
Dans cet atelier de programmation, vous allez apprendre à utiliser certaines fonctionnalités avancées de BigQuery, dont les suivantes:
- Fonctions définies par l'utilisateur en JavaScript
- Tables partitionnées
- Requêtes directes sur les données stockées dans Google Cloud Storage et Google Drive
Vous allez récupérer les données de la Commission électorale fédérale des États-Unis, les nettoyer et les charger dans BigQuery. Vous aurez également l'opportunité de poser des questions intéressantes sur cet ensemble de données.
Cet atelier de programmation ne suppose aucune expérience préalable dans BigQuery, mais une connaissance de SQL vous aidera à en tirer le meilleur parti.
Points abordés
- Utiliser des fonctions JavaScript définies par l'utilisateur pour effectuer des opérations difficiles avec SQL
- Utiliser BigQuery pour effectuer des opérations ETL (extraction, transformation et chargement) sur des données hébergées dans d'autres datastores, tels que Google Cloud Storage et Google Drive
Ce dont vous avez besoin
- Projet Google Cloud avec facturation activée
- Un bucket Google Cloud Storage
- SDK Google Cloud installé
Comment allez-vous utiliser ce tutoriel ?
Comment évalueriez-vous votre niveau d'expérience avec BigQuery ?
Configuration de l'environnement au rythme de chacun
Si vous n'avez pas encore de compte Google (Gmail ou Google Apps), vous devez en créer un. Connectez-vous à la console Google Cloud Platform (console.cloud.google.com) et créez un projet:



Mémorisez l'ID du projet. Il s'agit d'un nom unique permettant de différencier chaque projet Google Cloud (le nom ci-dessus est déjà pris ; vous devez en trouver un autre). Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
Vous devez ensuite activer la facturation dans Cloud Console afin d'utiliser les ressources Google Cloud.
Suivre cet atelier de programmation ne devrait pas vous coûter plus d'un euro. Cependant, cela peut s'avérer plus coûteux si vous décidez d'utiliser davantage de ressources ou si vous n'interrompez pas les ressources (voir la section "Effectuer un nettoyage" à la fin du présent document).
Les nouveaux utilisateurs de Google Cloud Platform peuvent bénéficier d'un essai offert de 300$.
Google Cloud Shell
Vous pouvez utiliser Google Cloud et BigQuery à distance depuis votre ordinateur portable. Dans cet atelier de programmation, nous utiliserons Google Cloud Shell, un environnement de ligne de commande fonctionnant dans le cloud.
Cette machine virtuelle basée sur Debian contient tous les outils de développement dont vous aurez besoin. Elle intègre un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Cela signifie que tout ce dont vous avez besoin pour cet atelier de programmation est un navigateur (oui, tout fonctionne sur un Chromebook).
Pour activer Google Cloud Shell, cliquez sur le bouton en haut à droite de la Console pour les développeurs, qui ne devrait pas prendre quelques instants pour provisionner l'environnement et s'y connecter :

Cliquez sur le bouton "Démarrer Cloud Shell" :


En principe, une fois que vous êtes connecté à Cloud Shell, vous êtes authentifié, et le projet est défini sur votre PROJECT_ID :
gcloud auth list
Résultat de la commande
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Résultat de la commande
[core] project = <PROJECT_ID>
Cloud Shell définit également certaines variables d'environnement par défaut qui peuvent être utiles lorsque vous exécutez de futures commandes.
echo $GOOGLE_CLOUD_PROJECT
Résultat de la commande
<PROJECT_ID>
Si, pour une raison quelconque, le projet n'est pas défini, exécutez simplement la commande suivante :
gcloud config set project <PROJECT_ID>
Vous recherchez votre PROJECT_ID ? Consultez l'ID utilisé pour la configuration ou recherchez-le dans le tableau de bord de la console:

IMPORTANT: Enfin, définissez la zone et la configuration du projet par défaut:
gcloud config set compute/zone us-central1-f
Vous pouvez choisir parmi différentes zones. Pour en savoir plus, consultez la documentation sur les régions et les zones.
Pour exécuter les requêtes BigQuery dans cet atelier de programmation, vous aurez besoin de votre propre ensemble de données. Donnez-lui un nom, par exemple campaign_funding. Exécutez les commandes suivantes dans votre interface système (Cloud Shell, par exemple):
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
Une fois l'ensemble de données créé, vous êtes prêt à l'utiliser. L'exécution de cette commande permet également de vérifier que vous avez correctement configuré le client de la ligne de commande bq, que l'authentification fonctionne et que vous disposez d'un accès en écriture au projet cloud sur lequel vous travaillez. Si vous gérez plusieurs projets, vous êtes invité à sélectionner celui qui vous intéresse dans une liste.

L'ensemble de données de finance de la commission fédérale des États-Unis a été décompressé et copié dans le bucket GCS gs://campaign-funding/.
Téléchargez l'un des fichiers sources en local pour que nous puissions voir à quoi il ressemble. Exécutez les commandes suivantes à partir d'une fenêtre de commande:
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
Le contenu du fichier de contributions individuel doit s'afficher. Nous allons examiner trois types de fichiers pour cet atelier de programmation: les contributions individuelles (indiv*.txt), les candidats (cn*.txt) et les comités (cm*.txt). Si vous êtes intéressé, utilisez le même mécanisme pour vérifier les autres fichiers.
Nous ne allons pas charger les données brutes directement dans BigQuery, mais nous les interrogerons depuis Google Cloud Storage. Pour ce faire, nous avons besoin de connaître le schéma et quelques informations le concernant.
L'ensemble de données est décrit sur le site Web des élections fédérales. Schémas des tables que nous allons examiner:
Afin de créer un lien vers les tables, vous devez créer une définition de table qui inclut les schémas. Exécutez les commandes suivantes pour générer les définitions de la table:
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
Ouvrez le fichier indiv_dev.json avec votre éditeur de texte préféré et examinez son contenu. Il contiendra le fichier json qui décrit comment interpréter le fichier de données FEC.
Nous devons apporter deux petites modifications à la section csvOptions. Ajoutez une valeur fieldDelimiter pour """ et une valeur quote pour """" (chaîne vide). Cette opération est nécessaire, car les fichiers ne sont en fait pas séparés par une virgule.
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
Le fichier indiv_dev.json doit se présenter comme suit :
"fieldDelimiter": "|",
"quote":"",
Étant donné que la création des définitions de tables pour les tables de commission et de candidats est similaire, et que le schéma contient un code récurrent, téléchargez simplement ces fichiers.
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
Ces fichiers ressemblent au fichier indiv_dev.json. Notez que vous pouvez également télécharger le fichier indiv_def.json, au cas où vous rencontreriez des difficultés pour obtenir les bonnes valeurs.
Ensuite, associez un tableau BigQuery à ces fichiers. Exécutez les commandes suivantes :
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
Cette opération va créer trois tables BigQuery: transactions, comités et candidats. Vous pouvez interroger ces tables comme il s'agit de tables BigQuery normales, mais elles ne sont pas stockées dans BigQuery, mais dans Google Cloud Storage. Si vous mettez à jour les fichiers sous-jacents, les modifications sont immédiatement répercutées dans les requêtes que vous exécutez.
Maintenant, essayons d'exécuter quelques requêtes. Ouvrez l'interface utilisateur Web BigQuery.

Recherchez votre ensemble de données dans le volet de navigation de gauche (vous devrez peut-être modifier la liste déroulante des projets en haut à gauche), cliquez sur le gros bouton rouge COMPOSE QUERY' et saisissez la requête suivante dans la zone:
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
Il s'agit des 100 derniers dons effectués par les employés de Google. Si vous le souhaitez, vous pouvez tester des propositions de dons auprès des résidents de votre code postal, ou trouver les plus gros dons en ville.
La requête et les résultats ressembleront à ceci:
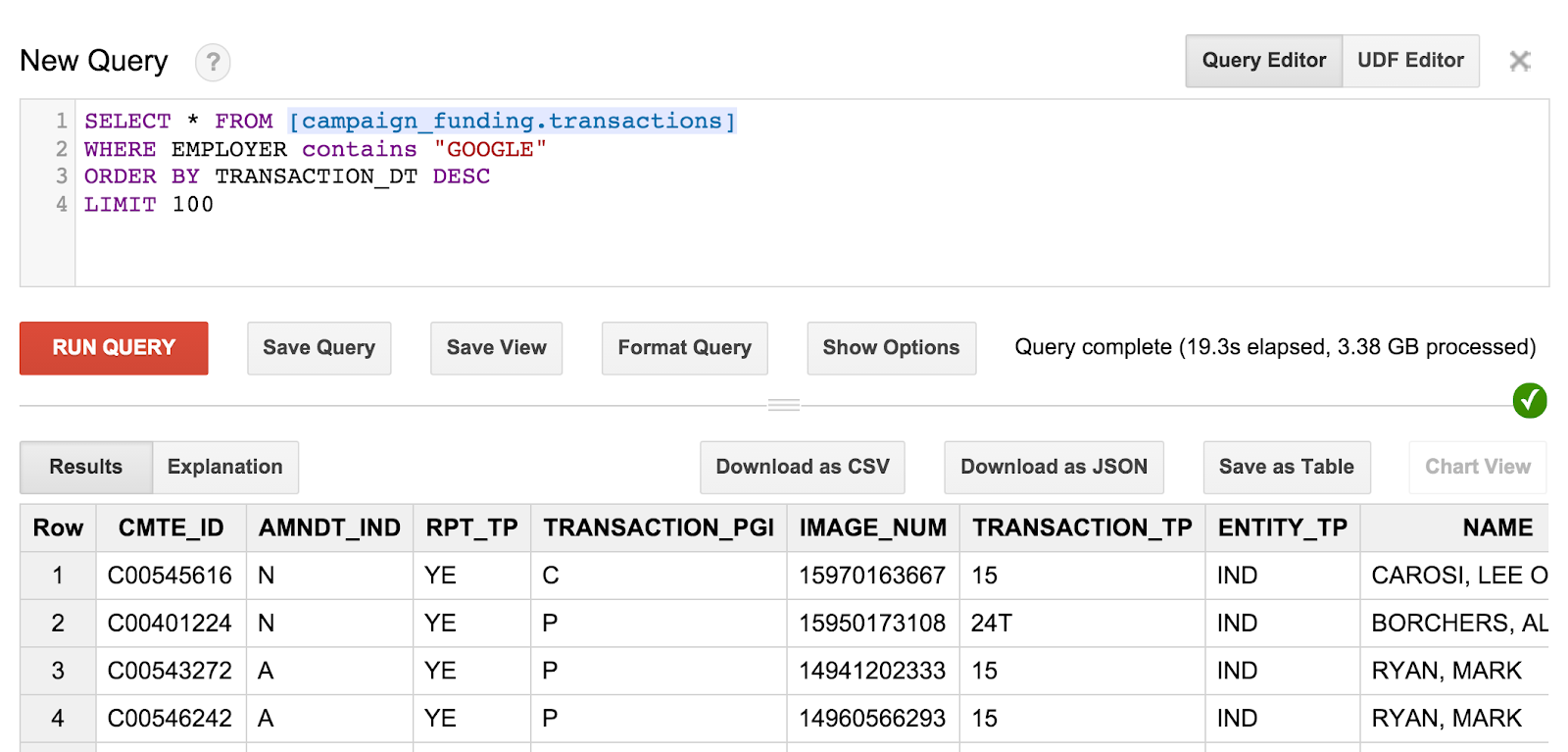
Toutefois, vous pouvez remarquer que le bénéficiaire de ces dons est réellement connu. Nous devons proposer des requêtes plus pertinentes pour obtenir ces informations.
Cliquez sur la table des transactions dans le volet de gauche, puis sur l'onglet du schéma. Elle devrait se présenter comme suit:
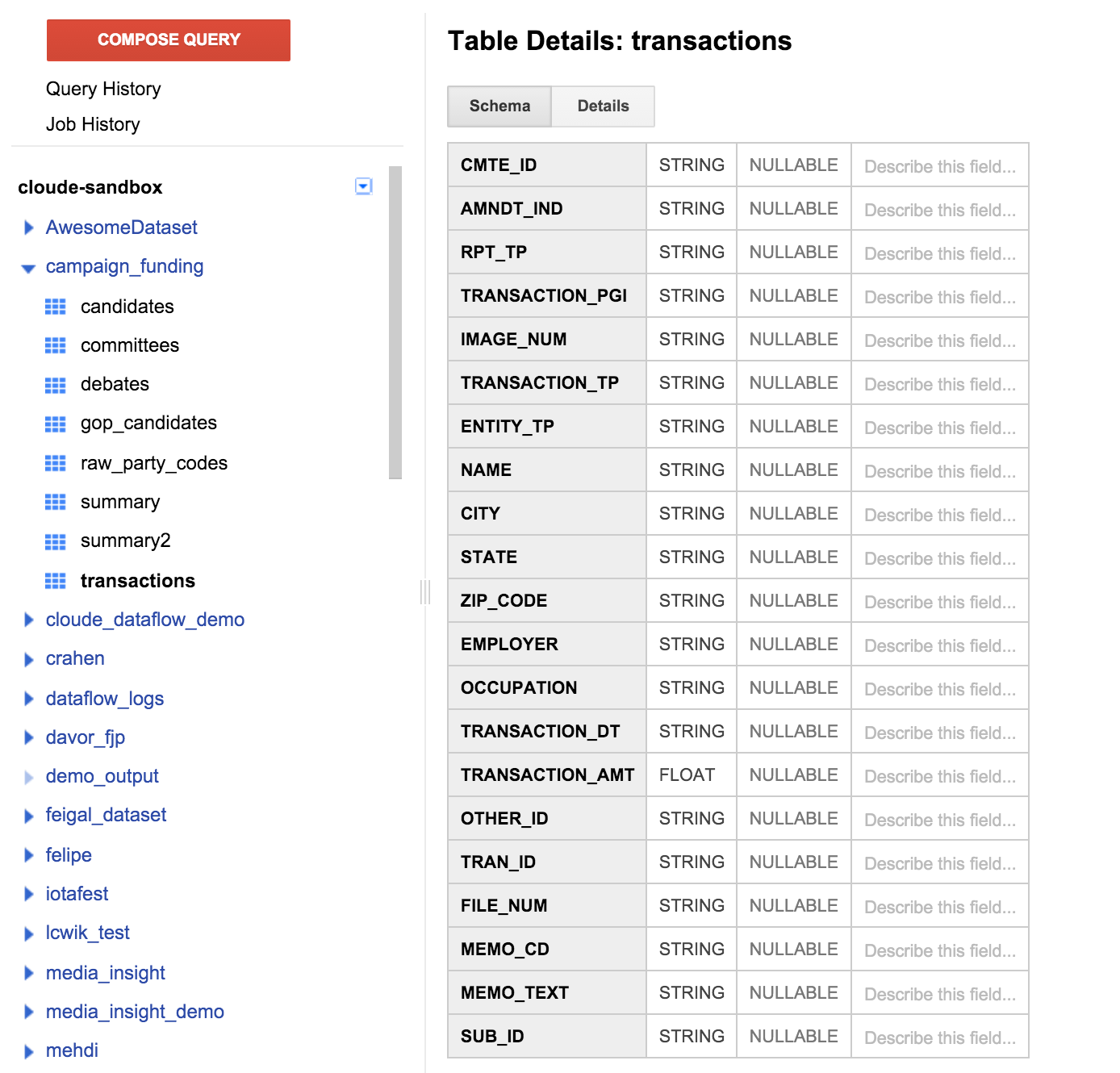
Une liste des champs correspondant à la définition de table spécifiée précédemment s'affiche. Notez qu'il n'y a pas de champ dédié au bénéficiaire ou qu'il n'y a aucun moyen de connaître la liste des candidats admissibles. Cependant, il existe un champ appelé CMTE_ID. Cela nous permet d'associer le comité qui a reçu le don. Ces informations ne sont toujours pas utiles.
Cliquez ensuite sur la table des comités pour afficher son schéma. Nous avons une CMET_ID, qui peut nous rejoindre dans le tableau des transactions. CAND_ID est un autre champ pouvant être associé à une table CAND_ID dans la table des candidats. Enfin, nous disposons d'un lien entre les transactions et les candidats via le tableau des comités.
Notez qu'il n'existe pas d'onglet d'aperçu pour les tables basées sur GCS. En effet, BigQuery doit lire les données d'une source de données externe pour pouvoir les lire. Utilisons une requête"SELECT *'" sur le tableau des candidats pour récupérer un échantillon de données.
SELECT * FROM [campaign_funding.candidates] LIMIT 100
Le résultat doit ressembler à ceci :
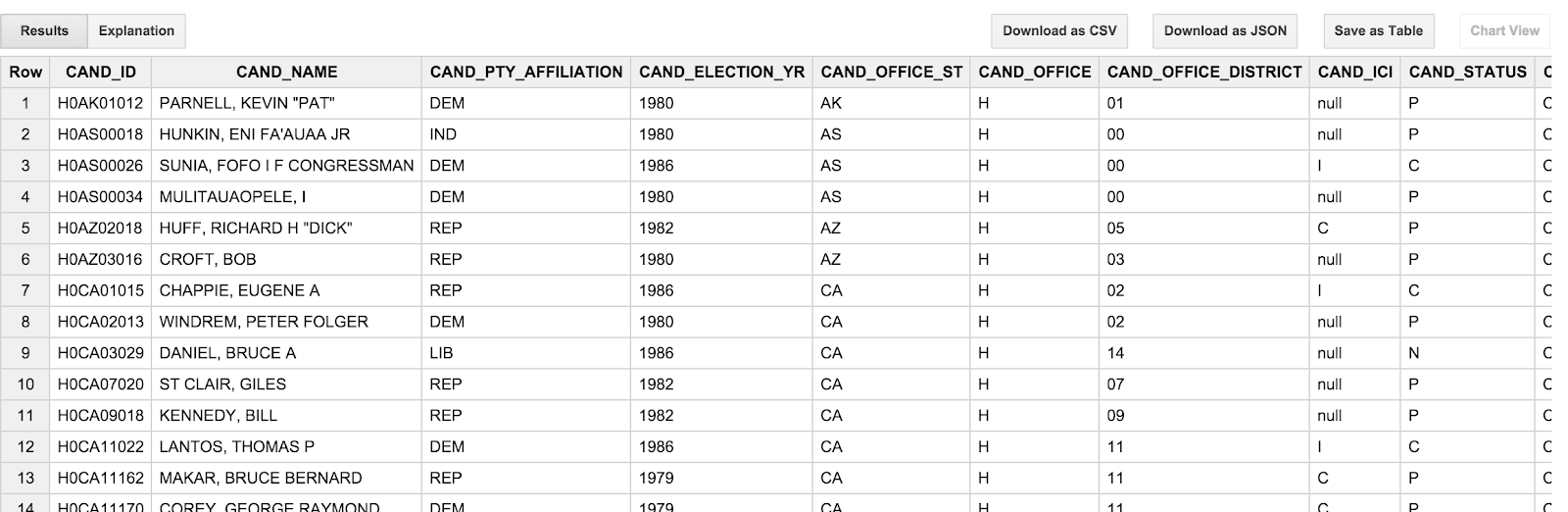
Comme vous pouvez le constater, les noms des candidats sont TOUT EN MAJUSCULES et sont présentés dans l'ordre (nom, prénom, ordre). C'est un peu agaçant, car ce comportement est peu enthousiasmant que l'on pense aux candidats. Il serait préférable de voir Barack Obama et non un OBAMA, BARACK". De plus, les dates de transaction (TRANSACTION_DT) dans le tableau des transactions sont anormalement floues. Il s'agit de valeurs de chaîne au format YYYYMMDD. Nous aborderons ces problèmes dans la section suivante.
Maintenant que nous savons comment les transactions se rapportent aux candidats, nous allons exécuter une requête pour déterminer qui donne de l'argent à qui. Coupez et collez la requête suivante dans la zone de rédaction:
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
Cette requête associe la table des transactions à la table des comités, puis à la table des candidats. Il ne prend en compte que les transactions des personnes dont le nom de profession est "ENGINEER". La requête agrège les résultats par affiliation de parti. Cela nous permet de voir la répartition des dons à différents partis politiques entre les ingénieurs.
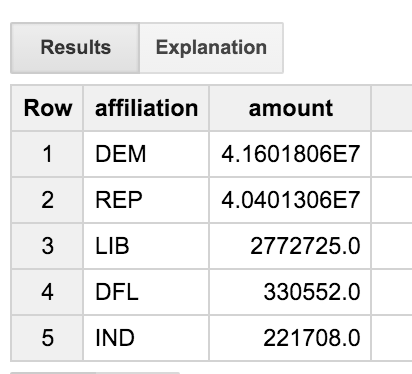
Nous constatons que les ingénieurs sont assez équilibrés, ce qui donne plus ou moins d'uniformité aux démocrates et aux républicains. Mais qu'est-ce que le parti "DFL' ? Ne serait-il pas intéressant d'avoir un nom complet plutôt qu'un simple code à trois lettres ?
Les codes du groupe sont définis sur le site Web de la FEC. Il existe une table qui met en correspondance le code du groupe avec le nom complet (il apparaît que "DFL' est "Democratic-Farmer-Labor'"). Bien que nous puissions effectuer manuellement les traductions de notre requête, cela semble fastidieux et difficile à synchroniser.
Et si nous pouvions analyser le code HTML dans le cadre de la requête ? Effectuez un clic droit n'importe où sur cette page et examinez le code source de la page. La source contient beaucoup d'informations d'en-tête et de code récurrent, mais recherchez la balise <table>. Chaque ligne de mappage est dans un élément <tr> HTML, le nom et le code sont tous deux encapsulés dans des éléments <td>. Chaque ligne ressemblera à ceci:
Le code HTML ressemble à ceci:
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
Notez que BigQuery ne peut pas lire le fichier directement depuis le Web. En effet, BigQuery est capable d'atteindre une source depuis des milliers de nœuds de calcul en même temps. Si elle était autorisée à s'exécuter sur des pages Web aléatoires, il s'agirait essentiellement d'une attaque par déni de service distribué (DDoS). Le fichier HTML de la page Web FEC est stocké dans le bucket gs://campaign-funding.
Nous devons créer une table à partir des données sur le financement des campagnes. Ce processus est semblable à celui des autres tables GCS que nous avons créées. La différence ici est que nous n'avons pas de schéma. Nous n'utilisons qu'un seul champ par ligne et nous l'appelons "data'". Nous considérons qu'il s'agit d'un fichier CSV, avec au lieu de séparer les virgules, nous utilisons un séparateur factice (`) sans guillemet.
Pour créer le tableau de recherche de groupes, exécutez les commandes suivantes à partir de la ligne de commande:
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
Nous allons à présent utiliser JavaScript pour analyser le fichier. En haut à droite de l'éditeur de requête BigQuery, vous devriez voir un bouton intitulé "Éditeur UDF". Cliquez dessus pour modifier une UDF JavaScript. Les champs de l'éditeur de fonctions définies par l'utilisateur seront préremplis avec des commentaires.

Supprimez le code qu'il contient, puis saisissez le code suivant:
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
Le code JavaScript se divise en deux parties. La première est une fonction qui prend une ligne d'entrée et émet une sortie analysée. L'autre est une définition qui enregistre cette fonction en tant que fonction définie par l'utilisateur (UDF) avec le nom tableParser et indique qu'elle utilise une colonne d'entrée appelée "data'" et génère deux colonnes, le code et le nom. La colonne du code correspond au code à trois lettres, tandis que la colonne "Name" (Nom) correspond au nom complet du groupe.
Revenez à l'onglet "Query Editor" (Éditeur de requête), puis saisissez la requête suivante:
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
L'exécution de cette requête analyse le fichier HTML brut et génère les valeurs de champ au format structuré. Plutôt élégant, hein ? Essayez de comprendre en quoi consiste "DFL'".
Maintenant que nous pouvons traduire les codes de groupe en noms, ajoutons une autre requête qui permet d'obtenir une information intéressante. Exécutez la requête suivante :
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
Cette requête permet d'identifier les candidats ayant reçu le plus de dons de campagne et d'illustrer leur affiliation à un parti.
Ces tables ne sont pas très volumineuses et prennent environ 30 secondes à effectuer une requête. Si vous allez travailler avec les tables, il faudra probablement les importer dans BigQuery. Vous pouvez exécuter une requête ETL sur la table pour regrouper les données en une fonction facile à utiliser, puis l'enregistrer en tant que table permanente. Cela signifie que vous n'avez pas toujours besoin de vous souvenir de la façon de traduire les codes de groupe. Vous pouvez également exclure les données erronées au fur et à mesure.
Cliquez sur le bouton "Afficher les options", puis sur le bouton "Sélectionner une table" à côté du libellé Destination Table. Sélectionnez votre ensemble de données campaign_funding, puis saisissez l'ID de table sous la forme summary'. Cochez la case allow large results'.

Exécutez maintenant la requête suivante:
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
Cette requête est beaucoup plus longue et propose des options de nettoyage supplémentaires. Par exemple, il ne tient pas compte des éléments dont le montant est supérieur à un million de dollars. Utilisez également des expressions régulières pour transformer LASTNAME, FIRSTNAME; en FIRSTNAME LASTNAME. Si vous vous sentez l'esprit aventurier, essayez de rédiger une UDF plus efficace et de corriger les majuscules (par exemple, &&tt;Firstname Lastname").
Enfin, essayez d'exécuter quelques requêtes sur votre table campaign_funding.summary pour vérifier qu'elles sont plus rapides. N'oubliez pas de supprimer d'abord l'option de requête de la table de destination, sinon vous risquez d'écraser la table récapitulative.
Vous avez maintenant nettoyé et importé les données du site Web FEC dans BigQuery.
Points abordés
- Utiliser des tables sauvegardées dans GCS dans BigQuery
- Utilisation de fonctions définies par l'utilisateur dans BigQuery
Étapes suivantes
- Voici quelques requêtes intéressantes pour savoir qui accorde de l'argent à ce cycle électoral.
En savoir plus
- En savoir plus sur les fonctions définies par l'utilisateur
- En savoir plus sur les sources de données fédérées (y compris GCS)
- Publiez vos questions et trouvez des réponses sur Stack Overflow à l'aide du tag google-bigquery.
Votre avis nous intéresse !
- N'hésitez pas à utiliser le lien situé en bas à gauche de cette page pour signaler des problèmes ou nous faire part de vos commentaires.