
La API de Cloud Natural Language te permite extraer entidades de textos, realizar análisis de opiniones y sintácticos, y clasificar texto en categorías.
En este lab, aprenderá a usar la API de Natural Language para analizar entidades, opiniones y sintaxis.
Qué aprenderás
- Cómo crear una solicitud a la API de Natural Language y llamar a la API con curl
- Cómo extraer entidades y ejecutar un análisis de opiniones en texto con la API de Natural Language
- Cómo realizar un análisis lingüístico de un texto con la API de Natural Language
- Cómo crear una solicitud a la API de Natural Language en un idioma diferente
Qué necesitarás
¿Cómo usarás este instructivo?
¿Cómo calificarías tu experiencia con Google Cloud Platform?
Configuración del entorno de autoaprendizaje
Si aún no tienes una Cuenta de Google (Gmail o Google Apps), debes crear una. Accede a Google Cloud Platform Console (console.cloud.google.com) y crea un proyecto nuevo:



Recuerde el ID de proyecto, un nombre único en todos los proyectos de Google Cloud (el nombre anterior ya se encuentra en uso y no lo podrá usar). Se mencionará más adelante en este codelab como PROJECT_ID.
A continuación, deberás habilitar la facturación en la consola de Cloud para usar los recursos de Google Cloud.
Ejecutar este codelab debería costar solo unos pocos dólares, pero su costo podría aumentar si decides usar más recursos o si los dejas en ejecución (consulta la sección “Limpiar” al final de este documento).
Los usuarios nuevos de Google Cloud Platform son aptos para obtener una prueba gratuita de USD 300.
Haz clic en el ícono de menú ubicado en la parte superior izquierda de la pantalla.

Selecciona APIs & services en el menú desplegable y haz clic en Panel.
Haz clic en Habilitar APIs y servicios.
Luego, escribe "language" en el cuadro de búsqueda. Haz clic en Google Cloud Natural Language API:
Haga clic en Habilitar para habilitarla:
Espera unos segundos para que se habilite. Verás este mensaje cuando se habilite:

Google Cloud Shell es un entorno de línea de comandos que se ejecuta en la nube. Esta máquina virtual basada en Debian está cargada con todas las herramientas de desarrollo que necesitarás (gcloud, bq, git y otras) y ofrece un directorio principal persistente de 5 GB. Usaremos Cloud Shell para crear nuestra solicitud a la API de Natural Language.
Para comenzar a usar Cloud Shell, haz clic en el ícono "Activar Google Cloud Shell"  en la esquina superior derecha de la barra de encabezado.
en la esquina superior derecha de la barra de encabezado.

Se abrirá una sesión de Cloud Shell en un marco nuevo en la parte inferior de la consola, que mostrará una línea de comandos. Espera hasta que aparezca el mensaje user@project:~$
Dado que usaremos curl para enviar una solicitud a la API de Natural Language, tendremos que generar una clave de API para pasar la URL de nuestra solicitud. Para crear una clave de API, navega a la sección Credenciales de APIs y servicios en Cloud Console:
En el menú desplegable, selecciona Clave de API:
A continuación, copia la clave generada. Necesitarás esta clave más adelante en el lab.
Ahora que tienes una clave de API, guárdala en una variable de entorno para no tener que ingresar el valor de la clave de API en cada solicitud. Puedes hacer esto en Cloud Shell. Asegúrate de reemplazar <your_api_key> por la clave que acabas de copiar.
export API_KEY=<YOUR_API_KEY>El primer método de la API de Natural Language que usaremos es analyzeEntities. Con este método, la API puede extraer entidades (como personas, lugares y eventos) del texto. Para probar el análisis de entidades de la API, usaremos la siguiente oración:
Joanne Rowling, quien escribe bajo el seudónimo J. K. Rowling y Robert Galbraith, es una novelista y guionista británica que escribió la saga de fantasía Harry Potter.
Compilaremos nuestra solicitud a la API de Natural Language en un archivo request.json. En tu entorno de Cloud Shell, crea el archivo request.json con el siguiente código. Puedes crear el archivo con uno de tus editores de línea de comandos preferidos (nano, vim, emacs) o usar el editor integrado Orion en Cloud Shell:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
}En la solicitud, le indicamos a la API de Natural Language sobre el texto que enviaremos. Los valores de tipo admitidos son PLAIN_TEXT o HTML. En "content", pasamos el texto que enviaremos a la API de Natural Language para el análisis. La API de Natural Language también admite el envío de archivos almacenados en Cloud Storage para el procesamiento de texto. Si quisiéramos enviar un archivo desde Cloud Storage, reemplazaríamos content por gcsContentUri y le asignaríamos el valor del URI de nuestro archivo de texto en Cloud Storage. encodingType informa a la API qué tipo de codificación de texto se debe utilizar cuando procesa el texto. La API utilizará esa información para calcular en qué parte de nuestro texto aparecerán entidades específicas.
Ahora puedes pasar el cuerpo de tu solicitud, junto con la variable de entorno de la clave de API que guardaste anteriormente, a la API de Natural Language con el siguiente comando curl (todo en una sola línea de comandos):
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonEl comienzo de tu respuesta debería verse de la siguiente manera:
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
}Para cada entidad de la respuesta, obtenemos la entidad type, la URL de Wikipedia asociada (si existe), el valor de salience y los índices que indican dónde aparece esta entidad en el texto. El valor de salience es un número del rango [0,1] que indica la centralidad de la entidad en el texto completo. La API de Natural Language también puede reconocer la misma entidad mencionada de diferentes maneras. Observa la lista mentions en la respuesta: la API puede indicar que "Joanne Rowling", "Rowling", "novelista" y "Robert Galbriath" corresponden a lo mismo.
Además de extraer entidades, la API de Natural Language te permite realizar el análisis de opiniones de un bloque de texto. Nuestra solicitud JSON incluirá los mismos parámetros que la solicitud anterior, pero, en este caso, cambiaremos el texto para incluir algo con opiniones más sólidas. Reemplaza tu archivo request.json por el siguiente código y siéntete libre de reemplazar las frases de content por tu propio texto:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
}Luego, enviaremos la solicitud al extremo analyzeSentiment de la API:
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
La respuesta debería verse de la siguiente manera:
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
}Ten en cuenta que obtienes dos tipos de valores de opiniones: opiniones para el documento completo y opiniones por cada oración. El método de opiniones devuelve dos valores: score y magnitude. score es un número entre -1.0 y 1.0 que indica qué tan positivo o negativo es el enunciado. magnitude es un número de 0 a infinito que representa el peso de las opiniones expresadas en el enunciado, independientemente de que sea positivo o negativo. Los bloques de textos más largos con enunciados de mucho peso tienen valores de mayor magnitud. La puntuación de la primera oración es positiva (0.7), mientras que la puntuación de la segunda es neutral (0.1).
Además de proporcionar detalles de opiniones sobre el documento de texto completo que enviamos a la API de NL, también puede desglosar opiniones por las entidades en nuestro texto. Usemos esta oración como ejemplo:
Me gustó el sushi, pero el servicio fue terrible.
En este caso, obtener una puntuación de opiniones para toda la oración, como lo hicimos anteriormente, podría no ser tan útil. Si se tratara de una opinión de un restaurante y hubiera cientos de opiniones para el mismo restaurante, querríamos saber exactamente qué aspectos les gustaron o no a las personas en sus opiniones. Afortunadamente, la API de NL tiene un método que nos permite obtener la opinión de cada entidad en nuestro texto, llamado analyzeEntitySentiment. Actualiza tu request.json con la oración anterior para probarlo:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
}Luego, llama al extremo analyzeEntitySentiment con el siguiente comando curl:
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
En la respuesta, obtendremos dos objetos de entidad: uno para "sushi" y otro para "servicio". Esta es la respuesta completa de JSON:
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
Podemos ver que la puntuación devuelta para "sushi" fue de 0.9, mientras que la de "servicio" fue de -0.9. Genial. También puedes observar que se muestran dos objetos de opiniones para cada entidad. Si cualquiera de estos términos se mencionara más de una vez, la API mostraría una puntuación y una magnitud de opiniones diferentes para cada mención, junto con una opinión agregada para la entidad.
Cuando analicemos el tercer método de la API de Natural Language, anotación de sintaxis, profundizaremos en los detalles lingüísticos de nuestro texto. analyzeSyntax es un método que proporciona un conjunto completo de detalles sobre los elementos semánticos y sintácticos del texto. Para cada palabra en el texto, la API nos indicará la categoría gramatical (sustantivo, verbo, adjetivo, etc.) y cómo se relaciona con otras palabras en la oración (¿Es el verbo raíz? ¿es un modificador?).
Probemos con una oración simple. Nuestra solicitud JSON será similar a las anteriores, pero se agrega una clave de atributos. Esto indicará a la API que queremos realizar una anotación sintáctica. Reemplaza tu request.json por el siguiente código:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}Luego, llama al método analyzeSyntax de la API:
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonLa respuesta debería mostrar un objeto como el siguiente para cada token de la oración. Aquí veremos la respuesta para la palabra "usos":
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}Desglosemos la respuesta. partOfSpeech nos brinda detalles lingüísticos sobre cada palabra (muchos son desconocidos, ya que no se aplican al inglés ni a esta palabra específica). tag indica la parte del discurso de esta palabra, en este caso, un verbo. También obtenemos detalles sobre el tiempo verbal, la modalidad y si la palabra es singular o plural. lemma es la forma canónica de la palabra (para "usos", es "uso"). Por ejemplo, las palabras ejecutar, ejecuta, ejecutó y ejecutando pertenecen al lema ejecutar. El valor de lemma es útil para hacer el seguimiento de los casos en que una palabra está presente en un fragmento de texto grande a lo largo del tiempo.
dependencyEdge incluye datos que puedes usar para crear un árbol de análisis de dependencia del texto. Este es un diagrama que muestra cómo se relacionan las palabras en una oración. Un árbol de análisis de dependencia de la oración anterior debería ser de la siguiente manera:
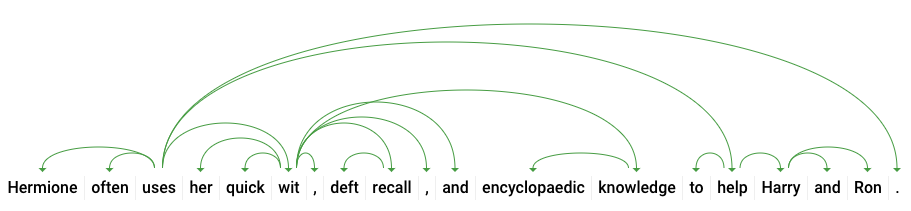
El headTokenIndex en nuestra respuesta anterior es el índice del token que tiene un arco que apunta a "usa". Podemos pensar cada token en la oración como una palabra en un arreglo, y el headTokenIndex de 2 para "uses" se refiere a la palabra "often", a la que está conectada en el árbol.
La API de Natural Language también admite otros idiomas además del inglés (la lista completa se encuentra aquí). Probemos la siguiente solicitud de entidad con una oración en japonés:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}Ten en cuenta que no le indicamos a la API en qué idioma está nuestro texto, pero no te preocupes: ya está programada para detectarlo automáticamente. Luego, lo enviaremos al extremo analyzeEntities:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonY aquí están las dos primeras entidades de nuestra respuesta:
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}La API extrae Japón como ubicación y Google como organización, junto con las páginas de Wikipedia de cada uno.
Aprendió cómo realizar un análisis de texto con la API de Cloud Natural Language mediante la extracción de entidades, el análisis de opiniones y la creación de anotaciones sintácticas.
Temas abordados
- Cómo crear una solicitud a la API de Natural Language y llamar a la API con curl
- Cómo extraer entidades y ejecutar un análisis de opiniones en texto con la API de Natural Language
- Cómo realizar un análisis lingüístico de un texto para crear árboles de análisis de dependencia
- Cómo crear una solicitud en japonés a la API de Natural Language
Próximos pasos
- Consulta los instructivos de la API de Natural Language en la documentación.
- Prueba la API de Vision y la API de Speech.