
Dataflow es un modelo de programación unificado y un servicio administrado para el desarrollo y la ejecución de una amplia variedad de patrones de procesamiento de datos, como ETL, cálculos por lote y cálculos continuos. Como Dataflow es un servicio administrado, puede designar recursos a pedido para minimizar la latencia y mantener una alta eficiencia de uso.
El modelo de Dataflow combina el procesamiento de transmisión y por lotes, de modo que los desarrolladores no tengan que hacer concesiones en términos de corrección, costo o tiempo de procesamiento. En este codelab, aprenderás a ejecutar una canalización de Dataflow que cuenta las ocurrencias de palabras únicas en un archivo de texto.
Este instructivo se adaptó de https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-maven
Qué aprenderás
- Cómo crear un proyecto de Maven con el SDK de Cloud Dataflow
- Cómo ejecutar una canalización de ejemplo con Google Cloud Platform Console
- Cómo borrar el bucket de Cloud Storage asociado y sus contenidos
Requisitos
¿Cómo usarás este instructivo?
¿Cómo calificarías tu experiencia con el uso de los servicios de Google Cloud Platform?
Configuración del entorno de autoaprendizaje
Si aún no tienes una Cuenta de Google (Gmail o Google Apps), debes crear una. Accede a Google Cloud Platform Console (console.cloud.google.com) y crea un proyecto nuevo:



Recuerde el ID de proyecto, un nombre único en todos los proyectos de Google Cloud (el nombre anterior ya se encuentra en uso y no lo podrá usar). Se mencionará más adelante en este codelab como PROJECT_ID.
A continuación, deberás habilitar la facturación en la consola de Cloud para usar los recursos de Google Cloud.
Ejecutar este codelab debería costar solo unos pocos dólares, pero su costo podría aumentar si decides usar más recursos o si los dejas en ejecución (consulta la sección “Limpiar” al final de este documento).
Los usuarios nuevos de Google Cloud Platform son aptos para obtener una prueba gratuita de USD 300.
Habilitar las API
Haz clic en el ícono de menú ubicado en la parte superior izquierda de la pantalla.

Selecciona API Manager en el menú desplegable.

Busque "Google Compute Engine" en el cuadro de búsqueda. En la lista de resultados que aparece, haz clic en "API de Google Compute Engine".
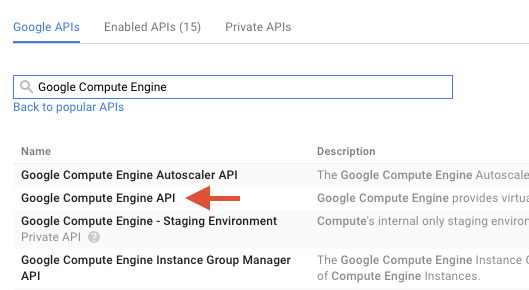
En la página de Google Compute Engine, haz clic en Habilitar.
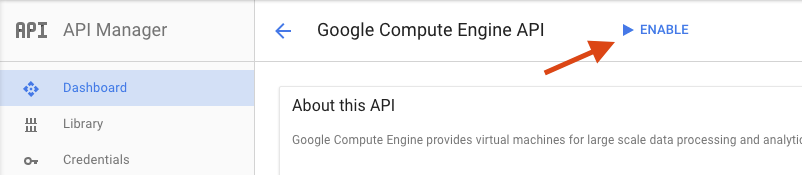
Una vez habilitada, haz clic en la flecha para volver.
Ahora busca las siguientes APIs y habilítalas también:
- API de Google Dataflow
- API de Stackdriver Logging
- Google Cloud Storage
- API de Google Cloud Storage JSON
- API de BigQuery
- API de Google Cloud Pub/Sub
- API de Google Cloud Datastore
En Google Cloud Platform Console, haz clic en el ícono de menú en la parte superior izquierda de la pantalla:
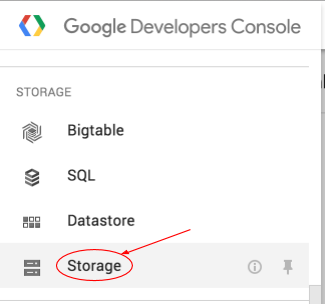
Desplázate hacia abajo y selecciona Cloud Storage en la subsección Almacenamiento:
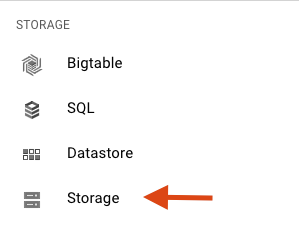
Ahora deberías ver el Explorador de Cloud Storage y, si usas un proyecto que actualmente no tiene ningún bucket de Cloud Storage, verás un cuadro de diálogo que te invita a crear uno nuevo:
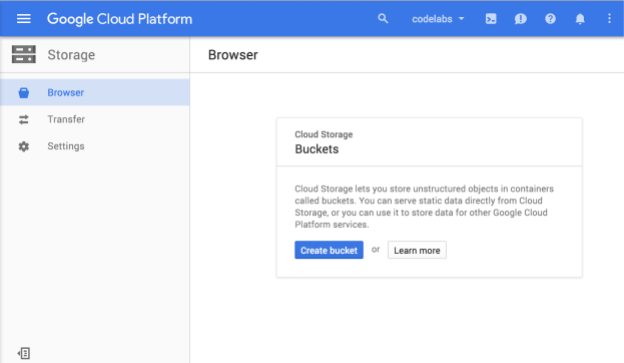
Presiona el botón Crear bucket para crear uno:
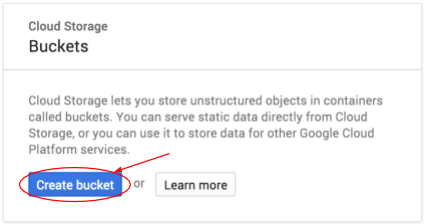
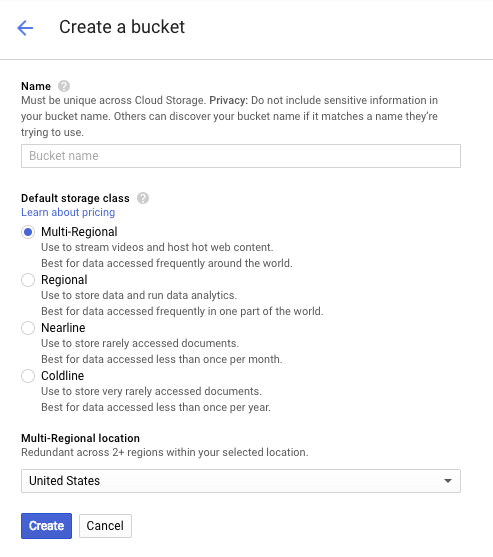
Ingresa un nombre para tu bucket. Como se indica en el cuadro de diálogo, los nombres de los buckets deben ser únicos en todo Cloud Storage. Por lo tanto, si eliges un nombre obvio, como "prueba", es probable que otra persona ya haya creado un bucket con ese nombre y recibas un error.
También hay algunas reglas sobre los caracteres permitidos en los nombres de buckets. Si comienzas y terminas el nombre de tu bucket con una letra o un número, y solo usas guiones en el medio, no tendrás problemas. Si intentas usar caracteres especiales o comenzar o terminar el nombre del bucket con algo que no sea una letra o un número, el cuadro de diálogo te recordará las reglas.
Ingresa un nombre único para tu bucket y presiona Crear. Si eliges algo que ya está en uso, verás el mensaje de error que se muestra arriba. Cuando crees un bucket correctamente, se te redirigirá a tu nuevo bucket vacío en el navegador:
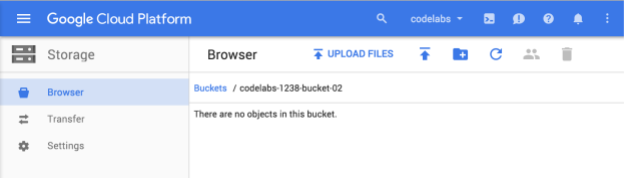
Por supuesto, el nombre del bucket que verás será diferente, ya que debe ser único en todos los proyectos.
Activa Google Cloud Shell
En GCP Console, haga clic en el ícono de Cloud Shell en la barra de herramientas superior derecha:

Haga clic en "Start Cloud Shell":

El aprovisionamiento y la conexión al entorno debería llevar solo unos minutos:

Esta máquina virtual está cargada con todas las herramientas para desarrolladores que necesitará. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Gran parte de su trabajo, si no todo, se puede hacer simplemente con un navegador o su Google Chromebook.
Una vez que te conectes a Cloud Shell, deberías ver que ya te autenticaste y que el proyecto ya se configuró con tu PROJECT_ID.
En Cloud Shell, ejecuta el siguiente comando para confirmar que tienes la autenticación:
gcloud auth list
Resultado del comando
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Resultado del comando
[core] project = <PROJECT_ID>
De lo contrario, puedes configurarlo con el siguiente comando:
gcloud config set project <PROJECT_ID>
Resultado del comando
Updated property [core/project].
Después de que se inicie Cloud Shell, comencemos por crear un proyecto de Maven que contenga el SDK de Cloud Dataflow para Java.
Ejecuta el comando mvn archetype:generate en tu shell de la siguiente manera:
mvn archetype:generate \
-DarchetypeArtifactId=google-cloud-dataflow-java-archetypes-examples \
-DarchetypeGroupId=com.google.cloud.dataflow \
-DarchetypeVersion=1.9.0 \
-DgroupId=com.example \
-DartifactId=first-dataflow \
-Dversion="0.1" \
-DinteractiveMode=false \
-Dpackage=com.exampleDespués de ejecutar el comando, deberías ver un directorio nuevo llamado first-dataflow en tu directorio actual. first-dataflow contiene un proyecto de Maven que incluye el SDK de Cloud Dataflow para Java y canalizaciones de ejemplo.
Comencemos por guardar el ID del proyecto y los nombres de los buckets de Cloud Storage como variables de entorno. Puedes hacer esto en Cloud Shell. Asegúrate de reemplazar <your_project_id> por el ID de tu proyecto.
export PROJECT_ID=<your_project_id>Ahora haremos lo mismo con el bucket de Cloud Storage. Recuerda reemplazar <your_bucket_name> por el nombre único que usaste para crear tu bucket en un paso anterior.
export BUCKET_NAME=<your_bucket_name>Cambia al directorio first-dataflow/.
cd first-dataflowA continuación, ejecutaremos una canalización denominada WordCount, que lee texto, convierte las líneas de texto en tokens de palabras individuales y cuenta la frecuencia con la que aparece cada una. Primero, ejecutaremos la canalización y, mientras se ejecuta, analizaremos lo que sucede en cada paso.
Para iniciar la canalización, ejecuta el comando mvn compile exec:java en el shell o la ventana de la terminal. Para los argumentos --project, --stagingLocation, y --output, el siguiente comando hace referencia a las variables de entorno que configuraste anteriormente en este paso.
mvn compile exec:java \
-Dexec.mainClass=com.example.WordCount \
-Dexec.args="--project=${PROJECT_ID} \
--stagingLocation=gs://${BUCKET_NAME}/staging/ \
--output=gs://${BUCKET_NAME}/output \
--runner=BlockingDataflowPipelineRunner"Mientras se ejecuta el trabajo, busquémoslo en la lista de trabajos.
Abre la IU de supervisión de Cloud Dataflow en Google Cloud Platform Console. Deberías ver tu trabajo de conteo de palabras con el estado En ejecución:

Ahora, veamos los parámetros de la canalización. Comience por hacer clic en el nombre de su trabajo:
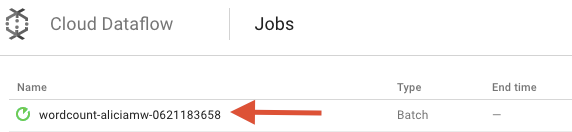
Cuando seleccionas un trabajo, puedes ver el grafo de ejecución. El gráfico de ejecución de una canalización representa cada una de sus transformaciones como un cuadro que contiene el nombre de la transformación y algo de información de su estado. Puede hacer clic en el símbolo que aparece en la esquina superior derecha de cada paso para ver más detalles:
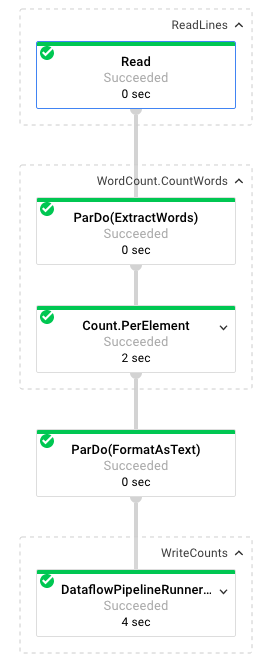
Veamos cómo la canalización transforma los datos en cada paso:
- Lectura: En este paso, la canalización lee de una fuente de entrada. En este caso, es un archivo de texto de Cloud Storage con el texto completo de la obra de Shakespeare El rey Lear. Nuestra canalización lee el archivo línea por línea y genera cada una como
PCollection, en la que cada línea de nuestro archivo de texto es un elemento de la colección. - CountWords: El paso
CountWordsse divide en dos partes. Primero, usa una función paralela (ParDo) llamadaExtractWordspara dividir cada línea en palabras individuales. El resultado de ExtractWords es una PCollection nueva en la que cada elemento es una palabra. El siguiente paso,Count, utiliza una transformación proporcionada por el SDK de Dataflow que devuelve pares clave-valor en los que la clave es una palabra única y el valor es la cantidad de veces que aparece. Este es el método que implementaCountWords. Puedes consultar el archivo WordCount.java completo en GitHub:
/**
* A PTransform that converts a PCollection containing lines of text
* into a PCollection of formatted word counts.
*/
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> apply(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}- FormatAsText: Esta es una función que da formato a cada par clave-valor y lo convierte en una string imprimible. Esta es la transformación
FormatAsTextpara implementar esto:
/** A SimpleFunction that converts a Word and Count into a printable string. */
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}- WriteCounts: En este paso, escribimos las cadenas imprimibles en varios archivos de texto fragmentados.
En unos minutos, veremos los resultados obtenidos de la canalización.
Ahora, consulta la página Resumen a la derecha del gráfico, que incluye los parámetros de canalización que incluimos en el comando mvn compile exec:java.
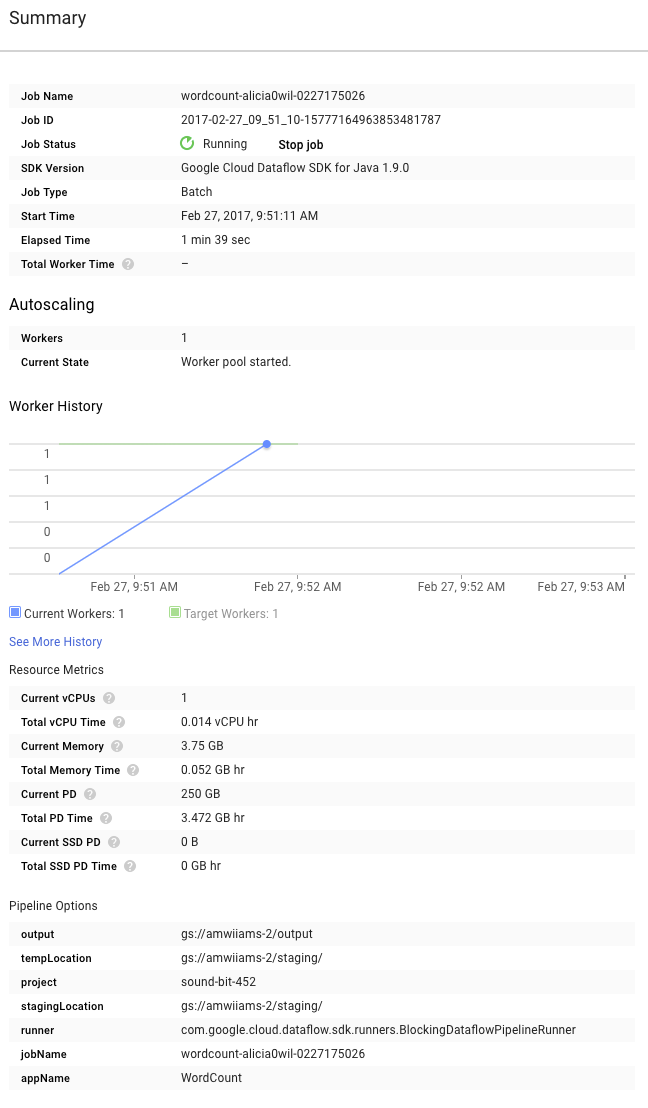
También puede ver los Contadores personalizados de la canalización, que, en este caso, muestran cuántas líneas vacías se encontraron hasta el momento durante la ejecución. Puedes agregar contadores nuevos a tu canalización para hacer un seguimiento de las métricas específicas de la aplicación.
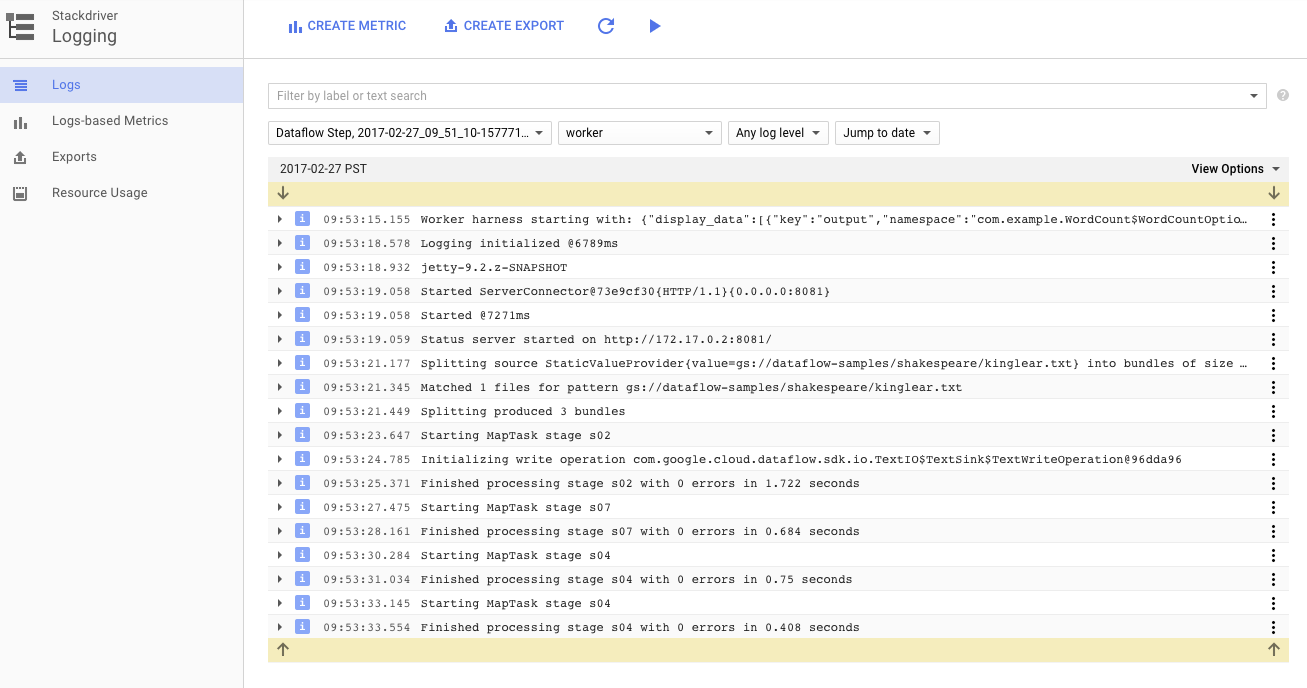
Puedes hacer clic en el ícono de Registros para ver los mensajes de error específicos.

Filtra los mensajes que aparecen en la pestaña Registros de trabajos con el menú desplegable Gravedad mínima.

Puedes usar el botón Registros de trabajador en la pestaña de registros para ver los registros de trabajador de las instancias de Compute Engine que ejecutan tu canalización. Los registros de trabajador constan de líneas de registro generadas por su código y el código generado por Dataflow que lo ejecuta.
Si intentas depurar una falla en la canalización, muchas veces habrá registros adicionales en los Registros de trabajador que te ayudarán a resolver el problema. Ten en cuenta que estos registros se agregan en todos los trabajadores y se pueden filtrar y buscar.
En el siguiente paso, verificaremos que el trabajo se haya ejecutado correctamente.
Abre la IU de supervisión de Cloud Dataflow en Google Cloud Platform Console.
Primero, deberías ver el trabajo de conteo de palabras con el estado En ejecución y, luego, Correcto:

El trabajo tardará entre 3 y 4 minutos en ejecutarse.
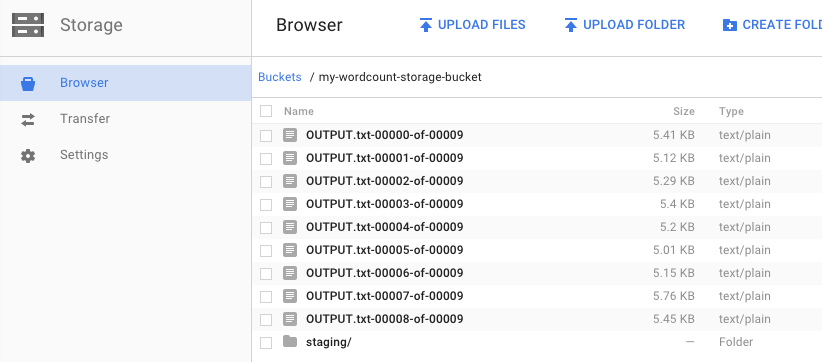
¿Recuerda cuando ejecutó la canalización y especificó el bucket para los resultados? Veamos los resultados (¿o no quiere saber cuántas veces aparece cada palabra en El rey Lear?). Regresa al navegador de Cloud Storage en Google Cloud Platform Console. En el bucket, deberías ver los archivos generados y los archivos de etapa de pruebas que creó el trabajo:
Puedes apagar tus recursos desde Google Cloud Platform Console.
Abre el navegador de Cloud Storage en Google Cloud Platform Console.
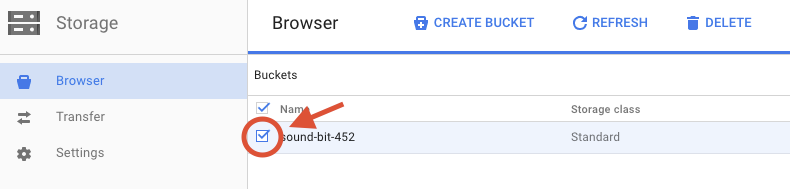
Selecciona la casilla de verificación que se encuentra junto al bucket que creaste.
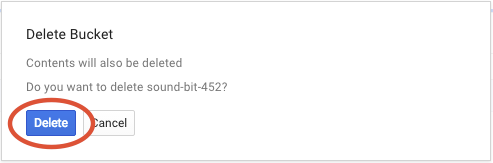
Haz clic en BORRAR para borrar de forma permanente el bucket y su contenido.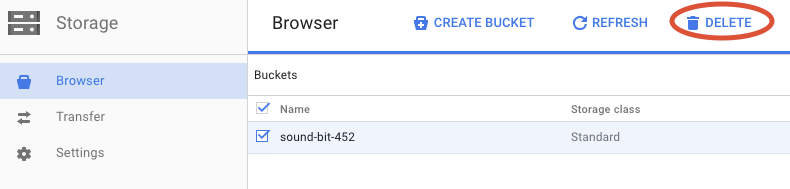
Aprendió a crear un proyecto de Maven con el SDK de Cloud Dataflow, ejecutar una canalización de ejemplo con Google Cloud Platform Console y borrar el bucket de Cloud Storage asociado y sus contenidos.
Más información
- Documentación de Dataflow: https://cloud.google.com/dataflow/docs/
Licencia
Esta obra se ofrece bajo una licencia Creative Commons Atribución 3.0 genérica y una licencia Apache 2.0.