
Mit der Cloud Vision API erhalten Sie Informationen über den Inhalt eines Bildes, indem Sie über eine nutzerfreundliche REST API leistungsstarke Modelle für maschinelles Lernen verwenden.
In diesem Lab senden Sie ein Bild an die Cloud Vision API, die die darin enthaltenen Objekte, Gesichter und Sehenswürdigkeiten erkennen soll.
Lerninhalte
- Vision API-Anfrage erstellen und API mit "curl" aufrufen
- Methoden zur Erkennung von Labels, Web, Gesichtern und Sehenswürdigkeiten der Vision API verwenden
Voraussetzungen
Wie werden Sie diese Anleitung verwenden?
Wie würden Sie Ihre Erfahrung mit der Google Cloud Platform bewerten?
Einrichtung der Umgebung im eigenen Tempo
Wenn Sie noch kein Google-Konto (Gmail oder Google Apps) haben, müssen Sie eins erstellen. Melden Sie sich in der Google Cloud Platform Console (console.cloud.google.com) an und erstellen Sie ein neues Projekt:



Notieren Sie sich die Projekt-ID, also den projektübergreifend nur einmal vorkommenden Namen eines Google Cloud-Projekts. Der oben angegebene Name ist bereits vergeben und kann leider nicht mehr verwendet werden. Sie wird in diesem Codelab später als PROJECT_ID bezeichnet.
Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Google Cloud-Ressourcen verwenden zu können.
Dieses Codelab sollte Sie nicht mehr als ein paar Dollar kosten, aber es könnte mehr sein, wenn Sie sich für mehr Ressourcen entscheiden oder wenn Sie sie laufen lassen (siehe Abschnitt „Bereinigen“ am Ende dieses Dokuments).
Neuen Nutzern der Google Cloud Platform steht eine kostenlose Testversion mit einem Guthaben von 300$ zur Verfügung.
Klicken Sie auf das Menüsymbol oben links auf dem Bildschirm.

Wählen Sie im Drop-down-Menü APIs & Services (APIs & Dienste) aus und klicken Sie auf „Dashboard“.
Klicken Sie auf APIs und Dienste aktivieren.
Geben Sie dann in das Suchfeld „vision“ ein. Klicken Sie auf Google Cloud Vision API:

Klicken Sie auf Aktivieren, um die Cloud Vision API zu aktivieren:

Es dauert einige Sekunden, bis die Funktion aktiviert ist. So sieht es aus, wenn die Funktion aktiviert ist:
Google Cloud Shell ist eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird. Auf dieser Debian-basierten virtuellen Maschine sind alle erforderlichen Entwicklungstools (gcloud, bq, git usw.) installiert und sie stellt ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher zur Verfügung. Wir verwenden Cloud Shell, um unsere Anfrage an die Speech API zu erstellen.
Klicken Sie zum Starten von Cloud Shell rechts oben in der Kopfzeile auf das Symbol „Google Cloud Shell aktivieren“  .
.

Im unteren Bereich der Konsole wird ein neuer Frame für die Cloud Shell-Sitzung geöffnet, in dem eine Befehlszeilen-Eingabeaufforderung angezeigt wird. Warten Sie, bis die Eingabeaufforderung „user@project:~$“ angezeigt wird.
Da Sie mit curl eine Anfrage an die Vision API senden möchten, müssen Sie zuvor einen API-Schlüssel generieren, um ihn in der Anfrage-URL zu übergeben. Gehen Sie dazu in der Cloud Console zu „APIs & Dienste“ > „Anmeldedaten“:
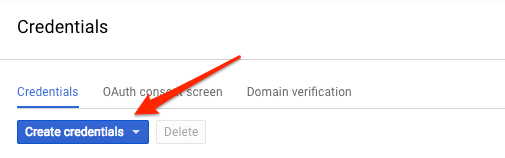
Wählen Sie im Drop-down-Menü API key (API-Schlüssel) aus:
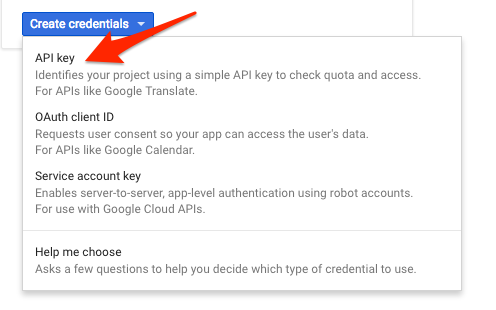
Kopieren Sie den gerade generierten Schlüssel.
Speichern Sie nun den API-Schlüssel in einer Umgebungsvariablen. So brauchen Sie den Wert des API-Schlüssels nicht in jede Anfrage einzufügen. Das können Sie in Cloud Shell tun. Ersetzen Sie <your_api_key> durch den gerade kopierten Schlüssel.
export API_KEY=<YOUR_API_KEY>Cloud Storage-Bucket erstellen
Es gibt zwei Möglichkeiten, ein Bild zur Bilderkennung an die Vision API zu senden: Entweder Sie senden der API einen Base64-codierten Bildstring oder Sie übergeben die URL einer in Google Cloud Storage gespeicherten Datei. Hier verwenden Sie eine Cloud Storage-URL. Erstellen Sie einen Google Cloud Storage-Bucket, in dem die Bilder gespeichert werden sollen.
Wechseln Sie in der Cloud Console für Ihr Projekt zum Storage-Browser:
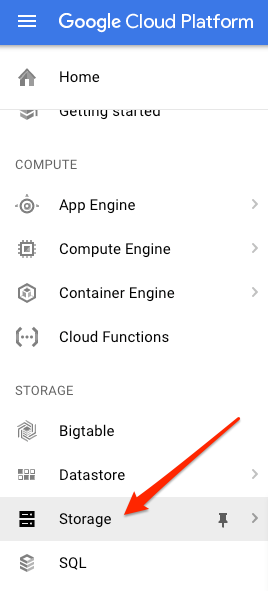
Klicken Sie dann auf Bucket erstellen. Geben Sie dem Bucket einen eindeutigen Namen (z. B. Ihre Projekt-ID) und klicken Sie auf Erstellen.

Bild in den Bucket hochladen
Klicken Sie mit der rechten Maustaste auf das folgende Donutbild. Klicken Sie dann auf Bild speichern unter und speichern Sie es im Ordner „Downloads“ als donuts.png.

Gehen Sie zu dem Bucket, den Sie gerade im Storage-Browser erstellt haben, und klicken Sie auf Dateien hochladen. Wählen Sie donuts.png aus.
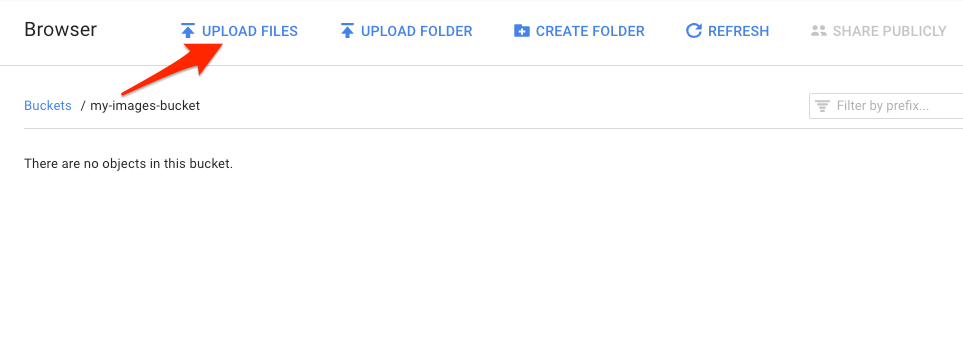
Die Datei sollte in Ihrem Bucket angezeigt werden:

Bearbeiten Sie als Nächstes die Berechtigung des Bildes.
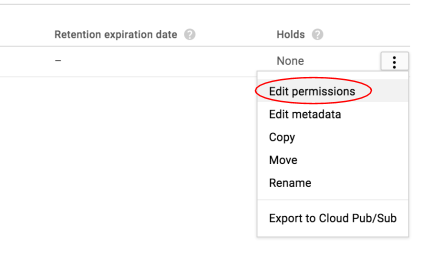
Klicken Sie auf Zeile hinzufügen.
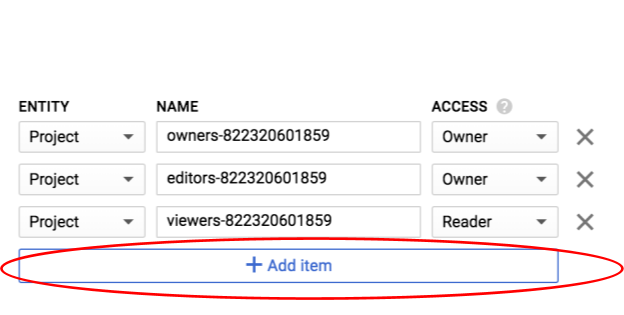
Fügen Sie eine neue Entität vom Typ Group und einen Namen vom Typ allUsers hinzu:
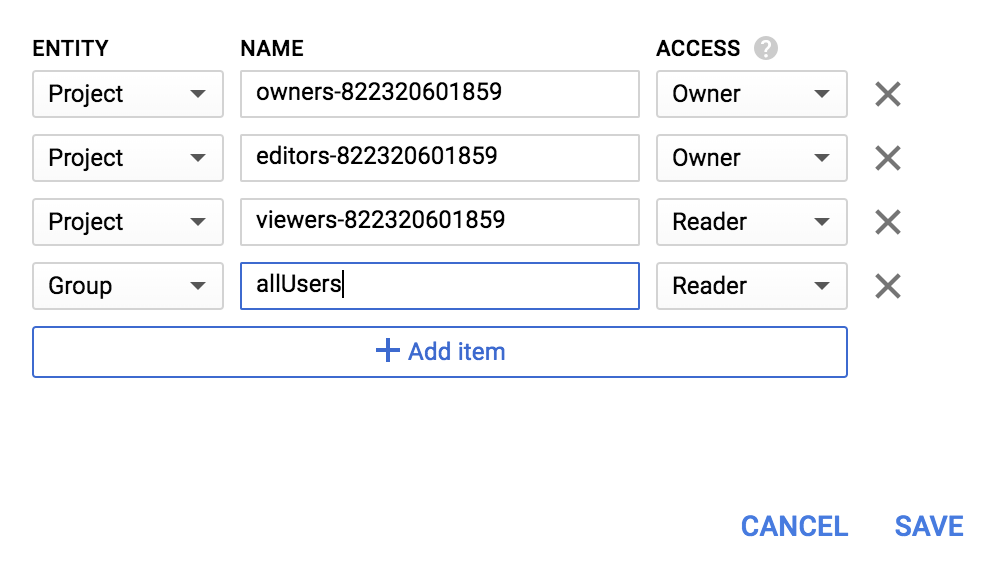
Klicken Sie auf Speichern.
Nachdem die Datei in den Bucket hochgeladen wurde, können Sie eine Vision API-Anfrage erstellen und die URL dieses Donutbildes übergeben.
Erstellen Sie in der Cloud Shell-Umgebung eine Datei namens request.json mit dem folgenden Code. Ersetzen Sie dabei my-bucket-name durch den Namen des von Ihnen erstellten Cloud Storage-Buckets. Sie können die Datei entweder mit Ihrem bevorzugten Befehlszeileneditor (nano, vim, emacs) oder mit dem in Cloud Shell integrierten Orion-Editor erstellen:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}Als erste Cloud Vision API-Funktion probieren wir die Labelerkennung aus. Diese Methode gibt eine Liste mit Labels (Wörtern) zurück, die den Bildinhalt beschreiben.
Wir können jetzt die Vision API mit „curl“ aufrufen:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Die Antwort sollte in etwa so aussehen:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}Die API konnte sogar erkennen, dass es sich um eine spezielle Art von Donuts handelt, nämlich Beignets. Für jedes Label, das die Vision API gefunden hat, wird ein description mit dem Namen des Elements zurückgegeben. Außerdem wird ein score zurückgegeben, eine Zahl zwischen 0 und 100, die angibt, wie genau die Beschreibung mit dem Bild übereinstimmt. Der mid-Wert entspricht der MID des Artikels im Knowledge Graph von Google. Sie können den mid-Wert verwenden, wenn Sie die Knowledge Graph API aufrufen, um weitere Informationen zum Objekt abzurufen.
Mit der Vision API können Sie nicht nur Labels zu einem Bild abrufen, sondern auch im Internet nach weiteren Details zum Bild suchen. Über die webDetection-Methode der API erhalten wir viele interessante Daten:
- Eine Liste der im Bild gefundenen Entitäten, basierend auf Inhalten von Seiten mit ähnlichen Bildern
- URLs von vollständig und teilweise übereinstimmenden Bildern im Web sowie die URLs dieser Seiten
- URLs ähnlicher Bilder (wie bei einer umgekehrten Bildersuche)
Zum Ausprobieren der Weberkennung verwenden wir wieder das Bild mit den Beignets von oben. Dazu müssen wir nur eine Zeile in der Datei request.json ändern. Sie können aber auch ein ganz anderes Bild nehmen. Ändern Sie in der Liste „features“ einfach den Wert von „type“ von LABEL_DETECTION in WEB_DETECTION. request.json sollte jetzt so aussehen:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}Senden Sie die Datei mit demselben curl-Befehl wie zuvor an die Vision API. Drücken Sie dazu in Cloud Shell einfach den Aufwärtspfeil:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Sehen Sie sich in der Antwort zuerst den Abschnitt webEntities an. Hier sind einige der Entitäten, die dieses Bild zurückgegeben hat:
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
Dieses Bild wurde in vielen Präsentationen zu unseren Cloud ML APIs wiederverwendet. Deshalb hat die API die Entitäten „Machine Learning“, „Google Cloud Platform“ und „Cloud Computing“ gefunden.
Außerdem zeigen viele der URLs unter fullMatchingImages, partialMatchingImages und pagesWithMatchingImages auf diese Codelab-Site (gute Metadaten).
Angenommen, Sie suchen andere Bilder mit Beignets, aber nicht genau dieselben. Hierfür bietet sich der Abschnitt visuallySimilarImages der API-Antwort an. Hier sind einige der visuell ähnlichen Bilder, die gefunden wurden:
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]Sie können diese URLs aufrufen, um sich die ähnlichen Bilder anzusehen:




Nicht schlecht, oder? Jetzt müssten Sie wirklich Appetit auf einen Beignet bekommen haben. Diese Suche funktioniert ähnlich wie die Bildersuche in Google Bilder:
Mit Cloud Vision können wir jedoch über eine einfach zu verwendende REST API auf diese Funktionalität zugreifen und sie in unsere Anwendungen integrieren.
Als Nächstes lernen Sie die Methoden zur Erkennung von Gesichtern und Sehenswürdigkeiten der Vision API kennen. Bei der Gesichtserkennung werden Daten zu in einem Bild gefundenen Gesichtern zurückgegeben, einschließlich der Emotionen in den Gesichtern und deren Position im Bild. Bei der Erkennung von Sehenswürdigkeiten werden bekannte (und nicht deutlich erkennbare) Sehenswürdigkeiten identifiziert. Es werden der Name der Sehenswürdigkeit, deren Koordinaten (Breiten- und Längengrade) sowie der Ort zurückgegeben, an dem die Sehenswürdigkeit in einem Bild erkannt wurde.
Neues Bild hochladen
Um diese beiden neuen Methoden zu verwenden, laden wir ein neues Bild mit Gesichtern und Sehenswürdigkeiten in unseren Cloud Storage-Bucket hoch. Klicken Sie mit der rechten Maustaste auf das folgende Bild. Klicken Sie dann auf Bild speichern unter und speichern Sie es als selfie.png im Ordner „Downloads“.

Laden Sie es dann wie im vorherigen Schritt in Ihren Cloud Storage-Bucket hoch und achten Sie darauf, dass das Kästchen „Öffentlich freigeben“ angeklickt ist.
Aktualisierung unserer Anfrage
Als Nächstes aktualisieren wir die Datei request.json, damit sie die URL des neuen Bildes enthält und die Erkennung von Gesichtern und Sehenswürdigkeiten anstelle der Labelerkennung verwendet. Ersetzen Sie my-bucket-name durch den Namen Ihres Cloud Storage-Buckets:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}Vision API aufrufen und die Antwort analysieren
Rufen Sie nun die Vision API mit demselben curl-Befehl wie zuvor auf:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Sehen wir uns zuerst das faceAnnotations-Objekt in unserer Antwort an. Die API gibt ein Objekt für jedes im Bild gefundene Gesicht zurück – in diesem Fall drei. Hier ist ein Ausschnitt aus unserer Antwort:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly: x,y-Koordinaten um das Gesicht im Bild fdBoundingPoly ist ein kleinerer Bereich als boundingPoly, der sich auf die Hautpartie des Gesichts beschränkt. landmarks ist ein Array von Objekten für jedes Gesichtsmerkmal (von einigen haben Sie vielleicht noch gar nicht gehört!). Hiermit wird der Typ des Orientierungspunktes zusammen mit der 3D-Position dieses Merkmals (x-, y-, z-Koordinaten) angegeben, wobei die z-Koordinate die Tiefe darstellt. Die übrigen Werte geben uns weitere Details zum Gesicht, einschließlich der Wahrscheinlichkeit von Freude, Trauer, Ärger und Überraschung. Das oben genannte Objekt bezieht sich auf die Person, die ganz hinten im Bild steht. Sie zieht eine Art Grimasse, deshalb steht bei joyLikelihood der Wert POSSIBLE.
Sehen wir uns als Nächstes den landmarkAnnotations-Teil unserer Antwort an:
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]Die Vision API konnte hier erkennen, dass das Bild in Petra aufgenommen wurde. Das ist sehr beeindruckend, weil die sichtbaren Anhaltspunkte in diesem Bild minimal sind. Die Werte in dieser Antwort sollten in etwa so aussehen wie die in der Antwort labelAnnotations oben.
Wir erhalten die mid der Sehenswürdigkeit, ihren Namen (description) sowie einen Konfidenzwert score. boundingPoly: Bereich im Bild, in dem die Sehenswürdigkeit erkannt wurde locations: Koordinaten (Breiten- und Längengrade) dieser Sehenswürdigkeit
Sie haben die Methoden zur Erkennung von Labels, Gesichtern und Sehenswürdigkeiten der Vision API kennengelernt. Es gibt aber drei weitere Methoden, die noch nicht vorgestellt wurden. In der Dokumentation erfahren Sie mehr zu den drei weiteren Methoden:
- Logoerkennung: Identifizieren Sie bekannte Logos und deren Position in einem Bild.
- SafeSearch-Erkennung: Finden Sie heraus, ob ein Bild explizite Inhalte enthält. Das ist sinnvoll bei Apps mit von Nutzern erstellten Inhalten. Sie können Bilder anhand der folgenden vier Faktoren filtern: Inhalte nur für Erwachsene, Medizinprodukt, Gewalt und Spoofing.
- Texterkennung: Führen Sie OCR aus, um Text aus Bildern zu extrahieren. Diese Methode kann sogar die Sprache des in einem Bild enthaltenen Textes erkennen.
Sie wissen nun, wie Sie Bilder mit der Vision API analysieren. In diesem Beispiel haben Sie der API die Google Cloud Storage-URL des Bildes übergeben. Alternativ können Sie einen Base64-codierten Bildstring übergeben.
Behandelte Themen
- Vision API mit "curl" durch Übergabe der URL eines Bildes in einem Cloud Storage-Bucket aufrufen
- Methoden zur Erkennung von Labels, Web, Gesichtern und Sehenswürdigkeiten der Vision API verwenden
Nächste Schritte
- Vision API-Anleitungen in der Dokumentation
- Vision API-Beispiel in Ihrer bevorzugten Sprache
- Speech API und Natural Language API testen