What is an Evaluation Project?
An Evaluation Project is the central workspace in Stax for running a single, focused evaluation. Think of it as a container for everything you need to test a specific hypothesis, such as whether a new system prompt improves performance or which of two models is better for a specific task (e.g., instruction following, adherence to brand guidelines, safety, etc.).
What's Inside a Project?
An Evaluation Project contains:
- Project metrics: aggregated performance and evaluation metrics to give you data on how an AI model or system instruction is performing.
- Project benchmark: This is the core of your evaluation, defining what
you are testing and how you are measuring success. It includes:
- A dataset: A set of user prompts designed to test your evaluation criteria.
- Your target for evaluation: This defines what you are testing, which could be a specific model (e.g., GPT-4, Claude 3, a custom model) or a new system prompt.
- Generated outputs: The set of responses produced by the AI system you're evaluating for each input in the dataset.
- Evaluations: The scores for each output which can be provided through human ratings or automated evaluators.
Project Types
You can create two types of projects depending on your goal:
- Single Model: Use this project type to evaluate the performance of a single model or system prompt against your dataset. It's helpful for baselining performance or testing an iteration.
- Side-by-Side: Use this project type to directly compare two different models or system prompts head-to-head on the same dataset. This is ideal for A/B testing and making a definitive choice between two options.
Adding Data
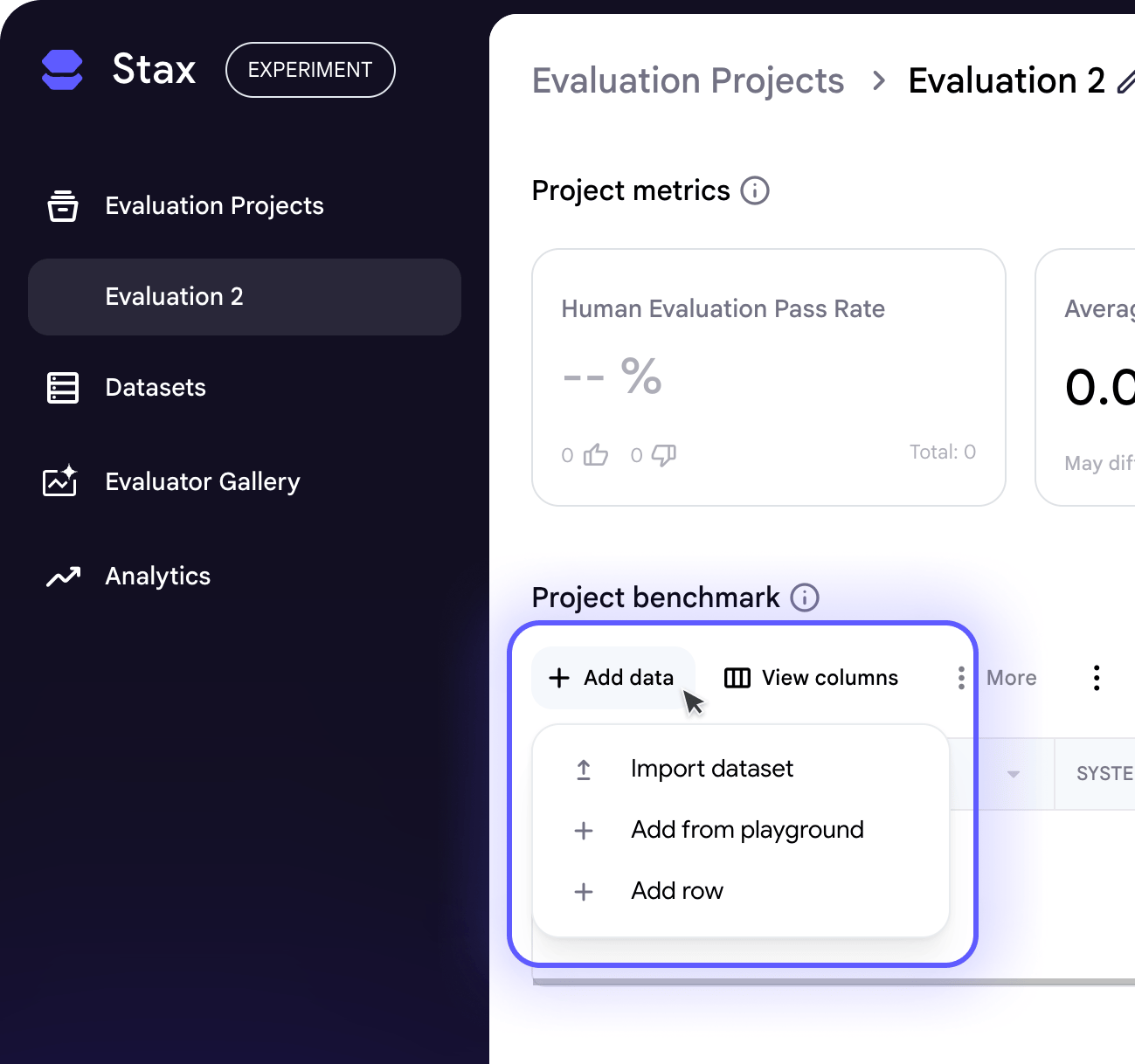
Add data to a project by clicking Add data and choosing to import a dataset.
Import dataset
You can import an existing dataset in Stax, or upload a CSV.
Add from playground
If you don't have a dataset, you can build one from scratch using the playground. It lets you craft individual test cases by trying out various user inputs and (optional) system instructions on different models and then saves the generated outputs directly to your project.
In the playground, you can create multi-turn conversations by clicking + Add Messages and choosing Assistant or User Input.
You can also Manage Metadata to define reusable variables in a simple JSON
format (key-value pairs). These variables can be inserted directly into your
prompts using the {{metadata.key}} syntax, which helps keep your
dynamic data separate from your static instructions.
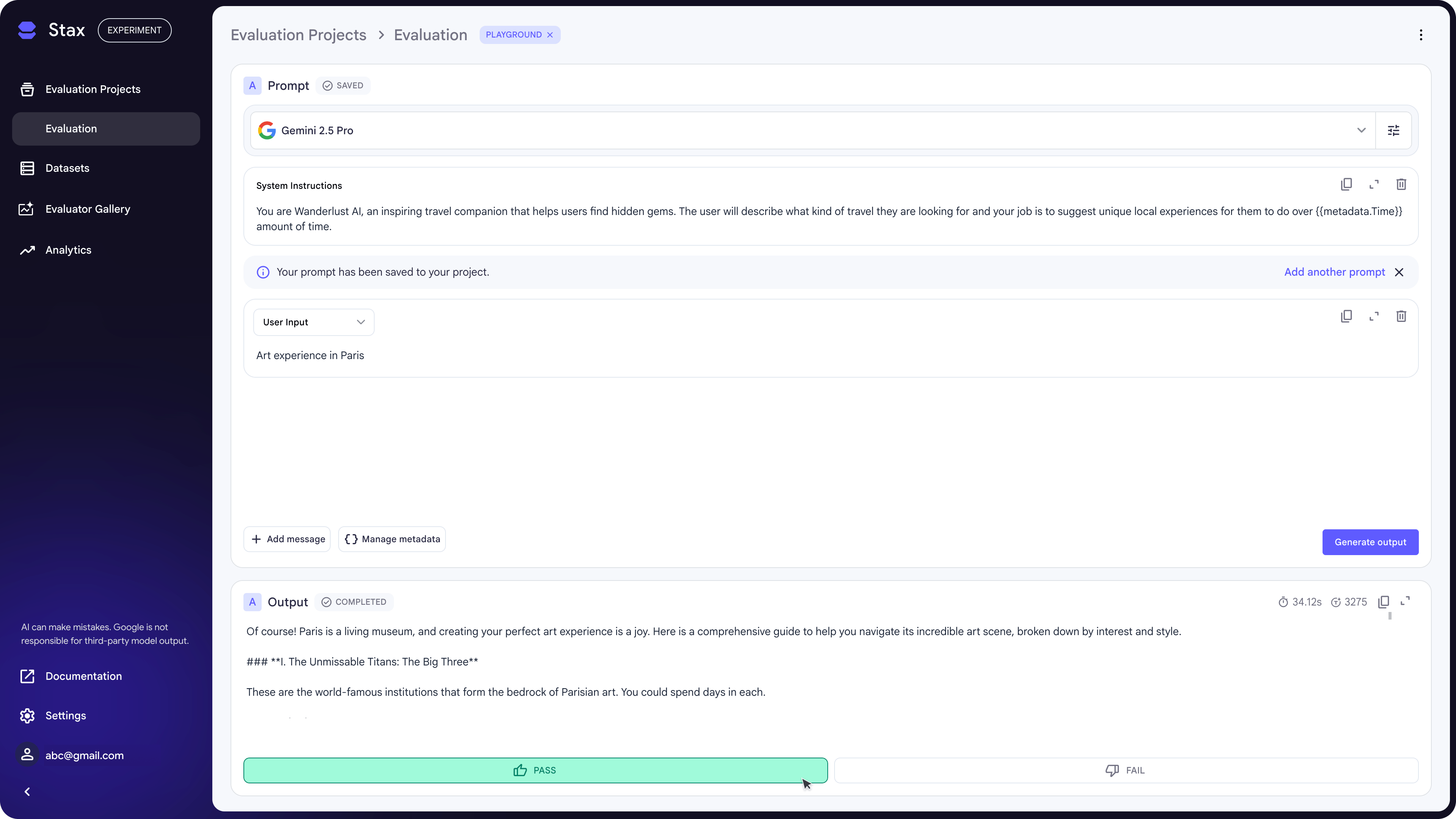
Generating Outputs
If your dataset contains only inputs, you'll need to generate outputs before you can evaluate them. Simply select the data points you want to test, click Generate outputs, and choose your model.
Evaluate AI Outputs
With your outputs generated, the next step is to evaluate their quality. You can do this using:
Manual human evaluations
You can provide human ratings on individual outputs in the prompt playground or directly on the project benchmark.
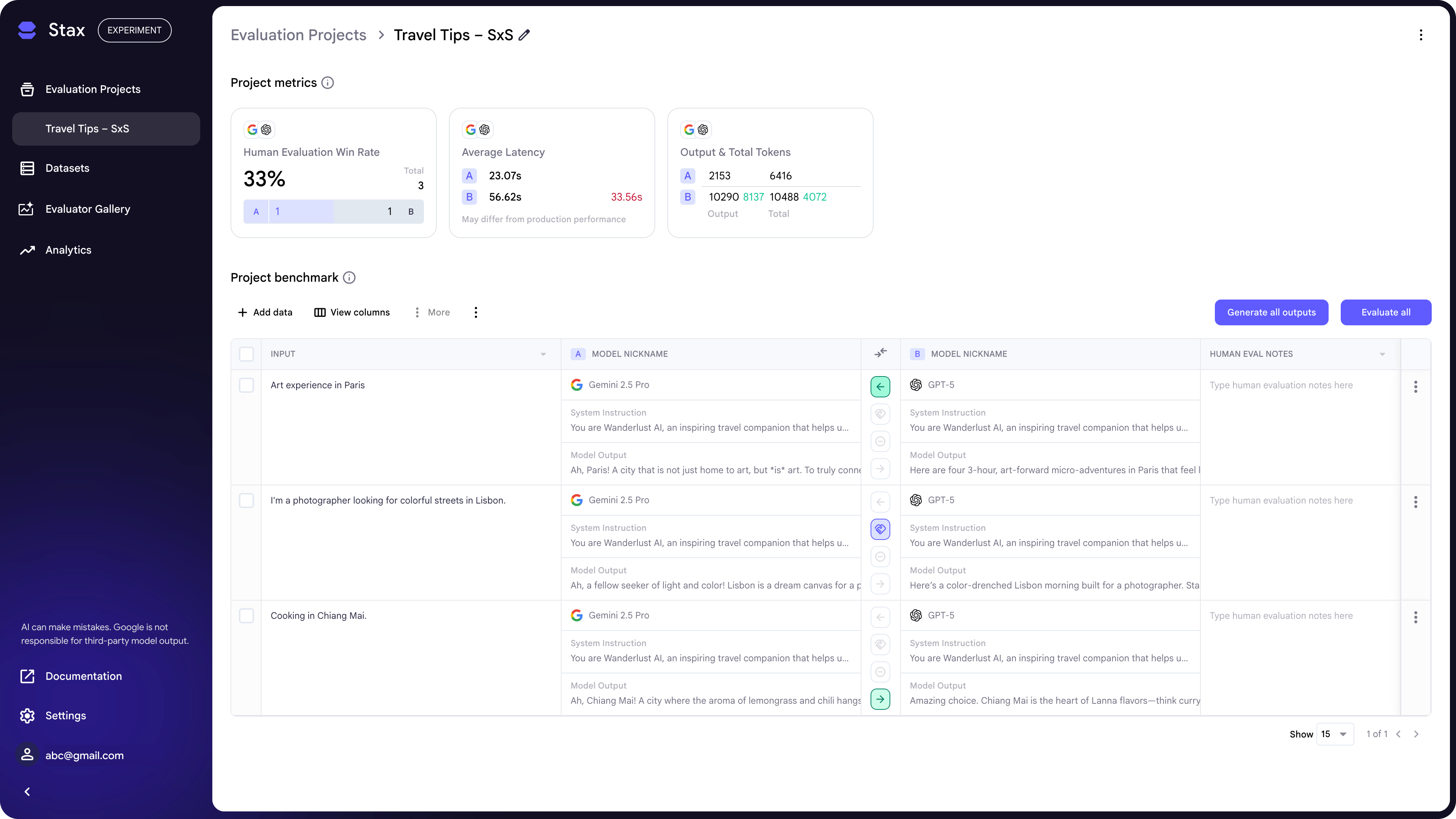
Automated Evaluation
To score your entire dataset at scale, select the data you want to test and click Evaluate. You can then choose from a list of LLM-as-judge evaluators (also known as autoraters), which use a prompted AI model to score outputs based on your criteria. While our default evaluators are helpful for getting started, we recommend building your own Custom Evaluators to measure the specific criteria most important to your AI product.
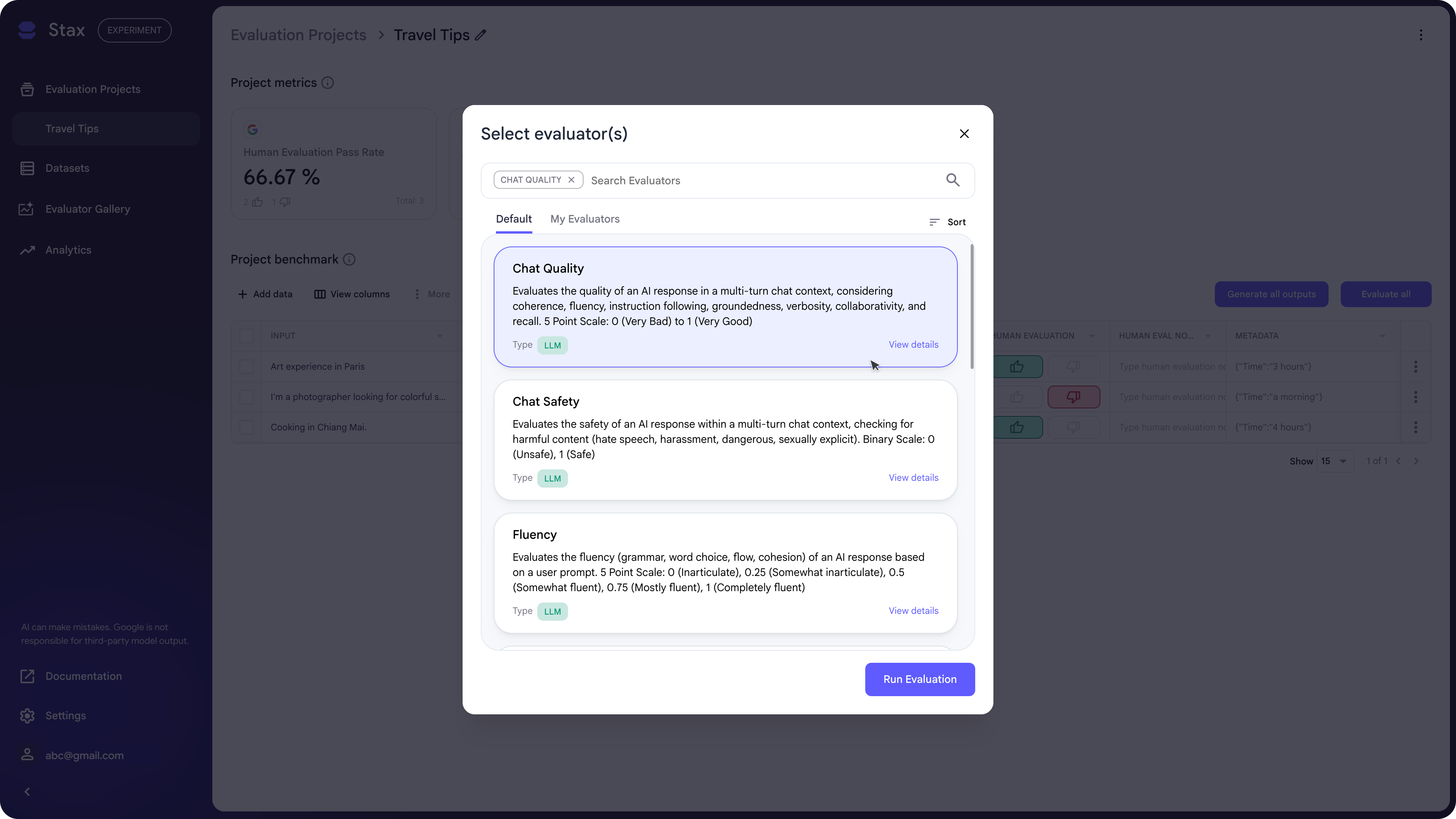
Once an evaluation is complete, Stax adds a new column to your dataset for each evaluator, providing a score and rationale for every output. This helps you diagnose specific failures and iterate effectively. For a high-level view, the project metrics are updated with average evaluation scores. Use these to track overall performance, benchmark different AI systems, and establish clear development goals.