
Dataflow ist ein einheitliches Programmiermodell und ein verwalteter Dienst für die Entwicklung und Ausführung verschiedener Datenverarbeitungsmuster wie ETL, Batchberechnung und kontinuierliche Berechnung. Da es sich um einen verwalteten Dienst handelt, können Ressourcen auf Abruf zugewiesen werden. Dies verringert die Latenz und sorgt gleichzeitig für eine anhaltend hohe Auslastungseffizienz.
Im Dataflow-Modell werden die Batch- und Streamverarbeitung kombiniert, damit Entwickler in Sachen Qualität, Kosten und Verarbeitungszeit keine Kompromisse eingehen müssen. In diesem Codelab erfahren Sie, wie Sie eine Dataflow-Pipeline ausführen, die die Vorkommen eindeutiger Wörter in einer Textdatei zählt.
Diese Anleitung basiert auf https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-maven.
Lerninhalte
- Maven-Projekt mit dem Cloud Dataflow SDK erstellen
- Beispiel-Pipeline mithilfe der Google Cloud Platform Console ausführen
- Zugehörigen Cloud Storage-Bucket und seine Inhalte löschen
Voraussetzungen
Wie werden Sie diese Anleitung verwenden?
Wie würden Sie Ihre Erfahrungen mit der Verwendung von Google Cloud Platform-Diensten bewerten?
Einrichtung der Umgebung im eigenen Tempo
Wenn Sie noch kein Google-Konto (Gmail oder Google Apps) haben, müssen Sie eins erstellen. Melden Sie sich in der Google Cloud Platform Console (console.cloud.google.com) an und erstellen Sie ein neues Projekt:



Notieren Sie sich die Projekt-ID, also den projektübergreifend nur einmal vorkommenden Namen eines Google Cloud-Projekts. Der oben angegebene Name ist bereits vergeben und kann leider nicht mehr verwendet werden. Sie wird in diesem Codelab später als PROJECT_ID bezeichnet.
Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Google Cloud-Ressourcen verwenden zu können.
Dieses Codelab sollte Sie nicht mehr als ein paar Dollar kosten, aber es könnte mehr sein, wenn Sie sich für mehr Ressourcen entscheiden oder wenn Sie sie laufen lassen (siehe Abschnitt „Bereinigen“ am Ende dieses Dokuments).
Neuen Nutzern der Google Cloud Platform steht eine kostenlose Testversion mit einem Guthaben von 300$ zur Verfügung.
APIs aktivieren
Klicken Sie auf das Menüsymbol oben links auf dem Bildschirm.

Wählen Sie im Drop-down-Menü API Manager aus.

Geben Sie im Suchfeld "Google Compute Engine" ein. Klicken Sie in der angezeigten Ergebnisliste auf „Google Compute Engine API“.
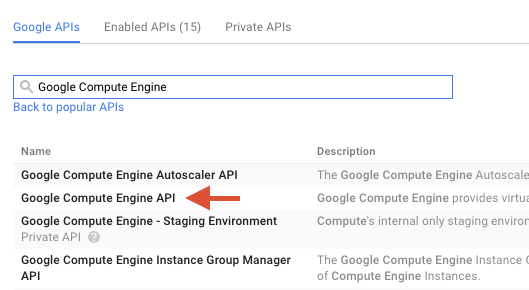
Klicken Sie auf der Seite „Google Compute Engine“ auf Aktivieren.
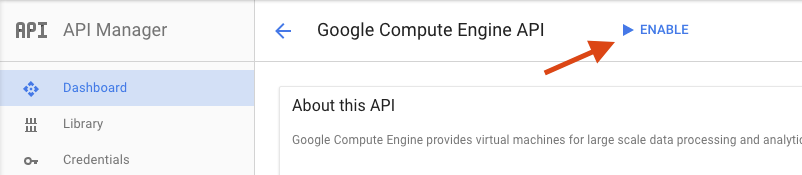
Klicken Sie nach der Aktivierung auf den Pfeil, um zurückzugehen.
Suchen Sie nun nach den folgenden APIs und aktivieren Sie sie ebenfalls:
- Google Dataflow API
- Stackdriver Logging API
- Google Cloud Storage
- Google Cloud Storage JSON API
- BigQuery API
- Google Cloud Pub/Sub API
- Google Cloud Datastore API
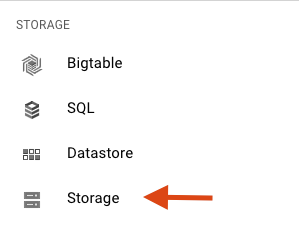
Klicken Sie in der Google Cloud Platform Console oben links auf das Symbol Menü:
Scrollen Sie nach unten und wählen Sie im Unterabschnitt Speicher die Option Cloud Storage aus:
Sie sollten jetzt den Cloud Storage-Browser sehen. Wenn Sie ein Projekt verwenden, in dem derzeit keine Cloud Storage-Buckets vorhanden sind, wird ein Dialogfeld angezeigt, in dem Sie aufgefordert werden, einen neuen Bucket zu erstellen:
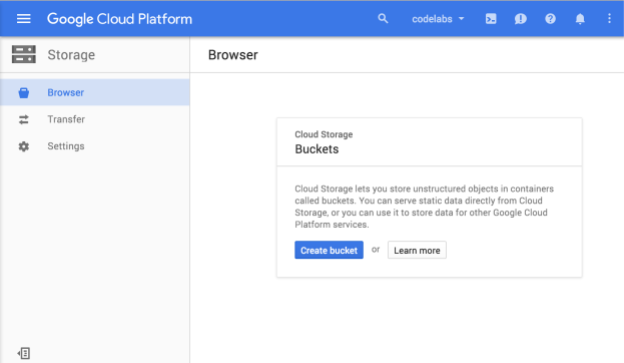
Klicken Sie auf die Schaltfläche Bucket erstellen, um einen Bucket zu erstellen:
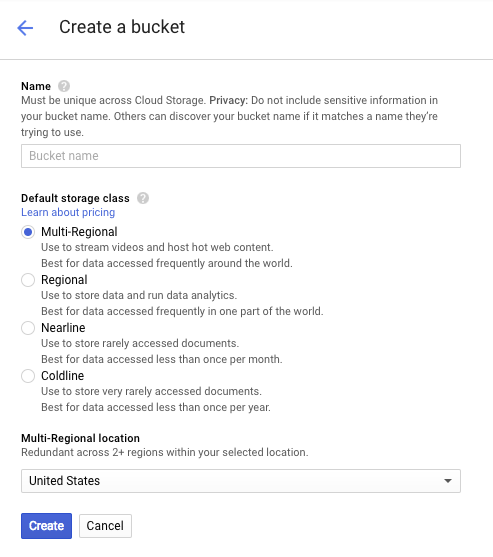
Geben Sie einen Namen für den Bucket ein. Wie im Dialogfeld angegeben, müssen Bucket-Namen in Cloud Storage einmalig sein. Wenn Sie also einen offensichtlichen Namen wie „test“ auswählen, hat wahrscheinlich schon jemand einen Bucket mit diesem Namen erstellt und Sie erhalten eine Fehlermeldung.
Außerdem gibt es einige Regeln dazu, welche Zeichen in Bucket-Namen zulässig sind. Wenn Sie den Bucket-Namen mit einem Buchstaben oder einer Zahl beginnen und beenden und nur Bindestriche in der Mitte verwenden, ist alles in Ordnung. Wenn Sie versuchen, Sonderzeichen zu verwenden oder den Bucket-Namen mit etwas anderem als einem Buchstaben oder einer Ziffer zu beginnen oder zu beenden, werden Sie im Dialogfeld an die Regeln erinnert.
Geben Sie einen eindeutigen Namen für den Bucket ein und klicken Sie auf Erstellen. Wenn Sie etwas auswählen, das bereits verwendet wird, wird die oben gezeigte Fehlermeldung angezeigt. Anschließend sehen Sie den neuen, leeren Bucket im Browser:
Der Bucket-Name, den Sie sehen, ist natürlich anders, da er für alle Projekte eindeutig sein muss.
Google Cloud Shell aktivieren
Klicken Sie in der GCP Console oben rechts in der Symbolleiste auf das Cloud Shell-Symbol:

Klicken Sie dann auf "Cloud Shell starten":

Die Bereitstellung und Verbindung mit der Umgebung dauert nur einen Moment:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf der Google Cloud, wodurch Netzwerkleistung und Authentifizierung deutlich verbessert werden. Sie können die meisten, wenn nicht sogar alle Schritte in diesem Lab einfach mit einem Browser oder Ihrem Google Chromebook durchführen.
Sobald Sie mit Cloud Shell verbunden sind, sollten Sie sehen, dass Sie bereits authentifiziert sind und das Projekt bereits auf Ihre PROJECT_ID eingestellt ist.
Führen Sie in Cloud Shell den folgenden Befehl aus, um zu prüfen, ob Sie authentifiziert sind:
gcloud auth list
Befehlsausgabe
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Befehlsausgabe
[core] project = <PROJECT_ID>
Ist dies nicht der Fall, können Sie die Einstellung mit diesem Befehl vornehmen:
gcloud config set project <PROJECT_ID>
Befehlsausgabe
Updated property [core/project].
Nachdem Cloud Shell gestartet wurde, erstellen wir zuerst ein Maven-Projekt, das das Cloud Dataflow SDK für Java enthält.
Führen Sie den Befehl mvn archetype:generate in der Shell so aus:
mvn archetype:generate \
-DarchetypeArtifactId=google-cloud-dataflow-java-archetypes-examples \
-DarchetypeGroupId=com.google.cloud.dataflow \
-DarchetypeVersion=1.9.0 \
-DgroupId=com.example \
-DartifactId=first-dataflow \
-Dversion="0.1" \
-DinteractiveMode=false \
-Dpackage=com.exampleNachdem Sie den Befehl ausgeführt haben, sollte ein neues Verzeichnis namens first-dataflow unter dem aktuellen Verzeichnis angezeigt werden. first-dataflow enthält ein Maven-Projekt mit dem Cloud Dataflow SDK für Java und Beispielpipelines.
Speichern Sie zuerst die Projekt-ID und die Namen der Cloud Storage-Buckets als Umgebungsvariablen. Das können Sie in Cloud Shell tun. Ersetzen Sie <your_project_id> durch Ihre eigene Projekt-ID.
export PROJECT_ID=<your_project_id>Wiederholen Sie den Vorgang für den Cloud Storage-Bucket. Ersetzen Sie <your_bucket_name> durch den eindeutigen Namen, den Sie zum Erstellen des Buckets in einem früheren Schritt verwendet haben.
export BUCKET_NAME=<your_bucket_name>Wechseln Sie zum Verzeichnis first-dataflow/.
cd first-dataflowWir führen eine Pipeline mit dem Namen "WordCount" aus, die Text liest, Textzeilen in einzelne Wörter tokenisiert und für jedes dieser Wörter eine Häufigkeitszählung durchführt. Zuerst führen wir die Pipeline aus. Während sie ausgeführt wird, sehen wir uns an, was bei den einzelnen Schritten passiert.
Starten Sie die Pipeline, indem Sie den Befehl mvn compile exec:java in der Shell oder im Terminalfenster ausführen. Für die Argumente --project, --stagingLocation, und --output werden im Befehl unten die Umgebungsvariablen verwendet, die Sie zuvor in diesem Schritt eingerichtet haben.
mvn compile exec:java \
-Dexec.mainClass=com.example.WordCount \
-Dexec.args="--project=${PROJECT_ID} \
--stagingLocation=gs://${BUCKET_NAME}/staging/ \
--output=gs://${BUCKET_NAME}/output \
--runner=BlockingDataflowPipelineRunner"Suchen Sie den Job in der Jobliste, solange der Job ausgeführt wird.
Öffnen Sie die Monitoring-UI von Cloud Dataflow in der Google Cloud Console. Für den Job zum Zählen der Wörter sollte nun der Status Wird ausgeführt angezeigt werden:

Sehen wir uns nun die Pipeline-Parameter an. Klicken Sie zuerst auf den Namen des Jobs.
Wenn Sie einen Job auswählen, können Sie sich die Ausführungsgrafik ansehen. Darin wird jede Transformation in der Pipeline als Feld dargestellt, das den Transformationsnamen und einige Statusangaben enthält. Falls Sie weitere Details zu einem Schritt sehen möchten, klicken Sie auf das Caret-Zeichen oben rechts.
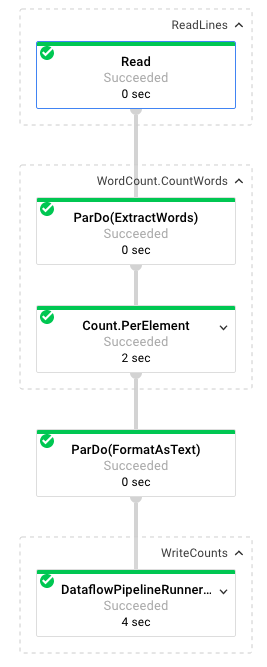
So wandelt die Pipeline die Daten in den einzelnen Schritten um:
- Lesen: In diesem Schritt liest die Pipeline aus einer Eingabequelle. In diesem Fall handelt es sich um eine Textdatei aus Cloud Storage mit dem vollständigen Text des Shakespeare-Stücks King Lear. Unsere Pipeline liest die Datei zeilenweise und gibt für jede Zeile eine
PCollectionaus, wobei jede Zeile in unserer Textdatei ein Element in der Sammlung ist. - CountWords: Der Schritt
CountWordszum Zählen der Wörter besteht aus zwei Teilen. Zuerst wird eine parallele Do-Funktion (ParDo) mit dem NamenExtractWordsverwendet, um jede Zeile in einzelne Wörter zu zerlegen. Die Ausgabe von ExtractWords ist eine neue PCollection, in der jedes Element ein Wort ist. Im nächsten Schritt,Count, wird eine vom Dataflow SDK bereitgestellte Transformation verwendet, die Schlüssel/Wert-Paare zurückgibt, wobei der Schlüssel ein eindeutiges Wort und der Wert die Anzahl der Vorkommen ist. Unten sehen Sie die Methode zur Implementierung vonCountWords. Die vollständige Datei „WordCount.java“ finden Sie auf GitHub:
/**
* A PTransform that converts a PCollection containing lines of text
* into a PCollection of formatted word counts.
*/
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> apply(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}- FormatAsText: Jedes Schlüssel/Wert-Paar wird hiermit als druckbarer String formatiert. So implementieren Sie die
FormatAsText-Transformation:
/** A SimpleFunction that converts a Word and Count into a printable string. */
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}- WriteCounts: In diesem Schritt werden die druckbaren Strings in mehrere partitionierte Textdateien geschrieben.
Wir sehen uns die Ausgabe der Pipeline gleich an.
Sehen Sie sich nun rechts neben dem Diagramm die Seite Zusammenfassung an. Dort finden Sie die Pipeline-Parameter, die wir in den mvn compile exec:java-Befehl aufgenommen haben.
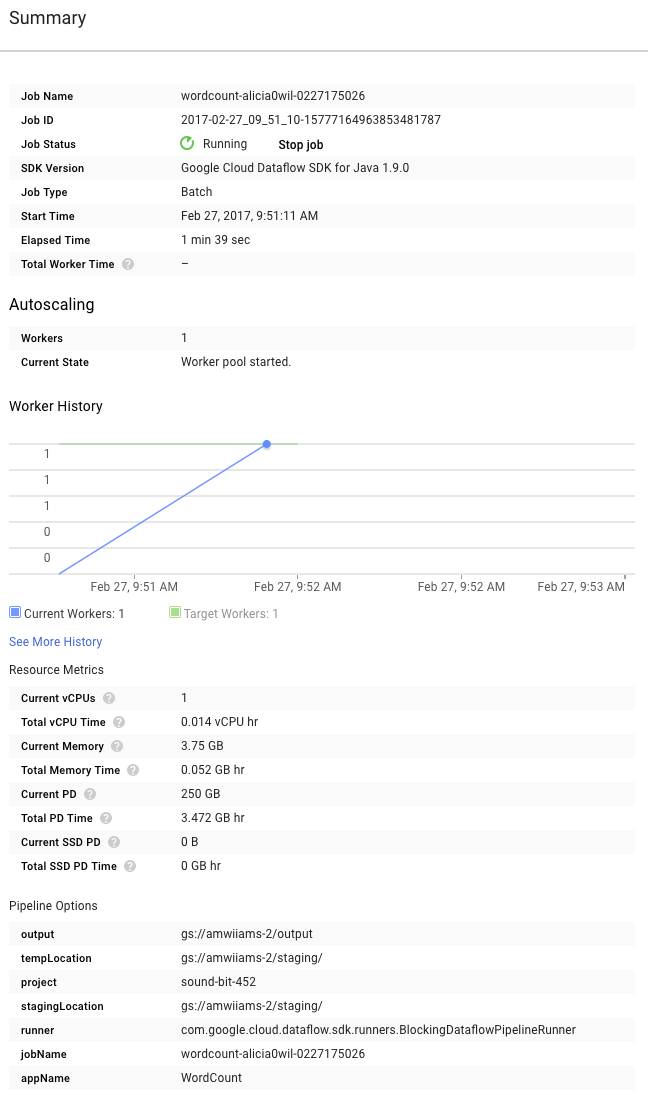
Sie sehen dort auch benutzerdefinierte Zähler für die Pipeline. In diesem Fall wird angezeigt, wie viele leere Zeilen bisher erkannt wurden. Sie können Ihrer Pipeline neue Zähler hinzufügen, um anwendungsspezifische Messwerte zu erfassen.
Klicken Sie auf das Symbol Logs, um die spezifischen Fehlermeldungen aufzurufen.

Sie können die Nachrichten, die auf dem Tab „Joblog“ angezeigt werden, über das Drop-down-Menü „Minimale Wichtigkeit“ filtern.

Mit der Schaltfläche Worker-Logs auf dem Tab „Logs“ können Sie Worker-Logs für die Compute Engine-Instanzen aufrufen, in denen Ihre Pipeline ausgeführt wird. Worker-Logs bestehen aus Log-Zeilen, die anhand Ihres Codes und des in Dataflow generierten Codes ausgegeben werden.
Wenn Sie versuchen, einen Fehler in der Pipeline zu beheben, finden Sie häufig zusätzliche Protokolle in den Worker-Logs, die Ihnen bei der Problemlösung helfen. Diese Logs werden für alle Worker zusammengefasst und können gefiltert und durchsucht werden.
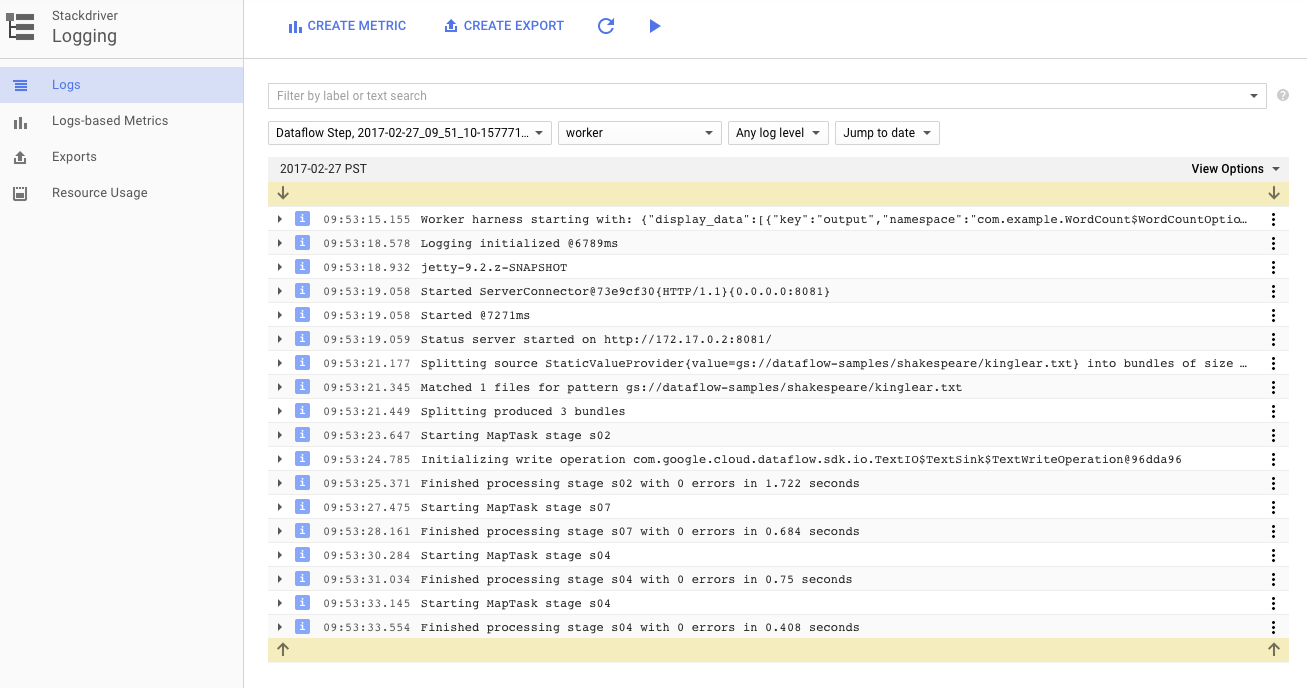
Im nächsten Schritt prüfen wir, ob Ihr Job erfolgreich ausgeführt wurde.
Öffnen Sie die Monitoring-UI von Cloud Dataflow in der Google Cloud Console.
Ihr Job zum Zählen der Wörter sollte zuerst den Status Wird ausgeführt und dann Erfolgreich haben:

Die Ausführung des Jobs dauert etwa drei bis vier Minuten.
Wir haben zuvor die Pipeline ausgeführt und einen Bucket für die Ausgabe angegeben. Sehen wir uns nun das Ergebnis an, denn Sie möchten bestimmt wissen, wie häufig jedes einzelne Wort in König Lear vorkommt. Kehren Sie in der Google Cloud Console zum Cloud Storage-Browser zurück. In Ihrem Bucket sollten Sie die Ausgabedateien und die Staging-Dateien sehen, die von Ihrem Job erstellt wurden:
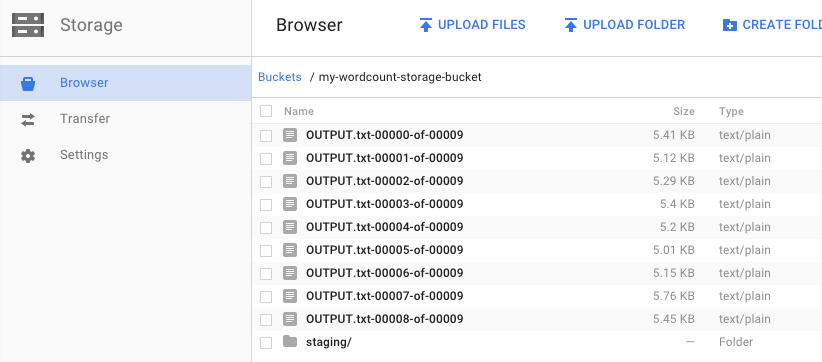
Sie können Ihre Ressourcen über die Google Cloud Console herunterfahren.
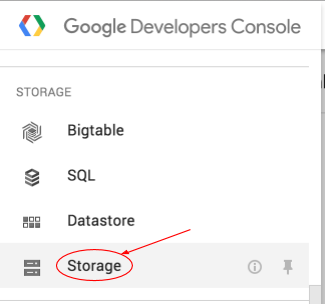
Öffnen Sie in der Google Cloud Platform Console den Cloud Storage-Browser.
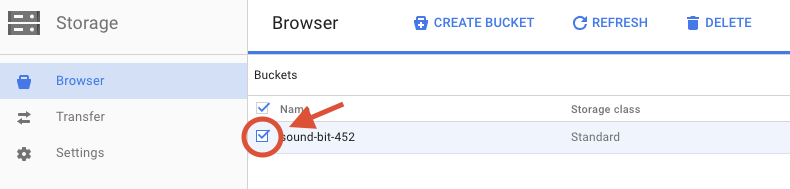
Klicken Sie das Kästchen neben dem von Ihnen erstellten Bucket an.
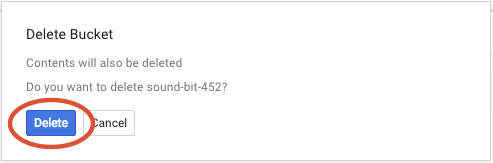
Klicken Sie auf LÖSCHEN, um den Bucket und seinen Inhalt endgültig zu löschen.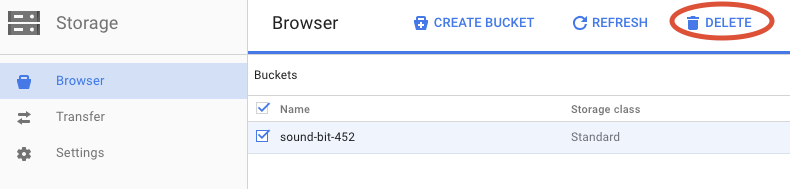
Sie haben gelernt, wie Sie mit dem Cloud Dataflow SDK ein Maven-Projekt erstellen und mithilfe der Google Cloud Platform Console eine Beispiel-Pipeline ausführen sowie den zugehörigen Cloud Storage-Bucket und dessen Inhalte löschen.
Weitere Informationen
- Dataflow-Dokumentation: https://cloud.google.com/dataflow/docs/
Lizenz
Dieses Werk ist unter einer Creative Commons Attribution 3.0 Generic License und einer Apache 2.0-Lizenz lizenziert.