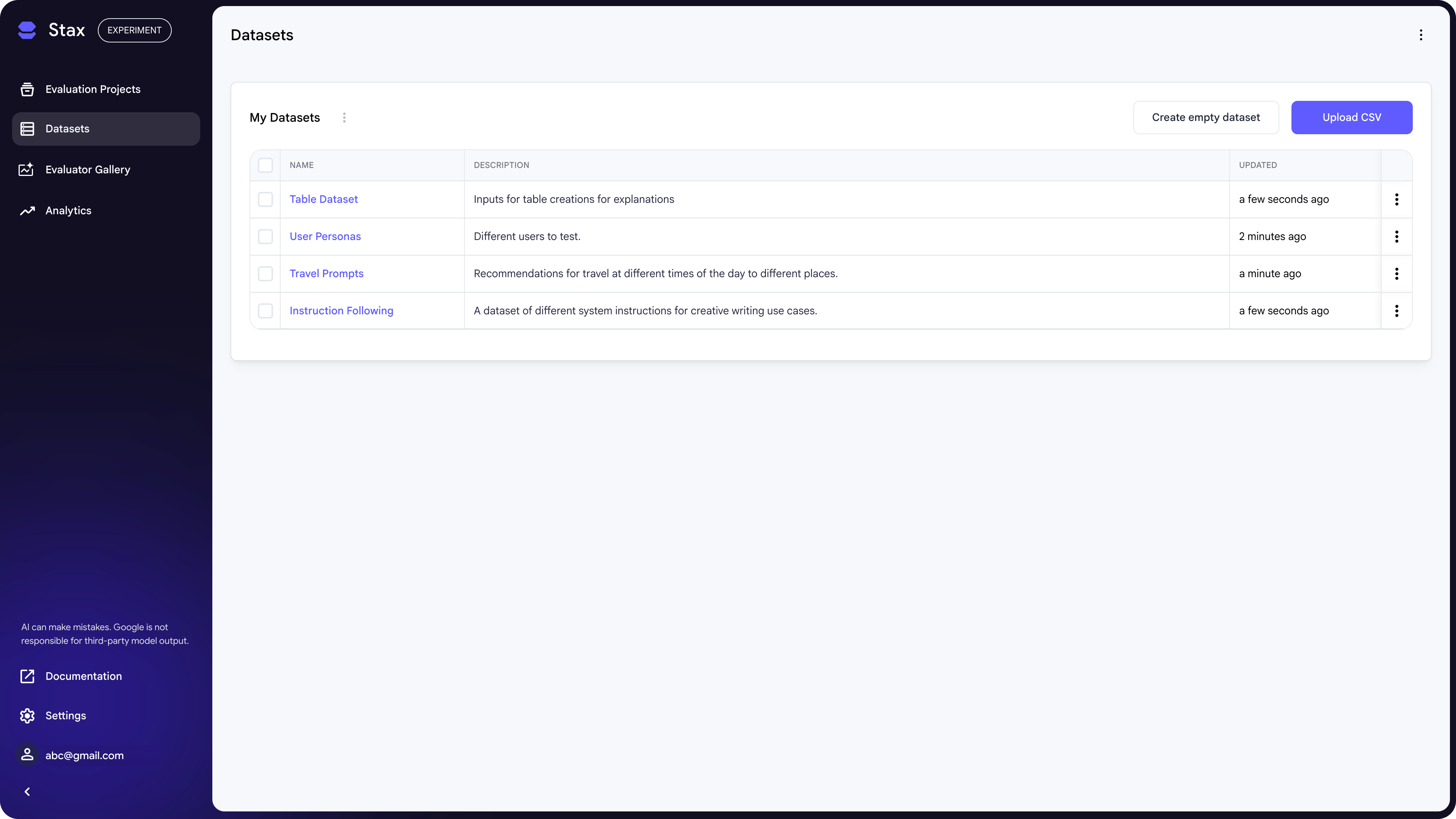
The Datasets page is your central library for managing reusable test sets for your Evaluation Projects. A dataset is a collection of user inputs designed to test specific criteria.
To consistently measure quality when comparing different AI systems (e.g., models or system prompts) on certain criteria, you should reuse the same dataset. You can create datasets by pulling from production data, writing them manually, or using an LLM to generate synthetic examples.
A good dataset is crucial for effective evaluation. It should:
- Elicit the specific behavior you're evaluating. For example, to test a model's ability to refuse inappropriate questions, your dataset needs a variety of prompts that are inappropriate in different ways.
- Cover a wide range of scenarios. This includes common cases (the "happy path"), edge cases, and adversarial examples designed to trick the system.
- Mirror real user data. For the most realistic evaluation, your dataset should reflect the kinds of inputs your users actually provide, ideally pulled from production logs.
- Prioritize quality over quantity. While the ideal size depends on the complexity of your evaluation, a good rule of thumb is to aim for hundreds of data points. However, it's better to have a smaller, focused dataset where each example tests something unique than a large, redundant one.
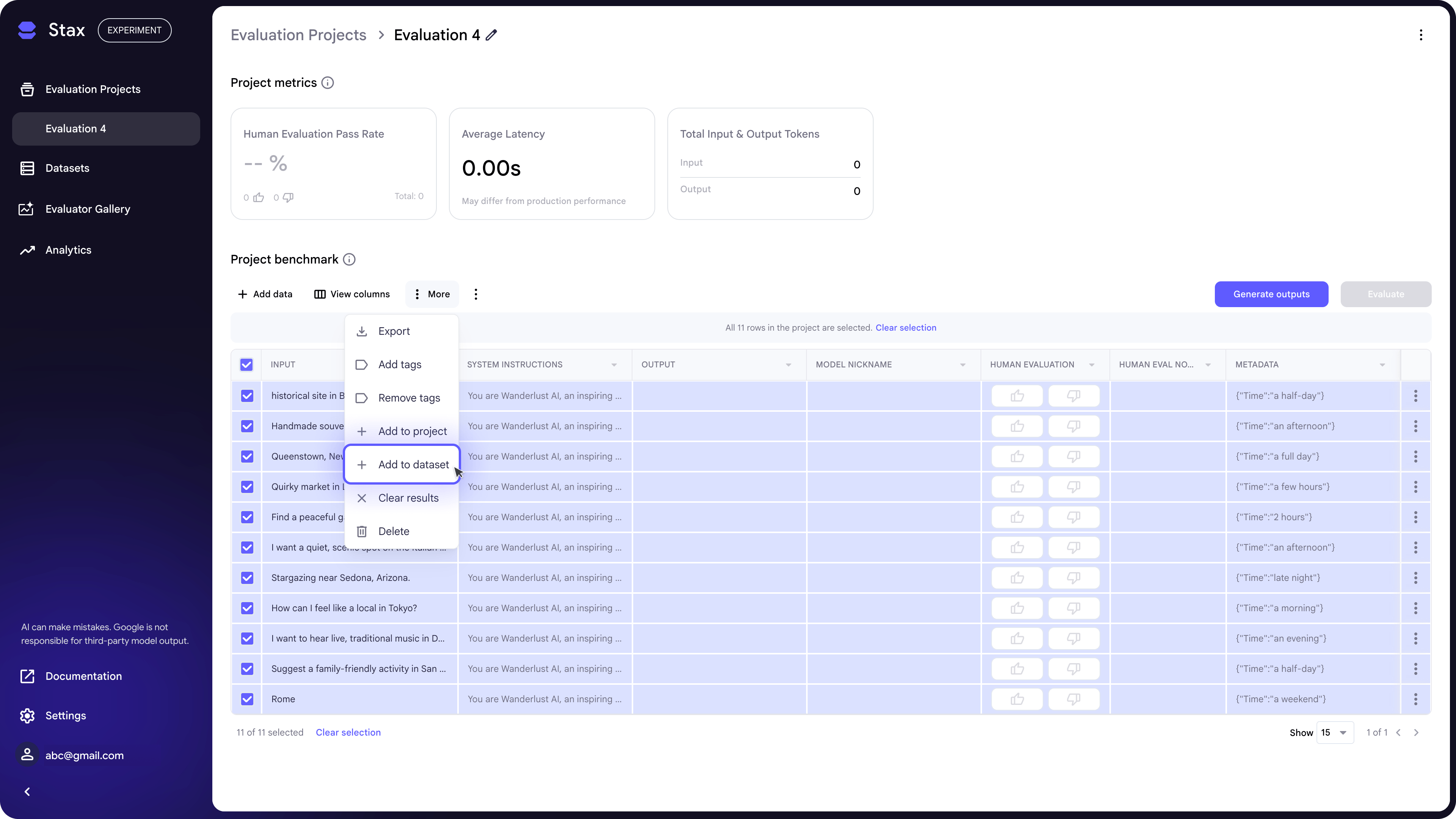
To create a dataset:
- Upload a CSV
- Add data from a project by selecting rows, then clicking More > Add to Dataset.
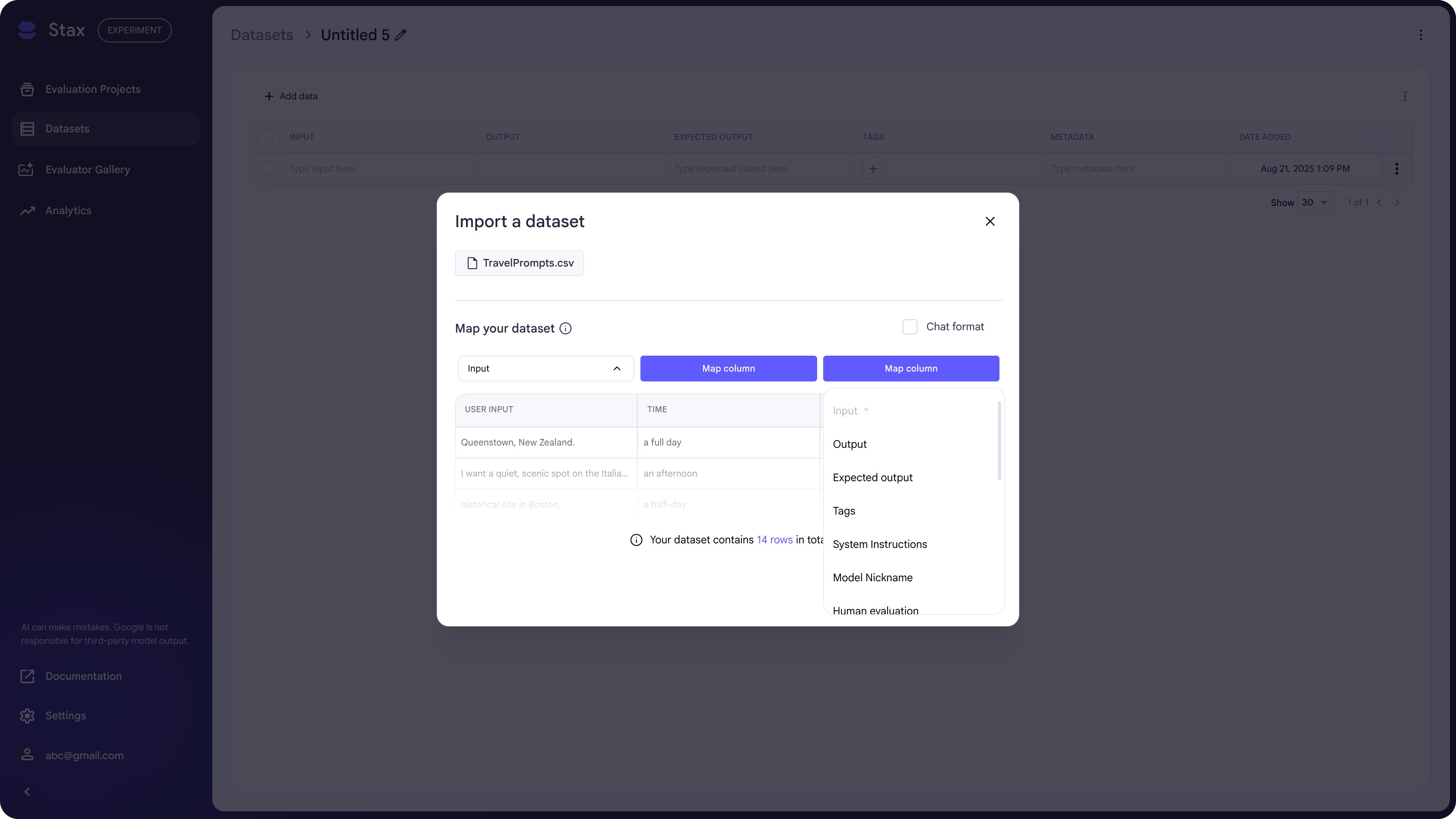
CSV Upload
You can create a dataset by uploading a CSV on the Datasets page or within an Evaluation Project. If you upload the CSV within a project, a dataset is automatically created.
For CSV uploads, Stax supports two main formats:
- Simple Format: Map your CSV columns directly to project benchmark fields like Input, Output, or System Prompt. Only the Input column is required. Here is an example CSV for the Simple Format.
- Chat Format: Upload a CSV containing JSON objects that follow the standard chat completion format.
For either format, you can map any column as Metadata. This creates a JSON
object where you can reference values as variables in your prompts (e.g.,
{{metadata.key}}), allowing for more dynamic and complex test cases.
Here is an example CSV for Chat Format.