
غالبًا ما يتضمّن تطوير "مهمة" لمنصة "المهام مع مساعد Google" تنفيذ Dialogflow لفهم اللغة الطبيعية (NLU) وتنفيذ Dialogflow الذي يعالج منطق الإجراء الخاص بك. يساعد إجراء اختبارات في قاعدة الرموز في ضمان أداء الإجراء الخاص بك على النحو المتوقّع في مرحلة الإنتاج.
عند تنفيذ اختبارات الوحدات أو عمليات الدمج أو الاختبارات الشاملة في الإجراء الخاص بك، يجب اعتبار أنّ وكيل Dialogflow وتنفيذه مكوّنين منفصلين.
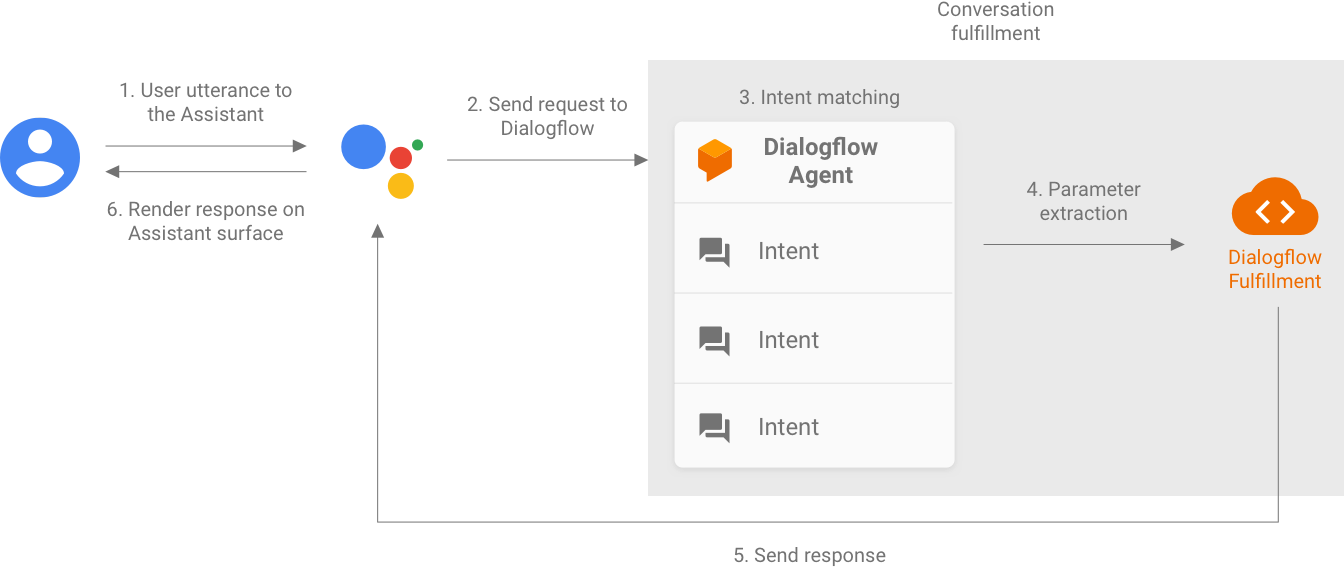
الشكل 1. مخطط انسيابي يصف الأنظمة التي يجب مراعاتها في الاختبار
اختبار وكيل Dialogflow
يتم اختبار وكيل Dialogflow وتنفيذه كمكوّنين منفصلين. توضّح الأقسام الفرعية التالية كيفية تصوّر وكيل Dialogflow لتنفيذ الإجراء الخاص بك واختباره.
Dialogflow كنظام لطلب البحث والهدف
يكون وكيل Dialogflow مسؤولاً عن تلقي طلب المستخدم ومطابقته بهدف واستخراج أي كيانات محددة مسبقًا من طلب البحث. يتفاعل وكيلك مع عملية تنفيذ طلبك من خلال تمرير رسالة تحتوي على الغرض المتطابق ومَعلماته والبيانات الوصفية في "المهام مع مساعد Google".
بصفتك المطوّر، يمكنك التحكّم في إعدادات وكيل Dialogflow، مثل بنية الأهداف والكيانات. تأتي البيانات الوصفية لـ "المهام مع مساعد Google" من "المهام مع مساعد Google"، ويمكن افتراض أنّها تتضمّن البيانات الصحيحة للاختبار.
عند إجراء الاختبارات، ركِّز على جعل الوكيل قادرًا على استخراج معلَمات الأهداف بشكل صحيح ومطابقة طلبات البحث مع الأغراض. يوفّر هذا النهج مقياسًا قابلاً للقياس لتقييم أداء الوكيل. ويمكنك حساب هذا المقياس عن طريق إعداد واستخدام حالات الاختبار الفردية أو مجموعة التحقق.
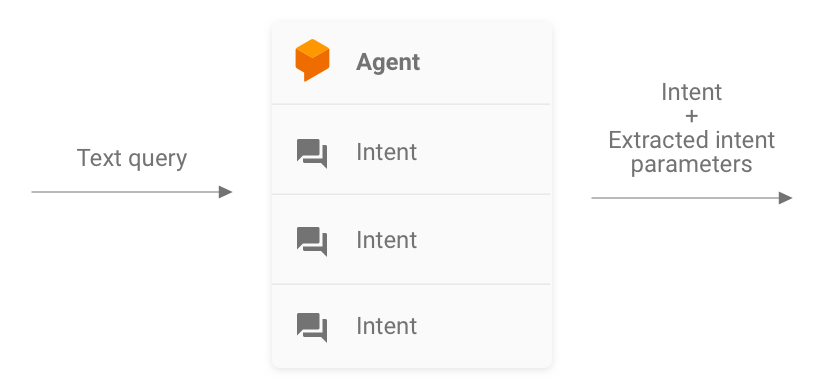
الشكل 2. تمثيل Dialogflow كنظام لطلب البحث والهدف
اختبارات الوحدات
بالنسبة إلى وكيل Dialogflow، يمكنك كتابة اختبارات حيث تتوقع كل حالة طلب بحث نصي كمدخل وتنتج البيانات الوصفية للهدف كمخرجات. يجب أن تحتوي البيانات الوصفية هذه على الأقل على اسم الغرض المطابق وقائمة بالمعلَمات المطابِقة.
تستخدم نقطة نهاية detectIntent في Dialogflow API
طلب البحث النصي كإدخال وتنشئ نتيجة منظَّمة تحتوي على
اسم الغرض الذي تم حله والمعلَمات المستخرَجة. وهذه النتيجة مفيدة لتقييم أداء الوكيل المطابِق للنية. للحصول على مرجع كامل لحقول مفيدة أخرى، يمكنك الاطّلاع على مرجع QueryResult.
يبدو نموذج الاختبار على النحو التالي:
it('choose_fact', async function() {
// The `dialogflow` variable is an abstraction around the API that creates
// and sends payloads to Dialogflow.
const resJson = await dialogflow.detectIntent(
'Tell me about the history of Google');
expect(resJson.queryResult).to.include.deep.keys('parameters');
// Check that Dialogflow extracted required entities from the query.
expect(resJson.queryResult.parameters).to.deep.equal({
'category': 'history',
// Put any other parameters you wish were extracted
});
expect(resJson.queryResult.intent.displayName).to.equal('choose_fact');
});
يستخدم هذا المقتطف Mocha وChai. يمكنك الاطّلاع على المثال الكامل لاختبار وحدة Dialogflow المكتوب في Node.js للمقالة حقائق عن Google.
يمكن تشغيل ملفات الاختبار بالتوازي لأنّ واجهة برمجة تطبيقات Dialogflow تقبل السمة sessionId كوسيطة. ونتيجة لذلك، يمكنك الحصول على وضع حماية منفصل لكل محادثة
أثناء استخدام عميل واجهة برمجة تطبيقات Dialogflow واحد.
بما أنّك ترسل طلبات مقابل واجهة برمجة تطبيقات Dialogflow، قد يتم فرض رسوم في حال بلوغ حصتك من المكالمات المجانية. راجِع الحصص والحدود للحصول على مزيد من المعلومات.
اختبارات الدمج
تؤدي أيضًا نقطة نهاية detectIntent الخاصة بواجهة برمجة تطبيقات Dialogflow
إلى تنفيذ عملية التنفيذ التابعة لجهات خارجية. وبناءً على ذلك، من الممكن كتابة حالات اختبار
تغطي عملية الدمج بين وكيل Dialogflow وتنفيذ
Dialogflow.
يكمن الفرق الرئيسي بين اختبار دمج الكتابة واختبارات الوحدة في Dialogflow في أنّه في اختبار الدمج، يمكنك تأكيد الردود الواردة من الردّ التلقائي على الويب بالإضافة إلى هدف Dialogflow واستخراج الكيان.
راجِع المثال العملي الكامل لاختبار التكامل المكتوب بلغة Node.js في مستودع حقائق عن Google.
اختبار الرد التلقائي على الويب لتنفيذ الطلبات في Dialogflow
يتم اختبار وكيل Dialogflow وتنفيذ Dialogflow كمكوِّنين منفصلين. توضّح الأقسام الفرعية التالية كيفية تصوّر واختبار تنفيذ الإجراء الخاص بك.
معالجة البيانات بتنسيق JSON-in وJSON-out
يتوقع رمز التنفيذ في Dialogflow طلبات وينشئ الردود بتنسيق JSON. نتيجة لذلك، يمكنك اختبار رمز التنفيذ من خلال اعتباره نظام JSON-in وJSON-out. يحتوي الطلب على بيانات وصفية من كلّ من Dialogflow و"المهام مع مساعد Google"، لذا فهو يتضمّن كل ما يلزم لتشغيل معالج معيّن للغرض في عملية التنفيذ.
لاختبار تشغيل معالج الأهداف، ترسل طلب JSON (إدخال) إلى الإجراء الخاص بك. يتم إرسال هذا الطلب إلى عملية التنفيذ، والتي يمكن الوصول إليها على الإنترنت. ينتج عن التنفيذ بعد ذلك استجابة JSON (مخرجات) يمكن تقييمها من أجل التحقّق من صحتها.

الشكل 3. تمثيل التنفيذ بتنسيق JSON-in وJSON-out
اختبارات الوحدات
يمكنك اعتبار رمز الرد التلقائي على الويب الخاص بالتنفيذ كنظام يقبل إدخال JSON وينشئ مخرجات JSON. يتم بعد ذلك تبسيط عملية اختبار "الإجراء" لتقديم طلب إلى عملية التنفيذ والتحقّق من ناتج JSON الناتج.
يمنحك هذا حرية استضافة عملية التنفيذ محليًا وإرسال طلبات HTTP محليًا للاختبار. إذا كنت تستخدم مكتبة عميل Actions on Google Node.js، يمكنك أيضًا إرسال طلبات JSON مباشرةً إلى طبقة البرمجيات الوسيطة لمكتبة العملاء.
إذا اختبرت رمز الرد التلقائي على الويب باستخدام مدخلات JSON وتلقيت نتائج JSON المتوقّعة، يمكنك عندئذٍ أن تقول بثقة معقولة أنّ الأجزاء التي تتحكم فيها تعمل بشكل صحيح. يمكنك افتراض أنّ Dialogflow وActions on Google يعملان بشكل صحيح لأنهما يُنشئان حمولات JSON الصحيحة. يوفر هذا العزل نموذج برمجة مبسط لكتابة الاختبارات.
في ما يلي مخطط عام لعملية الاختبار:
- استخدِم المحاكي في وحدة تحكّم المهام للحصول على طلبات JSON لكل خطوة في حالة الاستخدام. احفظها كملفات JSON. بدلاً من ذلك، يمكنك إنشاء هذه الطلبات بنفسك باستخدام المعلومات الواردة في المستندات المرجعية للردود التلقائية على الويب.
- كتابة اختبارات لاستدعاء الرد التلقائي على الويب مع هذه الحمولات.
- في كل اختبار، تأكَّد من أنّ استجابة JSON تحتوي على العناصر المتوقّعة.
بالإضافة إلى ذلك، يسمح لك هذا النموذج باختبار طريقة تنفيذ Dialogflow في إعدادات الدمج المستمر لأنّ نقطة نهاية التنفيذ يمكن تشغيلها على الجهاز، وتتضمّن واجهة برمجة تطبيقات Dialogflow مفهومًا مضمَّنًا للجلسات.
يظهر مثال على الاختبار على النحو التالي:
it('yes-history', function() {
expect(jsonRes.payload).to.have.deep.keys('google');
expect(jsonRes.payload.google.expectUserResponse).to.be.true;
expect(jsonRes.payload.google.richResponse.items).to.have.lengthOf(3);
expect(jsonRes.payload.google.richResponse.suggestions).to.have
.deep.members([
{'title': 'Sure'}, {'title': 'No thanks'},
]);
});
يستخدم المقتطف أعلاه Mocha وChai. راجِع مثال العمل الكامل المكتوب في Node.js في مستودع حقائق عن Google.
تصميم تنفيذ الوحدة القابل للاختبار
غالبًا ما يحتوي رمز الردّ التلقائي على الويب على منطق عمل مخصّص يعتمد عليه تطبيقك لتلبية احتياجاته. بالإضافة إلى ذلك، يمكن أن يحتوي رمز الرد التلقائي على الويب أيضًا على معالجات الأهداف.
لتحسين دقة اختبارات الوحدة لرمز التنفيذ، من الممارسات الجيدة تنظيم التعليمة البرمجية بطريقة يمكن فيها فصل منطق العمل عن إجراءات التعامل مع النية. وهذا يعني وجود معالِجات النية ومنطق الأعمال في وحدات منفصلة، بحيث يمكن اختبار كل قطعة على نحو مستقل.
على سبيل المثال، يمكنك الاطّلاع على مثال عن إجراء shiritori على GitHub.
في هذا النموذج، يحتوي functions/index.js وfunctions/shiritori/*.js بشكل منفصل على معالِجات الأهداف ومنطق النشاط التجاري، ما يسمح بإنشاء مجموعات اختبار أكثر فعالية.
اختبارات الدمج
لكتابة حالات الاختبار التي تغطي عملية الدمج بين Dialogflow ورمز الرد التلقائي على الويب الخاص بالتنفيذ، يُرجى الاطّلاع على قسم اختبار الدمج في Dialogflow أعلاه.
تحميل الاختبارات
قبل نشر الإجراء الخاص بك في مرحلة الإنتاج، ننصحك أيضًا باختبار عملية تنفيذ الردّ التلقائي على الويب لعرض مشاكل الأداء التي تؤدي إلى تدهور خدمة توصيل الطلبات أو إيقافها.
إليك بعض الأمثلة على مشاكل الأداء التي قد تكتشفها في اختبار التحميل:
- الحوسبة والذاكرة محدودة
- قيود الحصص من موفّري الخدمات
- قراءة وتكتب البيانات البطيئة
- مشاكل التزامن في الرمز
تعتمد سيناريوهات اختبار التحميل على نمط الاستخدام المتوقّع أو السابق للإجراء الخاص بك، ولكن السيناريوهات النموذجية للاختبار هي الزيادات المفاجئة في التحميل (الارتفاع) والتحميلات المستمرة (الارتقاء).
حدد السيناريوهات التي يتم فيها استدعاء الرد التلقائي على الويب ويجري عمليات كثيفة الموارد. تتضمن العمليات التي تستهلك موارد نموذجية الاستعلام عن قاعدة بيانات، واستدعاء واجهة برمجة تطبيقات أخرى، وإجراء الحوسبة، وعمليات استهلاك الذاكرة مثل عرض ملف صوتي.
بالنسبة إلى هذه السيناريوهات، يمكنك تسجيل الطلبات المُرسَلة من خوادم "المهام مع مساعد Google" إلى الردّ التلقائي على الويب من سجلّات الردّ التلقائي على الويب أو من سجلّات Stackdriver. يمكنك أيضًا تلقي الطلبات من محاكي وحدة تحكم الإجراءات.
بعد تلقّي الطلبات، يمكنك استخدام أداة اختبار التحميل لمعرفة كيفية استجابة ردّك التلقائي على الويب في ظل سيناريوهات اختبار التحميل المختلفة. تعرض الأقسام الفرعية التالية بعض الأمثلة على اختبار الارتفاع والانخفاض في قيمة الاختبار باستخدام ApacheBench.
اختبار الارتفاع
يتطلّب اختبار الارتفاع المفاجئ إرسال عدد ثابت من الطلبات إلى الرد التلقائي على الويب لبعض الوقت وزيادة التحميل فجأة. على سبيل المثال، يمكنك إعداد اختبار يرسل 10 طلبات بحث في الثانية (QPS) مع بعض الارتفاعات بمقدار 60 طلب بحث في الثانية.
يمكنك تشغيل أمر ApacheBench التالي لإرسال 60 طلبًا متزامنًا إلى الرد التلقائي على الويب:
ab -n 60 -c 60 -p ActionRequest.json -T 'application/json' https://example.com/webhookFunctionName
لنفترض أنّ ملف ActionRequest.json يحتوي على حمولة الطلبات التي تم التقاطها والتي تم إرسالها إلى الرد التلقائي على الويب.
اختبار نقع المياه
يتطلّب اختبار وضع السكون إرسال عدد ثابت من الطلبات إلى الرد التلقائي على الويب ومراقبة الردّ. على سبيل المثال، يمكنك إعداد اختبار يرسل حملاً ثابتًا يتراوح بين 10 و20 Q في الثانية لعدة دقائق لمعرفة ما إذا كانت أوقات الاستجابة ستزيد أم لا.
يمكنك تشغيل أمر ApacheBench التالي لإرسال 1200 طلب، مع 10 طلبات متزامنة كل ثانية:
ab -t 120 -n 1200 -p ActionRequest.json -T 'application/json' https://example.com/webhookFunctionName
لنفترض أنّ ملف ActionRequest.json يحتوي على حمولة الطلبات التي تم التقاطها والتي تم إرسالها إلى الرد التلقائي على الويب.
جارٍ تحليل نتائج اختبار التحميل
بعد إجراء اختبارات التحميل، يمكنك تحليل النتائج المتعلقة بأوقات الاستجابة للردّ التلقائي على الويب. عادةً ما تكون مؤشرات المشاكل في تنفيذ الرد التلقائي على الويب مؤشرات مثل متوسط وقت الاستجابة الذي يزيد مع كل اختبار أو أسوأ وقت استجابة غير مقبول للإجراء الخاص بك.
الاختبار الشامل
يستخدم الاختبار الشامل قبل إرسال الإجراء للحصول على الموافقة محاكي وحدة تحكّم الإجراءات. يمكنك العثور على خطوات الاختبار الشامل من خلال مُحاكي وحدة تحكّم المهام في مستندات محاكي الإجراءات. يساعدك إجراء هذه الاختبارات في إزالة أوجه عدم التأكّد المحتملة من مكوِّن البنية الأساسية لـ "المهام مع مساعد Google".