Glosarium ini mendefinisikan istilah kecerdasan buatan.
A
ablasi
Teknik untuk mengevaluasi pentingnya fitur atau komponen dengan menghapusnya sementara dari model. Kemudian, Anda melatih ulang model tanpa fitur atau komponen tersebut, dan jika performa model yang dilatih ulang jauh lebih buruk, maka fitur atau komponen yang dihapus kemungkinan penting.
Misalnya, Anda melatih model klasifikasi pada 10 fitur dan mencapai presisi 88% pada set pengujian. Untuk memeriksa kepentingan fitur pertama, Anda dapat melatih ulang model hanya menggunakan sembilan fitur lainnya. Jika model yang dilatih ulang berperforma jauh lebih buruk (misalnya, presisi 55%), maka fitur yang dihapus mungkin penting. Sebaliknya, jika model yang dilatih ulang memiliki performa yang sama baiknya, maka fitur tersebut mungkin tidak terlalu penting.
Ablasi juga dapat membantu menentukan pentingnya:
- Komponen yang lebih besar, seperti seluruh subsistem dari sistem ML yang lebih besar
- Proses atau teknik, seperti langkah pra-pemrosesan data
Dalam kedua kasus tersebut, Anda akan mengamati perubahan (atau tidak adanya perubahan) performa sistem setelah Anda menghapus komponen.
Pengujian A/B
Cara statistik untuk membandingkan dua (atau lebih) teknik—A dan B. Biasanya, A adalah teknik yang sudah ada, dan B adalah teknik baru. Pengujian A/B tidak hanya menentukan teknik mana yang memiliki performa lebih baik, tetapi juga apakah perbedaannya signifikan secara statistik.
Pengujian A/B biasanya membandingkan satu metrik pada dua teknik; misalnya, bagaimana perbandingan akurasi model untuk dua teknik? Namun, pengujian A/B juga dapat membandingkan sejumlah metrik terbatas.
chip akselerator
Kategori komponen hardware khusus yang dirancang untuk melakukan komputasi utama yang diperlukan untuk algoritma deep learning.
Chip akselerator (atau cukup akselerator) dapat meningkatkan kecepatan dan efisiensi tugas pelatihan dan inferensi secara signifikan dibandingkan dengan CPU umum. VM ini ideal untuk melatih jaringan saraf dan tugas intensif komputasi serupa.
Contoh chip akselerator meliputi:
- Tensor Processing Unit (TPU) Google dengan hardware khusus untuk deep learning.
- GPU NVIDIA, yang awalnya dirancang untuk pemrosesan grafis, dirancang untuk memungkinkan pemrosesan paralel, yang dapat meningkatkan kecepatan pemrosesan secara signifikan.
akurasi
Jumlah prediksi klasifikasi yang benar dibagi dengan total jumlah prediksi. Definisinya yaitu:
Misalnya, model yang membuat 40 prediksi yang benar dan 10 prediksi yang salah akan memiliki akurasi:
Klasifikasi biner memberikan nama tertentu untuk berbagai kategori prediksi yang benar dan prediksi yang salah. Jadi, rumus akurasi untuk klasifikasi biner adalah sebagai berikut:
dalam hal ini:
- TP adalah jumlah positif benar (prediksi yang benar).
- TN adalah jumlah negatif benar (prediksi yang benar).
- FP adalah jumlah positif palsu (prediksi yang salah).
- FN adalah jumlah negatif palsu (prediksi yang salah).
Bandingkan dan bedakan akurasi dengan presisi dan perolehan.
Lihat Klasifikasi: Akurasi, perolehan, presisi, dan metrik terkait di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
tindakan
Dalam reinforcement learning, mekanisme yang digunakan agen untuk bertransisi antara status lingkungan. Agen memilih tindakan dengan menggunakan kebijakan.
fungsi aktivasi
Fungsi yang memungkinkan jaringan neural mempelajari hubungan non-linear (kompleks) antara fitur dan label.
Fungsi aktivasi populer meliputi:
Plot fungsi aktivasi tidak pernah berupa garis lurus tunggal. Misalnya, plot fungsi aktivasi ReLU terdiri dari dua garis lurus:

Plot fungsi aktivasi sigmoid akan terlihat seperti berikut:

Klik ikon untuk melihat contoh.
Dalam jaringan saraf, fungsi aktivasi memanipulasi jumlah tertimbang dari semua input ke neuron. Untuk menghitung jumlah tertimbang, neuron menjumlahkan produk nilai dan bobot yang relevan. Misalnya, anggap saja input yang relevan ke neuron terdiri dari hal berikut:
| nilai input | berat masukan |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
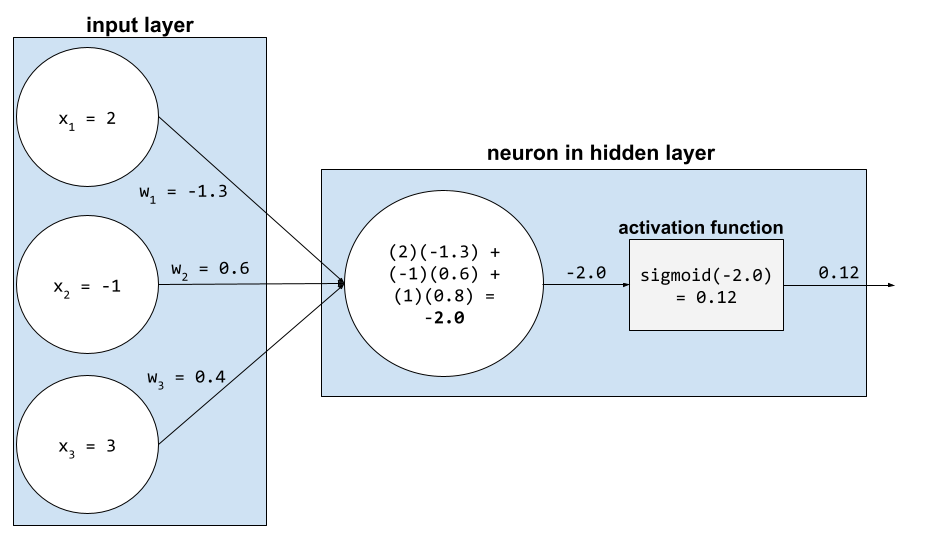
Lihat Jaringan neural: Fungsi aktivasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
pembelajaran aktif
Pendekatan pelatihan yang memungkinkan algoritma memilih beberapa data yang dipelajarinya. Pembelajaran aktif sangat berharga jika contoh berlabel langka atau mahal untuk didapatkan. Daripada mencari berbagai contoh berlabel secara membabi buta, algoritma pembelajaran aktif secara selektif mencari berbagai contoh yang dibutuhkan untuk pembelajaran.
AdaGrad
Algoritma penurunan gradien mutakhir yang menskalakan ulang gradien dari tiap parameter, yang secara efektif memberikan kecepatan pembelajaran independen ke tiap parameter. Untuk penjelasan selengkapnya, lihat Adaptive Subgradient Methods for Online Learning and Stochastic Optimization.
adaptasi
Sinonim untuk penyesuaian atau penyesuaian.
agen
Software yang dapat memproses input pengguna multimodal untuk merencanakan dan mengeksekusi tindakan atas nama pengguna.
Dalam reinforcement learning, agen adalah entitas yang menggunakan kebijakan untuk memaksimalkan hasil yang diharapkan dari transisi antara status lingkungan.
agentic
Bentuk adjektif dari agen. Agentik mengacu pada kualitas yang dimiliki agen (seperti otonomi).
alur kerja agentic
Proses dinamis di mana agen secara otonom merencanakan dan menjalankan tindakan untuk mencapai sasaran. Prosesnya dapat melibatkan penalaran, pemanggilan alat eksternal, dan mengoreksi sendiri rencananya.
pengelompokan aglomeratif
Lihat pengelompokan hierarkis.
Kemiringan AI
Output dari sistem AI generatif yang lebih mengutamakan kuantitas daripada kualitas. Misalnya, halaman web dengan konten buatan AI yang tidak bermutu diisi dengan konten berkualitas rendah buatan AI yang diproduksi dengan murah.
deteksi anomali
Proses mengidentifikasi pencilan. Misalnya, jika rata-rata untuk fitur tertentu adalah 100 dengan standar deviasi 10, maka deteksi anomali akan menandai nilai 200 sebagai mencurigakan.
AR
Singkatan darirealitas tertambah.
area di bawah kurva PR
Lihat AUC PR (Area di bawah Kurva PR).
area di bawah kurva ROC
Lihat AUC (Area di bawah kurva ROC).
kecerdasan umum buatan
Mekanisme non-manusia yang menunjukkan berbagai macam kemampuan memecahkan masalah, kreativitas, dan adaptasi. Misalnya, program yang mendemonstrasikan kecerdasan umum buatan dapat menerjemahkan teks, menyusun simfoni, dan unggul dalam game yang belum ditemukan.
kecerdasan buatan
Program atau model non-manusia yang dapat menyelesaikan tugas-tugas rumit. Misalnya, program atau model yang menerjemahkan teks atau program atau model yang mengidentifikasi penyakit dari gambar radiologi keduanya menunjukkan kecerdasan buatan.
Secara formal, machine learning adalah subbidang kecerdasan buatan. Namun, dalam beberapa tahun terakhir, beberapa organisasi mulai menggunakan istilah kecerdasan buatan dan machine learning secara bergantian.
Attention,
Mekanisme yang digunakan dalam jaringan neural yang menunjukkan pentingnya kata atau bagian kata tertentu. Mekanisme perhatian memadatkan jumlah informasi yang dibutuhkan model untuk memprediksi token/kata berikutnya. Mekanisme atensi umum dapat terdiri dari jumlah berbobot atas sekumpulan input, dengan bobot untuk setiap input dihitung oleh bagian lain dari jaringan neural.
Lihat juga self-attention dan multi-head self-attention, yang merupakan blok penyusun Transformer.
Lihat LLM: Apa itu model bahasa besar? di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya tentang self-attention.
atribut
Sinonim untuk fitur.
Dalam keadilan machine learning, atribut sering kali merujuk pada karakteristik yang berkaitan dengan individu.
pengambilan sampel atribut
Taktik untuk melatih hutan keputusan yang setiap pohon keputusannya hanya mempertimbangkan subset acak dari fitur yang mungkin saat mempelajari kondisi. Umumnya, subset fitur yang berbeda diambil sampelnya untuk setiap node. Sebaliknya, saat melatih pohon keputusan tanpa pengambilan sampel atribut, semua fitur yang mungkin dipertimbangkan untuk setiap node.
AUC (Area di bawah kurva ROC)
Angka antara 0,0 dan 1,0 yang merepresentasikan kemampuan model klasifikasi biner untuk memisahkan kelas positif dari kelas negatif. Semakin dekat AUC ke 1,0, semakin baik kemampuan model untuk memisahkan kelas satu sama lain.
Misalnya, ilustrasi berikut menunjukkan model klasifikasi yang memisahkan kelas positif (oval hijau) dari kelas negatif (persegi panjang ungu) dengan sempurna. Model yang sempurna secara tidak realistis ini memiliki AUC 1,0:

Sebaliknya, ilustrasi berikut menunjukkan hasil untuk model klasifikasi yang menghasilkan hasil acak. Model ini memiliki AUC 0,5:

Ya, model sebelumnya memiliki AUC 0,5, bukan 0,0.
Sebagian besar model berada di antara dua ekstrem tersebut. Misalnya, model berikut memisahkan positif dari negatif, dan oleh karena itu memiliki AUC antara 0,5 dan 1,0:

AUC mengabaikan nilai apa pun yang Anda tetapkan untuk nilai minimum klasifikasi. Sebagai gantinya, AUC mempertimbangkan semua kemungkinan batas klasifikasi.
Klik ikon untuk mempelajari hubungan antara AUC dan kurva ROC.
AUC merepresentasikan area di bawah kurva ROC. Misalnya, kurva ROC untuk model yang memisahkan positif dari negatif dengan sempurna akan terlihat seperti berikut:
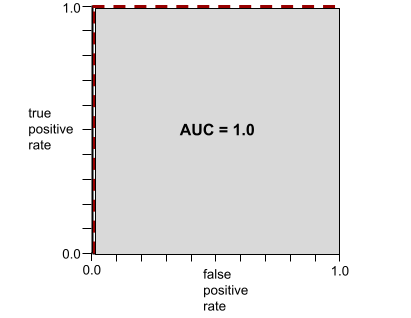
AUC adalah area wilayah abu-abu dalam ilustrasi sebelumnya. Dalam kasus yang tidak biasa ini, area tersebut hanyalah panjang area abu-abu (1,0) dikalikan dengan lebar area abu-abu (1,0). Jadi, hasil kali 1,0 dan 1,0 menghasilkan AUC tepat 1,0, yang merupakan skor AUC tertinggi yang mungkin.
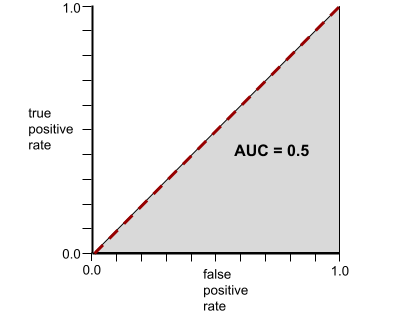
Sebaliknya, kurva ROC untuk model klasifikasi yang tidak dapat memisahkan kelas sama sekali adalah sebagai berikut. Area wilayah abu-abu ini adalah 0,5.
Kurva ROC yang lebih umum terlihat kira-kira seperti berikut:

Menghitung luas area di bawah kurva ini secara manual akan sangat melelahkan, itulah sebabnya program biasanya menghitung sebagian besar nilai AUC.
Lihat Klasifikasi: KOP dan ABK di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
augmented reality
Teknologi yang menempatkan gambar buatan komputer pada tampilan pengguna tentang dunia nyata, sehingga memberikan tampilan komposit.
autoencoder
Sistem yang belajar untuk mengekstrak informasi paling penting dari input. Autoencoder adalah kombinasi encoder dan decoder. Autoencoder mengandalkan proses dua langkah berikut:
- Encoder memetakan input ke format (biasanya) lossy berdimensi lebih rendah (perantara).
- Dekoder membuat versi input asli yang lossy dengan memetakan format berdimensi lebih rendah ke format input berdimensi lebih tinggi yang asli.
Autoencoder dilatih secara end-to-end dengan membuat decoder mencoba merekonstruksi input asli dari format perantara encoder sedekat mungkin. Karena format perantara lebih kecil (berdimensi lebih rendah) daripada format asli, autoencoder dipaksa untuk mempelajari informasi penting dalam input, dan output tidak akan sama persis dengan input.
Contoh:
- Jika data input berupa grafik, salinan tidak persis akan mirip dengan grafik asli, tetapi sedikit dimodifikasi. Mungkin salinan tidak persis akan menghilangkan derau dari grafik asli atau mengisi beberapa piksel yang hilang.
- Jika data input adalah teks, autoencoder akan menghasilkan teks baru yang meniru (tetapi tidak identik dengan) teks asli.
Lihat juga autoencoder variasional.
evaluasi otomatis
Menggunakan software untuk menilai kualitas output model.
Jika output model relatif sederhana, skrip atau program dapat membandingkan output model dengan respons ideal. Jenis evaluasi otomatis ini terkadang disebut evaluasi terprogram. Metrik seperti ROUGE atau BLEU sering kali berguna untuk evaluasi terprogram.
Jika output model kompleks atau tidak ada satu jawaban yang benar, program ML terpisah yang disebut penilai otomatis terkadang melakukan evaluasi otomatis.
Berbeda dengan evaluasi manual.
bias otomatisasi
Saat pengambil keputusan manusia lebih memilih rekomendasi yang dibuat oleh sistem pengambilan keputusan otomatis daripada informasi yang dibuat tanpa otomatisasi, meskipun sistem pengambilan keputusan otomatis tersebut membuat kesalahan.
Lihat Keadilan: Jenis bias di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
AutoML
Proses otomatis apa pun untuk membangun model machine learning . AutoML dapat melakukan tugas seperti berikut secara otomatis:
- Cari model yang paling sesuai.
- Sesuaikan hyperparameter.
- Siapkan data (termasuk melakukan rekayasa fitur).
- Deploy model yang dihasilkan.
AutoML berguna bagi data scientist karena dapat menghemat waktu dan upaya mereka dalam mengembangkan pipeline machine learning dan meningkatkan akurasi prediksi. Alat ini juga berguna bagi non-pakar, karena membuat tugas machine learning yang rumit lebih mudah diakses oleh mereka.
Lihat Machine Learning Otomatis (AutoML) di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
evaluasi pemberi rating otomatis
Mekanisme hibrida untuk menilai kualitas output model AI generatif yang menggabungkan evaluasi manual dengan evaluasi otomatis. Autorater adalah model ML yang dilatih pada data yang dibuat oleh evaluasi manusia. Idealnya, pemberi rating otomatis belajar meniru evaluator manusia.Penilai otomatis bawaan tersedia, tetapi penilai otomatis terbaik adalah yang di-fine-tune secara khusus untuk tugas yang Anda evaluasi.
model autoregresif
Model yang menyimpulkan prediksi berdasarkan prediksi sebelumnya. Misalnya, model bahasa autoregresif memprediksi token berikutnya berdasarkan token yang diprediksi sebelumnya. Semua model bahasa besar berbasis Transformer bersifat autoregresif.
Sebaliknya, model gambar berbasis GAN biasanya tidak autoregresif karena menghasilkan gambar dalam satu penerusan ke depan dan tidak secara iteratif dalam langkah-langkah. Namun, model pembuatan gambar tertentu bersifat autoregresif karena model tersebut menghasilkan gambar secara bertahap.
kerugian tambahan
Fungsi kerugian—yang digunakan bersama dengan jaringan neural model utama fungsi kerugian—yang membantu mempercepat pelatihan selama iterasi awal saat bobot diinisialisasi secara acak.
Fungsi kerugian tambahan mendorong gradien yang efektif ke lapisan sebelumnya. Hal ini memfasilitasi konvergensi selama pelatihan dengan mengatasi masalah gradien yang menghilang.
presisi rata-rata pada k
Metrik untuk meringkas performa model pada satu perintah yang menghasilkan hasil berperingkat, seperti daftar rekomendasi buku bernomor. Presisi rata-rata pada k, adalah rata-rata nilai presisi pada k untuk setiap hasil relevan. Oleh karena itu, rumus untuk presisi rata-rata pada k adalah:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
dalam hal ini:
- \(n\) adalah jumlah item yang relevan dalam daftar.
Berbeda dengan perolehan pada k.
kondisi yang sejajar dengan sumbu
Dalam pohon keputusan, kondisi
yang hanya melibatkan satu fitur. Misalnya, jika area
adalah fitur, maka berikut adalah kondisi yang sejajar dengan sumbu:
area > 200
Berbeda dengan kondisi miring.
B
propagasi balik
Algoritma yang menerapkan penurunan gradien di jaringan neural.
Pelatihan jaringan neural melibatkan banyak iterasi dari siklus dua tahap berikut:
- Selama forward pass, sistem memproses batch contoh untuk menghasilkan prediksi. Sistem membandingkan setiap prediksi dengan setiap nilai label. Perbedaan antara prediksi dan nilai label adalah kerugian untuk contoh tersebut. Sistem menggabungkan kerugian untuk semua contoh guna menghitung total kerugian untuk batch saat ini.
- Selama backward pass (backpropagation), sistem mengurangi kerugian dengan menyesuaikan bobot semua neuron di semua lapisan tersembunyi.
Jaringan neural sering kali berisi banyak neuron di banyak lapisan tersembunyi. Setiap neuron tersebut berkontribusi pada keseluruhan kerugian dengan cara yang berbeda. Backpropagation menentukan apakah akan menambah atau mengurangi bobot yang diterapkan pada neuron tertentu.
Kecepatan pembelajaran adalah pengganda yang mengontrol tingkat kenaikan atau penurunan setiap bobot di setiap operasi backward. Kecepatan pembelajaran yang besar akan menaikkan atau menurunkan setiap bobot lebih banyak daripada kecepatan pembelajaran yang kecil.
Dalam istilah kalkulus, backpropagation menerapkan aturan rantai. dari kalkulus. Artinya, backpropagation menghitung turunan parsial dari error yang terkait dengan setiap parameter.
Beberapa tahun lalu, praktisi ML harus menulis kode untuk menerapkan backpropagation. API ML modern seperti Keras kini menerapkan backpropagation untuk Anda. Fiuh!
Lihat Jaringan neural di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
mengantongi
Metode untuk melatih ansambel dengan setiap model konstituen dilatih pada subset acak dari contoh pelatihan yang diambil sampelnya dengan penggantian. Misalnya, hutan acak adalah kumpulan pohon keputusan yang dilatih dengan bagging.
Istilah bagging adalah singkatan dari bootstrap aggregating.
Lihat Random forest di kursus Decision Forest untuk mengetahui informasi selengkapnya.
kantong kata
Representasi kata-kata dalam frasa atau bagian teks, terlepas dari urutannya. Misalnya, bag of words merepresentasikan tiga frasa berikut secara identik:
- melompat
- melompat
- melompati
Setiap kata dipetakan ke indeks dalam vektor renggang, dengan vektor memiliki indeks untuk setiap kata dalam kosakata. Misalnya, frasa melompat dipetakan ke dalam vektor fitur dengan nilai bukan nol pada tiga indeks yang sesuai dengan kata , melompat, dan . Nilai bukan nol dapat berupa salah satu dari berikut:
- 1 untuk menunjukkan keberadaan sebuah kata.
- Jumlah frekuensi munculnya kata dalam bag. Misalnya, jika frasanya adalah merah marun adalah dengan bulu merah marun, maka merah marun dan akan ditampilkan sebagai 2, sedangkan kata-kata lainnya akan ditampilkan sebagai 1.
- Nilai lain, seperti logaritma jumlah berapa kali suatu kata muncul dalam bag.
dasar
Model yang digunakan sebagai titik referensi untuk membandingkan seberapa baik performa model lain (biasanya, model yang lebih kompleks). Misalnya, model regresi logistik dapat berfungsi sebagai dasar yang baik untuk model dalam.
Untuk masalah tertentu, tolok ukur membantu developer model mengukur performa minimum yang diharapkan yang harus dicapai oleh model baru agar model tersebut berguna.
model dasar
Model terlatih yang dapat berfungsi sebagai titik awal untuk penyesuaian guna menangani tugas atau aplikasi tertentu.
Lihat juga model terlatih dan model dasar.
batch
Kumpulan contoh yang digunakan dalam satu iterasi pelatihan. Ukuran batch menentukan jumlah contoh dalam batch.
Lihat epoch untuk penjelasan tentang hubungan batch dengan epoch.
Lihat Regresi linear: Hyperparameter di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
inferensi batch
Proses menyimpulkan prediksi pada beberapa contoh tidak berlabel yang dibagi menjadi subset yang lebih kecil ("batch").
Inferensi batch dapat memanfaatkan fitur paralelisasi chip akselerator. Artinya, beberapa akselerator dapat menyimpulkan prediksi secara bersamaan pada berbagai batch contoh yang tidak berlabel, sehingga meningkatkan jumlah inferensi per detik secara signifikan.
Lihat Sistem ML produksi: Inferensi statis versus dinamis di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
normalisasi batch
Menormalisasi input atau output fungsi aktivasi di lapisan tersembunyi. Normalisasi batch dapat memberikan manfaat berikut:
- Membuat jaringan neural lebih stabil dengan melindungi dari bobot pencilan.
- Aktifkan kecepatan pembelajaran yang lebih tinggi, yang dapat mempercepat pelatihan.
- Mengurangi overfitting.
ukuran batch
Jumlah contoh dalam batch. Misalnya, jika ukuran batch adalah 100, model akan memproses 100 contoh per iterasi.
Berikut adalah strategi ukuran batch yang populer:
- Penurunan Gradien Stokastik (SGD), dengan ukuran tumpukan 1.
- Batch penuh, dengan ukuran batch adalah jumlah contoh dalam set pelatihan secara keseluruhan. Misalnya, jika set pelatihan berisi satu juta contoh, maka ukuran batchnya adalah satu juta contoh. Batch penuh biasanya merupakan strategi yang tidak efisien.
- Tumpukan mini dengan ukuran tumpukan biasanya antara 10 dan 1.000. Tumpukan mini biasanya merupakan strategi yang paling efisien.
Lihat informasi selengkapnya di sini:
- Sistem ML produksi: Inferensi statis versus dinamis dalam Kursus Singkat Machine Learning.
- Playbook Penyesuaian Deep Learning.
Jaringan neural Bayesian
Jaringan neural probabilistik yang memperhitungkan ketidakpastian dalam bobot dan output. Model regresi jaringan saraf standar biasanya memprediksi nilai skalar; misalnya, model standar memprediksi harga rumah sebesar 853.000. Sebaliknya, jaringan saraf Bayesian memprediksi distribusi nilai; misalnya, model Bayesian memprediksi harga rumah senilai 853.000 dengan simpangan baku 67.200.
Jaringan saraf Bayesian mengandalkan Teorema Bayes untuk menghitung ketidakpastian dalam bobot dan prediksi. Jaringan saraf Bayesian dapat berguna jika penghitungan ketidakpastian bersifat penting, seperti dalam model yang terkait dengan obat-obatan. Jaringan saraf Bayesian juga dapat membantu mencegah overfitting.
Pengoptimalan Bayesian
Teknik model regresi probabilistik untuk mengoptimalkan fungsi objektif yang mahal secara komputasi dengan mengoptimalkan pengganti yang mengukur ketidakpastian menggunakan teknik pembelajaran Bayesian. Karena pengoptimalan Bayesian itu sendiri sangat mahal, biasanya digunakan untuk mengoptimalkan tugas yang mahal untuk dievaluasi dan memiliki sejumlah kecil parameter, seperti memilih hyperparameter.
Persamaan Bellman
Dalam reinforcement learning, identitas berikut dipenuhi oleh Q-function yang optimal:
\[Q(s, a) = r(s, a) + \gamma \mathbb{E}_{s'|s,a} \max_{a'} Q(s', a')\]
Algoritma reinforcement learning menerapkan identitas ini untuk membuat Q-learning menggunakan aturan update berikut:
\[Q(s,a) \gets Q(s,a) + \alpha \left[r(s,a) + \gamma \displaystyle\max_{\substack{a_1}} Q(s',a') - Q(s,a) \right] \]
Selain reinforcement learning, persamaan Bellman memiliki penerapan pada pemrograman dinamis. Lihat entri Wikipedia untuk persamaan Bellman.
BERT (Bidirectional Encoder Representations from Transformers)
Arsitektur model untuk representasi teks. Model BERT terlatih dapat bertindak sebagai bagian dari model yang lebih besar untuk klasifikasi teks atau tugas ML lainnya.
BERT memiliki karakteristik berikut:
- Menggunakan arsitektur Transformer, dan oleh karena itu mengandalkan self-attention.
- Menggunakan bagian encoder Transformer. Tugas encoder adalah menghasilkan representasi teks yang baik, bukan melakukan tugas tertentu seperti klasifikasi.
- Bersifat dua arah.
- Menggunakan penyamaran untuk pelatihan tanpa pengawasan.
Varian BERT mencakup:
Lihat Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing untuk mengetahui ringkasan BERT.
bias (etika/keadilan)
1. Stereotip, prasangka, atau preferensi terhadap beberapa hal, orang, atau kelompok dibandingkan yang lain. Bias ini dapat memengaruhi pengumpulan dan interpretasi data, desain sistem, dan cara pengguna berinteraksi dengan sistem. Bentuk bias jenis ini meliputi:
- bias otomatisasi
- bias konfirmasi
- bias pelaku eksperimen
- bias atribusi kelompok
- bias implisit
- bias dalam golongan
- bias kehomogenan luar golongan
2. Error sistematis yang disebabkan oleh prosedur sampling atau pelaporan. Bentuk bias jenis ini meliputi:
Harap bedakan dengan istilah bias dalam model machine learning atau bias prediksi.
Lihat Fairness: Types of bias di Machine Learning Crash Course untuk mengetahui informasi selengkapnya.
bias (matematika) atau istilah bias
Intersep atau ofset dari asal. Bias adalah parameter dalam model machine learning, yang disimbolkan oleh salah satu dari berikut ini:
- b
- w0
Misalnya, bias bernilai b dalam formula berikut:
Dalam garis dua dimensi sederhana, bias hanya berarti "intersep y". Misalnya, bias garis dalam ilustrasi berikut adalah 2.
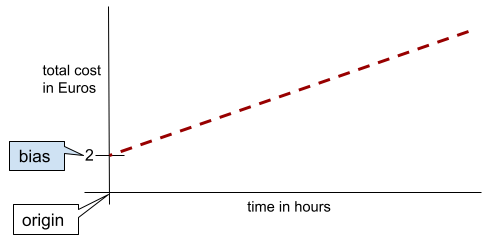
Bias ada karena tidak semua model dimulai dari titik asal (0,0). Misalnya, anggaplah biaya masuk taman hiburan adalah 2 Euro dan biaya tambahan 0,5 Euro untuk setiap jam pelanggan berada di sana. Oleh karena itu, model yang memetakan total biaya memiliki bias 2 karena biaya terendah adalah 2 Euro.
Bias tidak boleh disamakan dengan bias dalam etika dan fairness atau bias prediksi.
Lihat Regresi Linear di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
dua arah
Istilah yang digunakan untuk mendeskripsikan sistem yang mengevaluasi teks yang mendahului dan mengikuti bagian teks target. Sebaliknya, sistem unidirectional hanya mengevaluasi teks yang mendahului bagian teks target.
Misalnya, pertimbangkan model bahasa yang di-masking yang harus menentukan probabilitas untuk kata atau kata-kata yang mewakili garis bawah dalam pertanyaan berikut:
Ada apa denganmu?
Model bahasa satu arah harus mendasarkan probabilitasnya hanya pada konteks yang diberikan oleh kata "Apa", "itu", dan "yang". Sebaliknya, model bahasa dua arah juga dapat memperoleh konteks dari "dengan" dan "Anda", yang dapat membantu model menghasilkan prediksi yang lebih baik.
model bahasa dua arah
Model bahasa yang menentukan probabilitas bahwa token tertentu ada di lokasi tertentu dalam kutipan teks berdasarkan teks sebelumnya dan berikutnya.
bigram
N-gram yang mana N=2.
klasifikasi biner
Jenis tugas klasifikasi yang memprediksi salah satu dari dua kelas yang saling eksklusif:
Misalnya, dua model machine learning berikut masing-masing melakukan klasifikasi biner:
- Model yang menentukan apakah pesan email adalah spam (kelas positif) atau bukan spam (kelas negatif).
- Model yang mengevaluasi gejala medis untuk menentukan apakah seseorang menderita penyakit tertentu (kelas positif) atau tidak menderita penyakit tersebut (kelas negatif).
Berbeda dengan klasifikasi multikelas.
Lihat juga regresi logistik dan nilai minimum klasifikasi.
Lihat Klasifikasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
kondisi biner
Dalam pohon keputusan, kondisi yang hanya memiliki dua kemungkinan hasil, biasanya ya atau tidak. Misalnya, berikut adalah kondisi biner:
temperature >= 100
Berbeda dengan kondisi non-biner.
Lihat Jenis kondisi dalam kursus Decision Forests untuk mengetahui informasi selengkapnya.
pengelompokan
Sinonim untuk pengelompokan.
model kotak hitam
Model yang "alasan"nya tidak mungkin atau sulit dipahami oleh manusia. Artinya, meskipun manusia dapat melihat bagaimana perintah memengaruhi respons, manusia tidak dapat menentukan secara pasti bagaimana model kotak hitam menentukan respons. Dengan kata lain, model kotak hitam tidak memiliki kemampuan interpretasi.
Sebagian besar model deep dan model bahasa besar adalah kotak hitam.
BLEU (Bilingual Evaluation Understudy)
Metrik antara 0,0 dan 1,0 untuk mengevaluasi terjemahan mesin, misalnya, dari bahasa Spanyol ke bahasa Jepang.
Untuk menghitung skor, BLEU biasanya membandingkan terjemahan model ML (teks yang dihasilkan) dengan terjemahan pakar manusia (teks referensi). Tingkat kecocokan N-gram dalam teks yang dihasilkan dan teks referensi menentukan skor BLEU.
Artikel asli tentang metrik ini adalah BLEU: a Method for Automatic Evaluation of Machine Translation.
Lihat juga BLEURT.
BLEURT (Bilingual Evaluation Understudy from Transformers)
Metrik untuk mengevaluasi terjemahan mesin dari satu bahasa ke bahasa lain, terutama ke dan dari bahasa Inggris.
Untuk terjemahan ke dan dari bahasa Inggris, BLEURT lebih selaras dengan peringkat manusia daripada BLEU. Tidak seperti BLEU, BLEURT menekankan kesamaan semantik (makna) dan dapat mengakomodasi parafrasa.
BLEURT mengandalkan model bahasa besar yang telah dilatih (BERT tepatnya) yang kemudian disesuaikan dengan teks dari penerjemah manusia.
Dokumen asli tentang metrik ini adalah BLEURT: Learning Robust Metrics for Text Generation.
mempercepat
Teknik machine learning yang secara berulang menggabungkan serangkaian model klasifikasi yang sederhana dan tidak terlalu akurat (disebut sebagai "pengklasifikasi lemah") menjadi model klasifikasi dengan akurasi tinggi (disebut sebagai "pengklasifikasi kuat") dengan menambahkan bobot contoh yang saat ini salah diklasifikasikan oleh model.
Lihat Pohon Keputusan Penguatan Gradien? di kursus Decision Forests untuk mengetahui informasi selengkapnya.
kotak pembatas
Dalam gambar, koordinat (x, y) persegi panjang di sekitar area yang diinginkan, seperti dalam gambar di bawah.

penyiaran
Memperluas bentuk operand dalam operasi matematika matriks ke dimensi yang kompatibel untuk operasi tersebut. Misalnya, aljabar linear mengharuskan dua operand dalam operasi penambahan matriks untuk memiliki dimensi yang sama. Akibatnya, Anda tidak dapat menambahkan matriks berbentuk (m, n) ke vektor yang panjangnya n. Penyiaran memungkinkan operasi ini dengan memperluas vektor sepanjang n ke matriks berbentuk (m, n) secara virtual dengan mereplikasi nilai yang sama di setiap kolom.
Lihat deskripsi penyiaran di NumPy berikut untuk detail selengkapnya.
pengelompokan
Mengonversi satu fitur menjadi beberapa fitur biner yang disebut bucket atau bin, biasanya berdasarkan rentang nilai. Fitur yang dipotong biasanya merupakan fitur berkelanjutan.
Misalnya, alih-alih merepresentasikan suhu sebagai satu fitur floating point berkelanjutan, Anda dapat membagi rentang suhu ke dalam bucket diskrit, seperti:
- <= 10 derajat Celsius akan menjadi bucket "dingin".
- 11 - 24 derajat Celsius akan menjadi rentang "sedang".
- >= 25 derajat Celsius akan menjadi kategori "hangat".
Model akan memperlakukan setiap nilai dalam bucket yang sama secara identik. Misalnya, nilai 13 dan 22 keduanya berada dalam bucket sedang, sehingga model memperlakukan kedua nilai tersebut secara identik.
Lihat Data numerik: Pengelompokan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
C
lapisan kalibrasi
Penyesuaian pascaprediksi, biasanya diperhitungkan untuk bias prediksi. Prediksi dan probabilitas yang disesuaikan harus cocok dengan distribusi set label yang diamati.
pemilihan kandidat
Kumpulan rekomendasi awal yang dipilih oleh sistem rekomendasi. Misalnya, pertimbangkan toko buku yang menawarkan 100.000 judul. Fase pembuatan kandidat membuat daftar buku yang sesuai untuk pengguna tertentu yang jauh lebih kecil, misalnya 500 buku. Namun, 500 buku tetap terlalu banyak untuk direkomendasikan kepada pengguna. Tahapan sistem rekomendasi berikutnya yang lebih mahal (seperti pemberian skor dan pemeringkatan ulang) akan mengurangi 500 rekomendasi tersebut menjadi set rekomendasi yang jauh lebih kecil dan berguna.
Lihat Ringkasan pembuatan kandidat di kursus Sistem Rekomendasi untuk mengetahui informasi selengkapnya.
sampling kandidat
Pengoptimalan waktu pelatihan yang menghitung probabilitas untuk semua label positif, menggunakan, misalnya, softmax, tetapi hanya untuk sampel label negatif acak. Misalnya, jika diberikan contoh berlabel beagle dan dog, pengambilan sampel kandidat menghitung probabilitas yang diprediksi dan suku kerugian yang sesuai untuk:
- beagle
- subset acak dari kelas negatif yang tersisa (misalnya, kucing, lolipop, pagar).
Idenya adalah bahwa kelas negatif dapat belajar dari penguatan negatif yang lebih jarang selama kelas positif selalu mendapatkan penguatan positif yang tepat, dan ini memang diamati secara empiris.
Sampling kandidat lebih efisien secara komputasi daripada algoritma pelatihan yang menghitung prediksi untuk semua kelas negatif, terutama jika jumlah kelas negatif sangat besar.
data kategorik
Fitur yang memiliki set kemungkinan nilai tertentu. Misalnya, pertimbangkan fitur kategoris bernama traffic-light-state, yang hanya dapat memiliki salah satu dari tiga kemungkinan nilai berikut:
redyellowgreen
Dengan merepresentasikan traffic-light-state sebagai fitur kategoris,
model dapat mempelajari
dampak yang berbeda dari red, green, dan yellow pada perilaku pengemudi.
Fitur kategorik terkadang disebut fitur diskrit.
Berbeda dengan data numerik.
Lihat Bekerja dengan data kategoris di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
model bahasa kausal
Sinonim untuk model bahasa satu arah.
Lihat model bahasa dua arah untuk membedakan berbagai pendekatan terarah dalam pemodelan bahasa.
sentroid
Pusat cluster sebagaimana ditentukan oleh algoritma k-means atau k-median. Misalnya, jika k bernilai 3, maka algoritma k-means atau k-median akan menemukan 3 sentroid.
Lihat Algoritma pengelompokan dalam kursus Pengelompokan untuk mengetahui informasi selengkapnya.
pengelompokan berbasis sentroid
Kategori algoritma pengelompokan yang mengatur data ke dalam cluster nonhierarkis. k-means adalah algoritma pengelompokan berbasis sentroid yang paling banyak digunakan.
Berbeda dengan algoritma pengelompokan hierarkis.
Lihat Algoritma pengelompokan dalam kursus Pengelompokan untuk mengetahui informasi selengkapnya.
prompting chain-of-thought
Teknik rekayasa perintah yang mendorong model bahasa besar (LLM) untuk menjelaskan penalarannya, langkah demi langkah. Misalnya, perhatikan perintah berikut, dengan memberikan perhatian khusus pada kalimat kedua:
Berapa gaya gravitasi yang akan dialami pengemudi dalam mobil yang melaju dari 0 hingga 60 mil per jam dalam 7 detik? Dalam jawaban, tunjukkan semua perhitungan yang relevan.
Respons LLM kemungkinan akan:
- Tampilkan urutan rumus fisika, dengan memasukkan nilai 0, 60, dan 7 di tempat yang sesuai.
- Jelaskan alasan pemilihan formula tersebut dan arti berbagai variabelnya.
Perintah rantai pemikiran memaksa LLM untuk melakukan semua perhitungan, yang dapat menghasilkan jawaban yang lebih benar. Selain itu, perintah chain-of-thought memungkinkan pengguna memeriksa langkah-langkah LLM untuk menentukan apakah jawaban yang diberikan masuk akal atau tidak.
Skor F N-gram karakter (ChrF)
Metrik untuk mengevaluasi model terjemahan mesin. Skor F N-gram Karakter menentukan tingkat tumpang-tindih N-gram dalam teks referensi dengan N-gram dalam teks yang dihasilkan model ML.
Skor F N-gram Karakter mirip dengan metrik dalam kelompok ROUGE dan BLEU, kecuali bahwa:
- Skor F N-gram Karakter beroperasi pada N-gram karakter.
- ROUGE dan BLEU beroperasi pada N-gram kata atau token.
chat
Isi dialog dua arah dengan sistem ML, biasanya model bahasa besar. Interaksi sebelumnya dalam chat (apa yang Anda ketik dan cara model bahasa besar merespons) menjadi konteks untuk bagian chat berikutnya.
Chatbot adalah aplikasi model bahasa besar.
pos pemeriksaan
Data yang merekam status parameter model baik selama pelatihan atau setelah pelatihan selesai. Misalnya, selama pelatihan, Anda dapat:
- Menghentikan pelatihan, mungkin secara sengaja atau mungkin sebagai akibat dari error tertentu.
- Ambil checkpoint.
- Kemudian, muat ulang titik pemeriksaan, mungkin di hardware yang berbeda.
- Mulai ulang pelatihan.
class
Kategori yang dapat dimiliki oleh label. Contoh:
- Dalam model klasifikasi biner yang mendeteksi spam, dua kelasnya mungkin adalah spam dan bukan spam.
- Dalam model klasifikasi multi-kelas yang mengidentifikasi ras, kelasnya mungkin pudel, beagle, pug, dan sebagainya.
Model klasifikasi memprediksi kelas. Sebaliknya, model regresi memprediksi angka, bukan kelas.
Lihat Klasifikasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
set data seimbang kelas
Set data yang berisi label kategoris yang jumlah instance setiap kategorinya kira-kira sama. Misalnya, pertimbangkan set data botani yang label binernya dapat berupa tanaman asli atau tanaman non-asli:
- Dataset dengan 515 tanaman asli dan 485 tanaman non-asli adalah dataset yang seimbang kelasnya.
- Set data dengan 875 tanaman asli dan 125 tanaman non-asli adalah set data kelas tidak seimbang.
Tidak ada garis pemisah formal antara set data kelas seimbang dan set data kelas tidak seimbang. Perbedaan ini hanya menjadi penting saat model yang dilatih pada set data yang sangat tidak seimbang kelasnya tidak dapat menyatu. Lihat Set data: set data tidak seimbang di Kursus Singkat Machine Learning untuk mengetahui detailnya.
model klasifikasi
Model yang prediksinya adalah class. Misalnya, berikut adalah semua model klasifikasi:
- Model yang memprediksi bahasa kalimat input (Prancis? Spanyol? Italia?).
- Model yang memprediksi spesies pohon (Maple? Oak? Baobab?).
- Model yang memprediksi kelas positif atau negatif untuk kondisi medis tertentu.
Sebaliknya, model regresi memprediksi angka, bukan kelas.
Dua jenis model klasifikasi yang umum adalah:
nilai minimum klasifikasi
Dalam klasifikasi biner, angka antara 0 dan 1 yang mengonversi output mentah model regresi logistik menjadi prediksi kelas positif atau kelas negatif. Perhatikan bahwa nilai minimum klasifikasi adalah nilai yang dipilih oleh manusia, bukan nilai yang dipilih oleh pelatihan model.
Model regresi logistik menghasilkan nilai mentah antara 0 dan 1. Lalu:
- Jika nilai mentah ini lebih besar dari nilai minimum klasifikasi, maka kelas positif diprediksi.
- Jika nilai mentah ini kurang dari nilai minimum klasifikasi, maka kelas negatif diprediksi.
Misalnya, anggap batas klasifikasi adalah 0,8. Jika nilai mentahnya adalah 0,9, model memprediksi kelas positif. Jika nilai mentahnya adalah 0,7, model memprediksi kelas negatif.
Pilihan batas klasifikasi sangat memengaruhi jumlah positif palsu dan negatif palsu.
Lihat Nilai minimum dan matriks kebingungan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
pengklasifikasi
Istilah umum untuk model klasifikasi.
set data kelas tidak seimbang
Set data untuk klasifikasi dengan jumlah total label setiap kelas berbeda secara signifikan. Misalnya, pertimbangkan set data klasifikasi biner yang dua labelnya dibagi sebagai berikut:
- 1.000.000 label negatif
- 10 label positif
Rasio label negatif terhadap positif adalah 100.000 banding 1, jadi ini adalah set data kelas tidak seimbang.
Sebaliknya, set data berikut seimbang menurut kelas karena rasio label negatif terhadap label positif relatif mendekati 1:
- 517 label negatif
- 483 label positif
Set data multikelas juga dapat memiliki kelas yang tidak seimbang. Misalnya, set data klasifikasi multikelas berikut juga tidak seimbang karena satu label memiliki lebih banyak contoh daripada dua label lainnya:
- 1.000.000 label dengan class "hijau"
- 200 label dengan class "ungu"
- 350 label dengan class "orange"
Melatih set data yang tidak seimbang kelasnya dapat menimbulkan tantangan khusus. Lihat Kumpulan data yang tidak seimbang di Kursus Singkat Machine Learning untuk mengetahui detailnya.
Lihat juga entropi, kelas mayoritas, dan kelas minoritas.
kliping
Teknik untuk menangani pencilan dengan melakukan salah satu atau kedua hal berikut:
- Mengurangi nilai fitur yang lebih besar dari nilai maksimum hingga nilai maksimum tersebut.
- Meningkatkan nilai fitur yang kurang dari nilai minimum hingga nilai minimum tersebut.
Misalnya, anggaplah <0,5% nilai untuk fitur tertentu berada di luar rentang 40–60. Dalam hal ini, Anda dapat melakukan hal berikut:
- Klip semua nilai di atas 60 (nilai maksimum) menjadi tepat 60.
- Klip semua nilai di bawah 40 (nilai minimum) menjadi tepat 40.
Pencilan dapat merusak model, terkadang menyebabkan bobot meluap selama pelatihan. Beberapa pencilan juga dapat merusak metrik seperti akurasi secara drastis. Pemangkasan adalah teknik umum untuk membatasi kerusakan.
Pengekangan gradien memaksa nilai gradien dalam rentang yang ditentukan selama pelatihan.
Lihat Data numerik: Normalisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Cloud TPU
Akselerator hardware khusus yang dirancang untuk mempercepat workload machine learning di Google Cloud.
pengelompokan
Mengelompokkan contoh terkait, terutama selama unsupervised learning. Setelah semua contoh dikelompokkan, manusia dapat secara opsional memberikan arti pada setiap kluster.
Banyak algoritma pengelompokan tersedia. Misalnya, algoritma k-means mengelompokkan contoh berdasarkan kedekatannya dengan sentroid, seperti pada diagram berikut:

Kemudian peneliti manusia dapat meninjau kluster dan, misalnya, memberi label kluster 1 sebagai "pohon kerdil" dan kluster 2 sebagai "pohon berukuran normal".
Sebagai contoh lain, pertimbangkan algoritma pengelompokan berdasarkan jarak contoh dari titik tengah, yang diilustrasikan sebagai berikut:

Lihat Kursus pengelompokan untuk mengetahui informasi selengkapnya.
adaptasi bersama
Perilaku yang tidak diinginkan saat neuron memprediksi pola dalam data pelatihan dengan hampir sepenuhnya mengandalkan keluaran neuron spesifik lain, bukannya mengandalkan perilaku jaringan secara keseluruhan. Jika pola yang menyebabkan adaptasi bersama tidak ada dalam data validasi, adaptasi bersama akan menyebabkan overfitting. Regularisasi dengan pelolosan mengurangi adaptasi bersama karena pelolosan memastikan bahwa neuron tidak dapat sepenuhnya mengandalkan neuron spesifik lain.
pemfilteran kolaboratif
Membuat prediksi tentang minat satu pengguna berdasarkan minat banyak pengguna lain. Pemfilteran kolaboratif sering digunakan dalam sistem rekomendasi.
Lihat Pemfilteran kolaboratif di kursus Sistem Rekomendasi untuk mengetahui informasi selengkapnya.
model ringkas
Model kecil apa pun yang dirancang untuk berjalan di perangkat kecil dengan resource komputasi terbatas. Misalnya, model ringkas dapat berjalan di ponsel, tablet, atau sistem sematan.
compute
(Kata benda) Resource komputasi yang digunakan oleh model atau sistem, seperti daya pemrosesan, memori, dan penyimpanan.
Lihat chip akselerator.
penyimpangan konsep
Perubahan hubungan antara fitur dan label. Seiring waktu, penyimpangan konsep akan mengurangi kualitas model.
Selama pelatihan, model mempelajari hubungan antara fitur dan labelnya dalam set pelatihan. Jika label dalam set pelatihan adalah proksi yang baik untuk dunia nyata, maka model seharusnya membuat prediksi dunia nyata yang baik. Namun, karena penyimpangan konsep, prediksi model cenderung menurun seiring waktu.
Misalnya, pertimbangkan model klasifikasi biner yang memprediksi apakah model mobil tertentu "hemat bahan bakar" atau tidak. Artinya, fitur tersebut dapat berupa:
- berat mobil
- kompresi mesin
- jenis transmisi
sementara labelnya adalah:
- hemat bahan bakar
- tidak hemat bahan bakar
Namun, konsep "mobil hemat bahan bakar" terus berubah. Model mobil yang diberi label hemat bahan bakar pada tahun 1994 hampir pasti akan diberi label tidak hemat bahan bakar pada tahun 2024. Model yang mengalami pergeseran konsep cenderung membuat prediksi yang semakin tidak berguna seiring waktu.
Bandingkan dan bedakan dengan nonstasioneritas.
kondisi
Dalam pohon keputusan, setiap node yang melakukan pengujian. Misalnya, pohon keputusan berikut berisi dua kondisi:
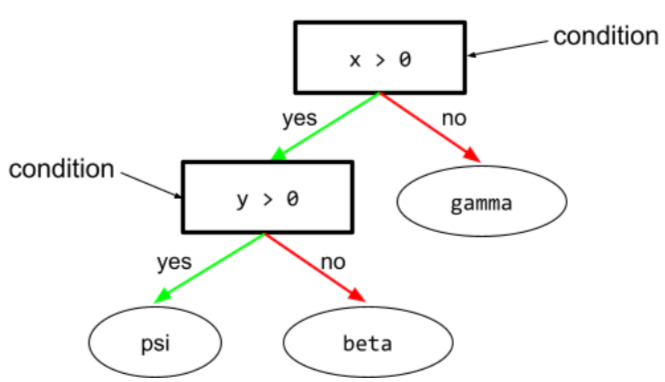
Kondisi juga disebut pemisahan atau pengujian.
Kondisi kontras dengan daun.
Lihat juga:
Lihat Jenis kondisi dalam kursus Decision Forests untuk mengetahui informasi selengkapnya.
konfabulasi
Sinonim untuk halusinasi.
Konfabulasi mungkin merupakan istilah yang lebih akurat secara teknis daripada halusinasi. Namun, halusinasi menjadi populer terlebih dahulu.
konfigurasi
Proses penetapan nilai properti awal yang digunakan untuk melatih model, termasuk:
- lapisan penyusun model
- lokasi data
- hyperparameter seperti:
Dalam project machine learning, konfigurasi dapat dilakukan melalui file konfigurasi khusus atau menggunakan library konfigurasi seperti berikut:
bias konfirmasi
Kecenderungan untuk mencari, menafsirkan, menyukai, dan mengingat informasi dengan cara yang mengonfirmasi keyakinan atau hipotesis yang sudah ada sebelumnya. Developer machine learning mungkin secara tidak sengaja mengumpulkan atau melabeli data dengan cara yang memengaruhi hasil yang mendukung keyakinan mereka yang sudah ada. Bias konfirmasi adalah bentuk bias implisit.
Bias pelaku eksperimen adalah bentuk bias konfirmasi di mana seorang pelaku eksperimen terus melatih model hingga hipotesis yang sudah ada sebelumnya terkonfirmasi.
matriks konfusi
Tabel NxN yang merangkum jumlah prediksi benar dan salah yang dibuat oleh model klasifikasi. Misalnya, perhatikan matriks kebingungan berikut untuk model klasifikasi biner:
| Tumor (diprediksi) | Non-Tumor (prediksi) | |
|---|---|---|
| Tumor (kebenaran nyata) | 18 (TP) | 1 (FN) |
| Non-Tumor (kebenaran nyata) | 6 (FP) | 452 (TN) |
Matriks konfusi sebelumnya menunjukkan hal berikut:
- Dari 19 prediksi yang kebenaran nyatanya adalah Tumor, model mengklasifikasikan 18 dengan benar dan 1 dengan salah.
- Dari 458 prediksi yang kebenaran nyatanya adalah Non-Tumor, model mengklasifikasikan 452 dengan benar dan 6 dengan salah.
Matriks kebingungan untuk masalah klasifikasi multi-kelas dapat membantu Anda mengidentifikasi pola kesalahan. Misalnya, pertimbangkan matriks kebingungan berikut untuk model klasifikasi multikelas 3 kelas yang mengategorikan tiga jenis iris yang berbeda (Virginica, Versicolor, dan Setosa). Jika kebenaran dasarnya adalah Virginica, matriks kebingungan menunjukkan bahwa model jauh lebih mungkin keliru memprediksi Versicolor daripada Setosa:
| Setosa (prediksi) | Versicolor (prediksi) | Virginica (diprediksi) | |
|---|---|---|---|
| Setosa (kebenaran dasar) | 88 | 12 | 0 |
| Versicolor (kebenaran nyata) | 6 | 141 | 7 |
| Virginica (kebenaran dasar) | 2 | 27 | 109 |
Sebagai contoh lain, matriks konfusi dapat mengungkapkan bahwa model yang dilatih untuk mengenali digit tulisan tangan cenderung salah memprediksi 9 bukannya 4, atau salah memprediksi 1 bukannya 7.
Matriks kebingungan berisi informasi yang cukup untuk menghitung berbagai metrik performa, termasuk presisi dan perolehan.
penguraian konstituensi
Membagi kalimat menjadi struktur tata bahasa yang lebih kecil ("konstituen"). Bagian selanjutnya dari sistem ML, seperti model natural language understanding, dapat mengurai konstituen dengan lebih mudah daripada kalimat aslinya. Misalnya, pertimbangkan kalimat berikut:
Teman saya mengadopsi dua kucing.
Parser konstituen dapat membagi kalimat ini menjadi dua konstituen berikut:
- Teman saya adalah frasa nomina.
- mengadopsi dua kucing adalah frasa kata kerja.
Konstituen ini dapat dibagi lagi menjadi konstituen yang lebih kecil. Misalnya, frasa verba
mengadopsi dua kucing
dapat dibagi lagi menjadi:
- mengadopsi adalah kata kerja.
- dua kucing adalah frasa nomina lainnya.
embedding bahasa yang dikontekstualisasi
Embedding yang mendekati "pemahaman" kata dan frasa seperti yang dilakukan penutur manusia yang fasih. Penyematan bahasa yang dikontekstualisasi dapat memahami sintaksis, semantik, dan konteks yang kompleks.
Misalnya, pertimbangkan sematan kata cow dalam bahasa Inggris. Embedding lama seperti word2vec dapat merepresentasikan kata-kata bahasa Inggris sehingga jarak dalam ruang embedding dari cow ke bull mirip dengan jarak dari ewe (domba betina) ke ram (domba jantan) atau dari female ke male. Penyematan bahasa yang dikontekstualisasi dapat melangkah lebih jauh dengan mengenali bahwa penutur bahasa Inggris terkadang menggunakan kata cow secara kasual untuk berarti sapi betina atau sapi jantan.
jendela konteks
Jumlah token yang dapat diproses model dalam perintah tertentu. Makin besar jendela konteks, makin banyak informasi yang dapat digunakan model untuk memberikan respons yang koheren dan konsisten terhadap perintah.
fitur berkelanjutan
Fitur floating point dengan rentang nilai yang mungkin tak terbatas, seperti suhu atau berat.
Berbeda dengan fitur diskrit.
sampling praktis
Menggunakan set data yang tidak dikumpulkan secara ilmiah untuk menjalankan eksperimen sederhana dalam waktu singkat. Pada tahapan eksperimen yang lebih dalam, gunakanlah set data yang dikumpulkan secara ilmiah.
konvergensi
Status yang dicapai saat nilai kerugian sedikit berubah atau tidak berubah sama sekali dengan setiap iterasi. Misalnya, kurva kerugian berikut menunjukkan konvergensi pada sekitar 700 iterasi:
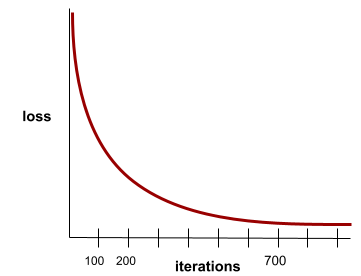
Model berkonvergensi saat pelatihan tambahan tidak akan meningkatkan kualitas model.
Dalam deep learning, nilai kerugian terkadang tetap konstan atau hampir konstan selama banyak iterasi sebelum akhirnya menurun. Selama periode panjang nilai kerugian yang konstan, Anda mungkin untuk sementara mendapatkan rasa konvergensi yang salah.
Lihat juga penghentian awal.
Lihat Konvergensi model dan kurva kerugian di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
pengodean percakapan
Dialog iteratif antara Anda dan model AI generatif untuk tujuan pembuatan software. Anda memberikan perintah yang mendeskripsikan beberapa software. Kemudian, model menggunakan deskripsi tersebut untuk membuat kode. Kemudian, Anda mengeluarkan perintah baru untuk mengatasi kekurangan dalam perintah sebelumnya atau dalam kode yang dibuat, dan model akan membuat kode yang diperbarui. Anda berdua terus bolak-balik hingga software yang dihasilkan cukup baik.
Pengodean percakapan pada dasarnya adalah makna asli dari pengodean suasana.
Berbeda dengan pengodean spesifikasi.
fungsi konveks
Fungsi yang mana daerah di atas grafik fungsi adalah himpunan konveks. Fungsi konveks prototipe berbentuk seperti huruf U. Misalnya, fungsi berikut adalah fungsi konveks:
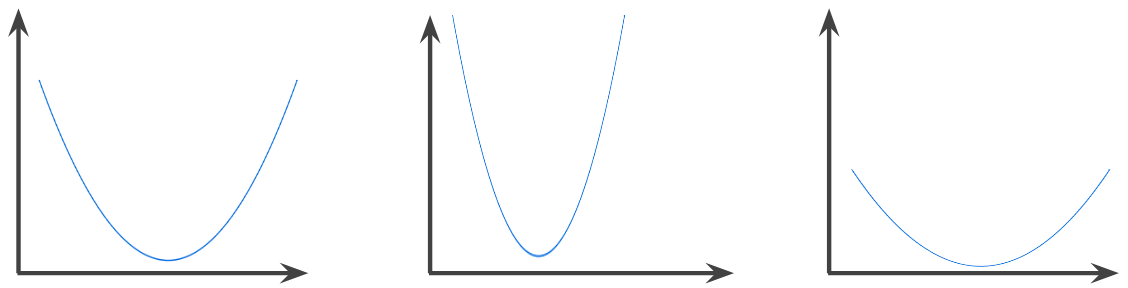
Sebaliknya, fungsi berikut tidak cembung. Perhatikan bagaimana area di atas grafik bukanlah himpunan cembung:

Fungsi konveks tegas memiliki tepat satu titik minimum lokal, yang juga merupakan titik minimum global. Fungsi berbentuk U klasik adalah fungsi konveks tegas. Namun, beberapa fungsi konveks (misalnya, garis lurus) tidak berbentuk U.
Lihat Konvergensi dan fungsi cembung di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
pengoptimalan konveks
Proses penggunaan teknik matematika seperti penurunan gradien untuk menemukan nilai minimum fungsi konveks. Banyak riset dalam machine learning telah berfokus pada perumusan berbagai masalah sebagai masalah pengoptimalan konveks dan dalam pemecahan masalah tersebut secara lebih efisien.
Untuk mengetahui detail selengkapnya, lihat Boyd dan Vandenberghe, Convex Optimization.
himpunan konveks
Subkumpulan ruang Euklidean sehingga garis yang ditarik antara dua titik mana pun dalam subkumpulan tetap sepenuhnya berada dalam subkumpulan. Misalnya, dua bentuk berikut adalah himpunan cembung:

Sebaliknya, dua bentuk berikut bukan himpunan cembung:

konvolusi
Dalam matematika, secara kasual, campuran dari dua fungsi. Dalam machine learning, konvolusi mencampur saringan konvolusional dan matriks masukan untuk melatih bobot.
Istilah "konvolusi" dalam machine learning sering kali merupakan cara singkat untuk merujuk ke operasi konvolusional atau lapisan konvolusional.
Tanpa konvolusi, algoritma machine learning harus mempelajari bobot terpisah untuk setiap sel dalam tensor besar. Misalnya, algoritma machine learning yang dilatih pada gambar 2K x 2K akan dipaksa untuk menemukan 4 juta bobot terpisah. Berkat konvolusi, algoritma machine learning hanya harus menemukan bobot untuk setiap sel dalam saringan konvolusional, yang secara drastis mengurangi memori yang diperlukan untuk melatih model. Saat filter konvolusional diterapkan, filter tersebut direplikasi di seluruh sel sehingga setiap sel dikalikan dengan filter.
Lihat Pengenalan Jaringan Neural Konvolusional di kursus Klasifikasi Gambar untuk mengetahui informasi selengkapnya.
filter konvolusional
Salah satu dari dua komponen dalam operasi konvolusional. (Aktor lainnya adalah slice matriks input.) Filter konvolusional adalah matriks yang memiliki urutan yang sama dengan matriks input, tetapi bentuknya lebih kecil. Misalnya, dengan matriks input 28x28, filter dapat berupa matriks 2D yang lebih kecil dari 28x28.
Dalam manipulasi fotografi, semua sel dalam filter konvolusional biasanya ditetapkan ke pola konstanta satu dan nol. Dalam machine learning, filter konvolusional biasanya diisi dengan angka acak, lalu jaringan melatih nilai yang ideal.
Lihat Konvolusi dalam kursus Klasifikasi Gambar untuk mengetahui informasi selengkapnya.
lapisan konvolusional
Lapisan jaringan neural dalam yang mana saringan konvolusional diteruskan di semua matriks masukan. Misalnya, pertimbangkan saringan konvolusional 3x3 berikut:
![Matriks 3x3 dengan nilai berikut: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?hl=id)
Animasi berikut menunjukkan lapisan konvolusional yang terdiri dari 9 operasi konvolusional yang melibatkan matriks input 5x5. Perhatikan bahwa setiap operasi konvolusional bekerja pada potongan matriks input 3x3 yang berbeda. Matriks 3x3 yang dihasilkan (di sebelah kanan) terdiri dari hasil 9 operasi konvolusional:
![Animasi yang menampilkan dua matriks. Matriks pertama adalah matriks 5x5: [[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
Matriks kedua adalah matriks 3x3:
[[181,303,618], [115,338,605], [169,351,560]].
Matriks kedua dihitung dengan menerapkan filter konvolusional
[[0, 1, 0], [1, 0, 1], [0, 1, 0]] di berbagai
subset matriks 5x5 3x3.](https://developers.google.com/static/machine-learning/glossary/images/AnimatedConvolution.gif?hl=id)
Lihat Lapisan yang Terhubung Sepenuhnya di kursus Klasifikasi Gambar untuk mengetahui informasi selengkapnya.
jaringan neural konvolusional
Jaringan neural yang setidaknya memiliki satu lapisan konvolusional. Jaringan neural konvolusional standar terdiri dari beberapa kombinasi lapisan berikut:
Jaringan neural konvolusional telah berhasil memecahkan masalah tertentu, seperti pengenalan gambar.
operasi konvolusional
Operasi matematika dua langkah berikut:
- Perkalian berbasis elemen dari saringan konvolusional dan potongan dari matriks masukan. (Potongan matriks input memiliki urutan dan ukuran yang sama dengan filter konvolusional.)
- Penjumlahan semua nilai dalam matriks produk yang dihasilkan.
Misalnya, perhatikan matriks input 5x5 berikut:
![Matriks 5x5: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?hl=id)
Sekarang bayangkan filter konvolusional 2x2 berikut:
![Matriks 2x2: [[1, 0], [0, 1]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?hl=id)
Setiap operasi konvolusional melibatkan satu potongan 2x2 dari matriks input. Misalnya, kita menggunakan slice 2x2 di kiri atas matriks input. Jadi, operasi konvolusi pada slice ini akan terlihat seperti berikut:
![Menerapkan filter konvolusional [[1, 0], [0, 1]] ke bagian 2x2 kiri atas matriks input, yaitu [[128,97], [35,22]].
Filter konvolusional membiarkan 128 dan 22 tetap utuh, tetapi
mengatur 97 dan 35 menjadi nol. Oleh karena itu, operasi konvolusi menghasilkan
nilai 150 (128+22).](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?hl=id)
Lapisan konvolusional terdiri dari serangkaian operasi konvolusional, masing-masing bekerja pada potongan matriks masukan yang berbeda.
biaya
Sinonim untuk loss.
pelatihan bersama
Pendekatan semi-supervised learning sangat berguna jika semua kondisi berikut terpenuhi:
- Rasio contoh tak berlabel terhadap contoh berlabel dalam set data tinggi.
- Ini adalah masalah klasifikasi (biner atau multi-kelas).
- Set data berisi dua set fitur prediktif berbeda yang independen dan saling melengkapi.
Pada dasarnya, pelatihan bersama memperkuat sinyal independen menjadi sinyal yang lebih kuat. Misalnya, pertimbangkan model klasifikasi yang mengategorikan setiap mobil bekas sebagai Baik atau Buruk. Satu set fitur prediksi dapat berfokus pada karakteristik gabungan seperti tahun, merek, dan model mobil; set fitur prediksi lainnya dapat berfokus pada catatan mengemudi pemilik sebelumnya dan riwayat perawatan mobil.
Makalah penting tentang pelatihan bersama adalah Combining Labeled and Unlabeled Data with Co-Training oleh Blum dan Mitchell.
keadilan kontrafaktual
Metrik keadilan yang memeriksa apakah model klasifikasi menghasilkan hasil yang sama untuk satu individu dengan individu lain yang identik dengan individu pertama, kecuali sehubungan dengan satu atau beberapa atribut sensitif. Mengevaluasi model klasifikasi untuk keadilan kontrafaktual adalah salah satu metode untuk menemukan potensi sumber bias dalam model.
Lihat salah satu informasi berikut untuk mengetahui informasi selengkapnya:
- Keadilan: Keadilan kontrafaktual dalam Kursus Singkat Machine Learning.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness
bias cakupan
Lihat bias seleksi.
frasa ambigu
Kalimat atau frasa dengan makna ambigu. Frasa ambigu menghadirkan masalah yang signifikan dalam natural language understanding. Misalnya, judul Red Tape Holds Up Skyscraper adalah frasa ambigu karena model NLU dapat menafsirkan judul secara harfiah atau kiasan.
kritikus
Sinonim untuk Deep Q-Network.
entropi silang
Generalisasi Log Loss ke masalah klasifikasi multikelas. Cross-entropy mengukur perbedaan antara dua distribusi probabilitas. Lihat juga perpleksitas.
validasi silang
Mekanisme untuk memperkirakan seberapa baik model akan digeneralisasi ke data baru dengan menguji model terhadap satu atau beberapa subset data yang tidak tumpang-tindih yang tidak disertakan dari set pelatihan.
fungsi distribusi kumulatif (CDF)
Fungsi yang menentukan frekuensi sampel yang kurang dari atau sama dengan nilai target. Misalnya, pertimbangkan distribusi normal nilai berkelanjutan. CDF memberi tahu Anda bahwa sekitar 50% sampel harus kurang dari atau sama dengan rata-rata dan sekitar 84% sampel harus kurang dari atau sama dengan satu standar deviasi di atas rata-rata.
D
analisis data
Memperoleh pemahaman data dengan mempertimbangkan sampel, pengukuran, dan visualisasi. Analisis data dapat sangat berguna saat pertama kali set data diterima, sebelum membuat model yang pertama. Analisis data juga penting dalam memahami masalah eksperimen dan proses debug dengan sistem.
pengayaan data
Meningkatkan rentang dan jumlah contoh pelatihan secara artifisial dengan mengubah contoh yang ada untuk membuat contoh tambahan. Misalnya, anggaplah gambar adalah salah satu fitur Anda, tetapi set data Anda tidak berisi contoh gambar yang memadai bagi model untuk mempelajari asosiasi yang berguna. Idealnya, Anda akan menambahkan gambar berlabel yang memadai ke set data Anda agar model Anda dapat dilatih dengan benar. Jika tindakan tersebut tidak memungkinkan, pengayaan data dapat memutar, melebarkan, dan mencerminkan setiap gambar untuk memproduksi berbagai variasi dari gambar aslinya, yang mungkin menghasilkan data berlabel yang memadai agar dapat melakukan pelatihan yang sangat baik.
DataFrame
Jenis data pandas yang populer untuk merepresentasikan set data dalam memori.
DataFrame dapat dianalogikan dengan tabel atau spreadsheet. Setiap kolom DataFrame memiliki nama (header), dan setiap baris diidentifikasi oleh angka unik.
Setiap kolom dalam DataFrame disusun seperti array 2D, kecuali setiap kolom dapat diberi jenis datanya sendiri.
Lihat juga halaman referensi pandas.DataFrame resmi.
paralelisme data
Cara menskalakan pelatihan atau inferensi yang mereplikasi seluruh model ke beberapa perangkat, lalu meneruskan subset data input ke setiap perangkat. Paralelisme data dapat memungkinkan pelatihan dan inferensi pada ukuran batch yang sangat besar; namun, paralelisme data mengharuskan model cukup kecil agar dapat dimuat di semua perangkat.
Paralelisme data biasanya mempercepat pelatihan dan inferensi.
Lihat juga paralelisme model.
Dataset API (tf.data)
API TensorFlow tingkat tinggi untuk membaca data dan
mengubahnya menjadi bentuk yang diperlukan algoritma machine learning.
Objek tf.data.Dataset merepresentasikan urutan elemen, yang mana
setiap elemen berisi satu atau beberapa Tensor. Objek tf.data.Iterator
memberikan akses ke elemen Dataset.
kumpulan data atau set data (data set atau dataset)
Kumpulan data mentah, biasanya (tetapi tidak secara eksklusif) disusun dalam salah satu format berikut:
- spreadsheet
- file dalam format CSV (nilai yang dipisahkan koma)
batas keputusan
Pemisah antara kelas yang dipelajari oleh model dalam masalah klasifikasi biner atau klasifikasi multikelas. Misalnya, dalam gambar berikut yang merepresentasikan masalah klasifikasi biner, batas keputusannya adalah perbatasan antara kelas berwarna oranye dan kelas berwarna biru:

hutan keputusan
Model yang dibuat dari beberapa pohon keputusan. Hutan keputusan membuat prediksi dengan menggabungkan prediksi pohon keputusannya. Jenis hutan keputusan yang populer mencakup hutan acak dan pohon penguatan gradien.
Lihat bagian Decision Forests dalam kursus Decision Forests untuk mengetahui informasi selengkapnya.
nilai minimum keputusan
Sinonim untuk batas klasifikasi.
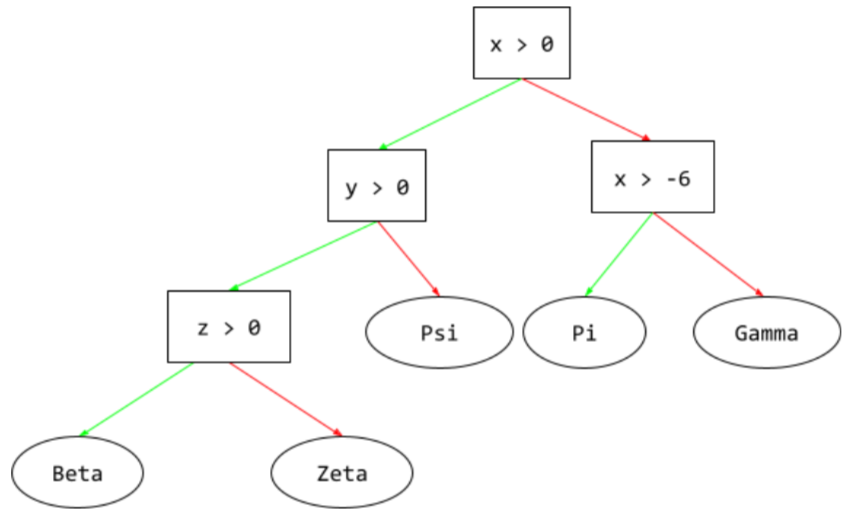
pohon keputusan
Model pembelajaran terawasi yang terdiri dari serangkaian kondisi dan daun yang disusun secara hierarkis. Misalnya, berikut adalah pohon keputusan:
decoder
Secara umum, sistem ML apa pun yang mengonversi dari representasi yang diproses, padat, atau internal ke representasi yang lebih mentah, jarang, atau eksternal.
Decoder sering kali menjadi komponen dari model yang lebih besar, yang sering kali dipasangkan dengan encoder.
Dalam tugas sequence-to-sequence, decoder dimulai dengan status internal yang dihasilkan oleh encoder untuk memprediksi urutan berikutnya.
Lihat Transformer untuk mengetahui definisi decoder dalam arsitektur Transformer.
Lihat Model bahasa yang besar di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
deep model
Jaringan neural yang berisi lebih dari satu lapisan tersembunyi.
Model dalam juga disebut deep neural network.
Berbeda dengan model lebar.
yang sangat populer
Sinonim untuk model dalam.
Deep Q-Network (DQN)
Dalam Q-learning, jaringan neural deep learning yang memprediksi Q-function.
Critic adalah sinonim untuk Deep Q-Network.
paritas demografis
Metrik keadilan yang terpenuhi jika hasil klasifikasi model tidak bergantung pada atribut sensitif tertentu.
Misalnya, jika orang Lilliput dan Brobdingnag mendaftar ke Universitas Glubbdubdrib, paritas demografi tercapai jika persentase orang Lilliput yang diterima sama dengan persentase orang Brobdingnag yang diterima, terlepas dari apakah satu kelompok rata-rata lebih memenuhi syarat daripada kelompok lainnya.
Berbeda dengan peluang yang sama dan kesetaraan peluang, yang memungkinkan hasil klasifikasi secara keseluruhan bergantung pada atribut sensitif, tetapi tidak memungkinkan hasil klasifikasi untuk label kebenaran nyata tertentu yang ditentukan bergantung pada atribut sensitif. Lihat "Menangkal diskriminasi dengan machine learning yang lebih cerdas" untuk visualisasi yang mengeksplorasi pertukaran saat mengoptimalkan kesetaraan demografis.
Lihat Keadilan: kesetaraan demografis di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
pengurangan noise
Pendekatan umum untuk self-supervised learning yang:
Proses menghilangkan derau memungkinkan pembelajaran dari contoh tanpa label. Set data asli berfungsi sebagai target atau label dan data yang tidak relevan sebagai input.
Beberapa model bahasa yang disamarkan menggunakan penghilangan derau sebagai berikut:
- Derau ditambahkan secara buatan ke kalimat yang tidak berlabel dengan menyamarkan beberapa token.
- Model mencoba memprediksi token asli.
fitur padat
Fitur yang sebagian besar atau semua nilainya bukan nol, biasanya Tensor nilai floating point. Misalnya, Tensor 10 elemen berikut bersifat padat karena 9 nilainya bukan nol:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Berbeda dengan fitur renggang.
lapisan padat
Sinonim untuk lapisan terhubung sepenuhnya.
kedalaman
Jumlah berikut dalam jaringan neural:
- jumlah lapisan tersembunyi
- jumlah lapisan output, yang biasanya 1
- jumlah lapisan penyematan
Misalnya, jaringan neural dengan lima lapisan tersembunyi dan satu lapisan keluaran memiliki kedalaman 6.
Perhatikan bahwa lapisan input tidak memengaruhi kedalaman.
jaringan neural konvolusional yang dapat dipisahkan menurut kedalaman (sepCNN)
Arsitektur jaringan neural konvolusional berdasarkan Inception, tetapi modul Inception diganti dengan konvolusi yang dapat dipisahkan menurut kedalaman. Juga dikenal sebagai Xception.
Konvolusi yang dapat dipisahkan per kedalaman (juga disingkat sebagai konvolusi yang dapat dipisahkan) memfaktorkan konvolusi 3D standar menjadi dua operasi konvolusi terpisah yang lebih efisien secara komputasi: pertama, konvolusi per kedalaman, dengan kedalaman 1 (n ✕ n ✕ 1), dan kemudian, konvolusi pointwise, dengan panjang dan lebar 1 (1 ✕ 1 ✕ n).
Untuk mempelajari lebih lanjut, lihat Xception: Deep Learning with Depthwise Separable Convolutions.
label turunan
Sinonim untuk label proxy.
perangkat
Istilah yang memiliki lebih dari satu definisi dengan dua kemungkinan definisi berikut:
- Kategori hardware yang dapat menjalankan sesi TensorFlow, yang meliputi CPU, GPU, dan TPU.
- Saat melatih model ML di chip akselerator (GPU atau TPU), bagian sistem yang benar-benar memanipulasi tensor dan embedding. Perangkat berjalan di chip akselerator. Sebaliknya, host biasanya berjalan di CPU.
privasi diferensial
Dalam machine learning, pendekatan anonimisasi untuk melindungi data sensitif apa pun (misalnya, informasi pribadi seseorang) yang disertakan dalam set pelatihan model agar tidak terekspos. Pendekatan ini memastikan bahwa model tidak mempelajari atau mengingat banyak hal tentang individu tertentu. Hal ini dilakukan dengan mengambil sampel dan menambahkan derau selama pelatihan model untuk mengaburkan titik data individual, sehingga mengurangi risiko tereksposnya data pelatihan sensitif.
Privasi diferensial juga digunakan di luar machine learning. Misalnya, ilmuwan data terkadang menggunakan privasi diferensial untuk melindungi privasi individu saat menghitung statistik penggunaan produk untuk berbagai demografi.
pengurangan dimensi
Menurunkan jumlah dimensi yang digunakan untuk merepresentasikan fitur tertentu dalam vektor fitur, biasanya dengan melakukan konversi menjadi vektor embedding.
dimensi
Istilah yang memiliki lebih dari satu definisi:
Jumlah tingkat koordinat dalam Tensor. Contoh:
- Skalar memiliki nol dimensi; misalnya,
["Hello"]. - Vektor memiliki satu dimensi; misalnya,
[3, 5, 7, 11]. - Matriks memiliki dua dimensi; misalnya,
[[2, 4, 18], [5, 7, 14]]. Anda dapat secara unik menetapkan sel tertentu dalam vektor satu dimensi dengan satu koordinat; Anda memerlukan dua koordinat untuk secara unik menetapkan sebuah sel dalam matriks dua dimensi.
- Skalar memiliki nol dimensi; misalnya,
Jumlah entri dalam vektor fitur.
Jumlah elemen dalam lapisan penyematan.
perintah langsung
Sinonim untuk zero-shot prompting.
fitur diskret
Fitur dengan set kemungkinan nilai yang terbatas. Misalnya, fitur yang nilainya hanya dapat berupa hewan, sayuran, atau mineral adalah fitur diskrit (atau kategoris).
Berbeda dengan fitur berkelanjutan.
model diskriminatif
Model yang memprediksi label dari serangkaian fitur. Secara lebih formal, model diskriminatif menentukan probabilitas bersyarat output yang diberikan fitur dan bobot; yaitu:
p(output | features, weights)
Misalnya, model yang memprediksi apakah email adalah spam dari fitur dan bobot adalah model diskriminatif.
Sebagian besar model supervised learning, termasuk model klasifikasi dan regresi, adalah model diskriminatif.
Berbeda dengan model generatif.
diskriminator
Sistem yang menentukan apakah contoh itu nyata atau palsu.
Atau, subsistem dalam jaringan adversarial generatif yang menentukan apakah contoh yang dibuat oleh generator itu nyata atau palsu.
Lihat Diskriminator dalam kursus GAN untuk mengetahui informasi selengkapnya.
dampak yang tidak seimbang
Membuat keputusan tentang orang-orang yang berdampak tidak proporsional pada subgrup populasi yang berbeda. Hal ini biasanya merujuk pada situasi ketika proses pengambilan keputusan algoritmik merugikan atau menguntungkan beberapa subgrup lebih dari subgrup lainnya.
Misalnya, algoritma yang menentukan kelayakan seorang Lilliput untuk mendapatkan pinjaman rumah miniatur lebih cenderung mengklasifikasikannya sebagai "tidak memenuhi syarat" jika alamat suratnya berisi kode pos tertentu. Jika Liliput Big-Endian lebih cenderung memiliki alamat surat dengan kode pos ini daripada Liliput Little-Endian, maka algoritma ini dapat menimbulkan dampak yang tidak setara.
Berbeda dengan perlakuan tidak setara, yang berfokus pada perbedaan yang terjadi saat karakteristik subgrup menjadi input eksplisit untuk proses pengambilan keputusan algoritma.
perlakuan yang berbeda
Memasukkan atribut sensitif subjek ke dalam proses pengambilan keputusan algoritma sehingga subgrup orang yang berbeda diperlakukan secara berbeda.
Misalnya, pertimbangkan algoritma yang menentukan kelayakan orang Lilliput untuk mendapatkan pinjaman rumah mini berdasarkan data yang mereka berikan dalam permohonan pinjaman. Jika algoritma menggunakan afiliasi Lilliputian sebagai Big-Endian atau Little-Endian sebagai input, algoritma tersebut menerapkan perlakuan berbeda di sepanjang dimensi tersebut.
Berbeda dengan dampak tidak setara, yang berfokus pada perbedaan dalam dampak sosial keputusan algoritmik pada subgrup, terlepas dari apakah subgrup tersebut merupakan input ke model atau tidak.
distilasi
Proses mengurangi ukuran satu model (dikenal sebagai pengajar) menjadi model yang lebih kecil (dikenal sebagai siswa) yang meniru prediksi model asli seakurat mungkin. Distilasi berguna karena model yang lebih kecil memiliki dua manfaat utama dibandingkan model yang lebih besar (pengajar):
- Waktu inferensi yang lebih cepat
- Mengurangi penggunaan memori dan energi
Namun, prediksi siswa biasanya tidak sebaik prediksi pengajar.
Distilasi melatih model siswa untuk meminimalkan fungsi loss berdasarkan perbedaan antara output prediksi model siswa dan model pengajar.
Bandingkan dan bedakan distilasi dengan istilah berikut:
Lihat LLM: Penyesuaian, distilasi, dan teknik perintah di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
distribusi
Frekuensi dan rentang nilai yang berbeda untuk fitur atau label tertentu. Distribusi menunjukkan seberapa besar kemungkinan suatu nilai tertentu.
Gambar berikut menunjukkan histogram dari dua distribusi yang berbeda:
- Di sebelah kiri, distribusi hukum pangkat kekayaan versus jumlah orang yang memiliki kekayaan tersebut.
- Di sebelah kanan, distribusi normal tinggi versus jumlah orang yang memiliki tinggi tersebut.
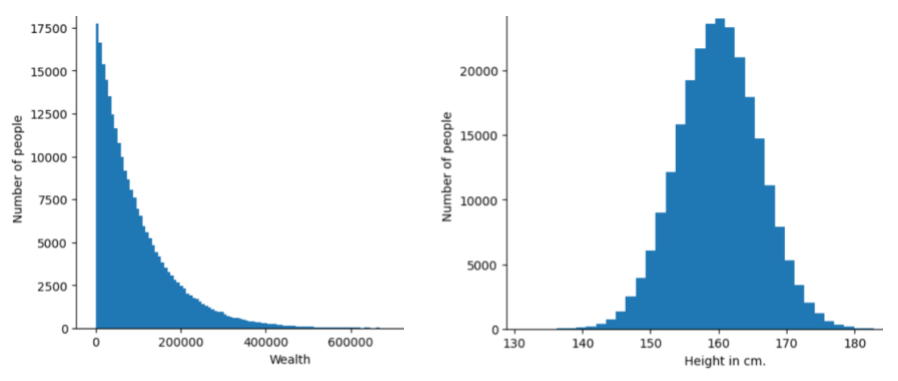
Memahami distribusi setiap fitur dan label dapat membantu Anda menentukan cara menormalisasi nilai dan mendeteksi pencilan.
Frasa di luar distribusi mengacu pada nilai yang tidak muncul dalam set data atau sangat jarang. Misalnya, gambar planet Saturnus akan dianggap di luar distribusi untuk set data yang terdiri dari gambar kucing.
pengelompokan divisif
Lihat pengelompokan hierarkis.
penurunan/pengurangan sampel
Istilah yang memiliki lebih dari satu makna:
- Mengurangi jumlah informasi dalam fitur untuk melatih model secara lebih efisien. Misalnya, sebelum melatih model pengenalan gambar, lakukan downsampling pada gambar beresolusi tinggi ke format beresolusi lebih rendah.
- Melatih contoh kelas yang terlalu banyak direpresentasikan dengan persentase rendah dan tidak proporsional untuk meningkatkan pelatihan model pada kelas yang kurang direpresentasikan. Misalnya, dalam dataset tidak seimbang kelas, model cenderung mempelajari banyak hal tentang kelas mayoritas dan tidak cukup tentang kelas minoritas. Penurunan/pengurangan sampel membantu menyeimbangkan jumlah pelatihan pada kelas mayoritas dan minoritas.
Lihat Set data: Set data tidak seimbang di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
DQN
Singkatan dari Deep Q-Network.
regularisasi dengan pelolosan
Bentuk regularisasi yang berguna dalam melatih jaringan neural. Regularisasi dengan pelolosan menghapus pilihan acak dari unit yang berjumlah tetap dalam lapisan jaringan untuk satu langkah gradien. Makin banyak unit yang dihilangkan, makin kuat regularisasinya. Hal ini dianalogikan dengan melatih jaringan untuk mengemulasi ansambel jaringan yang lebih kecil dalam jumlah eksponensial. Untuk mengetahui detail selengkapnya, lihat Pelolosan: Cara Sederhana untuk Mencegah Overfitting pada Jaringan Neural.
dinamis
Sesuatu yang dilakukan secara sering atau terus-menerus. Istilah dinamis dan online merupakan sinonim dalam machine learning. Berikut adalah penggunaan umum dinamis dan online dalam machine learning:
- Model dinamis (atau model online) adalah model yang dilatih ulang secara sering atau terus-menerus.
- Pelatihan dinamis (atau pelatihan online) adalah proses pelatihan yang dilakukan secara sering atau terus-menerus.
- Inferensi dinamis (atau inferensi online) adalah proses membuat prediksi sesuai permintaan.
model dinamis
Model yang sering (bahkan terus-menerus) dilatih ulang. Model dinamis adalah "pembelajar seumur hidup" yang terus beradaptasi dengan data yang terus berkembang. Model dinamis juga dikenal sebagai model online.
Berbeda dengan model statis.
E
eksekusi segera
Lingkungan pemrograman TensorFlow yang mana operasi dijalankan secara langsung. Sebaliknya, operasi yang disebut dengan eksekusi grafik tidak akan dijalankan sampai dievaluasi secara eksplisit. Eksekusi segera adalah antarmuka imperatif, seperti kode dalam sebagian besar bahasa pemrograman. Program eksekusi segera umumnya jauh lebih mudah untuk dilakukan debug daripada program eksekusi grafik.
penghentian awal
Metode regularisasi yang melibatkan pengakhiran pelatihan sebelum kerugian pelatihan selesai menurun. Dalam penghentian awal, Anda sengaja menghentikan pelatihan model saat kerugian pada set data validasi mulai meningkat; yaitu, saat performa generalisasi memburuk.
Berbeda dengan keluar lebih awal.
jarak penggerak bumi (EMD)
Ukuran kesamaan relatif dari dua distribusi. Makin rendah jarak penggerak tanah, makin mirip distribusinya.
jarak pengeditan
Pengukuran seberapa mirip dua string teks satu sama lain. Dalam machine learning, jarak edit berguna karena alasan berikut:
- Jarak pengeditan mudah dihitung.
- Jarak edit dapat membandingkan dua string yang diketahui serupa satu sama lain.
- Jarak pengeditan dapat menentukan tingkat kesamaan string yang berbeda dengan string tertentu.
Ada beberapa definisi jarak pengeditan, yang masing-masing menggunakan operasi string yang berbeda. Lihat Jarak Levenshtein untuk melihat contohnya.
Notasi Einsum
Notasi yang efisien untuk menjelaskan cara menggabungkan dua tensor. Tensor digabungkan dengan mengalikan elemen satu tensor dengan elemen tensor lainnya, lalu menjumlahkan hasil perkaliannya. Notasi Einsum menggunakan simbol untuk mengidentifikasi sumbu setiap tensor, dan simbol yang sama tersebut disusun ulang untuk menentukan bentuk tensor hasil baru.
NumPy menyediakan implementasi Einsum umum.
lapisan penyematan
Hidden layer khusus yang dilatih pada fitur kategoris berdimensi tinggi untuk mempelajari vektor embedding berdimensi lebih rendah secara bertahap. Lapisan penyematan memungkinkan jaringan neural dilatih secara jauh lebih efisien daripada hanya melatih fitur kategorikal berdimensi tinggi.
Misalnya, saat ini Bumi mendukung sekitar 73.000 spesies pohon. Misalkan
spesies pohon adalah fitur dalam model Anda, sehingga lapisan
input model Anda mencakup vektor one-hot sepanjang 73.000 elemen.
Misalnya, baobab mungkin ditampilkan seperti ini:

Array dengan 73.000 elemen sangat panjang. Jika Anda tidak menambahkan lapisan embedding ke model, pelatihan akan sangat memakan waktu karena mengalikan 72.999 angka nol. Mungkin Anda memilih lapisan penyematan yang terdiri dari 12 dimensi. Oleh karena itu, lapisan embedding akan secara bertahap mempelajari vektor embedding baru untuk setiap spesies pohon.
Dalam situasi tertentu, hashing adalah alternatif yang wajar untuk lapisan penyematan.
Lihat Penyematan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
ruang sematan
Ruang vektor berdimensi d yang memetakan fitur dari ruang vektor berdimensi lebih tinggi. Ruang penyematan dilatih untuk menangkap struktur yang bermakna bagi aplikasi yang dimaksud.
Produk dot dari dua embedding adalah ukuran kesamaan dari embedding tersebut.
vektor embedding
Secara umum, array bilangan floating point yang diambil dari lapisan tersembunyi mana pun yang menjelaskan input ke lapisan tersembunyi tersebut. Sering kali, vektor embedding adalah array bilangan floating point yang dilatih di lapisan embedding. Misalnya, anggaplah lapisan embedding harus mempelajari vektor embedding untuk setiap 73.000 spesies pohon di Bumi. Mungkin array berikut adalah vektor embedding untuk pohon baobab:

Vektor penyematan bukanlah sekumpulan angka acak. Lapisan penyematan menentukan nilai ini melalui pelatihan, mirip dengan cara jaringan neural mempelajari bobot lain selama pelatihan. Setiap elemen array adalah rating di sepanjang karakteristik spesies pohon. Elemen mana yang merepresentasikan karakteristik spesies pohon? Hal itu sangat sulit ditentukan oleh manusia.
Bagian vektor embedding yang luar biasa secara matematis adalah bahwa item yang serupa memiliki set angka floating-point yang serupa. Misalnya, spesies pohon yang serupa memiliki kumpulan angka floating point yang lebih serupa daripada spesies pohon yang tidak serupa. Redwood dan sequoia adalah spesies pohon yang terkait, sehingga akan memiliki kumpulan angka floating point yang lebih mirip daripada redwood dan kelapa. Angka dalam vektor embedding akan berubah setiap kali Anda melatih ulang model, meskipun Anda melatih ulang model dengan input yang identik.
fungsi distribusi kumulatif empiris (eCDF atau EDF)
Fungsi distribusi kumulatif berdasarkan pengukuran empiris dari set data nyata. Nilai fungsi di titik mana pun di sepanjang sumbu x adalah fraksi pengamatan dalam set data yang kurang dari atau sama dengan nilai yang ditentukan.
minimalisasi risiko empiris (MRE) (empirical risk minimization (ERM))
Memilih fungsi yang meminimalkan kerugian pada set pelatihan. Berbeda dengan minimalisasi risiko struktural.
pembuat enkode
Secara umum, sistem ML apa pun yang mengonversi dari representasi mentah, jarang, atau eksternal menjadi representasi yang lebih diproses, lebih padat, atau lebih internal.
Encoder sering kali menjadi komponen dari model yang lebih besar, yang sering kali dipasangkan dengan decoder. Beberapa Transformer memasangkan encoder dengan decoder, meskipun Transformer lainnya hanya menggunakan encoder atau hanya menggunakan decoder.
Beberapa sistem menggunakan output encoder sebagai input ke jaringan klasifikasi atau regresi.
Dalam tugas sequence-to-sequence, encoder mengambil urutan input dan menampilkan status internal (vektor). Kemudian, dekoder menggunakan status internal tersebut untuk memprediksi urutan berikutnya.
Lihat Transformer untuk mengetahui definisi encoder dalam arsitektur Transformer.
Lihat LLM: Apa itu model bahasa besar di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
endpoint
Lokasi yang dapat diakses melalui jaringan (biasanya URL) tempat layanan dapat dijangkau.
ansambel
Kumpulan model yang dilatih secara independen yang prediksinya dirata-ratakan atau digabungkan. Dalam banyak kasus, ansambel menghasilkan prediksi yang lebih baik daripada model tunggal. Misalnya, hutan acak adalah ansambel yang dibangun dari beberapa pohon keputusan. Perhatikan bahwa tidak semua hutan keputusan adalah ansambel.
Lihat Random Forest di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
entropi
Dalam teori informasi, deskripsi tentang seberapa tidak terduganya distribusi probabilitas. Atau, entropi juga didefinisikan sebagai seberapa banyak informasi yang terkandung dalam setiap contoh. Distribusi memiliki entropi tertinggi jika semua nilai variabel acak memiliki kemungkinan yang sama.
Entropi set dengan dua kemungkinan nilai "0" dan "1" (misalnya, label dalam masalah klasifikasi biner) memiliki formula berikut:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
dalam hal ini:
- H adalah entropi.
- p adalah fraksi contoh "1".
- q adalah fraksi contoh "0". Perhatikan bahwa q = (1 - p)
- log umumnya adalah log2. Dalam hal ini, unit entropi adalah bit.
Misalnya, anggap saja hal berikut:
- 100 contoh berisi nilai "1"
- 300 contoh berisi nilai "0"
Oleh karena itu, nilai entropi adalah:
- p = 0,25
- q = 0,75
- H = (-0,25)log2(0,25) - (0,75)log2(0,75) = 0,81 bit per contoh
Kumpulan data yang seimbang sempurna (misalnya, 200 "0" dan 200 "1") akan memiliki entropi 1,0 bit per contoh. Seiring bertambahnya ketidakseimbangan dalam kumpulan data, entropinya akan mendekati 0,0.
Dalam pohon keputusan, entropi membantu merumuskan perolehan informasi untuk membantu pemisah memilih kondisi selama pertumbuhan pohon keputusan klasifikasi.
Bandingkan entropi dengan:
- gini impurity
- Fungsi kerugian cross-entropy
Entropi sering disebut entropi Shannon.
Lihat Splitter persis untuk klasifikasi biner dengan fitur numerik dalam kursus Decision Forests untuk mengetahui informasi selengkapnya.
lingkungan
Dalam pembelajaran reinforcement, dunia yang berisi agen dan memungkinkan agen mengamati status dunia tersebut. Misalnya, dunia yang direpresentasikan dapat berupa game seperti catur, atau dunia fisik seperti labirin. Saat agen menerapkan tindakan ke lingkungan, lingkungan akan bertransisi antar-status.
episode
Dalam reinforcement learning, setiap percobaan berulang oleh agen untuk mempelajari lingkungan.
epoch
Pass pelatihan penuh pada seluruh set pelatihan sehingga setiap contoh telah diproses satu kali.
Epoch mewakili N/ukuran batch
iterasi pelatihan, dengan N adalah
jumlah total contoh.
Misalnya, anggap saja hal berikut:
- Set data terdiri dari 1.000 contoh.
- Ukuran batch adalah 50 contoh.
Oleh karena itu, satu epoch memerlukan 20 iterasi:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Lihat Regresi linear: Hyperparameter di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
kebijakan epsilon greedy
Dalam pembelajaran beruntun, kebijakan yang mengikuti kebijakan acak dengan probabilitas epsilon atau kebijakan serakah. Misalnya, jika epsilon adalah 0,9, kebijakan akan mengikuti kebijakan acak 90% dari waktu dan kebijakan serakah 10% dari waktu.
Selama episode berturut-turut, algoritma mengurangi nilai epsilon untuk beralih dari mengikuti kebijakan acak ke mengikuti kebijakan serakah. Dengan mengubah kebijakan, agen pertama-tama akan menjelajahi lingkungan secara acak, lalu memanfaatkan hasil eksplorasi acak secara serakah.
kesetaraan peluang
Metrik keadilan untuk menilai apakah model memprediksi hasil yang diinginkan dengan sama baiknya untuk semua nilai atribut sensitif. Dengan kata lain, jika hasil yang diinginkan untuk model adalah kelas positif, tujuannya adalah agar rasio positif benar sama untuk semua grup.
Kesetaraan peluang terkait dengan peluang yang sama, yang mengharuskan kedua rasio positif benar dan rasio positif palsu sama untuk semua grup.
Misalkan Universitas Glubbdubdrib menerima orang Lilliput dan Brobdingnag untuk mengikuti program matematika yang ketat. Sekolah menengah Lilliput menawarkan kurikulum kelas matematika yang kuat, dan sebagian besar siswa memenuhi syarat untuk program universitas. Sekolah menengah Brobdingnag tidak menawarkan kelas matematika sama sekali, dan akibatnya, jauh lebih sedikit siswa mereka yang memenuhi syarat. Kesetaraan peluang terpenuhi untuk label pilihan "diterima" sehubungan dengan kewarganegaraan (Lilliput atau Brobdingnag) jika siswa yang memenuhi syarat memiliki peluang yang sama untuk diterima, terlepas dari apakah mereka berasal dari Lilliput atau Brobdingnag.
Misalnya, anggaplah 100 orang Lilliput dan 100 orang Brobdingnag mendaftar ke Universitas Glubbdubdrib, dan keputusan penerimaan dibuat sebagai berikut:
Tabel 1. Pelamar Lilliputian (90% memenuhi syarat)
| Berkualitas | Tidak memenuhi syarat | |
|---|---|---|
| Diizinkan | 45 | 3 |
| Ditolak | 45 | 7 |
| Total | 90 | 10 |
|
Persentase siswa yang memenuhi syarat yang diterima: 45/90 = 50% Persentase siswa yang tidak memenuhi syarat yang ditolak: 7/10 = 70% Total persentase siswa Lilliput yang diterima: (45+3)/100 = 48% |
||
Tabel 2. Pelamar Brobdingnagian (10% memenuhi syarat):
| Berkualitas | Tidak memenuhi syarat | |
|---|---|---|
| Diizinkan | 5 | 9 |
| Ditolak | 5 | 81 |
| Total | 10 | 90 |
|
Persentase siswa yang memenuhi syarat yang diterima: 5/10 = 50% Persentase siswa yang tidak memenuhi syarat yang ditolak: 81/90 = 90% Total persentase siswa Brobdingnag yang diterima: (5+9)/100 = 14% |
||
Contoh sebelumnya memenuhi kesetaraan peluang untuk penerimaan siswa yang memenuhi syarat karena Lilliputian dan Brobdingnagian yang memenuhi syarat memiliki peluang 50% untuk diterima.
Meskipun kesetaraan peluang terpenuhi, dua metrik keadilan berikut tidak terpenuhi:
- paritas demografi: Lilliputians dan Brobdingnagians diterima di universitas dengan tingkat yang berbeda; 48% siswa Lilliputians diterima, tetapi hanya 14% siswa Brobdingnagians yang diterima.
- peluang yang sama: Meskipun siswa Lilliput dan Brobdingnag yang memenuhi syarat memiliki peluang yang sama untuk diterima, batasan tambahan bahwa siswa Lilliput dan Brobdingnag yang tidak memenuhi syarat memiliki peluang yang sama untuk ditolak tidak terpenuhi. Lilliput yang tidak memenuhi syarat memiliki rasio penolakan 70%, sedangkan Brobdingnag yang tidak memenuhi syarat memiliki rasio penolakan 90%.
Lihat Keadilan: Kesetaraan peluang di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
peluang yang sama
Metrik keadilan untuk menilai apakah model memprediksi hasil dengan sama baiknya untuk semua nilai atribut sensitif dengan mempertimbangkan kelas positif dan kelas negatif—bukan hanya satu kelas atau kelas lainnya secara eksklusif. Dengan kata lain, rasio positif benar dan rasio negatif palsu harus sama untuk semua grup.
Peluang yang sama terkait dengan kesetaraan peluang, yang hanya berfokus pada tingkat error untuk satu kelas (positif atau negatif).
Misalnya, Universitas Glubbdubdrib menerima orang Lilliput dan Brobdingnag untuk mengikuti program matematika yang ketat. Sekolah menengah Lilliput menawarkan kurikulum yang kuat untuk kelas matematika, dan sebagian besar siswa memenuhi syarat untuk program universitas. Sekolah menengah Brobdingnag tidak menawarkan kelas matematika sama sekali, dan akibatnya, jauh lebih sedikit siswa mereka yang memenuhi syarat. Peluang yang sama terpenuhi asalkan terlepas dari apakah pelamar adalah Lilliputian atau Brobdingnagian, jika mereka memenuhi syarat, mereka memiliki peluang yang sama untuk diterima dalam program tersebut, dan jika mereka tidak memenuhi syarat, mereka memiliki peluang yang sama untuk ditolak.
Misalkan 100 orang Lilliput dan 100 orang Brobdingnag mendaftar ke Universitas Glubbdubdrib, dan keputusan penerimaan dibuat sebagai berikut:
Tabel 3. Pelamar Lilliputian (90% memenuhi syarat)
| Berkualitas | Tidak memenuhi syarat | |
|---|---|---|
| Diizinkan | 45 | 2 |
| Ditolak | 45 | 8 |
| Total | 90 | 10 |
|
Persentase siswa yang memenuhi syarat yang diterima: 45/90 = 50% Persentase siswa yang tidak memenuhi syarat yang ditolak: 8/10 = 80% Total persentase siswa Lilliput yang diterima: (45+2)/100 = 47% |
||
Tabel 4. Pelamar Brobdingnagian (10% memenuhi syarat):
| Berkualitas | Tidak memenuhi syarat | |
|---|---|---|
| Diizinkan | 5 | 18 |
| Ditolak | 5 | 72 |
| Total | 10 | 90 |
|
Persentase siswa yang memenuhi syarat yang diterima: 5/10 = 50% Persentase siswa yang tidak memenuhi syarat yang ditolak: 72/90 = 80% Total persentase siswa Brobdingnag yang diterima: (5+18)/100 = 23% |
||
Peluang yang sama terpenuhi karena siswa Lilliput dan Brobdingnag yang memenuhi syarat memiliki peluang 50% untuk diterima, dan siswa Lilliput dan Brobdingnag yang tidak memenuhi syarat memiliki peluang 80% untuk ditolak.
Peluang yang sama didefinisikan secara formal dalam "Equality of Opportunity in Supervised Learning" sebagai berikut: "prediktor Ŷ memenuhi peluang yang sama sehubungan dengan atribut yang dilindungi A dan hasil Y jika Ŷ dan A independen, bersyarat pada Y."
Estimator
TensorFlow API yang tidak digunakan lagi. Gunakan tf.keras, bukan Estimator.
evaluasi
Terutama digunakan sebagai singkatan untuk evaluasi LLM. Secara lebih luas, evaluasi adalah singkatan dari segala bentuk evaluasi.
evaluasi
Proses mengukur kualitas model atau membandingkan berbagai model satu sama lain.
Untuk mengevaluasi model machine learning terawasi, Anda biasanya menilainya berdasarkan set validasi dan set pengujian. Mengevaluasi LLM biasanya melibatkan penilaian kualitas dan keamanan yang lebih luas.
pencocokan persis
Metrik semua atau tidak sama sekali yang output modelnya cocok dengan kebenaran nyata atau teks referensi secara persis atau tidak. Misalnya, jika kebenaran dasarnya adalah orange, satu-satunya output model yang memenuhi pencocokan persis adalah orange.
Pencocokan persis juga dapat mengevaluasi model yang outputnya berupa urutan (daftar item yang diberi peringkat). Secara umum, pencocokan persis mengharuskan daftar berperingkat yang dihasilkan cocok persis dengan data sebenarnya; yaitu, setiap item dalam kedua daftar harus dalam urutan yang sama. Namun, jika kebenaran dasar terdiri dari beberapa urutan yang benar, maka pencocokan persis hanya memerlukan output model yang cocok dengan salah satu urutan yang benar.
contoh
Nilai satu baris fitur dan mungkin label. Contoh dalam supervised learning terbagi dalam dua kategori umum:
- Contoh berlabel terdiri dari satu atau beberapa fitur dan satu label. Contoh berlabel digunakan selama pelatihan.
- Contoh tidak berlabel terdiri dari satu atau beberapa fitur, tetapi tidak memiliki label. Contoh tak berlabel digunakan selama inferensi.
Misalnya, Anda melatih model untuk menentukan pengaruh kondisi cuaca terhadap nilai ujian siswa. Berikut tiga contoh berlabel:
| Fitur | Label | ||
|---|---|---|---|
| Suhu | Kelembapan | Tekanan | Skor pengujian |
| 15 | 47 | 998 | Baik |
| 19 | 34 | 1020 | Luar biasa |
| 18 | 92 | 1012 | Buruk |
Berikut adalah tiga contoh yang tidak berlabel:
| Suhu | Kelembapan | Tekanan | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
Baris set data biasanya merupakan sumber mentah untuk contoh. Artinya, contoh biasanya terdiri dari subset kolom dalam set data. Selain itu, fitur dalam contoh juga dapat mencakup fitur sintetis, seperti persilangan fitur.
Lihat Supervised Learning di kursus Pengantar Machine Learning untuk mengetahui informasi selengkapnya.
replay pengalaman
Dalam reinforcement learning, teknik DQN digunakan untuk mengurangi korelasi temporal dalam data pelatihan. Agen menyimpan transisi status dalam buffer pemutaran ulang, lalu mengambil sampel transisi dari buffer pemutaran ulang untuk membuat data pelatihan.
bias pelaku eksperimen
Lihat bias konfirmasi.
masalah gradien meledak
Kecenderungan gradien dalam deep neural network (terutama recurrent neural network) menjadi sangat curam (tinggi). Gradien yang curam sering kali menyebabkan update yang sangat besar pada bobot setiap node dalam jaringan neural dalam.
Model yang mengalami masalah gradien meledak menjadi sulit atau tidak mungkin dilatih. Pemangkasan gradien dapat mengurangi masalah ini.
Bandingkan dengan masalah gradien yang hilang.
F
F1
Metrik "gabungan" klasifikasi biner yang mengandalkan presisi dan perolehan. Berikut rumusnya:
faktualitas
Dalam dunia ML, properti yang menjelaskan model yang outputnya didasarkan pada kenyataan. Faktualitas adalah konsep, bukan metrik. Misalnya, Anda mengirimkan perintah berikut ke model bahasa besar:
Apa rumus kimia untuk garam dapur?
Model yang mengoptimalkan faktualitas akan merespons:
NaCl
Kita cenderung mengasumsikan bahwa semua model harus didasarkan pada faktualitas. Namun, beberapa perintah, seperti berikut, akan menyebabkan model AI generatif mengoptimalkan kreativitas, bukan faktualitas.
Buatkan saya sajak lucu tentang astronot dan ulat.
Limerick yang dihasilkan kemungkinan tidak akan didasarkan pada kenyataan.
Berbeda dengan keterikatan dengan data.
batasan keadilan
Menerapkan batasan pada algoritma untuk memastikan satu atau beberapa definisi keadilan terpenuhi. Contoh batasan keadilan meliputi:- Memproses pasca-pemrosesan output model Anda.
- Mengubah fungsi kerugian untuk memasukkan penalti karena melanggar metrik keadilan.
- Menambahkan batasan matematika secara langsung ke masalah pengoptimalan.
metrik keadilan
Definisi "keadilan" secara matematis yang dapat diukur. Beberapa metrik keadilan yang umum digunakan meliputi:
Banyak metrik keadilan yang saling eksklusif; lihat ketidakcocokan metrik keadilan.
negatif palsu (NP)
Contoh yang mana model salah memprediksi kelas negatif. Misalnya, model memprediksi bahwa pesan email tertentu bukan spam (kelas negatif), tetapi pesan email tersebut sebenarnya adalah spam.
rasio negatif palsu
Proporsi contoh positif sebenarnya yang salah diprediksi oleh model sebagai kelas negatif. Formula berikut menghitung rasio negatif palsu:
Lihat Nilai minimum dan matriks kebingungan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
positif palsu (PP)
Contoh yang mana model salah memprediksi kelas positif. Misalnya, model memprediksi bahwa pesan email tertentu adalah spam (kelas positif), tetapi pesan email tersebut sebenarnya bukan spam.
Lihat Nilai minimum dan matriks kebingungan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
rasio positif palsu (FPR)
Proporsi contoh negatif sebenarnya yang mana model salah memprediksi kelas positif. Formula berikut menghitung rasio positif palsu:
Rasio positif palsu adalah sumbu x dalam kurva ROC.
Lihat Klasifikasi: KOP dan ABK di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
peluruhan cepat
Teknik pelatihan untuk meningkatkan performa LLM. Peluruhan cepat melibatkan penurunan kecepatan pembelajaran dengan cepat selama pelatihan. Strategi ini membantu mencegah model melakukan overfitting pada data pelatihan, dan meningkatkan generalisasi.
fitur
Variabel input ke model machine learning. Contoh terdiri dari satu atau beberapa fitur. Misalnya, Anda melatih model untuk menentukan pengaruh kondisi cuaca terhadap nilai ujian siswa. Tabel berikut menunjukkan tiga contoh, yang masing-masing berisi tiga fitur dan satu label:
| Fitur | Label | ||
|---|---|---|---|
| Suhu | Kelembapan | Tekanan | Skor pengujian |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
Berbeda dengan label.
Lihat Supervised Learning dalam kursus Introduction to Machine Learning untuk mengetahui informasi selengkapnya.
persilangan fitur
Fitur sintetis yang dibentuk dengan "menyilangkan" fitur kategoris atau fitur yang dikelompokkan.
Misalnya, pertimbangkan model "perkiraan suasana hati" yang merepresentasikan suhu dalam salah satu dari empat kelompok berikut:
freezingchillytemperatewarm
Dan mewakili kecepatan angin dalam salah satu dari tiga bucket berikut:
stilllightwindy
Tanpa persilangan fitur, model linear dilatih secara independen pada masing-masing
tujuh bucket yang berbeda sebelumnya. Jadi, model dilatih, misalnya,
freezing secara independen dari pelatihan, misalnya,
windy.
Atau, Anda dapat membuat persilangan fitur suhu dan kecepatan angin. Fitur sintetis ini akan memiliki 12 kemungkinan nilai berikut:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
Berkat persilangan fitur, model dapat mempelajari perbedaan suasana hati antara hari freezing-windy dan hari freezing-still.
Jika Anda membuat fitur sintetis dari dua fitur yang masing-masing memiliki banyak bucket berbeda, persilangan fitur yang dihasilkan akan memiliki sejumlah besar kemungkinan kombinasi. Misalnya, jika satu fitur memiliki 1.000 bucket dan fitur lainnya memiliki 2.000 bucket, persilangan fitur yang dihasilkan memiliki 2.000.000 bucket.
Secara formal, salib adalah produk Kartesius.
Persilangan fitur sebagian besar digunakan dengan model linear dan jarang digunakan dengan jaringan saraf tiruan.
Lihat Data kategoris: Persilangan fitur di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
rekayasa fitur
Proses yang melibatkan langkah-langkah berikut:
- Menentukan fitur mana yang mungkin berguna dalam melatih model.
- Mengonversi data mentah dari set data menjadi versi efisien dari fitur tersebut.
Misalnya, Anda dapat menentukan bahwa temperature mungkin merupakan fitur yang berguna. Kemudian, Anda dapat bereksperimen dengan pengelompokan
untuk mengoptimalkan apa yang dapat dipelajari model dari berbagai rentang temperature.
Rekayasa fitur terkadang disebut ekstraksi fitur atau featurisasi.
Lihat Data numerik: Cara model menyerap data menggunakan vektor fitur di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
ekstraksi fitur
Istilah yang memiliki lebih dari satu definisi:
- Mengambil representasi fitur perantara yang dihitung oleh model tanpa pengawasan atau model terlatih (misalnya, nilai lapisan tersembunyi dalam jaringan neural) untuk digunakan dalam model lain sebagai input.
- Sinonim dari rekayasa fitur.
tingkat kepentingan fitur
Sinonim untuk kepentingan variabel.
set fitur
Grup fitur tempat model machine learning dilatih. Misalnya, set fitur sederhana untuk model yang memprediksi harga rumah dapat terdiri dari kode pos, ukuran properti, dan kondisi properti.
spesifikasi fitur
Menjelaskan informasi yang diperlukan untuk mengekstrak data fitur dari buffer protokol tf.Example. Karena buffer protokol tf.Example hanyalah penampung data, Anda harus menentukan hal berikut:
- Data yang akan diekstrak (yaitu, kunci untuk fitur)
- Jenis data (misalnya, float atau int)
- Panjang (tetap atau variabel)
vektor fitur
Array nilai fitur yang terdiri dari contoh. Vektor fitur dimasukkan selama pelatihan dan selama inferensi. Misalnya, vektor fitur untuk model dengan dua fitur diskrit mungkin adalah:
[0.92, 0.56]
Setiap contoh memberikan nilai yang berbeda untuk vektor fitur, sehingga vektor fitur untuk contoh berikutnya dapat berupa:
[0.73, 0.49]
Rekayasa fitur menentukan cara merepresentasikan fitur dalam vektor fitur. Misalnya, fitur kategoris biner dengan lima kemungkinan nilai dapat direpresentasikan dengan enkode one-hot. Dalam hal ini, bagian vektor fitur untuk contoh tertentu akan terdiri dari empat angka nol dan satu angka 1.0 di posisi ketiga, sebagai berikut:
[0.0, 0.0, 1.0, 0.0, 0.0]
Sebagai contoh lain, misalkan model Anda terdiri dari tiga fitur:
- fitur kategorikal biner dengan lima kemungkinan nilai yang direpresentasikan dengan
encoding satu kali; misalnya:
[0.0, 1.0, 0.0, 0.0, 0.0] - fitur kategorikal biner lain dengan tiga kemungkinan nilai yang direpresentasikan
dengan encoding one-hot; misalnya:
[0.0, 0.0, 1.0] - fitur floating point; misalnya:
8.3.
Dalam hal ini, vektor fitur untuk setiap contoh akan direpresentasikan oleh sembilan nilai. Dengan nilai contoh dalam daftar sebelumnya, vektor fitur akan menjadi:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
Lihat Data numerik: Cara model menyerap data menggunakan vektor fitur di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
fiturisasi
Proses mengekstrak fitur dari sumber input, seperti dokumen atau video, dan memetakan fitur tersebut ke dalam vektor fitur.
Beberapa pakar ML menggunakan fiturisasi sebagai sinonim untuk rekayasa fitur atau ekstraksi fitur.
federated learning
Pendekatan machine learning terdistribusi yang melatih model machine learning menggunakan contoh terdesentralisasi yang berada di perangkat, seperti smartphone. Dalam federated learning, subset perangkat mendownload model saat ini dari server koordinasi pusat. Perangkat menggunakan contoh yang disimpan di perangkat untuk meningkatkan kualitas model. Kemudian, perangkat mengupload peningkatan model (tetapi bukan contoh pelatihan) ke server koordinasi, tempat peningkatan tersebut digabungkan dengan update lainnya untuk menghasilkan model global yang lebih baik. Setelah penggabungan, model yang diperbarui oleh perangkat tidak lagi diperlukan dan dapat dihapus.
Karena contoh pelatihan tidak pernah diupload, federated learning mengikuti prinsip privasi pengumpulan data yang terfokus dan minimalisasi data.
Lihat komik Federated Learning (ya, komik) untuk mengetahui detail selengkapnya.
feedback loop
Dalam machine learning, situasi saat prediksi model memengaruhi data pelatihan untuk model yang sama atau model lain. Misalnya, model yang merekomendasikan film akan memengaruhi film yang dilihat orang, yang kemudian akan memengaruhi model rekomendasi film berikutnya.
Lihat Sistem ML produksi: Pertanyaan yang harus diajukan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
jaringan saraf alur maju (FFN)
Jaringan neural tanpa koneksi berulang atau siklis. Misalnya, jaringan neural dalam tradisional merupakan jaringan saraf alur maju. Berbeda dengan recurrent neural networks, yang bersifat siklis.
pemelajaran beberapa tahap
Pendekatan machine learning, yang sering digunakan untuk klasifikasi objek, dirancang untuk melatih model klasifikasi yang efektif hanya dari sejumlah kecil contoh pelatihan.
Lihat juga pemelajaran satu tahap dan pemelajaran nol tahap.
few-shot prompting
Perintah yang berisi lebih dari satu (beberapa) contoh yang menunjukkan cara model bahasa besar harus merespons. Misalnya, perintah panjang berikut berisi dua contoh yang menunjukkan kepada model bahasa besar cara menjawab kueri.
| Bagian dari satu perintah | Catatan |
|---|---|
| Apa mata uang resmi negara yang ditentukan? | Pertanyaan yang ingin Anda minta jawabannya dari LLM. |
| Prancis: EUR | Satu contoh. |
| Inggris Raya: GBP | Contoh lainnya. |
| India: | Kueri sebenarnya. |
Few-shot prompting umumnya menghasilkan hasil yang lebih diinginkan daripada zero-shot prompting dan one-shot prompting. Namun, perintah few-shot memerlukan perintah yang lebih panjang.
Few-shot prompting adalah bentuk few-shot learning yang diterapkan pada pembelajaran berbasis perintah.
Lihat Rekayasa perintah di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Biola
Library konfigurasi yang mengutamakan Python yang menetapkan nilai fungsi dan class tanpa kode atau infrastruktur yang invasif. Dalam kasus Pax—dan codebase ML lainnya—fungsi dan class ini merepresentasikan model dan pelatihan hyperparameter.
Fiddle mengasumsikan bahwa codebase machine learning biasanya dibagi menjadi:
- Kode library, yang menentukan lapisan dan pengoptimal.
- Kode "perekat" set data, yang memanggil library dan menghubungkan semuanya.
Fiddle merekam struktur panggilan kode lem dalam bentuk yang tidak dievaluasi dan dapat diubah.
penyesuaian
Proses pelatihan khusus tugas kedua dilakukan pada model terlatih untuk menyempurnakan parameternya untuk kasus penggunaan tertentu. Misalnya, urutan pelatihan lengkap untuk beberapa model bahasa besar adalah sebagai berikut:
- Prapelatihan: Melatih model bahasa besar pada set data umum yang sangat besar, seperti semua halaman Wikipedia berbahasa Inggris.
- Penyesuaian: Melatih model terlatih untuk melakukan tugas tertentu, seperti merespons kueri medis. Penyesuaian biasanya melibatkan ratusan atau ribuan contoh yang berfokus pada tugas tertentu.
Sebagai contoh lain, urutan pelatihan lengkap untuk model gambar besar adalah sebagai berikut:
- Prapelatihan: Melatih model gambar besar pada set data gambar umum yang luas, seperti semua gambar di Wikimedia Commons.
- Penyesuaian: Melatih model terlatih untuk melakukan tugas tertentu, seperti membuat gambar orca.
Penyesuaian dapat mencakup kombinasi strategi berikut:
- Mengubah semua parameter model yang sudah ada dan telah dilatih sebelumnya. Hal ini terkadang disebut penyesuaian penuh.
- Mengubah hanya beberapa parameter yang ada pada model terlatih (biasanya, lapisan yang paling dekat dengan lapisan output), sambil mempertahankan parameter yang ada lainnya (biasanya, lapisan yang paling dekat dengan lapisan input). Lihat parameter-efficient tuning.
- Menambahkan lebih banyak lapisan, biasanya di atas lapisan yang ada yang paling dekat dengan lapisan output.
Penyesuaian adalah bentuk transfer learning. Oleh karena itu, penyesuaian mungkin menggunakan fungsi kerugian yang berbeda atau jenis model yang berbeda dengan yang digunakan untuk melatih model terlatih. Misalnya, Anda dapat melakukan penyesuaian pada model gambar besar terlatih untuk menghasilkan model regresi yang menampilkan jumlah burung dalam gambar input.
Bandingkan dan bedakan penyesuaian dengan istilah berikut:
Lihat Penyesuaian di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Model flash
Rangkaian model Gemini yang relatif kecil dan dioptimalkan untuk kecepatan dan latensi rendah. Model Flash dirancang untuk berbagai aplikasi yang memerlukan respons cepat dan throughput tinggi.
Flax
Library open source berperforma tinggi untuk deep learning yang dibangun di atas JAX. Flax menyediakan fungsi untuk pelatihan jaringan neural, serta metode untuk mengevaluasi performanya.
Flaxformer
Library Transformer open source, yang dibangun di atas Flax, dirancang terutama untuk pemrosesan bahasa alami dan riset multimodal.
gerbang lupa
Bagian sel Long Short-Term Memory yang mengatur aliran informasi melalui sel. Gerbang pelupa mempertahankan konteks dengan memutuskan informasi mana yang akan dihapus dari status sel.
model dasar
Model terlatih yang sangat besar dan dilatih pada set pelatihan yang sangat besar dan beragam. Model dasar dapat melakukan kedua hal berikut:
- Merespons dengan baik berbagai permintaan.
- Berfungsi sebagai model dasar untuk penyesuaian tambahan atau penyesuaian lainnya.
Dengan kata lain, model dasar sudah sangat mumpuni secara umum, tetapi dapat disesuaikan lebih lanjut agar lebih berguna untuk tugas tertentu.
fraksi keberhasilan
Metrik untuk mengevaluasi teks yang dihasilkan model ML. Pecahan keberhasilan adalah jumlah output teks yang dihasilkan "berhasil" dibagi dengan total jumlah output teks yang dihasilkan. Misalnya, jika model bahasa besar menghasilkan 10 blok kode, lima di antaranya berhasil, maka rasio keberhasilannya adalah 50%.
Meskipun fraksi keberhasilan sangat berguna dalam statistik, dalam ML, metrik ini terutama berguna untuk mengukur tugas yang dapat diverifikasi seperti pembuatan kode atau masalah matematika.
full softmax
Sinonim untuk softmax.
Berbeda dengan sampling kandidat.
Lihat Jaringan neural: Klasifikasi multi-kelas di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
lapisan terhubung sepenuhnya
Lapisan tersembunyi yang setiap node-nya terhubung ke setiap node di lapisan tersembunyi berikutnya.
Lapisan terhubung seluruhnya juga dikenal sebagai lapisan padat.
transformasi fungsi
Fungsi yang menggunakan fungsi sebagai input dan menampilkan fungsi yang ditransformasi sebagai output. JAX menggunakan transformasi fungsi.
G
GAN
Singkatan dari generative adversarial network.
Gemini
Ekosistem yang terdiri dari AI tercanggih Google. Elemen ekosistem ini mencakup:
- Berbagai model Gemini.
- Antarmuka percakapan interaktif ke model Gemini. Pengguna mengetik perintah dan Gemini merespons perintah tersebut.
- Berbagai Gemini API.
- Berbagai produk bisnis berdasarkan model Gemini; misalnya, Gemini untuk Google Cloud.
Model Gemini
Model multimodal berbasis Transformer mutakhir Google. Model Gemini dirancang khusus untuk terintegrasi dengan agen.
Pengguna dapat berinteraksi dengan model Gemini dalam berbagai cara, termasuk melalui antarmuka dialog interaktif dan melalui SDK.
Gemma
Sekumpulan model terbuka yang ringan, dibangun dari riset dan teknologi yang sama dengan yang digunakan untuk membuat model Gemini. Beberapa model Gemma yang berbeda tersedia, masing-masing menyediakan fitur yang berbeda, seperti kemampuan melihat, membuat kode, dan mengikuti perintah. Lihat Gemma untuk mengetahui detailnya.
GenAI atau genAI
Singkatan untuk AI generatif.
generalisasi
Kemampuan model untuk membuat prediksi yang benar terkait data baru yang sebelumnya tidak terlihat. Model yang dapat melakukan generalisasi adalah kebalikan dari model yang overfitting.
Lihat Generalisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
kurva generalisasi
Plot loss pelatihan dan loss validasi sebagai fungsi dari jumlah iterasi.
Kurva generalisasi dapat membantu Anda mendeteksi kemungkinan overfitting. Misalnya, kurva generalisasi berikut menunjukkan overfitting karena kerugian validasi pada akhirnya menjadi jauh lebih tinggi daripada kerugian pelatihan.
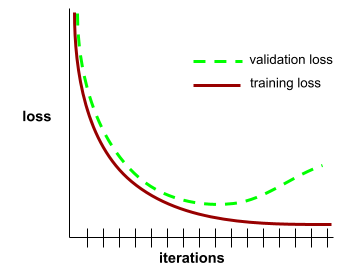
Lihat Generalisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
model linear tergeneralisasi
Generalisasi model regresi kuadrat terkecil, yang didasarkan pada derau Gaussian, ke jenis model lain yang didasarkan pada jenis derau lainnya, seperti derau Poisson atau derau kategoris. Contoh model linear tergeneralisasi meliputi:
- regresi logistik
- regresi multikelas
- regresi kuadrat terkecil
Parameter model linear tergeneralisasi dapat ditemukan melalui pengoptimalan konveks.
Model linear tergeneralisasi menunjukkan properti berikut:
- Prediksi rata-rata model regresi kuadrat terkecil yang optimal sama dengan label rata-rata pada data pelatihan.
- Probabilitas rata-rata yang diprediksi oleh model regresi logistik optimal sama dengan label rata-rata pada data pelatihan.
Kualitas model linear tergeneralisasi dibatasi oleh fiturnya. Tidak seperti model dalam, model linear tergeneralisasi tidak dapat "mempelajari fitur baru".
teks yang dihasilkan
Secara umum, teks yang dihasilkan model ML. Saat mengevaluasi model bahasa besar, beberapa metrik membandingkan teks yang dihasilkan dengan teks referensi. Misalnya, Anda sedang mencoba menentukan seberapa efektif model ML menerjemahkan dari bahasa Prancis ke bahasa Belanda. Dalam hal ini:
- Teks yang dihasilkan adalah terjemahan Belanda yang dihasilkan oleh model ML.
- Teks rujukan adalah terjemahan dalam bahasa Belanda yang dibuat oleh penerjemah manusia (atau software).
Perhatikan bahwa beberapa strategi evaluasi tidak melibatkan teks referensi.
jaringan saraf generatif berlawanan (GAN)
Sistem untuk membuat data baru yang generator-nya membuat data dan diskriminator-nya menentukan apakah data yang dibuat tersebut valid atau tidak valid.
Lihat kursus Generative Adversarial Networks untuk mengetahui informasi selengkapnya.
AI generatif
Bidang transformatif yang baru muncul tanpa definisi formal. Namun, sebagian besar pakar setuju bahwa model AI generatif dapat membuat ("menghasilkan") konten yang memenuhi semua kriteria berikut:
- kompleks
- koheren
- asli
Contoh AI generatif meliputi:
- Model bahasa besar, yang dapat menghasilkan teks asli yang canggih dan menjawab pertanyaan.
- Model pembuatan gambar, yang dapat menghasilkan gambar unik.
- Model pembuatan audio dan musik, yang dapat menyusun musik asli atau menghasilkan ucapan yang realistis.
- Model pembuatan video, yang dapat membuat video asli.
Beberapa teknologi sebelumnya, termasuk LSTM dan RNN, juga dapat menghasilkan konten orisinal dan koheren. Beberapa pakar menganggap teknologi sebelumnya ini sebagai AI generatif, sementara yang lain merasa bahwa AI generatif yang sebenarnya memerlukan output yang lebih kompleks daripada yang dapat dihasilkan oleh teknologi sebelumnya tersebut.
Berbeda dengan ML prediktif.
model generatif
Secara praktis, model yang melakukan salah satu tindakan berikut:
- Membuat (menghasilkan) contoh baru dari set data pelatihan. Misalnya, model generatif dapat membuat puisi setelah dilatih di set data yang terdiri dari beberapa puisi. Bagian generator dari jaringan saraf generatif berlawanan termasuk dalam kategori ini.
- Menentukan probabilitas bahwa contoh baru berasal dari set pelatihan, atau dibuat dari mekanisme yang sama yang membuat set pelatihan. Misalnya, setelah dilatih di set data yang terdiri dari kalimat bahasa Inggris, model generatif dapat menentukan probabilitas bahwa masukan baru adalah kalimat bahasa Inggris yang valid.
Model generatif dapat secara teoretis memahami distribusi contoh atau fitur tertentu dalam set data. Definisinya yaitu:
p(examples)
Model unsupervised learning bersifat generatif.
Berbeda dengan model diskriminatif.
generator
Subsistem dalam generative adversarial network yang membuat contoh baru.
Berbeda dengan model diskriminatif.
ketidakmurnian gini
Metrik yang mirip dengan entropi. Splitter menggunakan nilai yang berasal dari ketidakmurnian Gini atau entropi untuk menyusun kondisi untuk klasifikasi pohon keputusan. Perolehan informasi berasal dari entropi. Tidak ada istilah setara yang diterima secara universal untuk metrik yang berasal dari ketidakmurnian gini; namun, metrik yang tidak disebutkan namanya ini sama pentingnya dengan perolehan informasi.
Ketidakmurnian Gini juga disebut indeks gini, atau cukup gini.
set data emas
Kumpulan data yang dikurasi secara manual yang merekam kebenaran nyata. Tim dapat menggunakan satu atau beberapa set data standar untuk mengevaluasi kualitas model.
Beberapa set data standar mencakup sub-domain kebenaran dasar yang berbeda. Misalnya, set data emas untuk klasifikasi gambar dapat merekam kondisi pencahayaan dan resolusi gambar.
respons emas
Respons yang diketahui baik. Misalnya, dengan prompt berikut:
2 + 2
Respons terbaik yang diharapkan adalah:
4
Google AI Studio
Alat Google yang menyediakan antarmuka yang mudah digunakan untuk bereksperimen dan membuat aplikasi menggunakan model bahasa besar Google. Lihat halaman beranda Google AI Studio untuk mengetahui detailnya.
GPT (Generative Pre-trained Transformer)
Serangkaian model bahasa besar berbasis Transformer yang dikembangkan oleh OpenAI.
Varian GPT dapat berlaku untuk beberapa modalitas, termasuk:
- pembuatan gambar (misalnya, ImageGPT)
- pembuatan gambar dari teks (misalnya, DALL-E).
gradien
Vektor turunan parsial yang terkait dengan semua variabel independen. Dalam machine learning, gradien adalah vektor turunan parsial dari fungsi model. Gradien mengarah ke arah pendakian paling curam.
akumulasi gradien
Teknik backpropagation yang memperbarui parameter hanya sekali per epoch, bukan sekali per iterasi. Setelah memproses setiap mini-batch, akumulasi gradien hanya memperbarui total gradien yang sedang berjalan. Kemudian, setelah memproses batch mini terakhir dalam epoch, sistem akhirnya memperbarui parameter berdasarkan total semua perubahan gradien.
Akumulasi gradien berguna jika ukuran batch sangat besar dibandingkan dengan jumlah memori yang tersedia untuk pelatihan. Jika memori menjadi masalah, kecenderungannya adalah mengurangi ukuran batch. Namun, mengurangi ukuran batch dalam backpropagation normal meningkatkan jumlah pembaruan parameter. Akumulasi gradien memungkinkan model menghindari masalah memori, tetapi tetap melatih secara efisien.
pohon (keputusan) penguatan gradien (GBT)
Jenis hutan keputusan yang:
- Pelatihan mengandalkan gradient boosting.
- Model lemah adalah pohon keputusan.
Lihat Gradient Boosted Decision Trees di kursus Decision Forests untuk mengetahui informasi selengkapnya.
gradient boosting
Algoritma pelatihan yang melatih model lemah secara iteratif untuk meningkatkan kualitas (mengurangi kerugian) model yang kuat. Misalnya, model yang lemah dapat berupa model linear atau pohon keputusan kecil. Model kuat menjadi jumlah dari semua model lemah yang dilatih sebelumnya.
Dalam bentuk gradient boosting yang paling sederhana, pada setiap iterasi, model lemah dilatih untuk memprediksi gradien kerugian model kuat. Kemudian, output model yang kuat diperbarui dengan mengurangi gradien yang diprediksi, mirip dengan penurunan gradien.
dalam hal ini:
- $F_{0}$ adalah model awal yang kuat.
- $F_{i+1}$ adalah model kuat berikutnya.
- $F_{i}$ adalah model kuat saat ini.
- $\xi$ adalah nilai antara 0,0 dan 1,0 yang disebut penyusutan, yang analog dengan kecepatan pembelajaran dalam penurunan gradien.
- $f_{i}$ adalah model lemah yang dilatih untuk memprediksi gradien kerugian $F_{i}$.
Variasi modern dari gradient boosting juga menyertakan turunan kedua (Hessian) dari loss dalam komputasinya.
Pohon keputusan biasanya digunakan sebagai model lemah dalam gradient boosting. Lihat pohon (keputusan) penguatan gradien.
pemotongan gradien
Mekanisme yang umum digunakan untuk mengurangi masalah gradien meledak dengan membatasi (memangkas) nilai maksimum gradien secara buatan saat menggunakan penurunan gradien untuk melatih model.
penurunan gradien
Teknik matematika untuk meminimalkan kerugian. Penurunan gradien menyesuaikan bobot dan bias secara berulang, yang secara bertahap menemukan kombinasi terbaik untuk meminimalkan kerugian.
Gradient descent lebih lama—jauh lebih lama—daripada machine learning.
Lihat Regresi linear: Penurunan gradien di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
grafik
Di TensorFlow, spesifikasi komputasi. Node dalam grafik merepresentasikan operasi. Edge diarahkan dan merepresentasikan penerusan hasil operasi (Tensor) sebagai operand ke operasi lain. Gunakan TensorBoard untuk memvisualisasikan grafik.
eksekusi grafik
Lingkungan pemrograman TensorFlow yang mana program mengonstruksi grafik terlebih dahulu, kemudian mengeksekusi semua atau sebagian grafik tersebut. Eksekusi grafik adalah mode eksekusi default di TensorFlow 1.x.
Berbeda dengan eksekusi segera.
kebijakan serakah
Dalam pembelajaran beruntun, kebijakan yang selalu memilih tindakan dengan pengembalian yang diharapkan tertinggi.
keterkaitan dengan data
Properti model yang outputnya didasarkan pada (berdasarkan) materi sumber tertentu. Misalnya, Anda memberikan seluruh buku teks fisika sebagai input ("konteks") ke model bahasa besar. Kemudian, Anda memberikan perintah ke model bahasa besar tersebut dengan pertanyaan fisika. Jika respons model mencerminkan informasi dalam buku teks tersebut, maka model tersebut memiliki rujukan pada buku teks tersebut.Perhatikan bahwa model berbasis fakta tidak selalu merupakan model faktual. Misalnya, buku teks fisika input dapat berisi kesalahan.
kebenaran dasar
Realitas.
Hal yang sebenarnya terjadi.
Misalnya, pertimbangkan model klasifikasi biner yang memprediksi apakah seorang mahasiswa tahun pertama di universitas akan lulus dalam waktu enam tahun. Kebenaran dasar untuk model ini adalah apakah siswa tersebut benar-benar lulus dalam waktu enam tahun atau tidak.
bias atribusi kelompok
Dengan asumsi bahwa hal yang benar bagi individu juga benar bagi semua orang dalam golongan tersebut. Efek dari bias atribusi golongan dapat diperburuk jika pengambilan sampel praktis digunakan untuk pengumpulan data. Dalam sampel bukan perwakilan, atribusi dapat dibuat yang tidak mencerminkan realitas.
Lihat juga bias kehomogenan luar golongan dan bias dalam golongan. Lihat juga Fairness: Types of bias di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
H
halusinasi
Produksi output yang tampak masuk akal, tetapi salah secara faktual oleh model AI generatif yang menyatakan membuat pernyataan tentang dunia nyata. Misalnya, model AI generatif yang mengklaim bahwa Barack Obama meninggal pada tahun 1865 berhalusinasi.
hashing
Dalam machine learning, mekanisme untuk pengelompokan data kategorik, terutama ketika jumlah kategorinya besar, tetapi jumlah kategori yang benar-benar muncul dalam set data relatif kecil.
Misalnya, Bumi merupakan rumah bagi sekitar 73.000 spesies pohon. Anda dapat merepresentasikan setiap 73.000 spesies pohon dalam 73.000 bucket kategorik yang berbeda. Atau, jika hanya ada 200 dari spesies pohon tersebut yang benar-benar muncul di set data, Anda dapat menggunakan teknik hashing untuk membagi spesies pohon menjadi sekitar 500 bucket.
Satu bucket dapat berisi beberapa spesies pohon. Misalnya, teknik hashing dapat menempatkan beringin dan cemara udang—dua spesies yang berbeda secara genetik—ke dalam bucket yang sama. Bagaimanapun juga, teknik hashing masih merupakan cara yang baik untuk memetakan set kategorik dalam jumlah besar ke jumlah bucket yang dipilih. Hashing mengubah fitur kategorik yang memiliki kemungkinan nilai dalam jumlah besar menjadi nilai dalam jumlah yang jauh lebih kecil dengan mengelompokkan nilai secara deterministik.
Lihat Data kategoris: Kosakata dan encoding one-hot di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
heuristik
Solusi sederhana dan cepat diterapkan untuk suatu masalah. Misalnya, "Dengan heuristik, kami mencapai akurasi 86%. Saat kami beralih ke jaringan neural dalam, akurasi meningkat hingga 98%."
lapisan tersembunyi
Lapisan dalam jaringan neural antara lapisan input (fitur) dan lapisan output (prediksi). Setiap lapisan tersembunyi terdiri dari satu atau beberapa neuron. Misalnya, jaringan neural berikut berisi dua lapisan tersembunyi, yang pertama dengan tiga neuron dan yang kedua dengan dua neuron:
Jaringan neural dalam berisi lebih dari satu lapisan tersembunyi. Misalnya, ilustrasi sebelumnya adalah jaringan neural dalam karena model berisi dua lapisan tersembunyi.
Lihat Jaringan neural: Node dan lapisan tersembunyi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
pengelompokan hierarkis
Kategori algoritma pengelompokan yang membuat pohon kluster. Pengelompokan hierarkis sangat cocok untuk data hierarkis, seperti taksonomi botani. Ada dua jenis algoritma pengelompokan hierarkis:
- Pengelompokan aglomeratif pertama-tama menetapkan setiap contoh ke dalam clusternya sendiri, dan secara berulang menggabungkan cluster terdekat untuk membuat pohon hierarki.
- Pengelompokan divisif mengelompokkan semua contoh ke dalam satu kluster terlebih dahulu, kemudian secara berulang membagi kluster ke dalam pohon hierarki.
Berbeda dengan pengelompokan berbasis sentroid.
Lihat Algoritma pengelompokan di kursus Pengelompokan untuk mengetahui informasi selengkapnya.
mendaki bukit
Algoritma untuk meningkatkan kualitas model ML secara berulang ("berjalan menanjak") hingga model berhenti meningkat ("mencapai puncak bukit"). Bentuk umum algoritma adalah sebagai berikut:
- Bangun model awal.
- Buat model kandidat baru dengan melakukan penyesuaian kecil pada cara Anda melatih atau menyesuaikan model. Hal ini mungkin memerlukan penggunaan kumpulan data pelatihan yang sedikit berbeda atau hyperparameter yang berbeda.
- Evaluasi model kandidat baru dan lakukan salah satu
tindakan berikut:
- Jika model kandidat berperforma lebih baik daripada model awal, model kandidat tersebut akan menjadi model awal baru. Dalam hal ini, ulangi Langkah 1, 2, dan 3.
- Jika tidak ada model yang mengungguli model awal, berarti Anda telah mencapai puncak bukit dan harus berhenti melakukan iterasi.
Lihat Panduan Penyesuaian Deep Learning untuk mendapatkan panduan tentang penyesuaian hyperparameter. Lihat modul Data di Kursus Singkat Machine Learning untuk mendapatkan panduan tentang rekayasa fitur.
kerugian engsel
Serangkaian fungsi loss untuk klasifikasi yang dirancang untuk menemukan batas keputusan sejauh mungkin dari setiap contoh pelatihan, sehingga memaksimalkan margin antara contoh dan batas. KSVMs menggunakan kerugian engsel (atau fungsi terkait, seperti kerugian engsel kuadrat). Untuk klasifikasi biner, fungsi kerugian hinge didefinisikan sebagai berikut:
dengan y adalah label sebenarnya, yaitu -1 atau +1, dan y' adalah output mentah dari model klasifikasi:
Oleh karena itu, plot kerugian engsel versus (y * y') terlihat sebagai berikut:

bias historis
Jenis bias yang sudah ada di dunia dan telah masuk ke dalam set data. Bias ini cenderung mencerminkan stereotipe budaya yang ada, ketidaksetaraan demografi, dan prasangka terhadap kelompok sosial tertentu.
Misalnya, pertimbangkan model klasifikasi yang memprediksi apakah pemohon pinjaman akan gagal membayar pinjaman atau tidak, yang dilatih menggunakan data historis gagal bayar pinjaman dari tahun 1980-an dari bank lokal di dua komunitas yang berbeda. Jika pemohon sebelumnya dari Komunitas A enam kali lebih mungkin gagal membayar pinjaman daripada pemohon dari Komunitas B, model mungkin mempelajari bias historis yang mengakibatkan model cenderung tidak menyetujui pinjaman di Komunitas A, meskipun kondisi historis yang mengakibatkan tingkat gagal bayar yang lebih tinggi di komunitas tersebut tidak lagi relevan.
Lihat Keadilan: Jenis bias di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
data pisahan
Contoh sengaja tidak digunakan ("dipisah") selama pelatihan. Set data validasi dan set data pengujian adalah contoh data pisahan. Data pisahan membantu mengevaluasi kemampuan model Anda dalam menggeneralisasi data selain data tempat model dilatih. Kerugian pada set pisahan memberikan perkiraan kerugian yang lebih baik pada set data yang tidak terlihat daripada kerugian pada set pelatihan.
host
Saat melatih model ML di chip akselerator (GPU atau TPU), bagian sistem yang mengontrol keduanya:
- Alur keseluruhan kode.
- Ekstraksi dan transformasi pipeline input.
Host biasanya berjalan di CPU, bukan di chip akselerator; perangkat memanipulasi tensor di chip akselerator.
evaluasi manual
Proses saat orang menilai kualitas output model ML; misalnya, meminta orang dwibahasa menilai kualitas model terjemahan ML. Evaluasi manusia sangat berguna untuk menilai model yang tidak memiliki satu jawaban yang benar.
Berbeda dengan evaluasi otomatis dan evaluasi autorater.
Human in the loop (HITL)
Idiom yang tidak jelas yang dapat berarti salah satu dari berikut ini:
- Kebijakan untuk melihat output AI generatif secara kritis atau skeptis.
- Strategi atau sistem untuk memastikan bahwa orang-orang membantu membentuk, mengevaluasi, dan menyempurnakan perilaku model. Dengan mempertahankan keterlibatan manusia, AI dapat memanfaatkan kecerdasan mesin dan kecerdasan manusia. Misalnya, sistem yang menggunakan AI untuk membuat kode yang kemudian ditinjau oleh software engineer adalah sistem dengan keterlibatan manusia.
hyperparameter
Variabel yang Anda atau layanan penyesuaian hyperparameter sesuaikan selama menjalankan pelatihan model berturut-turut. Misalnya, kecepatan pembelajaran adalah hyperparameter. Anda dapat menetapkan laju pembelajaran ke 0,01 sebelum satu sesi pelatihan. Jika Anda menentukan bahwa 0,01 terlalu tinggi, Anda dapat menetapkan kecepatan pembelajaran ke 0,003 untuk sesi pelatihan berikutnya.
Sebaliknya, parameter adalah berbagai bobot dan bias yang dipelajari model selama pelatihan.
Lihat Regresi linear: Hyperparameter di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
bidang hiper
Batas yang memisahkan ruang menjadi dua subruang. Misalnya, garis adalah hyperplane dalam dua dimensi dan bidang adalah hyperplane dalam tiga dimensi. Biasanya dalam machine learning, bidang-hiper adalah batas yang memisahkan ruang berdimensi tinggi. Kernel Support Vector Machines menggunakan bidang-hiper untuk memisahkan kelas positif dari kelas negatif, biasanya dalam ruang yang berdimensi sangat tinggi.
I
i.i.d.
Singkatan dari terdistribusi secara independen dan identik.
pengenalan gambar
Suatu proses yang mengklasifikasikan objek, pola, atau konsep dalam suatu gambar. Pengenalan citra juga dikenal sebagai klasifikasi gambar.
Untuk informasi selengkapnya, lihat ML Practicum: Image Classification.
Lihat kursus Praktikum ML: Klasifikasi Gambar untuk mengetahui informasi selengkapnya.
set data tidak seimbang
Sinonim untuk set data kelas tidak seimbang.
bias implisit
Secara otomatis membuat asosiasi atau asumsi berdasarkan model dan ingatan pikiran seseorang. Bias implisit dapat memengaruhi hal berikut:
- Cara data dikumpulkan dan diklasifikasikan.
- Cara sistem machine learning dirancang dan dikembangkan.
Misalnya, saat membuat model klasifikasi untuk mengidentifikasi foto pernikahan, seorang engineer dapat menggunakan keberadaan gaun putih dalam foto sebagai fitur. Namun, gaun putih hanya menjadi kebiasaan selama era tertentu dan dalam budaya tertentu.
Lihat juga bias konfirmasi.
imputasi
Bentuk singkat dari imputasi nilai.
ketidakcocokan metrik keadilan
Gagasan bahwa beberapa konsep keadilan tidak kompatibel satu sama lain dan tidak dapat dipenuhi secara bersamaan. Akibatnya, tidak ada satu metrik universal untuk mengukur keadilan yang dapat diterapkan pada semua masalah ML.
Meskipun hal ini mungkin tampak mengecewakan, ketidakcocokan metrik keadilan tidak berarti upaya keadilan tidak membuahkan hasil. Sebaliknya, hal ini menunjukkan bahwa keadilan harus ditentukan secara kontekstual untuk masalah ML tertentu, dengan tujuan mencegah bahaya khusus untuk kasus penggunaannya.
Lihat "On the (im)possibility of fairness" untuk mengetahui pembahasan yang lebih mendetail tentang ketidakcocokan metrik keadilan.
pembelajaran dalam konteks
Sinonim untuk few-shot prompting.
terdistribusi secara independen dan identik (i.i.d)
Data yang diambil dari distribusi yang tidak berubah, dan setiap nilai yang diambil tidak bergantung pada nilai yang telah diambil sebelumnya. i.i.d. adalah gas ideal machine learning—konstruksi matematis yang berguna, tetapi hampir tidak pernah ditemukan secara persis di dunia nyata. Misalnya, distribusi pengunjung halaman web mungkin terdistribusi secara independen dan identik selama jendela waktu yang singkat; artinya, distribusi tidak berubah selama jendela waktu tersebut dan kunjungan satu orang umumnya tidak bergantung pada kunjungan orang lain. Namun, jika Anda memperluas jangka waktu tersebut, perbedaan musiman pada pengunjung halaman web mungkin muncul.
Lihat juga nonstasioneritas.
keadilan individu
Metrik keadilan yang memeriksa apakah individu yang serupa diklasifikasikan secara serupa. Misalnya, Brobdingnagian Academy mungkin ingin memenuhi keadilan individu dengan memastikan bahwa dua siswa dengan nilai dan skor tes standar yang identik memiliki peluang yang sama untuk diterima.
Perhatikan bahwa keadilan individu sepenuhnya bergantung pada cara Anda mendefinisikan "kemiripan" (dalam hal ini, nilai dan skor tes), dan Anda dapat berisiko memunculkan masalah keadilan baru jika metrik kemiripan Anda melewatkan informasi penting (seperti ketelitian kurikulum siswa).
Lihat "Keadilan Melalui Kesadaran" untuk pembahasan yang lebih mendetail tentang keadilan individu.
inferensi
Dalam machine learning tradisional, proses pembuatan prediksi dengan menerapkan model terlatih ke contoh tak berlabel. Lihat Supervised Learning dalam kursus Intro to ML untuk mempelajari lebih lanjut.
Dalam model bahasa besar, inferensi adalah proses penggunaan model terlatih untuk menghasilkan respons terhadap perintah input.
Inferensi memiliki arti yang agak berbeda dalam statistik. Lihat artikel Wikipedia tentang inferensi statistik untuk mengetahui detailnya.
jalur inferensi
Dalam pohon keputusan, selama inferensi, rute yang diambil oleh contoh tertentu dari root ke kondisi lainnya, yang berakhir dengan leaf. Misalnya, dalam pohon keputusan berikut, panah yang lebih tebal menunjukkan jalur inferensi untuk contoh dengan nilai fitur berikut:
- x = 7
- y = 12
- z = -3
Jalur inferensi dalam ilustrasi berikut melewati tiga
kondisi sebelum mencapai leaf (Zeta).
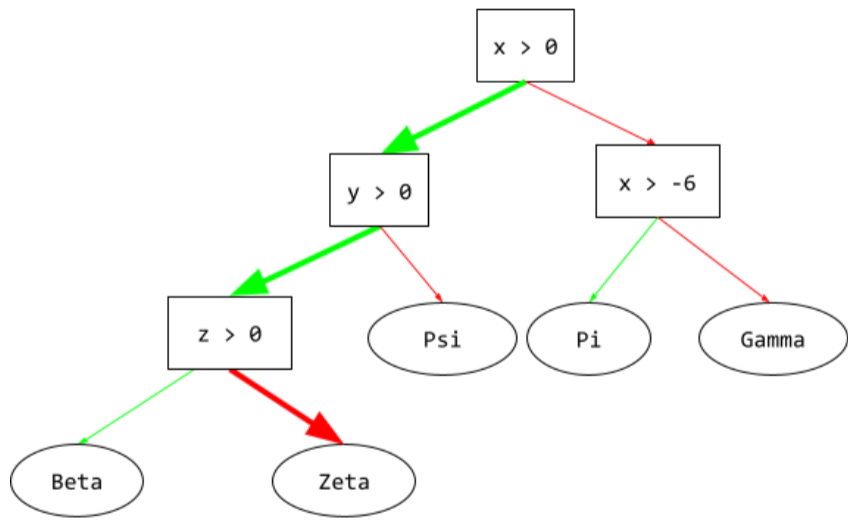
Tiga panah tebal menunjukkan jalur inferensi.
Lihat Pohon keputusan dalam kursus Decision Forests untuk mengetahui informasi selengkapnya.
perolehan informasi
Dalam hutan keputusan, perbedaan antara entropi node dan jumlah entropi node turunannya yang diberi bobot (berdasarkan jumlah contoh). Entropi node adalah entropi contoh di node tersebut.
Misalnya, pertimbangkan nilai entropi berikut:
- entropi node induk = 0,6
- entropi satu node turunan dengan 16 contoh relevan = 0,2
- entropi node turunan lain dengan 24 contoh yang relevan = 0,1
Jadi, 40% contoh berada di satu node turunan dan 60% berada di node turunan lainnya. Jadi:
- jumlah entropi berbobot dari node turunan = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Jadi, perolehan informasi adalah:
- perolehan informasi = entropi node induk - jumlah entropi tertimbang node turunan
- perolehan informasi = 0,6 - 0,14 = 0,46
Sebagian besar pemisah berupaya membuat kondisi yang memaksimalkan perolehan informasi.
bias dalam kelompok
Menunjukkan keberpihakan pada golongan atau karakteristik milik seseorang. Jika penguji atau pelabel terdiri dari teman, keluarga, atau rekan developer machine learning, bias dalam golongan dapat membatalkan validasi pengujian produk atau set data.
Bias dalam golongan adalah bentuk bias atribusi golongan. Lihat juga bias kehomogenan luar golongan.
Lihat Fairness: Types of bias di Machine Learning Crash Course untuk mengetahui informasi selengkapnya.
generator input
Mekanisme yang digunakan untuk memuat data ke dalam jaringan neural.
Generator input dapat dianggap sebagai komponen yang bertanggung jawab untuk memproses data mentah menjadi tensor yang diulang untuk menghasilkan batch untuk pelatihan, evaluasi, dan inferensi.
lapisan input
Lapisan jaringan neural yang berisi vektor fitur. Artinya, lapisan input menyediakan contoh untuk pelatihan atau inferensi. Misalnya, lapisan input dalam jaringan neural berikut terdiri dari dua fitur:
kondisi dalam set
Dalam pohon keputusan, kondisi yang menguji keberadaan satu item dalam sekumpulan item. Misalnya, berikut adalah kondisi dalam set:
house-style in [tudor, colonial, cape]
Selama inferensi, jika nilai fitur
gaya rumah adalah tudor atau colonial atau cape, kondisi ini akan bernilai Ya. Jika
nilai fitur gaya visual adalah sesuatu yang lain (misalnya, ranch),
maka kondisi ini akan bernilai Tidak.
Kondisi dalam set biasanya menghasilkan pohon keputusan yang lebih efisien daripada kondisi yang menguji fitur berenkode one-hot.
instance
Sinonim untuk contoh.
penyesuaian instruksi
Bentuk penyesuaian yang meningkatkan kemampuan model AI generatif dalam mengikuti petunjuk. Penyesuaian perintah melibatkan pelatihan model pada serangkaian perintah instruksi, yang biasanya mencakup berbagai tugas. Model yang disesuaikan dengan petunjuk ini kemudian cenderung menghasilkan respons yang berguna terhadap perintah zero-shot di berbagai tugas.
Bandingkan dan bedakan dengan:
dapat ditafsirkan
Kemampuan untuk menjelaskan atau mempresentasikan alasan model ML dalam istilah yang dapat dipahami oleh manusia.
Sebagian besar model regresi linear, misalnya, sangat mudah ditafsirkan. (Anda hanya perlu melihat bobot terlatih untuk setiap fitur.) Hutan keputusan juga sangat mudah ditafsirkan. Namun, beberapa model memerlukan visualisasi yang rumit agar dapat ditafsirkan.
Anda dapat menggunakan Learning Interpretability Tool (LIT) untuk menafsirkan model ML.
kecocokan antar-pelabel
Pengukuran seberapa sering pemberi rating manusia menyetujui saat melakukan tugas. Jika penilai tidak setuju, petunjuk tugas mungkin perlu ditingkatkan. Terkadang disebut juga kecocokan antar-anotator atau reliabilitas antar-pelabel. Lihat juga kappa Cohen, yang merupakan salah satu pengukuran kecocokan antar-pelabel yang paling populer.
Lihat Data kategoris: Masalah umum di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
intersection over union (IoU)
Irisan dua himpunan dibagi dengan gabungannya. Dalam tugas deteksi gambar machine learning, IoU digunakan untuk mengukur akurasi kotak pembatas yang diprediksi model sehubungan dengan kotak pembatas kebenaran nyata. Dalam hal ini, IoU untuk dua kotak adalah rasio antara area yang tumpang-tindih dan total area, dan nilainya berkisar dari 0 (tidak ada tumpang-tindih antara kotak pembatas yang diprediksi dan kotak pembatas kebenaran dasar) hingga 1 (kotak pembatas yang diprediksi dan kotak pembatas kebenaran dasar memiliki koordinat yang sama persis).
Misalnya, pada gambar di bawah:
- Kotak pembatas yang diprediksi (koordinat yang membatasi lokasi meja samping tempat tidur dalam lukisan yang diprediksi model) diuraikan dengan warna ungu.
- Kotak pembatas kebenaran dasar (koordinat yang membatasi lokasi sebenarnya meja malam dalam lukisan) diuraikan dengan warna hijau.
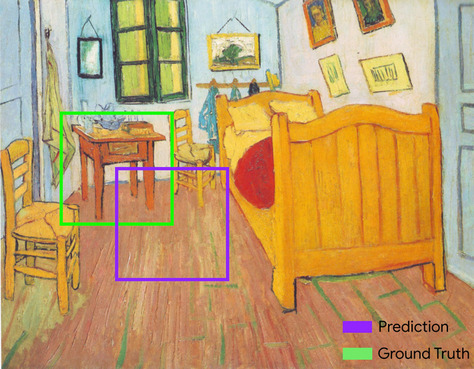
Di sini, perpotongan kotak pembatas untuk prediksi dan kebenaran dasar (kiri bawah) adalah 1, dan gabungan kotak pembatas untuk prediksi dan kebenaran dasar (kanan bawah) adalah 7, sehingga IoU-nya adalah \(\frac{1}{7}\).

IoU
Singkatan untuk intersection over union.
matriks item
Dalam sistem rekomendasi, matriks vektor sematan yang dihasilkan oleh faktorisasi matriks yang menyimpan sinyal laten tentang setiap item. Setiap baris matriks item memiliki nilai fitur laten tunggal untuk semua item. Misalnya, pertimbangkan sistem rekomendasi film. Setiap kolom dalam matriks item mewakili satu film. Sinyal laten mungkin merepresentasikan genre, atau mungkin merupakan sinyal yang lebih sulit ditafsirkan yang melibatkan interaksi kompleks antara genre, bintang, usia film, atau faktor lainnya.
Matriks item memiliki jumlah kolom yang sama dengan matriks target yang sedang difaktorisasi. Misalnya, mengingat sistem rekomendasi film yang mengevaluasi 10.000 judul film, matriks item akan memiliki 10.000 kolom.
item
Dalam sistem rekomendasi, entitas yang direkomendasikan oleh sistem. Misalnya, video adalah item yang direkomendasikan oleh toko video, sedangkan buku adalah item yang direkomendasikan oleh toko buku.
iterasi
Satu pembaruan parameter model—bobot dan bias model—selama pelatihan. Ukuran tumpukan menentukan jumlah contoh yang diproses model dalam satu iterasi. Misalnya, jika ukuran batch adalah 20, model akan memproses 20 contoh sebelum menyesuaikan parameter.
Saat melatih jaringan neural, satu iterasi melibatkan dua proses berikut:
- Penerusan maju untuk mengevaluasi kerugian pada satu batch.
- Pass mundur (propagasi mundur) untuk menyesuaikan parameter model berdasarkan kerugian dan kecepatan pembelajaran.
Lihat Penurunan gradien di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
J
JAX
Library komputasi array, yang menggabungkan XLA (Accelerated Linear Algebra) dan diferensiasi otomatis untuk komputasi numerik berperforma tinggi. JAX menyediakan API yang sederhana dan canggih untuk menulis kode numerik yang dipercepat dengan transformasi yang dapat dikomposisikan. JAX menyediakan fitur seperti:
grad(diferensiasi otomatis)jit(kompilasi tepat waktu)vmap(vektorisasi atau pengelompokan otomatis)pmap(paralelisasi)
JAX adalah bahasa untuk mengekspresikan dan menyusun transformasi kode numerik, yang serupa—tetapi cakupannya jauh lebih besar—dengan library NumPy Python. (Sebenarnya, library .numpy di JAX secara fungsional setara, tetapi merupakan versi yang ditulis ulang sepenuhnya dari library Python NumPy.)
JAX sangat cocok untuk mempercepat banyak tugas machine learning dengan mengubah model dan data menjadi bentuk yang sesuai untuk paralelisme di seluruh GPU dan TPU chip akselerator.
Flax, Optax, Pax, dan banyak library lainnya dibangun di infrastruktur JAX.
K
Keras
API machine learning Python yang populer. Keras berjalan pada beberapa framework deep learning, termasuk TensorFlow, yang mana tersedia sebagai tf.keras.
Kernel Support Vector Machines (KSVM)
Algoritma klasifikasi yang berupaya memaksimalkan margin antara kelas positif dan kelas negatif dengan memetakan vektor data masukan ke ruang berdimensi yang lebih tinggi. Misalnya, pertimbangkan masalah klasifikasi yang mana set data masukan memiliki seratus fitur. Untuk memaksimalkan margin antara kelas positif dan negatif, KSVM dapat secara internal memetakan fitur tersebut dalam ruang satu juta dimensi. KSVMs menggunakan fungsi kerugian yang disebut kerugian engsel.
keypoint
Koordinat fitur tertentu dalam gambar. Misalnya, untuk model pengenalan gambar yang membedakan spesies bunga, titik utama dapat berupa pusat setiap kelopak, batang, benang sari, dan sebagainya.
Validasi silang k-fold
Algoritma untuk memprediksi kemampuan model dalam melakukan generalisasi ke data baru. k dalam k-fold mengacu pada jumlah grup yang sama yang Anda bagi menjadi contoh set data; yaitu, Anda melatih dan menguji model k kali. Untuk setiap putaran pelatihan dan pengujian, grup yang berbeda akan menjadi set pengujian, dan semua grup yang tersisa akan menjadi set pelatihan. Setelah k putaran pelatihan dan pengujian, Anda menghitung rata-rata dan standar deviasi dari metrik pengujian yang dipilih.
Misalnya, anggaplah set data Anda terdiri dari 120 contoh. Selanjutnya, misalkan Anda memutuskan untuk menetapkan k ke 4. Oleh karena itu, setelah mengacak contoh, Anda membagi set data menjadi empat kelompok yang sama dengan 30 contoh dan melakukan empat putaran pelatihan dan pengujian:
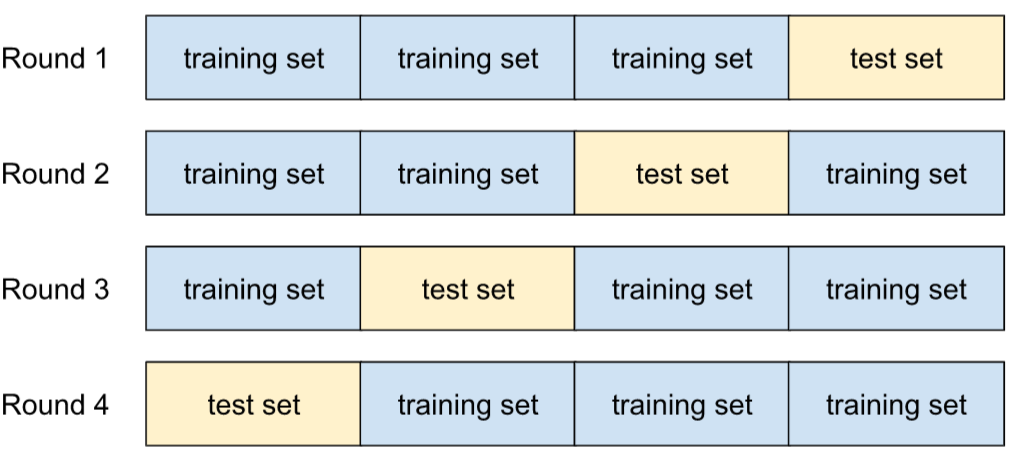
Misalnya, Mean Squared Error (MSE) mungkin menjadi metrik yang paling bermakna untuk model regresi linear. Oleh karena itu, Anda akan menemukan rata-rata dan standar deviasi MSE di keempat putaran.
k-means
Algoritma pengelompokan populer yang mengelompokkan contoh dalam unsupervised learning. Algoritma k-means pada dasarnya melakukan hal berikut:
- Secara berulang menentukan titik tengah k terbaik (dikenal sebagai sentroid).
- Menetapkan setiap contoh ke sentroid terdekat. Contoh yang paling dekat dengan centroid yang sama termasuk dalam grup yang sama.
Algoritma k-means memilih lokasi sentroid untuk meminimalkan kumulatif kuadrat jarak dari setiap contoh ke sentroid terdekatnya.
Misalnya, perhatikan plot tinggi terhadap lebar berikut:

Jika k=3, algoritma k-means akan menentukan tiga sentroid. Setiap contoh ditetapkan ke sentroid terdekatnya, sehingga menghasilkan tiga grup:

Bayangkan jika produsen ingin menentukan ukuran ideal untuk sweater kecil, sedang, dan besar. Tiga centroid mengidentifikasi tinggi rata-rata dan lebar rata-rata setiap dalam cluster tersebut. Jadi, produsen mungkin harus mendasarkan ukuran sweter pada tiga sentroid tersebut. Perhatikan bahwa sentroid cluster biasanya bukan contoh dalam cluster.
Ilustrasi sebelumnya menunjukkan k-means untuk contoh dengan hanya dua fitur (tinggi dan lebar). Perhatikan bahwa k-means dapat mengelompokkan contoh di banyak fitur.
Lihat Apa yang dimaksud dengan pengelompokan k-means? di kursus Pengelompokan untuk mengetahui informasi selengkapnya.
k-median
Algoritma pengelompokan yang sangat terkait dengan k-means. Perbedaan praktis antara keduanya adalah sebagai berikut:
- Dalam k-means, sentroid ditentukan dengan meminimalkan jumlah kuadrat jarak antara kandidat sentroid dan setiap contohnya.
- Dalam k-median, sentroid ditentukan dengan meminimalkan jumlah jarak antara kandidat sentroid dan setiap contohnya.
Perhatikan bahwa definisi jarak juga berbeda:
- k-means bergantung pada jarak Euclid dari sentroid ke contoh. (Dalam dua dimensi, jarak Euclid berarti menggunakan teorema Pythagoras untuk menghitung sisi miring.) Misalnya, jarak k-means antara (2,2) dan (5,-2) adalah:
- k-median bergantung pada jarak Manhattan dari sentroid ke contoh. Jarak ini adalah jumlah delta absolut di setiap dimensi. Misalnya, jarak k-median antara (2,2) dan (5,-2) adalah:
L
Regularisasi L0
Jenis regularisasi yang mengurangi jumlah total bobot bukan nol dalam model. Misalnya, model yang memiliki 11 bobot bukan nol akan dikenai penalti lebih besar daripada model serupa yang memiliki 10 bobot bukan nol.
Regularisasi L0 terkadang disebut regularisasi norma L0.
Kerugian L1
Fungsi kerugian yang menghitung nilai absolut dari perbedaan antara nilai label aktual dan nilai yang diprediksi oleh model. Misalnya, berikut adalah penghitungan kerugian L1 untuk batch lima contoh:
| Nilai sebenarnya contoh | Nilai yang diprediksi model | Nilai absolut delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = kerugian L1 | ||
Kerugian L1 kurang sensitif terhadap pencilan daripada kerugian L2.
Mean Absolute Error adalah rata-rata kerugian L1 per contoh.
Lihat Regresi linear: Loss di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Regularisasi L1
Jenis regularisasi yang mengganjar bobot sesuai dengan jumlah nilai absolut dari bobot. Regularisasi L1 membantu mendorong bobot fitur yang tidak relevan atau hampir tidak relevan menjadi persis 0. Fitur dengan bobot 0 akan dihapus secara efektif dari model.
Berbeda dengan regularisasi L2.
Kerugian L2
Fungsi kerugian yang menghitung kuadrat perbedaan antara nilai label aktual dan nilai yang diprediksi oleh model. Misalnya, berikut adalah penghitungan kerugian L2 untuk batch lima contoh:
| Nilai sebenarnya contoh | Nilai yang diprediksi model | Kuadrat delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = kerugian L2 | ||
Karena adanya kuadrat, kerugian L2 memperkuat pengaruh pencilan. Artinya, kerugian L2 bereaksi lebih kuat terhadap prediksi yang buruk daripada kerugian L1. Misalnya, kerugian L1 untuk batch sebelumnya adalah 8, bukan 16. Perhatikan bahwa satu pencilan menyumbang 9 dari 16.
Model regresi biasanya menggunakan kerugian L2 sebagai fungsi kerugian.
Rataan Kuadrat Galat adalah rata-rata kerugian L2 per contoh. Kerugian kuadrat adalah nama lain untuk kerugian L2.
Lihat Regresi logistik: Loss dan regularisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Regularisasi L2
Jenis regularisasi yang mengganjar bobot sesuai dengan jumlah kuadrat bobot. Regularisasi L2 membantu mendorong bobot pencilan (bobot dengan nilai positif tinggi atau negatif rendah) lebih dekat ke 0, tetapi tidak benar-benar 0. Fitur dengan nilai yang sangat mendekati 0 tetap ada dalam model, tetapi tidak terlalu memengaruhi prediksi model.
Regularisasi L2 selalu meningkatkan generalisasi dalam model linear.
Berbeda dengan regularisasi L1.
Lihat Overfitting: Regularisasi L2 di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
label
Dalam supervised machine learning, bagian "jawaban" atau "hasil" dari contoh.
Setiap contoh berlabel terdiri dari satu atau beberapa fitur dan satu label. Misalnya, dalam set data deteksi spam, label mungkin berupa "spam" atau "bukan spam". Dalam set data curah hujan, labelnya mungkin berupa jumlah hujan yang turun selama periode tertentu.
Lihat Supervised Learning di Pengantar Machine Learning untuk mengetahui informasi selengkapnya.
contoh berlabel
Contoh yang berisi satu atau beberapa fitur dan label. Misalnya, tabel berikut menunjukkan tiga contoh berlabel dari model penilaian rumah, yang masing-masing memiliki tiga fitur dan satu label:
| Jumlah kamar | Jumlah kamar mandi | Usia rumah | Harga rumah (label) |
|---|---|---|---|
| 3 | 2 | 15 | $345.000 |
| 2 | 1 | 72 | $179.000 |
| 4 | 2 | 34 | $392.000 |
Dalam supervised machine learning, model dilatih pada contoh berlabel dan membuat prediksi pada contoh tak berlabel.
Bandingkan contoh berlabel dengan contoh yang tidak berlabel.
Lihat Supervised Learning di Pengantar Machine Learning untuk mengetahui informasi selengkapnya.
kebocoran label
Cacat desain model yang mana fitur adalah proxy untuk
label. Misalnya, pertimbangkan model
klasifikasi biner yang memprediksi
apakah calon pelanggan akan membeli produk tertentu atau tidak.
Misalkan salah satu fitur untuk model adalah Boolean bernama
SpokeToCustomerAgent. Selanjutnya, misalkan agen pelanggan hanya ditugaskan setelah calon pelanggan benar-benar membeli produk. Selama pelatihan, model akan dengan cepat mempelajari hubungan antara SpokeToCustomerAgent dan label.
Lihat Memantau pipeline di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
lambda
Sinonim dari derajat regularisasi.
Lambda adalah istilah yang kelebihan muatan. Di sini kita berfokus pada definisi istilah dalam regularisasi.
LaMDA (Language Model for Dialogue Applications)
Model bahasa besar berbasis Transformer yang dikembangkan oleh Google dan dilatih menggunakan set data dialog besar yang dapat menghasilkan respons percakapan yang realistis.
LaMDA: our breakthrough conversation technology memberikan ringkasan.
tempat terkenal
Sinonim untuk titik-titik penting.
model bahasa
Model yang memperkirakan probabilitas token atau urutan token yang terjadi dalam urutan token yang lebih panjang.
Lihat Apa yang dimaksud dengan model bahasa? di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
model bahasa besar
Setidaknya, model bahasa yang memiliki parameter dalam jumlah yang sangat besar. Secara lebih informal, model bahasa berbasis Transformer, seperti Gemini atau GPT.
Lihat Model bahasa besar (LLM) di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
latensi
Waktu yang dibutuhkan model untuk memproses input dan menghasilkan respons. Respons latensi tinggi memerlukan waktu lebih lama untuk dihasilkan daripada respons latensi rendah.
Faktor-faktor yang memengaruhi latensi model bahasa besar meliputi:
- Panjang input dan output [token]
- Kompleksitas model
- Infrastruktur tempat model berjalan
Mengoptimalkan latensi sangat penting untuk membuat aplikasi yang responsif dan mudah digunakan.
ruang laten
Sinonim untuk ruang sematan.
lapisan
Sekumpulan neuron dalam jaringan neural. Tiga jenis lapisan umum adalah sebagai berikut:
- Input layer, yang memberikan nilai untuk semua fitur.
- Satu atau beberapa lapisan tersembunyi, yang menemukan hubungan non-linear antara fitur dan label.
- Lapisan output, yang memberikan prediksi.
Misalnya, ilustrasi berikut menunjukkan jaringan neural dengan satu lapisan input, dua lapisan tersembunyi, dan satu lapisan output:
Di TensorFlow, lapisan juga merupakan fungsi Python yang menggunakan Tensor dan opsi konfigurasi sebagai input dan menghasilkan tensor lain sebagai output.
Layers API (tf.layers)
TensorFlow API untuk mengonstruksi jaringan neural dalam sebagai komposisi lapisan. Layers API memungkinkan Anda membuat berbagai jenis lapisan, seperti:
tf.layers.Denseuntuk lapisan terhubung sepenuhnya.tf.layers.Conv2Duntuk lapisan konvolusional.
Layers API mengikuti konvensi Keras layers API. Artinya, selain awalan yang berbeda, semua fungsi di Layers API memiliki nama dan tanda tangan yang sama dengan fungsi yang setara di Keras Layers API.
daun
Endpoint apa pun dalam pohon keputusan. Tidak seperti kondisi, leaf tidak melakukan pengujian. Sebaliknya, daun adalah kemungkinan prediksi. Leaf juga merupakan node terminal dari jalur inferensi.
Misalnya, pohon keputusan berikut berisi tiga daun:
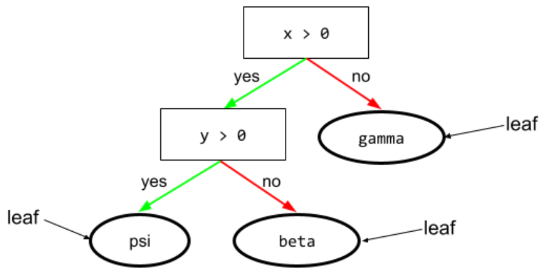
Lihat Pohon keputusan dalam kursus Decision Forests untuk mengetahui informasi selengkapnya.
Learning Interpretability Tool (LIT)
Alat visual dan interaktif untuk pemahaman model dan visualisasi data.
Anda dapat menggunakan LIT open source untuk menafsirkan model atau memvisualisasikan data teks, gambar, dan tabel.
kecepatan pembelajaran
Angka floating point yang memberi tahu algoritma penurunan gradien seberapa kuat penyesuaian bobot dan bias pada setiap iterasi. Misalnya, kecepatan pembelajaran 0,3 akan menyesuaikan bobot dan bias tiga kali lebih kuat daripada kecepatan pembelajaran 0,1.
Kecepatan pembelajaran adalah hyperparameter utama. Jika Anda menyetel kecepatan pembelajaran terlalu rendah, pelatihan akan memakan waktu terlalu lama. Jika Anda menetapkan kecepatan pembelajaran terlalu tinggi, penurunan gradien sering kali kesulitan mencapai konvergensi.
Lihat Regresi linear: Hyperparameter di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
regresi kuadrat terkecil
Model regresi linear yang dilatih dengan meminimalkan Kerugian L2.
Jarak Levenshtein
Metrik jarak pengeditan yang menghitung operasi hapus, sisipkan, dan ganti paling sedikit yang diperlukan untuk mengubah satu kata menjadi kata lain. Misalnya, jarak Levenshtein antara kata "hati" dan "panah" adalah tiga karena tiga pengeditan berikut adalah perubahan paling sedikit untuk mengubah satu kata menjadi kata lainnya:
- heart → deart (ganti "h" dengan "d")
- deart → dart (hapus "e")
- dart → darts (sisipkan "s")
Perhatikan bahwa urutan sebelumnya bukan satu-satunya jalur tiga pengeditan.
linier
Hubungan antara dua variabel atau lebih yang dapat direpresentasikan hanya melalui penjumlahan dan perkalian.
Plot hubungan linear adalah garis.
Berbeda dengan nonlinier.
model linear
Model yang menetapkan satu bobot per fitur untuk membuat prediksi. (Model linear juga menyertakan bias.) Sebaliknya, hubungan fitur dengan prediksi dalam model dalam umumnya non-linear.
Model linear biasanya lebih mudah dilatih dan lebih dapat ditafsirkan daripada model dalam. Namun, model deep dapat mempelajari hubungan yang kompleks antar fitur.
Regresi linear dan regresi logistik adalah dua jenis model linear.
regresi linear
Jenis model machine learning yang memenuhi kedua kondisi berikut:
- Modelnya adalah model linear.
- Prediksi adalah nilai floating-point. (Ini adalah bagian regresi dari regresi linear.)
Bandingkan regresi linear dengan regresi logistik. Selain itu, bandingkan regresi dengan klasifikasi.
Lihat Regresi linear di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
LIT
Singkatan untuk Learning Interpretability Tool (LIT), yang sebelumnya dikenal sebagai Language Interpretability Tool.
LLM
Singkatan dari model bahasa besar.
Evaluasi LLM (evaluasi)
Serangkaian metrik dan tolok ukur untuk menilai performa model bahasa besar (LLM). Secara umum, evaluasi LLM:
- Membantu peneliti mengidentifikasi area yang perlu ditingkatkan pada LLM.
- Berguna dalam membandingkan berbagai LLM dan mengidentifikasi LLM terbaik untuk tugas tertentu.
- Membantu memastikan bahwa LLM aman dan etis untuk digunakan.
Lihat Model bahasa besar (LLM) di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
regresi logistik
Jenis model regresi yang memprediksi probabilitas. Model regresi logistik memiliki karakteristik berikut:
- Labelnya adalah kategoris. Istilah regresi logistik biasanya mengacu pada regresi logistik biner, yaitu, pada model yang menghitung probabilitas untuk label dengan dua kemungkinan nilai. Varian yang kurang umum, regresi logistik multinomial, menghitung probabilitas untuk label dengan lebih dari dua kemungkinan nilai.
- Fungsi kerugian selama pelatihan adalah Kerugian Log. (Beberapa unit Log Loss dapat ditempatkan secara paralel untuk label dengan lebih dari dua kemungkinan nilai.)
- Model memiliki arsitektur linear, bukan deep neural network. Namun, bagian lain dari definisi ini juga berlaku untuk model dalam yang memprediksi probabilitas untuk label kategoris.
Misalnya, pertimbangkan model regresi logistik yang menghitung probabilitas email input sebagai spam atau bukan spam. Selama inferensi, misalkan model memprediksi 0,72. Oleh karena itu, model memperkirakan:
- Peluang email tersebut adalah spam sebesar 72%.
- Peluang 28% bahwa email tersebut bukan spam.
Model regresi logistik menggunakan arsitektur dua langkah berikut:
- Model menghasilkan prediksi mentah (y') dengan menerapkan fungsi linear fitur input.
- Model menggunakan prediksi mentah tersebut sebagai input ke fungsi sigmoid, yang mengonversi prediksi mentah menjadi nilai antara 0 dan 1, secara eksklusif.
Seperti model regresi lainnya, model regresi logistik memprediksi angka. Namun, angka ini biasanya menjadi bagian dari model klasifikasi biner sebagai berikut:
- Jika angka yang diprediksi lebih besar daripada nilai minimum klasifikasi, model klasifikasi biner memprediksi kelas positif.
- Jika angka yang diprediksi kurang dari nilai minimum klasifikasi, model klasifikasi biner memprediksi kelas negatif.
Lihat Regresi logistik di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
logits
Vektor prediksi mentah (tidak dinormalisasi) yang dihasilkan model klasifikasi, yang biasanya kemudian diteruskan ke fungsi normalisasi. Jika model memecahkan masalah klasifikasi multikelas, logits biasanya menjadi input ke fungsi softmax. Fungsi softmax kemudian menghasilkan vektor probabilitas (yang dinormalisasi) dengan satu nilai untuk setiap kemungkinan kelas.
Kerugian Log
Fungsi kerugian yang digunakan dalam regresi logistik biner.
Lihat Regresi logistik: Loss dan regularisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
log-peluang
Logaritma peluang suatu peristiwa.
Long Short-Term Memory (LSTM)
Jenis sel dalam jaringan neural berulang yang digunakan untuk memproses urutan data dalam aplikasi seperti pengenalan tulisan tangan, terjemahan mesin, dan pemberian teks pada gambar. LSTM mengatasi masalah gradien yang hilang yang terjadi saat melatih RNN karena urutan data yang panjang dengan mempertahankan histori dalam status memori internal berdasarkan input baru dan konteks dari sel sebelumnya dalam RNN.
LoRA
Singkatan dari Low-Rank Adaptability.
kalah
Selama pelatihan model yang diawasi, ukuran seberapa jauh prediksi model dari labelnya.
Fungsi kerugian menghitung kerugian.
Lihat Regresi linear: Loss di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
agregator kerugian
Jenis algoritma machine learning yang meningkatkan performa model dengan menggabungkan prediksi beberapa model dan menggunakan prediksi tersebut untuk membuat satu prediksi. Akibatnya, penggabung kerugian dapat mengurangi varians prediksi dan meningkatkan akurasi prediksi.
kurva kerugian
Plot loss sebagai fungsi jumlah iterasi pelatihan. Plot berikut menunjukkan kurva kerugian yang umum:
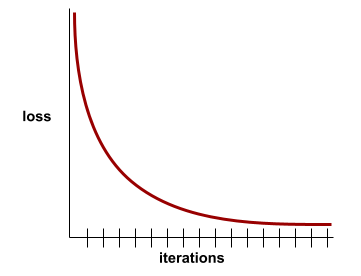
Kurva kerugian dapat membantu Anda menentukan kapan model Anda berkonvergensi atau overfitting.
Kurva kerugian dapat memetakan semua jenis kerugian berikut:
Lihat juga kurva generalisasi.
Lihat Overfitting: Menafsirkan kurva kerugian di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
fungsi kerugian
Selama pelatihan atau pengujian, fungsi matematika yang menghitung kerugian pada batch contoh. Fungsi kerugian menampilkan kerugian yang lebih rendah untuk model yang membuat prediksi baik daripada model yang membuat prediksi buruk.
Tujuan pelatihan biasanya adalah untuk meminimalkan kerugian yang dihasilkan oleh fungsi kerugian.
Ada banyak jenis fungsi kerugian. Pilih fungsi kerugian yang sesuai untuk jenis model yang Anda buat. Contoh:
- Kerugian L2 (atau Rataan Kuadrat Galat) adalah fungsi kerugian untuk regresi linear.
- Kerugian Log adalah fungsi kerugian untuk regresi logistik.
permukaan kerugian
Grafik bobot vs. kerugian. Penurunan gradien bertujuan untuk menemukan bobot saat permukaan penyimpangan berada pada minimum lokal.
efek hilang di tengah (lost-in-the-middle effect)
Kecenderungan LLM untuk menggunakan informasi dari awal dan akhir jendela konteks yang panjang secara lebih efektif daripada informasi dari tengah. Artinya, dengan konteks yang panjang, efek hilang di tengah menyebabkan akurasi menjadi:
- Relatif tinggi jika informasi yang relevan untuk membentuk respons berada di dekat awal atau akhir konteks.
- Relatif rendah jika informasi yang relevan untuk membentuk respons berada di tengah konteks.
Istilah ini berasal dari Lost in the Middle: How Language Models Use Long Contexts.
Adaptasi Peringkat Rendah (LoRA)
Teknik efisien parameter untuk penyesuaian yang "membekukan" bobot model yang telah dilatih sebelumnya (sehingga tidak dapat lagi diubah) lalu menyisipkan sekumpulan kecil bobot yang dapat dilatih ke dalam model. Kumpulan bobot yang dapat dilatih ini (juga dikenal sebagai "matriks update") jauh lebih kecil daripada model dasar dan oleh karena itu, pelatihan jauh lebih cepat.
LoRA memberikan manfaat berikut:
- Meningkatkan kualitas prediksi model untuk domain tempat penyesuaian diterapkan.
- Penyesuaian lebih cepat daripada teknik yang memerlukan penyesuaian semua parameter model.
- Mengurangi biaya komputasi inferensi dengan memungkinkan penyajian serentak beberapa model khusus yang berbagi model dasar yang sama.
LSTM
Singkatan dari Long Short-Term Memory.
M
machine learning
Program atau sistem yang melatih model dari data input. Model terlatih dapat menghasilkan prediksi yang bermanfaat dari data baru (yang belum pernah dilihat) yang diambil dari distribusi yang sama dengan yang digunakan untuk melatih model.
Machine learning juga merujuk pada bidang studi yang berkaitan dengan program atau sistem ini.
Lihat kursus Pengantar Machine Learning untuk mengetahui informasi selengkapnya.
terjemahan mesin
Menggunakan software (biasanya, model machine learning) untuk mengonversi teks dari satu bahasa manusia ke bahasa manusia lain, misalnya, dari bahasa Inggris ke bahasa Jepang.
kelas mayoritas
Label yang lebih umum dalam set data kelas tidak seimbang. Misalnya, dalam set data yang berisi 99% label negatif dan 1% label positif, label negatif adalah kelas mayoritas.
Berbeda dengan kelas minoritas.
Lihat Set data: Set data tidak seimbang di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Proses keputusan Markov (MDP)
Grafik yang merepresentasikan model pengambilan keputusan di mana keputusan (atau tindakan) diambil untuk menavigasi urutan status dengan asumsi bahwa properti Markov berlaku. Dalam reinforcement learning, transisi antar-status ini menampilkan reward numerik.
Properti Markov
Properti lingkungan tertentu, tempat transisi status ditentukan sepenuhnya oleh informasi implisit dalam status saat ini dan tindakan agen.
model bahasa yang disamarkan
Model bahasa yang memprediksi probabilitas token kandidat untuk mengisi bagian yang kosong dalam sebuah urutan. Misalnya, model bahasa yang di-masking dapat menghitung probabilitas untuk kandidat kata yang akan menggantikan garis bawah dalam kalimat berikut:
____ dalam topi kembali.
Literatur biasanya menggunakan string "MASK" dan bukan garis bawah. Contoh:
"MASK" di topi kembali muncul.
Sebagian besar model bahasa yang di-masking modern bersifat bidireksional.
matplotlib
Library perencanaan 2D Python open source. matplotlib membantu Anda memvisualisasikan berbagai aspek machine learning.
faktorisasi matriks
Dalam matematika, mekanisme untuk menemukan matriks yang produk titiknya mendekati matriks target.
Dalam sistem rekomendasi, matriks target sering kali menyimpan rating pengguna pada item. Misalnya, matriks target untuk sistem rekomendasi film mungkin terlihat seperti berikut, yang mana bilangan bulat positif adalah rating pengguna dan 0 berarti bahwa pengguna tidak menilai film:
| Casablanca | The Philadelphia Story | Black Panther | Wonder Woman | Pulp Fiction | |
|---|---|---|---|---|---|
| Pengguna 1 | 5,0 | 3.0 | 0,0 | 2.0 | 0,0 |
| Pengguna 2 | 4.0 | 0,0 | 0,0 | 1.0 | 5,0 |
| Pengguna 3 | 3.0 | 1.0 | 4.0 | 5,0 | 0,0 |
Sistem rekomendasi film bertujuan untuk memprediksi rating pengguna untuk film yang belum diberi rating. Misalnya, apakah Pengguna 1 akan menyukai Black Panther?
Salah satu pendekatan untuk sistem rekomendasi adalah menggunakan faktorisasi matriks untuk menghasilkan dua matriks berikut:
- Matriks pengguna, dibentuk dari jumlah pengguna X jumlah dimensi embedding.
- Matriks item, dibentuk dari jumlah dimensi embedding X jumlah item.
Misalnya, menggunakan faktorisasi matriks pada tiga pengguna dan lima item dapat menghasilkan matriks pengguna dan matriks item berikut:
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
Produk titik matriks pengguna dan matriks item menghasilkan matriks rekomendasi yang tidak hanya berisi rating pengguna asli, tetapi juga prediksi untuk film yang belum ditonton setiap pengguna. Misalnya, pertimbangkan rating Pengguna 1 untuk Casablanca, yaitu 5.0. Perkalian titik yang sesuai dengan sel tersebut dalam matriks rekomendasi diharapkan berkisar 5.0, dan memang demikian:
(1.1 * 0.9) + (2.3 * 1.7) = 4.9Lebih penting lagi, apakah Pengguna 1 akan menyukai Black Panther? Mengambil produk titik yang sesuai dengan baris pertama dan kolom ketiga akan menghasilkan prediksi rating 4,3:
(1.1 * 1.4) + (2.3 * 1.2) = 4.3Faktorisasi matriks biasanya menghasilkan matriks pengguna dan matriks item yang, jika digabungkan, jauh lebih ringkas daripada matriks target.
Rata-Rata Error Absolut (MAE)
Rata-rata kerugian per contoh saat L1 loss digunakan. Hitung Rata-Rata Error Absolut sebagai berikut:
- Menghitung kerugian L1 untuk batch.
- Membagi kerugian L1 dengan jumlah contoh dalam batch.
Misalnya, pertimbangkan penghitungan kerugian L1 pada batch lima contoh berikut:
| Nilai sebenarnya contoh | Nilai yang diprediksi model | Kerugian (perbedaan antara nilai aktual dan prediksi) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = kerugian L1 | ||
Jadi, kerugian L1 adalah 8 dan jumlah contohnya adalah 5. Oleh karena itu, Rata-Rata Error Absolut adalah:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Bandingkan Galat Mutlak Rataan dengan Rataan Kuadrat Galat dan Galat Akar Rataan Kuadrat.
presisi rata-rata pada k (mAP@k)
Rata-rata statistik dari semua skor presisi rata-rata pada k di seluruh set data validasi. Salah satu penggunaan presisi rata-rata mean pada k adalah untuk menilai kualitas rekomendasi yang dihasilkan oleh sistem rekomendasi.
Meskipun frasa "rata-rata" terdengar berlebihan, nama metrik ini sudah tepat. Bagaimanapun, metrik ini menemukan rata-rata dari beberapa nilai presisi rata-rata pada k.
Rataan Kuadrat Galat (MSE)
Rata-rata kerugian per contoh saat L2 loss digunakan. Hitung Rataan Kuadrat Galat (RKG) sebagai berikut:
- Menghitung kerugian L2 untuk batch.
- Membagi kerugian L2 dengan jumlah contoh dalam batch.
Misalnya, pertimbangkan kerugian pada batch lima contoh berikut:
| Nilai sebenarnya | Prediksi model | Kerugian | Kerugian kuadrat |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = kerugian L2 | |||
Oleh karena itu, Rataan Kuadrat Galat adalah:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
Rataan Kuadrat Galat adalah pengoptimal pelatihan yang populer, terutama untuk regresi linear.
Bandingkan Rataan Kuadrat Galat dengan Rataan Galat Absolut dan Galat Akar Rataan Kuadrat.
TensorFlow Playground menggunakan Rataan Kuadrat Galat untuk menghitung nilai kerugian.
mesh
Dalam pemrograman paralel ML, istilah yang terkait dengan penetapan data dan model ke chip TPU, serta menentukan cara nilai ini akan di-shard atau direplikasi.
Mesh adalah istilah yang memiliki lebih dari satu makna yang dapat berarti salah satu dari berikut:
- Tata letak fisik chip TPU.
- Konstruksi logis abstrak untuk memetakan data dan model ke chip TPU.
Dalam kedua kasus tersebut, jaring ditentukan sebagai bentuk.
meta-learning
Bagian dari machine learning yang menemukan atau meningkatkan algoritma pembelajaran. Sistem meta-learning juga dapat bertujuan untuk melatih model agar dapat mempelajari tugas baru dengan cepat dari sejumlah kecil data atau dari pengalaman yang diperoleh dalam tugas sebelumnya. Algoritma meta-learning umumnya mencoba mencapai hal berikut:
- Meningkatkan atau mempelajari fitur yang dibuat secara manual (seperti penginisialisasi atau pengoptimal).
- Lebih efisien data dan efisien komputasi.
- Meningkatkan generalisasi.
Meta-learning terkait dengan few-shot learning.
metrik
Statistik yang Anda minati.
Tujuan adalah metrik yang coba dioptimalkan oleh sistem machine learning.
Metrics API (tf.metrics)
API TensorFlow untuk mengevaluasi model. Misalnya, tf.metrics.accuracy
menentukan seberapa sering prediksi model cocok dengan label.
tumpukan mini
Subset kecil yang dipilih secara acak dari batch yang diproses dalam satu iterasi. Ukuran tumpukan dari tumpukan mini biasanya antara 10 dan 1.000 contoh.
Misalnya, anggap saja seluruh set pelatihan (batch penuh) terdiri dari 1.000 contoh. Selanjutnya, misalkan Anda menetapkan ukuran batch setiap tumpukan mini menjadi 20. Oleh karena itu, setiap iterasi menentukan kerugian pada 20 contoh acak dari 1.000 contoh,lalu menyesuaikan bobot dan bias yang sesuai.
Menghitung kerugian pada mini-batch jauh lebih efisien daripada menghitung kerugian pada semua contoh dalam batch penuh.
Lihat Regresi linear: Hyperparameter di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
penurunan gradien stokastik tumpukan mini
Algoritma penurunan gradien yang menggunakan tumpukan mini. Dengan kata lain, penurunan gradien stokastik tumpukan mini memperkirakan gradien berdasarkan subset kecil dari data pelatihan. Penurunan gradien stokastik reguler menggunakan tumpukan mini berukuran 1.
kerugian minimax
Fungsi kerugian untuk jaringan adversarial generatif, berdasarkan cross-entropy antara distribusi data yang dihasilkan dan data sebenarnya.
Kerugian minimax digunakan dalam makalah pertama untuk mendeskripsikan jaringan adversarial generatif.
Lihat Fungsi Kerugian dalam kursus Generative Adversarial Networks untuk mengetahui informasi selengkapnya.
kelas minoritas
Label yang kurang umum dalam set data kelas tidak seimbang. Misalnya, dalam set data yang berisi 99% label negatif dan 1% label positif, label positif adalah kelas minoritas.
Berbeda dengan kelas mayoritas.
Lihat Set data: Set data tidak seimbang di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
campuran pakar
Skema untuk meningkatkan efisiensi jaringan neural dengan hanya menggunakan subset parameternya (dikenal sebagai pakar) untuk memproses token atau contoh input tertentu. Jaringan gating mengarahkan setiap token atau contoh input ke pakar yang tepat.
Untuk mengetahui detailnya, lihat salah satu makalah berikut:
- Jaringan Neural yang Sangat Besar: Lapisan Mixture-of-Experts dengan Gerbang yang Jarang
- Mixture-of-Experts dengan Perutean Pilihan Pakar
ML
Singkatan dari machine learning.
MMIT
Singkatan dari multimodal instruction-tuned.
MNIST
Set data domain publik yang dikompilasi oleh LeCun, Cortes, dan Burges yang berisi 60.000 gambar, setiap gambar menunjukkan cara manusia secara manual menulis digit tertentu dari 0–9. Setiap gambar disimpan sebagai array bilangan bulat berukuran 28x28, yang mana setiap bilangan bulat adalah nilai hitam putih antara 0 dan 255, inklusif.
MNIST adalah set data kanonis untuk machine learning, yang sering digunakan untuk menguji pendekatan machine learning baru. Untuk mengetahui detailnya, lihat Database MNIST untuk Digit Tulisan Tangan.
modalitas
Kategori data tingkat tinggi. Misalnya, angka, teks, gambar, video, dan audio adalah lima modalitas yang berbeda.
model
Secara umum, konstruksi matematika apa pun yang memproses data input dan menampilkan output. Dengan kata lain, model adalah kumpulan parameter dan struktur yang diperlukan agar sistem dapat membuat prediksi. Dalam supervised machine learning, model mengambil contoh sebagai input dan menyimpulkan prediksi sebagai output. Dalam machine learning yang diawasi, model agak berbeda. Contoh:
- Model regresi linear terdiri dari serangkaian bobot dan bias.
- Model jaringan neural terdiri dari:
- Kumpulan lapisan tersembunyi, yang masing-masing berisi satu neuron atau lebih.
- Bobot dan bias yang terkait dengan setiap neuron.
- Model pohon keputusan terdiri dari:
- Bentuk hierarki; yaitu, pola yang menghubungkan kondisi dan daun.
- Kondisi dan daun.
Anda dapat menyimpan, memulihkan, atau membuat salinan model.
Unsupervised machine learning juga menghasilkan model, biasanya berupa fungsi yang dapat memetakan contoh input ke kelompok yang paling sesuai.
kapasitas model
Kompleksitas masalah yang dapat dipelajari oleh model. Semakin kompleks masalah yang dapat dipelajari model, semakin tinggi pula kapasitas model. Kapasitas model biasanya meningkat seiring dengan jumlah parameter model. Untuk definisi formal kapasitas model klasifikasi, lihat dimensi VC.
penggabungan model
Sistem yang memilih model yang ideal untuk kueri inferensi tertentu.
Bayangkan sekelompok model, mulai dari yang sangat besar (banyak parameter) hingga yang jauh lebih kecil (lebih sedikit parameter). Model yang sangat besar menggunakan lebih banyak resource komputasi pada waktu inferensi daripada model yang lebih kecil. Namun, model yang sangat besar biasanya dapat menyimpulkan permintaan yang lebih kompleks daripada model yang lebih kecil. Pengelompokan model menentukan kompleksitas kueri inferensi, lalu memilih model yang sesuai untuk melakukan inferensi. Motivasi utama untuk pengelompokan model adalah mengurangi biaya inferensi dengan umumnya memilih model yang lebih kecil, dan hanya memilih model yang lebih besar untuk kueri yang lebih kompleks.
Bayangkan model kecil berjalan di ponsel dan versi model yang lebih besar berjalan di server jarak jauh. Cascading model yang baik mengurangi biaya dan latensi dengan memungkinkan model yang lebih kecil menangani permintaan sederhana dan hanya memanggil model jarak jauh untuk menangani permintaan yang kompleks.
Lihat juga model router.
paralelisme model
Cara menskalakan pelatihan atau inferensi yang menempatkan berbagai bagian dari satu model di perangkat yang berbeda. Paralelisme model memungkinkan model yang terlalu besar untuk dimuat di satu perangkat.
Untuk menerapkan paralelisme model, sistem biasanya melakukan hal berikut:
- Membagi model menjadi beberapa bagian yang lebih kecil.
- Mendistribusikan pelatihan bagian-bagian yang lebih kecil tersebut ke beberapa pemroses. Setiap prosesor melatih bagian modelnya sendiri.
- Menggabungkan hasil untuk membuat satu model.
Paralelisme model memperlambat pelatihan.
Lihat juga paralelisme data.
router model
Algoritma yang menentukan model ideal untuk inferensi dalam penggabungan model. Router model itu sendiri biasanya merupakan model machine learning yang secara bertahap mempelajari cara memilih model terbaik untuk input tertentu. Namun, perute model terkadang bisa berupa algoritma non-machine learning yang lebih sederhana.
pelatihan model
Proses penentuan model terbaik.
MOE
Singkatan dari mixture of experts.
Momentum
Algoritma penurunan gradien canggih yang langkah pembelajarannya tidak hanya bergantung pada turunan dalam langkah saat ini, tetapi juga pada turunan langkah yang langsung mendahuluinya. Momentum melibatkan penghitungan rata-rata bergerak berbobot eksponensial dari gradien dari waktu ke waktu, yang analog dengan momentum dalam fisika. Momentum terkadang mencegah pembelajaran terjebak dalam minimum lokal.
MT
Singkatan dari machine translation.
klasifikasi multi-kelas
Dalam supervised learning, masalah klasifikasi dengan set data yang berisi lebih dari dua kelas label. Misalnya, label dalam set data Iris harus berupa salah satu dari tiga kelas berikut:
- Iris setosa
- Iris virginica
- Iris versicolor
Model yang dilatih pada set data Iris yang memprediksi jenis Iris pada contoh baru melakukan klasifikasi multi-class.
Sebaliknya, masalah klasifikasi yang membedakan tepat dua kelas adalah model klasifikasi biner. Misalnya, model email yang memprediksi spam atau bukan spam adalah model klasifikasi biner.
Dalam masalah pengelompokan, klasifikasi multikelas mengacu pada lebih dari dua kelompok.
Lihat Jaringan neural: Klasifikasi multi-kelas di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
regresi logistik multikelas
Menggunakan regresi logistik dalam masalah klasifikasi multikelas.
self-attention multi-head
Ekstensi self-attention yang menerapkan mekanisme self-attention beberapa kali untuk setiap posisi dalam urutan input.
Transformer memperkenalkan self-attention multi-head.
multimodal yang dioptimalkan untuk mengikuti perintah
Model yang dioptimalkan untuk mengikuti perintah (instruction-tuned) yang dapat memproses input di luar teks, seperti gambar, video, dan audio.
model multimodal
Model yang input, output, atau keduanya mencakup lebih dari satu modalitas. Misalnya, pertimbangkan model yang mengambil gambar dan teks (dua modalitas) sebagai fitur, dan menghasilkan skor yang menunjukkan seberapa sesuai teks untuk gambar tersebut. Jadi, input model ini bersifat multimodal dan outputnya bersifat unimodal.
klasifikasi multinomial
Sinonim untuk klasifikasi multi-kelas.
regresi multinomial
Sinonim untuk regresi logistik multikelas.
multitasking
Teknik machine learning yang melatih satu model untuk melakukan beberapa tugas.
Model multi-tugas dibuat dengan melatih data yang sesuai untuk setiap tugas yang berbeda. Hal ini memungkinkan model belajar untuk membagikan informasi di seluruh tugas, yang membantu model belajar secara lebih efektif.
Model yang dilatih untuk beberapa tugas sering kali memiliki kemampuan generalisasi yang lebih baik dan dapat lebih andal dalam menangani berbagai jenis data.
T
Nano
Model Gemini yang relatif kecil dan dirancang untuk penggunaan di perangkat. Lihat Gemini Nano untuk mengetahui detailnya.
Perangkap NaN
Saat di mana satu angka dalam model Anda menjadi NaN selama pelatihan, yang menyebabkan banyak atau semua angka lain dalam model Anda akhirnya menjadi NaN.
NaN adalah singkatan dari Not a Number (Bukan Angka).
natural language processing
Bidang pengajaran komputer untuk memproses apa yang dikatakan atau diketik pengguna menggunakan aturan linguistik. Hampir semua natural language processing modern mengandalkan machine learning.natural language understanding
Subkumpulan natural language processing yang menentukan maksud dari sesuatu yang diucapkan atau diketik. Natural language understanding dapat melampaui natural language processing untuk mempertimbangkan aspek bahasa yang kompleks seperti konteks, sarkasme, dan sentimen.
kelas negatif
Dalam klasifikasi biner, satu kelas disebut positif dan kelas lainnya disebut negatif. Kelas positif adalah hal atau peristiwa yang diuji oleh model dan kelas negatif adalah kemungkinan lainnya. Contoh:
- Kelas negatif dalam tes medis dapat berupa "bukan tumor".
- Kelas negatif dalam model klasifikasi email dapat berupa "bukan spam".
Berbeda dengan kelas positif.
sampling negatif
Sinonim untuk sampling kandidat.
Neural Architecture Search (NAS)
Teknik untuk mendesain arsitektur jaringan neural secara otomatis. Algoritma NAS dapat mengurangi jumlah waktu dan resource yang diperlukan untuk melatih jaringan saraf tiruan.
NAS biasanya menggunakan:
- Ruang penelusuran, yang merupakan sekumpulan kemungkinan arsitektur.
- Fungsi kebugaran, yang merupakan ukuran seberapa baik performa arsitektur tertentu pada tugas tertentu.
Algoritma NAS sering kali dimulai dengan sekumpulan kecil kemungkinan arsitektur dan secara bertahap memperluas ruang penelusuran saat algoritma mempelajari lebih lanjut arsitektur yang efektif. Fungsi kebugaran biasanya didasarkan pada performa arsitektur pada set pelatihan, dan algoritma biasanya dilatih menggunakan teknik reinforcement learning.
Algoritma NAS telah terbukti efektif dalam menemukan arsitektur berperforma tinggi untuk berbagai tugas, termasuk klasifikasi gambar, klasifikasi teks, dan terjemahan mesin.
alur maju
Model yang berisi setidaknya satu lapisan tersembunyi. Jaringan neural dalam adalah jenis jaringan neural yang berisi lebih dari satu lapisan tersembunyi. Misalnya, diagram berikut menunjukkan jaringan neural dalam yang berisi dua lapisan tersembunyi.
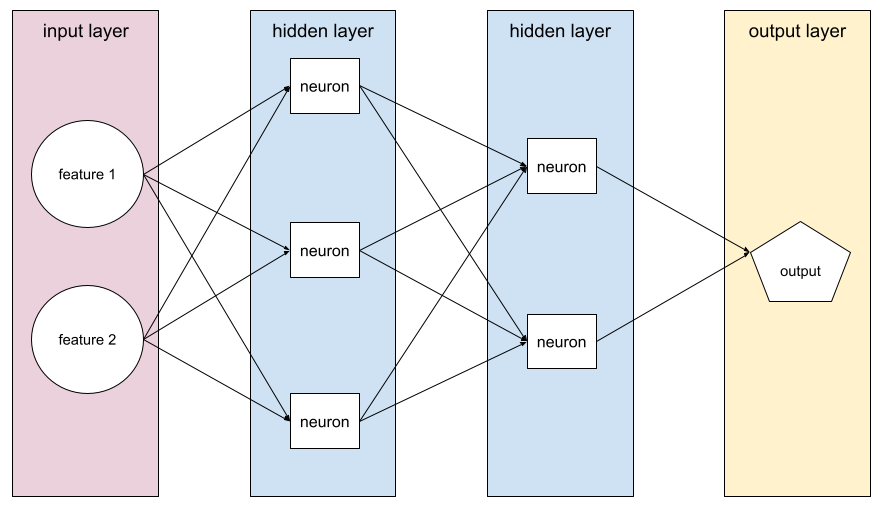
Setiap neuron dalam jaringan neural terhubung ke semua node di lapisan berikutnya. Misalnya, dalam diagram sebelumnya, perhatikan bahwa setiap tiga neuron di lapisan tersembunyi pertama terhubung secara terpisah ke kedua neuron di lapisan tersembunyi kedua.
Jaringan neural yang diimplementasikan di komputer terkadang disebut jaringan neural buatan untuk membedakannya dari jaringan neural yang ditemukan di otak dan sistem saraf lainnya.
Beberapa jaringan neural dapat meniru hubungan nonlinier yang sangat kompleks antara berbagai fitur dan label.
Lihat juga jaringan neural konvolusional dan jaringan neural berulang.
Lihat Jaringan neural di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
neuron
Dalam machine learning, unit berbeda dalam lapisan tersembunyi dari jaringan neural. Setiap neuron melakukan tindakan dua langkah berikut:
- Menghitung jumlah tertimbang nilai input yang dikalikan dengan bobot yang sesuai.
- Meneruskan jumlah terbobot sebagai input ke fungsi aktivasi.
Neuron di lapisan tersembunyi pertama menerima input dari nilai fitur di lapisan input. Neuron di lapisan tersembunyi mana pun di luar lapisan pertama menerima input dari neuron di lapisan tersembunyi sebelumnya. Misalnya, neuron di lapisan tersembunyi kedua menerima input dari neuron di lapisan tersembunyi pertama.
Ilustrasi berikut menyoroti dua neuron dan inputnya.
Neuron dalam jaringan neural meniru perilaku neuron dalam otak dan bagian lain dari sistem saraf.
N-gram
Urutan N kata yang teratur. Misalnya, benar-benar gila adalah 2-gram. Karena urutan relevan, madly truly adalah 2-gram yang berbeda dengan truly madly.
| T | Nama untuk jenis N-gram ini | Contoh |
|---|---|---|
| 2 | bigram atau 2-gram | pergi, pergi ke, makan siang, makan malam |
| 3 | trigram atau 3-gram | makan terlalu banyak, hidup bahagia selamanya, lonceng berbunyi |
| 4 | 4 gram | jalan-jalan di taman, debu di angin, anak laki-laki itu makan lentil |
Banyak model natural language understanding bergantung pada N-gram untuk memprediksi kata selanjutnya yang akan diketik atau dikatakan oleh pengguna. Misalnya, pengguna mengetik bahagia selamanya. Model NLU berdasarkan trigram kemungkinan akan memprediksi bahwa pengguna akan mengetik kata setelah.
Bedakan N-gram dengan kantong data, yang merupakan set kata yang tidak berurutan.
Lihat Model bahasa yang besar di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
NLP
Singkatan dari natural language processing.
NLU
Singkatan dari natural language understanding.
node (pohon keputusan)
Dalam pohon keputusan, setiap kondisi atau daun.
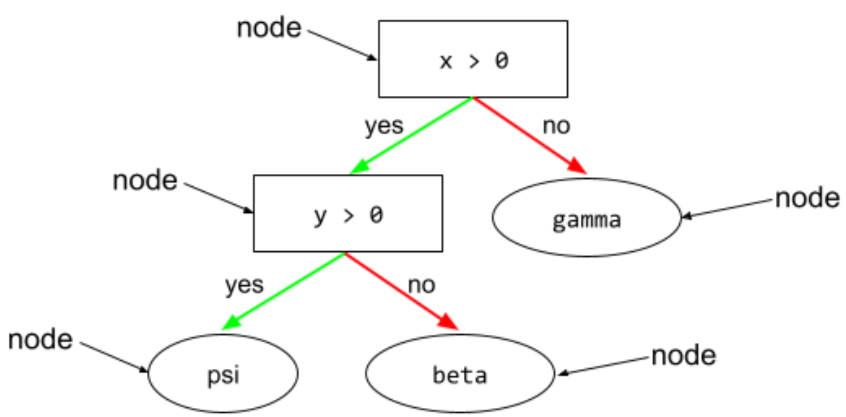
Lihat Pohon Keputusan dalam kursus Decision Forests untuk mengetahui informasi selengkapnya.
simpul (jaringan neural)
Neuron dalam lapisan tersembunyi.
Lihat Jaringan Neural di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
simpul (grafik TensorFlow) (node (TensorFlow graph))
Operasi dalam grafik TensorFlow.
kebisingan
Secara garis besar, segala sesuatu yang mengaburkan sinyal dalam set data. Derau dapat dimasukkan ke dalam data dengan berbagai cara. Contoh:
- Pemberi rating manusia melakukan kesalahan dalam pemberian label.
- Manusia dan instrumen salah mencatat atau menghilangkan nilai fitur.
kondisi non-biner
Kondisi yang berisi lebih dari dua kemungkinan hasil. Misalnya, kondisi non-biner berikut berisi tiga kemungkinan hasil:
Lihat Jenis kondisi dalam kursus Decision Forests untuk mengetahui informasi selengkapnya.
nonlinier
Hubungan antara dua variabel atau lebih yang tidak dapat direpresentasikan hanya melalui penambahan dan perkalian. Hubungan linear dapat direpresentasikan sebagai garis; hubungan nonlinear tidak dapat direpresentasikan sebagai garis. Misalnya, pertimbangkan dua model yang masing-masing menghubungkan satu fitur dengan satu label. Model di sebelah kiri bersifat linear dan model di sebelah kanan bersifat non-linear:

Lihat Jaringan neural: Node dan lapisan tersembunyi di Kursus Singkat Machine Learning untuk bereksperimen dengan berbagai jenis fungsi nonlinier.
bias tidak merespons
Lihat bias seleksi.
nonstasioneritas
Fitur yang nilainya berubah di satu atau beberapa dimensi, biasanya waktu. Misalnya, perhatikan contoh nonstasioneritas berikut:
- Jumlah pakaian renang yang terjual di toko tertentu bervariasi sesuai musim.
- Jumlah buah tertentu yang dipanen di wilayah tertentu adalah nol selama sebagian besar tahun, tetapi besar untuk jangka waktu singkat.
- Akibat perubahan iklim, suhu rata-rata tahunan berubah.
Berbeda dengan stasioneritas.
tidak ada satu jawaban yang benar (NORA)
Perintah yang memiliki beberapa respons yang benar. Misalnya, perintah berikut tidak memiliki satu jawaban yang benar:
Ceritakan lelucon lucu tentang gajah.
Mengevaluasi respons terhadap perintah tanpa satu jawaban yang benar biasanya jauh lebih subjektif daripada mengevaluasi perintah dengan satu jawaban yang benar. Misalnya, mengevaluasi lelucon tentang gajah memerlukan cara sistematis untuk menentukan seberapa lucu lelucon tersebut.
NORA
Singkatan untuk tidak ada satu jawaban yang benar.
normalisasi
Secara umum, proses mengonversi rentang nilai sebenarnya variabel menjadi rentang nilai standar, seperti:
- -1 hingga +1
- 0 hingga 1
- Skor Z (kira-kira, -3 hingga +3)
Misalnya, rentang nilai sebenarnya dari fitur tertentu adalah 800 hingga 2.400. Sebagai bagian dari rekayasa fitur, Anda dapat menormalisasi nilai sebenarnya ke rentang standar, seperti -1 hingga +1.
Normalisasi adalah tugas umum dalam rekayasa fitur. Model biasanya dilatih lebih cepat (dan menghasilkan prediksi yang lebih baik) jika setiap fitur numerik dalam vektor fitur memiliki rentang yang hampir sama.
Lihat juga Normalisasi skor Z.
Lihat Data Numerik: Normalisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Notebook LM
Alat berbasis Gemini yang memungkinkan pengguna mengupload dokumen, lalu menggunakan perintah untuk mengajukan pertanyaan tentang, meringkas, atau mengatur dokumen tersebut. Misalnya, seorang penulis dapat mengupload beberapa cerita pendek dan meminta NotebookLM untuk menemukan tema umumnya atau mengidentifikasi mana yang akan menjadi film terbaik.
deteksi kebaruan
Proses penentuan apakah contoh baru (novel) berasal dari distribusi yang sama dengan set pelatihan. Dengan kata lain, setelah melakukan pelatihan pada set pelatihan, deteksi kebaruan akan menentukan apakah contoh baru (selama inferensi atau selama pelatihan tambahan) adalah pencilan.
Berbeda dengan deteksi pencilan.
data numerik
Fitur yang direpresentasikan sebagai bilangan bulat atau bilangan real-bernilai. Misalnya, model penilaian rumah mungkin merepresentasikan ukuran rumah (dalam kaki persegi atau meter persegi) sebagai data numerik. Merepresentasikan fitur sebagai data numerik menunjukkan bahwa nilai fitur memiliki hubungan matematis dengan label. Artinya, jumlah meter persegi di rumah mungkin memiliki hubungan matematika dengan nilai rumah tersebut.
Tidak semua data bilangan bulat harus direpresentasikan sebagai data numerik. Misalnya,
kode pos di beberapa belahan dunia adalah bilangan bulat; namun, kode pos
bilangan bulat tidak boleh direpresentasikan sebagai data numerik dalam model. Hal ini karena kode pos 20000 tidak dua kali (atau setengah) lebih efektif daripada kode pos 10000. Selain itu, meskipun kode pos yang berbeda berkorelasi dengan nilai properti yang berbeda, kita tidak dapat mengasumsikan bahwa nilai properti di kode pos 20000 dua kali lebih berharga daripada nilai properti di kode pos 10000.
Kode pos sebaiknya direpresentasikan sebagai data kategorik.
Fitur numerik terkadang disebut fitur berkelanjutan.
Lihat Bekerja dengan data numerik di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
NumPy
Library matematika open source yang menyediakan operasi array dalam Python. pandas dibuat di NumPy.
O
tujuan
Metrik yang coba dioptimalkan oleh algoritma Anda.
fungsi objektif
Formula matematika atau metrik yang ingin dioptimalkan oleh model. Misalnya, fungsi objektif untuk regresi linear biasanya adalah Mean Squared Loss. Oleh karena itu, saat melatih model regresi linear, pelatihan bertujuan untuk meminimalkan Rataan Kuadrat Galat.
Dalam beberapa kasus, tujuannya adalah memaksimalkan fungsi objektif. Misalnya, jika fungsi objektifnya adalah akurasi, tujuannya adalah memaksimalkan akurasi.
Lihat juga loss.
kondisi miring
Dalam pohon keputusan, kondisi yang melibatkan lebih dari satu fitur. Misalnya, jika tinggi dan lebar adalah fitur, maka berikut adalah kondisi miring:
height > width
Berbeda dengan kondisi sejajar sumbu.
Lihat Jenis kondisi dalam kursus Decision Forests untuk mengetahui informasi selengkapnya.
offline
Sinonim untuk statis.
inferensi offline
Proses model yang menghasilkan batch prediksi lalu melakukan caching (menyimpan) prediksi tersebut. Aplikasi kemudian dapat mengakses prediksi yang disimpulkan dari cache, bukan menjalankan ulang model.
Misalnya, pertimbangkan model yang membuat perkiraan cuaca lokal (prediksi) sekali setiap empat jam. Setelah setiap model dijalankan, sistem akan meng-cache semua perkiraan cuaca lokal. Aplikasi cuaca mengambil prakiraan dari cache.
Inferensi offline juga disebut inferensi statis.
Berbeda dengan inferensi online. Lihat Sistem ML produksi: Inferensi statis versus dinamis di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
enkode one-hot
Merepresentasikan data kategoris sebagai vektor yang:
- Satu elemen disetel ke 1.
- Semua elemen lainnya ditetapkan ke 0.
Enkode one-hot biasanya digunakan untuk merepresentasikan string atau ID yang memiliki kemungkinan set nilai yang terbatas.
Misalnya, anggaplah fitur kategoris tertentu bernama
Scandinavia memiliki lima kemungkinan nilai:
- "Denmark"
- "Swedia"
- "Norwegia"
- "Finlandia"
- "Islandia"
Enkode one-hot dapat merepresentasikan setiap lima nilai sebagai berikut:
| Negara | Vektor | ||||
|---|---|---|---|---|---|
| "Denmark" | 1 | 0 | 0 | 0 | 0 |
| "Swedia" | 0 | 1 | 0 | 0 | 0 |
| "Norwegia" | 0 | 0 | 1 | 0 | 0 |
| "Finlandia" | 0 | 0 | 0 | 1 | 0 |
| "Islandia" | 0 | 0 | 0 | 0 | 1 |
Berkat encoding one-hot, model dapat mempelajari berbagai koneksi berdasarkan masing-masing dari lima negara.
Merepresentasikan fitur sebagai data numerik adalah alternatif untuk enkode one-hot. Sayangnya, merepresentasikan negara-negara Skandinavia secara numerik bukanlah pilihan yang baik. Misalnya, perhatikan representasi numerik berikut:
- "Denmark" adalah 0
- "Swedia" adalah 1
- "Norwegia" adalah 2
- "Finlandia" adalah 3
- "Islandia" adalah 4
Dengan encoding numerik, model akan menafsirkan angka mentah secara matematis dan akan mencoba melatih angka tersebut. Namun, Islandia sebenarnya tidak dua kali lebih banyak (atau setengah lebih banyak) dari sesuatu seperti Norwegia, sehingga model akan sampai pada beberapa kesimpulan yang aneh.
Lihat Data kategoris: Kosakata dan encoding one-hot di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
satu jawaban benar (ORA)
Perintah yang memiliki satu respons yang benar. Misalnya, pertimbangkan perintah berikut:
Benar atau salah: Saturnus lebih besar dari Mars.
Satu-satunya respons yang benar adalah benar.
Berbeda dengan tidak ada satu jawaban yang benar.
pemelajaran satu tahap
Pendekatan machine learning, yang sering digunakan untuk klasifikasi objek, dirancang untuk mempelajari model klasifikasi yang efektif dari satu contoh pelatihan.
Lihat juga pemelajaran beberapa tahap dan pemelajaran tanpa tahap.
one-shot prompting
Perintah yang berisi satu contoh yang menunjukkan cara model bahasa besar harus merespons. Misalnya, perintah berikut berisi satu contoh yang menunjukkan kepada model bahasa besar cara menjawab kueri.
| Bagian dari satu perintah | Catatan |
|---|---|
| Apa mata uang resmi negara yang ditentukan? | Pertanyaan yang ingin Anda minta jawabannya dari LLM. |
| Prancis: EUR | Satu contoh. |
| India: | Kueri sebenarnya. |
Bandingkan dan bedakan prompt sekali tembak dengan istilah berikut:
satu vs. semua
Dalam masalah klasifikasi dengan N kelas, solusi yang terdiri dari N model klasifikasi biner terpisah—satu model klasifikasi biner untuk setiap kemungkinan hasil. Misalnya, dengan model yang mengklasifikasikan contoh sebagai hewan, tumbuhan, atau mineral, solusi satu vs. semua akan memberikan tiga model klasifikasi biner terpisah berikut:
- hewan versus bukan hewan
- sayuran versus bukan sayuran
- mineral versus bukan mineral
online
Sinonim untuk dinamis.
inferensi online
Menghasilkan prediksi sesuai permintaan. Misalnya, anggaplah aplikasi meneruskan input ke model dan mengeluarkan permintaan untuk prediksi. Sistem yang menggunakan inferensi online merespons permintaan dengan menjalankan model (dan menampilkan prediksi ke aplikasi).
Berbeda dengan inferensi offline.
Lihat Sistem ML produksi: Inferensi statis versus dinamis di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
operasi (op)
Di TensorFlow, prosedur apa pun yang membuat, memanipulasi, atau menghancurkan Tensor. Misalnya, perkalian matriks adalah operasi yang mengambil dua Tensor sebagai input dan menghasilkan satu Tensor sebagai output.
Optax
Library pemrosesan dan pengoptimalan gradien untuk JAX. Optax memfasilitasi riset dengan menyediakan elemen penyusun yang dapat digabungkan kembali dengan cara kustom untuk mengoptimalkan model parametrik seperti deep neural network. Sasaran lainnya meliputi:
- Menyediakan implementasi yang mudah dibaca, diuji dengan baik, dan efisien dari komponen inti.
- Meningkatkan produktivitas dengan memungkinkan penggabungan elemen tingkat rendah ke dalam pengoptimal kustom (atau komponen pemrosesan gradien lainnya).
- Mempercepat penerapan ide baru dengan mempermudah siapa pun untuk berkontribusi.
pengoptimal
Implementasi spesifik dari algoritma penurunan gradien. Pengoptimal populer meliputi:
- AdaGrad, yang merupakan singkatan dari ADAptive GRADient descent.
- Adam, yang merupakan singkatan dari ADAptive with Momentum.
ORA
Singkatan dari one right answer (satu jawaban yang benar).
bias kehomogenan luar golongan
Kecenderungan untuk melihat anggota luar kelompok lebih mirip daripada anggota dalam kelompok saat membandingkan sikap, nilai, ciri kepribadian, dan karakteristik lainnya. Dalam golongan mengacu pada orang yang berinteraksi dengan Anda secara berkala; luar golongan mengacu pada orang yang tidak berinteraksi dengan Anda secara berkala. Jika Anda membuat set data dengan meminta orang untuk memberikan atribut tentang luar golongan, atribut tersebut mungkin kurang bernuansa dan lebih stereotip daripada atribut yang dicantumkan oleh peserta untuk orang di dalam golongan mereka.
Misalnya, Liliput mungkin mendeskripsikan rumah Liliput lain dengan sangat mendetail, dengan menyebutkan perbedaan kecil dalam gaya arsitektur, jendela, pintu, dan ukuran. Namun, orang-orang Lilliput yang sama mungkin hanya menyatakan bahwa semua orang Brobdingnag tinggal di rumah yang identik.
Bias kehomogenan luar golongan adalah bentuk bias atribusi golongan.
Lihat juga bias dalam golongan.
deteksi outlier
Proses mengidentifikasi outlier dalam set pelatihan.
Berbeda dengan deteksi kebaruan.
kekecualian
Nilai yang jauh dari sebagian besar nilai lainnya. Dalam machine learning, salah satu dari berikut adalah pencilan:
- Data input yang nilainya lebih dari sekitar 3 standar deviasi dari rata-rata.
- Bobot dengan nilai absolut yang tinggi.
- Nilai prediksi yang relatif jauh dari nilai sebenarnya.
Misalnya, anggaplah widget-price adalah fitur model tertentu.
Asumsikan bahwa rata-rata widget-price adalah 7 Euro dengan simpangan baku
1 Euro. Contoh yang berisi widget-price sebesar 12 Euro atau 2 Euro
akan dianggap sebagai pencilan karena setiap harga tersebut
lima kali simpangan baku dari rata-rata.
Pencilan sering kali disebabkan oleh kesalahan ketik atau kesalahan input lainnya. Dalam kasus lain, pencilan bukanlah kesalahan; lagipula, nilai yang lima kali simpang deviasi dari rata-rata jarang terjadi, tetapi bukan tidak mungkin.
Pencilan biasanya menyebabkan masalah dalam pelatihan model. Penyesuaian nilai adalah salah satu cara untuk mengelola pencilan.
Lihat Bekerja dengan data numerik di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
evaluasi di luar sampel (evaluasi OOB)
Mekanisme untuk mengevaluasi kualitas decision forest dengan menguji setiap decision tree terhadap contoh yang tidak digunakan selama pelatihan decision tree tersebut. Misalnya, dalam diagram berikut, perhatikan bahwa sistem melatih setiap pohon keputusan pada sekitar dua pertiga contoh, lalu mengevaluasinya terhadap sepertiga contoh yang tersisa.
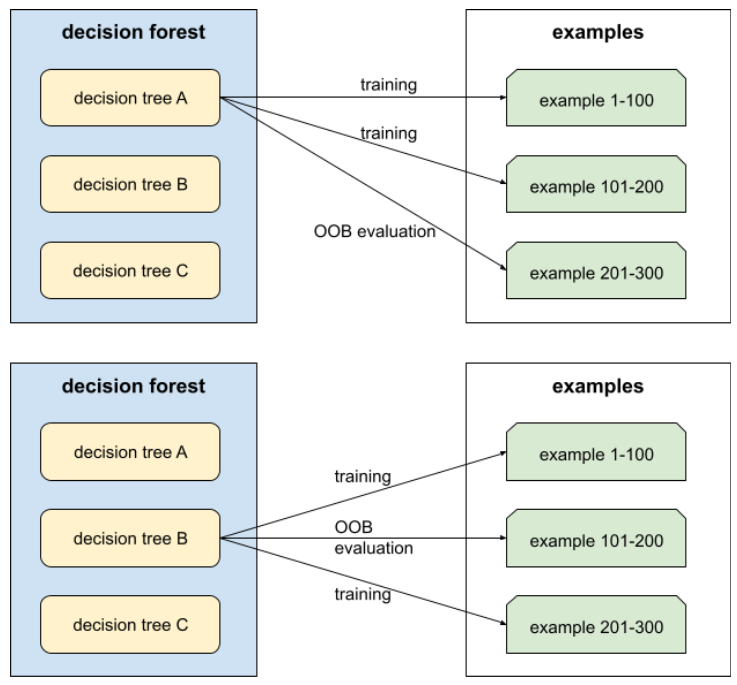
Evaluasi out-of-bag adalah perkiraan mekanisme validasi silang yang efisien secara komputasi dan konservatif. Dalam validasi silang, satu model dilatih untuk setiap putaran validasi silang (misalnya, 10 model dilatih dalam validasi silang 10 kali lipat). Dengan evaluasi OOB, satu model dilatih. Karena bagging menahan beberapa data dari setiap pohon selama pelatihan, evaluasi OOB dapat menggunakan data tersebut untuk memperkirakan validasi silang.
Lihat Evaluasi di luar sampel di kursus Decision Forests untuk mengetahui informasi selengkapnya.
lapisan output
Lapisan "akhir" jaringan neural. Lapisan output berisi prediksi.
Ilustrasi berikut menunjukkan jaringan neural dalam kecil dengan lapisan input, dua lapisan tersembunyi, dan lapisan output:
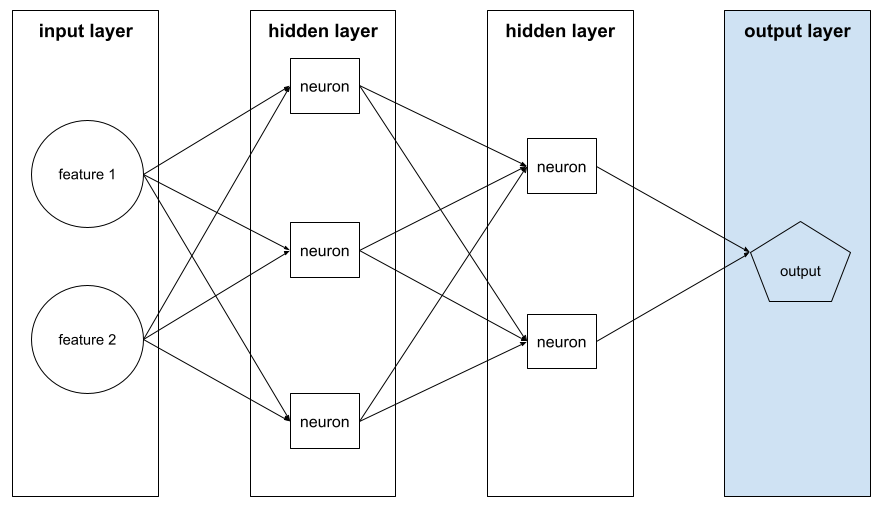
overfitting
Membuat model yang sangat cocok dengan data pelatihan sehingga model gagal membuat prediksi yang benar pada data baru.
Regularisasi dapat mengurangi overfitting. Pelatihan pada set pelatihan yang besar dan beragam juga dapat mengurangi overfitting.
Lihat Overfitting di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
oversampling
Menggunakan kembali contoh kelas minoritas dalam set data kelas tidak seimbang untuk membuat set pelatihan yang lebih seimbang.
Misalnya, pertimbangkan masalah klasifikasi biner dengan rasio kelas mayoritas terhadap kelas minoritas adalah 5.000:1. Jika set data berisi satu juta contoh, maka set data hanya berisi sekitar 200 contoh kelas minoritas, yang mungkin terlalu sedikit untuk pelatihan yang efektif. Untuk mengatasi kekurangan ini, Anda dapat melakukan oversampling (menggunakan kembali) 200 contoh tersebut beberapa kali, sehingga mungkin menghasilkan contoh yang cukup untuk pelatihan yang berguna.
Anda harus berhati-hati terhadap overfitting saat melakukan oversampling.
Berbeda dengan pengurangan sampel.
P
data yang dikemas
Pendekatan untuk menyimpan data secara lebih efisien.
Data yang dipadatkan menyimpan data menggunakan format terkompresi atau dengan cara lain yang memungkinkan data diakses secara lebih efisien. Data yang dikemas meminimalkan jumlah memori dan komputasi yang diperlukan untuk mengaksesnya, sehingga menghasilkan pelatihan yang lebih cepat dan inferensi model yang lebih efisien.
Data yang dikemas sering digunakan dengan teknik lain, seperti augmentasi data dan regularisasi, yang selanjutnya meningkatkan performa model.
PaLM
Singkatan dari Pathways Language Model.
pandas
API analisis data berorientasi kolom yang dibangun di atas numpy. Banyak framework machine learning, termasuk TensorFlow, mendukung struktur data pandas sebagai input. Untuk mengetahui detailnya, lihat dokumentasi pandas.
parameter
Bobot dan bias yang dipelajari model selama pelatihan. Misalnya, dalam model regresi linear, parameter terdiri dari bias (b) dan semua bobot (w1, w2, dan seterusnya) dalam formula berikut:
Sebaliknya, hyperparameter adalah nilai yang Anda (atau layanan penyesuaian hyperparameter) berikan ke model. Misalnya, kecepatan pembelajaran adalah hyperparameter.
parameter-efficient tuning
Serangkaian teknik untuk menyesuaikan model bahasa besar (LLM) terlatih (PLM) secara lebih efisien daripada penyesuaian penuh. Penyesuaian yang efisien parameter biasanya menyesuaikan jauh lebih sedikit parameter daripada penyesuaian penuh, tetapi umumnya menghasilkan model bahasa besar yang berperforma sama baiknya (atau hampir sama baiknya) dengan model bahasa besar yang dibuat dari penyesuaian penuh.
Bandingkan dan bedakan parameter-efficient tuning dengan:
Parameter-efficient tuning juga dikenal sebagai parameter-efficient fine-tuning.
Server Parameter (PS)
Pekerjaan yang melacak parameter model dalam setelan terdistribusi.
pembaruan parameter
Operasi penyesuaian parameter model selama pelatihan, biasanya dalam satu iterasi penurunan gradien.
turunan parsial
Turunan yang semua variabelnya kecuali satu dianggap sebagai konstanta. Misalnya, turunan parsial f(x, y) terhadap x adalah turunan f yang dianggap sebagai fungsi x saja (yaitu, dengan mempertahankan y konstan). Turunan parsial f terhadap x hanya berfokus pada cara x berubah dan mengabaikan semua variabel lain dalam persamaan.
bias partisipasi
Sinonim untuk bias abstain. Lihat bias seleksi.
strategi partisi
Algoritma yang mana variabel dibagi di semua server parameter.
lulus pada k (pass@k)
Metrik untuk menentukan kualitas kode (misalnya, Python) yang dihasilkan oleh model bahasa besar. Lebih khusus lagi, lulus pada k memberi tahu Anda kemungkinan bahwa setidaknya satu blok kode yang dihasilkan dari k blok kode yang dihasilkan akan lulus semua pengujian unitnya.
Model bahasa besar sering kali kesulitan menghasilkan kode yang baik untuk masalah pemrograman yang kompleks. Software engineer beradaptasi dengan masalah ini dengan meminta model bahasa besar untuk membuat beberapa (k) solusi untuk masalah yang sama. Kemudian, software engineer menguji setiap solusi terhadap pengujian unit. Penghitungan lulus pada k bergantung pada hasil pengujian unit:
- Jika satu atau beberapa solusi tersebut lulus pengujian unit, maka LLM Lulus tantangan pembuatan kode tersebut.
- Jika tidak ada solusi yang lulus pengujian unit, maka LLM Gagal dalam tantangan pembuatan kode tersebut.
Rumus untuk lulus pada k adalah sebagai berikut:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
Secara umum, nilai k yang lebih tinggi menghasilkan skor lulus pada k yang lebih tinggi; namun, nilai k yang lebih tinggi memerlukan lebih banyak resource pengujian unit dan model bahasa besar.
Pathways Language Model (PaLM)
Model lama dan pendahulu model Gemini.
Pax
Framework pemrograman yang dirancang untuk melatih jaringan neural model berskala besar sehingga model tersebut mencakup beberapa TPU slice chip akselerator slice atau pod.
Pax dibangun di atas Flax, yang dibangun di atas JAX.
perceptron
Sistem (hardware atau software) yang menggunakan satu atau beberapa nilai masukan, menjalankan fungsi pada jumlah bobot masukan, dan menghitung satu nilai keluaran. Dalam machine learning, fungsi biasanya bersifat non-linear, seperti ReLU, sigmoid, atau tanh. Misalnya, perseptron berikut bergantung pada fungsi sigmoid untuk memproses tiga nilai input:
Dalam ilustrasi berikut, perseptron menggunakan tiga input, yang masing-masing dimodifikasi sendiri oleh bobot sebelum memasuki perseptron:

Perceptron adalah neuron dalam jaringan neural.
performa
Istilah yang memiliki lebih dari satu makna:
- Arti standar dalam software engineering. Yaitu: Seberapa cepat (atau efisien) software ini berjalan?
- Makna dalam machine learning. Di sini, performa menjawab pertanyaan berikut: Seberapa benar model ini? Yaitu, seberapa baik prediksi model?
permutation variable importances
Jenis kepentingan variabel yang mengevaluasi peningkatan error prediksi model setelah melakukan permutasi pada nilai fitur. Kepentingan variabel permutasi adalah metrik independen model.
perpleksitas
Salah satu ukuran terkait seberapa baik model menyelesaikan tugasnya. Misalnya, tugas Anda adalah membaca beberapa huruf pertama dari kata yang diketik pengguna di keyboard ponsel, dan menawarkan daftar kata yang mungkin melengkapi kata tersebut. Perplexity, P, untuk tugas ini kira-kira adalah jumlah tebakan yang perlu Anda berikan agar daftar Anda berisi kata sebenarnya yang sedang diketik pengguna.
Perpleksitas terkait dengan entropi silang sebagai berikut:
pipeline
Infrastruktur di sekitar algoritma machine learning. Pipeline mencakup pengumpulan data, memasukkan data ke dalam file data pelatihan, melatih satu atau beberapa model, dan mengekspor model ke produksi.
Lihat pipeline ML dalam kursus Mengelola Project ML untuk mengetahui informasi selengkapnya.
pipelining
Bentuk paralelisme model yang membagi pemrosesan model menjadi beberapa tahap berurutan dan setiap tahap dijalankan di perangkat yang berbeda. Saat satu tahap memproses satu batch, tahap sebelumnya dapat memproses batch berikutnya.
Lihat juga pelatihan bertahap.
pjit
Fungsi JAX yang membagi kode untuk dijalankan di beberapa chip akselerator. Pengguna meneruskan fungsi ke pjit, yang menampilkan fungsi yang memiliki semantik yang setara, tetapi dikompilasi ke dalam komputasi XLA yang berjalan di beberapa perangkat (seperti GPU atau core TPU).
pjit memungkinkan pengguna membagi komputasi tanpa menulis ulang dengan menggunakan partisi SPMD.
Mulai Maret 2023, pjit telah digabungkan dengan jit. Lihat
Array terdistribusi dan paralelisasi
otomatis
untuk mengetahui detail selengkapnya.
PLM
Singkatan dari pre-trained language model.
pmap
Fungsi JAX yang menjalankan salinan fungsi input pada beberapa perangkat hardware pokok (CPU, GPU, atau TPU), dengan nilai input yang berbeda. pmap mengandalkan SPMD.
kebijakan
Dalam reinforcement learning, pemetaan probabilistik agen dari status ke tindakan.
penggabungan
Mengurangi satu atau beberapa matriks yang dibuat oleh lapisan konvolusional sebelumnya ke matriks yang lebih kecil. Penggabungan biasanya melibatkan pengambilan nilai maksimum atau rata-rata di seluruh area yang digabungkan. Misalnya, anggaplah kita memiliki matriks 3x3 berikut:
![Matriks 3x3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingStart.svg?hl=id)
Operasi penggabungan, seperti operasi konvolusional, membagi matriks tersebut menjadi beberapa potongan, kemudian menggeser operasi konvolusional tersebut dengan langkah. Misalnya, operasi penggabungan membagi matriks konvolusional menjadi potongan 2x2 dengan langkah 1x1. Seperti yang diilustrasikan dalam diagram berikut, empat operasi penggabungan terjadi. Bayangkan bahwa setiap operasi penggabungan memilih nilai maksimum dari empat nilai dalam slice tersebut:
![Matriks inputnya adalah 3x3 dengan nilai: [[5,3,1], [8,2,5], [9,4,3]].
Submatriks 2x2 kiri atas dari matriks input adalah [[5,3], [8,2]], sehingga
operasi penggabungan kiri atas menghasilkan nilai 8 (yang merupakan
maksimum dari 5, 3, 8, dan 2). Submatriks 2x2 kanan atas dari matriks
input adalah [[3,1], [2,5]], sehingga operasi penggabungan kanan atas menghasilkan
nilai 5. Submatriks 2x2 kiri bawah dari matriks input adalah
[[8,2], [9,4]], sehingga operasi penggabungan kiri bawah menghasilkan nilai
9. Submatriks 2x2 kanan bawah dari matriks input adalah
[[2,5], [4,3]], sehingga operasi penggabungan kanan bawah menghasilkan nilai
5. Singkatnya, operasi penggabungan menghasilkan matriks 2x2
[[8,5], [9,5]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingConvolution.svg?hl=id)
Penggabungan membantu menerapkan invariansi translasi dalam matriks input.
Penggabungan untuk aplikasi visi lebih dikenal secara formal sebagai penggabungan spasial. Aplikasi deret waktu biasanya menyebut penggabungan sebagai penggabungan temporal. Secara kurang formal, penggabungan sering disebut subsampling atau downsampling.
Lihat Pengantar Convolutional Neural Networks dalam kursus Praktikum ML: Klasifikasi Gambar.
encoding posisi
Teknik untuk menambahkan informasi tentang posisi token dalam urutan ke sematan token. Model Transformer menggunakan encoding posisional untuk lebih memahami hubungan antara berbagai bagian dalam urutan.
Implementasi umum encoding posisi menggunakan fungsi sinusoidal. (Secara khusus, frekuensi dan amplitudo fungsi sinusoidal ditentukan oleh posisi token dalam urutan.) Teknik ini memungkinkan model Transformer mempelajari cara memperhatikan berbagai bagian urutan berdasarkan posisinya.
kelas positif
Class yang Anda uji.
Misalnya, kelas positif dalam model kanker dapat berupa "tumor". Kelas positif dalam model klasifikasi email dapat berupa "spam".
Berbeda dengan kelas negatif.
pasca-pemrosesan
Menyesuaikan output model setelah model dijalankan. Pemrosesan pasca dapat digunakan untuk menerapkan batasan keadilan tanpa memodifikasi model itu sendiri.
Misalnya, seseorang dapat menerapkan pasca-pemrosesan ke model klasifikasi biner dengan menetapkan nilai minimum klasifikasi sehingga kesetaraan peluang dipertahankan untuk beberapa atribut dengan memeriksa bahwa rasio positif benar sama untuk semua nilai atribut tersebut.
model yang dilatih ulang
Istilah yang didefinisikan secara longgar yang biasanya merujuk pada model terlatih awal yang telah melalui beberapa pascapemrosesan, seperti salah satu atau beberapa hal berikut:
AUC PR (area di bawah kurva PR)
Area di bawah kurva presisi-recall yang diinterpolasi, yang diperoleh dengan memetakan titik (recall, presisi) untuk berbagai nilai batas klasifikasi.
Praksis
Library ML inti berperforma tinggi dari Pax. Praxis sering disebut sebagai "Layer library".
Praxis tidak hanya berisi definisi untuk class Layer, tetapi juga sebagian besar komponen pendukungnya, termasuk:
- input data
- library konfigurasi (HParam dan Fiddle)
- pengoptimal
Praxis menyediakan definisi untuk class Model.
presisi
Metrik untuk model klasifikasi yang menjawab pertanyaan berikut:
Saat model memprediksi kelas positif, berapa persentase prediksi yang benar?
Berikut rumusnya:
dalam hal ini:
- positif benar berarti model dengan benar memprediksi kelas positif.
- positif palsu berarti model salah memprediksi kelas positif.
Misalnya, anggaplah model membuat 200 prediksi positif. Dari 200 prediksi positif ini:
- 150 di antaranya adalah positif benar.
- 50 di antaranya adalah positif palsu.
Dalam hal ini:
Berbeda dengan akurasi dan perolehan.
Lihat Klasifikasi: Akurasi, perolehan, presisi, dan metrik terkait di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
presisi pada k (precision@k)
Metrik untuk mengevaluasi daftar item yang diberi peringkat (diurutkan). Presisi pada k mengidentifikasi fraksi dari k item pertama dalam daftar tersebut yang "relevan". Definisinya yaitu:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
Nilai k harus kurang dari atau sama dengan panjang daftar yang ditampilkan. Perhatikan bahwa panjang daftar yang ditampilkan bukan bagian dari perhitungan.
Relevansi sering kali bersifat subjektif; bahkan evaluator manusia pakar sering kali tidak setuju mengenai item mana yang relevan.
Bandingkan dengan:
kurva presisi-recall
Kurva presisi versus recall pada berbagai batas klasifikasi.
prediksi
Output model. Contoh:
- Prediksi model klasifikasi biner adalah kelas positif atau kelas negatif.
- Prediksi model klasifikasi multi-class adalah satu kelas.
- Prediksi model regresi linear adalah angka.
bias prediksi
Nilai yang menunjukkan seberapa jauh rata-rata prediksi dari rata-rata label dalam set data.
Harap bedakan dengan istilah bias dalam model machine learning atau dengan bias dalam etika dan keadilan.
ML prediktif
Sistem machine learning standar ("klasik").
Istilah ML prediktif tidak memiliki definisi formal. Sebaliknya, istilah ini membedakan kategori sistem ML yang tidak didasarkan pada AI generatif.
kesetaraan prediktif
Metrik keadilan yang memeriksa apakah, untuk model klasifikasi tertentu, tingkat presisi setara untuk subgrup yang dipertimbangkan.
Misalnya, model yang memprediksi penerimaan di perguruan tinggi akan memenuhi paritas prediktif untuk kewarganegaraan jika tingkat presisinya sama untuk orang Lilliput dan Brobdingnag.
Paritas prediktif terkadang juga disebut paritas tarif prediktif.
Lihat "Penjelasan Definisi Keadilan" (bagian 3.2.1) untuk pembahasan yang lebih mendetail tentang paritas prediktif.
paritas tarif prediktif
Nama lain untuk paritas prediktif.
prapemrosesan
Memproses data sebelum digunakan untuk melatih model. Pra-pemrosesan bisa sesederhana menghapus kata-kata dari korpus teks berbahasa Inggris yang tidak ada dalam kamus bahasa Inggris, atau bisa juga serumit mengekspresikan ulang titik data dengan cara yang menghilangkan sebanyak mungkin atribut yang berkorelasi dengan atribut sensitif. Praproses dapat membantu memenuhi batasan keadilan.model terlatih
Meskipun istilah ini dapat merujuk ke model terlatih atau vektor sematan terlatih, model terlatih kini biasanya merujuk ke model bahasa besar terlatih atau bentuk model AI generatif terlatih lainnya.
Lihat juga model dasar dan model dasar.
pra-pelatihan
Pelatihan awal model pada set data yang besar. Beberapa model terlatih adalah raksasa yang canggung dan biasanya harus disempurnakan melalui pelatihan tambahan. Misalnya, pakar ML dapat melakukan pra-pelatihan model bahasa besar pada set data teks yang sangat besar, seperti semua halaman berbahasa Inggris di Wikipedia. Setelah pra-pelatihan, model yang dihasilkan dapat disempurnakan lebih lanjut melalui salah satu teknik berikut:
- distilasi
- penyesuaian (fine-tuning)
- penyesuaian petunjuk
- parameter-efficient tuning
- penyesuaian perintah
keyakinan awal
Hal yang Anda yakini terkait data sebelum Anda mulai melatih data tersebut. Misalnya, regularisasi L2 mengandalkan keyakinan sebelumnya bahwa bobot harus kecil dan umumnya didistribusikan dengan nilai sekitar nol.
Pro
Model Gemini dengan parameter yang lebih sedikit daripada Ultra, tetapi lebih banyak parameter daripada Nano. Lihat Gemini Pro untuk mengetahui detailnya.
model regresi probabilistik
Model regresi yang tidak hanya menggunakan bobot untuk setiap fitur, tetapi juga ketidakpastian bobot tersebut. Model regresi probabilistik menghasilkan prediksi dan ketidakpastian prediksi tersebut. Misalnya, model regresi probabilistik dapat menghasilkan prediksi 325 dengan standar deviasi 12. Untuk mengetahui informasi selengkapnya tentang model regresi probabilistik, lihat Colab ini di tensorflow.org.
fungsi kepadatan probabilitas
Fungsi yang mengidentifikasi frekuensi sampel data yang memiliki tepat nilai tertentu. Jika nilai set data adalah bilangan floating point kontinu, kecocokan persis jarang terjadi. Namun, mengintegrasikan fungsi kepadatan probabilitas dari nilai x ke nilai y akan menghasilkan frekuensi sampel data yang diharapkan antara x dan y.
Misalnya, pertimbangkan distribusi normal yang memiliki rata-rata 200 dan deviasi standar 30. Untuk menentukan frekuensi yang diharapkan dari sampel data yang berada dalam rentang 211,4 hingga 218,7, Anda dapat mengintegrasikan fungsi kepadatan probabilitas untuk distribusi normal dari 211,4 hingga 218,7.
perintah
Teks apa pun yang dimasukkan sebagai input ke model bahasa besar untuk mengondisikan model agar berperilaku dengan cara tertentu. Perintah dapat berupa frasa pendek atau panjang (misalnya, seluruh teks novel). Perintah terbagi dalam beberapa kategori, termasuk yang ditampilkan dalam tabel berikut:
| Kategori perintah | Contoh | Catatan |
|---|---|---|
| Pertanyaan | Seberapa cepat merpati bisa terbang? | |
| Petunjuk | Tulis puisi lucu tentang arbitrase. | Perintah yang meminta model bahasa besar untuk melakukan sesuatu. |
| Contoh | Terjemahkan kode Markdown ke HTML. Misalnya:
Markdown: * item daftar HTML: <ul> <li>item daftar</li> </ul> |
Kalimat pertama dalam perintah contoh ini adalah petunjuk. Bagian perintah lainnya adalah contoh. |
| Peran | Jelaskan alasan penurunan gradien digunakan dalam pelatihan machine learning kepada PhD di bidang Fisika. | Bagian pertama kalimat adalah petunjuk; frasa "to a PhD in Physics" adalah bagian peran. |
| Input parsial yang harus diselesaikan oleh model | Perdana Menteri Inggris Raya tinggal di | Perintah input parsial dapat berakhir tiba-tiba (seperti contoh ini) atau berakhir dengan garis bawah. |
Model AI generatif dapat merespons perintah dengan teks, kode, gambar, embedding, video…hampir semua hal.
pembelajaran berbasis perintah
Kemampuan model tertentu yang memungkinkannya menyesuaikan perilakunya sebagai respons terhadap input teks arbitrer (perintah). Dalam paradigma pembelajaran berbasis perintah yang umum, model bahasa besar merespons perintah dengan menghasilkan teks. Misalnya, pengguna memasukkan perintah berikut:
Ringkas Hukum Ketiga Gerak Newton.
Model yang mampu melakukan pembelajaran berbasis perintah tidak dilatih secara khusus untuk menjawab perintah sebelumnya. Sebaliknya, model "mengetahui" banyak fakta tentang fisika, banyak tentang aturan bahasa umum, dan banyak tentang apa yang merupakan jawaban yang umumnya berguna. Pengetahuan tersebut sudah cukup untuk memberikan jawaban yang (semoga) bermanfaat. Masukan tambahan dari petugas ("Jawaban itu terlalu rumit" atau "Apa itu reaksi?") memungkinkan beberapa sistem pembelajaran berbasis perintah secara bertahap meningkatkan kegunaan jawabannya.
desain perintah
Sinonim untuk rekayasa perintah.
rekayasa perintah
Seni membuat perintah yang mendapatkan respons yang diinginkan dari model bahasa besar. Manusia melakukan rekayasa perintah. Menulis perintah yang terstruktur dengan baik adalah bagian penting untuk memastikan respons yang berguna dari model bahasa besar. Rekayasa perintah bergantung pada banyak faktor, termasuk:
- Set data yang digunakan untuk melakukan pra-pelatihan dan mungkin menyesuaikan model bahasa besar.
- Suhu dan parameter decoding lainnya yang digunakan model untuk membuat respons.
Desain perintah adalah sinonim untuk rekayasa perintah.
Lihat Pengantar desain perintah untuk mengetahui detail selengkapnya tentang cara menulis perintah yang bermanfaat.
set perintah
Sekelompok perintah untuk mengevaluasi model bahasa besar. Misalnya, ilustrasi berikut menunjukkan kumpulan perintah yang terdiri dari tiga perintah:
Kumpulan perintah yang baik terdiri dari kumpulan perintah yang cukup "luas" untuk mengevaluasi secara menyeluruh keamanan dan kegunaan model bahasa besar.
Lihat juga set respons.
penyesuaian perintah
Mekanisme parameter efficient tuning yang mempelajari "awalan" yang ditambahkan sistem ke perintah yang sebenarnya.
Salah satu variasi penyesuaian perintah—terkadang disebut penyesuaian awalan—adalah dengan menambahkan awalan di setiap lapisan. Sebaliknya, sebagian besar penyesuaian perintah hanya menambahkan awalan ke lapisan input.
proxy (atribut sensitif)
Atribut yang digunakan sebagai pengganti atribut sensitif. Misalnya, kode pos seseorang dapat digunakan sebagai proksi untuk pendapatan, ras, atau etnisitasnya.label proxy
Data yang digunakan untuk memperkirakan label yang tidak tersedia secara langsung dalam set data.
Misalnya, Anda harus melatih model untuk memprediksi tingkat stres karyawan. Dataset Anda berisi banyak fitur prediktif, tetapi tidak berisi label bernama tingkat stres. Tanpa gentar, Anda memilih "kecelakaan di tempat kerja" sebagai label proxy untuk tingkat stres. Lagipula, karyawan yang mengalami stres berat lebih sering mengalami kecelakaan daripada karyawan yang tenang. Atau tidak? Mungkin kecelakaan di tempat kerja sebenarnya meningkat dan menurun karena berbagai alasan.
Sebagai contoh kedua, misalkan Anda ingin apakah sedang hujan? menjadi label Boolean untuk set data Anda, tetapi set data Anda tidak berisi data hujan. Jika foto tersedia, Anda mungkin membuat foto orang yang membawa payung sebagai label proxy untuk apakah hujan? Apakah itu label proxy yang bagus? Mungkin, tetapi orang-orang di beberapa budaya mungkin lebih cenderung membawa payung untuk melindungi diri dari matahari daripada hujan.
Label proxy sering kali tidak sempurna. Jika memungkinkan, pilih label aktual daripada label proxy. Namun, jika label sebenarnya tidak ada, pilih label pengganti dengan sangat hati-hati, dengan memilih kandidat label pengganti yang paling tidak buruk.
Lihat Set Data: Label di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
fungsi murni
Fungsi yang outputnya hanya didasarkan pada inputnya, dan tidak memiliki efek samping. Secara khusus, fungsi murni tidak menggunakan atau mengubah status global apa pun, seperti konten file atau nilai variabel di luar fungsi.
Fungsi murni dapat digunakan untuk membuat kode yang aman untuk thread, yang bermanfaat saat membagi kode model di beberapa chip akselerator.
Metode transformasi fungsi JAX mengharuskan fungsi input adalah fungsi murni.
T
Fungsi Q
Dalam reinforcement learning, fungsi yang memprediksi hasil yang diharapkan dari pengambilan tindakan dalam status, lalu mengikuti kebijakan tertentu.
Fungsi Q juga dikenal sebagai fungsi nilai tindakan-status.
Q-learning
Dalam reinforcement learning, algoritma yang memungkinkan agen mempelajari fungsi Q yang optimal dari proses keputusan Markov dengan menerapkan persamaan Bellman. Proses keputusan Markov memodelkan lingkungan.
kuantil
Setiap bucket dalam distribusi kuantil.
pengelompokan kuantil
Mendistribusikan nilai fitur ke dalam bucket sehingga setiap bucket berisi jumlah contoh yang sama (atau hampir sama). Misalnya, gambar berikut membagi 44 poin menjadi 4 bucket, yang masing-masing berisi 11 poin. Agar setiap bucket dalam gambar berisi jumlah titik yang sama, beberapa bucket mencakup lebar nilai x yang berbeda.

Lihat Data numerik: Pengelompokan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
kuantisasi
Istilah yang memiliki lebih dari satu makna yang dapat digunakan dengan salah satu cara berikut:
- Menerapkan pengelompokan kuantil pada fitur tertentu.
- Mengubah data menjadi nol dan satu untuk penyimpanan, pelatihan, dan inferensi yang lebih cepat. Karena data Boolean lebih kuat terhadap derau dan error daripada format lainnya, kuantisasi dapat meningkatkan kebenaran model. Teknik kuantisasi mencakup pembulatan, pemotongan, dan pengelompokan.
Mengurangi jumlah bit yang digunakan untuk menyimpan parametermodel. Misalnya, anggaplah parameter model disimpan sebagai angka floating point 32-bit. Kuantisasi mengonversi parameter tersebut dari 32 bit menjadi 4, 8, atau 16 bit. Kuantisasi mengurangi hal-hal berikut:
- Penggunaan komputasi, memori, disk, dan jaringan
- Waktu untuk menyimpulkan prediksi
- Konsumsi daya
Namun, kuantisasi terkadang mengurangi kebenaran prediksi model.
antrean
Operasi TensorFlow yang menerapkan struktur data antrean. Biasanya digunakan di I/O.
R
RAG
Singkatan dari retrieval-augmented generation.
hutan acak
Ensemble pohon keputusan di mana setiap pohon keputusan dilatih dengan derau acak tertentu, seperti bagging.
Hutan acak adalah jenis hutan keputusan.
Lihat Random Forest dalam kursus Decision Forests untuk mengetahui informasi selengkapnya.
kebijakan acak
Dalam reinforcement learning, sebuah kebijakan yang memilih tindakan secara acak.
peringkat (ordinalitas)
Posisi ordinal kelas dalam masalah machine learning yang mengategorikan kelas dari tertinggi hingga terendah. Misalnya, sistem peringkat perilaku dapat memberi peringkat reward dari yang tertinggi (steak) hingga yang terendah (kale layu).
urutan (Tensor)
Jumlah dimensi dalam Tensor. Misalnya, skalar memiliki peringkat 0, vektor memiliki peringkat 1, dan matriks memiliki peringkat 2.
Jangan sampai tertukar dengan urutan (ordinalitas).
peringkat
Jenis supervised learning yang tujuannya adalah mengurutkan daftar item.
pemberi rating
Manusia yang memberikan label untuk contoh. "Anotator" adalah nama lain untuk pemberi rating.
Lihat Data kategoris: Masalah umum di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
ingatan
Metrik untuk model klasifikasi yang menjawab pertanyaan berikut:
Jika kebenaran dasar adalah kelas positif, berapa persentase prediksi yang diidentifikasi model dengan benar sebagai kelas positif?
Berikut rumusnya:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
dalam hal ini:
- positif benar berarti model dengan benar memprediksi kelas positif.
- negatif palsu berarti model salah memprediksi kelas negatif.
Misalnya, model Anda membuat 200 prediksi pada contoh yang kebenaran nyatanya adalah kelas positif. Dari 200 prediksi ini:
- 180 di antaranya adalah positif benar.
- 20 adalah negatif palsu.
Dalam hal ini:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Lihat Klasifikasi: Akurasi, perolehan, presisi, dan metrik terkait untuk mengetahui informasi selengkapnya.
recall pada k (recall@k)
Metrik untuk mengevaluasi sistem yang menghasilkan daftar item yang diberi peringkat (diurutkan). Perolehan pada k mengidentifikasi fraksi item yang relevan dalam k item pertama dalam daftar tersebut dari total jumlah item relevan yang ditampilkan.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Berbeda dengan presisi pada k.
sistem rekomendasi
Sistem yang memilih set yang relatif kecil untuk item yang diinginkan dari korpus besar untuk setiap pengguna. Misalnya, sistem rekomendasi video dapat merekomendasikan dua video dari korpus 100.000 video, memilih Casablanca dan The Philadelphia Story untuk satu pengguna, serta Wonder Woman dan Black Panther untuk pengguna lain. Sistem rekomendasi video dapat mendasarkan rekomendasinya pada faktor-faktor seperti:
- Film yang telah diberi rating atau ditonton oleh pengguna serupa.
- Genre, sutradara, aktor, demografi target...
Lihat kursus Sistem Rekomendasi untuk mengetahui informasi selengkapnya.
Unit Linear Terarah (ReLU)
Fungsi aktivasi dengan perilaku berikut:
- Jika input negatif atau nol, maka outputnya adalah 0.
- Jika input positif, output sama dengan input.
Contoh:
- Jika inputnya adalah -3, maka outputnya adalah 0.
- Jika inputnya adalah +3, maka outputnya adalah 3.0.
Berikut adalah plot ReLU:
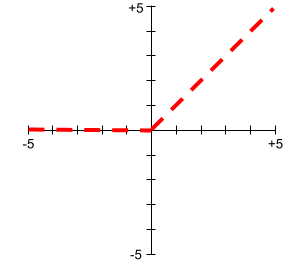
ReLU adalah fungsi aktivasi yang sangat populer. Meskipun perilakunya sederhana, ReLU tetap memungkinkan jaringan neural mempelajari hubungan nonlinier antara fitur dan label.
jaringan neural berulang
Jaringan neural yang sengaja dijalankan beberapa kali, yang mana bagian dari setiap proses dimasukkan ke proses berikutnya. Secara khusus, lapisan tersembunyi dari proses sebelumnya memberikan sebagian input ke lapisan tersembunyi yang sama dalam proses berikutnya. Jaringan saraf berulang sangat berguna untuk mengevaluasi urutan, sehingga lapisan tersembunyi dapat belajar dari proses sebelumnya dari jaringan saraf pada bagian awal urutan.
Misalnya, gambar berikut menunjukkan jaringan neural berulang yang berjalan empat kali. Perhatikan bahwa nilai yang dipelajari di lapisan tersembunyi dari run pertama menjadi bagian dari input ke lapisan tersembunyi yang sama di run kedua. Demikian pula, nilai yang dipelajari di lapisan tersembunyi pada run kedua menjadi bagian dari input ke lapisan tersembunyi yang sama pada run ketiga. Dengan cara ini, jaringan neural berulang secara bertahap melatih dan memprediksi makna seluruh urutan, bukan hanya makna setiap kata.

teks referensi
Respons pakar terhadap prompt . Misalnya, dengan perintah berikut:
Terjemahkan pertanyaan "What is your name?" dari bahasa Inggris ke bahasa Prancis.
Respons pakar mungkin seperti ini:
Siapa nama Anda?
Berbagai metrik (seperti ROUGE) mengukur tingkat kecocokan teks referensi dengan teks yang dihasilkan model ML.
refleksi diri
Strategi untuk meningkatkan kualitas alur kerja berbasis agen dengan memeriksa (merefleksikan) output langkah sebelum meneruskan output tersebut ke langkah berikutnya.
Pemeriksa sering kali adalah LLM yang sama yang menghasilkan respons (meskipun bisa berupa LLM yang berbeda). Bagaimana bisa LLM yang sama yang menghasilkan respons menjadi penilai yang adil atas responsnya sendiri? "Triknya" adalah membuat LLM berpikir kritis (reflektif). Proses ini serupa dengan penulis yang menggunakan pola pikir kreatif untuk menulis draf pertama, lalu beralih ke pola pikir kritis untuk mengeditnya.
Misalnya, bayangkan alur kerja agentik yang langkah pertamanya adalah membuat teks untuk cangkir kopi. Perintah untuk langkah ini mungkin:
Anda adalah seorang kreator. Buat teks orisinal yang lucu dengan panjang kurang dari 50 karakter yang cocok untuk mug kopi.
Sekarang bayangkan perintah refleksi berikut:
Anda adalah seorang peminum kopi. Apakah Anda menganggap respons sebelumnya lucu?
Alur kerja kemudian hanya akan meneruskan teks yang menerima skor refleksi tinggi ke tahap berikutnya.
model regresi
Secara informal, model yang menghasilkan prediksi numerik. (Sebaliknya, model klasifikasi menghasilkan prediksi kelas.) Misalnya, berikut adalah semua model regresi:
- Model yang memprediksi nilai rumah tertentu dalam Euro, seperti 423.000.
- Model yang memprediksi harapan hidup pohon tertentu dalam tahun, seperti 23,2.
- Model yang memprediksi jumlah hujan dalam inci yang akan turun di kota tertentu selama enam jam ke depan, seperti 0,18.
Dua jenis model regresi yang umum adalah:
- Regresi linear, yang menemukan garis yang paling sesuai dengan nilai label ke fitur.
- Regresi logistik, yang menghasilkan probabilitas antara 0,0 dan 1,0 yang biasanya dipetakan oleh sistem ke prediksi kelas.
Tidak setiap model yang menghasilkan prediksi numerik adalah model regresi. Dalam beberapa kasus, prediksi numerik sebenarnya hanyalah model klasifikasi yang kebetulan memiliki nama kelas numerik. Misalnya, model yang memprediksi kode pos numerik adalah model klasifikasi, bukan model regresi.
regularisasi
Mekanisme apa pun yang mengurangi overfitting. Jenis regularisasi yang populer meliputi:
- Regularisasi L1
- Regularisasi L2
- regularisasi dengan pelolosan
- penghentian awal (ini bukan metode regularisasi formal, tetapi dapat membatasi overfitting secara efektif)
Regularisasi juga dapat didefinisikan sebagai penalti pada kompleksitas model.
Lihat Overfitting: Kompleksitas model di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
derajat regularisasi
Angka yang menentukan tingkat kepentingan relatif regularisasi selama pelatihan. Meningkatkan tingkat regularisasi akan mengurangi overfitting, tetapi dapat mengurangi kemampuan prediksi model. Sebaliknya, mengurangi atau menghilangkan tingkat regularisasi akan meningkatkan overfitting.
Lihat Overfitting: Regularisasi L2 di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
reinforcement learning (RL)
Sekumpulan algoritma yang mempelajari kebijakan optimal, yang tujuannya adalah memaksimalkan hasil saat berinteraksi dengan lingkungan. Misalnya, imbalan akhir dari kebanyakan game adalah kemenangan. Sistem pembelajaran berbasis imbalan dapat menjadi pakar dalam bermain game kompleks, dengan mengevaluasi urutan gerakan dari game sebelumnya yang akhirnya mengakibatkan kemenangan dan urutan yang akhirnya mengakibatkan kekalahan.
Reinforcement Learning from Human Feedback (RLHF)
Menggunakan masukan dari pemberi rating manual untuk meningkatkan kualitas respons model. Misalnya, mekanisme RLHF dapat meminta pengguna untuk menilai kualitas respons model dengan emoji 👍 atau 👎. Sistem kemudian dapat menyesuaikan responsnya di masa mendatang berdasarkan masukan tersebut.
ReLU
Singkatan dari Rectified Linear Unit.
replay buffer
Dalam algoritma seperti DQN, memori yang digunakan oleh agen untuk menyimpan transisi status untuk digunakan dalam replay pengalaman.
replika
Salinan (atau bagian dari) set pelatihan atau model, biasanya disimpan di komputer lain. Misalnya, sistem dapat menggunakan strategi berikut untuk menerapkan paralelisme data:
- Tempatkan replika model yang ada di beberapa komputer.
- Kirim subkumpulan set pelatihan yang berbeda ke setiap replika.
- Gabungkan pembaruan parameter.
Replika juga dapat merujuk ke salinan server inferensi lain. Meningkatkan jumlah replika akan meningkatkan jumlah permintaan yang dapat ditayangkan oleh sistem secara bersamaan, tetapi juga meningkatkan biaya penayangan.
bias pelaporan
Fakta bahwa frekuensi orang menulis tentang tindakan, hasil, atau properti tidak mencerminkan frekuensi di dunia nyata atau sejauh mana suatu properti merupakan karakteristik kelas individu. Bias pelaporan dapat memengaruhi komposisi data yang dipelajari oleh sistem machine learning.
Misalnya, dalam buku, kata tertawa lebih sering muncul daripada bernapas. Model machine learning yang memperkirakan frekuensi relatif tawa dan pernapasan dari korpus buku mungkin akan menentukan bahwa tawa lebih umum daripada pernapasan.
Lihat Keadilan: Jenis bias di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
vektor yang sama
Proses memetakan data ke fitur yang berguna.
pemeringkatan ulang
Tahap akhir dari sistem rekomendasi, yang mana item yang diberi skor dapat dinilai ulang menurut beberapa algoritma (biasanya, non-ML) lainnya. Pemeringkatan ulang mengevaluasi daftar item yang dihasilkan berdasarkan fase penskoran, dengan mengambil tindakan seperti:
- Menghilangkan item yang telah dibeli pengguna.
- Menaikkan skor item yang lebih baru.
Lihat Peringkatan ulang dalam kursus Sistem Rekomendasi untuk mengetahui informasi selengkapnya.
respons
Teks, gambar, audio, atau video yang disimpulkan oleh model AI generatif. Dengan kata lain, perintah adalah input ke model AI generatif dan responsnya adalah output.
kumpulan respons
Kumpulan respons yang model bahasa besar berikan untuk input set perintah.
Retrieval-augmented generation (RAG)
Teknik untuk meningkatkan kualitas output model bahasa besar (LLM) dengan menghubungkannya pada sumber pengetahuan yang diambil setelah model dilatih. RAG meningkatkan akurasi respons LLM dengan memberi LLM yang dilatih akses ke informasi yang diambil dari pusat informasi atau dokumen tepercaya.
Motivasi umum untuk menggunakan retrieval-augmented generation meliputi:
- Meningkatkan akurasi faktual respons yang dihasilkan model.
- Memberi model akses ke pengetahuan yang tidak digunakan untuk melatihnya.
- Mengubah pengetahuan yang digunakan model.
- Memungkinkan model mengutip sumber.
Misalnya, anggaplah aplikasi kimia menggunakan PaLM API untuk membuat ringkasan yang terkait dengan kueri pengguna. Saat backend aplikasi menerima kueri, backend akan:
- Menelusuri ("mengambil") data yang relevan dengan kueri pengguna.
- Menambahkan ("melengkapi") data kimia yang relevan ke kueri pengguna.
- Menginstruksikan LLM untuk membuat ringkasan berdasarkan data yang ditambahkan.
pengembalian
Dalam pembelajaran beruntun, dengan kebijakan dan status tertentu, hasil adalah jumlah semua reward yang diharapkan diterima oleh agen saat mengikuti kebijakan dari status hingga akhir episode. Agen memperhitungkan sifat tertunda dari reward yang diharapkan dengan mendiskon reward sesuai dengan transisi status yang diperlukan untuk mendapatkan reward.
Oleh karena itu, jika faktor diskonnya adalah \(\gamma\), dan \(r_0, \ldots, r_{N}\) menunjukkan reward hingga akhir episode, maka perhitungan pengembaliannya adalah sebagai berikut:
reward
Dalam reinforcement learning, hasil numerik dari pengambilan tindakan dalam status, sebagaimana ditentukan oleh lingkungan.
regularisasi punggungan
Sinonim untuk regularisasi L2. Istilah regularisasi batas lebih sering digunakan dalam konteks statistika murni, sedangkan regularisasi L2 lebih sering digunakan dalam machine learning.
RNN
Singkatan dari recurrent neural networks.
Kurva ROC (receiver operating characteristic)
Grafik rasio positif benar versus rasio positif palsu untuk berbagai batas klasifikasi dalam klasifikasi biner.
Bentuk kurva ROC menunjukkan kemampuan model klasifikasi biner untuk memisahkan kelas positif dari kelas negatif. Misalnya, model klasifikasi biner memisahkan semua kelas negatif dengan sempurna dari semua kelas positif:
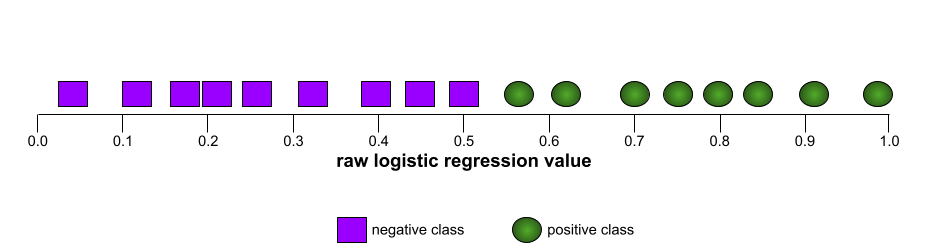
Kurva ROC untuk model sebelumnya terlihat seperti berikut:
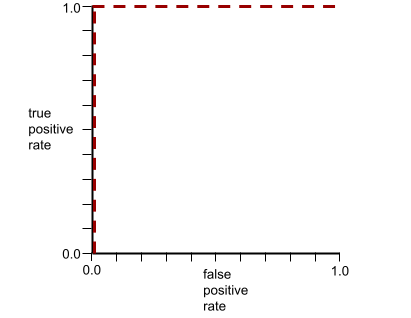
Sebaliknya, ilustrasi berikut menggambarkan nilai regresi logistik mentah untuk model yang buruk yang tidak dapat memisahkan kelas negatif dari kelas positif sama sekali:
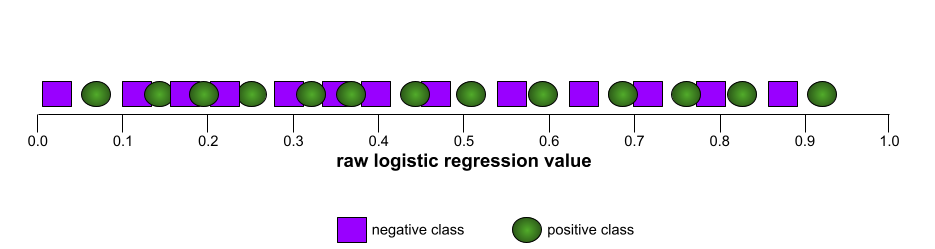
Kurva ROC untuk model ini terlihat seperti berikut:
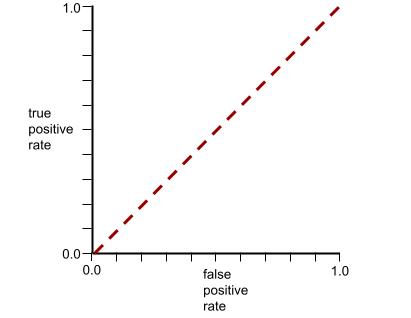
Sementara itu, di dunia nyata, sebagian besar model klasifikasi biner memisahkan kelas positif dan negatif sampai batas tertentu, tetapi biasanya tidak sempurna. Jadi, kurva ROC standar berada di antara dua titik ekstrem:
Titik pada kurva ROC yang paling dekat dengan (0.0,1.0) secara teoretis mengidentifikasi batas klasifikasi yang ideal. Namun, beberapa masalah dunia nyata lainnya memengaruhi pemilihan nilai minimum klasifikasi yang ideal. Misalnya, mungkin negatif palsu menyebabkan lebih banyak masalah daripada positif palsu.
Metrik numerik yang disebut AUC meringkas kurva ROC menjadi satu nilai floating point.
perintah peran
Perintah, biasanya dimulai dengan kata ganti Anda, yang memberi tahu model AI generatif untuk berpura-pura menjadi orang tertentu atau peran tertentu saat membuat respons. Perintah berbasis peran dapat membantu model AI generatif mendapatkan "pola pikir" yang tepat untuk menghasilkan respons yang lebih berguna. Misalnya, salah satu perintah peran berikut mungkin sesuai, bergantung pada jenis respons yang Anda inginkan:
Anda memiliki gelar PhD di bidang ilmu komputer.
Anda adalah seorang software engineer yang senang memberikan penjelasan sabar tentang Python kepada siswa pemrograman baru.
Anda adalah pahlawan aksi dengan serangkaian keterampilan pemrograman yang sangat khusus. Yakinkan saya bahwa Anda akan menemukan item tertentu dalam daftar Python.
root
Node awal (kondisi pertama) dalam pohon keputusan. Menurut konvensi, diagram menempatkan root di bagian atas pohon keputusan. Contoh:
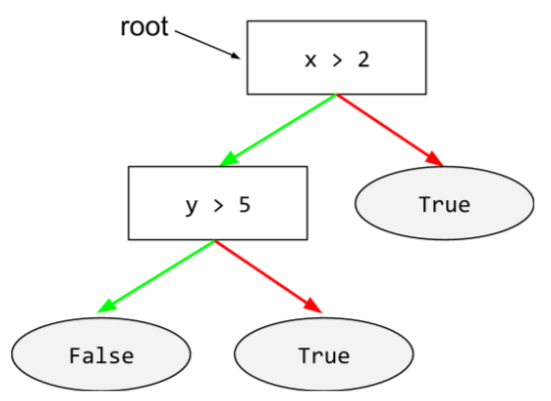
direktori root
Direktori yang Anda tentukan untuk menghosting subdirektori file peristiwa dan checkpoint TensorFlow dari beberapa model.
Galat Akar Rataan Kuadrat (RMSE)
Akar kuadrat dari Rataan Kuadrat Galat.
invariansi rotasional
Dalam masalah klasifikasi gambar, kemampuan algoritma untuk berhasil mengklasifikasikan gambar meskipun orientasi gambar berubah. Misalnya, algoritma tetap dapat mengidentifikasi raket tenis, baik raket tersebut menghadap ke atas, ke samping, atau ke bawah. Perhatikan bahwa invariansi rotasional tidak selalu diinginkan; misalnya, 9 terbalik seharusnya tidak diklasifikasikan sebagai 9.
Lihat juga invariansi translasi dan invariansi ukuran.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Serangkaian metrik yang mengevaluasi model ringkasan otomatis dan terjemahan mesin. Metrik ROUGE menentukan tingkat tumpang-tindih teks rujukan dengan teks yang dihasilkan model ML. Setiap anggota keluarga ROUGE mengukur tumpang-tindih dengan cara yang berbeda. Skor ROUGE yang lebih tinggi menunjukkan kemiripan yang lebih besar antara teks referensi dan teks yang dihasilkan daripada skor ROUGE yang lebih rendah.
Setiap anggota keluarga ROUGE biasanya menghasilkan metrik berikut:
- Presisi
- Recall
- F1
Untuk mengetahui detail dan contohnya, lihat:
ROUGE-L
Anggota keluarga ROUGE yang berfokus pada panjang subsekuen umum terpanjang dalam teks referensi dan teks yang dihasilkan. Rumus berikut menghitung perolehan dan presisi untuk ROUGE-L:
Kemudian, Anda dapat menggunakan F1 untuk menggabungkan recall ROUGE-L dan presisi ROUGE-L ke dalam satu metrik:
ROUGE-L mengabaikan semua baris baru dalam teks referensi dan teks yang dihasilkan, sehingga subsekuens umum terpanjang dapat mencakup beberapa kalimat. Jika teks rujukan dan teks yang dihasilkan melibatkan beberapa kalimat, variasi ROUGE-L yang disebut ROUGE-Lsum umumnya merupakan metrik yang lebih baik. ROUGE-Lsum menentukan subsekuen umum terpanjang untuk setiap kalimat dalam sebuah bagian, lalu menghitung rata-rata subsekuen umum terpanjang tersebut.
ROUGE-N
Sekumpulan metrik dalam keluarga ROUGE yang membandingkan N-gram bersama dengan ukuran tertentu dalam teks referensi dan teks yang dihasilkan. Contoh:
- ROUGE-1 mengukur jumlah token bersama dalam teks referensi dan teks yang dihasilkan.
- ROUGE-2 mengukur jumlah bigram (2-gram) yang sama dalam teks referensi dan teks yang dihasilkan.
- ROUGE-3 mengukur jumlah trigram (3-gram) yang sama dalam teks referensi dan teks yang dihasilkan.
Anda dapat menggunakan formula berikut untuk menghitung recall ROUGE-N dan presisi ROUGE-N untuk anggota keluarga ROUGE-N mana pun:
Kemudian, Anda dapat menggunakan F1 untuk menggabungkan perolehan ROUGE-N dan presisi ROUGE-N ke dalam satu metrik:
ROUGE-S
Bentuk ROUGE-N yang toleran yang memungkinkan pencocokan skip-gram. Artinya, ROUGE-N hanya menghitung N-gram yang cocok persis, tetapi ROUGE-S juga menghitung N-gram yang dipisahkan oleh satu atau beberapa kata. Misalnya, perhatikan kode berikut:
- teks referensi: Awan putih
- teks yang dihasilkan: Awan putih yang berarak
Saat menghitung ROUGE-N, 2-gram, White clouds tidak cocok dengan White billowing clouds. Namun, saat menghitung ROUGE-S, Awan putih cocok dengan Awan putih yang bergulung-gulung.
R-persegi
Metrik regresi yang menunjukkan seberapa besar variasi dalam label disebabkan oleh fitur individual atau set fitur. R-kuadrat adalah nilai antara 0 dan 1, yang dapat Anda tafsirkan sebagai berikut:
- R-kuadrat 0 berarti tidak ada variasi label yang disebabkan oleh set fitur.
- R-kuadrat 1 berarti semua variasi label disebabkan oleh set fitur.
- R-kuadrat antara 0 dan 1 menunjukkan sejauh mana variasi label dapat diprediksi dari fitur tertentu atau set fitur. Misalnya, R-kuadrat 0,10 berarti 10 persen varians dalam label disebabkan oleh set fitur, R-kuadrat 0,20 berarti 20 persen disebabkan oleh set fitur, dan seterusnya.
R kuadrat adalah kuadrat dari koefisien korelasi Pearson antara nilai yang diprediksi model dan kebenaran dasar.
S
bias sampling
Lihat bias seleksi.
pengambilan sampel dengan pengembalian
Metode memilih item dari sekumpulan item kandidat yang sama dapat dipilih beberapa kali. Frasa "dengan pengembalian" berarti bahwa setelah setiap pilihan, item yang dipilih dikembalikan ke kumpulan item kandidat. Metode inversi, pengambilan sampel tanpa penggantian, berarti item kandidat hanya dapat dipilih satu kali.
Misalnya, perhatikan kumpulan buah berikut:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}Misalkan sistem memilih fig secara acak sebagai item pertama.
Jika menggunakan pengambilan sampel dengan penggantian, sistem akan memilih item kedua dari set berikut:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}Ya, itu set yang sama seperti sebelumnya, sehingga sistem berpotensi
memilih fig lagi.
Jika menggunakan sampling tanpa penggantian, setelah dipilih, sampel tidak dapat
dipilih lagi. Misalnya, jika sistem secara acak memilih fig sebagai
sampel pertama, maka fig tidak dapat dipilih lagi. Oleh karena itu, sistem
memilih contoh kedua dari kumpulan berikut (yang dikurangi):
fruit = {kiwi, apple, pear, cherry, lime, mango}SavedModel
Format yang direkomendasikan untuk menyimpan dan memulihkan model TensorFlow. SavedModel adalah format serialisasi yang dapat dipulihkan dengan bahasa netral, yang memungkinkan sistem dan fitur berlevel tinggi untuk memproduksi, mengonsumsi, dan mengubah model TensorFlow.
Lihat bagian Menyimpan dan Memulihkan di Panduan Pemrogram TensorFlow untuk mengetahui detail selengkapnya.
Hemat
Objek TensorFlow yang bertanggung jawab untuk menyimpan checkpoint model.
skalar
Satu angka atau satu string yang dapat direpresentasikan sebagai tensor dengan rank 0. Misalnya, setiap baris kode berikut membuat satu skalar di TensorFlow:
breed = tf.Variable("poodle", tf.string)
temperature = tf.Variable(27, tf.int16)
precision = tf.Variable(0.982375101275, tf.float64)penskalaan
Setiap transformasi atau teknik matematika yang menggeser rentang label, nilai fitur, atau keduanya. Beberapa bentuk penskalaan sangat berguna untuk transformasi seperti normalisasi.
Bentuk penskalaan umum yang berguna dalam Machine Learning meliputi:
- penskalaan linear, yang biasanya menggunakan kombinasi pengurangan dan pembagian untuk mengganti nilai asli dengan angka antara -1 dan +1 atau antara 0 dan 1.
- penskalaan logaritmik, yang menggantikan nilai asli dengan logaritmanya.
- Normalisasi skor Z, yang menggantikan nilai asli dengan nilai floating point yang merepresentasikan jumlah standar deviasi dari rata-rata fitur tersebut.
scikit-learn
Platform machine learning open source yang populer. Lihat scikit-learn.org.
penskoran
Bagian dari sistem rekomendasi yang memberikan nilai atau peringkat untuk setiap item yang dihasilkan oleh fase pembuatan kandidat.
bias seleksi
Kesalahan dalam kesimpulan yang diambil dari data sampel karena proses pemilihan yang menghasilkan perbedaan sistematis antara sampel yang diamati dalam data dan yang tidak diamati. Berikut ini beberapa bentuk bias seleksi:
- bias cakupan: Populasi yang direpresentasikan dalam set data tidak sesuai dengan populasi yang digunakan model machine learning untuk membuat prediksi.
- bias sampling: Data tidak dikumpulkan secara acak dari grup target.
- Bias non-respons (juga disebut bias partisipasi): Pengguna dari grup tertentu memilih tidak ikut survei dengan tingkat yang berbeda dari pengguna dari grup lain.
Misalnya, Anda sedang membuat model machine learning yang memprediksi kesukaan orang terhadap suatu film. Untuk mengumpulkan data pelatihan, Anda membagikan survei kepada semua orang di barisan depan teater yang menayangkan film. Secara spontan, hal ini mungkin terdengar seperti cara yang wajar untuk mengumpulkan set data; namun, bentuk pengumpulan data semacam ini dapat memperkenalkan bentuk-bentuk bias seleksi berikut:
- bias cakupan: Dengan mengambil sampel dari populasi yang memilih untuk menonton film, prediksi model Anda tidak dapat digeneralisasikan kepada orang-orang yang belum mengekspresikan minat terhadap film tersebut.
- bias pengambilan sampel: Daripada mengambil sampel secara acak dari populasi yang dituju (semua orang di bioskop), Anda hanya mengambil sampel orang-orang di barisan depan. Mungkin orang yang duduk di baris depan lebih tertarik dengan film tersebut daripada orang yang duduk di baris lain.
- bias non-respons: Secara umum, orang yang memiliki pendapat kuat cenderung merespons survei opsional lebih sering daripada orang yang memiliki pendapat ringan. Karena survei film bersifat opsional, respons cenderung membentuk distribusi bimodal daripada distribusi normal (berbentuk lonceng).
self-attention (juga disebut lapisan self-attention)
Lapisan jaringan neural yang mengubah urutan embedding (misalnya, embedding token) menjadi urutan embedding lainnya. Setiap sematan dalam urutan output dibuat dengan mengintegrasikan informasi dari elemen urutan input melalui mekanisme perhatian.
Bagian self dari self-attention mengacu pada urutan yang memperhatikan dirinya sendiri, bukan konteks lain. Self-attention adalah salah satu elemen penyusun utama untuk Transformer dan menggunakan terminologi pencarian kamus, seperti "kueri", "kunci", dan "nilai".
Lapisan self-attention dimulai dengan urutan representasi input, satu untuk setiap kata. Representasi input untuk sebuah kata dapat berupa sematan sederhana. Untuk setiap kata dalam urutan input, jaringan menilai relevansi kata tersebut dengan setiap elemen dalam seluruh urutan kata. Skor relevansi menentukan seberapa banyak representasi akhir kata menggabungkan representasi kata lain.
Misalnya, perhatikan kalimat berikut:
Hewan tersebut tidak menyeberang jalan karena terlalu lelah.
Ilustrasi berikut (dari Transformer: A Novel Neural Network Architecture for Language Understanding) menunjukkan pola perhatian lapisan self-attention untuk kata ganti it, dengan kegelapan setiap garis menunjukkan seberapa besar kontribusi setiap kata terhadap representasi:
Lapisan self-attention menandai kata-kata yang relevan dengan "it". Dalam kasus ini, lapisan perhatian telah mempelajari cara menandai kata-kata yang mungkin dirujuknya, dengan memberikan bobot tertinggi pada hewan.
Untuk urutan n token, self-attention mengubah urutan embedding n secara terpisah, sekali di setiap posisi dalam urutan.
Lihat juga perhatian dan self-attention multi-head.
self-supervised learning
Serangkaian teknik untuk mengonversi masalah unsupervised machine learning menjadi masalah supervised machine learning dengan membuat label pengganti dari contoh tidak berlabel.
Beberapa model berbasis Transformer seperti BERT menggunakan pembelajaran mandiri.
Pelatihan mandiri adalah pendekatan semi-supervised learning.
pelatihan mandiri
Varian self-supervised learning yang sangat berguna jika semua kondisi berikut terpenuhi:
- Rasio contoh tak berlabel terhadap contoh berlabel dalam set data tinggi.
- Ini adalah masalah klasifikasi.
Pelatihan mandiri dilakukan dengan mengulangi dua langkah berikut hingga model berhenti meningkat:
- Gunakan supervised machine learning untuk melatih model pada contoh berlabel.
- Gunakan model yang dibuat pada Langkah 1 untuk membuat prediksi (label) pada contoh yang tidak berlabel, dan memindahkan contoh yang memiliki keyakinan tinggi ke contoh berlabel dengan label yang diprediksi.
Perhatikan bahwa setiap iterasi Langkah 2 menambahkan lebih banyak contoh berlabel untuk dilatih di Langkah 1.
semi-supervised learning
Melatih model pada data yang beberapa contoh pelatihannya memiliki label, tetapi yang lainnya tidak. Salah satu teknik untuk semi-supervised learning adalah menyimpulkan label untuk contoh yang tidak berlabel, lalu melatih label yang disimpulkan untuk membuat model baru. Semi-supervised learning dapat berguna jika label mahal untuk diperoleh, tetapi contoh tak berlabel tersedia dalam jumlah banyak.
Self-training adalah salah satu teknik untuk semi-supervised learning.
atribut sensitif
Atribut manusia yang dapat diberi pertimbangan khusus karena alasan hukum, etika, sosial, atau personal.analisis sentimen
Menggunakan algoritma statistik atau machine learning untuk menentukan sikap keseluruhan grup—positif atau negatif—terhadap layanan, produk, organisasi, atau topik. Misalnya, menggunakan natural language understanding, algoritma dapat melakukan analisis sentimen terkait masukan tekstual dari mata kuliah universitas untuk menentukan sejauh mana mahasiswa umumnya menyukai atau tidak menyukai mata kuliah tersebut.
Lihat panduan Klasifikasi teks untuk mengetahui informasi selengkapnya.
model urutan
Model yang inputnya memiliki ketergantungan berurutan. Misalnya, memprediksi video berikutnya yang ditonton dari urutan video yang ditonton sebelumnya.
tugas sequence-to-sequence
Tugas yang mengonversi urutan input token menjadi urutan token output. Misalnya, dua jenis tugas sequence-to-sequence yang populer adalah:
- Penerjemah:
- Urutan input contoh: "Aku sayang kamu".
- Urutan output contoh: "Je t'aime."
- Penjawaban pertanyaan:
- Contoh urutan input: "Apakah saya perlu membawa mobil di Jakarta?"
- Urutan output contoh: "Tidak. Biarkan mobil Anda di rumah."
porsi
Proses membuat model terlatih tersedia untuk memberikan prediksi melalui inferensi online atau inferensi offline.
bentuk (Tensor)
Jumlah elemen di setiap dimensi tensor. Bentuk direpresentasikan sebagai daftar bilangan bulat. Misalnya, tensor dua dimensi berikut memiliki bentuk [3,4]:
[[5, 7, 6, 4], [2, 9, 4, 8], [3, 6, 5, 1]]
TensorFlow menggunakan format row-major (gaya C) untuk merepresentasikan urutan dimensi, itulah sebabnya bentuk di TensorFlow adalah [3,4], bukan [4,3]. Dengan kata lain, dalam Tensor TensorFlow dua dimensi, bentuknya
adalah [jumlah baris, jumlah kolom].
Bentuk statis adalah bentuk tensor yang diketahui pada waktu kompilasi.
Bentuk dinamis tidak diketahui pada waktu kompilasi dan oleh karena itu bergantung pada data runtime. Tensor ini dapat direpresentasikan dengan dimensi placeholder di TensorFlow, seperti pada [3, ?].
shard
Pembagian logis set pelatihan atau model. Biasanya, beberapa proses membuat sharding dengan membagi contoh atau parameter menjadi beberapa bagian yang (biasanya) berukuran sama. Setiap bagian kemudian ditetapkan ke mesin yang berbeda.
Memecah model disebut paralelisme model; memecah data disebut paralelisme data.
penyusutan
Hyperparameter dalam gradient boosting yang mengontrol overfitting. Penciutan dalam gradient boosting mirip dengan kecepatan pembelajaran dalam penurunan gradien. Penyusutan adalah nilai desimal antara 0,0 dan 1,0. Nilai penyusutan yang lebih rendah mengurangi kecocokan berlebih lebih banyak daripada nilai penyusutan yang lebih besar.
evaluasi berdampingan
Membandingkan kualitas dua model dengan menilai respons mereka terhadap perintah yang sama. Misalnya, anggaplah perintah berikut diberikan kepada dua model yang berbeda:
Buat gambar lucu yang sedang menyulap tiga bola.
Dalam evaluasi berdampingan, pemberi rating akan memilih gambar mana yang "lebih baik" (Lebih akurat? Lebih indah? Lebih imut?).
fungsi sigmoid
Fungsi matematika yang "memadatkan" nilai input ke dalam rentang terbatas, biasanya 0 hingga 1 atau -1 hingga +1. Artinya, Anda dapat meneruskan angka apa pun (dua, satu juta, minus satu miliar, apa pun) ke sigmoid dan outputnya akan tetap berada dalam rentang yang dibatasi. Plot fungsi aktivasi sigmoid akan terlihat seperti berikut:
Fungsi sigmoid memiliki beberapa kegunaan dalam machine learning, termasuk:
- Mengonversi output mentah model regresi logistik atau regresi multinomial menjadi probabilitas.
- Bertindak sebagai fungsi aktivasi di beberapa jaringan saraf.
ukuran kesamaan
Dalam algoritma pengelompokan, metrik yang digunakan untuk menentukan seberapa mirip dua contoh yang diberikan.
single program / multiple data (SPMD)
Teknik paralelisme yang menjalankan komputasi yang sama pada data input yang berbeda secara paralel di perangkat yang berbeda. Tujuan SPMD adalah mendapatkan hasil dengan lebih cepat. Ini adalah gaya pemrograman paralel yang paling umum.
invariansi ukuran
Dalam masalah klasifikasi gambar, kemampuan algoritma untuk berhasil mengklasifikasikan gambar meskipun ukuran gambar berubah. Misalnya, algoritma tetap dapat mengidentifikasi kucing, baik jika kucing tersebut menggunakan 2 juta piksel atau 200 ribu piksel. Perhatikan bahwa algoritma klasifikasi gambar terbaik pun masih memiliki batasan praktis pada invarian ukuran. Misalnya, algoritma (atau manusia) tidak mungkin mengklasifikasikan gambar kucing yang hanya menggunakan 20 piksel dengan benar.
Lihat juga invariansi translasi dan invariansi rotasi.
Lihat Kursus pengelompokan untuk mengetahui informasi selengkapnya.
membuat sketsa
Dalam unsupervised machine learning, kategori algoritma yang melakukan analisis kesamaan awal pada contoh. Algoritma sketching menggunakan fungsi hash yang sensitif terhadap lokalitas untuk mengidentifikasi titik-titik yang mungkin mirip, kemudian mengelompokkannya ke dalam bucket.
Sketching mengurangi perhitungan yang dibutuhkan untuk perhitungan kesamaan pada set data besar. Bukannya menghitung kesamaan untuk setiap pasangan contoh dalam set data, kita menghitung kesamaan hanya untuk setiap pasangan titik dalam setiap bucket.
skip-gram
n-gram yang dapat menghilangkan (atau "melewati") kata-kata dari konteks asli, yang berarti N kata mungkin tidak berdekatan pada awalnya. Lebih tepatnya, "k-skip-n-gram" adalah n-gram yang hingga k kata dapat dilewati.
Misalnya, "the quick brown fox" memiliki kemungkinan 2-gram berikut:
- "the quick" (cepat)
- "quick brown" (cepat cokelat)
- "brown fox" (rubah cokelat)
"1-skip-2-gram" adalah pasangan kata yang memiliki paling banyak 1 kata di antaranya. Oleh karena itu, "the quick brown fox" memiliki 2-gram 1-skip berikut:
- "the brown" (cokelat)
- "quick fox" (rubah cepat)
Selain itu, semua 2-gram juga 1-skip-2-gram, karena kurang dari satu kata dapat dilewati.
Skip-gram berguna untuk memahami lebih banyak konteks di sekitar kata. Dalam contoh, "fox" dikaitkan langsung dengan "quick" dalam set 1-skip-2-gram, tetapi tidak dalam set 2-gram.
Skip-gram membantu melatih model embedding kata.
softmax
Fungsi yang menentukan probabilitas untuk setiap kemungkinan kelas dalam model klasifikasi multi-class. Jumlah probabilitasnya adalah 1,0. Misalnya, tabel berikut menunjukkan cara softmax mendistribusikan berbagai probabilitas:
| Gambar adalah... | Probability |
|---|---|
| anjing | 0,85 |
| kucing | .13 |
| kuda | .02 |
Softmax juga disebut softmax penuh.
Berbeda dengan sampling kandidat.
Lihat Jaringan neural: Klasifikasi multi-kelas di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
penyesuaian perintah ringan
Teknik untuk menyesuaikan model bahasa besar untuk tugas tertentu, tanpa penyesuaian yang memerlukan banyak resource. Daripada melatih ulang semua bobot dalam model, penyesuaian perintah ringan secara otomatis menyesuaikan perintah untuk mencapai sasaran yang sama.
Dengan perintah tekstual, penyesuaian perintah lembut biasanya menambahkan embedding token tambahan ke perintah dan menggunakan backpropagation untuk mengoptimalkan input.
Perintah "keras" berisi token aktual, bukan penyematan token.
fitur renggang
Fitur yang sebagian besar nilainya nol atau kosong. Misalnya, fitur yang berisi satu nilai 1 dan satu juta nilai 0 adalah fitur jarang. Sebaliknya, fitur padat memiliki nilai yang sebagian besar bukan nol atau kosong.
Dalam machine learning, sejumlah besar fitur adalah fitur jarang. Fitur kategoris biasanya merupakan fitur jarang. Misalnya, dari 300 kemungkinan spesies pohon di hutan, satu contoh mungkin hanya mengidentifikasi pohon maple. Atau, dari jutaan kemungkinan video dalam koleksi video, satu contoh dapat mengidentifikasi hanya "Casablanca".
Dalam model, Anda biasanya merepresentasikan fitur renggang dengan enkode one-hot. Jika enkode one-hot berukuran besar, Anda dapat menempatkan lapisan penyematan di atas enkode one-hot untuk efisiensi yang lebih besar.
representasi renggang
Menyimpan hanya posisi elemen bukan nol dalam fitur jarang.
Misalnya, anggaplah fitur kategoris bernama species mengidentifikasi 36 spesies pohon di hutan tertentu. Selanjutnya, asumsikan bahwa setiap
contoh hanya mengidentifikasi satu spesies.
Anda dapat menggunakan vektor one-hot untuk merepresentasikan spesies pohon dalam setiap contoh.
Vektor one-hot akan berisi satu 1 (untuk merepresentasikan
spesies pohon tertentu dalam contoh tersebut) dan 35 0 (untuk merepresentasikan
35 spesies pohon yang tidak ada dalam contoh tersebut). Jadi, representasi one-hot
dari maple mungkin terlihat seperti berikut:

Atau, representasi jarang hanya akan mengidentifikasi posisi spesies tertentu. Jika maple berada di posisi 24, representasi jarang
maple cukup berupa:
24
Perhatikan bahwa representasi renggang jauh lebih ringkas daripada representasi one-hot.
Klik ikon untuk melihat contoh yang sedikit lebih kompleks.
Misalkan setiap contoh dalam model Anda harus merepresentasikan kata-kata—tetapi bukan urutan kata-kata tersebut—dalam kalimat bahasa Inggris. Bahasa Inggris terdiri dari sekitar 170.000 kata, jadi bahasa Inggris adalah fitur kategoris dengan sekitar 170.000 elemen. Sebagian besar kalimat dalam bahasa Inggris menggunakan sebagian kecil dari 170.000 kata tersebut, sehingga kumpulan kata dalam satu contoh hampir pasti akan menjadi data jarang.
Pertimbangkan kalimat berikut:
My dog is a great dog
Anda dapat menggunakan varian vektor one-hot untuk merepresentasikan kata-kata dalam kalimat ini. Dalam varian ini, beberapa sel dalam vektor dapat berisi nilai bukan nol. Selain itu, dalam varian ini, sel dapat berisi bilangan bulat selain satu. Meskipun kata "my", "is", "a", dan "great" hanya muncul sekali dalam kalimat, kata "dog" muncul dua kali. Menggunakan vektor one-hot ini untuk merepresentasikan kata-kata dalam kalimat ini akan menghasilkan vektor 170.000 elemen berikut:

Representasi jarang dari kalimat yang sama cukup berupa:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
Lihat Bekerja dengan data kategorik di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
vektor renggang
Vektor yang sebagian besar nilainya adalah nol. Lihat juga fitur renggang dan ketersebaran.
ketersebaran
Jumlah elemen yang disetel ke nol (atau null) dalam vektor atau matriks dibagi dengan jumlah total entri dalam vektor atau matriks tersebut. Misalnya, pertimbangkan matriks 100 elemen yang 98 selnya berisi nol. Penghitungan ketersebaran adalah sebagai berikut:
Ketersebaran fitur mengacu pada ketersebaran vektor fitur; ketersebaran model mengacu pada ketersebaran bobot model.
penggabungan spasial
Lihat penggabungan.
pengodean spesifikasi
Proses penulisan dan pengelolaan file dalam bahasa manusia (misalnya, Inggris) yang menjelaskan software. Kemudian, Anda dapat meminta model AI generatif atau engineer software lain untuk membuat software yang memenuhi deskripsi tersebut.
Kode yang dibuat secara otomatis umumnya memerlukan iterasi. Dalam pengodean spesifikasi, Anda melakukan iterasi pada file deskripsi. Sebaliknya, dalam pengodean percakapan, Anda melakukan iterasi dalam kotak perintah. Dalam praktiknya, pembuatan kode otomatis terkadang melibatkan kombinasi kedua pengodean spesifikasi dan pengodean percakapan.
bagian
Dalam pohon keputusan, nama lain untuk kondisi.
splitter
Saat melatih pohon keputusan, rutin (dan algoritma) yang bertanggung jawab untuk menemukan kondisi terbaik di setiap node.
SPMD
Singkatan dari single program / multiple data.
SQuAD
Akronim untuk Stanford Question Answering Dataset, yang diperkenalkan dalam makalah SQuAD: 100,000+ Questions for Machine Comprehension of Text. Pertanyaan dalam set data ini berasal dari orang-orang yang mengajukan pertanyaan tentang artikel Wikipedia. Beberapa pertanyaan di SQuAD memiliki jawaban, tetapi pertanyaan lainnya sengaja tidak memiliki jawaban. Oleh karena itu, Anda dapat menggunakan SQuAD untuk mengevaluasi kemampuan LLM dalam melakukan kedua hal berikut:
- Jawab pertanyaan yang dapat dijawab.
- Identifikasi pertanyaan yang tidak dapat dijawab.
Pencocokan persis yang dikombinasikan dengan F1 adalah metrik paling umum untuk mengevaluasi LLM terhadap SQuAD.
kerugian engsel kuadrat
Kuadrat dari kerugian engsel. Kerugian engsel kuadrat menghukum pencilan lebih berat daripada kerugian engsel reguler.
kerugian kuadrat
Sinonim untuk L2 loss.
pelatihan bertahap
Taktik melatih model dalam urutan tahap diskrit. Tujuannya bisa berupa mempercepat proses pelatihan, atau mencapai kualitas model yang lebih baik.
Ilustrasi pendekatan penumpukan progresif ditampilkan di bawah:
- Tahap 1 berisi 3 lapisan tersembunyi, tahap 2 berisi 6 lapisan tersembunyi, dan tahap 3 berisi 12 lapisan tersembunyi.
- Tahap 2 memulai pelatihan dengan bobot yang dipelajari di 3 lapisan tersembunyi Tahap 1. Tahap 3 memulai pelatihan dengan bobot yang dipelajari dalam 6 lapisan tersembunyi Tahap 2.
Lihat juga pipelining.
dengan status tersembunyi akhir
Dalam pembelajaran beruntun, nilai parameter yang menjelaskan konfigurasi lingkungan saat ini, yang digunakan oleh agen untuk memilih tindakan.
fungsi nilai tindakan status
Sinonim untuk fungsi Q.
static
Sesuatu yang dilakukan sekali, bukan terus-menerus. Istilah statis dan offline adalah sinonim. Berikut adalah penggunaan umum statis dan offline dalam machine learning:
- Model statis (atau model offline) adalah model yang dilatih satu kali, lalu digunakan untuk jangka waktu tertentu.
- Pelatihan statis (atau pelatihan offline) adalah proses pelatihan model statis.
- Inferensi statis (atau inferensi offline) adalah proses saat model menghasilkan batch prediksi sekaligus.
Berbeda dengan dinamis.
inferensi statis
Sinonim untuk inferensi offline.
stasioneritas
Fitur yang nilainya tidak berubah di satu atau beberapa dimensi, biasanya waktu. Misalnya, fitur yang nilainya terlihat hampir sama pada tahun 2021 dan 2023 menunjukkan stasioneritas.
Di dunia nyata, hanya ada sedikit fitur yang menunjukkan stasioneritas. Bahkan fitur yang identik dengan stabilitas (seperti permukaan laut) berubah seiring waktu.
Berbeda dengan nonstasioneritas.
langkah
Penerusan maju dan penerusan mundur dari satu tumpukan.
Lihat backpropagation untuk mengetahui informasi selengkapnya tentang forward pass dan backward pass.
ukuran langkah
Sinonim untuk kecepatan pembelajaran.
penurunan gradien stokastik (SGD)
Algoritma penurunan gradien yang mana ukuran tumpukan bernilai satu. Dengan kata lain, SGD melatih satu contoh yang dipilih secara seragam dan acak dari set pelatihan.
Lihat Regresi linear: Hyperparameter di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
langkah
Dalam operasi konvolusional atau penggabungan, delta di setiap dimensi serangkaian potongan input berikutnya. Misalnya, animasi berikut menunjukkan langkah (1,1) selama operasi konvolusi. Oleh karena itu, slice input berikutnya dimulai satu posisi di sebelah kanan slice input sebelumnya. Saat operasi mencapai tepi kanan, slice berikutnya akan berada di sebelah kiri, tetapi satu posisi di bawah.
Contoh sebelumnya menunjukkan langkah dua dimensi. Jika matriks input tiga dimensi, langkah juga akan tiga dimensi.
minimalisasi risiko struktural (SRM)
Algoritma yang menyeimbangkan dua sasaran:
- Kebutuhan untuk membangun model yang paling prediktif (misalnya, kerugian terendah).
- Kebutuhan untuk menjaga model sesederhana mungkin (misalnya, regularisasi yang kuat).
Misalnya, fungsi yang meminimalkan kerugian+regularisasi pada set pelatihan adalah algoritma minimalisasi risiko struktural.
Berbeda dengan minimalisasi risiko empiris.
subsampling
Lihat penggabungan.
token subkata
Dalam model bahasa, token adalah substring dari sebuah kata, yang mungkin merupakan seluruh kata.
Misalnya, kata seperti "itemize" dapat dipecah menjadi "item" (kata dasar) dan "ize" (akhiran), yang masing-masing diwakili oleh tokennya sendiri. Dengan membagi kata-kata yang tidak umum menjadi beberapa bagian, yang disebut subkata, model bahasa dapat beroperasi pada bagian-bagian kata yang lebih umum, seperti awalan dan akhiran.
Sebaliknya, kata-kata umum seperti "going" mungkin tidak dipecah dan mungkin diwakili oleh satu token.
ringkasan
Di TensorFlow, nilai atau set nilai yang dihitung pada langkah tertentu, biasanya digunakan untuk melacak metrik model selama pelatihan.
supervised machine learning
Melatih model dari fitur dan label yang sesuai. Supervised machine learning dianalogikan dengan mempelajari subjek dengan mempelajari serangkaian pertanyaan dan jawabannya yang sesuai. Setelah menguasai pemetaan antara pertanyaan dan jawaban, siswa kemudian dapat memberikan jawaban untuk pertanyaan baru (yang belum pernah dilihat sebelumnya) tentang topik yang sama.
Bandingkan dengan unsupervised machine learning.
Lihat Supervised Learning dalam kursus Pengantar ML untuk mengetahui informasi selengkapnya.
fitur sintetis
Fitur yang tidak ada di antara fitur masukan, tetapi dirakit dari satu atau beberapa fitur masukan. Metode untuk membuat fitur sintetis mencakup hal berikut:
- Mengelompokkan fitur berkelanjutan ke dalam bin rentang.
- Membuat persilangan fitur.
- Mengalikan (atau membagi) satu nilai fitur dengan nilai fitur lainnya
atau dengan nilai fitur itu sendiri. Misalnya, jika
adanbadalah fitur input, maka berikut adalah contoh fitur sintetis:- ab
- a2
- Menerapkan fungsi transendental ke nilai fitur. Misalnya, jika
cadalah fitur input, maka berikut adalah contoh fitur sintetis:- sin(c)
- ln(c)
Fitur yang dibuat dengan menormalisasi atau menskalakan saja tidak dianggap sebagai fitur sintetis.
T
T5
Model transfer learning text-to-text yang diperkenalkan oleh Google AI pada tahun 2020. T5 adalah model encoder-decoder, berdasarkan arsitektur Transformer, yang dilatih pada set data yang sangat besar. Model ini efektif dalam berbagai tugas natural language processing, seperti membuat teks, menerjemahkan bahasa, dan menjawab pertanyaan dengan cara percakapan.
T5 mendapatkan namanya dari lima huruf T dalam "Text-to-Text Transfer Transformer".
T5X
Framework machine learning open source yang dirancang untuk membangun dan melatih model natural language processing (NLP) dalam skala besar. T5 diimplementasikan pada codebase T5X (yang dibangun di JAX dan Flax).
tabular Q-learning
Dalam reinforcement learning, menerapkan Q-learning dengan menggunakan tabel untuk menyimpan Q-function untuk setiap kombinasi state dan action.
target
Sinonim untuk label.
jaringan target
Dalam Deep Q-learning, jaringan neural yang merupakan aproksimasi stabil dari jaringan neural utama, dengan jaringan neural utama menerapkan fungsi Q atau kebijakan. Kemudian, Anda dapat melatih jaringan utama pada nilai Q yang diprediksi oleh jaringan target. Oleh karena itu, Anda mencegah loop umpan balik yang terjadi saat jaringan utama melatih nilai Q yang diprediksi oleh dirinya sendiri. Dengan menghindari masukan ini, stabilitas pelatihan akan meningkat.
tugas
Masalah yang dapat diselesaikan menggunakan teknik machine learning, seperti:
suhu
Hyperparameter yang mengontrol tingkat keacakan output model. Temperatur yang lebih tinggi menghasilkan output yang lebih acak, sedangkan temperatur yang lebih rendah menghasilkan output yang kurang acak.
Memilih suhu terbaik bergantung pada aplikasi dan/atau nilai string tertentu.
data temporal
Data yang dicatat pada titik waktu yang berbeda. Misalnya, penjualan mantel musim dingin yang dicatat untuk setiap hari dalam setahun akan menjadi data temporal.
Tensor
Struktur data utama dalam program TensorFlow. Tensor adalah struktur data N dimensi (dengan N bisa sangat besar), yang paling umum adalah skalar, vektor, atau matriks. Elemen Tensor dapat menyimpan nilai bilangan bulat, floating point, atau string.
TensorBoard
Dasbor yang menampilkan ringkasan yang disimpan selama eksekusi satu atau beberapa program TensorFlow.
TensorFlow
Platform machine learning terdistribusi berskala besar. Istilah ini juga merujuk pada lapisan API dasar dalam stack TensorFlow, yang mendukung komputasi umum pada grafik aliran data.
Meskipun TensorFlow terutama digunakan untuk machine learning, Anda juga dapat menggunakan TensorFlow untuk tugas non-ML yang memerlukan komputasi numerik menggunakan grafik alur data.
TensorFlow Playground
Program yang memvisualisasikan pengaruh hyperparameter yang berbeda terhadap pelatihan (terutama jaringan neural) model. Buka http://playground.tensorflow.org untuk melakukan eksperimen dengan TensorFlow Playground.
TensorFlow Serving
Platform untuk men-deploy model terlatih dalam produksi.
Tensor Processing Unit (TPU)
Sirkuit terintegrasi khusus aplikasi (ASIC) yang mengoptimalkan performa beban kerja machine learning. ASIC ini di-deploy sebagai beberapa chip TPU di perangkat TPU.
Urutan tensor
Lihat urutan (Tensor).
Bentuk tensor
Jumlah elemen yang dimiliki oleh Tensor dalam berbagai dimensi.
Misalnya, Tensor [5, 10] memiliki bentuk 5 dalam satu dimensi dan 10
dalam dimensi lainnya.
Ukuran tensor
Jumlah total skalar yang dimiliki oleh Tensor. Misalnya, Tensor
[5, 10] memiliki ukuran 50.
TensorStore
Library untuk membaca dan menulis array multi-dimensi besar secara efisien.
kondisi penghentian
Dalam reinforcement learning, kondisi yang menentukan kapan episode berakhir, seperti saat agen mencapai status tertentu atau melampaui jumlah transisi status minimum. Misalnya, dalam tic-tac-toe (juga dikenal sebagai noughts and crosses), episode berakhir saat pemain menandai tiga ruang berturut-turut atau saat semua ruang ditandai.
uji
Dalam pohon keputusan, nama lain untuk kondisi.
kerugian pengujian
Metrik yang merepresentasikan loss model terhadap set pengujian. Saat membuat model, Anda biasanya mencoba meminimalkan kerugian pengujian. Hal ini karena kerugian pengujian yang rendah adalah sinyal kualitas yang lebih kuat daripada kerugian pelatihan yang rendah atau kerugian validasi yang rendah.
Perbedaan besar antara kerugian pengujian dan kerugian pelatihan atau kerugian validasi terkadang menunjukkan bahwa Anda perlu meningkatkan tingkat regularisasi.
set pengujian
Subset set data yang dicadangkan untuk menguji model yang telah dilatih.
Biasanya, Anda membagi contoh dalam set data menjadi tiga subset berbeda berikut:
- set pelatihan
- set validasi
- set pengujian
Setiap contoh dalam set data hanya boleh termasuk dalam salah satu subkumpulan di atas. Misalnya, satu contoh tidak boleh termasuk dalam set pelatihan dan set pengujian.
Set pelatihan dan set validasi sangat terkait dengan pelatihan model. Karena set pengujian hanya terkait secara tidak langsung dengan pelatihan, kerugian pengujian adalah metrik berkualitas tinggi yang tidak terlalu bias dibandingkan kerugian pelatihan atau kerugian validasi.
Lihat Set data: Membagi set data asli di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
rentang teks
Rentang indeks array yang terkait dengan subbagian tertentu dari string teks.
Misalnya, kata good dalam string Python s="Be good now" menempati
rentang teks dari 3 hingga 6.
tf.Example
Buffer protokol standar yang digunakan untuk mendeskripsikan data masukan untuk pelatihan atau inferensi model machine learning.
tf.keras
Implementasi Keras yang terintegrasi ke dalam TensorFlow.
nilai minimum (untuk pohon keputusan)
Dalam kondisi yang sejajar dengan sumbu, nilai yang dibandingkan dengan fitur. Misalnya, 75 adalah nilai batas dalam kondisi berikut:
grade >= 75
Lihat Splitter persis untuk klasifikasi biner dengan fitur numerik dalam kursus Decision Forests untuk mengetahui informasi selengkapnya.
analisis deret waktu
Subbidang machine learning dan statistik yang menganalisis data temporal. Banyak jenis masalah machine learning memerlukan analisis deret waktu, termasuk klasifikasi, pengelompokan, perkiraan, dan deteksi anomali. Misalnya, Anda dapat menggunakan analisis deret waktu untuk memperkirakan penjualan mantel musim dingin pada masa mendatang per bulan berdasarkan data penjualan historis.
langkah waktu
Satu sel "yang diuraikan" dalam jaringan saraf berulang. Misalnya, gambar berikut menunjukkan tiga langkah waktu (berlabel dengan subskrip t-1, t, dan t+1):

token
Dalam model bahasa, unit atomik yang digunakan model untuk melakukan pelatihan dan membuat prediksi. Token biasanya berupa salah satu dari berikut:
- satu kata—misalnya, frasa " suka kucing" terdiri dari tiga token kata: "", "suka", dan "kucing".
- karakter—misalnya, frasa "ikan sepeda" terdiri dari sembilan token karakter. (Perhatikan bahwa ruang kosong dihitung sebagai salah satu token.)
- subkata—yang mana satu kata dapat berupa satu token atau beberapa token. Subkata terdiri dari kata dasar, awalan, atau akhiran. Misalnya, model bahasa yang menggunakan subkata sebagai token mungkin memandang kata "dogs" sebagai dua token (kata dasar "dog" dan akhiran jamak "s"). Model bahasa yang sama mungkin melihat satu kata "lebih tinggi" sebagai dua subkata (kata dasar "tinggi" dan sufiks "er").
Di domain di luar model bahasa, token dapat merepresentasikan jenis unit atomik lainnya. Misalnya, dalam visi komputer, token dapat berupa subset dari gambar.
Lihat Model bahasa yang besar di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
tokenizer
Sistem atau algoritma yang menerjemahkan urutan data input menjadi token.
Sebagian besar model dasar modern bersifat multimodal. Tokenizer untuk sistem multimodal harus menerjemahkan setiap jenis input ke dalam format yang sesuai. Misalnya, dengan data input yang terdiri dari teks dan grafik, tokenizer dapat menerjemahkan teks input ke dalam subkata dan gambar input ke dalam patch kecil. Kemudian, tokenizer harus mengonversi semua token menjadi satu ruang penyematan terpadu, yang memungkinkan model "memahami" aliran input multimodal.
akurasi top-k
Persentase kemunculan "label target" dalam k posisi pertama daftar yang dihasilkan. Daftar tersebut dapat berupa rekomendasi yang dipersonalisasi atau daftar item yang diurutkan berdasarkan softmax.
Akurasi top-k juga dikenal sebagai akurasi pada k.
marshmallow
Komponen jaringan neural dalam yang merupakan jaringan neural dalam itu sendiri. Dalam beberapa kasus, setiap menara membaca dari sumber data independen, dan menara tersebut tetap independen hingga outputnya digabungkan dalam lapisan akhir. Dalam kasus lain, (misalnya, dalam encoder dan decoder tower dari banyak Transformer), tower memiliki koneksi silang satu sama lain.
perilaku negatif
Tingkat konten yang kasar, mengancam, atau menyinggung. Banyak model machine learning dapat mengidentifikasi dan mengukur toksisitas. Sebagian besar model ini mengidentifikasi toksisitas di sepanjang beberapa parameter, seperti tingkat bahasa yang melecehkan dan tingkat bahasa yang mengancam.
TPU
Singkatan dari Tensor Processing Unit.
Chip TPU
Akselerator aljabar linear yang dapat diprogram dengan memori bandwidth tinggi on-chip yang dioptimalkan untuk beban kerja machine learning. Beberapa chip TPU di-deploy di perangkat TPU.
Perangkat TPU
Papan sirkuit cetak (PCB) dengan beberapa chip TPU, antarmuka jaringan bandwidth tinggi, dan hardware pendingin sistem.
Node TPU
Resource TPU di Google Cloud dengan jenis TPU tertentu. Node TPU terhubung ke Jaringan VPC Anda dari jaringan VPC peer. Node TPU adalah resource yang ditentukan dalam Cloud TPU API.
Pod TPU
Konfigurasi spesifik perangkat TPU di pusat data Google. Semua perangkat dalam Pod TPU terhubung satu sama lain melalui jaringan khusus berkecepatan tinggi. Pod TPU adalah konfigurasi terbesar dari perangkat TPU yang tersedia untuk versi TPU tertentu.
Resource TPU
Entitas TPU di Google Cloud yang Anda buat, kelola, atau gunakan. Misalnya, node TPU dan jenis TPU adalah resource TPU.
Slice TPU
Slice TPU adalah sebagian kecil dari perangkat TPU dalam Pod TPU. Semua perangkat dalam slice TPU terhubung satu sama lain melalui jaringan khusus berkecepatan tinggi.
Jenis TPU
Konfigurasi satu atau beberapa perangkat TPU dengan versi hardware TPU tertentu. Anda memilih jenis TPU saat membuat
node TPU di Google Cloud. Misalnya, jenis TPU v2-8 adalah perangkat TPU v2 tunggal dengan 8 core. Jenis TPU v3-2048 memiliki 256 perangkat TPU v3 yang terhubung ke jaringan dan total 2048 core. Jenis TPU adalah resource yang ditentukan di Cloud TPU API.
TPU worker
Proses yang berjalan di mesin host dan menjalankan program machine learning di perangkat TPU.
pelatihan
Proses penentuan parameter ideal (bobot dan bias) yang membentuk model. Selama pelatihan, sistem membaca contoh dan secara bertahap menyesuaikan parameter. Pelatihan menggunakan setiap contoh dari beberapa kali hingga miliaran kali.
Lihat Supervised Learning dalam kursus Pengantar ML untuk mengetahui informasi selengkapnya.
kerugian pelatihan
Metrik yang merepresentasikan kerugian model selama iterasi pelatihan tertentu. Misalnya, anggap fungsi kerugiannya adalah Rataan Kuadrat Galat (RKG). Mungkin kerugian pelatihan (Mean Squared Error) untuk iterasi ke-10 adalah 2,2, dan kerugian pelatihan untuk iterasi ke-100 adalah 1,9.
Kurva kerugian memetakan kerugian pelatihan versus jumlah iterasi. Kurva kerugian memberikan petunjuk berikut tentang pelatihan:
- Kemiringan ke bawah menunjukkan bahwa model meningkat.
- Kemiringan ke atas menunjukkan bahwa model semakin buruk.
- Lereng datar menunjukkan bahwa model telah mencapai konvergensi.
Misalnya, kurva kerugian yang agak ideal berikut menunjukkan:
- Lereng menurun yang curam selama iterasi awal, yang menyiratkan peningkatan model yang cepat.
- Lereng yang berangsur-angsur mendatar (tetapi masih menurun) hingga mendekati akhir pelatihan, yang menyiratkan peningkatan model yang berkelanjutan dengan kecepatan yang agak lebih lambat daripada selama iterasi awal.
- Lereng datar di akhir pelatihan, yang menunjukkan konvergensi.
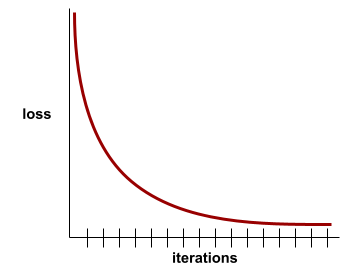
Meskipun kerugian pelatihan penting, lihat juga generalisasi.
diferensiasi performa pelatihan dan penayangan
Perbedaan antara performa model selama pelatihan dan performa model yang sama selama penayangan.
set pelatihan
Subset set data yang digunakan untuk melatih model.
Biasanya, contoh dalam set data dibagi menjadi tiga subset berbeda berikut:
- set pelatihan
- set validasi
- set pengujian
Idealnya, setiap contoh dalam set data hanya boleh termasuk dalam salah satu subkumpulan sebelumnya. Misalnya, satu contoh tidak boleh termasuk dalam set pelatihan dan set validasi.
Lihat Set data: Membagi set data asli di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
lintasan
Dalam reinforcement learning, urutan tuple yang merepresentasikan urutan transisi state dari agent, di mana setiap tuple sesuai dengan status, action, reward, dan status berikutnya untuk transisi status tertentu.
transfer learning
Mentransfer informasi dari satu tugas machine learning ke tugas lainnya. Misalnya, dalam pemelajaran multi-tugas, satu model menyelesaikan beberapa tugas, seperti model dalam yang memiliki simpul output yang berbeda untuk tugas yang berbeda. Pemelajaran transfer dapat melibatkan transfer pengetahuan dari solusi tugas yang lebih sederhana ke tugas yang lebih kompleks, atau melibatkan transfer pengetahuan dari tugas yang memiliki lebih banyak data ke tugas yang memiliki lebih sedikit data.
Sebagian besar sistem machine learning menyelesaikan satu tugas. Transfer learning adalah langkah awal menuju kecerdasan buatan di mana satu program dapat menyelesaikan beberapa tugas.
Transformator
Arsitektur jaringan neural yang dikembangkan di Google yang mengandalkan mekanisme self-attention untuk mengubah urutan sematan input menjadi urutan sematan output tanpa mengandalkan konvolusi atau jaringan neural berulang. Transformer dapat dilihat sebagai tumpukan lapisan self-attention.
Transformer dapat mencakup salah satu hal berikut:
Encoder mengubah urutan embedding menjadi urutan baru dengan panjang yang sama. Encoder mencakup N lapisan identik, yang masing-masing berisi dua sublapisan. Kedua sub-lapisan ini diterapkan di setiap posisi urutan penyematan input, mengubah setiap elemen urutan menjadi penyematan baru. Sub-layer encoder pertama menggabungkan informasi dari seluruh urutan input. Sub-layer encoder kedua mengubah informasi yang dikumpulkan menjadi embedding output.
Decoder mengubah urutan embedding input menjadi urutan embedding output, yang mungkin memiliki panjang yang berbeda. Decoder juga mencakup N lapisan identik dengan tiga sub-lapisan, dua di antaranya mirip dengan sub-lapisan encoder. Sub-lapisan decoder ketiga mengambil output encoder dan menerapkan mekanisme self-attention untuk mengumpulkan informasi darinya.
Postingan blog Transformer: A Novel Neural Network Architecture for Language Understanding memberikan pengantar yang baik tentang Transformer.
Lihat LLM: Apa itu model bahasa besar? di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
invariansi translasi
Dalam masalah klasifikasi gambar, kemampuan algoritma untuk berhasil mengklasifikasikan gambar meskipun posisi objek dalam gambar berubah. Misalnya, algoritma tetap dapat mengidentifikasi gambar, meskipun tersebut berada di tengah bingkai atau di ujung kiri bingkai.
Lihat juga invariansi ukuran dan invariansi rotasional.
trigram
N-gram yang mana N=3.
negatif benar (TN)
Contoh yang mana model dengan benar memprediksi kelas negatif. Misalnya, model menyimpulkan bahwa pesan email tertentu bukan spam, dan pesan email tersebut memang bukan spam.
positif benar (TP)
Contoh yang mana model dengan benar memprediksi kelas positif. Misalnya, model menyimpulkan bahwa pesan email tertentu adalah spam, dan pesan email tersebut memang spam.
rasio positif benar (TPR)
Sinonim untuk perolehan. Definisinya yaitu:
Rasio positif benar adalah sumbu y dalam kurva ROC.
TTL
Singkatan dari time to live.
U
Ultra
Model Gemini dengan parameter terbanyak. Lihat Gemini Ultra untuk mengetahui detailnya.
ketidaktahuan (terhadap atribut sensitif)
Situasi saat atribut sensitif ada, tetapi tidak disertakan dalam data pelatihan. Karena atribut sensitif sering kali berkorelasi dengan atribut lain dari data seseorang, model yang dilatih tanpa mengetahui atribut sensitif masih dapat memiliki dampak yang tidak setara sehubungan dengan atribut tersebut, atau melanggar batasan keadilan lainnya.
underfitting
Menghasilkan model dengan kemampuan prediksi yang buruk karena model belum sepenuhnya memahami kompleksitas data pelatihan. Banyak masalah yang dapat menyebabkan kurang cocok (underfitting), termasuk:
- Melakukan pelatihan pada set fitur yang salah.
- Pelatihan untuk epoch yang terlalu sedikit atau pada kecepatan pembelajaran yang terlalu rendah.
- Melakukan pelatihan dengan tingkat regularisasi yang terlalu tinggi.
- Menyediakan terlalu sedikit lapisan tersembunyi dalam jaringan neural dalam.
Lihat Overfitting di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
kurang sampel
Menghapus contoh dari kelas mayoritas dalam set data kelas tidak seimbang untuk membuat set pelatihan yang lebih seimbang.
Misalnya, pertimbangkan set data yang memiliki rasio kelas mayoritas terhadap kelas minoritas adalah 20:1. Untuk mengatasi ketidakseimbangan kelas ini, Anda dapat membuat set pelatihan yang terdiri dari semua contoh kelas minoritas, tetapi hanya sepersepuluh contoh kelas mayoritas, yang akan membuat rasio kelas set pelatihan menjadi 2:1. Berkat undersampling, set pelatihan yang lebih seimbang ini dapat menghasilkan model yang lebih baik. Atau, set pelatihan yang lebih seimbang ini mungkin berisi contoh yang tidak cukup untuk melatih model yang efektif.
Berbeda dengan oversampling.
satu arah
Sistem yang hanya mengevaluasi teks yang mendahului bagian teks target. Sebaliknya, sistem dua arah mengevaluasi teks yang mendahului dan mengikuti bagian teks target. Lihat bidireksional untuk mengetahui detail selengkapnya.
model bahasa satu arah
Model bahasa yang mendasarkan probabilitasnya hanya pada token yang muncul sebelum, bukan setelah, token target. Berbeda dengan model bahasa dua arah.
contoh tak berlabel
Contoh yang berisi fitur, tetapi tidak ada label. Misalnya, tabel berikut menunjukkan tiga contoh tidak berlabel dari model penilaian rumah, masing-masing dengan tiga fitur, tetapi tanpa nilai rumah:
| Jumlah kamar | Jumlah kamar mandi | Usia rumah |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
Dalam supervised machine learning, model dilatih pada contoh berlabel dan membuat prediksi pada contoh tak berlabel.
Dalam pembelajaran semi-supervised dan unsupervised, contoh tak berlabel digunakan selama pelatihan.
Membedakan contoh tak berlabel dengan contoh berlabel.
unsupervised machine learning
Melatih model untuk menemukan pola dalam set data, biasanya set data tak berlabel.
Penggunaan unsupervised machine learning yang paling umum adalah untuk mengelompokkan data ke dalam beberapa kelompok contoh yang serupa. Misalnya, algoritma machine learning tanpa pengawasan dapat mengelompokkan lagu berdasarkan berbagai properti musik. Cluster yang dihasilkan dapat menjadi input untuk algoritma machine learning lainnya (misalnya, untuk layanan rekomendasi musik). Pengelompokan dapat membantu saat label yang berguna langka atau tidak ada. Misalnya, dalam domain seperti anti-penyalahgunaan dan penipuan, kluster dapat membantu manusia untuk lebih memahami data.
Berbeda dengan supervised machine learning.
Lihat Apa itu Machine Learning? di kursus Pengantar ML untuk mengetahui informasi selengkapnya.
pemodelan peningkatan
Teknik pemodelan, yang umum digunakan dalam pemasaran, yang memodelkan "efek kausal" (juga dikenal sebagai "dampak inkremental") dari "perlakuan" pada "individu". Berikut ini dua contoh:
- Dokter dapat menggunakan pemodelan peningkatan untuk memprediksi penurunan mortalitas (efek kausal) dari prosedur medis (perawatan) bergantung pada usia dan riwayat medis pasien (individu).
- Pemasar dapat menggunakan pemodelan peningkatan untuk memprediksi peningkatan probabilitas pembelian (efek kausal) karena iklan (perlakuan) pada seseorang (individu).
Pemodelan peningkatan berbeda dari klasifikasi atau regresi karena beberapa label (misalnya, setengah label dalam perlakuan biner) selalu tidak ada dalam pemodelan peningkatan. Misalnya, pasien dapat menerima atau tidak menerima pengobatan; oleh karena itu, kita hanya dapat mengamati apakah pasien akan sembuh atau tidak sembuh dalam salah satu dari dua situasi ini (tetapi tidak pernah keduanya). Keuntungan utama model peningkatan adalah model ini dapat membuat prediksi untuk situasi yang tidak diamati (kontrafaktual) dan menggunakannya untuk menghitung efek kausal.
penambahan bobot
Menerapkan bobot ke kelas pengurangan sampel yang sama dengan faktor yang digunakan ketika melakukan pengurangan sampel.
matriks pengguna
Dalam sistem rekomendasi, vektor sematan yang dihasilkan oleh faktorisasi matriks yang memiliki sinyal laten terkait preferensi pengguna. Setiap baris matriks pengguna menyimpan informasi tentang kekuatan relatif berbagai sinyal laten untuk satu pengguna. Misalnya, pertimbangkan sistem rekomendasi film. Dalam sistem ini, sinyal laten dalam matriks pengguna dapat merepresentasikan minat setiap pengguna pada genre tertentu, atau mungkin berupa sinyal yang lebih sulit diinterpretasikan yang melibatkan interaksi kompleks di berbagai faktor.
Matriks pengguna memiliki kolom untuk setiap fitur laten dan baris untuk setiap pengguna. Artinya, matriks pengguna memiliki jumlah baris yang sama dengan matriks target yang difaktorisasi. Misalnya, mengingat sistem rekomendasi film untuk 1.000.000 pengguna, matriks pengguna akan memiliki 1.000.000 baris.
V
validasi
Evaluasi awal kualitas model. Validasi memeriksa kualitas prediksi model terhadap set validasi.
Karena set validasi berbeda dengan set pelatihan, validasi membantu mencegah overfitting.
Anda dapat menganggap evaluasi model terhadap set validasi sebagai putaran pertama pengujian dan evaluasi model terhadap set pengujian sebagai putaran kedua pengujian.
kerugian validasi
Metrik yang merepresentasikan kerugian model pada set validasi selama iterasi pelatihan tertentu.
Lihat juga kurva generalisasi.
set validasi
Subset set data yang melakukan evaluasi awal terhadap model terlatih. Biasanya, Anda mengevaluasi model terlatih terhadap set validasi beberapa kali sebelum mengevaluasi model terhadap set pengujian.
Biasanya, Anda membagi contoh dalam set data menjadi tiga subset berbeda berikut:
- set pelatihan
- set validasi
- set pengujian
Idealnya, setiap contoh dalam set data hanya boleh termasuk dalam salah satu subkumpulan sebelumnya. Misalnya, satu contoh tidak boleh termasuk dalam set pelatihan dan set validasi.
Lihat Set data: Membagi set data asli di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
imputasi nilai
Proses mengganti nilai yang hilang dengan pengganti yang dapat diterima. Jika nilai tidak ada, Anda dapat menghapus seluruh contoh atau menggunakan imputasi nilai untuk menyelamatkan contoh.
Misalnya, pertimbangkan set data yang berisi fitur temperature yang seharusnya direkam setiap jam. Namun, hasil pemeriksaan suhu tidak tersedia selama satu jam tertentu. Berikut adalah bagian set data:
| Stempel waktu | Suhu |
|---|---|
| 1680561000 | 10 |
| 1680564600 | 12 |
| 1680568200 | tidak ada |
| 1680571800 | 20 |
| 1680575400 | 21 |
| 1680579000 | 21 |
Sistem dapat menghapus contoh yang tidak ada atau mengimputasi suhu yang tidak ada sebagai 12, 16, 18, atau 20, bergantung pada algoritma imputasi.
masalah gradien yang menghilang
Kecenderungan gradien lapisan tersembunyi awal dari beberapa jaringan neural dalam menjadi sangat datar (rendah). Gradien yang semakin rendah akan menghasilkan perubahan yang semakin kecil pada bobot di node dalam jaringan neural dalam, sehingga menyebabkan sedikit atau tidak ada pembelajaran. Model yang mengalami masalah gradien yang menghilang menjadi sulit atau tidak mungkin dilatih. Sel Long Short-Term Memory mengatasi masalah ini.
Bandingkan dengan masalah gradien meledak.
kepentingan variabel
Kumpulan skor yang menunjukkan nilai penting relatif setiap fitur terhadap model.
Misalnya, pertimbangkan pohon keputusan yang memperkirakan harga rumah. Misalkan pohon keputusan ini menggunakan tiga fitur: ukuran, usia, dan gaya. Jika sekumpulan kepentingan variabel untuk ketiga fitur dihitung menjadi {size=5.8, age=2.5, style=4.7}, maka ukuran lebih penting bagi pohon keputusan daripada usia atau gaya.
Ada berbagai metrik kepentingan variabel yang dapat memberi tahu pakar ML tentang berbagai aspek model.
autoencoder variasional (VAE)
Jenis autoencoder yang memanfaatkan perbedaan antara input dan output untuk menghasilkan versi input yang dimodifikasi. Autoencoder variasi berguna untuk AI generatif.
VAE didasarkan pada inferensi variasi: teknik untuk memperkirakan parameter model probabilitas.
vektor
Istilah yang sangat memiliki lebih dari satu makna yang bervariasi di berbagai bidang matematika dan ilmiah. Dalam machine learning, vektor memiliki dua properti:
- Jenis data: Vektor dalam machine learning biasanya menyimpan angka floating point.
- Jumlah elemen: Ini adalah panjang vektor atau dimensinya.
Misalnya, pertimbangkan vektor fitur yang menyimpan delapan angka floating point. Vektor fitur ini memiliki panjang atau dimensi delapan. Perhatikan bahwa vektor machine learning sering kali memiliki sejumlah besar dimensi.
Anda dapat merepresentasikan berbagai jenis informasi sebagai vektor. Contoh:
- Setiap posisi di permukaan Bumi dapat direpresentasikan sebagai vektor 2 dimensi, dengan satu dimensi adalah garis lintang dan dimensi lainnya adalah garis bujur.
- Harga saat ini dari 500 saham dapat direpresentasikan sebagai vektor 500 dimensi.
- Distribusi probabilitas pada sejumlah kelas terbatas dapat direpresentasikan sebagai vektor. Misalnya, sistem
klasifikasi multikelas yang
memprediksi salah satu dari tiga warna output (merah, hijau, atau kuning) dapat menghasilkan
vektor
(0.3, 0.2, 0.5)yang berartiP[red]=0.3, P[green]=0.2, P[yellow]=0.5.
Vektor dapat digabungkan; oleh karena itu, berbagai media yang berbeda dapat direpresentasikan sebagai satu vektor. Beberapa model beroperasi langsung pada penggabungan banyak enkode one-hot.
Prosesor khusus seperti TPU dioptimalkan untuk melakukan operasi matematika pada vektor.
Vektor adalah tensor dengan rank 1.
Vertex
Platform Google Cloud untuk AI dan machine learning. Vertex menyediakan alat dan infrastruktur untuk membangun, men-deploy, dan mengelola aplikasi AI, termasuk akses ke model Gemini.vibe coding
Memberi perintah pada model AI generatif untuk membuat software. Artinya, perintah Anda mendeskripsikan tujuan dan fitur software, yang diterjemahkan oleh model AI generatif menjadi kode sumber. Kode yang dihasilkan tidak selalu sesuai dengan maksud Anda, sehingga coding suasana biasanya memerlukan iterasi.
Andrej Karpathy menciptakan istilah vibe coding dalam postingan X ini. Dalam postingan X, Karpathy mendeskripsikannya sebagai "jenis coding baru...tempat Anda sepenuhnya menyerah pada getaran..." Jadi, istilah ini awalnya menyiratkan pendekatan yang sengaja longgar untuk membuat software yang bahkan mungkin tidak memeriksa kode yang dihasilkan. Namun, istilah ini telah berkembang pesat di banyak kalangan hingga kini berarti semua bentuk coding yang dihasilkan AI.
Untuk mengetahui deskripsi yang lebih mendetail tentang pengodean nuansa, lihat What is vibe coding?.
Selain itu, bandingkan dan bedakan vibe coding dengan:
W
Kerugian Wasserstein
Salah satu fungsi kerugian yang umum digunakan dalam jaringan adversarial generatif, berdasarkan jarak penggerak bumi antara distribusi data yang dihasilkan dan data sebenarnya.
bobot
Nilai yang dikalikan model dengan nilai lain. Pelatihan adalah proses penentuan bobot ideal model; inferensi adalah proses penggunaan bobot yang dipelajari tersebut untuk membuat prediksi.
Lihat Regresi linear di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Weighted Alternating Least Squares (WALS)
Algoritma untuk meminimalkan fungsi objektif selama faktorisasi matriks dalam sistem rekomendasi, yang memungkinkan penurunan bobot dari contoh yang hilang. WALS meminimalkan bobot error kuadrat antara matriks asli dan rekonstruksi dengan beralih antara memperbaiki faktorisasi baris dan faktorisasi kolom. Masing-masing pengoptimalan ini dapat diselesaikan dengan pengoptimalan konveks kuadrat terkecil. Untuk mengetahui detailnya, lihat kursus Sistem Rekomendasi.
jumlah tertimbang
Jumlah semua nilai input yang relevan dikalikan dengan bobot yang sesuai. Misalnya, anggap saja input yang relevan terdiri dari berikut ini:
| nilai input | berat masukan |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
Oleh karena itu, jumlah tertimbang adalah:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Jumlah terbobot adalah argumen input untuk fungsi aktivasi.
model lebar
Model linear yang biasanya memiliki banyak fitur masukan renggang. Kita menyebutnya sebagai "lebar" karena model semacam itu adalah jenis jaringan neural khusus dengan sejumlah besar masukan yang terhubung langsung ke simpul keluaran. Biasanya lebih mudah untuk melakukan debug dan pemeriksaan pada model lebar daripada model dalam. Meskipun model lebar tidak dapat mengekspresikan nonlinearitas melalui lapisan tersembunyi, model lebar dapat menggunakan transformasi seperti persilangan fitur dan pengelompokan untuk memodelkan nonlinearitas dengan cara lain.
Berbeda dengan model dalam.
lebar
Jumlah neuron dalam lapisan tertentu dari jaringan neural.
kebijaksanaan banyak orang
Gagasan bahwa merata-ratakan pendapat atau perkiraan dari sekelompok besar orang ("keramaian") sering kali menghasilkan hasil yang sangat baik. Misalnya, pertimbangkan game di mana orang menebak jumlah kacang jeli yang dikemas dalam toples besar. Meskipun sebagian besar tebakan individu tidak akurat, rata-rata semua tebakan secara empiris terbukti sangat mendekati jumlah sebenarnya kacang jeli dalam toples.
Ensemble adalah analog software dari kebijaksanaan banyak orang. Meskipun model individual membuat prediksi yang sangat tidak akurat, merata-ratakan prediksi banyak model sering kali menghasilkan prediksi yang sangat baik. Misalnya, meskipun pohon keputusan individu mungkin membuat prediksi yang buruk, hutan keputusan sering kali membuat prediksi yang sangat baik.
embedding kata
Merepresentasikan setiap kata dalam kumpulan kata dalam vektor embedding; yaitu, merepresentasikan setiap kata sebagai vektor nilai floating-point antara 0,0 dan 1,0. Kata-kata dengan makna serupa memiliki representasi yang lebih serupa daripada kata-kata dengan makna yang berbeda. Misalnya, wortel, seledri, dan mentimun akan memiliki representasi yang relatif serupa, yang akan sangat berbeda dari representasi pesawat, kacamata hitam, dan pasta gigi.
X
XLA (Accelerated Linear Algebra)
Compiler machine learning open source untuk GPU, CPU, dan akselerator ML.
Compiler XLA mengambil model dari framework ML populer seperti PyTorch, TensorFlow, dan JAX, lalu mengoptimalkannya untuk eksekusi berperforma tinggi di berbagai platform hardware termasuk GPU, CPU, dan akselerator ML.
Z
zero-shot learning
Jenis pelatihan machine learning di mana model menyimpulkan prediksi untuk tugas yang belum dilatih secara khusus. Dengan kata lain, model diberi nol contoh pelatihan khusus tugas, tetapi diminta untuk melakukan inferensi untuk tugas tersebut.
zero-shot prompting
Perintah yang tidak memberikan contoh cara Anda menginginkan model bahasa besar merespons. Contoh:
| Bagian dari satu perintah | Catatan |
|---|---|
| Apa mata uang resmi negara yang ditentukan? | Pertanyaan yang ingin Anda minta jawabannya dari LLM. |
| India: | Kueri sebenarnya. |
Model bahasa besar dapat merespons dengan salah satu dari berikut ini:
- Rupee
- INR
- Rs
- Rupee India
- Rupee
- Rupee India
Semua jawaban benar, meskipun Anda mungkin lebih menyukai format tertentu.
Bandingkan dan bedakan prompting zero-shot dengan istilah berikut:
Normalisasi skor Z
Teknik penskalaan yang mengganti nilai fitur mentah dengan nilai floating point yang merepresentasikan jumlah standar deviasi dari rata-rata fitur tersebut. Misalnya, pertimbangkan fitur yang memiliki rata-rata 800 dan standar deviasi 100. Tabel berikut menunjukkan cara normalisasi skor Z memetakan nilai mentah ke skor Z-nya:
| Nilai mentah | Z-score |
|---|---|
| 800 | 0 |
| 950 | +1,5 |
| 575 | -2,25 |
Model machine learning kemudian dilatih pada skor Z untuk fitur tersebut, bukan pada nilai mentah.
Lihat Data numerik: Normalisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Glosarium ini mendefinisikan istilah machine learning.