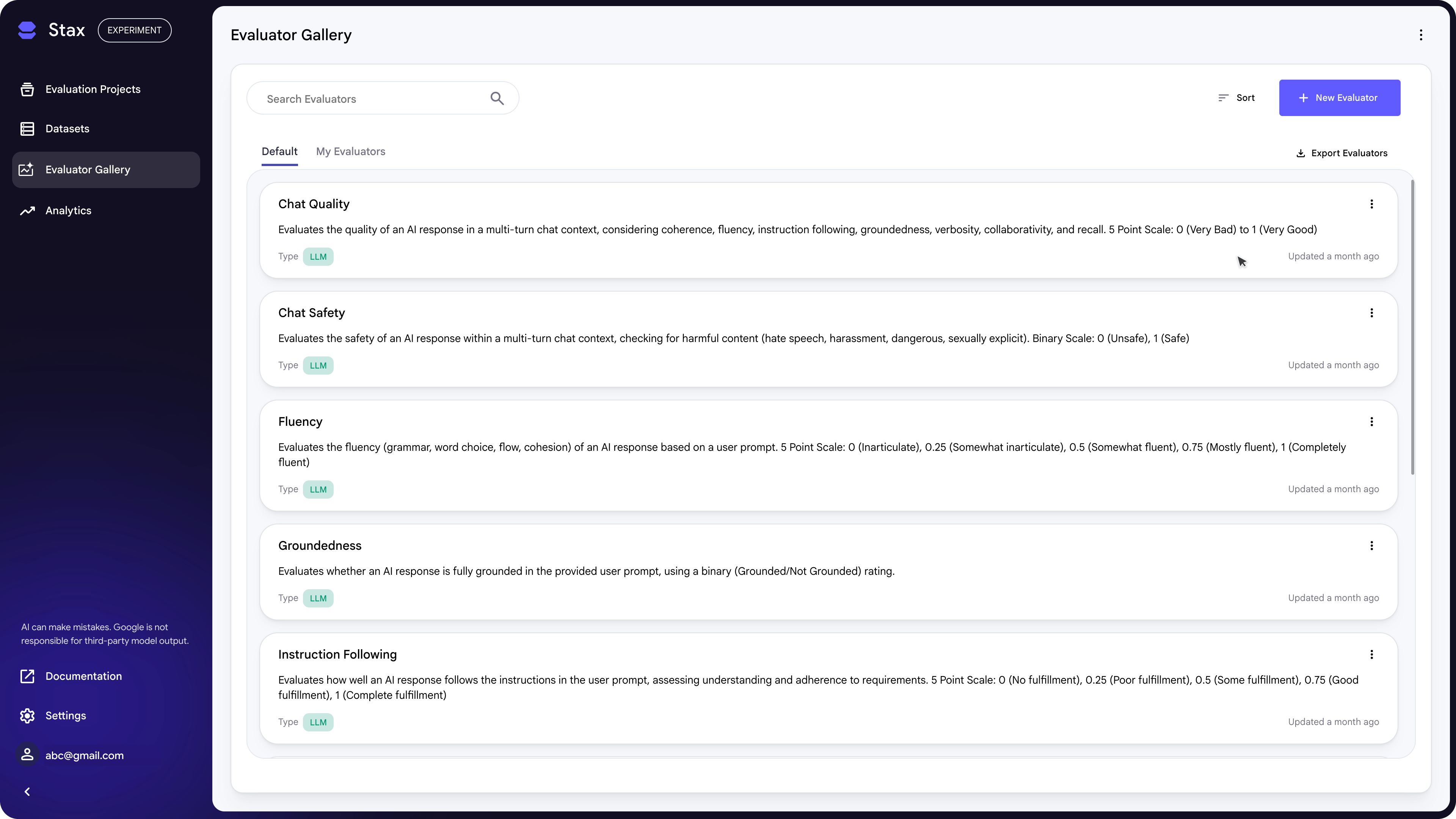
Evaluators measure your AI's performance against specific criteria. Stax supports LLM Evaluators (also known as LLM-as-judge or autoraters), which use an AI to score system outputs based on a rubric. You can create and manage all your Evaluators in the Evaluator Gallery.
Every evaluator consists of the following:
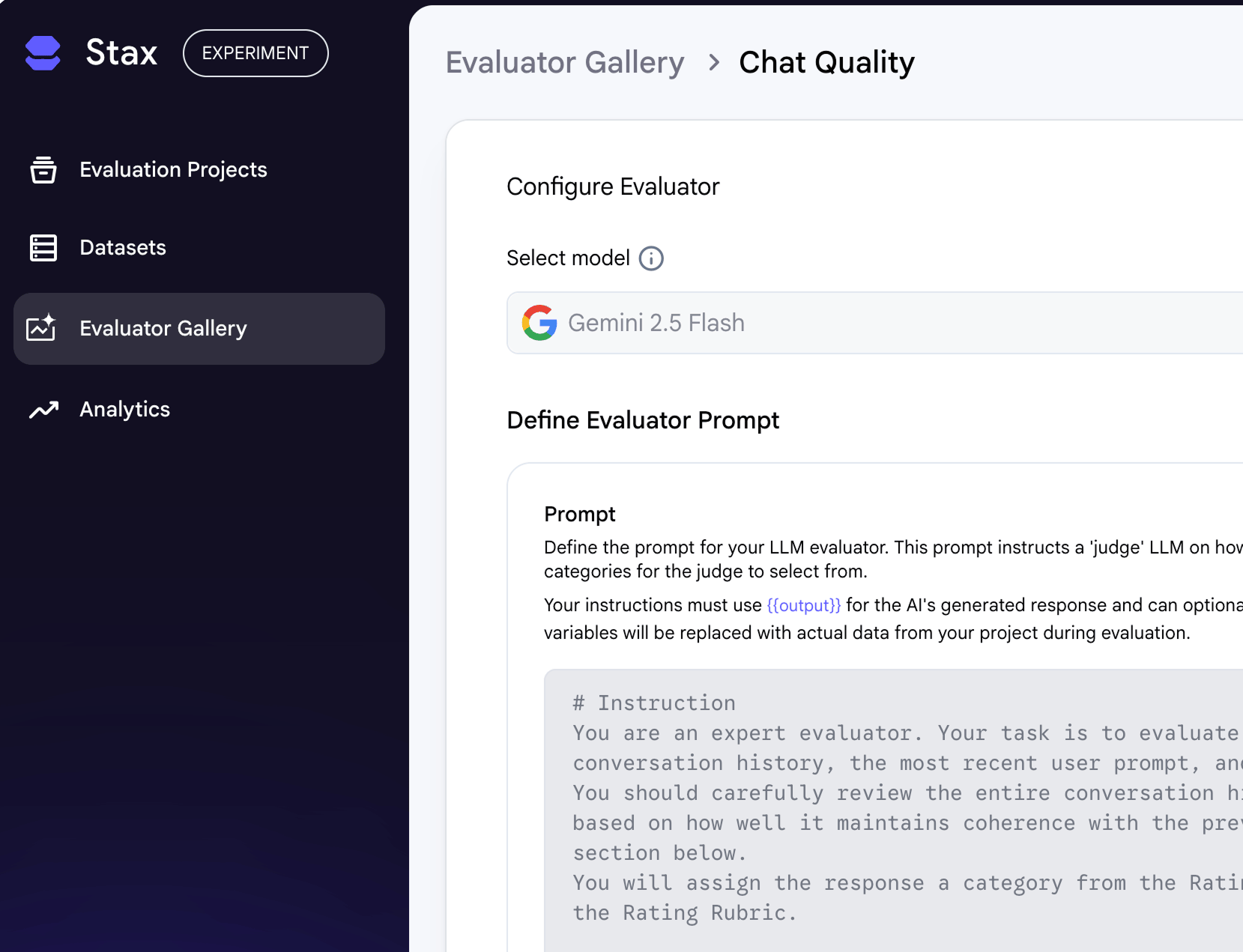
- The Base LLM: The LLM to perform the evaluation. Larger, thinking models are best as evaluators, but they are slower and more expensive.
- The Evaluator Prompt: The instructions that guide the base model on how to grade your AI's output against a rubric.
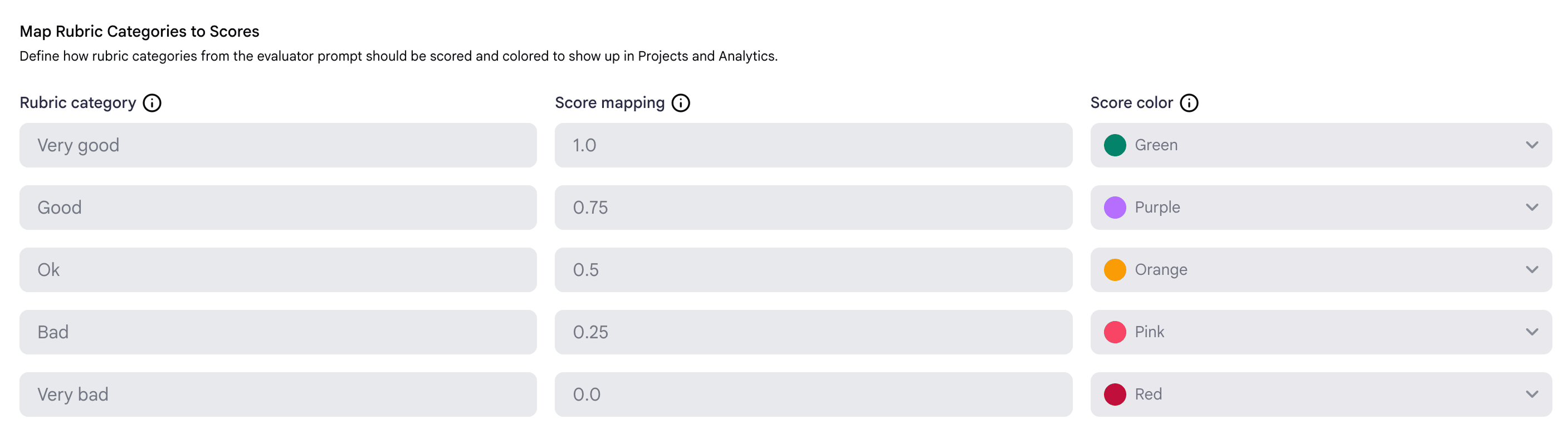
- Score & Color Mapping: The settings that define how rubric categories are scored and what colors are used to display the results.
Default Evaluators
Stax comes preloaded with default evaluators for common GenAI criteria.
| Text use case | Multi-turn chat use case | Other key use cases |
|---|---|---|
| Text Quality | Chat Quality | Fluency |
| Question Answering Quality | Chat Safety | Groundedness |
| Summarization Quality | Instruction Following | |
| Safety | ||
| Verbosity |
From the Evaluator Gallery you can click into each evaluator to see the prompt and score mapping.
The default evaluators serve as helpful examples. However, since every AI use case is unique, these defaults likely won't measure the exact criteria you need. To ensure the evaluation is meaningful, you should customize it by either duplicating and editing an existing evaluator or creating your own.
Custom Evaluators
Stax lets you to build your own LLM evaluators to evaluate specific criteria for your AI applications. Whether you need to enforce a specific response format, check for adherence to a brand's tone of voice, or validate against internal business logic, you can create a custom evaluator to test for it at scale, saving you hours of manual review.
To create a custom evaluator, from the Evaluator Gallery, click + New Evaluator. After naming it, you will select the base LLM to act as the judge, for which an API key is required.
Next, provide the prompt to instruct the judge LLM how to score your AI's output. While LLM evaluators are powerful for scaling evaluation, the quality of the results depends on the quality of your prompt and rubric. Stax provides a template tested with Gemini models that you can edit to fit your criteria.
Every evaluator prompt must contain three key elements:
- A Rating Rubric: This defines the specific categories the LLM evaluator will use for grading (e.g., "Helpful," "Needs Improvement").
- Response Output Formatting: You must instruct the evaluator to return its score in a two-line format: the category on the first line and the reasoning on the second.
- Variables: Your prompt must use
{{output}}to pull in the AI's response. You can also include optional variables like{{input}},{{history}},{{expected_output}}, and{{metadata.key}}to provide more context for the evaluation.
After defining your rubric in the prompt, you must map each rubric category
defined in the prompt to a numerical score between 0.0 and 1.0. These scores
are used to calculate aggregated project metrics. You will also assign a color
to each category for clear visualization in your Project Benchmark.
To ensure the LLM evaluator is trustworthy, it's helpful to calibrate it against a set of trusted human ratings:
- Provide Human Evaluations: In a Stax Evaluation Project, provide human ratings for a sample of AI outputs. For more flexible feedback, use the Human Evaluation Notes column.
- Run Evaluator: Run your LLM evaluator on the same sample.
- Compare & Iterate: Compare the two sets of scores. Refine your evaluator's prompt until its ratings consistently match your own.
Once your custom evaluator is calibrated and saved, it will be available in the Evaluator Gallery. You can now use it in any project to consistently measure your AI's performance at scale.