Comprender conceptos básicos del SEO en JavaScript
JavaScript es una parte importante de la plataforma web porque aporta muchas funciones que convierten a la Web en una potente plataforma de aplicaciones. Si permites que la Búsqueda de Google pueda descubrir las aplicaciones web que hayas creado con JavaScript, te resultará más fácil llegar a nuevos usuarios y volver a captar el interés de los que ya tengas cuando busquen el contenido que proporciona tu aplicación web. Aunque la Búsqueda de Google ejecuta JavaScript siempre con la versión más reciente de Chromium, hay algunos aspectos que puedes optimizar.
En esta guía, se explica cómo procesa la Búsqueda de Google el código JavaScript y se proporcionan prácticas recomendadas sobre cómo optimizar aplicaciones web JavaScript para la Búsqueda de Google.
Cómo procesa Google el código JavaScript
Google procesa las aplicaciones web JavaScript en tres fases principales:
- Rastreo
- Renderizado
- Indexación
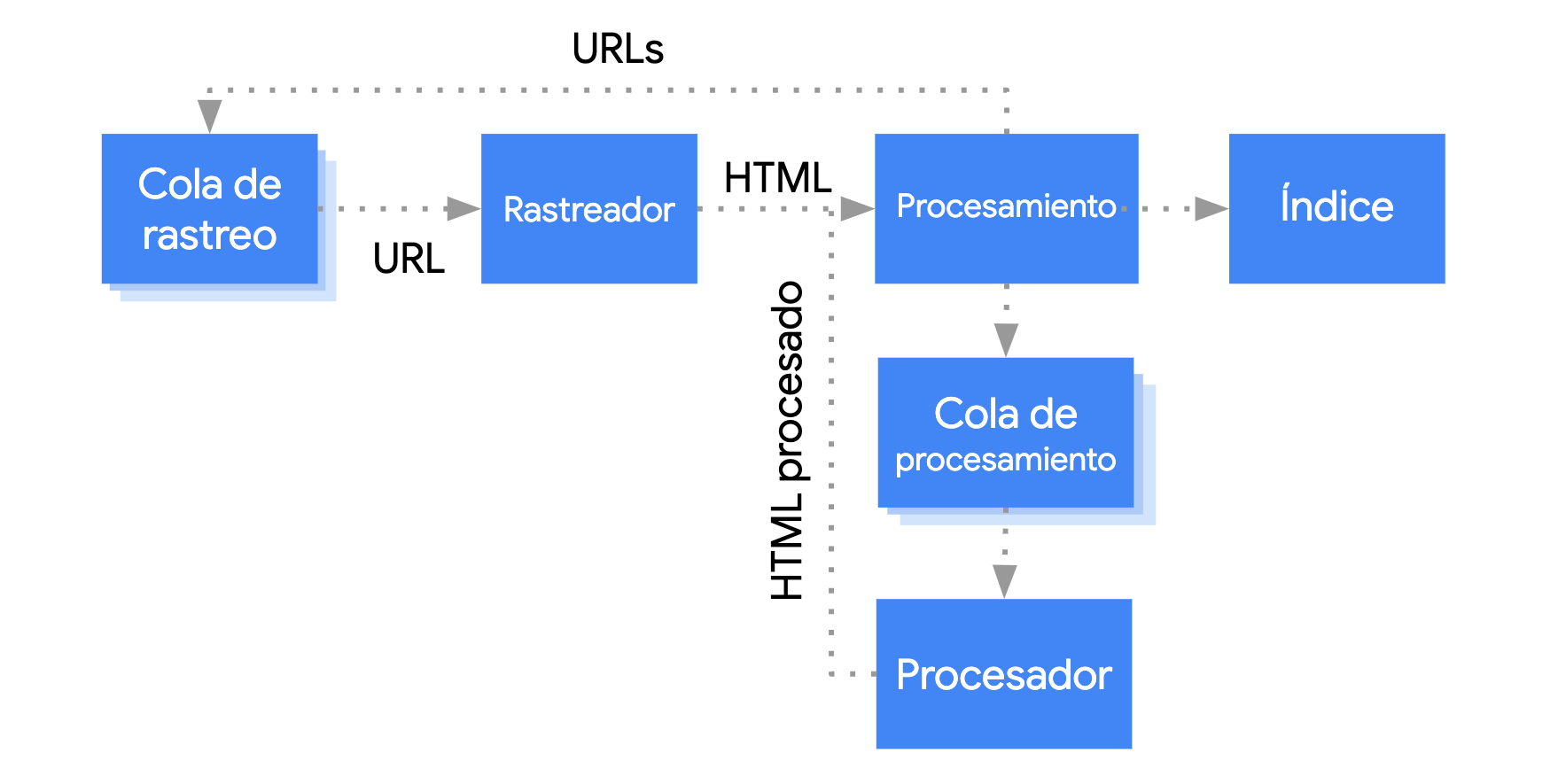
Antes de rastrear o renderizar las páginas, el robot de Google las coloca en una cola. No se puede saber a primera vista si una página está en la cola de rastreo o en la de renderizado. Cuando el robot de Google obtiene una URL de la cola de rastreo mediante una solicitud HTTP, primero verifica si permites que se rastree. Para ello, lee el archivo robots.txt. Si no lo permites, el robot de Google no envía ninguna solicitud HTTP a la URL y se la salta. La Búsqueda de Google no renderizará el JavaScript de archivos bloqueados ni de páginas bloqueadas.
A continuación, el robot de Google analiza la respuesta que recibe y busca otras URLs en el atributo href de los enlaces HTML; si hay alguna, la añade a la cola de rastreo. Para que no se busquen enlaces, utiliza el mecanismo nofollow.
El sistema de rastrear URLs y analizar las respuestas HTML es útil para procesar sitios web clásicos o páginas que se renderizan en el servidor, ya que en ambos casos en el HTML de la respuesta HTTP se incluye todo el contenido. No obstante, es posible que en algunos sitios web con JavaScript se use el modelo de esqueleto de aplicación, en el que el HTML que se devuelve en primera instancia no incluye el contenido real, sino que Google tiene que ejecutar JavaScript para ver el contenido real de la página que el código JavaScript genera.
El robot de Google pone en la cola de renderizado todas las páginas con un código de estado HTTP 200, a menos que el encabezado o la etiqueta meta robots de una página indique a Google que no debe indexarse.
Las páginas suelen permanecer en esta cola durante unos segundos, aunque a veces podrían estar algo más de tiempo. Una vez que los recursos de Google lo permiten, un Chromium sin interfaz gráfica renderiza la página y ejecuta el JavaScript.
Después, el robot de Google vuelve a analizar el HTML renderizado en busca de enlaces y, si hay alguno, lo pone en la cola de rastreo. Google también indexa la página con el documento HTML renderizado.
Ten en cuenta que sigue siendo una buena opción renderizar el contenido previamente o en el servidor, ya que así tu sitio web funcionará más rápido para los usuarios y los rastreadores; además, no todos los robots pueden ejecutar JavaScript.
Describir las páginas con títulos y fragmentos únicos
Tener elementos <title> y metadescripciones únicos y descriptivos ayuda a los usuarios a identificar rápidamente el resultado que mejor se adapta a sus necesidades.
Puedes crear y cambiar tanto las metadescripciones como el elemento <title> con JavaScript.
Definir la URL canónica
La etiqueta de enlace rel="canonical" ayuda a Google a encontrar la versión canónica de una página.
Puedes usar JavaScript para definir la URL canónica, pero ten en cuenta que no debes usarlo para cambiarla por una diferente a la que especificaste en el HTML original.
La mejor forma de definir la URL canónica es usar HTML, pero, si tienes que usar JavaScript, asegúrate de que la URL canónica siempre tenga el mismo valor que el HTML original.
Si no puedes definir la URL canónica en el HTML, puedes usar JavaScript para hacerlo y omitirla en el HTML original.
Escribir código compatible
Como los navegadores ofrecen muchas APIs y JavaScript es un lenguaje que evoluciona rápidamente, Google tiene ciertas limitaciones en cuanto a las APIs y las funciones de JavaScript que admite. Para que tu código sea compatible con Google, sigue nuestras recomendaciones para solucionar problemas de JavaScript.
Te recomendamos que utilices la publicación diferencial y polyfills si detectas que falta una API de navegador que necesitas. Como algunas funciones de navegador no pueden incluirse mediante polyfill, consulta las posibles limitaciones en la documentación sobre polyfill.
Usar códigos de estado HTTP con significado
El robot de Google detecta si no se ha podido rastrear una página mediante los códigos de estado HTTP.
Por lo tanto, te recomendamos que indiques al robot de Google si no se puede rastrear o indexar una página mediante códigos de estado claros, como el código de error 404 si no se puede encontrar una página o el 401 si hay que iniciar sesión para acceder a ella.
Con los códigos de estado HTTP, también puedes avisar al robot de Google de que una página se ha trasladado a otra URL para que el índice pueda actualizarse correctamente.
Consulta la lista de códigos de estado HTTP y descubre cómo afectan a la Búsqueda de Google.
Evitar errores soft 404 en aplicaciones de página única
Por lo general, en las aplicaciones de página única que deben renderizar los clientes, el enrutamiento se implementa de modo que también lo realicen los clientes.
En estos casos, es poco práctico (y a veces imposible) devolver códigos de estado HTTP con significado.
Para que no se produzcan errores soft 404 al usar el renderizado y el enrutamiento del cliente, sigue una de estas estrategias:
- Usa redirecciones JavaScript que lleven a una URL en la que el servidor pueda devolver un código de estado HTTP
404(por ejemplo,/not-found). - Añade la etiqueta
<meta name="robots" content="noindex">a las páginas de error mediante JavaScript.
A continuación puedes ver un fragmento de código que muestra cómo se implementaría una redirección:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
A continuación puedes ver un fragmento de código que muestra cómo se implementaría la etiqueta noindex:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
Utilizar la API History en vez de fragmentos
Google solo puede descubrir tus enlaces si son elementos HTML <a> con un atributo href.
En las aplicaciones de página única en las que se utiliza enrutamiento de cliente, implementa el enrutamiento entre las diferentes vistas de tu aplicación web mediante la API History. Para asegurarte de que el robot de Google pueda analizar y extraer tus URLs, no cargues distintas partes del contenido de la página mediante fragmentos. A continuación se muestra un ejemplo de lo que no debería hacerse, ya que el robot de Google no puede resolver las URLs de forma fiable:
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
En lugar de utilizar el código de arriba, implementa la API History para asegurarte de que el robot de Google pueda acceder a tus URLs:
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
Inyectar correctamente la etiqueta de enlace rel="canonical"
Aunque no recomendamos utilizar JavaScript en este caso, es posible insertar una etiqueta de enlace rel="canonical" con JavaScript.
La Búsqueda de Google recogerá la URL canónica insertada cuando renderice la página. A continuación, se muestra un ejemplo de cómo insertar una etiqueta de enlace rel="canonical" con JavaScript:
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
Usar etiquetas meta robots con cuidado
Puedes impedir que Google indexe una página o siga enlaces mediante la etiqueta meta robots.
Por ejemplo, si añades la etiqueta meta que se indica a continuación en la parte superior de tu página, Google no podrá indexarla:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
Con JavaScript, puedes añadir etiquetas meta robots a páginas, así como cambiar su contenido.
En el fragmento de código de ejemplo que aparece a continuación, se muestra cómo cambiar la etiqueta meta robots con JavaScript para impedir que la página se indexe si no se devuelve contenido en una llamada a la API.
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
Utilizar almacenamiento en caché de larga duración
Para reducir las solicitudes de red que se hacen y disminuir el uso de recursos, el robot de Google almacena mucho contenido en caché. A veces, el WRS ignora los encabezados de almacenamiento en caché, por lo que quizá acabe usando recursos CSS o JavaScript obsoletos.
Para resolver este problema, crea una huella digital del contenido e inclúyela en el nombre del archivo (por ejemplo, main.2bb85551.js).
Como las huellas digitales dependen del contenido, cada vez que modifiques un archivo, su nombre cambiará.
Puedes consultar más información al respecto en la guía de web.dev sobre estrategias de almacenamiento en caché de larga duración.
Utilizar datos estructurados
Si utilizas datos estructurados en tus páginas, puedes usar JavaScript para generar el archivo JSON-LD necesario e insertarlo en la página. Prueba tu implementación para evitar problemas.
Seguir las prácticas recomendadas sobre componentes web
Google admite componentes web. Cuando Google renderiza una página, combina el contenido de shadow DOM y de light DOM. Esto significa que Google solo puede ver el contenido que está visible en el HTML renderizado. Para asegurarte de que Google siga viendo tu contenido después de renderizarlo, usa la prueba de resultados enriquecidos o la herramienta de inspección de URLs y comprueba el HTML renderizado.
Si el contenido no es visible en el HTML renderizado, Google no podrá indexarlo.
A continuación se muestra un ejemplo en el que se crea un componente web que muestra su contenido light DOM dentro del shadow DOM correspondiente. Una forma de asegurarse de que tanto el light DOM como el shadow DOM se muestren en el HTML renderizado es utilizar un elemento Slot.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>Una vez renderizado, Google puede indexar este contenido:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Solucionar problemas con imágenes y contenido de carga en diferido
Las imágenes pueden consumir mucho ancho de banda y afectar al rendimiento. Una buena estrategia es utilizar la carga en diferido para cargar solo imágenes cuando el usuario está a punto de verlas. Sigue nuestras directrices de carga en diferido para asegurarte de que implementas este método en tu sitio sin que afecte a su rendimiento en las búsquedas.