
Cloud Vision API 將強大的機器學習模型封裝於容易使用的 REST API 中,協助使用者瞭解圖片內容。
在本實驗室中,我們將圖片傳送至 Vision API,以偵測物件、臉孔和地標。
課程內容
- 建立 Vision API 要求並使用 curl 呼叫 API
- 使用 Vision API 的標籤、網路、臉部和地標偵測方法
事前準備
您會如何使用本教學課程?
你對 Google Cloud Platform 的使用體驗滿意嗎?
自行設定環境
如果您還沒有 Google 帳戶 (Gmail 或 Google 應用程式),請先建立帳戶。登入 Google Cloud Platform 主控台 (console.cloud.google.com),然後建立新專案:



請記住專案 ID,這是所有 Google Cloud 專案中不重複的名稱 (上述名稱已遭占用,因此不適用於您,抱歉!)。本程式碼研究室稍後會將其稱為 PROJECT_ID。
接著,您必須在 Cloud 控制台中啟用帳單,才能使用 Google Cloud 資源。
完成本程式碼研究室的費用不應超過數美元,但如果您決定使用更多資源,或是將資源繼續執行 (請參閱本文件結尾的「清除」一節),則可能會增加費用。
Google Cloud Platform 新使用者享有價值 $300 美元的免費試用期。
按一下畫面左上方的「選單」圖示。

從下拉式選單中選取「API 和服務」,然後按一下「資訊主頁」。
按一下「啟用 API 和服務」。
接著,在搜尋框中搜尋「視覺」。按一下「Google Cloud Vision API」:

按一下「啟用」來啟用 Cloud Vision API:

稍待片刻,等待按鈕重新啟用。啟用後,畫面會顯示以下內容:
Google Cloud Shell 是 在雲端執行的指令列環境,這種以 Debian 為基礎的虛擬機器,搭載各種您需要的開發工具 (包括 gcloud、bq、git 等等),而且主目錄提供 5 GB 的永久儲存空間。我們會使用 Cloud Shell 建立 Speech API 的要求。
如要開始使用 Cloud Shell,請按一下標題列右上角的「啟用 Google Cloud Shell」圖示  。
。

系統會在控制台底部的新頁框中開啟 Cloud Shell 工作階段,並顯示指令列提示。等待 user@project:~$ 提示出現
我們會使用 curl 將要求傳送至 Vision API,因此需要產生 API 金鑰,才能傳入要求網址。如要建立 API 金鑰,請前往 Cloud 控制台的「API 和服務」部分,然後前往「憑證」專區:
在下拉式選單中選取「API 金鑰」:
接著,複製您剛產生的金鑰。
您現在已擁有 API 金鑰,儲存為環境變數後,就不需要為每個要求插入 API 金鑰值。您可以在 Cloud Shell 中執行此操作。請務必將 <your_api_key> 替換成您剛才複製的金鑰。
export API_KEY=<YOUR_API_KEY>建立 Cloud Storage bucket
如要將圖片傳送至 Vision API 進行圖片偵測,有兩種方式:將 base64 編碼的圖片字串傳送至 API,或是將儲存在 Google Cloud Storage 的檔案網址傳遞至 API。我們將使用 Cloud Storage 網址。我們會建立 Google Cloud Storage bucket 來儲存圖片。
前往專案的 Cloud Storage 瀏覽器:
然後按一下「建立 bucket」。為 bucket 提供專屬名稱 (例如專案 ID),然後按一下「建立」。
將圖片上傳至 bucket
在下列甜甜圈圖片上按一下滑鼠右鍵,然後點選「另存圖片為」,並將圖片儲存至「下載」資料夾,命名為 donuts.png。

在儲存空間瀏覽器中前往剛才建立的 bucket,然後按一下「上傳檔案」。然後選取「donuts.png」donuts.png。
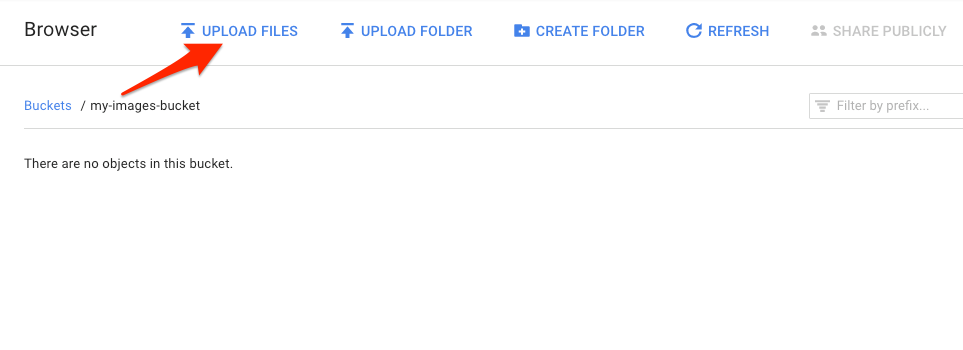
值區中應該會顯示該檔案:

接著編輯圖片的權限。
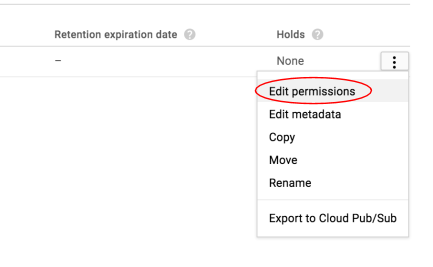
按一下「新增項目」。
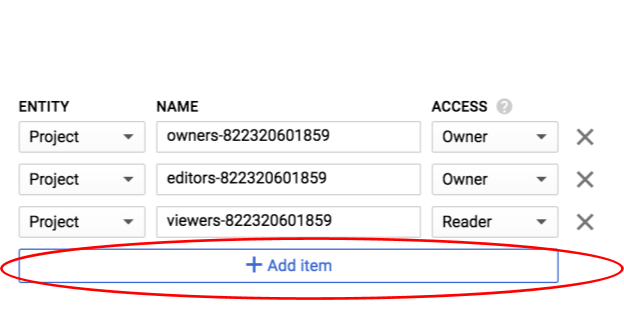
新增 Group 的 Entity,以及 allUsers 的 Name:
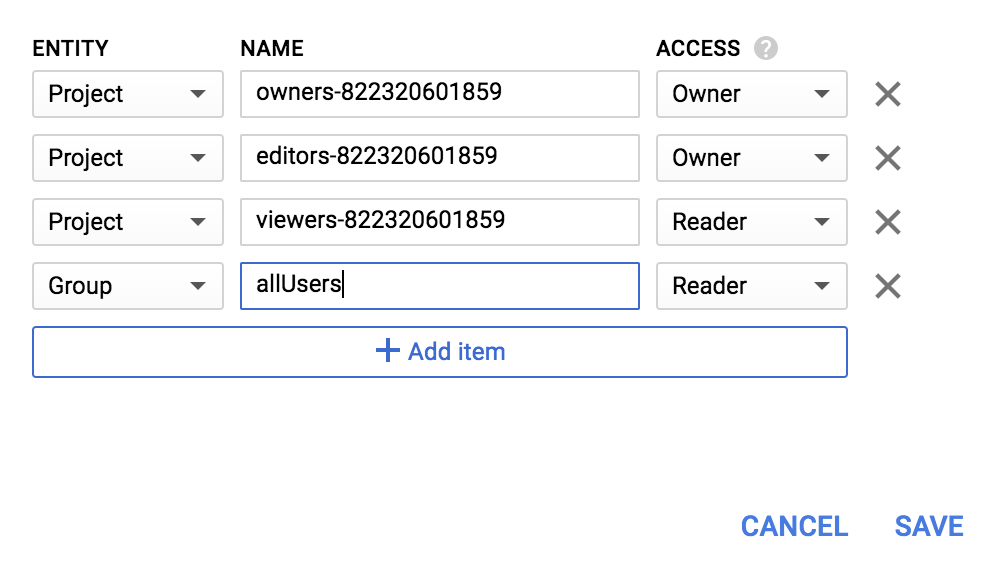
按一下 [儲存]。
現在您已將檔案存放在 bucket 中,可以建立 Vision API 要求,並將這張甜甜圈圖片的網址傳遞給要求。
在 Cloud Shell 環境中,使用下列程式碼建立 request.json 檔案,並務必將 my-bucket-name 替換為您建立的 Cloud Storage bucket 名稱。您可以使用偏好的指令列編輯器 (nano、vim、emacs) 建立檔案,或使用 Cloud Shell 內建的 Orion 編輯器:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}我們要探討的第一項 Cloud Vision API 功能是標籤偵測。這個方法會傳回圖片內容的標籤 (字詞) 清單。
現在可以透過 curl 呼叫 Vision API:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}回應內容應如下所示:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}API 能夠辨識出這些甜甜圈的具體類型 (法式甜甜圈),太酷了!對於 Vision API 找到的每個標籤,系統都會傳回含有項目名稱的 description。此外,這項功能也會傳回 score,也就是 0 到 100 之間的數字,表示系統對描述內容與圖片內容相符的信心程度。mid 值會對應至 Google 知識圖譜中的項目 MID。呼叫 Knowledge Graph API 時,可以使用 mid 取得項目的詳細資訊。
除了取得圖片內容的標籤,Vision API 也能在網路上搜尋圖片的額外詳細資料。透過 API 的 webDetection 方法,我們取得許多有趣的資料:
- 根據含有類似圖片的網頁內容,列出圖片中找到的實體
- 在網路上找到完全或部分相符的圖片網址,以及這些圖片所在網頁的網址
- 相似圖片的網址,例如反向圖片搜尋
如要試用網頁偵測功能,請使用上述的甜甜圈圖片,因此我們只需要變更 request.json 檔案中的一行 (您也可以冒險使用完全不同的圖片)。在特徵清單下方,將類型從「LABEL_DETECTION」變更為「WEB_DETECTION」。request.json 現在應如下所示:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}如要將圖片傳送至 Vision API,請使用與先前相同的 curl 指令 (只要按下 Cloud Shell 中的向上鍵即可):
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}讓我們深入瞭解回應內容,首先是 webEntities。這張圖片傳回的部分實體如下:
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
這張圖片已在許多 Cloud ML API 簡報中重複使用,因此 API 找到「機器學習」、「Google Cloud Platform」和「雲端運算」實體。
如果檢查 fullMatchingImages、partialMatchingImages 和 pagesWithMatchingImages 下的網址,會發現許多網址都指向這個程式碼研究室網站 (真是太 meta 了!)。
假設我們想尋找其他甜甜圈圖片,但不想找到完全相同的圖片,這時,API 回應中的 visuallySimilarImages 部分就能派上用場。以下是系統找到的幾張相似圖片:
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]我們可以前往這些網址查看類似圖片:




分析成效非常出色!現在你可能很想吃貝涅餅 (抱歉)。這類似於在 Google 圖片中以圖片搜尋:
但有了 Cloud Vision,我們就能透過簡單易用的 REST API 存取這項功能,並整合到應用程式中。
接下來,我們將探討 Vision API 的臉部和地標偵測方法。臉部偵測方法會傳回圖片中臉孔的資料,包括臉部情緒和在圖片中的位置。地標偵測功能可識別常見 (和不常見) 的地標,並傳回地標名稱、經緯度座標,以及地標在圖片中的位置。
上傳新圖片
如要使用這兩種新方法,請將含有臉部和地標的新圖片上傳至 Cloud Storage bucket。在下列圖片上按一下滑鼠右鍵,然後點選「另存圖片」,並將圖片儲存至「下載」資料夾,命名為 selfie.png。

然後以與上一個步驟相同的方式,將檔案上傳至 Cloud Storage bucket,並務必勾選「公開分享」核取方塊。
更新要求
接著,我們會更新 request.json 檔案,加入新圖片的網址,並改用臉部和地標偵測功能,而非標籤偵測功能。請務必將 my-bucket-name 替換為 Cloud Storage 值區名稱:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}呼叫 Vision API 並剖析回應
現在,您可以使用上述相同的 curl 指令呼叫 Vision API:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}首先,請查看回覆中的 faceAnnotations 物件。您會發現 API 會針對圖片中找到的每張臉孔傳回一個物件,在本例中為三個。以下是我們回覆的片段:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly 會提供圖片中臉孔周圍的 x 和 y 座標。fdBoundingPoly 是比 boundingPoly 小的方塊,可編碼臉部皮膚部分。landmarks 是每個臉部特徵的物件陣列 (有些特徵您可能從未聽過!)。這會告訴我們地標類型,以及該特徵的 3D 位置 (x、y、z 座標),其中 z 座標是深度。其餘值則提供臉部更多詳細資料,包括喜、悲、怒和驚訝的可能程度。上述物件適用於圖片中最後方的人,您可以看到他做出有點滑稽的表情,這說明瞭 joyLikelihood 的 POSSIBLE。
接著來看回應的 landmarkAnnotations 部分:
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]在這裡,Vision API 能夠判斷這張相片是在佩特拉拍攝,這相當令人驚豔,因為這張圖片的視覺線索極少。這項回應中的值應與上述 labelAnnotations 回應類似。
我們會取得地標的 mid、名稱 (description) 和信賴度 score。boundingPoly 顯示圖片中識別出地標的區域。locations 鍵會告訴我們這個地標的經緯度座標。
我們已瞭解 Vision API 的標籤、臉部和地標偵測方法,但還有三種方法尚未探討。請參閱說明文件,瞭解其他三種方法:
- 標誌偵測:識別常見標誌及其在圖片中的位置。
- 安全搜尋偵測:判斷圖片是否含有煽情露骨內容。這項功能適用於任何含有使用者原創內容的應用程式。您可以根據四個因素篩選圖片:成人、醫療、暴力和惡搞內容。
- 文字偵測:執行 OCR 從圖片中擷取文字。這項方法甚至可以辨識圖片中文字的語言。
您已瞭解如何使用 Vision API 分析圖片。在本範例中,您將圖片的 Google Cloud Storage 網址傳送給 API。您也可以傳送採用 Base64 編碼的圖片字串。
涵蓋內容
- 使用 curl 呼叫 Vision API,並傳遞 Cloud Storage 值區中圖片的網址
- 使用 Vision API 的標籤、網路、臉部和地標偵測方法
後續步驟
- 查看說明文件中的 Vision API 教學課程
- 以慣用語言尋找 Vision API 範例
- 試試 Speech API 和 Natural Language API Codelab!