
هنگام بازگرداندن پاسخ به دستیار Google، می توانید از زیر مجموعه ای از زبان نشانه گذاری ترکیبی گفتار ( SSML ) در پاسخ های خود استفاده کنید. با استفاده از SSML، میتوانید پاسخهای مکالمهتان را بیشتر شبیه گفتار طبیعی جلوه دهید. مثال زیر نشانه گذاری SSML و صدای مربوطه را از دستیار Google نشان می دهد:
Node.js
function saySSML(conv) { const ssml = '<speak>' + 'Here are <say-as interpret-as="characters">SSML</say-as> samples. ' + 'I can pause <break time="3" />. ' + 'I can play a sound <audio src="https://www.example.com/MY_WAVE_FILE.wav">your wave file</audio>. ' + 'I can speak in cardinals. Your position is <say-as interpret-as="cardinal">10</say-as> in line. ' + 'Or I can speak in ordinals. You are <say-as interpret-as="ordinal">10</say-as> in line. ' + 'Or I can even speak in digits. Your position in line is <say-as interpret-as="digits">10</say-as>. ' + 'I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>. ' + 'Finally, I can speak a paragraph with two sentences. ' + '<p><s>This is sentence one.</s><s>This is sentence two.</s></p>' + '</speak>'; conv.add(ssml); }
JSON
{ "expectUserResponse": true, "expectedInputs": [ { "possibleIntents": [ { "intent": "actions.intent.TEXT" } ], "inputPrompt": { "richInitialPrompt": { "items": [ { "simpleResponse": { "textToSpeech": "<speak>Here are <say-as interpret-as=\"characters\">SSML</say-as> samples. I can pause <break time=\"3\" />. I can play a sound <audio src=\"https://www.example.com/MY_WAVE_FILE.wav\">your wave file</audio>. I can speak in cardinals. Your position is <say-as interpret-as=\"cardinal\">10</say-as> in line. Or I can speak in ordinals. You are <say-as interpret-as=\"ordinal\">10</say-as> in line. Or I can even speak in digits. Your position in line is <say-as interpret-as=\"digits\">10</say-as>. I can also substitute phrases, like the <sub alias=\"World Wide Web Consortium\">W3C</sub>. Finally, I can speak a paragraph with two sentences. <p><s>This is sentence one.</s><s>This is sentence two.</s></p></speak>" } } ] } } } ] }
صوتی
URL ها در SSML
هنگام تعریف یک پاسخ SSML که فقط شامل یک URL است، علامت های آمپر در آن URL می توانند به دلیل قالب بندی XML مشکلاتی ایجاد کنند. برای اطمینان از ارجاع صحیح URL، نمونه های & را با & .
حتی اگر پاسخ SSML شما فقط شامل یک URL باشد، Actions on Google برای پاسخ به متن نمایشی نیاز دارد. از آنجایی که متن داخل تگ <audio> توسط دستیار گفته نمی شود، می توانید متن پرکننده یا توضیح کوتاهی را در تگ <audio> خود وارد کنید تا این نیاز را برآورده کنید. نوشتار داخل تگ <audio> پس از پخش صدا توسط Assistant گفته نمیشود و مطابق با الزامات Action on Google برای نسخه نمایش متنی SSML شما است.
در اینجا نمونه ای از پاسخ مشکل ساز SSML آورده شده است:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
</audio>
</speak>
مثال بالا برای قالب بندی XML مناسب از & فرار نمی کند.
یک نسخه ثابت از همان پاسخ SSML به شکل زیر است:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
text
</audio>
</speak>
پشتیبانی از عناصر SSML
بخشهای زیر عناصر و گزینههای SSML را توصیف میکنند که میتوانند در Actions شما استفاده شوند.
<speak>
عنصر ریشه پاسخ SSML.
برای کسب اطلاعات بیشتر در مورد عنصر speak ، به مشخصات W3 مراجعه کنید.
مثال
<speak> my SSML content </speak>
<break>
عنصری خالی که مکث یا سایر مرزهای عروضی بین کلمات را کنترل می کند. استفاده از <break> بین هر جفت نشانه اختیاری است. اگر این عنصر بین کلمات وجود نداشته باشد، وقفه به طور خودکار بر اساس بافت زبانی تعیین می شود.
برای کسب اطلاعات بیشتر در مورد عنصر break ، مشخصات W3 را ببینید.
صفات
| صفت | توضیحات |
|---|---|
time | طول وقفه را بر حسب ثانیه یا میلی ثانیه تنظیم می کند (به عنوان مثال "3 ثانیه" یا "250 میلی ثانیه"). |
strength | قدرت شکست عروضی خروجی را با عبارات نسبی تنظیم می کند. مقادیر معتبر عبارتند از: "x-ضعیف"، "متوسط"، "قوی" و "x-strong". مقدار "none" نشان می دهد که هیچ مرز شکست عروضی نباید خروجی داشته باشد، که می تواند برای جلوگیری از شکست عروضی که در غیر این صورت پردازنده تولید میکند. |
مثال
مثال زیر نحوه استفاده از عنصر <break> را برای مکث بین مراحل نشان می دهد:
<speak> Step 1, take a deep breath. <break time="200ms"/> Step 2, exhale. Step 3, take a deep breath again. <break strength="weak"/> Step 4, exhale. </speak>
<say‑as>
این عنصر به شما امکان می دهد اطلاعات مربوط به نوع ساختار متن موجود در عنصر را نشان دهید. همچنین به تعیین سطح جزئیات برای رندر متن موجود کمک می کند.
عنصر <say‑as> دارای ویژگی مورد نیاز، interpret-as که نحوه بیان مقدار را تعیین می کند. format و detail ویژگی های اختیاری ممکن است بسته به مقدار خاص interpret-as استفاده شود.
نمونه ها
ویژگی interpret-as از مقادیر زیر پشتیبانی می کند:
-
currencyمثال زیر به صورت "چهل و دو دلار و یک سنت" گفته می شود. اگر ویژگی زبان حذف شود، از محلی فعلی استفاده می کند.
<speak> <say-as interpret-as='currency' language='en-US'>$42.01</say-as> </speak> telephoneبه توضیح
interpret-as='telephone'در یادداشت WG W3C SSML 1.0 say-as توجه کنید.مثال زیر به صورت "یک هشت صفر صفر دو صفر دو یک دو یک دو" گفته می شود. اگر ویژگی "google:style" حذف شود، صفر به عنوان حرف O صحبت می کند.
ویژگی "google:style='zero-as-zero'" در حال حاضر فقط در زبان های زبان انگلیسی کار می کند.
<speak> <say-as interpret-as='telephone' google:style='zero-as-zero'>1800-202-1212</say-as> </speak>verbatimیاspell-outمثال زیر حرف به حرف نوشته شده است:
<speak> <say-as interpret-as="verbatim">abcdefg</say-as> </speak>-
dateویژگی
formatدنباله ای از کدهای کاراکتر فیلد تاریخ است. کدهای کاراکتر فیلد پشتیبانی شده درformat{y,m,d} به ترتیب برای سال، ماه و روز (از ماه) هستند. اگر کد فیلد یک بار برای سال، ماه یا روز ظاهر شود، تعداد ارقام مورد انتظار به ترتیب 4، 2 و 2 است. اگر کد فیلد تکرار شود، تعداد ارقام مورد انتظار تعداد دفعاتی است که کد تکرار می شود. فیلدهای متن تاریخ ممکن است با علائم نگارشی و/یا فاصله از هم جدا شوند.ویژگی
detailشکل گفتاری تاریخ را کنترل می کند. برایdetail='1'فقط فیلدهای روز و یکی از فیلدهای ماه یا سال مورد نیاز است، اگرچه هر دو ممکن است ارائه شوند. این پیش فرض زمانی است که کمتر از هر سه فیلد داده شود. شکل گفتاری «{روز ترتیبی} از {ماه}، {سال}» است.مثال زیر به عنوان "دهم سپتامبر، نوزده و شصت" گفته می شود:
<speak> <say-as interpret-as="date" format="yyyymmdd" detail="1"> 1960-09-10 </say-as> </speak>مثال زیر به عنوان "دهم سپتامبر" گفته می شود:
<speak> <say-as interpret-as="date" format="dm">10-9</say-as> </speak>برای
detail='2'فیلدهای روز، ماه و سال مورد نیاز است و زمانی که هر سه فیلد ارائه میشوند، این پیشفرض است. شکل گفتاری "{month} {ordinal day}, {year}" است.مثال زیر به عنوان "دهم سپتامبر نوزده و شصت" گفته می شود:
<speak> <say-as interpret-as="date" format="dmy" detail="2"> 10-9-1960 </say-as> </speak> -
charactersمثال زیر به صورت "CAN" گفته می شود:
<speak> <say-as interpret-as="characters">can</say-as> </speak> -
cardinalمثال زیر به صورت «دوازده هزار و سیصد و چهل و پنج» (برای انگلیسی ایالات متحده) یا «دوازده هزار و سیصد و چهل و پنج (برای انگلیسی بریتانیا)» گفته می شود:
<speak> <say-as interpret-as="cardinal">12345</say-as> </speak> -
ordinalمثال زیر به صورت "اول" گفته می شود:
<speak> <say-as interpret-as="ordinal">1</say-as> </speak> -
fractionمثال زیر به صورت "پنج و نیم" گفته می شود:
<speak> <say-as interpret-as="fraction">5+1/2</say-as> </speak> -
expletiveیاbleepمثال زیر به عنوان یک بوق ظاهر می شود، گویی سانسور شده است:
<speak> <say-as interpret-as="expletive">censor this</say-as> </speak> -
unitواحدها را بسته به عدد به مفرد یا جمع تبدیل می کند. مثال زیر به صورت "10 فوت" گفته می شود:
<speak> <say-as interpret-as="unit">10 foot</say-as> </speak> -
timeمثال زیر به صورت «دو و نیم بعد از ظهر» گفته میشود:
<speak> <say-as interpret-as="time" format="hms12">2:30pm</say-as> </speak>ویژگی
formatدنباله ای از کدهای کاراکتر فیلد زمانی است. کدهای کاراکتر فیلد پشتیبانی شده درformatعبارتند از {h,m,s,Z,12,24} برای ساعت، دقیقه (از ساعت)، ثانیه (از دقیقه)، منطقه زمانی، زمان 12 ساعته، و زمان 24 ساعته به ترتیب. اگر کد فیلد یک بار برای ساعت، دقیقه یا ثانیه ظاهر شود، تعداد ارقام مورد انتظار به ترتیب 1، 2 و 2 است. اگر کد فیلد تکرار شود، تعداد ارقام مورد انتظار تعداد دفعاتی است که کد تکرار می شود. فیلدهای متن زمان ممکن است با علائم نگارشی و/یا فاصله از هم جدا شوند. اگر ساعت، دقیقه یا ثانیه در قالب مشخص نشده باشد یا ارقام منطبقی وجود نداشته باشد، فیلد به عنوان مقدار صفر در نظر گرفته می شود.formatپیش فرض "hms12" است.ویژگی
detailکنترل میکند که فرم گفتاری زمان ۱۲ ساعته یا ۲۴ ساعته باشد. فرم گفتاری زمان 24 ساعته است اگرdetail='1'یا اگرdetailحذف شده باشد و قالب زمان 24 ساعته است. فرم گفتاری 12 ساعت زمان است اگرdetail='2'یا اگرdetailحذف شده باشد و قالب زمان 12 ساعت است.
برای کسب اطلاعات بیشتر در مورد عنصر say-as ، مشخصات W3 را ببینید.
<audio>
از درج فایل های صوتی ضبط شده و درج فرمت های صوتی دیگر در ارتباط با خروجی گفتار سنتز شده پشتیبانی می کند.
صفات
| صفت | مورد نیاز | پیش فرض | ارزش ها |
|---|---|---|---|
src | بله | n/a | یک URI که به منبع رسانه صوتی اشاره دارد. پروتکل پشتیبانی شده https است. |
clipBegin | نه | 0 | یک TimeDesignation که از ابتدای منبع صوتی برای شروع پخش از آن فاصله دارد. اگر این مقدار بیشتر یا مساوی مدت زمان واقعی منبع صوتی باشد، هیچ صوتی درج نمی شود. |
clipEnd | نه | بی نهایت | یک TimeDesignation که فاصله منبع صوتی از شروع تا پایان پخش در آن است. اگر مدت زمان واقعی منبع صوتی کمتر از این مقدار باشد، پخش در آن زمان به پایان می رسد. اگر clipBegin بزرگتر یا مساوی با clipEnd باشد، هیچ صوتی درج نمی شود. |
speed | نه | 100% | نسبت نرخ پخش خروجی نسبت به نرخ ورودی عادی که به صورت درصد بیان می شود. فرمت یک عدد واقعی مثبت و به دنبال آن ٪ است. محدوده پشتیبانی شده در حال حاضر [50٪ (آهسته - نیم سرعت)، 200٪ (سریع - سرعت دو برابر)] است. مقادیر خارج از آن محدوده ممکن است (یا نه) تنظیم شوند تا در آن قرار گیرند. |
repeatCount | نه | 1 یا 10 اگر repeatDur تنظیم شده باشد | یک عدد واقعی که مشخص میکند چند بار صدا را وارد کنید (پس از کلیپ کردن، در صورت وجود، توسط clipBegin و/یا clipEnd ). تکرارهای کسری پشتیبانی نمی شوند، بنابراین مقدار به نزدیکترین عدد صحیح گرد می شود. صفر یک مقدار معتبر نیست و بنابراین به عنوان نامشخص تلقی می شود و در آن حالت دارای مقدار پیش فرض است. |
repeatDur | نه | بی نهایت | یک TimeDesignation که محدودیتی در مدت زمان صوتی درج شده پس از پردازش منبع برای ویژگیهای clipBegin ، clipEnd ، repeatCount و speed است (به جای مدت زمان پخش عادی). اگر مدت زمان صدای پردازش شده کمتر از این مقدار باشد، پخش در آن زمان به پایان می رسد. |
soundLevel | نه | +0dB | سطح صدای صدا را با دسی بل soundLevel تنظیم کنید. حداکثر دامنه +/-40dB است اما ممکن است برد واقعی به طور موثر کمتر باشد و کیفیت خروجی ممکن است نتایج خوبی در کل محدوده به همراه نداشته باشد. |
تنظیمات زیر برای صدا پشتیبانی می شود:
- فرمت: MP3 (MPEG v2)
- 24 هزار نمونه در ثانیه
- 24K ~ 96K بیت در ثانیه، نرخ ثابت
- فرمت: Opus در Ogg
- 24 هزار نمونه در ثانیه (باند فوق العاده)
- 24K - 96K بیت در ثانیه، نرخ ثابت
- فرمت (منسوخ شده): WAV (RIFF)
- PCM 16 بیتی امضا شده، اندیان کوچک
- 24 هزار نمونه در ثانیه
- برای همه فرمت ها:
- تک کانال ترجیح داده می شود، اما استریو قابل قبول است.
- حداکثر مدت زمان 240 ثانیه اگر میخواهید صدا را با مدت زمان طولانیتری پخش کنید، پاسخ رسانه را در نظر بگیرید.
- محدودیت حجم فایل 5 مگابایت
- URL منبع باید از پروتکل HTTPS استفاده کند.
- UserAgent ما هنگام واکشی صدا "Google-Speech-Actions" است.
محتویات عنصر <audio> اختیاری است و اگر فایل صوتی قابل پخش نباشد یا دستگاه خروجی از صدا پشتیبانی نمی کند استفاده می شود. محتویات ممکن است شامل یک عنصر <desc> باشند که در این صورت از محتوای متنی آن عنصر برای نمایش استفاده می شود. برای اطلاعات بیشتر، بخش صدای ضبط شده را در چک لیست پاسخ ها ببینید.
URL src نیز باید یک URL https باشد ( Google Cloud Storage میتواند فایلهای صوتی شما را در یک URL https میزبانی کند).
برای کسب اطلاعات بیشتر در مورد پاسخ های رسانه ها، بخش پاسخ رسانه ها را در راهنمای پاسخ ها ببینید.
برای کسب اطلاعات بیشتر در مورد عنصر audio ، به مشخصات W3 مراجعه کنید.
مثال
<speak> <audio src="cat_purr_close.ogg"> <desc>a cat purring</desc> PURR (sound didn't load) </audio> </speak>
<p>,<s>
جمله و عناصر پاراگراف.
برای اطلاعات بیشتر در مورد عناصر p و s ، مشخصات W3 را ببینید.
مثال
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
بهترین شیوه ها
- از تگ های <s>...</s> برای قرار دادن جملات کامل استفاده کنید، به خصوص اگر حاوی عناصر SSML باشند که عروض را تغییر می دهند (یعنی <audio>، <break>، <emphasis>، <par>، <prosody>، <say-as>، <seq> و <sub>).
- اگر قرار است یک وقفه در گفتار به اندازهای طولانی باشد که بتوانید آن را بشنوید، از برچسبهای <s>...</s> استفاده کنید و آن فاصله را بین جملهها قرار دهید.
<sub>
نشان دهید که متن موجود در مقدار مشخصه مستعار جایگزین متن موجود برای تلفظ می شود.
همچنین می توانید از عنصر sub برای ارائه تلفظ ساده کلمه ای که خواندن آن مشکل است استفاده کنید. آخرین مثال زیر این مورد استفاده را در ژاپنی نشان می دهد.
برای کسب اطلاعات بیشتر در مورد عنصر sub ، به مشخصات W3 مراجعه کنید.
نمونه ها
<sub alias="World Wide Web Consortium">W3C</sub>
<sub alias="にっぽんばし">日本橋</sub>
<mark>
یک عنصر خالی که یک نشانگر را در متن یا دنباله برچسب قرار می دهد. می توان از آن برای ارجاع به یک مکان خاص در دنباله یا برای قرار دادن یک نشانگر در جریان خروجی برای اعلان ناهمزمان استفاده کرد.
| صفت | توضیحات | ||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
name | شناسه رشته برای هر علامت. | ||||||||||||||||||||||||||||||||||||||||||
| گزینه | توضیحات |
|---|---|
| نسبی | یک مقدار نسبی را مشخص کنید (مثلاً "کم"، "متوسط"، "بالا" و غیره) که در آن "متوسط" گام پیش فرض است. |
| نیم صداها | به ترتیب با استفاده از "+ N st" یا " -N st" گام را با نیمتونهای " N " افزایش یا کاهش دهید. توجه داشته باشید که "+/-" و "st" مورد نیاز است. |
| درصد | به ترتیب با استفاده از "+ N %" یا "- N %" گام را با " N " درصد افزایش یا کاهش دهید. توجه داشته باشید که "%" مورد نیاز است اما "+/-" اختیاری است. |
برای کسب اطلاعات بیشتر در مورد عنصر prosody ، به مشخصات W3 مراجعه کنید.
مثال
مثال زیر از عنصر <prosody> برای صحبت آهسته در 2 نیمتون پایینتر از حد معمول استفاده میکند:
<prosody rate="slow" pitch="-2st">Can you hear me now?</prosody>
<emphasis>
برای افزودن یا حذف تاکید از متن موجود در عنصر استفاده می شود. عنصر <emphasis> گفتار را مشابه <prosody> تغییر میدهد، اما بدون نیاز به تنظیم ویژگیهای گفتار فردی.
این عنصر از یک ویژگی اختیاری "level" با مقادیر معتبر زیر پشتیبانی می کند:
-
strong -
moderate -
none -
reduced
برای کسب اطلاعات بیشتر در مورد عنصر emphasis ، مشخصات W3 را ببینید.
مثال
مثال زیر از عنصر <emphasis> برای اعلام استفاده می کند:
<emphasis level="moderate">This is an important announcement</emphasis>
<par>
یک محفظه رسانه موازی که به شما امکان می دهد چندین عنصر رسانه را همزمان پخش کنید. تنها محتوای مجاز مجموعه ای از یک یا چند عنصر <par> ، <seq> و <media> است. ترتیب عناصر <media> مهم نیست.
مگر اینکه عنصر فرزند زمان شروع متفاوتی را مشخص کند، زمان شروع ضمنی برای عنصر مشابه ظرف <par> است. اگر عنصر فرزند دارای مقدار آفست برای ویژگی شروع یا پایان خود باشد، افست عنصر نسبت به زمان شروع ظرف <par> خواهد بود. برای عنصر ریشه <par> ، ویژگی start نادیده گرفته می شود و زمان شروع زمانی است که فرآیند سنتز گفتار SSML شروع به تولید خروجی برای عنصر ریشه <par> می کند (یعنی به طور موثر زمان "صفر").
مثال
<speak>
<par>
<media xml:id="question" begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media xml:id="answer" begin="question.end+2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media begin="answer.end-0.2s" soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</par>
</speak> <seq>
یک محفظه رسانه متوالی که به شما امکان می دهد عناصر رسانه را یکی پس از دیگری پخش کنید. تنها محتوای مجاز مجموعه ای از یک یا چند عنصر <seq> ، <par> و <media> است. ترتیب عناصر رسانه ترتیبی است که در آن ارائه می شوند.
ویژگی های شروع و پایان عناصر فرزند را می توان روی مقادیر افست تنظیم کرد ( مشخصات زمان را در زیر ببینید). مقادیر افست آن عناصر فرزند نسبت به انتهای عنصر قبلی در دنباله یا در مورد اولین عنصر در دنباله، نسبت به ابتدای ظرف <seq> آن خواهد بود.
مثال
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak> <media>
یک لایه رسانه را در یک عنصر <par> یا <seq> نشان می دهد. محتوای مجاز عنصر <media> یک عنصر SSML <speak> یا <audio> است. جدول زیر ویژگی های معتبر برای عنصر <media> را توضیح می دهد.
صفات
| صفت | مورد نیاز | پیش فرض | ارزش ها |
|---|---|---|---|
| xml:id | نه | بدون ارزش | یک شناسه XML منحصر به فرد برای این عنصر. موجودیت های رمزگذاری شده پشتیبانی نمی شوند. مقادیر شناسه مجاز با عبارت منظم "([-_#]|\p{L}|\p{D})+" مطابقت دارد. برای اطلاعات بیشتر به XML-ID مراجعه کنید. |
| آغاز شود | نه | 0 | زمان شروع این ظرف رسانه ای. اگر این عنصر محفظه رسانه ریشه باشد، نادیده گرفته میشود (با پیشفرض «0» رفتار میشود). برای مقادیر رشته معتبر به بخش مشخصات زمان در زیر مراجعه کنید. |
| پایان | نه | بدون ارزش | مشخصاتی برای زمان پایان برای این ظرف رسانه. برای مقادیر رشته معتبر به بخش مشخصات زمان در زیر مراجعه کنید. |
| تکرار شمارش | نه | 1 | یک عدد واقعی که مشخص می کند چند بار رسانه را وارد کنید. تکرارهای کسری پشتیبانی نمی شوند، بنابراین مقدار به نزدیکترین عدد صحیح گرد می شود. صفر یک مقدار معتبر نیست و بنابراین به عنوان نامشخص تلقی می شود و در آن حالت دارای مقدار پیش فرض است. |
| تکرار دور | نه | بدون ارزش | یک TimeDesignation که محدودیتی در مدت زمان رسانه درج شده است. اگر مدت زمان رسانه کمتر از این مقدار باشد، پخش در آن زمان به پایان می رسد. |
| سطح صدا | نه | +0dB | سطح صدای صدا را با دسی بل soundLevel تنظیم کنید. حداکثر دامنه +/-40dB است اما ممکن است برد واقعی به طور موثر کمتر باشد و کیفیت خروجی ممکن است نتایج خوبی در کل محدوده به همراه نداشته باشد. |
| fadeInDur | نه | 0s | یک TimeDesignation که طی آن رسانه از حالت بی صدا به soundLevel که به صورت اختیاری مشخص شده است، محو می شود. اگر مدت زمان رسانه کمتر از این مقدار باشد، محو شدن در پایان پخش متوقف می شود و سطح صدا به سطح صدای مشخص شده نمی رسد. |
| fadeOutDur | نه | 0s | یک TimeDesignation که در طی آن رسانه از soundLevel که به صورت اختیاری مشخص شده است تا زمانی که سایلنت شود محو می شود. اگر مدت زمان رسانه کمتر از این مقدار باشد، سطح صدا روی مقدار کمتری تنظیم می شود تا اطمینان حاصل شود که در پایان پخش به سکوت می رسد. |
مشخصات زمان
یک مشخصه زمانی، که برای مقدار ویژگیهای «شروع» و «پایان» عناصر <media> و محفظههای رسانه (عناصر <par> و <seq> ) استفاده میشود، یا مقدار افست است (مثلاً +2.5s ) یا یک مقدار syncbase (به عنوان مثال، foo_id.end-250ms ).
- مقدار افست - مقدار افست زمان یک مقدار زمان شمارش SMIL است که به مقادیری اجازه می دهد که با عبارت منظم مطابقت داشته باشند:
"\s\*(+|-)?\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"رشته رقم اول تمام قسمت عدد اعشاری و رشته رقم دوم قسمت کسری اعشاری است. علامت پیش فرض (یعنی "(+|-)؟") "+" است. مقادیر واحد به ترتیب مربوط به ساعت، دقیقه، ثانیه و میلی ثانیه است. پیش فرض برای واحدها "s" (ثانیه) است.
- مقدار Syncbase - یک مقدار syncbase یک مقدار همگامسازی SMIL است که به مقادیری اجازه میدهد که با عبارت منظم مطابقت داشته باشند:
"([-_#]|\p{L}|\p{D})+\.(begin|end)\s\*(+|-)\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"ارقام و واحدها به همان روشی به عنوان مقدار افست تفسیر می شوند.
شبیه ساز TTS
کنسول Actions شامل یک شبیه ساز TTS است که می توانید از آن برای آزمایش SSML با هر یک از عناصر بالا استفاده کنید. میتوانید شبیهساز TTS را در کنسول زیر Simulator > Audio پیدا کنید. متن و SSML خود را در شبیه ساز تایپ کنید و روی Update و Listen کلیک کنید تا خروجی TTS را بشنوید.
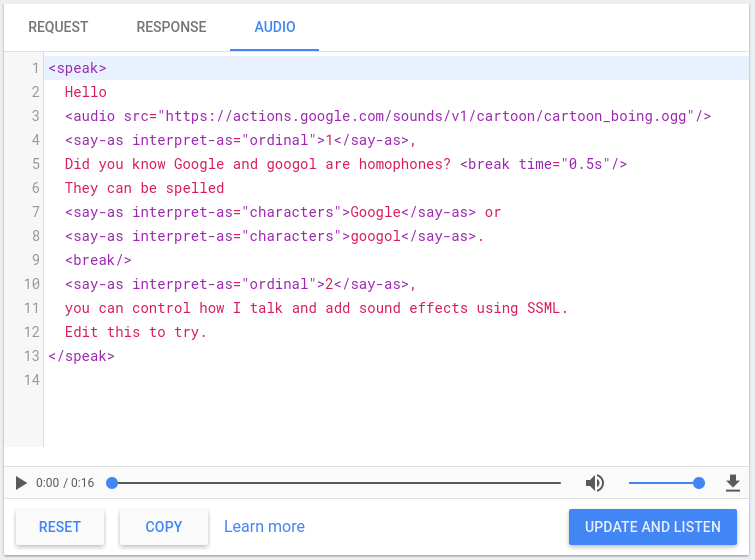
همچنین می توانید برای ذخیره یک فایل .mp3 از خروجی TTS خود، روی دکمه دانلود کلیک کنید.
جز در مواردی که غیر از این ذکر شده باشد،محتوای این صفحه تحت مجوز Creative Commons Attribution 4.0 License است. نمونه کدها نیز دارای مجوز Apache 2.0 License است. برای اطلاع از جزئیات، به خطمشیهای سایت Google Developers مراجعه کنید. جاوا علامت تجاری ثبتشده Oracle و/یا شرکتهای وابسته به آن است.
تاریخ آخرین بهروزرسانی 2026-02-18 بهوقت ساعت هماهنگ جهانی.