В предыдущем уроке (Введение) мы увидели, как спутниковые вложения фиксируют годовые траектории спутниковых наблюдений и климатические переменные. Это делает набор данных пригодным для картирования сельскохозяйственных культур без необходимости моделирования фенологии. Картирование типов сельскохозяйственных культур — сложная задача, которая обычно требует моделирования фенологии и сбора полевых образцов для всех сельскохозяйственных культур, выращиваемых в регионе.
В этом руководстве мы применим метод неконтролируемой классификации для картирования посевов, который позволяет нам выполнять эту сложную задачу, не полагаясь на метки полей. Этот метод использует местные знания о регионе, а также агрегированную статистику по посевам, которая легко доступна для многих регионов мира.
Выберите регион
В этом уроке мы создадим карту типов сельскохозяйственных культур для округа Серро-Гордо, штат Айова. Этот округ находится в кукурузном поясе США, где выращивают две основные культуры: кукурузу и сою. Эти местные знания важны и помогут нам определить ключевые параметры нашей модели.
Начнем с определения границы выбранного округа.
// Select the region
// Cerro Gordo County, Iowa
var counties = ee.FeatureCollection('TIGER/2018/Counties');
var selected = counties
.filter(ee.Filter.eq('GEOID', '19033'));
var geometry = selected.geometry();
Map.centerObject(geometry, 12);
Map.addLayer(geometry, {color: 'red'}, 'Selected Region', false);

Рисунок: Выбранный регион
Подготовьте набор данных для встраивания спутников
Затем мы загружаем набор данных Satellite Embedding, фильтруем изображения за выбранный год и создаем мозаику.
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
var year = 2022;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredembeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
var embeddingsImage = filteredembeddings.mosaic();
Создайте маску пахотных земель
Для нашего моделирования нам необходимо исключить несельскохозяйственные территории. Существует множество глобальных и региональных наборов данных, которые можно использовать для создания маски посевов. ESA WorldCover или GFSAD Global Cropland Extent Product являются хорошими вариантами для глобальных наборов данных о посевах. Более поздним дополнением стал продукт ESA WorldCereal Active Cropland , который содержит сезонные карты активных посевов. Поскольку наш регион находится в США, для получения маски посевов мы можем использовать более точный региональный набор данных USDA NASS Cropland Data Layers (CDL).
// Use Cropland Data Layers (CDL) to obtain cultivated cropland
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var croplandMask = cdl.select('cultivated').eq(2).rename('cropmask');
// Visualize the crop mask
var croplandMaskVis = {min: 0, max: 1, palette: ['white', 'green']};
Map.addLayer(croplandMask.clip(geometry), croplandMaskVis, 'Crop Mask');
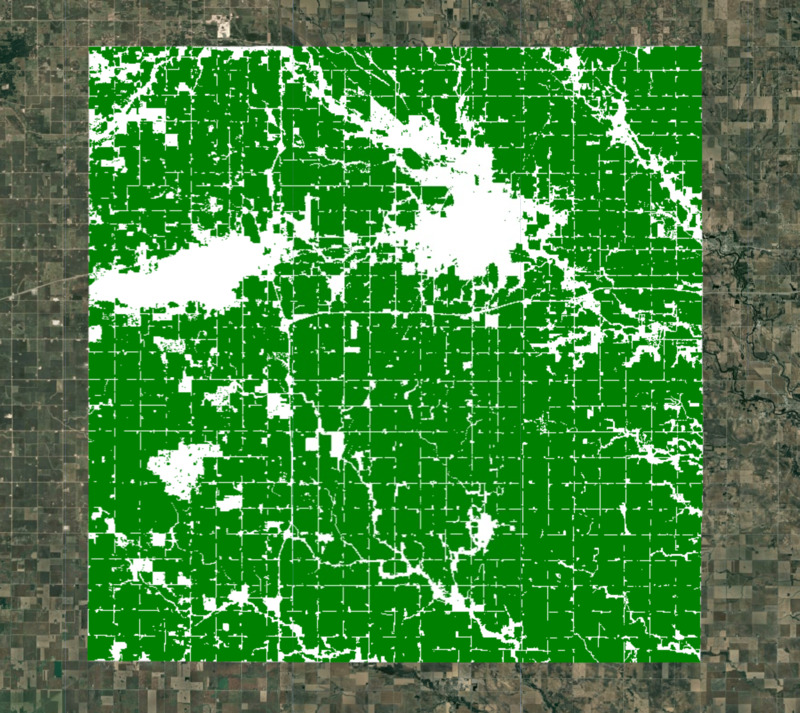
Рисунок: Выбранный регион с маской пахотных земель
Извлечение обучающих образцов
Применяем маску пахотных земель к встраиваемой мозаике. Теперь у нас есть все пиксели, представляющие возделываемые пахотные земли в округе.
// Mask all non-cropland pixels
var clusterImage = embeddingsImage.updateMask(croplandMask);
Нам необходимо взять спутниковое изображение и получить случайные выборки для обучения модели кластеризации. Поскольку интересующая нас область содержит много замаскированных пикселей, простая случайная выборка может привести к выборкам с нулевыми значениями. Чтобы обеспечить извлечение необходимого количества ненулевых выборок, мы используем стратифицированную выборку для получения необходимого количества выборок в немаскированных областях.
// Stratified random sampling
var training = clusterImage.addBands(croplandMask).stratifiedSample({
numPoints: 1000,
classBand: 'cropmask',
region: geometry,
scale: 10,
tileScale: 16,
seed: 100,
dropNulls: true,
geometries: true
});
Экспортировать образец в актив (необязательно)
Извлечение выборок — это ресурсоёмкая операция, поэтому рекомендуется экспортировать извлечённые обучающие выборки в виде ресурсов и использовать их на последующих этапах. Это поможет избежать ошибок, связанных с превышением времени ожидания вычислений или нехваткой пользовательской памяти при работе с большими регионами.
Запустите задачу экспорта и дождитесь ее завершения, прежде чем продолжить.
// Replace this with your asset folder
// The folder must exist before exporting
var exportFolder = 'projects/spatialthoughts/assets/satellite_embedding/';
var samplesExportFc = 'cluster_training_samples';
var samplesExportFcPath = exportFolder + samplesExportFc;
Export.table.toAsset({
collection: training,
description: 'Cluster_Training_Samples',
assetId: samplesExportFcPath
});
После завершения задачи экспорта мы можем прочитать извлеченные образцы обратно в наш код в качестве коллекции признаков.
// Use the exported asset
var training = ee.FeatureCollection(samplesExportFcPath);
Визуализируйте образцы
Независимо от того, запускали ли вы выборку интерактивно или экспортировали её в коллекцию признаков, теперь у вас есть обучающая переменная с точками выборки. Давайте распечатаем первую выборку, чтобы проверить её и добавить обучающие точки на Map .
print('Extracted sample', training.first());
Map.addLayer(training, {color: 'blue'}, 'Extracted Samples', false);

Рисунок: Извлеченные случайные выборки для кластеризации
Выполнить неконтролируемую кластеризацию
Теперь мы можем обучить кластеризатор и сгруппировать 64D векторы эмбеддинга в выбранное количество отдельных кластеров. Исходя из наших локальных знаний, большую часть площади занимают два основных типа сельскохозяйственных культур, а оставшуюся часть занимают несколько других. Мы можем выполнить неконтролируемую кластеризацию на основе спутникового эмбеддинга, чтобы получить кластеры пикселей со схожими временными траекториями и паттернами. Пиксели со схожими спектральными и пространственными характеристиками, а также схожей фенологией будут сгруппированы в один кластер.
Функция ee.Clusterer.wekaCascadeKMeans() позволяет нам задать минимальное и максимальное количество кластеров и найти оптимальное на основе обучающих данных. Здесь наши знания локальной среды пригодятся для определения минимального и максимального количества кластеров. Поскольку мы ожидаем несколько различных типов кластеров — кукуруза, соя и несколько других культур, — мы можем использовать 4 в качестве минимального количества кластеров и 5 в качестве максимального. Возможно, вам придётся поэкспериментировать с этими значениями, чтобы определить, что лучше всего подходит для вашего региона.
// Cluster the Satellite Embedding Image
var minClusters = 4;
var maxClusters = 5;
var clusterer = ee.Clusterer.wekaCascadeKMeans({
minClusters: minClusters, maxClusters: maxClusters}).train({
features: training,
inputProperties: clusterImage.bandNames()
});
var clustered = clusterImage.cluster(clusterer);
Map.addLayer(clustered.randomVisualizer().clip(geometry), {}, 'Clusters');
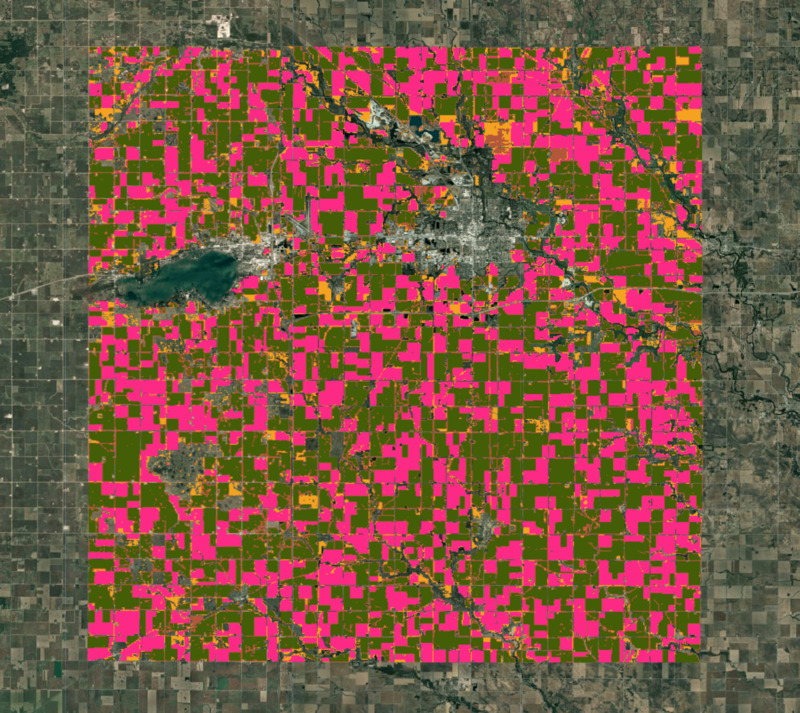
Рисунок: Кластеры, полученные в результате неконтролируемой классификации
Назначить метки кластерам
При визуальном осмотре кластеры, полученные на предыдущих этапах, хорошо совпадают с границами ферм, показанными на изображении высокого разрешения. Исходя из местных данных, мы знаем, что два крупнейших кластера — это кукуруза и соя. Давайте вычислим площади каждого кластера на нашем изображении.
// Calculate Cluster Areas
// 1 Acre = 4046.86 Sq. Meters
var areaImage = ee.Image.pixelArea().divide(4046.86).addBands(clustered);
var areas = areaImage.reduceRegion({
reducer: ee.Reducer.sum().group({
groupField: 1,
groupName: 'cluster',
}),
geometry: geometry,
scale: 10,
maxPixels: 1e10
});
var clusterAreas = ee.List(areas.get('groups'));
// Process results to extract the areas and create a FeatureCollection
var clusterAreas = clusterAreas.map(function(item) {
var areaDict = ee.Dictionary(item);
var clusterNumber = areaDict.getNumber('cluster').format();
var area = areaDict.getNumber('sum');
return ee.Feature(null, {cluster: clusterNumber, area: area});
});
var clusterAreaFc = ee.FeatureCollection(clusterAreas);
print('Cluster Areas', clusterAreaFc);
Мы выбираем 2 кластера с наибольшей площадью.
var selectedFc = clusterAreaFc.sort('area', false).limit(2);
print('Top 2 Clusters by Area', selectedFc);
Но мы до сих пор не знаем, какой кластер соответствует какой культуре. Если у вас есть несколько полевых образцов кукурузы или сои, вы можете наложить их на кластеры, чтобы определить их соответствующие метки. При отсутствии полевых образцов мы можем использовать совокупную статистику по урожаю. Во многих частях мира совокупная статистика по урожаю собирается и публикуется регулярно. В США Национальная служба сельскохозяйственной статистики (NASS) располагает подробной статистикой по урожаю для каждого округа и каждой основной культуры. В 2022 году в округе Серро-Гордо, штат Айова, посевная площадь кукурузы составила 161 500 акров, а сои — 110 500 акров.
Используя эту информацию, мы теперь знаем, что среди двух верхних кластеров наибольший, скорее всего, будет занимать кукуруза, а второй — соя. Давайте присвоим этим кластерам метки и сравним вычисленные площади с опубликованной статистикой.
var cornFeature = selectedFc.sort('area', false).first();
var soybeanFeature = selectedFc.sort('area').first();
var cornCluster = cornFeature.get('cluster');
var soybeanCluster = soybeanFeature.get('cluster');
print('Corn Area (Detected)', cornFeature.getNumber('area').round());
print('Corn Area (From Crop Statistics)', 163500);
print('Soybean Area (Detected)', soybeanFeature.getNumber('area').round());
print('Soybean Area (From Crop Statistics)', 110500);
Создайте карту посевов
Теперь мы знаем метки для каждого кластера и можем извлечь пиксели для каждого типа урожая и объединить их для создания окончательной карты урожая.
// Select the clusters to create the crop map
var corn = clustered.eq(ee.Number.parse(cornCluster));
var soybean = clustered.eq(ee.Number.parse(soybeanCluster));
var merged = corn.add(soybean.multiply(2));
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(merged.clip(geometry), cropVis, 'Crop Map (Detected)');
Чтобы облегчить интерпретацию результатов, мы также можем использовать элементы пользовательского интерфейса для создания и добавления легенды на карту.
// Add a Legend
var legend = ui.Panel({
layout: ui.Panel.Layout.Flow('horizontal'),
style: {position: 'bottom-center', padding: '8px 15px'}});
var addItem = function(color, name) {
var colorBox = ui.Label({
style: {color: '#ffffff',
backgroundColor: color,
padding: '10px',
margin: '0 4px 4px 0',
}
});
var description = ui.Label({
value: name,
style: {
margin: '0px 10px 0px 2px',
}
});
return ui.Panel({
widgets: [colorBox, description],
layout: ui.Panel.Layout.Flow('horizontal')
});
};
var title = ui.Label({
value: 'Legend',
style: {
fontWeight: 'bold',
fontSize: '16px',
margin: '0px 10px 0px 4px'
}
});
legend.add(title);
legend.add(addItem('#ffd400', 'Corn'));
legend.add(addItem('#267300', 'Soybean'));
legend.add(addItem('#bdbdbd', 'Other Crops'));
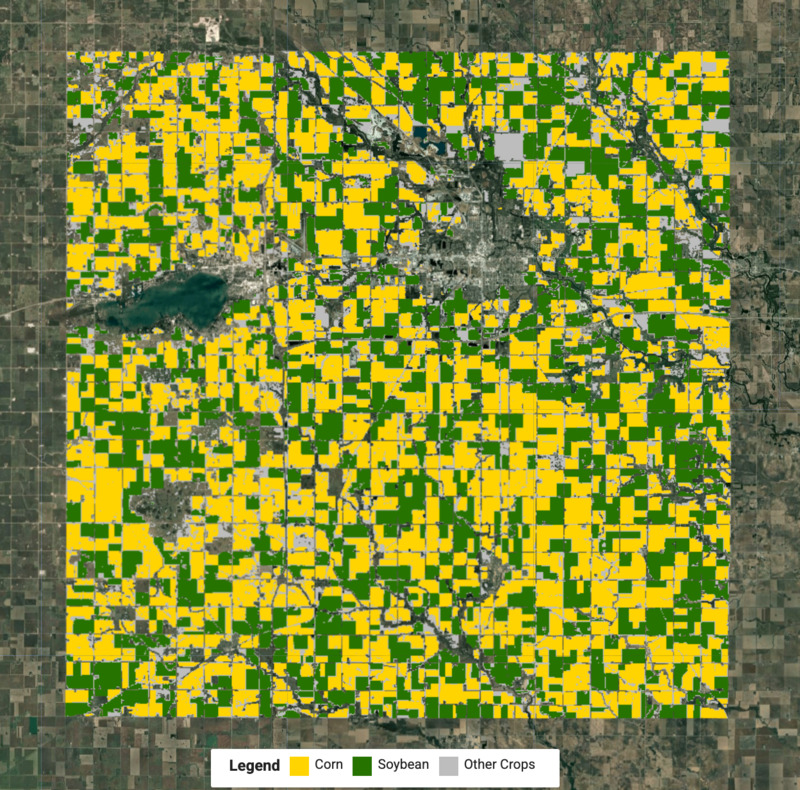
Рисунок: Карта посевов кукурузы и сои
Подтвердите результаты
Нам удалось получить карту типов сельскохозяйственных культур с помощью набора данных Satellite Embedding без каких-либо меток полей, используя только агрегированную статистику и локальные знания региона. Давайте сравним наши результаты с официальной картой типов сельскохозяйственных культур из слоёв данных по сельскохозяйственным угодьям (CDL) Министерства сельского хозяйства США (USDA NASS).
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var cropMap = cropLandcover.updateMask(croplandMask).rename('crops');
// Original data has unique values for each crop ranging from 0 to 254
var cropClasses = ee.List.sequence(0, 254);
// We remap all values as following
// Crop | Source Value | Target Value
// Corn | 1 | 1
// Soybean | 5 | 2
// All other| 0-255 | 0
var targetClasses = ee.List.repeat(0, 255).set(1, 1).set(5, 2);
var cropMapReclass = cropMap.remap(cropClasses, targetClasses).rename('crops');
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(cropMapReclass.clip(geometry), cropVis, 'Crop Landcover (CDL)');

Рисунок: (слева) карта посевов, полученная с помощью спутниковых изображений (справа) карта посевов из CDL
Несмотря на расхождения между нашими результатами и официальной картой, вы заметите, что нам удалось получить довольно хорошие результаты с минимальными усилиями. Применяя к результатам постобработку , мы можем удалить некоторые шумы и заполнить пробелы в выходных данных.
Попробуйте полный сценарий для этого урока в редакторе кода Earth Engine .