
Mit der Cloud Natural Language API können Sie Entitäten aus Text extrahieren, Text klassifizieren, d. h. Kategorien zuordnen, sowie Sentiment- und Syntaxanalysen erstellen.
In diesem Lab erfahren Sie, wie Sie mit der Natural Language API Entitäten, Stimmungen und die Syntax analysieren.
Lerninhalte
- Natural Language API-Anfrage erstellen und die API mit "curl" aufrufen
- Mit der Natural Language API Entitäten extrahieren und eine Sentimentanalyse für einen Text durchführen
- Sprachliche Analyse des Textes mit der Natural Language API durchführen
- Natural Language API-Anfrage in einer anderen Sprache erstellen
Voraussetzungen
Wie werden Sie diese Anleitung verwenden?
Wie würden Sie Ihre Erfahrung mit der Google Cloud Platform bewerten?
Einrichtung der Umgebung im eigenen Tempo
Wenn Sie noch kein Google-Konto (Gmail oder Google Apps) haben, müssen Sie eins erstellen. Melden Sie sich in der Google Cloud Platform Console (console.cloud.google.com) an und erstellen Sie ein neues Projekt:



Notieren Sie sich die Projekt-ID, also den projektübergreifend nur einmal vorkommenden Namen eines Google Cloud-Projekts. Der oben angegebene Name ist bereits vergeben und kann leider nicht mehr verwendet werden. Sie wird in diesem Codelab später als PROJECT_ID bezeichnet.
Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Google Cloud-Ressourcen verwenden zu können.
Dieses Codelab sollte Sie nicht mehr als ein paar Dollar kosten, aber es könnte mehr sein, wenn Sie sich für mehr Ressourcen entscheiden oder wenn Sie sie laufen lassen (siehe Abschnitt „Bereinigen“ am Ende dieses Dokuments).
Neuen Nutzern der Google Cloud Platform steht eine kostenlose Testversion mit einem Guthaben von 300$ zur Verfügung.
Klicken Sie auf das Menüsymbol oben links auf dem Bildschirm.

Wählen Sie im Drop-down-Menü APIs & Services (APIs & Dienste) aus und klicken Sie auf „Dashboard“.
Klicken Sie auf APIs und Dienste aktivieren.
Geben Sie dann in das Suchfeld "language" ein. Klicken Sie auf Google Cloud Natural Language API:
Klicken Sie darauf, um die Cloud Natural Language API zu aktivieren:
Es dauert einige Sekunden, bis die Funktion aktiviert ist. So sieht es aus, wenn die Funktion aktiviert ist:

Google Cloud Shell ist eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird. Auf dieser Debian-basierten virtuellen Maschine sind alle erforderlichen Entwicklungstools (gcloud, bq, git usw.) installiert und sie stellt ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher zur Verfügung. Wir verwenden Cloud Shell, um unsere Anfrage an die Natural Language API zu erstellen.
Klicken Sie zum Starten von Cloud Shell rechts oben in der Kopfzeile auf das Symbol „Google Cloud Shell aktivieren“  .
.

Im unteren Bereich der Konsole wird ein neuer Frame für die Cloud Shell-Sitzung geöffnet, in dem eine Befehlszeilen-Eingabeaufforderung angezeigt wird. Warten Sie, bis die Eingabeaufforderung „user@project:~$“ angezeigt wird.
Da Sie mit curl eine Anfrage an die Natural Language API senden, müssen Sie einen API-Schlüssel generieren, mit dem die Anfrage-URL übergeben wird. Gehen Sie dazu in der Cloud Console zu „APIs & Dienste“ > „Anmeldedaten“:
Wählen Sie im Drop-down-Menü API key (API-Schlüssel) aus:
Kopieren Sie den gerade generierten Schlüssel. Sie benötigen diesen Schlüssel später im Lab.
Speichern Sie nun den API-Schlüssel in einer Umgebungsvariablen. So brauchen Sie den Wert des API-Schlüssels nicht in jede Anfrage einzufügen. Das können Sie in Cloud Shell tun. Ersetzen Sie <your_api_key> durch den gerade kopierten Schlüssel.
export API_KEY=<YOUR_API_KEY>Die erste Methode der Natural Language API, die wir verwenden, ist analyzeEntities. Damit kann die API Entitäten (wie Personen, Orte und Ereignisse) aus Text extrahieren. Für die Entitätenanalyse der API verwenden wir folgenden Satz:
Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series.
Wir erstellen unsere Anfrage an die Natural Language API in einer request.json-Datei. Erstellen Sie in Ihrer Cloud Shell-Umgebung die Datei request.json mit dem folgenden Code. Sie können die Datei entweder mit Ihrem bevorzugten Befehlszeileneditor (nano, vim, emacs) oder mit dem in Cloud Shell integrierten Orion-Editor erstellen:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
}In der Anfrage teilen wir der Natural Language API Informationen zu dem von uns gesendeten Text mit. Unterstützte Werte sind PLAIN_TEXT oder HTML. Unter "content" übergeben Sie den Text, der zur Analyse an die Natural Language API gesendet werden soll. Die Natural Language API unterstützt auch das Senden von Dateien aus Cloud Storage zur Textverarbeitung. Wenn wir eine Datei aus Cloud Storage senden möchten, ersetzen wir content durch gcsContentUri und verwenden den Wert des URI der Textdatei in Cloud Storage. encodingType teilt der API mit, welche Art von Textcodierung bei der Verarbeitung des Textes verwendet werden soll. Die API berechnet damit die Position bestimmter Entitäten im Text.
Mit dem folgenden curl-Befehl können Sie nun den Anfragetext zusammen mit der zuvor gespeicherten Umgebungsvariablen mit dem API-Schlüssel an die Natural Language API übergeben. Platzieren Sie dabei alle Elemente in der gleichen Befehlszeile:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonDer Anfang der Antwort sollte folgendermaßen aussehen:
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
}Zu jeder Entität in der Antwort erhalten Sie den Entitätstyp (type), die zugehörige Wikipedia-URL (falls vorhanden), den Auffälligkeitswert (salience) und die Indizes darüber, wo diese Entität im Text zu finden ist. Die Salienz ist eine Zahl im Bereich [0,1], die sich auf die Zentralität der Entität im gesamten Dokumenttext bezieht. Die Natural Language API kann außerdem dieselbe Entität auf unterschiedliche Weisen erkennen. Sehen Sie sich die Liste mentions in der Antwort an: Die API erkennt, dass sich „Joanne Rowling“, „Rowling“, „Schriftstellerin“ und „Robert Galbriath“ auf dieselbe Person beziehen.
Mit der Natural Language API können Sie nicht nur Entitäten extrahieren, sondern auch eine Sentimentanalyse für einen Textblock machen. Die JSON-Anfrage enthält in diesem Fall dieselben Parameter wie die obige Anfrage, jedoch ändern wir jetzt den Text, indem wir Elemente aufnehmen, die auf eine intensivere Stimmung hindeuten. Ersetzen Sie Ihre request.json-Datei durch Folgendes und fügen Sie hinter content Ihren eigenen Text ein:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
}Als Nächstes senden wir die Anfrage an den Endpunkt analyzeSentiment der API:
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Die Antwort sollte folgendermaßen aussehen:
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
}Sie sehen, dass die Antwort zwei Arten von „sentiment“-Werten enthält: einen für das gesamte Dokument und einen für jeden einzelnen Satz. Die Sentimentanalyse gibt zwei Werte zurück: score und magnitude. score ist eine Zahl zwischen -1,0 und 1,0, die angibt, wie positiv oder negativ die Aussage ist. magnitude ist eine Zahl im Bereich 0 bis unendlich, die das Gewicht der zum Ausdruck gebrachten Stimmung angibt, unabhängig davon, ob die Aussage positiv oder negativ ist. Längere Textblöcke mit stark gewichteten Aussagen haben höhere "magnitude"-Werte. Der Wert für den ersten Satz ist positiv (0,7), während der Wert für den zweiten Satz neutral ist (0,1).
Die Natural Language API liefert nicht nur Informationen über die Stimmung im gesamten Textdokument, das wir an die NL API senden, sondern kann die Stimmung auch nach Entitäten im Text aufschlüsseln. Sehen Sie sich diesen Beispielsatz an:
I liked the sushi but the service was terrible.
In diesem Fall liefert eine Sentimentanalyse für den gesamten Satz, so wie sie oben durchgeführt wurde, keine aussagekräftigen Ergebnisse. Wenn dies eine Restaurantbewertung wäre und es Hunderte von Bewertungen für dasselbe Restaurant gäbe, würden wir wissen wollen, was genau den Kunden gefallen hat und was nicht. Glücklicherweise verfügt die Natural Language API über die Methode analyzeEntitySentiment, mit der wir die Stimmung für jede Entität im Text ermitteln können. Fügen Sie den obigen Satz in die Datei „request.json“ ein, um die Funktion auszuprobieren:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
}Rufen Sie dann den Endpunkt analyzeEntitySentiment mit dem folgenden curl-Befehl auf:
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Die Antwort enthält zwei Entitätenobjekte: eines für „sushi“ und eines für „service“. Hier die vollständige JSON-Antwort:
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
Wir sehen, dass der zurückgegebene Wert für „sushi“ 0,9 beträgt, der für „service“ dagegen -0,9. Nicht schlecht, oder? Sie stellen auch fest, dass für jede Entität zwei "sentiment"-Objekte ausgegeben werden. Wenn einer dieser Begriffe mehr als einmal vorkommen würde, würde die API bei jeder Erwähnung einen anderen Wert für "sentiment" und "magnitude" sowie einen aggregierten "sentiment"-Wert für die Entität ausgeben.
Mit der dritten Methode der Natural Language API – der Syntaxanmerkung – lassen sich die sprachlichen Details eines Textes noch genauer analysieren. analyzeSyntax ist eine Methode, die detaillierte Informationen zu den semantischen und syntaktischen Elementen des Textes liefert. Für jedes Wort im Text ermittelt die API die Wortart (Substantiv, Verb, Adjektiv) und in welcher Beziehung es zu anderen Wörtern im Satz steht (Ist es das Vollverb? Ein Attribut?).
Probieren Sie es mit einem einfachen Satz aus. Unsere JSON-Anfrage ähnelt den vorherigen Anfragen, enthält jedoch einen zusätzlichen Funktionsschlüssel. Daran erkennt die API, dass Sie eine Syntaxannotation durchführen möchten. Ersetzen Sie „request.json“ durch Folgendes:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}Rufen Sie dann die Methode analyzeSyntax der API auf:
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonIn der Antwort sollte ein Objekt wie das Folgende für jedes Token im Satz zurückgegeben werden. Sehen wir uns die Antwort für das Wort „verwendet“ an:
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}Schlüsseln wir nun die Antwort auf. partOfSpeech liefert uns sprachliche Details zu jedem Wort. Viele sind unbekannt, da sie nicht auf Englisch oder dieses bestimmte Wort zutreffen. tag gibt die Wortart dieses Wortes an, in diesem Fall ein Verb. Außerdem erhalten wir Informationen zur Zeitform, Modalität und dazu, ob das Wort im Singular oder Plural steht. lemma ist die kanonische Form des Wortes (für „verwendet“ ist es „verwenden“). Zum Beispiel haben die Wörter laufen, läuft, lief und laufend alle das Lemma laufen. Der "lemma"-Wert ist hilfreich, um zu ermitteln, wie häufig ein Wort in einem langen Textabschnitt vorkommt.
dependencyEdge enthält Daten, mit denen Sie einen Abhängigkeitsparsebaum des Textes erstellen können. Dabei handelt es sich um ein Diagramm, in dem dargestellt wird, in welcher Beziehung Wörter in einem Satz zueinander stehen. Ein Abhängigkeitsparsebaum für den obigen Satz würde folgendermaßen aussehen:
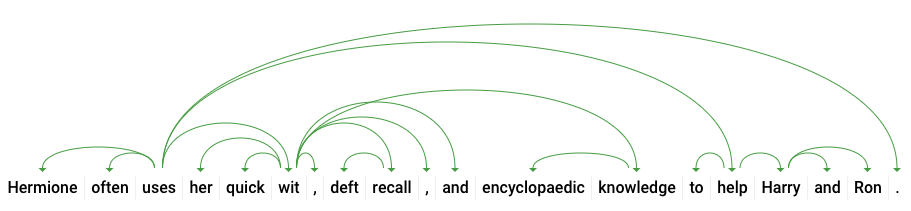
Die headTokenIndex in unserer Antwort oben ist der Index des Tokens, das auf „verwendet“ verweist. Wir können uns jedes Token im Satz als Wort in einem Array vorstellen. Der Wert headTokenIndex von 2 für „verwendet“ bezieht sich auf das Wort „häufig“, mit dem es im Baum verbunden ist.
Die Natural Language API unterstützt neben Englisch auch andere Sprachen. Wir versuchen es mit der folgenden Entitätsanfrage mit einem Satz auf Japanisch:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}Wir haben nicht mitgeteilt, in welcher Sprache der Text vorliegt. Die API erkennt das automatisch. Als Nächstes senden wir das Ganze an den Endpunkt analyzeEntities:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonHier sind die ersten beiden Einheiten in unserer Antwort:
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}Die API extrahiert „Japan“ als Standort und „Google“ als Organisation sowie die Wikipedia-Seiten für beide.
Sie haben gelernt, wie Sie mit der Cloud Natural Language API eine Textanalyse durchführen, indem Sie Entitäten extrahieren, die Stimmung analysieren und Syntaxannotationen platzieren.
Behandelte Themen
- Natural Language API-Anfrage erstellen und die API mit "curl" aufrufen
- mit der Natural Language API Entitäten extrahiert und eine Sentimentanalyse für einen Text durchgeführt,
- eine sprachliche Analyse des Textes durchgeführt, um Abhängigkeitsparsebäume zu erstellen,
- Eine Natural Language API-Anfrage auf Japanisch senden
Nächste Schritte
- Natural Language API-Anleitungen in der Dokumentation
- Vision API und Speech API testen