
Użyj wizualnej odpowiedzi wyboru, jeśli chcesz, aby użytkownik wybrał jedną z kilku kilku opcji aby kontynuować działanie. Możesz użyć tych elementów wizualnych typy odpowiedzi związanych z wyborem w prompcie:
- Lista
- Kolekcja
- Przeglądanie kolekcji
Podczas definiowania wizualnej odpowiedzi do wyboru użyj kandydata z parametrem
RICH_RESPONSE, dzięki czemu Asystent Google zwraca tylko
na obsługiwanych urządzeniach. Możesz użyć tylko jednej odpowiedzi rozszerzonej na content
w prompcie.
Dodawanie wizualnej odpowiedzi do wyboru
Odpowiedzi wyboru wizualnego wykorzystują wypełnienie przedziału, aby przedstawić opcje. który użytkownik może wybrać i obsługiwać zaznaczony element. Gdy użytkownicy wybiorą produkt, Asystent przekazuje wybraną wartość elementu do webhooka jako argument. Następnie: jako wartość argumentu otrzymasz klucz dla wybranego elementu.
Aby używać wizualnej odpowiedzi wyboru, musisz zdefiniować typ, który reprezentuje odpowiedź, którą użytkownik później wybiera. W webhooku możesz zastąpić te ustawienia z treścią, którą chcesz wyświetlić do wyboru.
Aby w kreatorze działań dodać wizualną odpowiedź wyboru do sceny, wykonaj te czynności: kroki:
- W scenie dodaj boks w sekcji Wypełnianie przedziałów.
- Wybierz wcześniej zdefiniowany typ wizualnej odpowiedzi wyboru i nadaj mu nazwę. Webhook używa tej nazwy boksu, aby później odwoływać się do typu.
- Zaznacz pole Wywołaj webhooka i podaj nazwę modułu obsługi zdarzeń. w webhooku, którego chcesz używać w wizualnej odpowiedzi umożliwiającej wybór.
- Zaznacz pole Wyślij prośby.
- W prompcie podaj odpowiednią treść JSON lub YAML na podstawie wizualną odpowiedź wyboru, którą chcesz zwrócić.
- W webhooku wykonaj czynności opisane w sekcji Obsługa wybranych elementów.
W sekcjach dotyczących listy, kolekcji i przeglądania kolekcji znajdziesz dostępne właściwości promptów i przykłady ich zastępowania .
Obsługa wybranych elementów
Odpowiedzi wyboru wizualnego wymagają obsługi wyboru użytkownika w przez webhooka. Gdy użytkownik wybierze coś z wizualnej odpowiedzi wyboru, Asystent Google wypełnia pole tą wartością.
W poniższym przykładzie kod webhooka odbiera i przechowuje wybraną opcję w zmiennej:
Node.js
app.handle('Option', conv => { // Note: 'prompt_option' is the name of the slot. const selectedOption = conv.session.params.prompt_option; conv.add(`You selected ${selectedOption}.`); });
JSON
{ "responseJson": { "session": { "id": "session_id", "params": { "prompt_option": "ITEM_1" } }, "prompt": { "override": false, "firstSimple": { "speech": "You selected ITEM_1.", "text": "You selected ITEM_1." } } } }
Lista
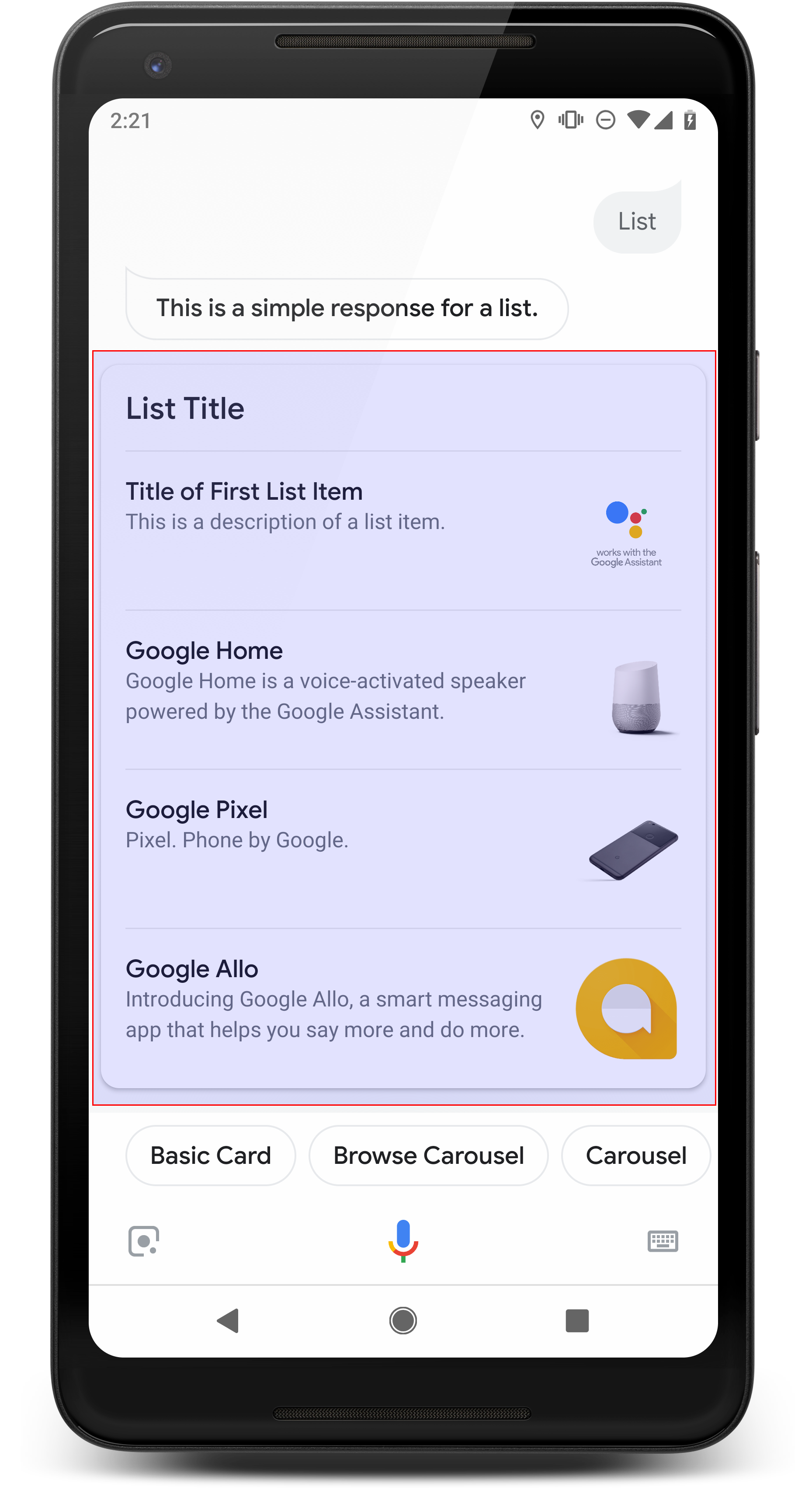
Lista przedstawia użytkownikom pionową listę wielu elementów, która umożliwia im wybierz jedną z nich, używając dotyku lub rozpoznawania mowy. Gdy użytkownik wybierze pozycję na liście, Asystent generuje zapytanie użytkownika (dymek czatu) zawierające tytuł listy elementu.
Listy są przydatne, gdy trzeba rozróżnić opcje lub gdy użytkownik musi wybrać opcje, które mają zostać przeskanowane w całości. Dla: np. „Piotr” czy chcesz porozmawiać z Peterem Jonsem albo Peterem Hansem?
Listy muszą zawierać od 2 do 30 pozycji. Liczba wyświetlane początkowo elementy zależą od urządzenia użytkownika i najczęstszych liczba to 10 elementów.
Tworzenie listy
Gdy tworzysz listę, prompt zawiera tylko klucze do każdej pozycji wykonanej przez użytkownika
który można wybrać. W webhooku definiujesz elementy odpowiadające tym kluczom.
na podstawie typu Entry.
Elementy listy zdefiniowane jako obiekty Entry mają następujący wygląd
cechy:
- tytuł,
- Stały rozmiar i rozmiar czcionki
- Maksymalna długość: 1 wiersz (obcięty wielokropkiem...)
- Wymagana jest niepowtarzalność (aby można było wybrać głos)
- Opis (opcjonalnie)
- Stały rozmiar i rozmiar czcionki
- Maksymalna długość: 2 wiersze (obcięte wielokropkiem...)
- Obraz (opcjonalnie)
- Rozmiar: 48 x 48 piks.
Odpowiedzi wyboru wizualnego wymagają zastąpienia typu nazwą jego boksu za pomocą
typu środowiska wykonawczego w trybie TYPE_REPLACE. W webhooku
modułu obsługi zdarzeń, odwołaj się do typu do zastąpienia nazwą jego przedziału (zdefiniowanego w
Dodawanie wybranych odpowiedzi) we właściwości name.
Po zastąpieniu typu wynikowy typ reprezentuje listę elementów użytkownik może wybrać jeden z wyświetlaczy Asystenta.
Właściwości
Typ odpowiedzi typu lista ma te właściwości:
| Właściwość | Typ | Co musisz zrobić | Opis |
|---|---|---|---|
items |
tablica ListItem |
Wymagane | Reprezentuje element na liście, który użytkownicy mogą wybrać. Każdy
ListItem zawiera klucz mapowany na wskazany typ dla
elementu listy. |
title |
ciąg znaków | Opcjonalnie | Zwykły tytuł listy (ograniczony do jednego wiersza). Jeśli nie ma tytułu wartość zostanie zwinięta. |
subtitle |
ciąg znaków | Opcjonalnie | Podtytuł listy w postaci zwykłego tekstu. |
Przykładowy kod
Poniższe przykłady określają treść promptu w kodzie webhooka lub w Odpowiedź webhooka JSON. Możesz jednak zdefiniować treść promptu w Actions Builder (w formacie YAML lub JSON).
Node.js
const ASSISTANT_LOGO_IMAGE = new Image({ url: 'https://developers.google.com/assistant/assistant_96.png', alt: 'Google Assistant logo' }); app.handle('List', conv => { conv.add('This is a list.'); // Override type based on slot 'prompt_option' conv.session.typeOverrides = [{ name: 'prompt_option', mode: 'TYPE_REPLACE', synonym: { entries: [ { name: 'ITEM_1', synonyms: ['Item 1', 'First item'], display: { title: 'Item #1', description: 'Description of Item #1', image: ASSISTANT_LOGO_IMAGE, } }, { name: 'ITEM_2', synonyms: ['Item 2', 'Second item'], display: { title: 'Item #2', description: 'Description of Item #2', image: ASSISTANT_LOGO_IMAGE, } }, { name: 'ITEM_3', synonyms: ['Item 3', 'Third item'], display: { title: 'Item #3', description: 'Description of Item #3', image: ASSISTANT_LOGO_IMAGE, } }, { name: 'ITEM_4', synonyms: ['Item 4', 'Fourth item'], display: { title: 'Item #4', description: 'Description of Item #4', image: ASSISTANT_LOGO_IMAGE, } }, ] } }]; // Define prompt content using keys conv.add(new List({ title: 'List title', subtitle: 'List subtitle', items: [ { key: 'ITEM_1' }, { key: 'ITEM_2' }, { key: 'ITEM_3' }, { key: 'ITEM_4' } ], })); });
JSON
{ "responseJson": { "session": { "id": "session_id", "params": {}, "typeOverrides": [ { "name": "prompt_option", "synonym": { "entries": [ { "name": "ITEM_1", "synonyms": [ "Item 1", "First item" ], "display": { "title": "Item #1", "description": "Description of Item #1", "image": { "alt": "Google Assistant logo", "height": 0, "url": "https://developers.google.com/assistant/assistant_96.png", "width": 0 } } }, { "name": "ITEM_2", "synonyms": [ "Item 2", "Second item" ], "display": { "title": "Item #2", "description": "Description of Item #2", "image": { "alt": "Google Assistant logo", "height": 0, "url": "https://developers.google.com/assistant/assistant_96.png", "width": 0 } } }, { "name": "ITEM_3", "synonyms": [ "Item 3", "Third item" ], "display": { "title": "Item #3", "description": "Description of Item #3", "image": { "alt": "Google Assistant logo", "height": 0, "url": "https://developers.google.com/assistant/assistant_96.png", "width": 0 } } }, { "name": "ITEM_4", "synonyms": [ "Item 4", "Fourth item" ], "display": { "title": "Item #4", "description": "Description of Item #4", "image": { "alt": "Google Assistant logo", "height": 0, "url": "https://developers.google.com/assistant/assistant_96.png", "width": 0 } } } ] }, "typeOverrideMode": "TYPE_REPLACE" } ] }, "prompt": { "override": false, "content": { "list": { "items": [ { "key": "ITEM_1" }, { "key": "ITEM_2" }, { "key": "ITEM_3" }, { "key": "ITEM_4" } ], "subtitle": "List subtitle", "title": "List title" } }, "firstSimple": { "speech": "This is a list.", "text": "This is a list." } } } }
Kolekcja
Kolekcja przewija się w poziomie i umożliwia użytkownikom wybranie jednego elementu dotykiem lub rozpoznawania mowy. W porównaniu z listami kolekcje mają duże kafelki. bogatsze treści. kafelki składające się na kolekcję są podobne do kafelków, podstawowa karta z obrazem. Gdy użytkownik wybierze element z kolekcji, Asystent generuje zapytanie użytkownika (dymek czatu) zawierające tytuł produktu.
Kolekcje są przydatne, gdy użytkownikowi są przedstawiane różne opcje. nie jest wymagane bezpośrednie porównanie (w przeciwieństwie do list). Ogólnie rzecz biorąc, preferujesz list do kolekcji, ponieważ listy można łatwiej przeglądać i interakcji głosowych.
Kolekcje muszą zawierać od 2 do 10 kafelków. Wł. urządzenia z obsługą wyświetlania, użytkownicy mogą przewijać karty, przesuwając palcem w lewo lub w prawo. w kolekcji, zanim wybierzesz element.
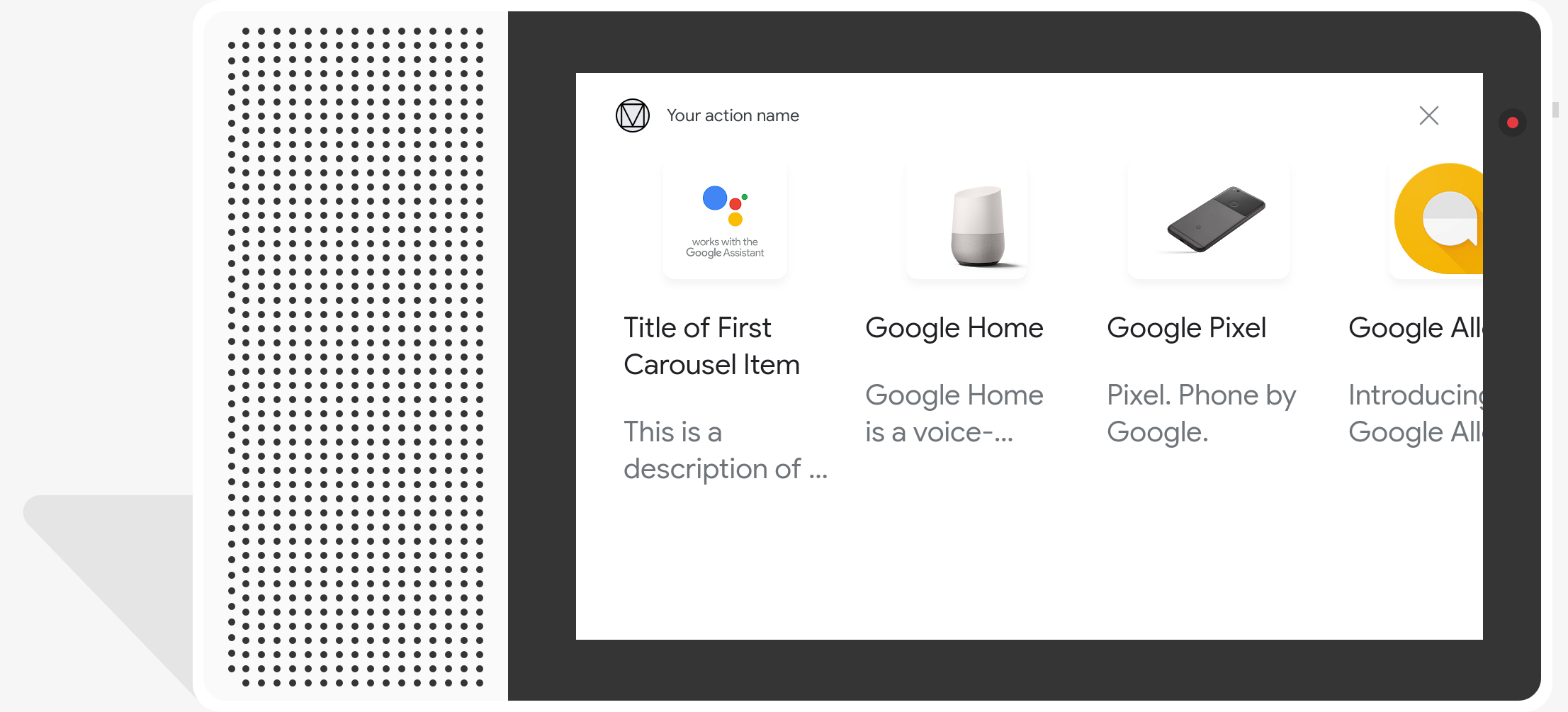
Tworzenie kolekcji
Podczas tworzenia kolekcji prompt zawiera tylko klucze do każdego elementu, którego
który użytkownik może wybrać. W webhooku definiujesz elementy odpowiadające tym
na podstawie typu Entry.
Elementy kolekcji zdefiniowane jako obiekty Entry mają następujący wygląd
cechy:
- Obraz (opcjonalnie)
- Wymuszony rozmiar obrazu to 128 dp (wysokość) i 232 dp (szerokość)
- Jeśli współczynnik proporcji obrazu nie pasuje do ramki ograniczającej obrazu, obraz jest wyśrodkowany i ma słupki po obu stronach.
- Jeśli link do zdjęcia nie działa, zamiast niego używany jest obraz zastępczy
- Tytuł (wymagany)
- Zwykły tekst. Markdown nie jest obsługiwany. Takie same opcje formatowania jak w podstawowa odpowiedź z informacjami o kartach
- Wysokość karty zwija się, jeśli nie podasz tytułu.
- Wymagana jest niepowtarzalność (aby można było wybrać głos)
- Opis (opcjonalnie)
- Zwykły tekst. Markdown nie jest obsługiwany. Takie same opcje formatowania jak w podstawowa odpowiedź z informacjami o kartach
Odpowiedzi wyboru wizualnego wymagają zastąpienia typu nazwą jego boksu za pomocą
typu środowiska wykonawczego w trybie TYPE_REPLACE. W webhooku
modułu obsługi zdarzeń, odwołaj się do typu do zastąpienia nazwą jego przedziału (zdefiniowanego w
Dodawanie wybranych odpowiedzi) we właściwości name.
Po zastąpieniu typu wynikowy typ reprezentuje zbiór funkcji które użytkownik może wybrać z listy wyświetlanych przez Asystenta.
Właściwości
Typ odpowiedzi dotyczącej kolekcji ma te właściwości:
| Właściwość | Typ | Co musisz zrobić | Opis |
|---|---|---|---|
items |
tablica CollectionItem |
Wymagane | Reprezentuje element w kolekcji, który użytkownicy mogą wybrać. Każdy
CollectionItem zawiera klucz mapowany na wskazany typ
dla elementu kolekcji. |
title |
ciąg znaków | Opcjonalnie | Zwykły tytuł kolekcji. Tytuły muszą być unikalne w aby umożliwić wybór głosu. |
subtitle |
ciąg znaków | Opcjonalnie | Podtytuł ze zwykłym tekstem kolekcji. |
image_fill |
ImageFill |
Opcjonalnie | Obramowanie między kartą a kontenerem obrazu, które ma być używane, gdy współczynnik proporcji obrazu nie pasuje do proporcji kontenera obrazu współczynnik proporcji. |
Przykładowy kod
Poniższe przykłady określają treść promptu w kodzie webhooka lub w Odpowiedź webhooka JSON. Możesz jednak zdefiniować treść promptu w Actions Builder (w formacie YAML lub JSON).
Node.js
const ASSISTANT_LOGO_IMAGE = new Image({ url: 'https://developers.google.com/assistant/assistant_96.png', alt: 'Google Assistant logo' }); app.handle('Collection', conv => { conv.add("This is a collection."); // Override type based on slot 'prompt_option' conv.session.typeOverrides = [{ name: 'prompt_option', mode: 'TYPE_REPLACE', synonym: { entries: [ { name: 'ITEM_1', synonyms: ['Item 1', 'First item'], display: { title: 'Item #1', description: 'Description of Item #1', image: ASSISTANT_LOGO_IMAGE, } }, { name: 'ITEM_2', synonyms: ['Item 2', 'Second item'], display: { title: 'Item #2', description: 'Description of Item #2', image: ASSISTANT_LOGO_IMAGE, } }, { name: 'ITEM_3', synonyms: ['Item 3', 'Third item'], display: { title: 'Item #3', description: 'Description of Item #3', image: ASSISTANT_LOGO_IMAGE, } }, { name: 'ITEM_4', synonyms: ['Item 4', 'Fourth item'], display: { title: 'Item #4', description: 'Description of Item #4', image: ASSISTANT_LOGO_IMAGE, } }, ] } }]; // Define prompt content using keys conv.add(new Collection({ title: 'Collection Title', subtitle: 'Collection subtitle', items: [ { key: 'ITEM_1' }, { key: 'ITEM_2' }, { key: 'ITEM_3' }, { key: 'ITEM_4' } ], })); });
JSON
{ "responseJson": { "session": { "id": "ABwppHHz--uQEEy3CCOANyB0J58oF2Yw5JEX0oXwit3uxDlRwzbEIK3Bcz7hXteE6hWovrLX9Ahpqu8t-jYnQRFGpAUqSuYjZ70", "params": {}, "typeOverrides": [ { "name": "prompt_option", "synonym": { "entries": [ { "name": "ITEM_1", "synonyms": [ "Item 1", "First item" ], "display": { "title": "Item #1", "description": "Description of Item #1", "image": { "alt": "Google Assistant logo", "height": 0, "url": "https://developers.google.com/assistant/assistant_96.png", "width": 0 } } }, { "name": "ITEM_2", "synonyms": [ "Item 2", "Second item" ], "display": { "title": "Item #2", "description": "Description of Item #2", "image": { "alt": "Google Assistant logo", "height": 0, "url": "https://developers.google.com/assistant/assistant_96.png", "width": 0 } } }, { "name": "ITEM_3", "synonyms": [ "Item 3", "Third item" ], "display": { "title": "Item #3", "description": "Description of Item #3", "image": { "alt": "Google Assistant logo", "height": 0, "url": "https://developers.google.com/assistant/assistant_96.png", "width": 0 } } }, { "name": "ITEM_4", "synonyms": [ "Item 4", "Fourth item" ], "display": { "title": "Item #4", "description": "Description of Item #4", "image": { "alt": "Google Assistant logo", "height": 0, "url": "https://developers.google.com/assistant/assistant_96.png", "width": 0 } } } ] }, "typeOverrideMode": "TYPE_REPLACE" } ] }, "prompt": { "override": false, "content": { "collection": { "imageFill": "UNSPECIFIED", "items": [ { "key": "ITEM_1" }, { "key": "ITEM_2" }, { "key": "ITEM_3" }, { "key": "ITEM_4" } ], "subtitle": "Collection subtitle", "title": "Collection Title" } }, "firstSimple": { "speech": "This is a collection.", "text": "This is a collection." } } } }
Przeglądanie kolekcji
Podobnie jak kolekcja, przeglądanie kolekcji stanowi bogatą odpowiedź który umożliwia przewijanie kart opcji. Obecne przeglądanie kolekcji: zaprojektowany specjalnie pod kątem treści internetowych i otwiera wybrany kafelek w sieci przeglądarki (lub przeglądarki AMP, jeśli wszystkie kafelki obsługują AMP).
Odpowiedzi podczas przeglądania kolekcji zawierają od 2 do 10 kafelków. Wł. urządzenia z obsługą wyświetlania, użytkownicy mogą przewijać karty, przesuwając palcem w górę lub w dół. .
Tworzenie przeglądania kolekcji
Tworząc przeglądanie kolekcji, zastanów się, jak użytkownicy będą wchodzić w interakcję
. Każda funkcja przeglądania kolekcji (item) otwiera swój zdefiniowany adres URL, dlatego podaj przydatne informacje
dane użytkownikowi.
Elementy przeglądania kolekcji mają następujące cechy wyświetlania:
- Obraz (opcjonalnie)
- Wymuszony jest rozmiar wysokości 128 dp i szerokości 232 dp.
- Jeśli współczynnik proporcji obrazu nie pasuje do ramki ograniczającej obrazu, zostanie on
jest wyśrodkowany z paskami po bokach lub u góry i na dole. Kolor
słupki są określane przez właściwość przeglądania kolekcji
ImageFill. - Jeśli link do zdjęcia nie działa, zamiast niego używany jest obraz zastępczy.
- Tytuł (wymagany)
- Zwykły tekst. Markdown nie jest obsługiwany. Takie samo formatowanie jak na karcie podstawowej odpowiedź rozszerzona.
- Wysokość karty zwija się, jeśli nie określono tytułu.
- Opis (opcjonalnie)
- Zwykły tekst. Markdown nie jest obsługiwany. Takie samo formatowanie jak na karcie podstawowej odpowiedź rozszerzona.
- Stopka (opcjonalnie)
- zwykły tekst; Format Markdown nie jest obsługiwany.
Właściwości
Typ odpowiedzi dotyczącej przeglądania kolekcji ma te właściwości:
| Właściwość | Typ | Co musisz zrobić | Opis |
|---|---|---|---|
item |
Obiekt | Wymagane | Reprezentuje element w kolekcji, który użytkownicy mogą wybrać. |
image_fill |
ImageFill |
Opcjonalnie | Obramowanie między kartą a kontenerem obrazu, które ma być używane, gdy współczynnik proporcji obrazu nie pasuje do współczynnika proporcji kontenera obrazu. |
Przeglądanie kolekcji item ma następujące właściwości:
| Właściwość | Typ | Co musisz zrobić | Opis |
|---|---|---|---|
title |
ciąg znaków | Wymagane | Zwykły tytuł elementu kolekcji. |
description |
ciąg znaków | Opcjonalnie | Opis elementu kolekcji. |
footer |
ciąg znaków | Opcjonalnie | Tekst stopki elementu kolekcji wyświetlany pod opisem. |
image |
Image |
Opcjonalnie | Obraz wyświetlany dla elementu kolekcji. |
openUriAction |
OpenUrl |
Wymagane | Identyfikator URI otwierany po wybraniu elementu kolekcji. |
Przykładowy kod
Poniższe przykłady określają treść promptu w kodzie webhooka lub w Odpowiedź webhooka JSON. Możesz jednak zdefiniować treść promptu w Actions Builder (w formacie YAML lub JSON).
YAML,
candidates: - first_simple: variants: - speech: This is a collection browse. content: collection_browse: items: - title: Item #1 description: Description of Item #1 footer: Footer of Item #1 image: url: 'https://developers.google.com/assistant/assistant_96.png' open_uri_action: url: 'https://www.example.com' - title: Item #2 description: Description of Item #2 footer: Footer of Item #2 image: url: 'https://developers.google.com/assistant/assistant_96.png' open_uri_action: url: 'https://www.example.com' image_fill: WHITE
JSON
{ "candidates": [ { "firstSimple": { "speech": "This is a collection browse.", "text": "This is a collection browse." }, "content": { "collectionBrowse": { "items": [ { "title": "Item #1", "description": "Description of Item #1", "footer": "Footer of Item #1", "image": { "url": "https://developers.google.com/assistant/assistant_96.png" }, "openUriAction": { "url": "https://www.example.com" } }, { "title": "Item #2", "description": "Description of Item #2", "footer": "Footer of Item #2", "image": { "url": "https://developers.google.com/assistant/assistant_96.png" }, "openUriAction": { "url": "https://www.example.com" } } ], "imageFill": "WHITE" } } } ] }
Node.js
// Collection Browse app.handle('collectionBrowse', (conv) => { conv.add('This is a collection browse.'); conv.add(new CollectionBrowse({ 'imageFill': 'WHITE', 'items': [ { 'title': 'Item #1', 'description': 'Description of Item #1', 'footer': 'Footer of Item #1', 'image': { 'url': 'https://developers.google.com/assistant/assistant_96.png' }, 'openUriAction': { 'url': 'https://www.example.com' } }, { 'title': 'Item #2', 'description': 'Description of Item #2', 'footer': 'Footer of Item #2', 'image': { 'url': 'https://developers.google.com/assistant/assistant_96.png' }, 'openUriAction': { 'url': 'https://www.example.com' } } ] })); });
JSON
{ "responseJson": { "session": { "id": "session_id", "params": {}, "languageCode": "" }, "prompt": { "override": false, "content": { "collectionBrowse": { "imageFill": "WHITE", "items": [ { "title": "Item #1", "description": "Description of Item #1", "footer": "Footer of Item #1", "image": { "url": "https://developers.google.com/assistant/assistant_96.png" }, "openUriAction": { "url": "https://www.example.com" } }, { "title": "Item #2", "description": "Description of Item #2", "footer": "Footer of Item #2", "image": { "url": "https://developers.google.com/assistant/assistant_96.png" }, "openUriAction": { "url": "https://www.example.com" } } ] } }, "firstSimple": { "speech": "This is a collection browse.", "text": "This is a collection browse." } } } }