DSPL Schema
Stay organized with collections
Save and categorize content based on your preferences.
Page Summary
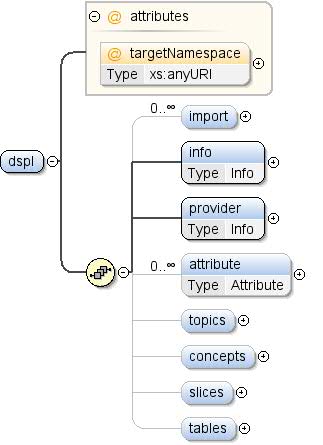
The DSPL XML Schema defines datasets using the dspl element, which contains tables, concepts, slices, and topics.
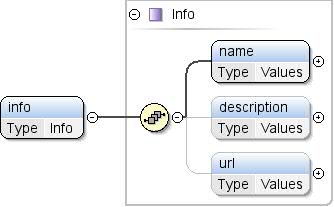
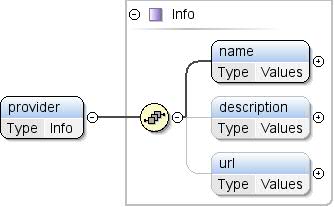
Datasets can import external data using the import element and provide general information with info and provider elements.
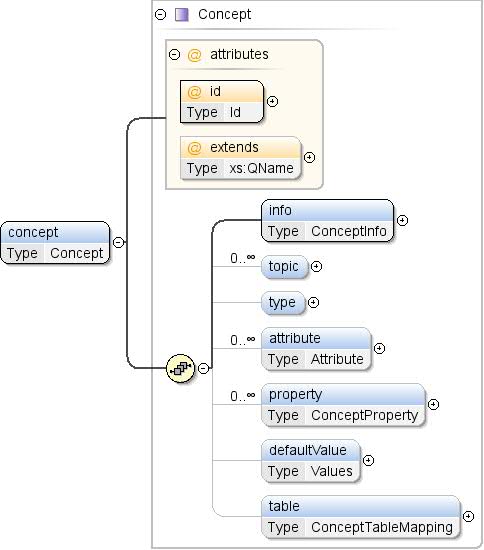
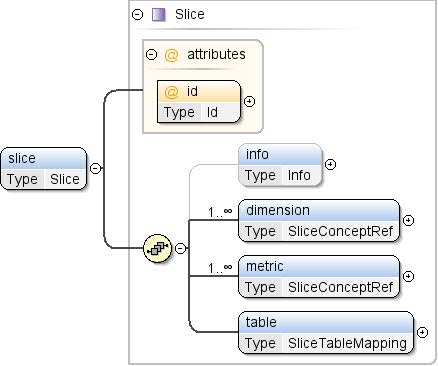
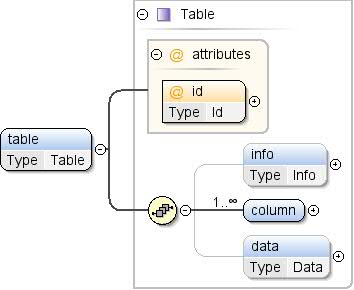
concepts, slices, and tables elements organize dataset structures, subsets of data, and the actual data, respectively.
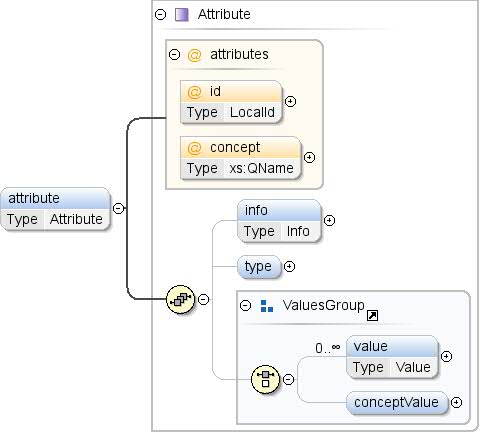
Attributes such as concept, id, and parentTopic are used to define relationships and identify elements within the dataset.
The schema leverages XML namespaces for modularity and reusability of datasets.
This page and its linked subpages document the DSPL XML schema.
This material is intended for advanced users who want to understand
the low-level details of the language; for most users, the content
in the
Developer Guide should be sufficient for creating and editing
DSPL datasets.
The complete XML schema is available for download in XSD format
on the
DSPL code site.
Element: dspl
Namespace
http://schemas.google.com/dspl/2010
Annotations
A DSPL specification describes a dataset. A dataset is
identified by its namespace. A dataset is comprised of the following
elements: - Tables: Data for the concepts and slices defined in the
dataset - Concepts: User-specified definitions and structures used in the
dataset - Slices: Combinations of dimensions and metrics present in the
dataset - Topics: Hierarchical labels used to organise the concepts of
the dataset
Each dataset may provide a target namespace. The target
namespace is a URI that uniquely identifies the dataset. For more
information about the use of namespaces in XML, see:
http://www.w3.org/TR/REC-xml-names/ If no targetNamespace is
provided, then a namespace will be generated when the dataset is
imported.
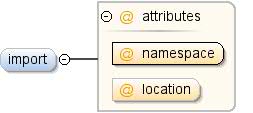
Import directive for external datasets -- modeled after the XML
Schema import directive. In order to use elements defined in an external
dataset, the external dataset must be referenced using an import
directive.
An optional location where the definition of the imported
dataset can be found, specified as a URL. If the location is
omitted, the system processing this DSPL dataset must already know
the imported dataset. Implementation note: The Google dataset
importer ignores the location attribute. Any imported dataset must
be known by the Google importer beforehand.
The namespace of the imported dataset, specified as a
URI. A prefix must be associated with this namespace before its
contents can be referenced. See [XML Namespaces] for more
information about the use of namespaces and prefixes in
XML.
A reference to a concept that corresponds to the values
of the attribute. If the attribute specifies a type, then the type
must match the type of the referenced concept. A reference to an
external concept must be of the form
"prefix:other_concept_id", where "prefix" is
the prefix used for the namespace of the external dataset (see XML
namespaces).
The id of the concept attribute. This identifier must be
unique within the concept (across attributes and properties). The
id may be omitted if the concept attribute is specified. In that
case, an id is implicity created with value the local name of the
referenced concept. For instance <attribute
concept="unit:currency"/> is equivalent to
<attribute id="currency"
concept="unit:currency"/>
A hierarchy of topics used to organize the contents of the
dataset. The order in which topics are given is meaningful and should be
respected by visualizations that displays these topics.
The unique identifier of a concept that this concept
extends. The referenced concept may be defined in the same dataset
or externally, i.e., in another dataset. A reference to an external
concept must be of the form "prefix:other_concept_id",
where "prefix" is the prefix used for the namespace of
the external dataset (see XML namespaces).
The namespace of the imported dataset, specified as a URI. A
prefix must be associated with this namespace before its contents can be
referenced. See [XML Namespaces] for more information about the use of
namespaces and prefixes in XML.
An optional location where the definition of the imported
dataset can be found, specified as a URL. If the location is omitted, the
system processing this DSPL dataset must already know the imported
dataset. Implementation note: The Google dataset importer ignores the
location attribute. Any imported dataset must be known by the Google
importer beforehand.
<xs:attribute name="location" use="optional">
<xs:annotation>
<xs:documentation>An optional location where the definition of the
imported dataset can be found, specified as a
URL. If the location is omitted, the system
processing this DSPL dataset must already know the
imported dataset.
Implementation note: The Google dataset importer
ignores the location attribute. Any imported dataset
must be known by the Google importer beforehand.</xs:documentation>
</xs:annotation>
</xs:attribute>
Each dataset may provide a target namespace. The target
namespace is a URI that uniquely identifies the dataset. For more
information about the use of namespaces in XML, see:
http://www.w3.org/TR/REC-xml-names/ If no targetNamespace is provided,
then a namespace will be generated when the dataset is
imported.
[[["Easy to understand","easyToUnderstand","thumb-up"],["Solved my problem","solvedMyProblem","thumb-up"],["Other","otherUp","thumb-up"]],[["Missing the information I need","missingTheInformationINeed","thumb-down"],["Too complicated / too many steps","tooComplicatedTooManySteps","thumb-down"],["Out of date","outOfDate","thumb-down"],["Samples / code issue","samplesCodeIssue","thumb-down"],["Other","otherDown","thumb-down"]],["Last updated 2024-06-26 UTC."],[],["The DSPL XML schema defines a dataset's structure using key components: `tables`, `concepts`, `slices`, and `topics`. The root `dspl` element encapsulates the dataset, utilizing `import` to reference externals, `info` and `provider` for metadata, `attribute` for dataset attributes, and `topics` to hierarchically organize the concepts. `concepts`, `slices`, `tables` are for concept definition, slice definition, and data table, respectively. Each element like `import`, `info`, `provider`, `attribute`, `topic`, `concept`, `slice`, `table` uses specific attributes and child elements for configuration. Each element has a specific cardinality that is defined in the document.\n"]]