डेटासेट (Dataset, DataCatalog, DataDownload) का स्ट्रक्चर्ड डेटा
डेटासेट का नाम, ब्यौरा, क्रिएटर, और बंटवारे के फ़ॉर्मैट जैसी अन्य जानकारी देने पर, Dataset Search टूल में डेटासेट को ढूंढना आसान हो जाता है. इस तरह की जानकारी, स्ट्रक्चर्ड डेटा के रूप में दी जाती है. Google, डेटासेट खोजने के अपने तरीके में schema.org और उन अन्य मेटाडेटा मानकों का इस्तेमाल करता है जिन्हें डेटासेट की जानकारी देने वाले पेजों में जोड़ा जा सकता है. इस मार्कअप का मकसद जैविक विज्ञान, सामाजिक विज्ञान, मशीन लर्निंग, नागरिक और सरकारी डेटा जैसे कई फ़ील्ड से डेटासेट खोजने की सुविधा को बेहतर बनाना है.
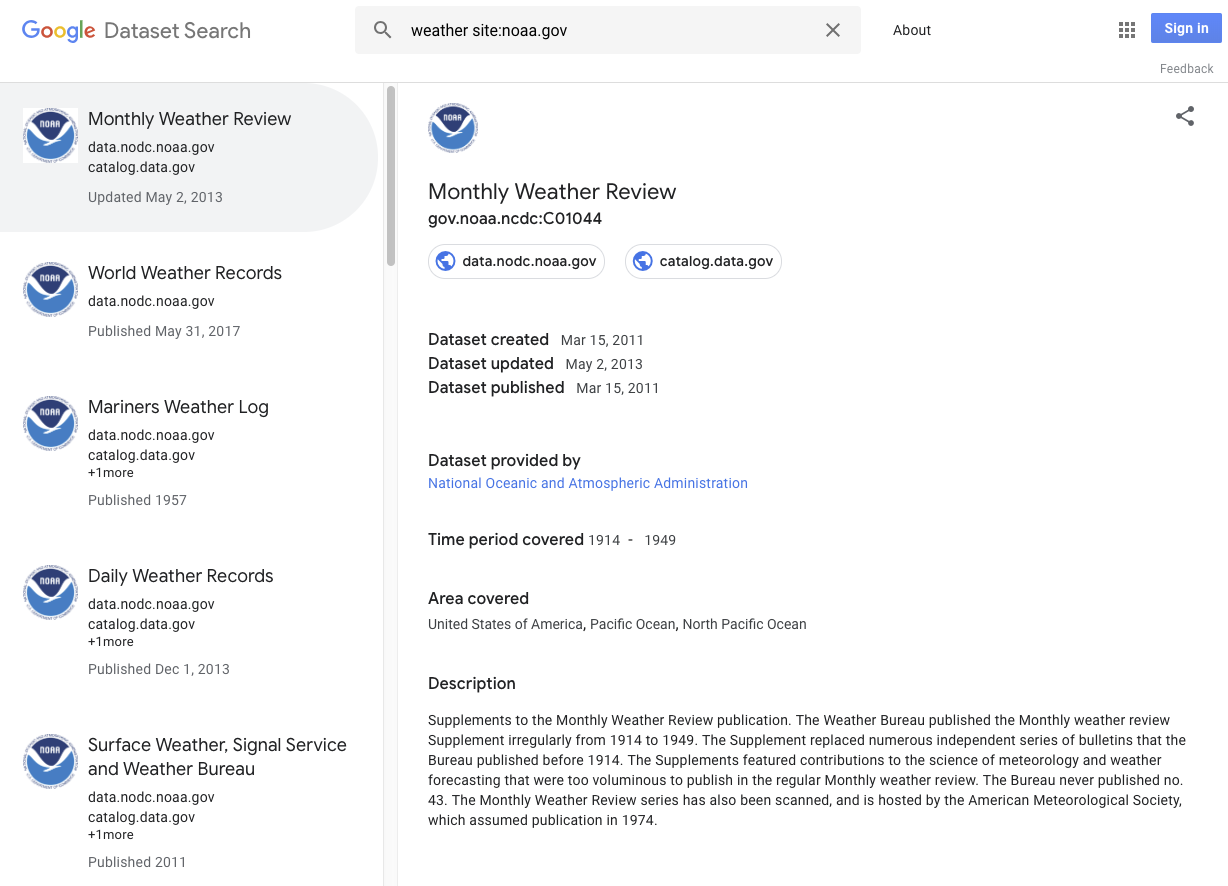
यहां कुछ ऐसी चीज़ों के उदाहरण दिए गए हैं जिन्हें डेटासेट के तौर पर इस्तेमाल किया जा सकता है:
- कुछ डेटा वाली टेबल या CSV फ़ाइल
- टेबल का व्यवस्थित संग्रह
- मालिकाना फ़ॉर्मैट में ऐसी फ़ाइल जिसमें डेटा मौजूद हो
- फ़ाइलों का ऐसा संग्रह जो एक साथ मिलकर कुछ बेहतर डेटासेट तैयार करता है.
- किसी दूसरे फ़ॉर्मैट में मौजूद डेटा वाला ऐसा स्ट्रक्चर्ड ऑब्जेक्ट जिसे प्रोसेस करने के लिए, आप शायद किसी खास टूल में लोड करना चाहें
- ऐसी इमेज जिनमें डेटा मौजूद हो
- मशीन लर्निंग से जुड़ी फ़ाइलें, जैसे कि तैयार किए गए पैरामीटर या न्यूरल नेटवर्क स्ट्रक्चर की जानकारी
स्ट्रक्चर्ड डेटा को जोड़ने का तरीका
स्ट्रक्चर्ड डेटा, किसी पेज के बारे में जानकारी देने और पेज के कॉन्टेंट को कैटगरी में बांटने का एक स्टैंडर्ड फ़ॉर्मैट है. अगर आपको स्ट्रक्चर्ड डेटा के बारे में ज़्यादा जानकारी नहीं है, तो स्ट्रक्चर्ड डेटा के काम करने का तरीका देखें.
स्ट्रक्चर्ड डेटा बनाने, उसकी जांच करने, और उसे रिलीज़ करने के बारे में खास जानकारी यहां दी गई है.
- ज़रूरी प्रॉपर्टी जोड़ें. जिस फ़ॉर्मैट का इस्तेमाल हो रहा है उसके हिसाब से जानें कि पेज पर स्ट्रक्चर्ड डेटा कहां डालना है.
- दिशा-निर्देशों का पालन करें.
- ज़्यादा बेहतर नतीजों (रिच रिज़ल्ट) की जांच का इस्तेमाल करके, अपने कोड की पुष्टि करें. साथ ही, सभी ज़रूरी गड़बड़ियों को ठीक करें. ऐसी अन्य समस्याओं को भी ठीक करें जो टूल में फ़्लैग की जा सकती हैं. ऐसा इसलिए, क्योंकि इससे आपके स्ट्रक्चर्ड डेटा की क्वालिटी को बेहतर बनाने में मदद मिल सकती है. हालांकि, ज़्यादा बेहतर नतीजों (रिच रिज़ल्ट) में शामिल होने के लिए, यह ज़रूरी नहीं है.
- स्ट्रक्चर्ड डेटा वाले कुछ पेजों को डिप्लॉय करें. इसके बाद, यूआरएल जांचने वाला टूल इस्तेमाल करके देखें कि Google को पेज कैसा दिखेगा. पक्का करें कि Google आपका पेज ऐक्सेस कर सकता हो. साथ ही, देखें कि उस पेज को robots.txt फ़ाइल और
noindexटैग से ब्लॉक न किया गया हो या लॉग इन करना ज़रूरी न हो. अगर पेज ठीक लगता है, तो Google को अपने यूआरएल फिर से क्रॉल करने के लिए कहा जा सकता है. - Google को आगे होने वाले बदलावों की जानकारी देने के लिए हमारा सुझाव है कि आप साइटमैप सबमिट करें. Search Console साइटमैप एपीआई की मदद से, इसे ऑटोमेट भी किया जा सकता है.
Dataset Search के नतीजों से किसी डेटासेट को मिटाना
अगर आपको Dataset Search के नतीजों में डेटासेट नहीं दिखाना है, तो robots meta टैग का इस्तेमाल करके अपने डेटा को इंडेक्स किए जाने के तरीके को कंट्रोल करें. ध्यान रखें कि Dataset Search में, बदलाव दिखने में कुछ समय (क्रॉल करने के शेड्यूल के हिसाब से दिन या हफ़्ते) लग सकता है.
डेटासेट खोजने का हमारा तरीका
हम डेटासेट के बारे में, वेब पेजों पर मौजूद स्ट्रक्चर्ड डेटा को समझ सकते हैं. इसे समझने के लिए, हम schema.org Dataset मार्कअप या W3C के डेटा कैटलॉग शब्दावली (DCAT) फ़ॉर्मैट में पेश किए गए उसी के जैसे स्ट्रक्चर का इस्तेमाल करते हैं. हम W3C CSVW के आधार पर स्ट्रक्चर्ड डेटा के लिए प्रयोग के तौर पर सुविधाओं की खोज भी कर रहे हैं. हम डेटासेट की जानकारी देने के लिए और भी बेहतर काम करना चाहते हैं. साथ ही, हमारे तरीके को सबसे अच्छे तरीके के तौर पर अपनाए जाने की उम्मीद करते हैं. हम डेटासेट ढूंढने के लिए किस तरीके का इस्तेमाल
करते हैं, इस बारे में ज़्यादा जानने के लिए,
डेटासेट ढूंढना आसान बनाना देखें.
उदाहरण
रिच रिज़ल्ट (ज़्यादा बेहतर नतीजों) के टेस्ट में, JSON-LD और schema.org सिंटैक्स (पसंदीदा) का इस्तेमाल करने वाले डेटासेट का उदाहरण यहां दिया गया है. उसी schema.org शब्दावली का इस्तेमाल RDFa 1.1 या माइक्रोडेटा सिंटैक्स में भी किया जा सकता है. मेटाडेटा के बारे में बताने के लिए, W3C DCAT शब्दावली का भी इस्तेमाल किया जा सकता है. नीचे दिया गया उदाहरण असल डेटासेट की जानकारी के मुताबिक है.
यहां JSON-LD में डेटासेट का एक उदाहरण दिया गया है:
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>RDFa में DCAT शब्दावली का इस्तेमाल करने वाले डेटासेट का एक उदाहरण यहां दिया गया है (यह ज़्यादा बेहतर नतीजे (रिच रिज़ल्ट) के टेस्ट में काम नहीं करता):
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>दिशा-निर्देश
साइटों को स्ट्रक्चर्ड डेटा से जुड़े दिशा-निर्देशों का पालन करना चाहिए. स्ट्रक्चर्ड डेटा से जुड़े दिशा-निर्देशों के अलावा, हम यहां दिए गए साइटमैप इस्तेमाल करने के सबसे सही तरीके के साथ-साथ, सोर्स और मूल जगह के सबसे सही तरीके अपनाने का भी सुझाव देते हैं.
साइटमैप इस्तेमाल करने के सबसे सही तरीके
साइटमैप फ़ाइल का इस्तेमाल
करें, ताकि Google को आपके यूआरएल ढूंढने में मदद मिल सके. साइटमैप फ़ाइल और sameAs मार्कअप का इस्तेमाल
करने से, आपकी साइट पर डेटासेट की जानकारी पब्लिश करने का रिकॉर्ड रखने में मदद मिलती है.
अगर आपके पास डेटासेट रिपॉज़िटरी (डेटा स्टोर करने की जगह) है, तो आपके पास कम से कम दो तरह के पेज हो सकते हैं: हर डेटासेट के लिए
कैननिकल ("लैंडिंग") पेज और एक से ज़्यादा डेटासेट वाले पेज (जैसे कि खोज
नतीजे या डेटासेट के कुछ सबसेट). हमारा सुझाव है कि आप कैननिकल पेज में डेटासेट के बारे में
स्ट्रक्चर्ड डेटा जोड़ें. अगर आपको डेटासेट की एक से ज़्यादा कॉपी में स्ट्रक्चर्ड डेटा यानी खोज नतीजों के पेज में सूचियां जोड़नी हैं, तो कैननिकल पेज से लिंक करने के लिए sameAs प्रॉपर्टी का इस्तेमाल करें.
सोर्स और मूल जगह के लिए सबसे सही तरीके
खुले डेटासेट को फिर से पब्लिश करना, इकट्ठा करना, और दूसरे डेटासेट के आधार पर तैयार करना आम बात है. यह उन स्थितियों को दिखाता है जिसमें डेटासेट को किसी दूसरे डेटासेट की कॉपी करके या दूसरे डेटासेट के आधार पर अलग तरीके से बनाया जाता है.
- जब डेटासेट या ब्यौरे को कहीं और पब्लिश किए गए कॉन्टेंट को कॉपी करके फिर से पब्लिश करना हो, तो मूल डेटासेट के सबसे ज़्यादा कैननिकल यूआरएल दिखाने के लिए
sameAsप्रॉपर्टी का इस्तेमाल करें.sameAsकी वैल्यू ऐसी होनी चाहिए जिससे डेटासेट के बारे में साफ़ तौर पर पता चल सके. इसका मतलब है कि दो अलग-अलग डेटासेट के लिए,sameAsकी एक ही वैल्यू का इस्तेमाल नहीं किया जाना चाहिए. - अगर फिर से पब्लिश किए गए डेटासेट और उसके मेटाडेटा में बहुत सारे बदलाव किए गए हैं, तो
isBasedOnप्रॉपर्टी का इस्तेमाल करें. - जब डेटासेट के बारे में जानकारी कई मूल डेटासेट से ली गई हो या इकट्ठा की गई हो, तो
isBasedOnप्रॉपर्टी का इस्तेमाल करें. - किसी भी ज़रूरी
डिजिटल ऑब्जेक्ट आइडेंटिफ़ायर (डीओआई) या कॉम्पैक्ट आइडेंटिफ़ायर को अटैच करने के लिए,
identifierप्रॉपर्टी का इस्तेमाल करें. अगर डेटासेट में एक से ज़्यादा आइडेंटिफ़ायर हैं, तोidentifierप्रॉपर्टी को एक से ज़्यादा बार इस्तेमाल करें. अगर आपने JSON-LD का इस्तेमाल किया है, तो यह JSON सूची के सिंटैक्स का इस्तेमाल करके दिखाया जाता है.
हम सुझावों के आधार पर अपनी सलाह को बेहतर बनाने की उम्मीद करते हैं. खास तौर पर ऐसे सुझाव जो मूल जगह, वर्शन, और टाइम सीरीज़ के पब्लिकेशन से जुड़ी तारीखों की जानकारी के बारे में हैं. कृपया समुदाय की चर्चाओं में शामिल हों.
टेक्स्ट प्रॉपर्टी के लिए सुझाव
हम टेक्स्ट वाली सभी प्रॉपर्टी को 5000 या इससे कम वर्णों तक सीमित रखने का सुझाव देते हैं. Google Dataset Search किसी भी टेक्स्ट वाली प्रॉपर्टी के पहले 5000 वर्णों का ही इस्तेमाल करता है. नाम और शीर्षक आम तौर पर कुछ शब्दों या एक छोटे वाक्य के होते हैं.
पहले से जानकारी वाली गड़बड़ियां और चेतावनियां
आपको Google के ज़्यादा बेहतर नतीजों (रिच रिज़ल्ट) की जांच और पुष्टि करने के दूसरे सिस्टम में गड़बड़ियां या चेतावनियां मिल सकती हैं. खास तौर पर, पुष्टि करने वाले सिस्टम से यह सुझाव मिल सकता है कि संगठनों को दी जाने वाली संपर्क जानकारी में contactType शामिल होनी चाहिए. काम की वैल्यू में customer service, emergency, journalist, newsroom, और public engagement को शामिल किया जाना चाहिए.
csvw:Table की गड़बड़ियों को, mainEntity प्रॉपर्टी की अनचाही वैल्यू के तौर पर अनदेखा भी किया जा सकता है.
अलग-अलग तरह के स्ट्रक्चर्ड डेटा की परिभाषा
आपका कॉन्टेंट रिच रिज़ल्ट में दिखे, इसके लिए आपको ज़रूरी प्रॉपर्टी जोड़नी होंगी. अपने कॉन्टेंट के बारे में ज़्यादा जानकारी जोड़ने के लिए, आपके पास सुझाई गई प्रॉपर्टी भी शामिल करने का विकल्प होता है. इससे लोगों को बेहतर अनुभव दिया जा सकता है.
अपने मार्कअप की पुष्टि करने के लिए, ज़्यादा बेहतर नतीजों (रिच रिज़ल्ट) की जांच का इस्तेमाल किया जा सकता है.
इसमें डेटासेट, उसके मेटाडेटा, और उसके कॉन्टेंट को दिखाने के बारे में जानकारी देने पर खास तौर से ध्यान दिया जाता है. जैसे कि, डेटासेट का मेटाडेटा उसके बारे में जानकारी देता है. इससे पता चलता है कि यह किस वैरिएबल के लिए काम करता है, इसे किसने बनाया है वगैरह. यानी इसमें वैरिएबल के लिए खास वैल्यू शामिल नहीं होती हैं.
Dataset
Dataset की पूरी जानकारी, schema.org/Dataset
पर मौजूद है.
आपके पास डेटासेट के पब्लिकेशन के बारे में ज़्यादा जानकारी देने का विकल्प होता है, जैसे कि लाइसेंस, पब्लिश करने की
तारीख, इसका डीओआई या
किसी अलग
रिपॉज़िटरी में डेटासेट के कैननिकल वर्शन के बारे में
बताने वाला sameAs. मूल जगह और लाइसेंस की जानकारी देने
वाले डेटासेट के लिए identifier, license, और sameAs जोड़ें.
Google के साथ काम करने वाली प्रॉपर्टी ये हैं:
| ज़रूरी प्रॉपर्टी | |
|---|---|
description
|
Text
डेटासेट के बारे में कम शब्दों में खास जानकारी. दिशा-निर्देश
|
name
|
Text
डेटासेट की जानकारी देने वाला नाम. जैसे कि "उत्तरी गोलार्ध में बर्फ़ की मोटाई". दिशा-निर्देश
हम इसका सुझाव देते हैं: दो अलग-अलग डेटासेट के लिए हम इसका सुझाव नहीं देते: दो अलग-अलग डेटासेट के लिए |
| सुझाई गई प्रॉपर्टी | |
|---|---|
alternateName
|
Text
इस डेटासेट के बारे में जानकारी देने वाले वैकल्पिक नाम, जैसे कि उपनाम या छोटा नाम. उदाहरण (JSON-LD फ़ॉर्मैट में): "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person या
Organization
यह डेटासेट बनाने या तैयार करने वाला. व्यक्ति की खास पहचान करने के लिए,
"creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text या CreativeWork
ऐसे शैक्षणिक लेखों की पहचान करता है जिसका सुझाव डेटा उपलब्ध कराने वाले व्यक्ति ने दिया हो. इसका मकसद उपयोगकर्ताओं को डेटासेट के साथ इन लेखों का भी
सुझाव देना है. "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" अन्य दिशा-निर्देश
|
funder
|
Person या Organizationवह व्यक्ति या संगठन जो इस डेटासेट के लिए आर्थिक सहायता देता है. व्यक्ति की खास पहचान करने के लिए, "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart या isPartOf
|
URL या
Dataset
अगर कोई डेटासेट छोटे-छोटे डेटासेट का संग्रह हो, तो ऐसा संबंध बताने के लिए "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL, Text या PropertyValue
एक पहचानकर्ता, जैसे कि डीओआई या कॉम्पैक्ट पहचानकर्ता. अगर डेटासेट में एक से ज़्यादा पहचानकर्ता
हैं, तो |
isAccessibleForFree
|
Boolean
डेटासेट को बिना पेमेंट किए ऐक्सेस किया जा सकता है या नहीं. |
keywords
|
Text
डेटासेट के बारे में खास जानकारी देने वाले कीवर्ड. |
license
|
URL या CreativeWork
वह लाइसेंस जिससे डेटासेट उपलब्ध कराया जाता है. उदाहरण के लिए: "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } अन्य दिशा-निर्देश
|
measurementTechnique
|
Text या URL
किसी डेटासेट में इस्तेमाल की गई ऐसी तकनीक, टेक्नोलॉजी या तरीका जो |
sameAs
|
URL
रेफ़रंस वाले वेब पेज का यूआरएल, जो साफ़ तौर पर डेटासेट की पहचान बताता है. |
spatialCoverage |
Text या Place
डेटासेट की जगह से जुड़ी जानकारी, एक ही जगह पर मुहैया कराई जा सकती है. अगर डेटासेट में जगह की जानकारी दी गई है, तो ही इस प्रॉपर्टी को शामिल करें. जैसे, ऐसी एक जगह जहां सभी मेज़रमेंट की जानकारी इकट्ठा की गई हो या किसी जगह के लिए बाउंडिंग बॉक्स की जगह की जानकारी मौजूद हो. पॉइंट "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } आकार अलग-अलग आकार वाली जगहों के बारे में जानकारी देने के लिए, "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } }
जगहों के नाम "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
डेटासेट के डेटा में समय अंतराल की खास जानकारी शामिल होती है. अगर डेटासेट में समय की जानकारी दी गई है, तो ही इस प्रॉपर्टी को शामिल करें. Schema.org में, समय अंतरालों और किसी खास समय की जानकारी ISO 8601 मानक में दी जाती है. आप डेटासेट में दिए अंतराल के आधार पर,
तारीखों के बारे में अलग-अलग तरह से जानकारी दे सकते हैं. समय के दो खुले अंतरालों के बारे में बताने के लिए दो दशमलव बिंदुओं ( कोई एक तारीख "temporalCoverage" : "2008" समयावधि "temporalCoverage" : "1950-01-01/2013-12-18" खुली समयावधि "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text या PropertyValue
ऐसा वैरिएबल जिसे यह डेटासेट मापता है. जैसे कि तापमान या दबाव. |
version
|
Text या Number
डेटासेट का वर्शन नंबर. |
url
|
URL
डेटासेट के बारे में जानकारी देने वाले पेज की जगह. |
DataCatalog
DataCatalog की पूरी जानकारी schema.org/DataCatalog
पर मौजूद है.
डेटासेट अक्सर रिपॉज़िटरी (डेटा स्टोर की जगह) में पब्लिश किए जाते हैं. यहां पर कई दूसरे डेटासेट भी मौजूद होते हैं. एक ही डेटासेट को ऐसी एक से ज़्यादा रिपोज़िटरी (डेटा स्टोर की जगह) में शामिल किया जा सकता है. सीधे इस डेटासेट की जानकारी देते हुए, इसके डेटा कैटलॉग के बारे में बताया जा सकता है. इसके लिए, इन प्रॉपर्टी का इस्तेमाल किया जा सकता है:
| सुझाई गई प्रॉपर्टी | |
|---|---|
includedInDataCatalog
|
DataCatalog
वह कैटलॉग जिससे यह डेटासेट जुड़ा है.
|
DataDownload
DataDownload की पूरी जानकारी schema.org/DataDownload
पर मौजूद है. डेटासेट की प्रॉपर्टी के अलावा, डेटासेट के लिए यहां दी गई उन प्रॉपर्टी को भी जोड़ें जो डाउनलोड के विकल्प मुहैया कराती हैं.
distribution प्रॉपर्टी, डेटासेट पाने की सुविधा मुहैया कराती है. इसमें मौजूद यूआरएल अक्सर डेटासेट की जानकारी देने वाले लैंडिंग पेज पर ले जाता है. distribution प्रॉपर्टी में यह जानकारी दी जाती है कि डेटा कहां से और किस फ़ॉर्मैट में मिलेगा. इस प्रॉपर्टी में कई वैल्यू हो सकती हैं: जैसे कि CSV वर्शन एक यूआरएल में मौजूद होता है और Excel वर्शन दूसरे यूआरएल में.
| ज़रूरी प्रॉपर्टी | |
|---|---|
distribution.contentUrl
|
URL
डाउनलोड करने के लिए लिंक. |
| सुझाई गई प्रॉपर्टी | |
|---|---|
distribution
|
DataDownload
डेटासेट डाउनलोड करने की जगह और डाउनलोड किए जाने वाले फ़ाइल फ़ॉर्मैट की जानकारी.
|
distribution.encodingFormat
|
Text या URL
डेटासेट शेयर करने के लिए फ़ाइल फ़ॉर्मैट.
|
टेबल में रखे गए डेटासेट
टेबल में दिए गए डेटासेट को खास तौर पर पंक्तियों और कॉलम के ग्रिड में व्यवस्थित किया जाता है. ऐसे पेज जिनमें टेबल में दिए गए डेटासेट एम्बेड किए गए होते हैं, उन पेजों के लिए ज़्यादा साफ़ जानकारी देने वाला मार्कअप भी बनाया जा सकता है. यह मार्कअप मूल तरीके को ध्यान में रखकर बनाया जा सकता है. फ़िलहाल, हमारी जानकारी के मुताबिक, CSVW ("वेब पर CSV", W3C देखें) का एक वैरिएंट, एचटीएमएल पेज पर उपयोगकर्ता के काम के कॉन्टेंट के साथ उपलब्ध कराया जाता है. यह कॉन्टेंट, टेबल के फ़ॉर्मैट में होता है.
यहां एक छोटी टेबल का उदाहरण दिया गया है, जिसे CSVW JSON-LD फ़ॉर्मैट के कोड में बदला गया है. ज़्यादा बेहतर नतीजों (रिच रिज़ल्ट) के टेस्ट में कुछ पहले से जानकारी वाली गड़बड़ियां मिली हैं.
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>Search Console की मदद से, ज़्यादा बेहतर नतीजों (रिच रिज़ल्ट) पर नज़र रखना
Search Console एक ऐसा टूल है जिसकी मदद से, आप Google Search में अपने पेज की परफ़ॉर्मेंस पर नज़र रख सकते हैं. Google Search के नतीजों में अपनी साइट को शामिल कराने के लिए, आपको Search Console में साइन अप करने की ज़रूरत नहीं है. हालांकि, इससे आपको यह समझने में मदद मिलेगी कि Google आपकी साइट को कैसे देखता है. साथ ही, इसकी मदद से, साइट की परफ़ॉर्मेंस को भी बेहतर बनाया जा सकता है. हमारा सुझाव है कि आप इन मामलों में Search Console देखें:
- पहली बार स्ट्रक्चर्ड डेटा इस्तेमाल करने के बाद
- नए टेंप्लेट जारी करने या कोड को अपडेट करने के बाद
- समय-समय पर ट्रैफ़िक का विश्लेषण करते समय
पहली बार स्ट्रक्चर्ड डेटा इस्तेमाल करने के बाद
जब Google, आपके पेजों को इंडेक्स कर ले, तब ज़्यादा बेहतर नतीजों (रिच रिज़ल्ट) की स्थिति वाली रिपोर्ट का इस्तेमाल करके, उन गड़बड़ियों को देखें जिन्हें ठीक करने की ज़रूरत है. आम तौर पर, मान्य आइटम की संख्या में बढ़ोतरी होगी और अमान्य आइटम की संख्या में कोई बढ़ोतरी नहीं होगी. अगर आपको स्ट्रक्चर्ड डेटा में गड़बड़ियां मिलती हैं, तो:
- अमान्य आइटम ठीक करें.
- लाइव यूआरएल की जांच करें और देखें कि गड़बड़ी ठीक हुई है या नहीं.
- स्थिति की रिपोर्ट का इस्तेमाल करके, पुष्टि करने का अनुरोध करें.
नए टेंप्लेट जारी करने या कोड को अपडेट करने के बाद
अपनी वेबसाइट में अहम बदलाव करने पर, स्ट्रक्चर्ड डेटा के अमान्य आइटम की संख्या में बढ़ोतरी पर नज़र रखें.- अगर आपको अमान्य आइटम की संख्या में बढ़ोतरी दिखती है, तो हो सकता है कि आपने ऐसा नया टेंप्लेट रोल आउट किया हो जो काम नहीं करता हो. इसके अलावा, यह भी हो सकता है कि आपकी साइट, मौजूदा टेंप्लेट से नए और खराब तरीके से इंटरैक्ट कर रही हो.
- अगर आपको मान्य आइटम की संख्या में कमी दिखती है, यानी वह अमान्य आइटम की संख्या में बढ़ोतरी से मेल नहीं खाती है, तो हो सकता है कि अब आप पेजों में स्ट्रक्चर्ड डेटा एम्बेड नहीं कर रहे हैं. गड़बड़ी की वजह जानने के लिए, यूआरएल जांचने वाले टूल का इस्तेमाल करें.
समय-समय पर ट्रैफ़िक का विश्लेषण करना
परफ़ॉर्मेंस रिपोर्ट का इस्तेमाल करके, Google Search से आने वाले ट्रैफ़िक का विश्लेषण करें. आपको डेटा से पता चलेगा कि आपका पेज Search में, ज़्यादा बेहतर नतीजे (रिच रिज़ल्ट) के तौर पर कितनी बार दिखता है. साथ ही, यह भी पता चलेगा कि लोग उस पर कितनी बार क्लिक करते हैं और खोज के नतीजों में आपकी साइट के दिखने की औसत जगह क्या है. आपके पास इन नतीजों को Search Console API की मदद से अपने-आप देखने का भी विकल्प है.समस्याएं हल करना
अगर आपको स्ट्रक्चर्ड डेटा लागू करने या डीबग करने में कोई समस्या आ रही है, तो यहां कुछ ऐसे रिसॉर्स दिए गए हैं जिनसे आपको मदद मिल सकती है.
- अगर आपने कॉन्टेंट मैनेजमेंट सिस्टम (सीएमएस) का इस्तेमाल किया है या कोई दूसरा व्यक्ति आपकी साइट को मैनेज कर रहा है, तो उससे मदद मांगें. उन्हें Search Console का वह मैसेज ज़रूर फ़ॉरवर्ड करें जिसमें समस्या के बारे में बताया गया है.
- Google यह गारंटी नहीं देता है कि जिन पेजों में स्ट्रक्चर्ड डेटा का इस्तेमाल हुआ है वे खोज के नतीजों में दिखेंगे. Google आपके कॉन्टेंट को ज़्यादा बेहतर नतीजों (रिच रिज़ल्ट) में क्यों नहीं दिखा सकता, इसकी आम वजहें जानने के लिए, स्ट्रक्चर्ड डेटा से जुड़े सामान्य दिशा-निर्देश देखें.
- आपके स्ट्रक्चर्ड डेटा में कोई गड़बड़ी हो सकती है. स्ट्रक्चर्ड डेटा से जुड़ी गड़बड़ियों की सूची और पार्स न किए जा सकने वाले स्ट्रक्चर्ड डेटा की रिपोर्ट देखें.
- अगर आपके किसी पेज पर मौजूद स्ट्रक्चर्ड डेटा के ख़िलाफ़ कोई मैन्युअल ऐक्शन लिया गया है, तो उसे अनदेखा कर दिया जाएगा. हालांकि, वह पेज अब भी Google Search के नतीजों में दिख सकता है. स्ट्रक्चर्ड डेटा से जुड़ी समस्याएं ठीक करने के लिए, मैन्युअल ऐक्शन की रिपोर्ट का इस्तेमाल करें.
- आपका कॉन्टेंट, तय किए गए दिशा-निर्देशों का पालन करता है या नहीं, यह जानने के लिए दिशा-निर्देशों को फिर से देखें. स्पैम वाला कॉन्टेंट या मार्कअप इस्तेमाल करने की वजह से, समस्या हो सकती है. हालांकि, यह हो सकता है कि इसकी वजह, सिंटैक्स की समस्या न हो. इस वजह से, 'ज़्यादा बेहतर नतीजों (रिच रिज़ल्ट) का टेस्ट' में इन समस्याओं की पहचान न हो पा रही हो.
- शामिल नहीं किए गए रिच रिज़ल्ट या रिच रिज़ल्ट की कुल संख्या में गिरावट आने की समस्या हल करें.
- पेज को फिर से क्रॉल करने और इंडेक्स करने में कुछ समय लग सकता है. याद रखें कि पेज को पब्लिश करने के बाद, Google को उसे ढूंढने और क्रॉल करने में कुछ दिन लग सकते हैं. क्रॉल और इंडेक्स करने के बारे में सामान्य सवालों के जवाब पाने के लिए, Google Search पर क्रॉल करने और इंडेक्स करने से जुड़े अक्सर पूछे जाने वाले सवाल देखें.
- Google Search Central फ़ोरम में सवाल पोस्ट करें.
Dataset Search के नतीजों में खास डेटासेट का न दिखना
error गड़बड़ी की वजह क्या है: आपकी साइट में, डेटासेट की जानकारी देने वाले पेज पर स्ट्रक्चर्ड डेटा नहीं है या पेज को अभी तक क्रॉल नहीं किया गया है.
done समस्या को हल करना
- जो पेज आपको Dataset Search के नतीजों में देखना है उसके लिंक को कॉपी करें और इसे ज़्यादा बेहतर नतीजों (रिच रिज़ल्ट) के टेस्ट के लिए डालें. अगर "इस टेस्ट से पता चला है कि पेज ज़्यादा बेहतर नतीजों (रिच रिज़ल्ट) के लिए ज़रूरी शर्तें पूरी नहीं करता" या "सभी मार्कअप ज़्यादा बेहतर नतीजों (रिच रिज़ल्ट) के लिए ज़रूरी शर्तें पूरी नहीं करते" मैसेज दिखता है, तो इसका मतलब है कि पेज पर कोई भी डेटासेट मार्कअप नहीं है या डेटासेट मार्कअप गलत है. आप स्ट्रक्चर्ड डेटा को जोड़ने का तरीका सेक्शन में जाकर, इसे ठीक कर सकते हैं.
- अगर पेज पर मार्कअप है, तो हो सकता है कि उसे अभी तक क्रॉल न किया गया हो. आप Search Console से क्रॉल की स्थिति की जांच कर सकते हैं.
कंपनी का लोगो मौजूद नहीं है या वह नतीजों में सही तरीके से नहीं दिख पा रहा है
error गड़बड़ी की वजह क्या है: हो सकता है कि आपके पेज पर संगठन के लोगो के लिए schema.org मार्कअप मौजूद न हो या Google के साथ आपका कारोबार रजिस्टर न हुआ हो.
done समस्या को हल करना
- अपने पेज पर स्ट्रक्चर्ड डेटा का लोगो जोड़ें.
- Google पर अपने कारोबार की जानकारी रजिस्टर करें.