세요.