Page Summary
-
This tutorial demonstrates Species Distribution Modeling (SDM) using Google Earth Engine (GEE), focusing on predicting and analyzing the habitat of the endangered Fairy pitta.
-
SDM requires species occurrence records and environmental variables, and implementing it in GEE provides access to large-scale environmental data and powerful computing.
-
The workflow for SDM in GEE includes collecting and preprocessing species data, defining the area of interest, adding environmental variables, generating pseudo-absence data, and performing model fitting and prediction.
-
Multicollinearity among environmental variables is addressed using the Variance Inflation Factor (VIF) to select the most relevant predictors for the model.
-
The tutorial utilizes the Random Forest algorithm and incorporates spatial block cross-validation to enhance the model's stability and reliability, evaluating accuracy using AUC-ROC and AUC-PR metrics.
 View source on GitHub
View source on GitHub
In this tutorial, the methodology of Species Distribution Modeling using Google Earth Engine will be introduced. A brief overview of Species Distribution Modeling will be provided, followed by the process of predicting and analyzing the habitat of an endangered bird species known as the Fairy pitta (scientific name: Pitta nympha).
Run me first
Run the following cell to initialize the API. The output will contain instructions on how to grant this notebook access to Earth Engine using your account.
import ee
# Trigger the authentication flow.
ee.Authenticate()
# Initialize the library.
ee.Initialize(project='my-project')
A brief overview of Species Distribution Modeling
Let's explore what species distribution models are, the advantages of using Google Earth Engine for their processing, the required data for the models, and how the workflow is structured.
What is Species Distribution Modeling?
Species Distribution Modeling (SDM below) is the most common methodology used to estimate the actual or potential geographic distribution of a species. It involves characterizing the environmental conditions suitable for a particular species and then identifying where these suitable conditions are distributed geographically.
SDM has emerged as a crucial component of conservation planning in recent years, and various modeling techniques have been developed for this purpose. Implementing SDM in Google Earth Engine (GEE below) provides easy access to large-scale environmental data, along with powerful computing capabilities and support for machine learning algorithms, allowing for rapid modeling.
Data Required for SDM
SDM typically utilizes the relationship between known species occurrence records and environmental variables to identify the conditions under which a population can sustain. In other words, two types of model input data are required:
- Occurrence records of known species
- Various environmental variables
These data are input into algorithms to identify environmental conditions associated with the presence of species.
Workflow of SDM using GEE
The workflow for SDM using GEE is as follows:
- Collection and preprocessing of species occurrence data
- Definition of the Area of Interest
- Addition of GEE environmental variables
- Generation of pseudo-absence data
- Model fitting and prediction
- Variable importance and accuracy assessment
Habitat Prediction and Analysis Using GEE
The Fairy pitta (Pitta nympha) will be used as a case study to demonstrate the application of GEE-based SDM. While this specific species has been selected for one example, researchers can apply the methodology to any target species of interest with slight modifications to the provided source code.
The Fairy pitta is a rare summer migrant and passage migrant in South Korea, whose distribution area is expanding due to recent climate warming on the Korean Peninsula. It is classified as a rare species, endangered wildlife of class II, Natural Monument No. 204, evaluated as Regionally Extinct (RE) in the National Red List, and Vulnerable (VU) according to the IUCN categories.
Conducting SDM for the conservation planning of the Fairy pitta appears to be quite valuable. Now, let's proceed with habitat prediction and analysis through GEE.
First, the Python libraries are imported.The import statement brings in the entire contents of a module, while the from import statement allows for the importation of specific objects from a module.
# Import libraries
import geemap
import geemap.colormaps as cm
import pandas as pd, geopandas as gpd
import numpy as np, matplotlib.pyplot as plt
import os, requests, math, random
from ipyleaflet import TileLayer
from statsmodels.stats.outliers_influence import variance_inflation_factor
Collection and Preprocessing of Species Occurrence Data
Now, let's collect occurrence data for the Fairy pitta. Even if you don't currently have access to occurrence data for the species of interest, you can obtain observational data about specific species through the GBIF API. The GBIF API is an interface that allows access to the species distribution data provided by GBIF, enabling users to search, filter, and download data, as well as acquire various information related to species.
In the code below, the species_name variable is assigned the scientific name of the species (e.g., Pitta nympha for Fairy pitta), and the country_code variable is assigned the country code (e.g., KR for South Korea). The base_url variable stores the address of the GBIF API. params is a dictionary containing parameters to be used in the API request:
scientificName: Sets the scientific name of the species to be searched.country: Limits the search to a specific country.hasCoordinate: Ensures only data with coordinates (true) are searched.basisOfRecord: Chooses only records of human observation (HUMAN_OBSERVATION).limit: Sets the maximum number of results returned to 10000.
def get_gbif_species_data(species_name, country_code):
"""
Retrieves observational data for a specific species using the GBIF API and returns it as a pandas DataFrame.
Parameters:
species_name (str): The scientific name of the species to query.
country_code (str): The country code of the where the observation data will be queried.
Returns:
pd.DataFrame: A pandas DataFrame containing the observational data.
"""
base_url = "https://api.gbif.org/v1/occurrence/search"
params = {
"scientificName": species_name,
"country": country_code,
"hasCoordinate": "true",
"basisOfRecord": "HUMAN_OBSERVATION",
"limit": 10000,
}
try:
response = requests.get(base_url, params=params)
response.raise_for_status() # Raises an exception for a response error.
data = response.json()
occurrences = data.get("results", [])
if occurrences: # If data is present
df = pd.json_normalize(occurrences)
return df
else:
print("No data found for the given species and country code.")
return pd.DataFrame() # Returns an empty DataFrame
except requests.RequestException as e:
print(f"Request failed: {e}")
return pd.DataFrame() # Returns an empty DataFrame in case of an exception
Using the parameters set previously, we query the GBIF API for observational records of the Fairy pitta (Pitta nympha), and load the results into a DataFrame to check the first row. A DataFrame is a data structure for handling table-formatted data, consisting of rows and columns. If necessary, the DataFrame can be saved as a CSV file and read back in.
# Retrieve Fairy Pitta data
df = get_gbif_species_data("Pitta nympha", "KR")
"""
# Save DataFrame to CSV and read back in.
df.to_csv("pitta_nympha_data.csv", index=False)
df = pd.read_csv("pitta_nympha_data.csv")
"""
df.head(1) # Display the first row of the DataFrame
Next, we convert the DataFrame into a GeoDataFrame that includes a column for geographic information (geometry) and check the first row. A GeoDataFrame can be saved as a GeoPackage file (*.gpkg) and read back in.
# Convert DataFrame to GeoDataFrame
gdf = gpd.GeoDataFrame(
df,
geometry=gpd.points_from_xy(df.decimalLongitude,
df.decimalLatitude),
crs="EPSG:4326"
)[["species", "year", "month", "geometry"]]
"""
# Convert GeoDataFrame to GeoPackage (requires pycrs module)
%pip install -U -q pycrs
gdf.to_file("pitta_nympha_data.gpkg", driver="GPKG")
gdf = gpd.read_file("pitta_nympha_data.gpkg")
"""
gdf.head(1) # Display the first row of the GeoDataFrame
This time, we have created a function to visualize the distribution of data by year and month from the GeoDataFrame and display it as a graph, which can then be saved as an image file. The use of a heatmap allows us to quickly grasp the frequency of species occurrence by year and month, providing an intuitive visualization of the temporal changes and patterns within the data. This allows for the identification of temporal patterns and seasonal variations in species occurrence data, as well as the rapid detection of outliers or quality issues within the data.
# Yearly and monthly data distribution heatmap
def plot_heatmap(gdf, h_size=8):
statistics = gdf.groupby(["month", "year"]).size().unstack(fill_value=0)
# Heatmap
plt.figure(figsize=(h_size, h_size - 6))
heatmap = plt.imshow(
statistics.values, cmap="YlOrBr", origin="upper", aspect="auto"
)
# Display values above each pixel
for i in range(len(statistics.index)):
for j in range(len(statistics.columns)):
plt.text(
j, i, statistics.values[i, j], ha="center", va="center", color="black"
)
plt.colorbar(heatmap, label="Count")
plt.title("Monthly Species Count by Year")
plt.xlabel("Year")
plt.ylabel("Month")
plt.xticks(range(len(statistics.columns)), statistics.columns)
plt.yticks(range(len(statistics.index)), statistics.index)
plt.tight_layout()
plt.savefig("heatmap_plot.png")
plt.show()
plot_heatmap(gdf)
The data from 1995 is very sparse, with significant gaps compared to other years, and the months of August and September also have limited samples and exhibit different seasonal characteristics compared to other periods. Excluding this data could contribute to improving the stability and predictive power of the model.
However, it's important to note that excluding data may enhance the model's generalization ability, but it could also lead to the loss of valuable information relevant to the research objectives. Therefore, such decisions should be made with careful consideration.
# Filtering data by year and month
filtered_gdf = gdf[
(~gdf['year'].eq(1995)) &
(~gdf['month'].between(8, 9))
]
Now, the filtered GeoDataFrame is converted into a Google Earth Engine object.
# Convert GeoDataFrame to Earth Engine object
data_raw = geemap.geopandas_to_ee(filtered_gdf)
Next, we will define the raster pixel size of the SDM results as 1km resolution.
# Spatial resolution setting (meters)
grain_size = 1000
When multiple occurrence points are present within the same 1km resolution raster pixel, there is a high likelihood that they share the same environmental conditions at the same geographic location. Using such data directly in the analysis can introduce bias into the results.
In other words, we need to limit the potential impact of geographic sampling bias. To achieve this, we will retain only one location within each 1km pixel and remove all others, allowing the model to more objectively reflect the environmental conditions.
def remove_duplicates(data, grain_size):
# Select one occurrence record per pixel at the chosen spatial resolution
random_raster = ee.Image.random().reproject("EPSG:4326", None, grain_size)
rand_point_vals = random_raster.sampleRegions(
collection=ee.FeatureCollection(data), geometries=True
)
return rand_point_vals.distinct("random")
data = remove_duplicates(data_raw, grain_size)
# Before selection and after selection
print("Original data size:", data_raw.size().getInfo())
print("Final data size:", data.size().getInfo())
The visualization comparing geographic sampling bias before preprocessing (in blue) and after preprocessing (in red) is shown below. To facilitate comparison, the map has been centered on the area with a high concentration of Fairy pitta occurrence coordinates in Hallasan National Park.
# Visualization of geographic sampling bias before (blue) and after (red) preprocessing
Map = geemap.Map(layout={"height": "400px", "width": "800px"})
# Add the random raster layer
random_raster = ee.Image.random().reproject("EPSG:4326", None, grain_size)
Map.addLayer(
random_raster,
{"min": 0, "max": 1, "palette": ["black", "white"], "opacity": 0.5},
"Random Raster",
)
# Add the original data layer in blue
Map.addLayer(data_raw, {"color": "blue"}, "Original data")
# Add the final data layer in red
Map.addLayer(data, {"color": "red"}, "Final data")
# Set the center of the map to the coordinates
Map.setCenter(126.712, 33.516, 14)
Map
Definition of the Area of Interest
Defining the Area of Interest (AOI below) refers to the term used by researchers to denote the geographical area they want to analyze. It has a similar meaning to the term Study Area.
In this context, we obtained the bounding box of the occurrence point layer geometry and created a 50-kilometer buffer around it (with a maximum tolerance of 1,000 meters) to define the AOI.
# Define the AOI
aoi = data.geometry().bounds().buffer(distance=50000, maxError=1000)
# Add the AOI to the map
outline = ee.Image().byte().paint(
featureCollection=aoi, color=1, width=3)
Map.remove_layer("Random Raster")
Map.addLayer(outline, {'palette': 'FF0000'}, "AOI")
Map.centerObject(aoi, 6)
Map
Addition of GEE environmental variables
Now, let's add environmental variables to the analysis. GEE provides a wide range of datasets for environmental variables such as temperature, precipitation, elevation, land cover, and terrain. These datasets enable us to comprehensively analyze various factors that may influence the habitat preferences of the Fairy pitta.
The selection of GEE environmental variables in SDM should reflect the habitat preference characteristics of the species. To do this, prior research and literature review on the Fairy pitta's habitat preferences should be conducted. This tutorial primarily focuses on the workflow of SDM using GEE, so some in-depth details are omitted.
WorldClim V1 Bioclim: This dataset provides 19 bioclimatic variables derived from monthly temperature and precipitation data. It covers the period from 1960 to 1991 and has a resolution of 927.67 meters.
# WorldClim V1 Bioclim
bio = ee.Image("WORLDCLIM/V1/BIO")
NASA SRTM Digital Elevation 30m: This dataset contains digital elevation data from the Shuttle Radar Topography Mission (SRTM). The data was primarily collected around the year 2000 and is provided at a resolution of approximately 30 meters (1 arc-second). The following code calculates elevation, slope, aspect, and hillshade layers from the SRTM data.
# NASA SRTM Digital Elevation 30m
terrain = ee.Algorithms.Terrain(ee.Image("USGS/SRTMGL1_003"))
Global Forest Cover Change (GFCC) Tree Cover Multi-Year Global 30m: The Vegetation Continuous Fields (VCF) dataset from Landsat estimates the proportion of vertically projected vegetation cover when the vegetation height is greater than 5 meters. This dataset is provided for four time periods centered around the years 2000, 2005, 2010, and 2015, with a resolution of 30 meters. Here, the median values from these four time periods are used.
# Global Forest Cover Change (GFCC) Tree Cover Multi-Year Global 30m
tcc = ee.ImageCollection("NASA/MEASURES/GFCC/TC/v3")
median_tcc = (
tcc.filterDate("2000-01-01", "2015-12-31")
.select(["tree_canopy_cover"], ["TCC"])
.median()
)
bio (Bioclimatic variables), terrain (topography), and median_tcc (tree canopy cover) are combined into a single multiband image. The elevation band is selected from terrain, and a watermask is created for locations where elevation is greater than 0. This masks regions below sea level (e.g. the ocean) and prepares the researcher to analyze various environmental factors for the AOI comprehensively.
# Combine bands into a multi-band image
predictors = bio.addBands(terrain).addBands(median_tcc)
# Create a water mask
watermask = terrain.select('elevation').gt(0)
# Mask out ocean pixels and clip to the area of interest
predictors = predictors.updateMask(watermask).clip(aoi)
When highly correlated predictor variables are included together in a model, multicollinearity issues can arise. Multicollinearity is a phenomenon that occurs when there are strong linear relationships among independent variables in a model, leading to instability in the estimation of the model's coefficients (weights). This instability can reduce the model's reliability and make predictions or interpretations for new data challenging. Therefore, we will consider multicollinearity and proceed with the process of selecting predictor variables.
First, we will generate 5,000 random points and then extract the predictor variable values of the single multiband image at those points.
# Generate 5,000 random points
data_cor = predictors.sample(scale=grain_size, numPixels=5000, geometries=True)
# Extract predictor variable values
pvals = predictors.sampleRegions(collection=data_cor, scale=grain_size)
We will convert the extracted predictor values for each point into a DataFrame and then check the first row.
# Converting predictor values from Earth Engine to a DataFrame
pvals_df = geemap.ee_to_df(pvals)
pvals_df.head(1)
# Displaying the columns
columns = pvals_df.columns
print(columns)
Calculating Spearman correlation coefficients between the given predictor variables and visualizing them in a heatmap.
def plot_correlation_heatmap(dataframe, h_size=10, show_labels=False):
# Calculate Spearman correlation coefficients
correlation_matrix = dataframe.corr(method="spearman")
# Create a heatmap
plt.figure(figsize=(h_size, h_size-2))
plt.imshow(correlation_matrix, cmap='coolwarm', interpolation='nearest')
# Optionally display values on the heatmap
if show_labels:
for i in range(correlation_matrix.shape[0]):
for j in range(correlation_matrix.shape[1]):
plt.text(j, i, f"{correlation_matrix.iloc[i, j]:.2f}",
ha='center', va='center', color='white', fontsize=8)
columns = dataframe.columns.tolist()
plt.xticks(range(len(columns)), columns, rotation=90)
plt.yticks(range(len(columns)), columns)
plt.title("Variables Correlation Matrix")
plt.colorbar(label="Spearman Correlation")
plt.savefig('correlation_heatmap_plot.png')
plt.show()
# Plot the correlation heatmap of variables
plot_correlation_heatmap(pvals_df)
Spearman correlation coefficient is useful for understanding the general associations among predictor variables but does not directly assess how multiple variables interact, specifically detecting multicollinearity.
The Variance Inflation Factor (VIF below) is a statistical metric used to evaluate multicollinearity and guide variable selection. It indicates the degree of linear relationship of each independent variable with the other independent variables, and high VIF values can be evidence of multicollinearity.
Typically, when VIF values exceed 5 or 10, it suggests that the variable has a strong correlation with other variables, potentially compromising the stability and interpretability of the model. In this tutorial, a criterion of VIF values less than 10 was used for variable selection. The following 6 variables were selected based on VIF.
# Filter variables based on Variance Inflation Factor (VIF)
def filter_variables_by_vif(dataframe, threshold=10):
original_columns = dataframe.columns.tolist()
remaining_columns = original_columns[:]
while True:
vif_data = dataframe[remaining_columns]
vif_values = [
variance_inflation_factor(vif_data.values, i)
for i in range(vif_data.shape[1])
]
max_vif_index = vif_values.index(max(vif_values))
max_vif = max(vif_values)
if max_vif < threshold:
break
print(f"Removing '{remaining_columns[max_vif_index]}' with VIF {max_vif:.2f}")
del remaining_columns[max_vif_index]
filtered_data = dataframe[remaining_columns]
bands = filtered_data.columns.tolist()
print("Bands:", bands)
return filtered_data, bands
filtered_pvals_df, bands = filter_variables_by_vif(pvals_df)
# Variable Selection Based on VIF
predictors = predictors.select(bands)
# Plot the correlation heatmap of variables
plot_correlation_heatmap(filtered_pvals_df, h_size=6, show_labels=True)
Next, let's visualize the 6 selected predictor variables on the map.
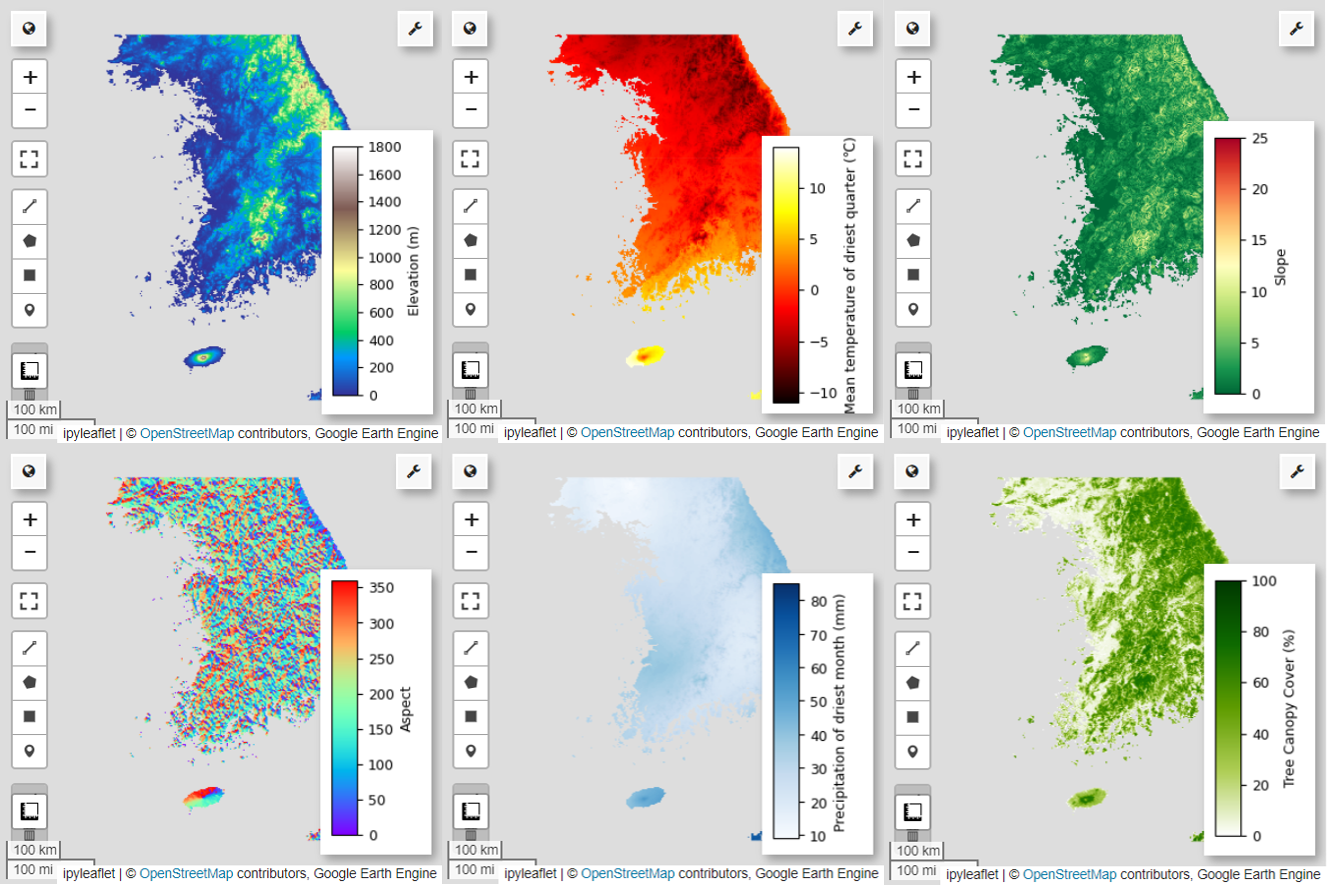
You can explore the available palettes for map visualization using the following code. For example, the terrain palette looks like this.
cm.plot_colormaps(width=8.0, height=0.2)
cm.plot_colormap('terrain', width=8.0, height=0.2, orientation='horizontal')
# Elevation layer
Map = geemap.Map(layout={'height':'400px', 'width':'800px'})
vis_params = {'bands':['elevation'], 'min': 0, 'max': 1800, 'palette': cm.palettes.terrain}
Map.addLayer(predictors, vis_params, 'elevation')
Map.add_colorbar(vis_params, label="Elevation (m)", orientation="vertical", layer_name="elevation")
Map.centerObject(aoi, 6)
Map
# Calculate the minimum and maximum values for bio09
min_max_val = (
predictors.select("bio09")
.multiply(0.1)
.reduceRegion(reducer=ee.Reducer.minMax(), scale=1000)
.getInfo()
)
# bio09 (Mean temperature of driest quarter) layer
Map = geemap.Map(layout={"height": "400px", "width": "800px"})
vis_params = {
"min": math.floor(min_max_val["bio09_min"]),
"max": math.ceil(min_max_val["bio09_max"]),
"palette": cm.palettes.hot,
}
Map.addLayer(predictors.select("bio09").multiply(0.1), vis_params, "bio09")
Map.add_colorbar(
vis_params,
label="Mean temperature of driest quarter (℃)",
orientation="vertical",
layer_name="bio09",
)
Map.centerObject(aoi, 6)
Map
# Slope layer
Map = geemap.Map(layout={'height':'400px', 'width':'800px'})
vis_params = {'bands':['slope'], 'min': 0, 'max': 25, 'palette': cm.palettes.RdYlGn_r}
Map.addLayer(predictors, vis_params, 'slope')
Map.add_colorbar(vis_params, label="Slope", orientation="vertical", layer_name="slope")
Map.centerObject(aoi, 6)
Map
# Aspect layer
Map = geemap.Map(layout={'height':'400px', 'width':'800px'})
vis_params = {'bands':['aspect'], 'min': 0, 'max': 360, 'palette': cm.palettes.rainbow}
Map.addLayer(predictors, vis_params, 'aspect')
Map.add_colorbar(vis_params, label="Aspect", orientation="vertical", layer_name="aspect")
Map.centerObject(aoi, 6)
Map
# Calculate the minimum and maximum values for bio14
min_max_val = (
predictors.select("bio14")
.reduceRegion(reducer=ee.Reducer.minMax(), scale=1000)
.getInfo()
)
# bio14 (Precipitation of driest month) layer
Map = geemap.Map(layout={"height": "400px", "width": "800px"})
vis_params = {
"bands": ["bio14"],
"min": math.floor(min_max_val["bio14_min"]),
"max": math.ceil(min_max_val["bio14_max"]),
"palette": cm.palettes.Blues,
}
Map.addLayer(predictors, vis_params, "bio14")
Map.add_colorbar(
vis_params,
label="Precipitation of driest month (mm)",
orientation="vertical",
layer_name="bio14",
)
Map.centerObject(aoi, 6)
Map
# TCC layer
Map = geemap.Map(layout={"height": "400px", "width": "800px"})
vis_params = {
"bands": ["TCC"],
"min": 0,
"max": 100,
"palette": ["ffffff", "afce56", "5f9c00", "0e6a00", "003800"],
}
Map.addLayer(predictors, vis_params, "TCC")
Map.add_colorbar(
vis_params, label="Tree Canopy Cover (%)", orientation="vertical", layer_name="TCC"
)
Map.centerObject(aoi, 6)
Map
Generation of pseudo-absence data
In the process of SDM, the selection of input data for a species is mainly approached using two methods:
Presence-Background Method: This method compares the locations where a particular species has been observed (presence) with other locations where the species has not been observed (background). Here, the background data does not necessarily mean areas where the species does not exist but rather is set up to reflect the overall environmental conditions of the study area. It is used to distinguish suitable environments where the species could exist from less suitable ones.
Presence-Absence Method: This method compares locations where the species has been observed (presence) with locations where it has definitively not been observed (absence). Here, absence data represents specific locations where the species is known not to exist. It does not reflect the overall environmental conditions of the study area but rather points to locations where the species is estimated not to exist.
In practice, it is often difficult to collect true absence data, so pseudo-absence data generated artificially is frequently used. However, it's important to acknowledge the limitations and potential errors of this method, as artificially generated pseudo-absence points may not accurately reflect true absence areas.
The choice between these two methods depends on data availability, research objectives, model accuracy and reliability, as well as time and resources. Here, we will use occurrence data collected from GBIF and artificially generated pseudo-absence data to model using the "Presence-Absence" method.
The generation of pseudo-absence data will be done through the "environmental profiling approach", and the specific steps are as follows:
Environmental Classification Using k-means Clustering: The k-means clustering algorithm, based on Euclidean distance, will be used to divide the pixels within the study area into two clusters. One cluster will represent areas with similar environmental characteristics to randomly selected 100 presence locations, while the other cluster will represent areas with different characteristics.
Generation of Pseudo-Absence Data within Dissimilar Clusters: Within the second cluster identified in the first step (which has different environmental characteristics from the presence data), randomly generated pseudo-absence points will be created. These pseudo-absence points will represent locations where the species is not expected to exist.
# Randomly select 100 locations for occurrence
pvals = predictors.sampleRegions(
collection=data.randomColumn().sort('random').limit(100),
properties=[],
scale=grain_size
)
# Perform k-means clustering
clusterer = ee.Clusterer.wekaKMeans(
nClusters=2,
distanceFunction="Euclidean"
).train(pvals)
cl_result = predictors.cluster(clusterer)
# Get cluster ID for locations similar to occurrence
cl_id = cl_result.sampleRegions(
collection=data.randomColumn().sort('random').limit(200),
properties=[],
scale=grain_size
)
# Define non-occurrence areas in dissimilar clusters
cl_id = ee.FeatureCollection(cl_id).reduceColumns(ee.Reducer.mode(),['cluster'])
cl_id = ee.Number(cl_id.get('mode')).subtract(1).abs()
cl_mask = cl_result.select(['cluster']).eq(cl_id)
# Presence location mask
presence_mask = data.reduceToImage(properties=['random'],
reducer=ee.Reducer.first()
).reproject('EPSG:4326', None,
grain_size).mask().neq(1).selfMask()
# Masking presence locations in non-occurrence areas and clipping to AOI
area_for_pa = presence_mask.updateMask(cl_mask).clip(aoi)
# Area for Pseudo-absence
Map = geemap.Map(layout={'height':'400px', 'width':'800px'})
Map.addLayer(area_for_pa, {'palette': 'black'}, 'AreaForPA')
Map.centerObject(aoi, 6)
Map
Model fitting and prediction
We will now divide the data into training data and test data. The training data will be used to find the optimal parameters by training the model, while the test data will be used to evaluate the model trained beforehand. An important concept to consider in this context is spatial autocorrelation.
Spatial autocorrelation is an essential element in SDM, associated with Tobler's law. It embodies the concept that "everything is related to everything else, but near things are more related than distant things". Spatial autocorrelation represents the significant relationship between the location of species and environmental variables. However, if spatial autocorrelation exists between the training and test data, the independence between the two data sets can be compromised. This significantly impacts the evaluation of the model's generalization ability.
One method to address this issue is the spatial block cross-validation technique, which involves dividing the data into training and testing datasets. This technique involves dividing the data into multiple blocks, using each block independently as training and test datasets to reduce the impact of spatial autocorrelation. This enhances the independence between datasets, allowing for a more accurate evaluation of the model's generalization ability.
The specific procedure is as follows:
- Creation of spatial blocks: Divide the entire dataset into spatial blocks of equal size (e.g., 50x50 km).
- Assignment of training and testing sets: Each spatial block is randomly assigned to either the training set (70%) or the test set (30%). This prevents the model from overfitting to data from specific areas and aims to achieve more generalized results.
- Iterative cross-validation: The entire process is repeated n times (e.g., 10 times). In each iteration, the blocks are randomly divided into training and test sets again, which is intended to improve the model's stability and reliability.
- Generation of pseudo-absence data: In each iteration, pseudo-absence data are randomly generated to evaluate the model's performance.
Scale = 50000
grid = watermask.reduceRegions(
collection=aoi.coveringGrid(scale=Scale, proj='EPSG:4326'),
reducer=ee.Reducer.mean()).filter(ee.Filter.neq('mean', None))
Map = geemap.Map(layout={'height':'400px', 'width':'800px'})
Map.addLayer(grid, {}, "Grid for spatial block cross validation")
Map.addLayer(outline, {'palette': 'FF0000'}, "Study Area")
Map.centerObject(aoi, 6)
Map
Now we can fit the model. Fitting a model involves understanding the patterns in the data and adjusting the model's parameters (weights and biases) accordingly. This process enables the model to make more accurate predictions when presented with new data. For this purpose, we have defined a function called SDM() to fit the model.
We will use the Random Forest algorithm.
def sdm(x):
seed = ee.Number(x)
# Random block division for training and validation
rand_blk = ee.FeatureCollection(grid).randomColumn(seed=seed).sort("random")
training_grid = rand_blk.filter(ee.Filter.lt("random", split)) # Grid for training
testing_grid = rand_blk.filter(ee.Filter.gte("random", split)) # Grid for testing
# Presence points
presence_points = ee.FeatureCollection(data)
presence_points = presence_points.map(lambda feature: feature.set("PresAbs", 1))
tr_presence_points = presence_points.filter(
ee.Filter.bounds(training_grid)
) # Presence points for training
te_presence_points = presence_points.filter(
ee.Filter.bounds(testing_grid)
) # Presence points for testing
# Pseudo-absence points for training
tr_pseudo_abs_points = area_for_pa.sample(
region=training_grid,
scale=grain_size,
numPixels=tr_presence_points.size().add(300),
seed=seed,
geometries=True,
)
# Same number of pseudo-absence points as presence points for training
tr_pseudo_abs_points = (
tr_pseudo_abs_points.randomColumn()
.sort("random")
.limit(ee.Number(tr_presence_points.size()))
)
tr_pseudo_abs_points = tr_pseudo_abs_points.map(lambda feature: feature.set("PresAbs", 0))
te_pseudo_abs_points = area_for_pa.sample(
region=testing_grid,
scale=grain_size,
numPixels=te_presence_points.size().add(100),
seed=seed,
geometries=True,
)
# Same number of pseudo-absence points as presence points for testing
te_pseudo_abs_points = (
te_pseudo_abs_points.randomColumn()
.sort("random")
.limit(ee.Number(te_presence_points.size()))
)
te_pseudo_abs_points = te_pseudo_abs_points.map(lambda feature: feature.set("PresAbs", 0))
# Merge training and pseudo-absence points
training_partition = tr_presence_points.merge(tr_pseudo_abs_points)
testing_partition = te_presence_points.merge(te_pseudo_abs_points)
# Extract predictor variable values at training points
train_pvals = predictors.sampleRegions(
collection=training_partition,
properties=["PresAbs"],
scale=grain_size,
geometries=True,
)
# Random Forest classifier
classifier = ee.Classifier.smileRandomForest(
numberOfTrees=500,
variablesPerSplit=None,
minLeafPopulation=10,
bagFraction=0.5,
maxNodes=None,
seed=seed,
)
# Presence probability: Habitat suitability map
classifier_pr = classifier.setOutputMode("PROBABILITY").train(
train_pvals, "PresAbs", bands
)
classified_img_pr = predictors.select(bands).classify(classifier_pr)
# Binary presence/absence map: Potential distribution map
classifier_bin = classifier.setOutputMode("CLASSIFICATION").train(
train_pvals, "PresAbs", bands
)
classified_img_bin = predictors.select(bands).classify(classifier_bin)
return [
classified_img_pr,
classified_img_bin,
training_partition,
testing_partition,
], classifier_pr
Spatial blocks are divided into 70% for model training and 30% for model testing, respectively. Pseudo-absence data are randomly generated within each training and testing set in every iteration. As a result, each execution yields different sets of presence and pseudo-absence data for model training and testing.
split = 0.7
numiter = 10
# Random Seed
runif = lambda length: [random.randint(1, 1000) for _ in range(length)]
items = runif(numiter)
# Fixed seed
# items = [287, 288, 553, 226, 151, 255, 902, 267, 419, 538]
results_list = [] # Initialize SDM results list
importances_list = [] # Initialize variable importance list
for item in items:
result, trained = sdm(item)
# Accumulate SDM results into the list
results_list.extend(result)
# Accumulate variable importance into the list
importance = ee.Dictionary(trained.explain()).get('importance')
importances_list.extend(importance.getInfo().items())
# Flatten the SDM results list
results = ee.List(results_list).flatten()
Now we can visualize the habitat suitability map and potential distribution map for the Fairy pitta. In this case, the habitat suitability map is created by using the mean() function to calculate the average for each pixel location across all images, and the potential distribution map is generated by using the mode() function to determine the most frequently occurring value at each pixel location across all images.
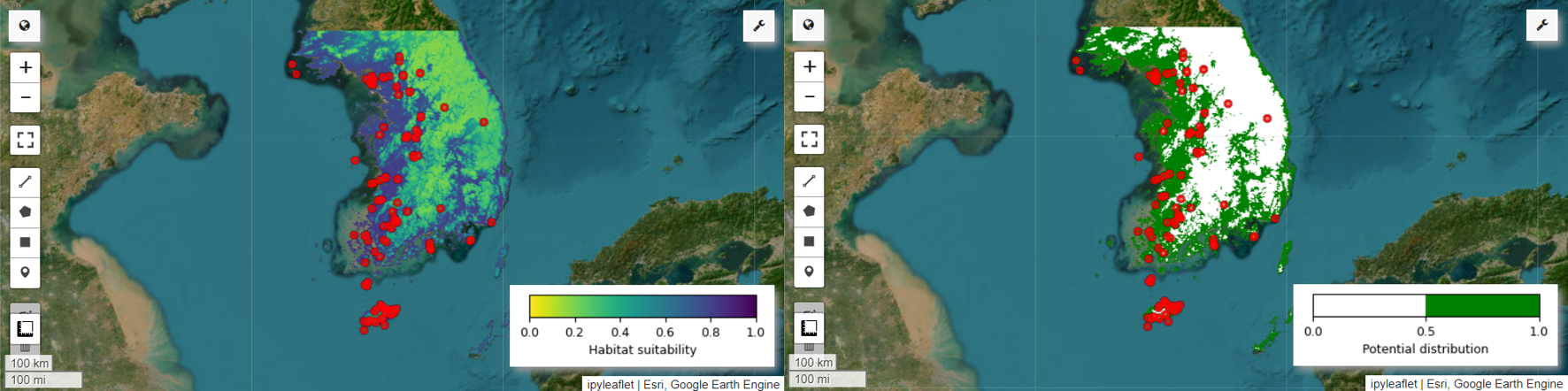
# Habitat suitability map
images = ee.List.sequence(
0, ee.Number(numiter).multiply(4).subtract(1), 4).map(
lambda x: results.get(x))
model_average = ee.ImageCollection.fromImages(images).mean()
Map = geemap.Map(layout={'height':'400px', 'width':'800px'}, basemap='Esri.WorldImagery')
vis_params = {
'min': 0,
'max': 1,
'palette': cm.palettes.viridis_r}
Map.addLayer(model_average, vis_params, 'Habitat suitability')
Map.add_colorbar(vis_params, label="Habitat suitability",
orientation="horizontal",
layer_name="Habitat suitability")
Map.addLayer(data, {'color':'red'}, 'Presence')
Map.centerObject(aoi, 6)
Map
# Potential distribution map
images2 = ee.List.sequence(1, ee.Number(numiter).multiply(4).subtract(1), 4).map(
lambda x: results.get(x)
)
distribution_map = ee.ImageCollection.fromImages(images2).mode()
Map = geemap.Map(
layout={"height": "400px", "width": "800px"}, basemap="Esri.WorldImagery"
)
vis_params = {"min": 0, "max": 1, "palette": ["white", "green"]}
Map.addLayer(distribution_map, vis_params, "Potential distribution")
Map.addLayer(data, {"color": "red"}, "Presence")
Map.add_colorbar(
vis_params,
label="Potential distribution",
discrete=True,
orientation="horizontal",
layer_name="Potential distribution",
)
Map.centerObject(data.geometry(), 6)
Map
Variable importance and accuracy assessment
Random Forest (ee.Classifier.smileRandomForest) is one of the ensemble learning methods, which operates by constructing multiple decision trees to make predictions. Each decision tree independently learns from different subsets of the data, and their results are aggregated to enable more accurate and stable predictions.
Variable importance is a measure that evaluates the impact of each variable on the predictions within the Random Forest model. We will use the previously defined importances_list to calculate and print the average variable importance.
def plot_variable_importance(importances_list):
# Extract each variable importance value into a list
variables = [item[0] for item in importances_list]
importances = [item[1] for item in importances_list]
# Calculate the average importance for each variable
average_importances = {}
for variable in set(variables):
indices = [i for i, var in enumerate(variables) if var == variable]
average_importance = np.mean([importances[i] for i in indices])
average_importances[variable] = average_importance
# Sort the importances in descending order of importance
sorted_importances = sorted(average_importances.items(),
key=lambda x: x[1], reverse=False)
variables = [item[0] for item in sorted_importances]
avg_importances = [item[1] for item in sorted_importances]
# Adjust the graph size
plt.figure(figsize=(8, 4))
# Plot the average importance as a horizontal bar chart
plt.barh(variables, avg_importances)
plt.xlabel('Importance')
plt.ylabel('Variables')
plt.title('Average Variable Importance')
# Display values above the bars
for i, v in enumerate(avg_importances):
plt.text(v + 0.02, i, f"{v:.2f}", va='center')
# Adjust the x-axis range
plt.xlim(0, max(avg_importances) + 5) # Adjust to the desired range
plt.tight_layout()
plt.savefig('variable_importance.png')
plt.show()
plot_variable_importance(importances_list)
Using the Testing Datasets, we calculate AUC-ROC and AUC-PR for each run. Then, we compute the average AUC-ROC and AUC-PR over n iterations.
AUC-ROC represents the area under the curve of the 'Sensitivity (Recall) vs. 1-Specificity' graph, illustrating the relationship between sensitivity and specificity as the threshold changes. Specificity is based on all observed non-occurrences. Therefore, AUC-ROC encompasses all quadrants of the confusion matrix.
AUC-PR represents the area under the curve of the 'Precision vs. Recall (Sensitivity)' graph, showing the relationship between precision and recall as the threshold varies. Precision is based on all predicted occurrences. Hence, AUC-PR does not include the true negatives (TN).
def print_pres_abs_sizes(TestingDatasets, numiter):
# Check and print the sizes of presence and pseudo-absence coordinates
def get_pres_abs_size(x):
fc = ee.FeatureCollection(TestingDatasets.get(x))
presence_size = fc.filter(ee.Filter.eq("PresAbs", 1)).size()
pseudo_absence_size = fc.filter(ee.Filter.eq("PresAbs", 0)).size()
return ee.List([presence_size, pseudo_absence_size])
sizes_info = (
ee.List.sequence(0, ee.Number(numiter).subtract(1), 1)
.map(get_pres_abs_size)
.getInfo()
)
for i, sizes in enumerate(sizes_info):
presence_size = sizes[0]
pseudo_absence_size = sizes[1]
print(
f"Iteration {i + 1}: Presence Size = {presence_size}, Pseudo-absence Size = {pseudo_absence_size}"
)
# Extracting the Testing Datasets
testing_datasets = ee.List.sequence(
3, ee.Number(numiter).multiply(4).subtract(1), 4
).map(lambda x: results.get(x))
print_pres_abs_sizes(testing_datasets, numiter)
def get_acc(hsm, t_data, grain_size):
pr_prob_vals = hsm.sampleRegions(
collection=t_data, properties=["PresAbs"], scale=grain_size
)
seq = ee.List.sequence(start=0, end=1, count=25) # Divide 0 to 1 into 25 intervals
def calculate_metrics(cutoff):
# Each element of the seq list is passed as cutoff(threshold value)
# Observed present = TP + FN
pres = pr_prob_vals.filterMetadata("PresAbs", "equals", 1)
# TP (True Positive)
tp = ee.Number(
pres.filterMetadata("classification", "greater_than", cutoff).size()
)
# TPR (True Positive Rate) = Recall = Sensitivity = TP / (TP + FN) = TP / Observed present
tpr = tp.divide(pres.size())
# Observed absent = FP + TN
abs = pr_prob_vals.filterMetadata("PresAbs", "equals", 0)
# FN (False Negative)
fn = ee.Number(
pres.filterMetadata("classification", "less_than", cutoff).size()
)
# TNR (True Negative Rate) = Specificity = TN / (FP + TN) = TN / Observed absent
tn = ee.Number(abs.filterMetadata("classification", "less_than", cutoff).size())
tnr = tn.divide(abs.size())
# FP (False Positive)
fp = ee.Number(
abs.filterMetadata("classification", "greater_than", cutoff).size()
)
# FPR (False Positive Rate) = FP / (FP + TN) = FP / Observed absent
fpr = fp.divide(abs.size())
# Precision = TP / (TP + FP) = TP / Predicted present
precision = tp.divide(tp.add(fp))
# SUMSS = SUM of Sensitivity and Specificity
sumss = tpr.add(tnr)
return ee.Feature(
None,
{
"cutoff": cutoff,
"TP": tp,
"TN": tn,
"FP": fp,
"FN": fn,
"TPR": tpr,
"TNR": tnr,
"FPR": fpr,
"Precision": precision,
"SUMSS": sumss,
},
)
return ee.FeatureCollection(seq.map(calculate_metrics))
def calculate_and_print_auc_metrics(images, testing_datasets, grain_size, numiter):
# Calculate AUC-ROC and AUC-PR
def calculate_auc_metrics(x):
hsm = ee.Image(images.get(x))
t_data = ee.FeatureCollection(testing_datasets.get(x))
acc = get_acc(hsm, t_data, grain_size)
# Calculate AUC-ROC
x = ee.Array(acc.aggregate_array("FPR"))
y = ee.Array(acc.aggregate_array("TPR"))
x1 = x.slice(0, 1).subtract(x.slice(0, 0, -1))
y1 = y.slice(0, 1).add(y.slice(0, 0, -1))
auc_roc = x1.multiply(y1).multiply(0.5).reduce("sum", [0]).abs().toList().get(0)
# Calculate AUC-PR
x = ee.Array(acc.aggregate_array("TPR"))
y = ee.Array(acc.aggregate_array("Precision"))
x1 = x.slice(0, 1).subtract(x.slice(0, 0, -1))
y1 = y.slice(0, 1).add(y.slice(0, 0, -1))
auc_pr = x1.multiply(y1).multiply(0.5).reduce("sum", [0]).abs().toList().get(0)
return (auc_roc, auc_pr)
auc_metrics = (
ee.List.sequence(0, ee.Number(numiter).subtract(1), 1)
.map(calculate_auc_metrics)
.getInfo()
)
# Print AUC-ROC and AUC-PR for each iteration
df = pd.DataFrame(auc_metrics, columns=["AUC-ROC", "AUC-PR"])
df.index = [f"Iteration {i + 1}" for i in range(len(df))]
df.to_csv("auc_metrics.csv", index_label="Iteration")
print(df)
# Calculate mean and standard deviation of AUC-ROC and AUC-PR
mean_auc_roc, std_auc_roc = df["AUC-ROC"].mean(), df["AUC-ROC"].std()
mean_auc_pr, std_auc_pr = df["AUC-PR"].mean(), df["AUC-PR"].std()
print(f"Mean AUC-ROC = {mean_auc_roc:.4f} ± {std_auc_roc:.4f}")
print(f"Mean AUC-PR = {mean_auc_pr:.4f} ± {std_auc_pr:.4f}")
%%time
# Calculate AUC-ROC and AUC-PR
calculate_and_print_auc_metrics(images, testing_datasets, grain_size, numiter)
This tutorial has provided a practical example of using Google Earth Engine (GEE) for Species Distribution Modeling (SDM). An important takeaway is the versatility and flexibility of GEE in the field of SDM. Leveraging Earth Engine's powerful geospatial data processing capabilities opens up endless possibilities for researchers and conservationists to understand and preserve biodiversity on our planet. By applying the knowledge and skills gained from this tutorial, individuals can explore and contribute to this fascinating field of ecological research.