
Cloud Vision API를 사용하면 간단한 REST API에 강력한 머신러닝 모델을 캡슐화하여 이미지 콘텐츠를 파악할 수 있습니다.
이 실습에서는 Vision API에 이미지를 전송하여 객체, 얼굴, 랜드마크를 인식하는 것을 확인합니다.
학습할 내용
- Vision API 요청 만들기 및 curl로 API 호출하기
- Vision API의 라벨, 웹, 얼굴, 랜드마크 감지 메서드 사용
필요한사항
이 튜토리얼을 어떻게 사용하실 계획인가요?
귀하의 Google Cloud Platform 사용 경험을 평가해 주세요.
자습형 환경 설정
아직 Google 계정 (Gmail 또는 Google Apps)이 없으면 계정을 만들어야 합니다. Google Cloud Platform 콘솔 (console.cloud.google.com)에 로그인하고 새 프로젝트를 만듭니다.



모든 Google Cloud 프로젝트에서 고유한 이름인 프로젝트 ID를 기억하세요(위의 이름은 이미 사용되었으므로 사용할 수 없습니다). 이 ID는 나중에 이 Codelab에서 PROJECT_ID라고 부릅니다.
그런 다음 Google Cloud 리소스를 사용할 수 있도록 Cloud 콘솔에서 결제를 사용 설정해야 합니다.
이 codelab을 실행하는 과정에는 많은 비용이 들지 않지만 더 많은 리소스를 사용하려고 하거나 실행 중일 경우 비용이 더 들 수 있습니다(이 문서 마지막의 '삭제' 섹션 참조).
Google Cloud Platform 신규 사용자는 $300 상당의 무료 체험판을 사용할 수 있습니다.
화면 왼쪽 상단의 메뉴 아이콘을 클릭합니다.

드롭다운에서 API 및 서비스를 선택하고 대시보드를 클릭합니다.
API 및 서비스 사용 설정을 클릭합니다.
그런 다음 검색창에서 'vision'을 검색합니다. Google Cloud Vision API를 클릭합니다.

사용 설정을 클릭하여 Cloud Vision API를 사용 설정합니다.

사용 설정될 때까지 몇 초간 기다립니다. 사용 설정되면 다음이 표시됩니다.
Google Cloud Shell은 Cloud에서 실행되는 명령줄 환경입니다. 이 Debian 기반 가상 머신은 필요한 모든 개발 도구 (gcloud, bq, git 등)와 함께 로드되며, 영구 5GB 홈 디렉터리를 제공합니다. Cloud Shell을 사용하여 Speech API에 대한 요청을 만듭니다.
Cloud Shell을 시작하려면 헤더 바의 오른쪽 상단에 있는 'Google Cloud Shell 활성화'  아이콘을 클릭합니다.
아이콘을 클릭합니다.

콘솔 하단에 있는 새 프레임 내에 Cloud Shell 세션이 열리면서 명령줄 프롬프트가 표시됩니다. user@project:~$ 프롬프트가 표시될 때까지 기다립니다.
Vision API로 요청을 전송하기 위해 curl을 사용할 것이므로, 요청 URL에 전달할 API 키를 만들어야 합니다. API 키를 만들려면 Cloud 콘솔의 API 및 서비스 사용자 인증 정보 섹션으로 이동하세요.
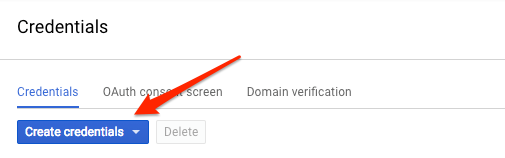
드롭다운 메뉴에서 API 키를 선택합니다.
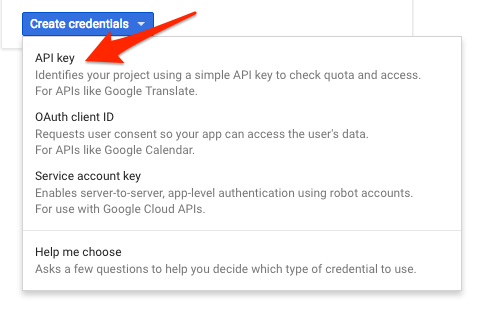
방금 만든 키를 복사합니다.
이제 API 키가 있으므로 각 요청에 API 키의 값을 삽입하지 않도록 환경 변수에 저장하겠습니다. Cloud Shell에서 이 작업을 수행할 수 있습니다. <your_api_key>를 방금 복사한 키로 대체해야 합니다.
export API_KEY=<YOUR_API_KEY>Cloud Storage 버킷 만들기
이미지 감지를 위해 Vision API에 이미지를 전송하는 방법에는 두 가지가 있습니다. API에 base64로 인코딩된 이미지 문자열을 전송하거나 Google Cloud Storage에 저장된 파일의 URL을 전달하는 방법입니다. Cloud Storage URL을 사용합니다. 이미지를 저장할 Google Cloud Storage 버킷을 만듭니다.
프로젝트의 Cloud 콘솔에서 스토리지 브라우저로 이동합니다.
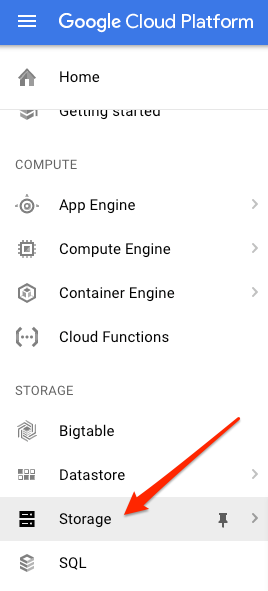
그런 다음 버킷 만들기를 클릭합니다. 버킷에 고유한 이름 (예: 프로젝트 ID)을 지정하고 만들기를 클릭합니다.
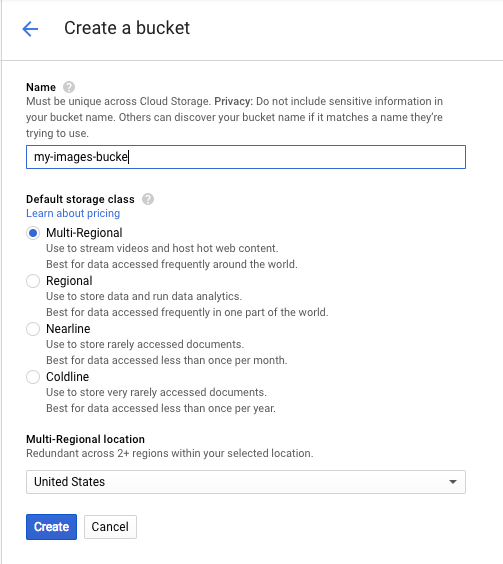
버킷에 이미지 업로드
다음 도넛 이미지를 마우스 오른쪽 버튼으로 클릭한 다음 이미지를 다른 이름으로 저장을 클릭하고 다운로드 폴더에 donuts.png로 저장합니다.

스토리지 브라우저에서 방금 만든 버킷으로 이동하여 파일 업로드를 클릭합니다. 그런 다음 donuts.png를 선택합니다.
버킷에 파일이 표시됩니다.

그런 다음 이미지의 권한을 수정합니다.
항목 추가를 클릭합니다.
Group의 새 항목과 allUsers의 이름을 추가합니다.
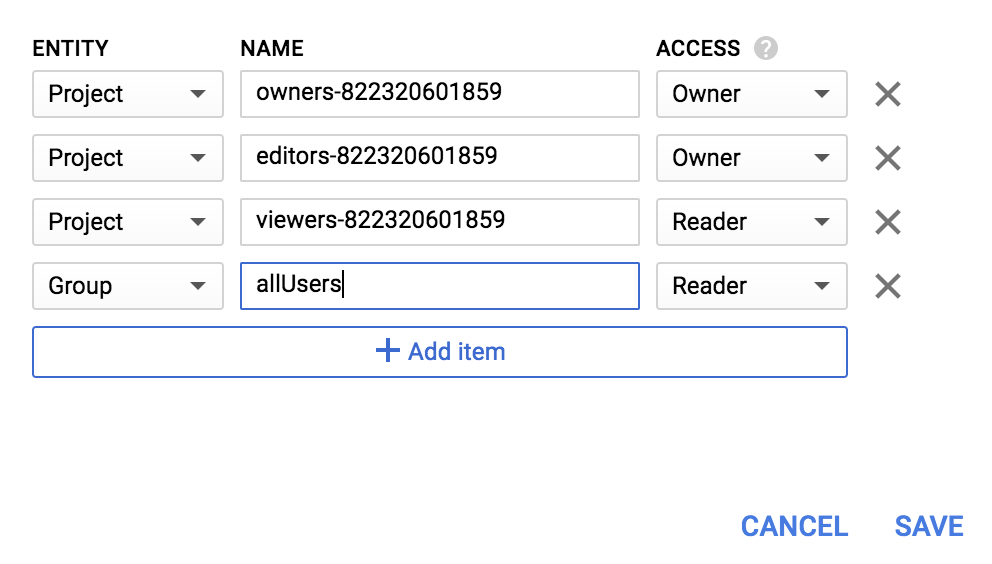
저장을 클릭합니다.
이제 버킷에 파일이 있으므로 이 도넛 사진의 URL을 전달하여 Vision API 요청을 만들 수 있습니다.
Cloud Shell 환경에서 아래 코드를 사용하여 request.json 파일을 생성합니다. 이때 my-bucket-name을 생성한 Cloud Storage 버킷 이름으로 바꿔야 합니다. nano, vim, emacs와 같이 원하는 명령줄 편집기를 사용하거나 Cloud Shell의 기본 Orion 편집기를 사용할 수 있습니다.
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}첫 번째로 살펴볼 Cloud Vision API 기능은 라벨 감지입니다. 이 메서드는 이미지에 있는 항목의 라벨 (단어) 목록을 반환합니다.
이제 curl을 사용하여 Vision API를 호출할 준비가 되었습니다.
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}응답이 다음과 같이 표시됩니다.
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}API가 이 도넛의 구체적인 유형 (베이네)을 식별할 수 있었습니다. 멋지네요. Vision API는 발견된 각 라벨에 대해 항목의 이름이 포함된 description를 반환합니다. 또한 설명이 이미지의 내용과 일치하는지 얼마나 확신하는지를 나타내는 0~100 사이의 숫자 score도 반환합니다. mid 값은 Google의 지식 그래프에 있는 항목의 mid에 매핑됩니다. Knowledge Graph API를 호출할 때 mid를 사용하여 항목에 대한 자세한 정보를 얻을 수 있습니다.
Vision API는 이미지에 있는 항목에 대한 라벨을 가져올 뿐만 아니라 인터넷에서 이미지에 대한 추가 세부정보를 검색할 수도 있습니다. API의 webDetection 메서드를 통해 다음과 같은 흥미로운 데이터를 많이 가져올 수 있습니다.
- 유사한 이미지가 있는 페이지의 콘텐츠를 기반으로 이미지에서 발견된 항목 목록
- 웹에서 발견된 완전 일치 및 부분 일치 이미지의 URL과 해당 페이지의 URL
- 이미지로 검색과 같이 유사한 이미지의 URL
웹 감지를 사용해 보려면 위의 베이글 이미지를 그대로 사용하면 되므로 request.json 파일에서 한 줄만 변경하면 됩니다 (알 수 없는 영역으로 모험을 떠나 완전히 다른 이미지를 사용해도 됨). 기능 목록에서 유형을 LABEL_DETECTION에서 WEB_DETECTION로 변경하면 됩니다. 이제 request.json가 다음과 같이 표시됩니다.
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}Vision API에 보내려면 이전과 동일한 curl 명령어를 사용하면 됩니다 (Cloud Shell에서 위쪽 화살표를 누르세요).
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}webEntities부터 시작하여 대답을 자세히 살펴보겠습니다. 이 이미지에서 반환된 항목은 다음과 같습니다.
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
이 이미지는 Google Cloud ML API에 관한 여러 프레젠테이션에서 재사용되었기 때문에 API가 '머신러닝', 'Google Cloud Platform', '클라우드 컴퓨팅'이라는 항목을 찾았습니다.
fullMatchingImages, partialMatchingImages, pagesWithMatchingImages 아래의 URL을 검사하면 많은 URL이 이 Codelab 사이트를 가리키는 것을 알 수 있습니다 (매우 메타적임).
베이네의 다른 이미지를 찾고 싶지만 정확히 동일한 이미지는 찾고 싶지 않다고 가정해 보겠습니다. 이때 API 응답의 visuallySimilarImages 부분이 유용합니다. 시각적으로 유사한 이미지는 다음과 같습니다.
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]이러한 URL로 이동하여 유사한 이미지를 확인할 수 있습니다.




아주 잘 분석하죠! 이제 베이네가 정말 먹고 싶을 거예요 (죄송합니다). 이는 Google 이미지에서 이미지를 사용해 검색하는 것과 유사합니다.
하지만 Cloud Vision을 사용하면 사용하기 쉬운 REST API로 이 기능에 액세스하고 애플리케이션에 통합할 수 있습니다.
다음으로 Vision API의 얼굴 및 랜드마크 감지 방법을 살펴보겠습니다. 얼굴 감지 메서드는 얼굴의 감정, 이미지 내 얼굴의 위치 등 이미지에서 발견된 얼굴에 관한 데이터를 반환합니다. 랜드마크 감지는 일반적인 랜드마크와 잘 알려지지 않은 랜드마크를 식별할 수 있습니다. 랜드마크의 이름, 위도 및 경도 좌표, 이미지에서 랜드마크가 식별된 위치를 반환합니다.
새 이미지 업로드하기
이 두 가지 새로운 메서드를 사용하려면 얼굴과 랜드마크가 있는 새 이미지를 Cloud Storage 버킷에 업로드하세요. 다음 이미지를 마우스 오른쪽 버튼으로 클릭한 다음 이미지를 다른 이름으로 저장을 클릭하고 다운로드 폴더에 selfie.png로 저장합니다.

그런 다음 이전 단계에서와 같은 방식으로 Cloud Storage 버킷에 업로드하고 '공개적으로 공유' 체크박스를 선택합니다.
요청 업데이트
다음으로 새 이미지의 URL을 포함하고 라벨 감지 대신 얼굴 및 랜드마크 감지를 사용하도록 request.json 파일을 업데이트합니다. my-bucket-name을 Cloud Storage 버킷의 이름으로 바꿔야 합니다.
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}Vision API 호출 및 응답 파싱
이제 위에서 사용한 것과 동일한 curl 명령어를 사용하여 Vision API를 호출할 수 있습니다.
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}먼저 응답의 faceAnnotations 객체를 살펴보겠습니다. API가 이미지에서 발견된 각 얼굴에 대해 객체를 반환합니다. 이 경우 3개의 얼굴이 발견되었습니다. 다음은 잘라낸 버전의 대답입니다.
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly는 이미지의 얼굴 주변 x,y 좌표를 제공합니다. fdBoundingPoly는 boundingPoly보다 작은 상자이며 얼굴의 피부 부분을 인코딩합니다. landmarks는 각 얼굴 특징의 객체 배열입니다 (일부는 알지 못했을 수도 있음). 이를 통해 랜드마크의 유형과 해당 기능의 3D 위치 (x,y,z 좌표)를 알 수 있습니다. 여기서 z 좌표는 깊이입니다. 나머지 값은 기쁨, 슬픔, 분노, 놀람의 가능성을 비롯한 얼굴에 관한 세부정보를 제공합니다. 위의 객체는 이미지에서 가장 뒤에 있는 사람을 위한 것입니다. 이 사람이 약간 어리석은 표정을 짓고 있어 POSSIBLE의 joyLikelihood를 설명할 수 있습니다.
다음으로 대답의 landmarkAnnotations 부분을 살펴보겠습니다.
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]여기에서 Vision API는 이 사진이 페트라에서 촬영되었음을 알 수 있었습니다. 이 이미지의 시각적 단서가 최소한임을 고려할 때 매우 인상적입니다. 이 응답의 값은 위의 labelAnnotations 응답과 비슷해야 합니다.
랜드마크의 mid, 이름 (description), 신뢰도 score를 가져옵니다. boundingPoly는 이미지에서 랜드마크가 식별된 영역을 보여줍니다. locations 키는 이 랜드마크의 위도 경도 좌표를 알려줍니다.
지금까지 Vision API의 라벨, 얼굴, 랜드마크 감지 방법을 살펴봤지만 아직 살펴보지 않은 세 가지 방법이 있습니다. 문서를 살펴보고 나머지 세 가지에 대해 알아보세요.
- 로고 감지: 이미지에서 일반적인 로고와 그 위치를 식별합니다.
- 세이프서치 감지: 이미지에 유해성 콘텐츠가 포함되어 있는지 여부를 확인합니다. 이는 사용자 생성 콘텐츠가 있는 모든 애플리케이션에 유용합니다. 성인용, 의료, 폭력, 패러디 콘텐츠의 네 가지 요소를 기준으로 이미지를 필터링할 수 있습니다.
- 텍스트 감지: OCR을 실행하여 이미지에서 텍스트를 추출합니다. 이 메서드는 이미지에 있는 텍스트의 언어를 식별할 수도 있습니다.
Vision API를 사용하여 이미지를 분석하는 방법을 알아보았습니다. 이 예시에서는 이미지의 Google Cloud Storage URL을 API에 전달했지만, 이미지의 Base64 인코딩 문자열을 전달할 수도 있습니다.
학습한 내용
- Cloud Storage 버킷에 있는 이미지의 URL을 전달하여 curl로 Vision API 호출
- Vision API의 라벨, 웹, 얼굴, 랜드마크 감지 메서드 사용
다음 단계
- 문서에서 Vision API 튜토리얼 확인하기
- 선호하는 언어로 Vision API 샘플 찾기
- Speech API 및 Natural Language API Codelab을 사용해 보세요.