Pelajari cara Google mengembangkan model klasifikasi gambar yang canggih untuk penelusuran di Google Foto. Dapatkan kursus kilat tentang jaringan neural konvolusional, lalu buat pengklasifikasi gambar Anda sendiri untuk membedakan foto kucing dan foto anjing.
Prasyarat
Kursus Crash Machine Learning atau pengalaman yang setara dengan dasar-dasar ML
Kemahiran dalam dasar-dasar pemrograman, dan beberapa pengalaman coding dalam Python
Pengantar
Pada bulan Mei 2013, Google merilis penelusuran foto pribadi, memberi pengguna kemampuan untuk mengambil foto di galeri foto berdasarkan objek yang ada di gambar.
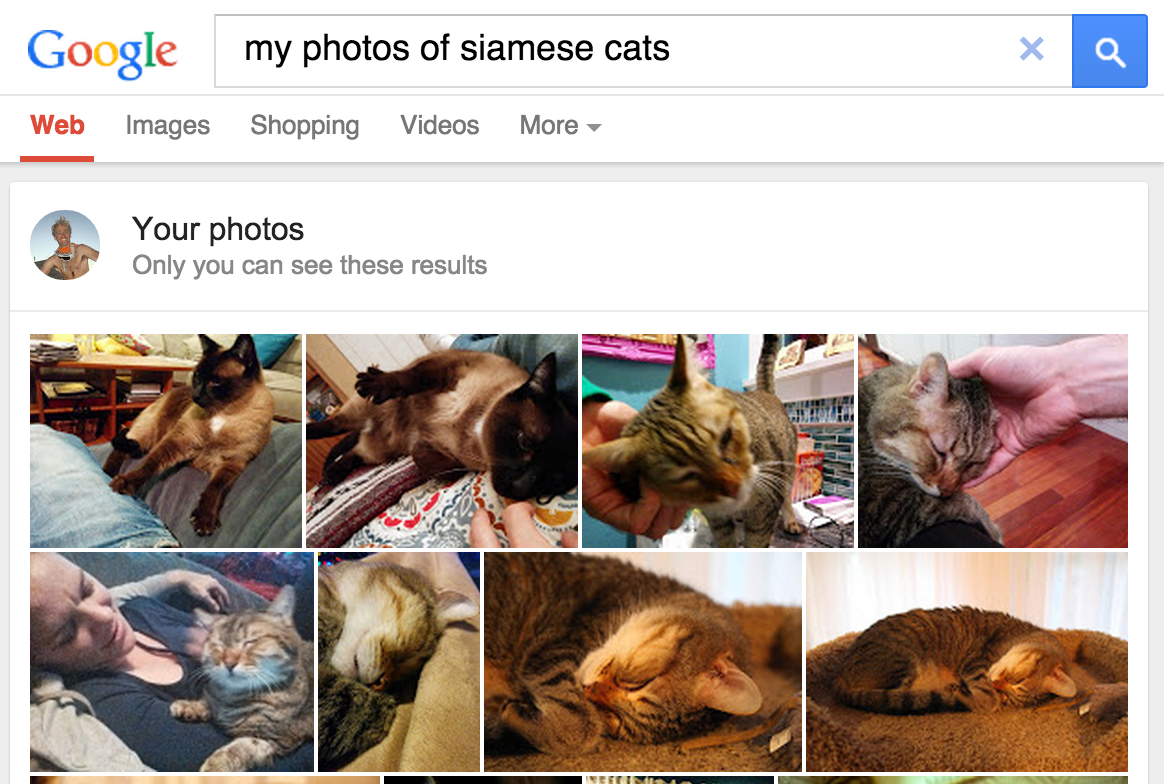 Gambar 1. Penelusuran Google Foto untuk
kucing Siiam dapat membantu pengiriman barang.
Gambar 1. Penelusuran Google Foto untuk
kucing Siiam dapat membantu pengiriman barang.
Fitur ini, yang kemudian dimasukkan ke dalam Google Foto pada tahun 2015, secara luas dianggap sebagai pengubah permainan, bukti konsep bahwa software computer vision dapat mengklasifikasikan gambar ke standar manusia, sehingga menambahkan nilai dalam beberapa cara:
- Pengguna tidak perlu lagi memberi tag pada foto dengan label seperti "pantai" untuk mengategorikan konten gambar, sehingga menghilangkan tugas manual yang bisa sangat membosankan saat mengelola kumpulan ratusan atau ribuan gambar.
- Pengguna dapat menjelajahi koleksi foto dengan cara baru, menggunakan istilah penelusuran untuk menemukan foto dengan objek yang mungkin belum pernah diberi tag. Misalnya, mereka dapat menelusuri "pohon palem" untuk menampilkan semua foto liburan mereka yang memiliki pohon palem di latar belakang.
- Software berpotensi "melihat" perbedaan taksonomi yang mungkin dijadikan pengguna akhir sendiri (misalnya, membedakan kucing Siam dan Abyssian), secara efektif meningkatkan pengetahuan pengguna' domain.
Cara Kerja Klasifikasi Gambar
Klasifikasi gambar adalah masalah pembelajaran yang diawasi: tentukan sekumpulan class target (objek yang akan diidentifikasi dalam gambar), dan latih model untuk mengenalinya menggunakan foto contoh berlabel. Model computer vision awal mengandalkan data piksel mentah sebagai input untuk model. Namun, seperti yang ditunjukkan pada Gambar 2, data piksel mentah saja tidak memberikan representasi yang cukup stabil untuk mencakup berbagai variasi objek seperti yang ditangkap dalam gambar. Posisi objek, latar belakang di belakang objek, pencahayaan sekitar, sudut kamera, dan fokus kamera semuanya dapat menghasilkan fluktuasi data piksel mentah; perbedaan ini cukup signifikan sehingga tidak dapat dikoreksi dengan mengambil rata-rata tertimbang dari nilai RGB piksel.
 Gambar 2. Kiri: Kucing dapat diambil
dalam foto dalam berbagai pose, dengan latar belakang dan kondisi pencahayaan
yang berbeda. Kanan: rata-rata data piksel untuk memperhitungkan variasi ini tidak menghasilkan informasi yang berarti.
Gambar 2. Kiri: Kucing dapat diambil
dalam foto dalam berbagai pose, dengan latar belakang dan kondisi pencahayaan
yang berbeda. Kanan: rata-rata data piksel untuk memperhitungkan variasi ini tidak menghasilkan informasi yang berarti.
Untuk membuat model objek lebih fleksibel, model computer vision klasik menambahkan fitur baru yang berasal dari data piksel, seperti histogram warna, tekstur, dan bentuk. Kelemahan dari pendekatan ini adalah bahwa engineer fitur menjadi beban yang sebenarnya, karena ada begitu banyak input yang harus disesuaikan. Untuk pengklasifikasi kucing, warna mana yang paling relevan? Seberapa fleksibel definisi bentuk? Karena fitur perlu disesuaikan dengan sangat tepat, membangun model yang kuat cukup menantang dan akurasi menjadi tidak baik.