

Dans cet atelier de programmation, vous allez apprendre à utiliser Stackdriver pour surveiller et analyser les métriques de performances et les journaux des services Google Cloud Platform et des VM.
Dans cet atelier de programmation, vous allez :
- Familiarisez-vous avec la page d'accueil Stackdriver.
- Comprendre les tableaux de bord et les graphiques
- Créer un test de disponibilité
- Créez une règle d'alerte simple.
- Utilisez les incidents d'alerte.
- Parcourez la visionneuse de journaux.
Quelle est votre expérience avec Stackdriver ?
Configuration de l'environnement au rythme de chacun
Si vous ne possédez pas encore de compte Google (Gmail ou Google Apps), vous devez en créer un.
Connectez-vous à la console Google Cloud Platform (console.developers.google.com) et créez un projet :


Mémorisez l'ID du projet. Il s'agit d'un nom unique permettant de différencier chaque projet Google Cloud. Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
Très important : accédez à la page Compute Engine pour activer l'API Compute Engine :
Ensuite, accédez à Compute Engine → Instances de VM.

La première fois que vous effectuez cette opération, un écran s'affiche avec le message "Compute Engine se prépare. Cette opération peut prendre une minute ou plus". Vous pouvez continuer à vous connecter à Google Cloud Shell ci-dessous, mais vous ne pourrez pas créer de VM tant que cette opération ne sera pas terminée.
La plupart des tâches s'effectueront dans Google Cloud Shell, un environnement de ligne de commande exécuté dans le cloud. Cette machine virtuelle basée sur Debian contient tous les outils de développement dont vous aurez besoin et offre un répertoire de base persistant de 5 Go. Ouvrez Google Cloud Shell en cliquant sur l'icône située dans l'angle supérieur droit de l'écran :

Enfin, définissons la zone par défaut et la configuration du projet à l'aide de Cloud Shell :
$ gcloud config set compute/zone us-central1-b $ gcloud config set compute/region us-central
Vous pouvez également choisir différentes zones. Pour en savoir plus sur les zones, consultez la documentation sur les régions et les zones.
Dans cette section, vous allez créer des instances Compute Engine exécutant nginx+ à l'aide de Cloud Launcher. Nous aurons besoin de ces instances pour illustrer la surveillance et les alertes. Vous pouvez créer une instance Compute Engine à partir de la console graphique ou de la ligne de commande. Cet atelier vous guidera à travers les lignes de commande.
Commençons.
Utilisez gcloud pour définir l'ID de votre projet :
$ gcloud config set project PROJECT_ID
Ensuite, assurez-vous de copier et coller ce qui suit tel quel :
$ for i in {1..3}; do \
gcloud compute instances create "nginx-plus-$i" \
--machine-type "n1-standard-1" \
--metadata "google-cloud-marketplace-solution-key=nginx-public:nginx-plus" \
--maintenance-policy "MIGRATE" --scopes default="https://www.googleapis.com/auth/cloud-platform" \
--tags "http-server","google-cloud-marketplace" \
--image "https://www.googleapis.com/compute/v1/projects/nginx-public/global/images/nginx-plus-ubuntu1404-v20150916-final" \
--boot-disk-size "10" --boot-disk-type "pd-standard" \
--boot-disk-device-name "nginx-plus-$i"; doneDes messages d'avertissement concernant la taille du disque s'affichent, puis le résultat suivant s'affiche à mesure que chaque VM est créée :
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS nginx-plus-1 us-central1-b n1-standard-2 X.X.X.X X.X.X.X RUNNING ...
Notez le EXTERNAL_IP, car vous en aurez besoin plus tard.
Ces opérations peuvent prendre quelques minutes.
Par défaut, Google Cloud Platform n'autorise que l'accès à quelques ports. Comme nous allons bientôt accéder à Nginx, activons le port 80 dans la configuration du pare-feu :
$ gcloud compute firewall-rules create allow-80 --allow tcp:80 --target-tags "http-server" Created [...]. NAME NETWORK SRC_RANGES RULES SRC_TAGS TARGET_TAGS allow-80 default 0.0.0.0/0 tcp:80 http-server
Une règle de pare-feu nommée "allow-80" est alors créée avec les valeurs par défaut suivantes :
- La liste des blocs d'adresses IP autorisés à établir des connexions entrantes (
--source-ranges) est définie sur0.0.0.0/0(Partout). - La liste des tags d'instance indiquant l'ensemble des instances du réseau pouvant accepter les connexions entrantes est définie sur "Aucun", ce qui signifie que la règle de pare-feu s'applique à toutes les instances.
Exécutez gcloud compute firewall-rules create --help pour afficher toutes les valeurs par défaut.
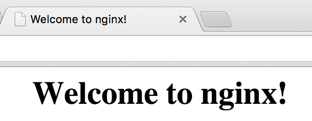
Une fois la première instance créée, vous pouvez tester si nginx est en cours d'exécution et accessible en accédant à http://EXTERNAL_IP/, où EXTERNAL_IP correspond à l'adresse IP publique de nginx-plus-1. La page Nginx devrait s'afficher :
Vous pouvez également afficher vos instances en cours d'exécution en saisissant :
$ gcloud compute instances list
Google Stackdriver est une solution de surveillance puissante qui intègre différents outils pour faciliter la surveillance et l'analyse de vos applications cloud. Vous pouvez utiliser Stackdriver pour afficher les métriques de performances, définir et recevoir des alertes, ajouter vos propres tableaux de bord et métriques personnalisés, afficher les journaux et les traces, et configurer des tableaux de bord intégrés, le tout depuis un emplacement centralisé.
Les étapes suivantes vous guideront pour activer Stackdriver et utiliser la console.
Par défaut, Google Stackdriver est actuellement en version bêta et n'est pas activé pour les nouveaux projets. Pour l'activer, accédez à la barre de navigation de gauche et cliquez sur "Monitoring" (vous devrez peut-être faire défiler la page pour trouver cette option).

Sur l'écran suivant, cliquez sur "Enable Monitoring" (Activer la surveillance) et patientez une minute.

Une fois l'option activée, le contenu change et le texte ci-dessous s'affiche. Cliquez sur "Accéder à la surveillance" pour commencer à explorer. Vous devrez vous connecter avec Google, puis vous serez redirigé vers la console Stackdriver de votre projet. C'est là que vous effectuerez et analyserez les tâches liées à la surveillance.

Familiarisons-nous avec la page d'accueil.

- Menu supérieur : permet de sélectionner différentes vues / contextes et d'accéder à toutes les actions Stackdriver disponibles.
- Tableaux de bord : il s'agit de tableaux de bord des métriques et des événements surveillés. Au départ, il s'agit de tableaux de bord système prédéfinis basés sur les ressources de votre projet, mais vous pouvez également créer vos propres tableaux de bord personnalisés.
- Tests de disponibilité : ils vérifient régulièrement la disponibilité des ressources destinées aux utilisateurs et permettent d'envoyer des alertes lorsque celles-ci deviennent indisponibles.
- Liste des groupes : les groupes permettent de regrouper des ressources qui partagent des propriétés et des caractéristiques afin qu'elles puissent être gérées en tant que groupe ou cluster pour des tâches telles que la surveillance et les alertes. Elles peuvent être détectées automatiquement ou définies par l'utilisateur.
- Volet "Incidents" : ce volet permet de suivre les incidents d'alerte. Aucune information ne s'affichera ici tant que vous n'aurez pas défini de règles d'alerte.
- Journal des événements : liste les événements liés à vos ressources surveillées (par exemple, les modifications d'instance, les événements d'incident, etc.).
Avant d'examiner les graphiques, vous remarquerez que la plupart des lignes se sont aplaties après l'initialisation de l'instance. Voyons si nous pouvons "décompresser" certains d'entre eux en générant une charge sur l'une des instances.
Pour vous connecter à l'instance via SSH à partir de la ligne de commande Cloud Shell :
$ gcloud compute ssh nginx-plus-1 ... Do you want to continue (Y/n)? Y ... Generating public/private rsa key pair. Enter passphrase (empty for no passphrase): [Hit Enter] Enter same passphrase again: [Hit Enter] ... yourusername@nginx-plus-1:~$
C'est tout ! Plutôt simple, non ? (En production, assurez-vous de saisir une phrase secrète :) Notez également qu'il est possible que vous ne soyez pas invité à ajouter une phrase secrète.
Vous pouvez également vous connecter en SSH à l'instance directement depuis la console en accédant à Compute Engine > Instances de VM, puis en cliquant sur SSH.

In the SSH window, type:
yourusername@nginx-plus-1:~$ sudo apt-get install rand
yourusername@nginx-plus-1:~$ for i in {1..10}; do dd if=/dev/zero of=/dev/null count=$(rand -M 80)M; sleep 60; done &Le processeur de l'instance nginx-plus-1 est en cours de chargement. Nous pouvons revenir à l'onglet du tableau de bord Stackdriver et commencer à explorer, mais avant de revenir à la page des tableaux de bord Stackdriver, profitons-en pour installer l'agent Cloud Logging.
Fetch and install the script:
yourusername@nginx-plus-1:~$ curl -sS https://dl.google.com/cloudagents/add-logging-agent-repo.sh | sudo bash /dev/stdin --also-install
Notez que lorsque vous installez dans un environnement de production, veillez à vérifier le hachage SHA-256. Pour en savoir plus sur la procédure d'installation, cliquez ici.
Il est maintenant temps de revenir à la console Google Stackdriver.
Prenez le temps de vous familiariser avec la navigation et l'utilisation des tableaux de bord et des graphiques. Pointez sur les lignes du graphique pour voir ce qui se passe. Modifiez la durée des graphiques (les commandes se trouvent en haut à droite). Vous pouvez toujours revenir à la vue "page d'accueil" en cliquant sur le logo Stackdriver en haut à gauche de la console.
Examinons le graphique de l'utilisation du processeur :

Voici quelques éléments du graphique :
- La ligne en surbrillance correspond à la métrique actuellement sélectionnée (un graphique peut afficher plusieurs métriques).
- La ligne horizontale grise représente le point dans le temps vers lequel pointe le curseur de la souris.
- En bas de l'écran figure le nom de la ressource, ainsi que la valeur au moment sélectionné.
- En haut du graphique se trouvent des points de couleur représentant les événements détaillés dans le journal des événements. Vous pouvez cliquer dessus pour obtenir la liste des événements. Remarque : Si vous n'avez pas encore d'événements, il est possible que vous n'en voyiez aucun.
- En haut à droite du graphique se trouvent trois commandes (de gauche à droite) :
- Afficher/Masquer une liste de métriques sous le graphique
- Activer/Désactiver le mode plein écran
- Menu avec divers éléments (vous DEVEZ essayer le mode Rayons X une fois que vous avez un graphique très verbeux). Notez l'option"Afficher les journaux", nous y reviendrons plus tard.
Les tests de disponibilité vous permettent de vérifier rapidement l'état d'une page Web, d'une instance ou d'un groupe de ressources. Chaque test configuré est régulièrement utilisé dans diverses zones du monde. Les tests de disponibilité peuvent servir de conditions dans les définitions des règles d'alerte.
Pour afficher vos tests et leur état, sélectionnez Alertes > Tests de disponibilité dans le menu supérieur. Vous trouverez également des sections Tests de disponibilité sur le tableau de bord Google Stackdriver et sur les pages consacrées à des ressources spécifiques. Pour les tests de disponibilité qui couvrent un groupe de ressources, vous pouvez développer le test pour afficher l'état des membres individuels du groupe.
Créons un test de disponibilité. Recherchez le widget "Tests de disponibilité" sur l'écran d'accueil Stackdriver :

Un nouveau pop-up s'affiche. Nous pouvons configurer des tests de disponibilité pour une seule ressource ou un groupe de ressources, utiliser des en-têtes et des charges utiles personnalisés, ajouter une authentification et d'autres options. Pour l'instant, nous allons simplement utiliser une vérification http par défaut qui vérifiera le groupe nginx créé automatiquement toutes les minutes.
Utilisez la capture d'écran ci-dessous pour remplir les différentes options :

Cliquez sur le bouton "Tester" pour vous assurer que vos points de terminaison sont accessibles (vous devriez obtenir trois messages de confirmation verts), puis cliquez sur "Enregistrer". Remarque : Si vous ne recevez pas de réponse positive, vous pouvez quand même poursuivre l'atelier, car il peut s'agir d'un problème de timing de vérification du test.
Vous verrez ensuite une boîte de dialogue "Test de disponibilité créé " et vous serez invité à indiquer si vous souhaitez créer une règle d'alerte pour ce test. Nous allons le faire dans la section suivante. Ne cliquez sur rien pour le moment.
Vous pouvez configurer des règles d'alerte pour définir les conditions qui déterminent si vos services et plates-formes cloud fonctionnent normalement. Cloud Monitoring fournit de nombreux types de métriques et de vérifications de l'état que vous pouvez utiliser dans les règles.
Lorsqu'une condition d'une règle d'alerte est enfreinte, un incident est créé et affiché dans la section "Incidents" de la console Stackdriver. Les personnes qui reçoivent la notification peuvent en accuser réception et fermer l'incident une fois qu'il a été résolu.
Cliquez sur "Créer une règle d'alerte" et passons à la configuration de la règle.

L'écran suivant devrait s'afficher :

Saisissez un nom pour la règle : "Test de disponibilité pour le groupe nginx".

Dans la section "Méthode de notification", cliquez sur "Ajouter une notification".

Saisissez l'adresse e-mail associée à votre compte Google Cloud. Faites défiler l'écran jusqu'en bas, puis cliquez sur "Save Policy" (Enregistrer la règle).
Revenez à la page d'accueil Stackdriver (en cliquant sur le logo en haut à gauche).
Le test de disponibilité que vous avez créé devrait maintenant s'afficher dans la section "Tests de disponibilité" du tableau de bord. Pour l'instant, l'état doit être vert.

Faites défiler la page jusqu'au journal des événements. L'événement de création d'une règle d'alerte devrait s'y trouver.
Maintenant, créons quelques problèmes :)
Voyons ce qui se passe lorsque nous arrêtons le service Nginx.
Reconnectez-vous à l'instance via SSH depuis la ligne de commande Cloud Shell :
$ gcloud compute ssh nginx-plus-1
Saisissez ensuite :
yourusername@nginx-plus-1:~$ sudo service nginx stop
Le test de disponibilité que nous avons créé devrait maintenant échouer. Un incident sera alors créé et un e-mail de notification d'alerte sera envoyé à l'adresse que vous avez saisie ci-dessus. La condition mettra une minute à être détectée (n'oubliez pas la durée d'une minute lors de la configuration du test de disponibilité). Examinons donc la page du groupe nginx.
Il existe plusieurs façons d'accéder au tableau de bord d'un groupe de ressources spécifique :
- Vous pouvez cliquer sur le nom du groupe sur la page d'accueil. Vous êtes alors redirigé vers un tableau de bord spécialement conçu pour surveiller les ressources du groupe. Vous pouvez également personnaliser ce tableau de bord.

- Dans le menu de premier niveau, sélectionnez "Groupes", puis recherchez votre groupe.
Cliquez ensuite sur le bouton d'actualisation automatique pour vous assurer que les tableaux de bord sont actualisés automatiquement. L'icône devient rouge.

Vous consultez maintenant un tableau de bord spécifique au groupe nginx créé automatiquement. Sur la droite, vous trouverez des graphiques de plusieurs métriques clés concernant le groupe. En d'autres termes, ces graphiques affichent des métriques liées à toutes les ressources du groupe nginx (les trois VM nginx+ que nous avons créées précédemment).
Sur la gauche, vous trouverez diverses informations sur le groupe :
- État de l'incident
- Tests de disponibilité
- Journal des événements
- Liste de ressources (instances, volumes, etc.)
Notez que ces journaux ne concernent que le groupe. Par conséquent, le journal des événements ne liste que les événements du groupe.
Vous pouvez cliquer sur différentes ressources ou sous-groupes pour accéder à leurs tableaux de bord spécifiques. Par exemple, si vous cliquez sur "nginx-plus-1", vous serez redirigé vers un tableau de bord qui ne contient que des métriques et des vérifications liées à cette instance. Essayez maintenant :

Les incidents Stackdriver sont ouverts lorsqu'un ensemble de conditions d'alerte répond à certains critères. Dans notre cas, nous avons défini une alerte pour le test de disponibilité nginx, qui échoue actuellement sur nginx-plus-1. Les incidents vous aident à suivre les conditions actuelles et à collaborer avec d'autres membres de l'équipe lorsque vous travaillez sur des problèmes.
Confirmons l'incident pour informer les autres membres de l'équipe que nous examinons le problème :

Notez que l'état de l'incident passe de "Ouvert" à "Confirmé". La situation est toujours en cours (les conditions de la règle d'alerte sont toujours enfreintes), mais vous signalez aux membres de l'équipe que vous vous en occupez. Cette action sera également enregistrée dans le journal des événements.
Les incidents peuvent être résolus manuellement ou automatiquement. Pour voir ce dernier, connectez-vous à nginx-plus-1 via SSH et résolvez le problème :
yourusername@nginx-plus-1:~$ sudo service nginx start
L'incident sera désormais résolu automatiquement une fois que le contrôle du temps d'activité reviendra à la normale. Vous pouvez également résoudre le problème vous-même en sélectionnant l'élément de menu "Résoudre".
Cloud Logging est une solution de journalisation en tant que service qui offre un emplacement central pratique pour afficher et interroger les journaux provenant de plusieurs sources. Vous pouvez également utiliser les journaux pour les exporter vers d'autres destinations (Google Cloud Storage, Google BigQuery ou Google Cloud Pub/Sub).
Pour accéder à la visionneuse de journaux Cloud, sélectionnez-la dans le menu de gauche de la console Cloud :

Vous serez redirigé vers le lecteur de journaux, où vous pourrez utiliser des requêtes prédéfinies, ou créer et enregistrer vos propres requêtes personnalisées. Vous pourrez également obtenir un flux en direct des journaux provenant de plusieurs ressources de votre déploiement cloud, créer des métriques à partir des journaux, exporter des données et bien plus encore.
Des commandes pratiques vous permettent de filtrer rapidement les informations pertinentes :

- Filtrer par types de ressources
- Filtrer les types de journaux spécifiques des ressources sélectionnées
- Filtrer des niveaux de journaux spécifiques
- Filtrer sur une ou plusieurs dates spécifiques pour examiner les problèmes passés
- Activer/Désactiver le streaming continu
- Champ de recherche pour le texte, les libellés ou les expressions régulières
Entraînons-nous maintenant à affiner la recherche pour trouver des journaux spécifiques.
Dans le sélecteur de type de ressource (1 dans la capture d'écran), sélectionnez Compute Engine > Tous les types de ressources.
Ensuite, dans le sélecteur de type de journal (2 dans la capture d'écran), sélectionnez "nginx-access" pour afficher tous les journaux d'accès.
Activez ensuite le streaming continu (5) pour afficher les journaux au fur et à mesure de leur arrivée. Si aucun nouveau journal n'apparaît, essayez de saisir l'adresse IP externe de l'une des VM nginx-plus dans votre navigateur.
Bien que cet atelier de programmation ne se concentre pas en détail sur les journaux, n'hésitez pas à les explorer plus tard avant de faire le ménage. Pour en savoir plus sur la navigation dans le lecteur, cliquez ici. Pour obtenir des informations plus générales sur les utilisations de Cloud Logging, consultez le répertoire de premier niveau de la documentation correspondante ici.
Libérons les ressources de calcul créées pendant l'atelier de programmation. Exécutez les commandes suivantes dans Cloud Shell :
$ for i in {1..3}; do \
gcloud -q --user-output-enabled=false compute instances delete nginx-plus-$i ; doneEnsuite, accédez à la console Google Stackdriver ("Surveillance" dans le menu du panneau de gauche de la console Cloud) et supprimez le test de disponibilité et les règles d'alerte que nous avons créés. Pour ce faire, vous pouvez utiliser les éléments de menu de premier niveau "Alertes > Présentation des règles" et "Alertes > Tests de disponibilité".
Vous êtes maintenant prêt à surveiller vos applications basées sur le cloud.
Points abordés
- Familiarisez-vous avec la page d'accueil Stackdriver.
- Comprendre les tableaux de bord et les graphiques
- Créer un test de disponibilité
- Créer une règle d'alerte simple
- Utiliser les incidents d'alerte
- Naviguer dans la visionneuse de journaux.
Étapes suivantes
- Essayez de créer un tableau de bord personnalisé.
- Découvrez les différentes options disponibles lorsque vous créez une règle d'alerte.
- Découvrez les différentes options disponibles lorsque vous utilisez Cloud Logging.
En savoir plus
- En savoir plus sur l'utilisation de l'API Monitoring
- Utilisez des métriques personnalisées.
Votre avis nous intéresse !
- Veuillez prendre quelques instants pour répondre à notre courte enquête.