Halaman ini berisi istilah glosarium Metrik. Untuk semua istilah glosarium, klik di sini.
A
akurasi
Jumlah prediksi klasifikasi yang benar dibagi dengan jumlah total prediksi. Definisinya yaitu:
Misalnya, model yang membuat 40 prediksi yang benar dan 10 prediksi yang salah akan memiliki akurasi:
Klasifikasi biner memberikan nama tertentu untuk berbagai kategori prediksi yang benar dan prediksi yang salah. Jadi, rumus akurasi untuk klasifikasi biner adalah sebagai berikut:
dengan:
- TP adalah jumlah positif benar (prediksi yang benar).
- TN adalah jumlah negatif benar (prediksi yang benar).
- FP adalah jumlah positif palsu (prediksi yang salah).
- FN adalah jumlah negatif palsu (prediksi yang salah).
Bandingkan dan bedakan akurasi dengan presisi dan perolehan.
Lihat Klasifikasi: Akurasi, perolehan, presisi, dan metrik terkait di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
area di bawah kurva PR
Lihat AUC PR (Area di bawah Kurva PR).
area di bawah kurva ROC
Lihat AUC (Area di bawah kurva ROC).
AUC (Area di bawah kurva ROC)
Angka antara 0,0 dan 1,0 yang merepresentasikan kemampuan model klasifikasi biner untuk memisahkan kelas positif dari kelas negatif. Semakin dekat AUC ke 1,0, semakin baik kemampuan model untuk memisahkan kelas satu sama lain.
Misalnya, ilustrasi berikut menunjukkan model klasifikasi yang memisahkan kelas positif (oval hijau) dari kelas negatif (persegi panjang ungu) dengan sempurna. Model yang sempurna secara tidak realistis ini memiliki AUC 1,0:

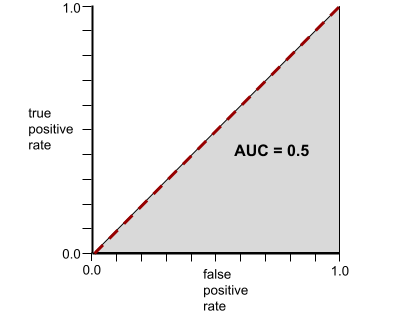
Sebaliknya, ilustrasi berikut menunjukkan hasil untuk model klasifikasi yang menghasilkan hasil acak. Model ini memiliki AUC 0,5:

Ya, model sebelumnya memiliki AUC 0,5, bukan 0,0.
Sebagian besar model berada di antara kedua ekstrem tersebut. Misalnya, model berikut memisahkan positif dari negatif, dan oleh karena itu memiliki AUC antara 0,5 dan 1,0:

AUC mengabaikan nilai apa pun yang Anda tetapkan untuk nilai minimum klasifikasi. Sebagai gantinya, AUC mempertimbangkan semua kemungkinan batas klasifikasi.
Klik ikon untuk mempelajari hubungan antara AUC dan kurva ROC.
AUC merepresentasikan area di bawah kurva ROC. Misalnya, kurva ROC untuk model yang memisahkan positif dari negatif dengan sempurna terlihat seperti berikut:
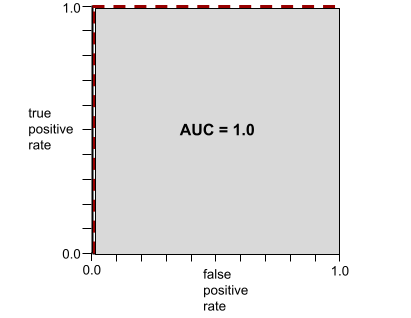
AUC adalah area wilayah abu-abu dalam ilustrasi sebelumnya. Dalam kasus yang tidak biasa ini, area tersebut hanyalah panjang area abu-abu (1.0) dikalikan dengan lebar area abu-abu (1.0). Jadi, hasil kali 1,0 dan 1,0 menghasilkan AUC tepat 1,0, yang merupakan skor AUC tertinggi yang mungkin.
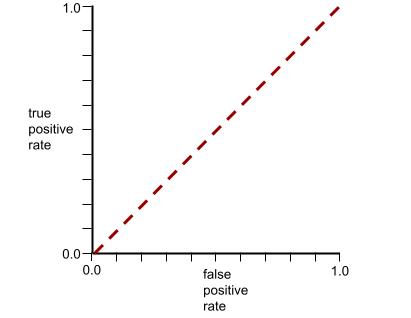
Sebaliknya, kurva ROC untuk model klasifikasi yang tidak dapat memisahkan kelas sama sekali adalah sebagai berikut. Area abu-abu ini adalah 0,5.
Kurva ROC yang lebih umum terlihat kira-kira seperti berikut:

Akan sangat sulit untuk menghitung luas area di bawah kurva ini secara manual, itulah sebabnya program biasanya menghitung sebagian besar nilai AUC.
Lihat Klasifikasi: KOP dan ABK di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
presisi rata-rata pada k
Metrik untuk meringkas performa model pada satu perintah yang menghasilkan hasil berperingkat, seperti daftar rekomendasi buku bernomor. Presisi rata-rata pada k, adalah rata-rata nilai presisi pada k untuk setiap hasil relevan. Oleh karena itu, rumus untuk presisi rata-rata pada k adalah:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
dengan:
- \(n\) adalah jumlah item yang relevan dalam daftar.
Berbeda dengan perolehan pada k.
B
dasar
Model yang digunakan sebagai titik referensi untuk membandingkan seberapa baik performa model lain (biasanya, model yang lebih kompleks). Misalnya, model regresi logistik dapat berfungsi sebagai dasar yang baik untuk model dalam.
Untuk masalah tertentu, tolok ukur membantu developer model mengukur performa minimum yang diharapkan yang harus dicapai oleh model baru agar model baru tersebut berguna.
Pertanyaan Boolean (BoolQ)
Set data untuk mengevaluasi kemahiran LLM dalam menjawab pertanyaan ya atau tidak. Setiap tantangan dalam set data memiliki tiga komponen:
- Kueri
- Bagian yang menyiratkan jawaban atas kueri.
- Jawaban yang benar, yaitu ya atau tidak.
Contoh:
- Kueri: Apakah ada pembangkit listrik tenaga nuklir di Michigan?
- Bagian: ...tiga pembangkit listrik tenaga nuklir memasok sekitar 30% listrik untuk Michigan.
- Jawaban benar: Ya
Peneliti mengumpulkan pertanyaan dari kueri Google Penelusuran yang dianonimkan dan digabungkan, lalu menggunakan halaman Wikipedia untuk mendasari informasi tersebut.
Untuk mengetahui informasi selengkapnya, lihat BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions.
BoolQ adalah komponen ansambel SuperGLUE.
BoolQ
Singkatan dari Boolean Questions.
C
CB
Singkatan dari CommitmentBank.
Skor F N-gram karakter (ChrF)
Metrik untuk mengevaluasi model terjemahan mesin. Skor F N-gram Karakter menentukan tingkat tumpang-tindih N-gram dalam teks rujukan dengan N-gram dalam teks yang dihasilkan model ML.
Skor-F N-gram Karakter mirip dengan metrik dalam keluarga ROUGE dan BLEU, kecuali bahwa:
- Skor F N-gram Karakter beroperasi pada N-gram karakter.
- ROUGE dan BLEU beroperasi pada N-gram kata atau token.
Pilihan Alternatif yang Masuk Akal (COPA)
Set data untuk mengevaluasi seberapa baik LLM dapat mengidentifikasi jawaban alternatif yang lebih baik dari dua jawaban alternatif untuk suatu premis. Setiap tantangan dalam set data terdiri dari tiga komponen:
- Premis, yang biasanya berupa pernyataan yang diikuti dengan pertanyaan
- Dua kemungkinan jawaban untuk pertanyaan yang diajukan dalam premis, salah satunya benar dan yang lainnya salah
- Jawaban yang benar
Contoh:
- Premis: Pria itu mematahkan jari kakinya. Apa PENYEBABNYA?
- Kemungkinan jawaban:
- Dia mendapatkan lubang di kausnya.
- Dia menjatuhkan palu di kakinya.
- Jawaban yang benar: 2
COPA adalah komponen ansambel SuperGLUE.
CommitmentBank (CB)
Set data untuk mengevaluasi kemahiran LLM dalam menentukan apakah penulis suatu bagian percaya pada klausa target dalam bagian tersebut. Setiap entri dalam set data berisi:
- Bagian
- Klausul target dalam bagian tersebut
- Nilai Boolean yang menunjukkan apakah penulis bagian tersebut meyakini klausa target
Contoh:
- Bagian: Betapa senangnya mendengar tawa Artemis. Dia anak yang sangat serius. Saya tidak tahu dia punya selera humor.
- Target klausa: dia memiliki selera humor
- Boolean: Benar (True), yang berarti penulis meyakini bahwa klausa target
CommitmentBank adalah komponen ansambel SuperGLUE.
COPA
Singkatan dari Choice of Plausible Alternatives.
biaya
Sinonim untuk loss.
keadilan kontrafaktual
Metrik keadilan yang memeriksa apakah model klasifikasi menghasilkan hasil yang sama untuk satu individu dengan individu lain yang identik dengan individu pertama, kecuali sehubungan dengan satu atau beberapa atribut sensitif. Mengevaluasi model klasifikasi untuk keadilan kontrafaktual adalah salah satu metode untuk menemukan potensi sumber bias dalam model.
Lihat salah satu referensi berikut untuk mengetahui informasi selengkapnya:
- Keadilan: Keadilan kontrafaktual dalam Kursus Singkat Machine Learning.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness
entropi silang
Generalisasi Log Loss ke masalah klasifikasi multikelas. Entropi silang mengukur perbedaan antara dua distribusi probabilitas. Lihat juga perpleksitas.
fungsi distribusi kumulatif (CDF)
Fungsi yang menentukan frekuensi sampel yang kurang dari atau sama dengan nilai target. Misalnya, pertimbangkan distribusi normal nilai berkelanjutan. CDF memberi tahu Anda bahwa sekitar 50% sampel harus kurang dari atau sama dengan rata-rata dan sekitar 84% sampel harus kurang dari atau sama dengan satu standar deviasi di atas rata-rata.
D
paritas demografis
Metrik keadilan yang terpenuhi jika hasil klasifikasi model tidak bergantung pada atribut sensitif tertentu.
Misalnya, jika orang Lilliput dan Brobdingnag mendaftar ke Universitas Glubbdubdrib, paritas demografi tercapai jika persentase orang Lilliput yang diterima sama dengan persentase orang Brobdingnag yang diterima, terlepas dari apakah satu kelompok rata-rata lebih memenuhi syarat daripada kelompok lainnya.
Berbeda dengan peluang yang sama dan kesetaraan peluang, yang memungkinkan hasil klasifikasi secara keseluruhan bergantung pada atribut sensitif, tetapi tidak memungkinkan hasil klasifikasi untuk label kebenaran nyata tertentu yang ditentukan bergantung pada atribut sensitif. Lihat "Menangani diskriminasi dengan machine learning yang lebih cerdas" untuk visualisasi yang mengeksplorasi pertukaran saat mengoptimalkan kesetaraan demografis.
Lihat Keadilan: kesetaraan demografis di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
E
jarak pemindah tanah (EMD)
Ukuran kemiripan relatif dari dua distribusi. Makin rendah jarak penggerak tanah, makin mirip distribusinya.
jarak pengeditan
Pengukuran seberapa mirip dua string teks satu sama lain. Dalam machine learning, jarak pengeditan berguna karena alasan berikut:
- Jarak pengeditan mudah dihitung.
- Jarak edit dapat membandingkan dua string yang diketahui serupa satu sama lain.
- Jarak pengeditan dapat menentukan tingkat kesamaan string yang berbeda dengan string tertentu.
Ada beberapa definisi jarak pengeditan, yang masing-masing menggunakan operasi string yang berbeda. Lihat Jarak Levenshtein untuk melihat contohnya.
fungsi distribusi kumulatif empiris (eCDF atau EDF)
Fungsi distribusi kumulatif berdasarkan pengukuran empiris dari set data nyata. Nilai fungsi di titik mana pun di sepanjang sumbu x adalah fraksi pengamatan dalam set data yang kurang dari atau sama dengan nilai yang ditentukan.
entropi
Dalam teori informasi, deskripsi tentang seberapa tidak terduga distribusi probabilitas. Atau, entropi juga didefinisikan sebagai seberapa banyak informasi yang terkandung dalam setiap contoh. Distribusi memiliki entropi tertinggi jika semua nilai variabel acak memiliki kemungkinan yang sama.
Entropi himpunan dengan dua kemungkinan nilai "0" dan "1" (misalnya, label dalam masalah klasifikasi biner) memiliki formula berikut:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
dengan:
- H adalah entropi.
- p adalah fraksi contoh "1".
- q adalah fraksi contoh "0". Perhatikan bahwa q = (1 - p)
- log umumnya adalah log2. Dalam hal ini, unit entropi adalah bit.
Misalnya, anggap saja hal berikut:
- 100 contoh berisi nilai "1"
- 300 contoh berisi nilai "0"
Oleh karena itu, nilai entropi adalah:
- p = 0,25
- q = 0,75
- H = (-0,25)log2(0,25) - (0,75)log2(0,75) = 0,81 bit per contoh
Kumpulan data yang seimbang sempurna (misalnya, 200 "0" dan 200 "1") akan memiliki entropi 1,0 bit per contoh. Seiring dengan makin tidak seimbangnya suatu set, entropinya bergerak menuju 0,0.
Dalam pohon keputusan, entropi membantu merumuskan perolehan informasi untuk membantu pemisah memilih kondisi selama pertumbuhan pohon keputusan klasifikasi.
Bandingkan entropi dengan:
- gini impurity
- Fungsi kerugian cross-entropy
Entropi sering disebut entropi Shannon.
Lihat Splitter persis untuk klasifikasi biner dengan fitur numerik dalam kursus Decision Forests untuk mengetahui informasi selengkapnya.
kesetaraan peluang
Metrik keadilan untuk menilai apakah model memprediksi hasil yang diinginkan dengan sama baiknya untuk semua nilai atribut sensitif. Dengan kata lain, jika hasil yang diinginkan untuk model adalah kelas positif, tujuannya adalah agar rasio positif benar sama untuk semua grup.
Kesetaraan peluang terkait dengan peluang yang sama, yang mengharuskan kedua rasio positif benar dan rasio positif palsu sama untuk semua grup.
Misalkan Universitas Glubbdubdrib menerima orang Lilliput dan Brobdingnag untuk mengikuti program matematika yang ketat. Sekolah menengah Lilliput menawarkan kurikulum kelas matematika yang kuat, dan sebagian besar siswa memenuhi syarat untuk program universitas. Sekolah menengah Brobdingnag tidak menawarkan kelas matematika sama sekali, sehingga lebih sedikit siswa mereka yang memenuhi syarat. Kesetaraan peluang terpenuhi untuk label pilihan "diterima" sehubungan dengan kewarganegaraan (Lilliput atau Brobdingnag) jika siswa yang memenuhi syarat memiliki peluang yang sama untuk diterima, terlepas dari apakah mereka berasal dari Lilliput atau Brobdingnag.
Misalnya, anggaplah 100 orang Lilliput dan 100 orang Brobdingnag mendaftar ke Universitas Glubbdubdrib, dan keputusan penerimaan dibuat sebagai berikut:
Tabel 1. Pelamar Lilliputian (90% memenuhi syarat)
| Berkualitas | Tidak memenuhi syarat | |
|---|---|---|
| Diizinkan | 45 | 3 |
| Ditolak | 45 | 7 |
| Total | 90 | 10 |
|
Persentase siswa yang memenuhi syarat yang diterima: 45/90 = 50% Persentase siswa yang tidak memenuhi syarat yang ditolak: 7/10 = 70% Total persentase siswa Lilliput yang diterima: (45+3)/100 = 48% |
||
Tabel 2. Pelamar Brobdingnagian (10% memenuhi syarat):
| Berkualitas | Tidak memenuhi syarat | |
|---|---|---|
| Diizinkan | 5 | 9 |
| Ditolak | 5 | 81 |
| Total | 10 | 90 |
|
Persentase siswa yang memenuhi syarat yang diterima: 5/10 = 50% Persentase siswa yang tidak memenuhi syarat yang ditolak: 81/90 = 90% Total persentase siswa Brobdingnag yang diterima: (5+9)/100 = 14% |
||
Contoh sebelumnya memenuhi kesetaraan peluang untuk penerimaan siswa yang memenuhi syarat karena Lilliputian dan Brobdingnagian yang memenuhi syarat memiliki peluang 50% untuk diterima.
Meskipun kesetaraan peluang terpenuhi, dua metrik keadilan berikut tidak terpenuhi:
- kesetaraan demografis: Lilliputian dan Brobdingnagian diterima di universitas dengan tingkat yang berbeda; 48% siswa Lilliputian diterima, tetapi hanya 14% siswa Brobdingnagian yang diterima.
- peluang yang sama: Meskipun siswa Lilliput dan Brobdingnag yang memenuhi syarat memiliki peluang yang sama untuk diterima, batasan tambahan bahwa siswa Lilliput dan Brobdingnag yang tidak memenuhi syarat memiliki peluang yang sama untuk ditolak tidak terpenuhi. Lilliput yang tidak memenuhi syarat memiliki rasio penolakan 70%, sedangkan Brobdingnag yang tidak memenuhi syarat memiliki rasio penolakan 90%.
Lihat Keadilan: Kesetaraan peluang di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
peluang yang sama
Metrik keadilan untuk menilai apakah model memprediksi hasil dengan sama baiknya untuk semua nilai atribut sensitif sehubungan dengan kelas positif dan kelas negatif—bukan hanya satu kelas atau kelas lainnya secara eksklusif. Dengan kata lain, rasio positif benar dan rasio negatif palsu harus sama untuk semua grup.
Peluang yang sama terkait dengan kesetaraan peluang, yang hanya berfokus pada tingkat kesalahan untuk satu kelas (positif atau negatif).
Misalnya, Universitas Glubbdubdrib menerima orang Lilliput dan Brobdingnag untuk mengikuti program matematika yang ketat. Sekolah menengah Lilliput menawarkan kurikulum kelas matematika yang kuat, dan sebagian besar siswa memenuhi syarat untuk program universitas. Sekolah menengah Brobdingnag tidak menawarkan kelas matematika sama sekali, dan akibatnya, lebih sedikit siswa mereka yang memenuhi syarat. Peluang yang sama akan terpenuhi asalkan terlepas dari apakah pelamar adalah Lilliputian atau Brobdingnagian, jika mereka memenuhi syarat, mereka memiliki peluang yang sama untuk diterima dalam program tersebut, dan jika mereka tidak memenuhi syarat, mereka memiliki peluang yang sama untuk ditolak.
Misalkan 100 orang Lilliput dan 100 orang Brobdingnag mendaftar ke Universitas Glubbdubdrib, dan keputusan penerimaan dibuat sebagai berikut:
Tabel 3. Pelamar Lilliputian (90% memenuhi syarat)
| Berkualitas | Tidak memenuhi syarat | |
|---|---|---|
| Diizinkan | 45 | 2 |
| Ditolak | 45 | 8 |
| Total | 90 | 10 |
|
Persentase siswa yang memenuhi syarat yang diterima: 45/90 = 50% Persentase siswa yang tidak memenuhi syarat yang ditolak: 8/10 = 80% Total persentase siswa Lilliput yang diterima: (45+2)/100 = 47% |
||
Tabel 4. Pelamar Brobdingnagian (10% memenuhi syarat):
| Berkualitas | Tidak memenuhi syarat | |
|---|---|---|
| Diizinkan | 5 | 18 |
| Ditolak | 5 | 72 |
| Total | 10 | 90 |
|
Persentase siswa yang memenuhi syarat yang diterima: 5/10 = 50% Persentase siswa yang tidak memenuhi syarat yang ditolak: 72/90 = 80% Total persentase siswa Brobdingnag yang diterima: (5+18)/100 = 23% |
||
Peluang yang sama terpenuhi karena siswa Lilliput dan Brobdingnag yang memenuhi syarat memiliki peluang 50% untuk diterima, dan siswa Lilliput dan Brobdingnag yang tidak memenuhi syarat memiliki peluang 80% untuk ditolak.
Peluang yang sama didefinisikan secara formal dalam "Equality of Opportunity in Supervised Learning" sebagai berikut: "prediktor Ŷ memenuhi peluang yang sama sehubungan dengan atribut yang dilindungi A dan hasil Y jika Ŷ dan A independen, bersyarat pada Y."
evaluasi
Terutama digunakan sebagai singkatan untuk evaluasi LLM. Secara umum, evaluasi adalah singkatan untuk segala bentuk evaluasi.
evaluasi
Proses mengukur kualitas model atau membandingkan berbagai model satu sama lain.
Untuk mengevaluasi model machine learning terawasi, Anda biasanya menilainya berdasarkan set validasi dan set pengujian. Mengevaluasi LLM biasanya melibatkan penilaian kualitas dan keamanan yang lebih luas.
pencocokan persis
Metrik semua atau tidak sama sekali yang output modelnya cocok dengan kebenaran nyata atau teks referensi secara persis atau tidak. Misalnya, jika kebenaran dasarnya adalah orange, satu-satunya output model yang memenuhi pencocokan persis adalah orange.
Pencocokan persis juga dapat mengevaluasi model yang outputnya berupa urutan (daftar item yang diberi peringkat). Secara umum, pencocokan persis mengharuskan daftar berperingkat yang dihasilkan cocok persis dengan data sebenarnya; yaitu, setiap item dalam kedua daftar harus dalam urutan yang sama. Namun, jika kebenaran dasar terdiri dari beberapa urutan yang benar, pencocokan persis hanya memerlukan output model yang cocok dengan salah satu urutan yang benar.
Ringkasan Ekstrem (xsum)
Set data untuk mengevaluasi kemampuan LLM dalam meringkas satu dokumen. Setiap entri dalam set data terdiri dari:
- Dokumen yang ditulis oleh British Broadcasting Corporation (BBC).
- Ringkasan satu kalimat dari dokumen tersebut.
Untuk mengetahui detailnya, lihat Jangan Beri Saya Detailnya, Cukup Ringkasannya Saja! Topic-Aware Convolutional Neural Networks for Extreme Summarization.
F
F1
Metrik "gabungan" klasifikasi biner yang mengandalkan presisi dan perolehan. Berikut rumusnya:
metrik keadilan
Definisi matematika tentang "keadilan" yang dapat diukur. Beberapa metrik keadilan yang umum digunakan meliputi:
Banyak metrik keadilan yang saling eksklusif; lihat ketidakcocokan metrik keadilan.
negatif palsu (NP)
Contoh yang mana model salah memprediksi kelas negatif. Misalnya, model memprediksi bahwa pesan email tertentu bukan spam (kelas negatif), tetapi pesan email tersebut sebenarnya adalah spam.
rasio negatif palsu
Proporsi contoh positif sebenarnya yang salah diprediksi oleh model sebagai kelas negatif. Formula berikut menghitung rasio negatif palsu:
Lihat Nilai minimum dan matriks kebingungan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
positif palsu (PP)
Contoh yang mana model salah memprediksi kelas positif. Misalnya, model memprediksi bahwa pesan email tertentu adalah spam (kelas positif), tetapi pesan email tersebut sebenarnya bukan spam.
Lihat Nilai minimum dan matriks kebingungan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
rasio positif palsu (FPR)
Proporsi contoh negatif sebenarnya yang mana model salah memprediksi kelas positif. Formula berikut menghitung rasio positif palsu:
Rasio positif palsu adalah sumbu x dalam kurva ROC.
Lihat Klasifikasi: KOP dan ABK di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
tingkat kepentingan fitur
Sinonim untuk kepentingan variabel.
model dasar
Model terlatih yang sangat besar dan dilatih pada set pelatihan yang sangat besar dan beragam. Model dasar dapat melakukan kedua hal berikut:
- Merespons dengan baik berbagai permintaan.
- Berfungsi sebagai model dasar untuk penyesuaian tambahan atau penyesuaian lainnya.
Dengan kata lain, model dasar sudah sangat mumpuni secara umum, tetapi dapat disesuaikan lebih lanjut agar lebih berguna untuk tugas tertentu.
fraksi keberhasilan
Metrik untuk mengevaluasi teks yang dihasilkan model ML. Pecahan keberhasilan adalah jumlah output teks yang dihasilkan "berhasil" dibagi dengan total jumlah output teks yang dihasilkan. Misalnya, jika model bahasa besar menghasilkan 10 blok kode, lima di antaranya berhasil, maka rasio keberhasilannya adalah 50%.
Meskipun fraksi keberhasilan sangat berguna dalam statistik, dalam ML, metrik ini terutama berguna untuk mengukur tugas yang dapat diverifikasi seperti pembuatan kode atau masalah matematika.
G
ketidakmurnian gini
Metrik yang mirip dengan entropi. Splitter menggunakan nilai yang berasal dari ketidakmurnian Gini atau entropi untuk menyusun kondisi untuk klasifikasi pohon keputusan. Perolehan informasi berasal dari entropi. Tidak ada istilah setara yang diterima secara universal untuk metrik yang berasal dari ketidakmurnian gini; namun, metrik yang tidak disebutkan namanya ini sama pentingnya dengan perolehan informasi.
Ketidakmurnian Gini juga disebut indeks gini, atau cukup gini.
H
kerugian engsel
Serangkaian fungsi loss untuk klasifikasi yang dirancang untuk menemukan batas keputusan sejauh mungkin dari setiap contoh pelatihan, sehingga memaksimalkan margin antara contoh dan batas. KSVMs menggunakan kerugian engsel (atau fungsi terkait, seperti kerugian engsel kuadrat). Untuk klasifikasi biner, fungsi kerugian hinge didefinisikan sebagai berikut:
dengan y adalah label sebenarnya, -1 atau +1, dan y' adalah output mentah dari model klasifikasi:
Oleh karena itu, plot kerugian engsel versus (y * y') terlihat sebagai berikut:

I
ketidakcocokan metrik keadilan
Gagasan bahwa beberapa konsep keadilan tidak kompatibel satu sama lain dan tidak dapat dipenuhi secara bersamaan. Akibatnya, tidak ada satu metrik universal untuk mengukur keadilan yang dapat diterapkan pada semua masalah ML.
Meskipun hal ini mungkin tampak mengecewakan, ketidakcocokan metrik keadilan tidak berarti upaya keadilan tidak membuahkan hasil. Sebagai gantinya, hal ini menunjukkan bahwa keadilan harus ditentukan secara kontekstual untuk masalah ML tertentu, dengan tujuan mencegah bahaya khusus untuk kasus penggunaannya.
Lihat "On the (im)possibility of fairness" untuk mengetahui pembahasan yang lebih mendetail tentang ketidakcocokan metrik keadilan.
keadilan individu
Metrik keadilan yang memeriksa apakah individu yang serupa diklasifikasikan secara serupa. Misalnya, Brobdingnagian Academy mungkin ingin memenuhi keadilan individu dengan memastikan bahwa dua siswa dengan nilai yang sama dan skor tes standar memiliki peluang yang sama untuk diterima.
Perhatikan bahwa keadilan individu sepenuhnya bergantung pada cara Anda mendefinisikan "kesamaan" (dalam hal ini, nilai dan skor tes), dan Anda dapat berisiko memunculkan masalah keadilan baru jika metrik kesamaan Anda melewatkan informasi penting (seperti ketelitian kurikulum siswa).
Lihat "Keadilan Melalui Kesadaran" untuk pembahasan yang lebih mendetail tentang keadilan individu.
perolehan informasi
Dalam hutan keputusan, perbedaan antara entropi node dan jumlah entropi node turunannya yang diberi bobot (berdasarkan jumlah contoh). Entropi node adalah entropi contoh di node tersebut.
Misalnya, pertimbangkan nilai entropi berikut:
- entropi node induk = 0,6
- entropi satu node turunan dengan 16 contoh relevan = 0,2
- entropi node turunan lain dengan 24 contoh yang relevan = 0,1
Jadi, 40% contoh berada di satu node turunan dan 60% berada di node turunan lainnya. Jadi:
- jumlah entropi berbobot dari node turunan = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Jadi, perolehan informasi adalah:
- perolehan informasi = entropi node induk - jumlah entropi tertimbang node turunan
- perolehan informasi = 0,6 - 0,14 = 0,46
Sebagian besar pemisah berupaya membuat kondisi yang memaksimalkan perolehan informasi.
kecocokan antar-penilai
Pengukuran seberapa sering pemberi rating manusia setuju saat melakukan tugas. Jika pemberi rating tidak setuju, petunjuk tugas mungkin perlu ditingkatkan. Terkadang disebut juga kecocokan antar-anotator atau reliabilitas antar-pelabel. Lihat juga kappa Cohen, yang merupakan salah satu pengukuran kecocokan antar-pelabel yang paling populer.
Lihat Data kategoris: Masalah umum di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
L
Kerugian L1
Fungsi kerugian yang menghitung nilai absolut dari perbedaan antara nilai label aktual dan nilai yang diprediksi oleh model. Misalnya, berikut adalah penghitungan kerugian L1 untuk batch lima contoh:
| Nilai sebenarnya contoh | Nilai yang diprediksi model | Nilai absolut delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = kerugian L1 | ||
Kerugian L1 kurang sensitif terhadap pencilan daripada kerugian L2.
Rataan Galat Mutlak adalah rata-rata kerugian L1 per contoh.
Lihat Regresi linear: Loss di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Kerugian L2
Fungsi kerugian yang menghitung kuadrat perbedaan antara nilai label aktual dan nilai yang diprediksi oleh model. Misalnya, berikut adalah penghitungan kerugian L2 untuk batch lima contoh:
| Nilai sebenarnya contoh | Nilai yang diprediksi model | Kuadrat delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = kerugian L2 | ||
Karena adanya kuadrat, kerugian L2 memperkuat pengaruh pencilan. Artinya, kerugian L2 bereaksi lebih kuat terhadap prediksi yang buruk daripada kerugian L1. Misalnya, kerugian L1 untuk batch sebelumnya adalah 8, bukan 16. Perhatikan bahwa satu pencilan menyumbang 9 dari 16.
Model regresi biasanya menggunakan kerugian L2 sebagai fungsi kerugian.
Rataan Kuadrat Galat adalah rata-rata kerugian L2 per contoh. Kerugian kuadrat adalah nama lain untuk kerugian L2.
Lihat Regresi logistik: Loss dan regularisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Evaluasi LLM (evaluasi)
Serangkaian metrik dan tolok ukur untuk menilai performa model bahasa besar (LLM). Secara umum, evaluasi LLM:
- Membantu peneliti mengidentifikasi area yang perlu ditingkatkan pada LLM.
- Berguna dalam membandingkan berbagai LLM dan mengidentifikasi LLM terbaik untuk tugas tertentu.
- Membantu memastikan bahwa LLM aman dan etis untuk digunakan.
Lihat Model bahasa besar (LLM) di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
kekalahan
Selama pelatihan model yang diawasi, ukuran seberapa jauh prediksi model dari labelnya.
Fungsi kerugian menghitung kerugian.
Lihat Regresi linear: Loss di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
fungsi kerugian
Selama pelatihan atau pengujian, fungsi matematika yang menghitung kerugian pada batch contoh. Fungsi kerugian menampilkan kerugian yang lebih rendah untuk model yang membuat prediksi baik daripada model yang membuat prediksi buruk.
Tujuan pelatihan biasanya adalah untuk meminimalkan kerugian yang dihasilkan oleh fungsi kerugian.
Ada berbagai jenis fungsi kerugian. Pilih fungsi kerugian yang sesuai untuk jenis model yang Anda buat. Contoh:
- Kerugian L2 (atau Rataan Kuadrat Galat) adalah fungsi kerugian untuk regresi linear.
- Kerugian Log adalah fungsi kerugian untuk regresi logistik.
M
MBPP
Singkatan dari Mostly Basic Python Problems.
Rata-Rata Error Absolut (MAE)
Rata-rata kerugian per contoh saat L1 loss digunakan. Hitung Rata-Rata Error Absolut sebagai berikut:
- Menghitung kerugian L1 untuk batch.
- Membagi kerugian L1 dengan jumlah contoh dalam batch.
Misalnya, pertimbangkan penghitungan kerugian L1 pada batch lima contoh berikut:
| Nilai sebenarnya contoh | Nilai yang diprediksi model | Loss (perbedaan antara aktual dan prediksi) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = kerugian L1 | ||
Jadi, kerugian L1 adalah 8 dan jumlah contohnya adalah 5. Oleh karena itu, Rata-Rata Error Absolut adalah:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Bandingkan Galat Mutlak Rata-Rata dengan Rataan Kuadrat Galat dan Galat Akar Rataan Kuadrat.
presisi rata-rata pada k (mAP@k)
Rata-rata statistik dari semua skor presisi rata-rata pada k di seluruh set data validasi. Salah satu penggunaan presisi rata-rata mean pada k adalah untuk menilai kualitas rekomendasi yang dihasilkan oleh sistem rekomendasi.
Meskipun frasa "rata-rata" terdengar berlebihan, nama metrik ini sudah tepat. Bagaimanapun, metrik ini menemukan rata-rata dari beberapa nilai presisi rata-rata pada k.
Rataan Kuadrat Galat (MSE)
Rata-rata kerugian per contoh saat L2 loss digunakan. Hitung Rataan Kuadrat Galat (RKG) sebagai berikut:
- Menghitung kerugian L2 untuk batch.
- Membagi kerugian L2 dengan jumlah contoh dalam batch.
Misalnya, pertimbangkan kerugian pada batch lima contoh berikut:
| Nilai sebenarnya | Prediksi model | Kerugian | Kerugian kuadrat |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = kerugian L2 | |||
Oleh karena itu, Rataan Kuadrat Galat adalah:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
Rataan Kuadrat Galat adalah pengoptimal pelatihan yang populer, terutama untuk regresi linear.
Bandingkan Rataan Kuadrat Galat dengan Rataan Galat Mutlak dan Galat Akar Rataan Kuadrat.
TensorFlow Playground menggunakan Mean Squared Error untuk menghitung nilai kerugian.
metrik
Statistik yang Anda minati.
Tujuan adalah metrik yang coba dioptimalkan oleh sistem machine learning.
Metrics API (tf.metrics)
API TensorFlow untuk mengevaluasi model. Misalnya, tf.metrics.accuracy
menentukan seberapa sering prediksi model cocok dengan label.
kerugian minimax
Fungsi kerugian untuk jaringan saraf generatif berlawanan, berdasarkan entropi silang antara distribusi data yang dihasilkan dan data nyata.
Kerugian minimax digunakan dalam makalah pertama untuk mendeskripsikan jaringan adversarial generatif.
Lihat Loss Functions dalam kursus Generative Adversarial Networks untuk mengetahui informasi selengkapnya.
kapasitas model
Kompleksitas masalah yang dapat dipelajari oleh model. Semakin kompleks masalah yang dapat dipelajari model, semakin tinggi pula kapasitas model. Kapasitas model biasanya meningkat seiring dengan jumlah parameter model. Untuk definisi formal kapasitas model klasifikasi, lihat dimensi VC.
Sebagian Besar Masalah Python Dasar (MBPP)
Set data untuk mengevaluasi kemahiran LLM dalam membuat kode Python. Mostly Basic Python Problems menyediakan sekitar 1.000 masalah pemrograman yang diperoleh dari banyak sumber. Setiap masalah dalam set data berisi:
- Deskripsi tugas
- Kode solusi
- Tiga kasus pengujian otomatis
T
kelas negatif
Dalam klasifikasi biner, satu kelas disebut positif dan kelas lainnya disebut negatif. Kelas positif adalah hal atau peristiwa yang diuji oleh model dan kelas negatif adalah kemungkinan lainnya. Contoh:
- Kelas negatif dalam tes medis dapat berupa "bukan tumor".
- Kelas negatif dalam model klasifikasi email dapat berupa "bukan spam".
Berbeda dengan kelas positif.
O
tujuan
Metrik yang coba dioptimalkan oleh algoritma Anda.
fungsi objektif
Formula matematika atau metrik yang ingin dioptimalkan oleh model. Misalnya, fungsi objektif untuk regresi linear biasanya adalah Mean Squared Loss. Oleh karena itu, saat melatih model regresi linear, pelatihan bertujuan untuk meminimalkan Rataan Kuadrat Galat.
Dalam beberapa kasus, tujuannya adalah memaksimalkan fungsi objektif. Misalnya, jika fungsi objektifnya adalah akurasi, tujuannya adalah untuk memaksimalkan akurasi.
Lihat juga loss.
P
lulus pada k (pass@k)
Metrik untuk menentukan kualitas kode (misalnya, Python) yang dihasilkan oleh model bahasa besar. Lebih khusus lagi, lulus pada k memberi tahu Anda kemungkinan bahwa setidaknya satu blok kode yang dihasilkan dari k blok kode yang dihasilkan akan lulus semua pengujian unitnya.
Model bahasa besar sering kali kesulitan menghasilkan kode yang baik untuk masalah pemrograman yang kompleks. Software engineer beradaptasi dengan masalah ini dengan meminta model bahasa besar untuk membuat beberapa (k) solusi untuk masalah yang sama. Kemudian, software engineer menguji setiap solusi terhadap pengujian unit. Penghitungan lulus pada k bergantung pada hasil pengujian unit:
- Jika satu atau beberapa solusi tersebut lulus pengujian unit, maka LLM Lulus tantangan pembuatan kode tersebut.
- Jika tidak ada solusi yang lulus pengujian unit, maka LLM Gagal dalam tantangan pembuatan kode tersebut.
Rumus untuk lulus pada k adalah sebagai berikut:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
Secara umum, nilai k yang lebih tinggi menghasilkan skor lulus pada k yang lebih tinggi; namun, nilai k yang lebih tinggi memerlukan lebih banyak resource pengujian unit dan model bahasa besar.
performa
Istilah yang memiliki lebih dari satu makna:
- Arti standar dalam software engineering. Yaitu: Seberapa cepat (atau efisien) software ini berjalan?
- Makna dalam machine learning. Di sini, performa menjawab pertanyaan berikut: Seberapa benar model ini? Artinya, seberapa baik prediksi model?
permutation variable importances
Jenis kepentingan variabel yang mengevaluasi peningkatan error prediksi model setelah melakukan permutasi pada nilai fitur. Permutation variable importance adalah metrik independen model.
kebingungan
Salah satu ukuran terkait seberapa baik model menyelesaikan tugasnya. Misalnya, tugas Anda adalah membaca beberapa huruf pertama dari kata yang diketik pengguna di keyboard ponsel, dan menawarkan daftar kata yang mungkin melengkapi kata tersebut. Perplexity, P, untuk tugas ini kira-kira adalah jumlah tebakan yang perlu Anda berikan agar daftar Anda berisi kata sebenarnya yang sedang diketik pengguna.
Perpleksitas terkait dengan entropi silang sebagai berikut:
kelas positif
Kelas yang Anda uji.
Misalnya, kelas positif dalam model kanker dapat berupa "tumor". Kelas positif dalam model klasifikasi email dapat berupa "spam".
Berbeda dengan kelas negatif.
AUC PR (area di bawah kurva PR)
Area di bawah kurva presisi-recall yang diinterpolasi, diperoleh dengan memetakan titik (recall, presisi) untuk berbagai nilai batas klasifikasi.
presisi
Metrik untuk model klasifikasi yang menjawab pertanyaan berikut:
Saat model memprediksi kelas positif, berapa persentase prediksi yang benar?
Berikut rumusnya:
dengan:
- positif benar berarti model dengan benar memprediksi kelas positif.
- positif palsu berarti model salah memprediksi kelas positif.
Misalnya, anggaplah model membuat 200 prediksi positif. Dari 200 prediksi positif ini:
- 150 di antaranya adalah positif benar.
- 50 di antaranya adalah positif palsu.
Dalam hal ini:
Berbeda dengan akurasi dan perolehan.
Lihat Klasifikasi: Akurasi, perolehan, presisi, dan metrik terkait di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
presisi di k (precision@k)
Metrik untuk mengevaluasi daftar item yang diberi peringkat (diurutkan). Presisi pada k mengidentifikasi fraksi dari k item pertama dalam daftar tersebut yang "relevan". Definisinya yaitu:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
Nilai k harus kurang dari atau sama dengan panjang daftar yang ditampilkan. Perhatikan bahwa panjang daftar yang ditampilkan bukan bagian dari perhitungan.
Relevansi sering kali bersifat subjektif; bahkan evaluator manusia pakar sering kali tidak setuju mengenai item mana yang relevan.
Bandingkan dengan:
kurva presisi-recall
Kurva presisi versus recall pada berbagai batas klasifikasi.
bias prediksi
Nilai yang menunjukkan seberapa jauh rata-rata prediksi dari rata-rata label dalam set data.
Harap bedakan dengan istilah bias dalam model machine learning atau dengan bias dalam etika dan keadilan.
kesetaraan prediktif
Metrik keadilan yang memeriksa apakah, untuk model klasifikasi tertentu, tingkat presisi setara untuk subgrup yang sedang dipertimbangkan.
Misalnya, model yang memprediksi penerimaan di perguruan tinggi akan memenuhi paritas prediktif untuk kewarganegaraan jika tingkat presisinya sama untuk Lilliputians dan Brobdingnagians.
Paritas prediktif terkadang juga disebut paritas tarif prediktif.
Lihat "Penjelasan Definisi Keadilan" (bagian 3.2.1) untuk pembahasan yang lebih mendetail tentang paritas prediktif.
paritas tarif prediktif
Nama lain untuk paritas prediktif.
fungsi kepadatan probabilitas
Fungsi yang mengidentifikasi frekuensi sampel data yang memiliki persis nilai tertentu. Jika nilai set data adalah bilangan floating point kontinu, kecocokan persis jarang terjadi. Namun, mengintegrasikan fungsi kepadatan probabilitas dari nilai x ke nilai y akan menghasilkan frekuensi sampel data yang diharapkan antara x dan y.
Misalnya, pertimbangkan distribusi normal yang memiliki rata-rata 200 dan deviasi standar 30. Untuk menentukan frekuensi sampel data yang diharapkan berada dalam rentang 211,4 hingga 218,7, Anda dapat mengintegrasikan fungsi kepadatan probabilitas untuk distribusi normal dari 211,4 hingga 218,7.
R
Dataset Pemahaman Bacaan dengan Penalaran yang Wajar (ReCoRD)
Set data untuk mengevaluasi kemampuan LLM dalam melakukan penalaran akal sehat. Setiap contoh dalam set data berisi tiga komponen:
- Satu atau dua paragraf dari artikel berita
- Kueri yang salah satu entitasnya diidentifikasi secara eksplisit atau implisit dalam bagian teks ditutupi.
- Jawaban (nama entity yang termasuk dalam mask)
Lihat ReCoRD untuk mengetahui daftar contoh yang lengkap.
ReCoRD adalah komponen ansambel SuperGLUE.
RealToxicityPrompts
Set data yang berisi sekumpulan awal kalimat yang mungkin berisi konten berbahaya. Gunakan set data ini untuk mengevaluasi kemampuan LLM dalam membuat teks tidak berbahaya untuk melengkapi kalimat. Biasanya, Anda menggunakan Perspective API untuk menentukan seberapa baik LLM melakukan tugas ini.
Lihat RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models untuk mengetahui detailnya.
ingatan
Metrik untuk model klasifikasi yang menjawab pertanyaan berikut:
Jika kebenaran dasar adalah kelas positif, berapa persentase prediksi yang diidentifikasi model dengan benar sebagai kelas positif?
Berikut rumusnya:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
dengan:
- positif benar berarti model dengan benar memprediksi kelas positif.
- negatif palsu berarti model salah memprediksi kelas negatif.
Misalnya, model Anda membuat 200 prediksi pada contoh yang kebenaran nyatanya adalah kelas positif. Dari 200 prediksi ini:
- 180 di antaranya adalah positif benar.
- 20 adalah negatif palsu.
Dalam hal ini:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Lihat Klasifikasi: Akurasi, perolehan, presisi, dan metrik terkait untuk mengetahui informasi selengkapnya.
perolehan pada k (recall@k)
Metrik untuk mengevaluasi sistem yang menghasilkan daftar item yang diberi peringkat (diurutkan). Perolehan pada k mengidentifikasi fraksi item yang relevan dalam k item pertama dalam daftar tersebut dari total jumlah item relevan yang ditampilkan.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Berbeda dengan presisi pada k.
Mengenali Implikasi Teks (RTE)
Set data untuk mengevaluasi kemampuan LLM dalam menentukan apakah suatu hipotesis dapat disimpulkan (ditarik secara logis) dari bagian teks. Setiap contoh dalam evaluasi RTE terdiri dari tiga bagian:
- Kutipan, biasanya dari artikel berita atau Wikipedia
- Hipotesis
- Jawaban yang benar, yang berupa:
- Benar (True), artinya hipotesis dapat disimpulkan dari teks
- Salah (False), artinya hipotesis tidak dapat disimpulkan dari teks
Contoh:
- Bagian: Euro adalah mata uang Uni Eropa.
- Hipotesis: Prancis menggunakan Euro sebagai mata uang.
- Implikasi (Entailment): Benar, karena Prancis adalah bagian dari Uni Eropa.
RTE adalah komponen ansambel SuperGLUE.
ReCoRD
Singkatan dari Reading Comprehension with Commonsense Reasoning Dataset.
Kurva ROC (receiver operating characteristic)
Grafik rasio positif benar versus rasio positif palsu untuk berbagai ambang batas klasifikasi dalam klasifikasi biner.
Bentuk kurva ROC menunjukkan kemampuan model klasifikasi biner untuk memisahkan kelas positif dari kelas negatif. Misalnya, model klasifikasi biner memisahkan semua kelas negatif dengan sempurna dari semua kelas positif:
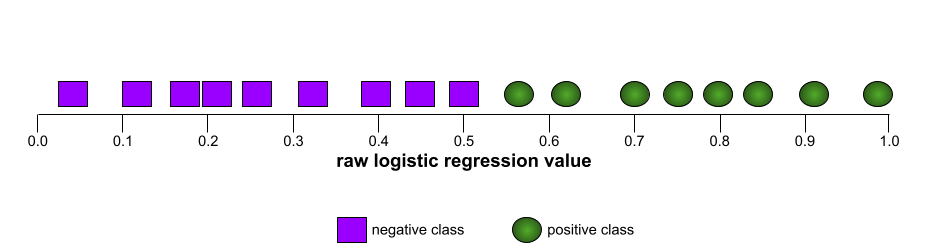
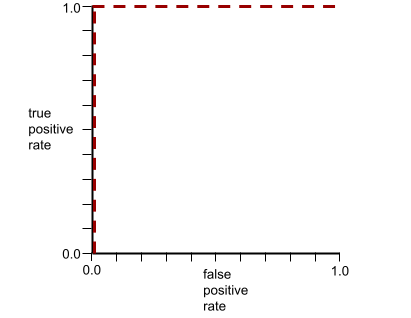
Kurva ROC untuk model sebelumnya terlihat seperti berikut:
Sebaliknya, ilustrasi berikut menggambarkan nilai regresi logistik mentah untuk model yang buruk dan tidak dapat memisahkan kelas negatif dari kelas positif sama sekali:
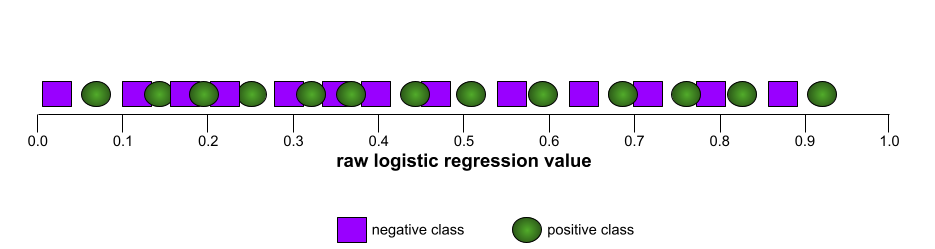
Kurva ROC untuk model ini terlihat seperti berikut:
Sementara itu, kembali ke dunia nyata, sebagian besar model klasifikasi biner memisahkan kelas positif dan negatif sampai batas tertentu, tetapi biasanya tidak sempurna. Jadi, kurva ROC yang umum berada di antara dua titik ekstrem:
Titik pada kurva ROC yang paling dekat dengan (0,0,1,0) secara teoretis mengidentifikasi batas klasifikasi yang ideal. Namun, beberapa masalah dunia nyata lainnya memengaruhi pemilihan nilai minimum klasifikasi yang ideal. Misalnya, negatif palsu mungkin menyebabkan lebih banyak masalah daripada positif palsu.
Metrik numerik yang disebut AUC meringkas kurva ROC menjadi satu nilai floating point.
Galat Akar Rataan Kuadrat (RMSE)
Akar kuadrat dari Rataan Kuadrat Galat.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Serangkaian metrik yang mengevaluasi model ringkasan otomatis dan terjemahan mesin. Metrik ROUGE menentukan tingkat tumpang-tindih teks referensi dengan teks yang dihasilkan model ML. Setiap anggota keluarga ROUGE mengukur tumpang-tindih dengan cara yang berbeda. Skor ROUGE yang lebih tinggi menunjukkan lebih banyak kesamaan antara teks referensi dan teks yang dihasilkan daripada skor ROUGE yang lebih rendah.
Setiap anggota keluarga ROUGE biasanya menghasilkan metrik berikut:
- Presisi
- Recall
- F1
Untuk mengetahui detail dan contohnya, lihat:
ROUGE-L
Anggota keluarga ROUGE yang berfokus pada panjang subsekuens umum terpanjang dalam teks referensi dan teks yang dihasilkan. Rumus berikut menghitung perolehan dan presisi untuk ROUGE-L:
Kemudian, Anda dapat menggunakan F1 untuk menggabungkan recall ROUGE-L dan presisi ROUGE-L ke dalam satu metrik:
ROUGE-L mengabaikan semua baris baru dalam teks referensi dan teks yang dihasilkan, sehingga subsekuens umum terpanjang dapat mencakup beberapa kalimat. Jika teks rujukan dan teks yang dihasilkan melibatkan beberapa kalimat, variasi ROUGE-L yang disebut ROUGE-Lsum umumnya merupakan metrik yang lebih baik. ROUGE-Lsum menentukan subsekuen umum terpanjang untuk setiap kalimat dalam sebuah bagian, lalu menghitung rata-rata subsekuen umum terpanjang tersebut.
ROUGE-N
Sekumpulan metrik dalam keluarga ROUGE yang membandingkan N-gram bersama dengan ukuran tertentu dalam teks referensi dan teks yang dihasilkan. Contoh:
- ROUGE-1 mengukur jumlah token bersama dalam teks referensi dan teks yang dihasilkan.
- ROUGE-2 mengukur jumlah bigram (2-gram) yang sama dalam teks referensi dan teks yang dihasilkan.
- ROUGE-3 mengukur jumlah trigram (3-gram) yang sama dalam teks referensi dan teks yang dihasilkan.
Anda dapat menggunakan formula berikut untuk menghitung recall ROUGE-N dan presisi ROUGE-N untuk anggota keluarga ROUGE-N mana pun:
Kemudian, Anda dapat menggunakan F1 untuk menggabungkan perolehan ROUGE-N dan presisi ROUGE-N ke dalam satu metrik:
ROUGE-S
Bentuk ROUGE-N yang toleran yang memungkinkan pencocokan skip-gram. Artinya, ROUGE-N hanya menghitung N-gram yang cocok persis, tetapi ROUGE-S juga menghitung N-gram yang dipisahkan oleh satu atau beberapa kata. Misalnya, perhatikan kode berikut:
- teks referensi: Awan putih
- generated text: Awan putih yang berarak
Saat menghitung ROUGE-N, 2-gram, White clouds tidak cocok dengan White billowing clouds. Namun, saat menghitung ROUGE-S, Awan putih cocok dengan Awan putih berarak.
R-persegi
Metrik regresi yang menunjukkan seberapa besar variasi dalam label disebabkan oleh satu fitur atau sekumpulan fitur. R-kuadrat adalah nilai antara 0 dan 1, yang dapat Anda tafsirkan sebagai berikut:
- R-kuadrat 0 berarti tidak ada variasi label yang disebabkan oleh set fitur.
- R-kuadrat 1 berarti semua variasi label disebabkan oleh set fitur.
- R-kuadrat antara 0 dan 1 menunjukkan sejauh mana variasi label dapat diprediksi dari fitur tertentu atau set fitur. Misalnya, R-kuadrat 0,10 berarti 10 persen varians dalam label disebabkan oleh set fitur, R-kuadrat 0,20 berarti 20 persen disebabkan oleh set fitur, dan seterusnya.
R kuadrat adalah kuadrat dari koefisien korelasi Pearson antara nilai yang diprediksi model dan kebenaran dasar.
RTE
Singkatan dari Recognizing Textual Entailment.
S
penskoran
Bagian dari sistem rekomendasi yang memberikan nilai atau peringkat untuk setiap item yang dihasilkan oleh fase pembuatan kandidat.
ukuran kesamaan
Dalam algoritma pengelompokan, metrik yang digunakan untuk menentukan seberapa mirip dua contoh yang diberikan.
ketersebaran
Jumlah elemen yang disetel ke nol (atau null) dalam vektor atau matriks dibagi dengan jumlah total entri dalam vektor atau matriks tersebut. Misalnya, pertimbangkan matriks 100 elemen yang 98 selnya berisi nol. Penghitungan kepadatan adalah sebagai berikut:
Ketersebaran fitur mengacu pada ketersebaran vektor fitur; ketersebaran model mengacu pada ketersebaran bobot model.
SQuAD
Akronim untuk Stanford Question Answering Dataset, yang diperkenalkan dalam makalah SQuAD: 100.000+ Questions for Machine Comprehension of Text. Pertanyaan dalam set data ini berasal dari orang-orang yang mengajukan pertanyaan tentang artikel Wikipedia. Beberapa pertanyaan di SQuAD memiliki jawaban, tetapi pertanyaan lainnya sengaja tidak memiliki jawaban. Oleh karena itu, Anda dapat menggunakan SQuAD untuk mengevaluasi kemampuan LLM dalam melakukan kedua hal berikut:
- Jawab pertanyaan yang dapat dijawab.
- Identifikasi pertanyaan yang tidak dapat dijawab.
Kecocokan persis yang dikombinasikan dengan F1 adalah metrik paling umum untuk mengevaluasi LLM terhadap SQuAD.
kerugian engsel kuadrat
Kuadrat dari kerugian engsel. Kerugian engsel kuadrat menghukum pencilan lebih berat daripada kerugian engsel reguler.
kerugian kuadrat
Sinonim untuk L2 loss.
SuperGLUE
Kumpulan set data untuk menilai kemampuan LLM secara keseluruhan dalam memahami dan menghasilkan teks. Ensemble terdiri dari set data berikut:
- Pertanyaan Boolean (BoolQ)
- CommitmentBank (CB)
- Choice of Plausible Alternatives (COPA)
- Pemahaman Bacaan Multi-kalimat (MultiRC)
- Dataset Pemahaman Bacaan dengan Penalaran Sehat (ReCoRD)
- Mengenali Implikasi Teks (RTE)
- Kata dalam Konteks (WiC)
- Winograd Schema Challenge (WSC)
Untuk mengetahui detailnya, lihat SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems.
T
kerugian pengujian
Metrik yang merepresentasikan loss model terhadap set pengujian. Saat membuat model, Anda biasanya mencoba meminimalkan kerugian pengujian. Hal ini karena kerugian pengujian yang rendah adalah sinyal kualitas yang lebih kuat daripada kerugian pelatihan yang rendah atau kerugian validasi yang rendah.
Perbedaan besar antara kerugian pengujian dan kerugian pelatihan atau kerugian validasi terkadang menunjukkan bahwa Anda perlu meningkatkan tingkat regularisasi.
akurasi top-k
Persentase kemunculan "label target" dalam k posisi pertama daftar yang dihasilkan. Daftar tersebut dapat berupa rekomendasi yang dipersonalisasi atau daftar item yang diurutkan berdasarkan softmax.
Akurasi top-k juga dikenal sebagai akurasi pada k.
perilaku negatif
Tingkat konten yang kasar, mengancam, atau menyinggung. Banyak model machine learning dapat mengidentifikasi, mengukur, dan mengklasifikasikan toksisitas. Sebagian besar model ini mengidentifikasi toksisitas di sepanjang beberapa parameter, seperti tingkat bahasa tidak sopan dan tingkat bahasa yang mengancam.
kerugian pelatihan
Metrik yang merepresentasikan kerugian model selama iterasi pelatihan tertentu. Misalnya, anggap fungsi kerugiannya adalah Rataan Kuadrat Galat (RKG). Mungkin kerugian pelatihan (Mean Squared Error) untuk iterasi ke-10 adalah 2,2, dan kerugian pelatihan untuk iterasi ke-100 adalah 1,9.
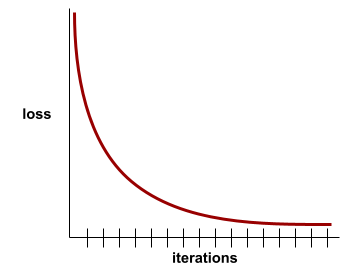
Kurva kerugian memetakan kerugian pelatihan versus jumlah iterasi. Kurva kerugian memberikan petunjuk berikut tentang pelatihan:
- Kemiringan ke bawah menunjukkan bahwa model meningkat.
- Kemiringan ke atas menunjukkan bahwa model semakin buruk.
- Lereng datar menunjukkan bahwa model telah mencapai konvergensi.
Misalnya, kurva kerugian yang agak ideal berikut menunjukkan:
- Lereng menurun yang curam selama iterasi awal, yang menyiratkan peningkatan model yang cepat.
- Lereng yang berangsur-angsur mendatar (tetapi masih menurun) hingga mendekati akhir pelatihan, yang menyiratkan peningkatan model yang berkelanjutan dengan kecepatan yang agak lebih lambat daripada selama iterasi awal.
- Lereng datar di akhir pelatihan, yang menunjukkan konvergensi.
Meskipun kerugian pelatihan penting, lihat juga generalisasi.
Penjawaban Pertanyaan Trivia
Set data untuk mengevaluasi kemampuan LLM dalam menjawab pertanyaan trivia. Setiap set data berisi pasangan pertanyaan-jawaban yang dibuat oleh penggemar trivia. Set data yang berbeda didasarkan pada sumber yang berbeda, termasuk:
- Penelusuran web (TriviaQA)
- Wikipedia (TriviaQA_wiki)
Untuk mengetahui informasi selengkapnya, lihat TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension.
negatif benar (TN)
Contoh yang mana model dengan benar memprediksi kelas negatif. Misalnya, model menyimpulkan bahwa pesan email tertentu bukan spam, dan pesan email tersebut memang bukan spam.
positif benar (TP)
Contoh yang mana model dengan benar memprediksi kelas positif. Misalnya, model menyimpulkan bahwa pesan email tertentu adalah spam, dan pesan email tersebut memang spam.
rasio positif benar (TPR)
Sinonim untuk perolehan. Definisinya yaitu:
Rasio positif benar adalah sumbu y dalam kurva ROC.
Typologically Diverse Question Answering (TyDi QA)
Set data besar untuk mengevaluasi kemahiran LLM dalam menjawab pertanyaan. Set data berisi pasangan pertanyaan dan jawaban dalam banyak bahasa.
Untuk mengetahui detailnya, lihat TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages.
U
rasio klaim tidak didukung (UCR)
Persentase klaim dalam respons yang tidak beralasan. Misalnya, jika respons LLM membuat 10 klaim, tetapi hanya 1 yang memiliki rujukan, UCR-nya adalah 90%.
UCR yang tinggi menunjukkan bahwa LLM terlalu sering berhalusinasi (hallucinating).
Lihat juga presisi kutipan dan perolehan kutipan.
V
kerugian validasi
Metrik yang merepresentasikan kerugian model pada set validasi selama iterasi pelatihan tertentu.
Lihat juga kurva generalisasi.
kepentingan variabel
Kumpulan skor yang menunjukkan nilai penting relatif dari setiap fitur terhadap model.
Misalnya, pertimbangkan pohon keputusan yang memperkirakan harga rumah. Misalkan pohon keputusan ini menggunakan tiga fitur: ukuran, usia, dan gaya. Jika sekumpulan kepentingan variabel untuk ketiga fitur dihitung menjadi {size=5,8, age=2,5, style=4,7}, maka ukuran lebih penting bagi pohon keputusan daripada usia atau gaya.
Ada berbagai metrik kepentingan variabel yang dapat memberi tahu pakar ML tentang berbagai aspek model.
W
Kerugian Wasserstein
Salah satu fungsi kerugian yang umum digunakan dalam jaringan adversarial generatif, berdasarkan jarak penggerak bumi antara distribusi data yang dihasilkan dan data nyata.
WiC
Singkatan untuk Kata dalam Konteks.
WikiLingua (wiki_lingua)
Set data untuk mengevaluasi kemampuan LLM dalam meringkas artikel pendek. WikiHow, ensiklopedia artikel yang menjelaskan cara melakukan berbagai tugas, adalah sumber yang ditulis manusia untuk artikel dan ringkasannya. Setiap entri dalam set data terdiri dari:
- Artikel, yang dibuat dengan menambahkan setiap langkah versi prosa (paragraf) dari daftar bernomor, minus kalimat pembuka setiap langkah.
- Ringkasan artikel tersebut, yang terdiri dari kalimat pembuka setiap langkah dalam daftar bernomor.
Untuk mengetahui detailnya, lihat WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization.
Tantangan Skema Winograd (WSC)
Format (atau set data yang sesuai dengan format tersebut) untuk mengevaluasi kemampuan LLM dalam menentukan frasa nomina yang dirujuk oleh pronomina.
Setiap entri dalam Winograd Schema Challenge terdiri dari:
- Bagian singkat, yang berisi kata ganti target
- Kata ganti target
- Frasa nomina kandidat, diikuti dengan jawaban yang benar (Boolean). Jika kata ganti target merujuk pada kandidat ini, jawabannya adalah Benar. Jika kata ganti target tidak merujuk pada kandidat ini, jawabannya adalah Salah (False).
Contoh:
- Bagian: Mark berbohong kepada Pete tentang dirinya sendiri, yang kemudian dimasukkan Pete dalam bukunya. Dia seharusnya lebih jujur.
- Kata ganti target: Dia (laki-laki)
- Frasa nomina kandidat:
- Mark: Benar, karena kata ganti target merujuk pada Mark
- Pete: Salah (False), karena kata ganti target tidak merujuk pada Peter
Winograd Schema Challenge adalah komponen ansambel SuperGLUE.
Kata dalam Konteks (WiC)
Kumpulan data untuk mengevaluasi seberapa baik LLM menggunakan konteks untuk memahami kata-kata yang memiliki banyak arti. Setiap entri dalam set data berisi:
- Dua kalimat, yang masing-masing berisi kata target
- Kata target
- Jawaban yang benar (Boolean), dengan:
- True berarti kata target memiliki arti yang sama dalam kedua kalimat
- Salah berarti kata target memiliki arti yang berbeda dalam kedua kalimat
Contoh:
- Dua kalimat:
- Ada banyak sampah di dasar sungai.
- Saya menyimpan segelas air di samping tempat tidur saat tidur.
- Kata target: tempat tidur
- Jawaban yang benar: Salah, karena kata target memiliki arti yang berbeda dalam kedua kalimat tersebut.
Untuk mengetahui detailnya, lihat WiC: the Word-in-Context Dataset for Evaluating Context-Sensitive Meaning Representations.
Words in Context adalah komponen ansambel SuperGLUE.
WSC
Singkatan dari Winograd Schema Challenge.
X
XL-Sum (xlsum)
Set data untuk mengevaluasi kemampuan LLM dalam meringkas teks. XL-Sum menyediakan entri dalam banyak bahasa. Setiap entri dalam set data berisi:
- Sebuah artikel, yang diambil dari British Broadcasting Company (BBC).
- Ringkasan artikel, yang ditulis oleh penulis artikel. Perhatikan bahwa ringkasan tersebut dapat berisi kata atau frasa yang tidak ada dalam artikel.
Untuk mengetahui detailnya, lihat XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages.