Page Summary
-
ML Kit's Pose Detection API enables real-time body pose tracking in apps, using skeletal landmark points to identify body positions.
-
It offers cross-platform support, full-body tracking with 33 landmarks including hands and feet, and InFrameLikelihood scores for landmark accuracy.
-
Two SDK options are available: a base SDK for real-time performance and an accurate SDK for higher precision landmark coordinates.
-
The API is currently in beta and subject to change.

The ML Kit Pose Detection API is a lightweight versatile solution for app developers to detect the pose of a subject's body in real time from a continuous video or static image. A pose describes the body's position at one moment in time with a set of skeletal landmark points. The landmarks correspond to different body parts such as the shoulders and hips. The relative positions of landmarks can be used to distinguish one pose from another.
ML Kit Pose Detection produces a full-body 33 point skeletal match that includes facial landmarks (ears, eyes, mouth, and nose) and points on the hands and feet. Figure 1 below shows the landmarks looking through the camera at the user, so it's a mirror image. The user's right side appears on the left of the image:
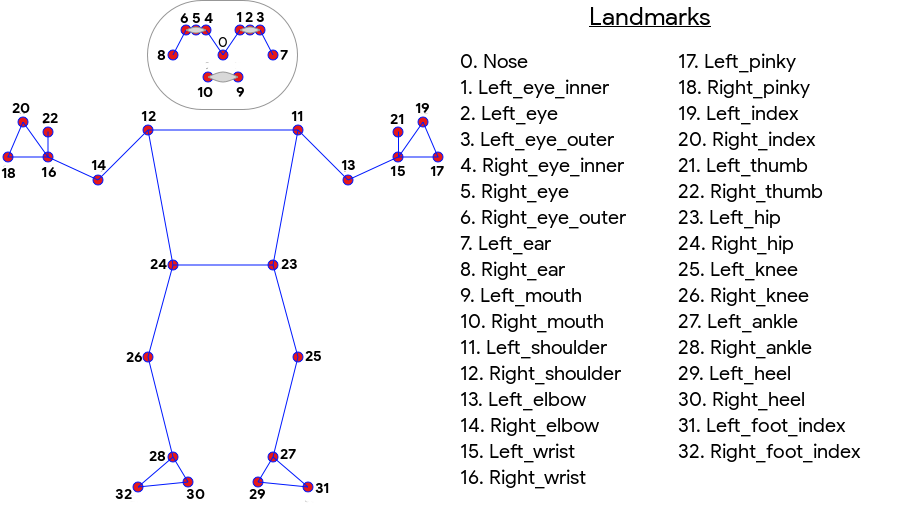
ML Kit Pose Detection doesn't require specialized equipment or ML expertise in order to achieve great results. With this technology developers can create one of a kind experiences for their users with only a few lines of code.
The user's face must be present in order to detect a pose. Pose detection works best when the subject’s entire body is visible in the frame, but it also detects a partial body pose. In that case the landmarks that are not recognized are assigned coordinates outside of the image.
Key capabilities
- Cross-platform support Enjoy the same experience on both Android and iOS.
- Full body tracking The model returns 33 key skeletal landmark points, including the positions of the hands and feet.
- InFrameLikelihood score For each landmark, a measure that indicates the probability that the landmark is within the image frame. The score has a range of 0.0 to 1.0, where 1.0 indicates high confidence.
- Two optimized SDKs The base SDK runs in real time on modern phones like the Pixel 4 and iPhone X. It returns results at the rate of ~30 and ~45 fps respectively. However, the precision of the landmark coordinates may vary. The accurate SDK returns results at a slower framerate, but produces more accurate coordinate values.
- Z Coordinate for depth analysis This value can help determine whether parts of the users body are in front or behind the users' hips. For more information, see the Z Coordinate section below.
The Pose Detection API is similar to the Facial Recognition API in that it returns a set of landmarks and their location. However, while Face Detection also tries to recognize features such as a smiling mouth or open eyes, Pose Detection does not attach any meaning to the landmarks in a pose or the pose itself. You can create your own algorithms to interpret a pose. See Pose Classification Tips for some examples.
Pose detection can only detect one person in an image. If two people are in the image, the model will assign landmarks to the person detected with the highest confidence.
Z Coordinate
The Z Coordinate is an experimental value that is calculated for every landmark. It is measured in "image pixels" like the X and Y coordinates, but it is not a true 3D value. The Z axis is perpendicular to the camera and passes between a subject's hips. The origin of the Z axis is approximately the center point between the hips (left/right and front/back relative to the camera). Negative Z values are towards the camera; positive values are away from it. The Z coordinate does not have an upper or lower bound.
Sample results
The following table shows the coordinates and InFrameLikelihood for a few landmarks in the pose to the right. Note that the Z coordinates for the user's left hand are negative, since they are in front of the subject's hips' center and towards the camera.

| Landmark | Type | Position | InFrameLikelihood |
|---|---|---|---|
| 11 | LEFT_SHOULDER | (734.9671, 550.7924, -118.11934) | 0.9999038 |
| 12 | RIGHT_SHOULDER | (391.27032, 583.2485, -321.15836) | 0.9999894 |
| 13 | LEFT_ELBOW | (903.83704, 754.676, -219.67009) | 0.9836427 |
| 14 | RIGHT_ELBOW | (322.18152, 842.5973, -179.28519) | 0.99970156 |
| 15 | LEFT_WRIST | (1073.8956, 654.9725, -820.93463) | 0.9737737 |
| 16 | RIGHT_WRIST | (218.27956, 1015.70435, -683.6567) | 0.995568 |
| 17 | LEFT_PINKY | (1146.1635, 609.6432, -956.9976) | 0.95273364 |
| 18 | RIGHT_PINKY | (176.17755, 1065.838, -776.5006) | 0.9785348 |
Under the hood
For more implementation details on the underlying ML models for this API, check out our Google AI blog post.
To learn more about our ML fairness practices and how the models were trained, see our Model Card