
ML Kit Pose Detection API เป็นโซลูชันอเนกประสงค์น้ำหนักเบาสำหรับให้นักพัฒนาแอปใช้ตรวจจับท่าทางของร่างกายในแบบเรียลไทม์จากวิดีโอต่อเนื่องหรือภาพนิ่ง ท่าทางอธิบายตำแหน่งของร่างกาย ณ ช่วงเวลาหนึ่งพร้อมกับชุดจุดที่เป็นรูปโครงกระดูก จุดสังเกตต่างๆ สอดคล้องกับส่วนต่างๆ ของร่างกาย เช่น ไหล่และสะโพก การใช้ตำแหน่งเปรียบเทียบของจุดสังเกตสามารถใช้แยกท่าทางต่างๆ ออกจากกัน
การตรวจจับท่าทางของ ML Kit สร้างการจับคู่แบบโครงร่าง 33 จุดทั้งร่างกายซึ่งรวมถึงจุดสังเกตบนใบหน้า (หู ตา ปาก และจมูก) รวมถึงจุดบนมือและเท้า รูปที่ 1 ด้านล่างแสดงจุดสังเกตเมื่อมองผู้ใช้ผ่านกล้อง จึงเป็นภาพสะท้อน ด้านขวาของผู้ใช้จะปรากฏทางด้านซ้ายของรูปภาพ
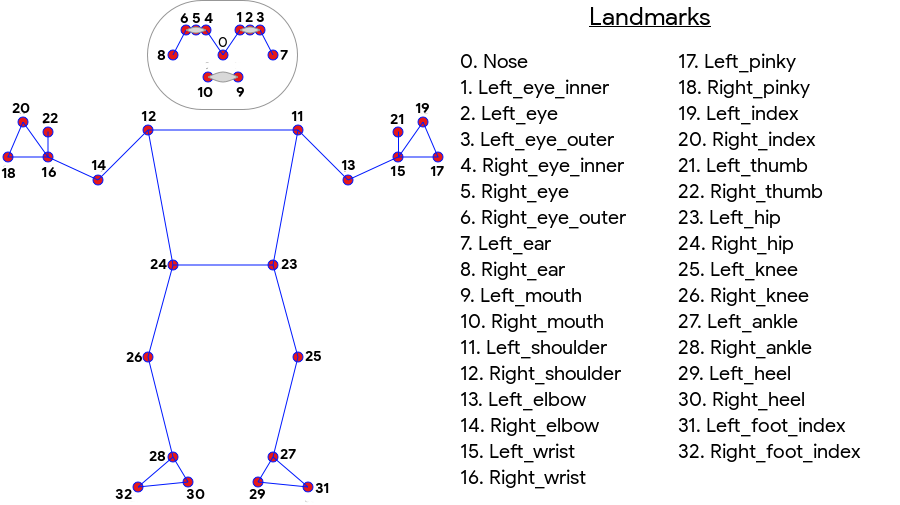
การตรวจจับท่าทางของ ML Kit ไม่จำเป็นต้องใช้อุปกรณ์พิเศษหรือความเชี่ยวชาญด้าน ML เพื่อผลลัพธ์ที่ยอดเยี่ยม เทคโนโลยีนี้ช่วยให้นักพัฒนาสามารถสร้างประสบการณ์ ที่ไม่เหมือนใครสำหรับผู้ใช้ด้วยโค้ดเพียงไม่กี่บรรทัด
ต้องมีใบหน้าของผู้ใช้เพื่อตรวจจับท่าทาง การตรวจจับท่าทางทำงานได้ดีที่สุดเมื่อมองเห็นร่างกายทั้งตัวในเฟรม แต่ก็ยังตรวจจับท่าทางบางส่วนของร่างกายได้ ในกรณีนี้ ระบบจะกำหนดพิกัดที่ไม่รู้จักให้กับจุดสังเกตนอกรูปภาพ
ความสามารถหลัก
- การสนับสนุนข้ามแพลตฟอร์ม ใช้งานได้เหมือนเดิมทั้งบน Android และ iOS
- การติดตามทั้งตัว โมเดลนี้จะแสดงจุดสำคัญที่เป็นโครงกระดูก 33 จุด รวมถึงตำแหน่งของมือและเท้า
- คะแนน InFrameLikelihood สำหรับจุดสังเกตแต่ละรายการ เป็นการวัดที่แสดงถึงความน่าจะเป็นที่จุดสังเกตอยู่ในเฟรมรูปภาพ คะแนนมีช่วงตั้งแต่ 0.0 ถึง 1.0 โดย 1.0 หมายถึงมีความมั่นใจสูง
- SDK ที่เพิ่มประสิทธิภาพ 2 แบบ SDK พื้นฐานทำงานแบบเรียลไทม์ในโทรศัพท์รุ่นใหม่อย่าง Pixel 4 และ iPhone X โดยจะแสดงผลลัพธ์ที่อัตราประมาณ 30 และ ~45 FPS ตามลำดับ อย่างไรก็ตาม ความแม่นยำของพิกัดจุดสังเกตอาจแตกต่างกันไป SDK ที่ถูกต้องจะแสดงผลลัพธ์ในอัตราเฟรมที่ช้าลง แต่สร้างค่าพิกัดที่แม่นยำยิ่งขึ้น
- Z ประสานงานสำหรับการวิเคราะห์ความลึก ค่านี้ช่วยระบุได้ว่าส่วนต่างๆ ของร่างกายของผู้ใช้อยู่ด้านหน้าหรือด้านหลังสะโพกของผู้ใช้ สำหรับข้อมูลเพิ่มเติม โปรดดูหัวข้อพิกัด Z ด้านล่าง
Pose Detection API นั้นคล้ายกับ Facial Recognition API ตรงที่จะแสดงชุดจุดสังเกตและตำแหน่งของจุดดังกล่าว อย่างไรก็ตาม แม้ว่าการตรวจจับใบหน้าจะพยายามจดจำฟีเจอร์ต่างๆ เช่น ปากที่กำลังยิ้มหรือตาอ้าตาอยู่ การตรวจจับท่าทางไม่ได้แนบความหมายใดๆ ไว้กับจุดสังเกตในท่าทางหรือการโพสท่านั้น คุณสามารถสร้างอัลกอริทึมของคุณเอง เพื่อตีความท่าทาง โปรดดูตัวอย่างในเคล็ดลับการจัดประเภทท่าทาง
การตรวจหาท่าทางจะตรวจจับบุคคลในรูปภาพได้เพียง 1 คนเท่านั้น หากมี 2 คนอยู่ในรูปภาพ โมเดลจะกำหนดจุดสังเกตให้กับบุคคลที่ตรวจพบด้วยความมั่นใจสูงสุด
พิกัด Z
พิกัด Z เป็นค่าทดลองที่คำนวณสำหรับจุดสังเกตทุกแห่ง ซึ่งจะวัดเป็น "พิกเซลภาพ" เช่น พิกัด X และ Y แต่ไม่ใช่ค่า 3 มิติที่แท้จริง แกน Z ตั้งฉากกับกล้องและข้ามระหว่างสะโพกของวัตถุ จุดเริ่มต้นของแกน Z คือจุดศูนย์กลางระหว่างสะโพก (ซ้าย/ขวาและด้านหน้า/ด้านหลังสัมพันธ์กับกล้อง) ค่าลบ Z จะอยู่ใกล้กับกล้อง ส่วนค่าบวกจะอยู่นอกค่า พิกัด Z ไม่มีขอบเขตบนหรือล่าง
ผลลัพธ์ตัวอย่าง
ตารางต่อไปนี้แสดงพิกัดและ InFrameLikelihood สำหรับจุดสังเกตบางรายการในโพสทางด้านขวา โปรดทราบว่าพิกัด Z สำหรับมือซ้ายของผู้ใช้เป็นค่าลบ เนื่องจากพิกัดดังกล่าวอยู่ด้านหน้าตรงกลางของสะโพกและหันเข้าหากล้อง

| สถานที่สำคัญ | Type | อันดับ | InFrameLikelihood |
|---|---|---|---|
| 11 | LEFT_SHOULDER | (734.9671, 550.7924, -118.11934) | 0.9999038 |
| 12 | RIGHT_SHOULDER | (391.27032, 583.2485, -321.15836) | 0.9999894 |
| 13 | LEFT_ELBOW | (903.83704, 754.676, -219.67009) | 0.9836427 |
| 14 | RIGHT_ELBOW | (322.18152, 842.5973, -179.28519) | 0.99970156 |
| 15 | LEFT_WRIST | (1073.8956, 654.9725, -820.93463) | 0.9737737 |
| 16 | RIGHT_WRIST | (218.27956, 1015.70435, -683.6567) | 0.995568 |
| 17 | LEFT_PINKY | (1146.1635, 609.6432, -956.9976) | 0.95273364 |
| 18 | RIGHT_PINKY | (176.17755, 1065.838, -776.5006) | 0.9785348 |
กลไกภายใน
ดูรายละเอียดเพิ่มเติมเกี่ยวกับการใช้งานโมเดล ML ที่สำคัญสำหรับ API นี้ได้ที่บล็อกโพสต์ AI ของ Google
หากต้องการดูข้อมูลเพิ่มเติมเกี่ยวกับแนวทางปฏิบัติด้านความเป็นธรรมของ ML และวิธีฝึกโมเดล โปรดดูการ์ดโมเดล