Private Aggregation API の主なコンセプト
このドキュメントの対象者
Private Aggregation API を使用すると、クロスサイト データにアクセスできるワークレットから集計データを収集できます。ここで紹介するコンセプトは、共有ストレージと Protected Audience API 内でレポート機能を構築するデベロッパーにとって重要です。
- クロスサイト測定用のレポート システムを構築するデベロッパーの場合。
- マーケティング担当者、データ サイエンティスト、またはその他の概要レポート利用者は、これらのメカニズムを理解することで、最適化された概要レポートを取得するための設計上の意思決定を行うことができます。
主な用語
このドキュメントを読む前に、主な用語とコンセプトを理解しておくことをおすすめします。ここでは、これらの各用語について詳しく説明します。
- 集計キー(バケットとも呼ばれます)は、事前に定義されたデータポイントのコレクションです。たとえば、ブラウザが国名を報告する位置情報のバケットを収集できます。集計キーには、複数のディメンション(国とコンテンツ ウィジェットの ID など)を含めることができます。
- 集計可能値は、集計キーに収集される個々のデータポイントです。コンテンツを閲覧したフランスのユーザーの数を測定する場合、
Franceは集計キーのディメンションで、1のviewCountは集計可能な値です。 - 集計可能レポートは、ブラウザ内で生成され、暗号化されます。Private Aggregation API の場合、これには単一のイベントに関するデータが含まれます。
- 集計サービスは、集計可能レポートのデータを処理して、概要レポートを作成します。
- 概要レポートは集計サービスの最終出力であり、ノイズの多いユーザーデータと詳細なコンバージョン データが含まれます。
- ワークレットは、特定の JavaScript 関数を実行し、リクエスト元に情報を返すことができるインフラストラクチャの一部です。ワークレット内では JavaScript を実行できますが、外部ページとのやり取りや通信はできません。
プライベート集計のワークフロー
集計キーと集計値を使用して Private Aggregation API を呼び出すと、ブラウザは集計可能レポートを生成します。レポートは、バッチ処理を行うサーバーに送信されます。バッチ処理されたレポートは、後で集計サービスによって処理され、概要レポートが生成されます。
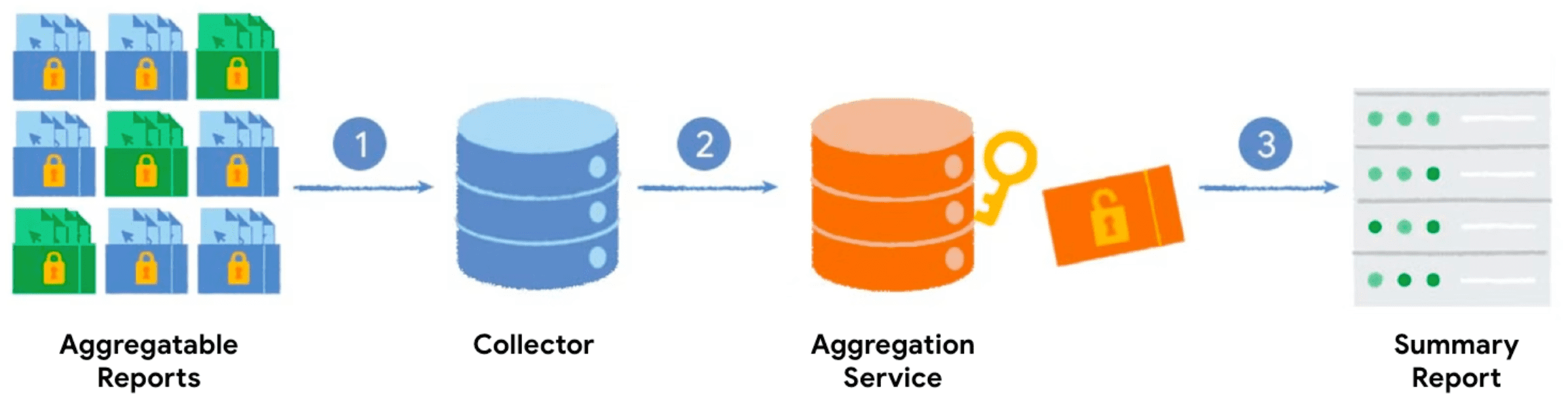
- Private Aggregation API を呼び出すと、クライアント(ブラウザ)が集計可能レポートを生成してサーバーに送信し、収集します。
- サーバーがクライアントからレポートを収集し、バッチ処理して集計サービスに送信します。
- 十分な量のレポートを収集したら、それらをバッチ処理して、信頼できる実行環境で実行されている集計サービスに送信し、概要レポートを生成します。
このセクションで説明するワークフローは、Attribution Reporting API に似ています。ただし、アトリビューション レポートでは、異なるタイミングで発生するインプレッション イベントとコンバージョン イベントから収集されたデータが関連付けられます。プライベート集計は単一のクロスサイトイベントを測定します
集計キー
集計キー(略して「キー」)は、集計可能な値が蓄積されるバケットを表します。1 つ以上のディメンションをキーにエンコードできます。ディメンションは、ユーザーの年齢層や広告キャンペーンのインプレッション数など、詳細に分析する側面を表します。
たとえば、複数のサイトに埋め込まれたウィジェットがあって、そのウィジェットを見たユーザーの国を分析するとします。「ウィジェットを見たユーザーの数は X 国のユーザーか」といった疑問に答える場合。この質問についてレポートするには、2 つのディメンション(ウィジェット ID と国 ID)をエンコードする集計キーを設定します。
Private Aggregation API に渡されるキーは、複数のディメンションで構成される BigInt です。この例では、ディメンションはウィジェット ID と国 ID です。ウィジェット ID が最大 4 桁(1234 など)で、各国がアルファベット順の番号にマッピングされているとします。たとえば、アフガニスタンは 1、フランスは 61、ジンバブエは「195」です。したがって、集計可能キーは 7 桁で、最初の 4 文字は WidgetID に予約され、最後の 3 文字は CountryID に予約されます。
たとえば、このキーはウィジェット ID 3276 を見たフランス(国 ID 061)のユーザー数を表し、集計キーは 3276061 です。
| 集計キー | |
| ウィジェット ID | 国 ID |
| 3,276 | 061 |
集計キーは、SHA-256 などのハッシュ メカニズムを使用して生成することもできます。たとえば、文字列 {"WidgetId":3276,"CountryID":67} をハッシュ化してから、42943797454801331377966796057547478208888578253058197330928948081739249096287n の BigInt 値に変換できます。ハッシュ値が 128 ビットを超える場合は、2^128−1 の最大許容バケット値を超えないように切り捨てることができます。
共有ストレージ ワークレット内では、ハッシュの生成に役立つ crypto モジュールと TextEncoder モジュールにアクセスできます。ハッシュの生成の詳細については、MDN の SubtleCrypto.digest() をご覧ください。
次の例は、ハッシュ値からバケットキーを生成する方法を示しています。
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
集計可能値
集計可能な値は、多くのユーザーのキーごとに合計され、サマリー レポートにサマリー値の形式で集計された分析情報が生成されます。
先ほどの質問例に戻ります。「ウィジェットを見たユーザーはフランスの人は何人いますか?」この質問に対する回答は、「ウィジェット ID 3276 を見たユーザーは約 4,881 人、フランス出身です」のようになります。集計可能値はユーザーごとに 1 です。4,881 users は、その集計キーのすべての集計可能値の合計です。4,881 users は集計値です。
| 集計キー | 集計可能値 | |
| ウィジェット ID | 国 ID | 視聴回数 |
| 3,276 | 061 | 1 |
この例では、ウィジェットを表示するユーザーごとに値を 1 ずつ増やしています。実際には、集計可能な値をスケーリングして信号対雑音比を改善できます。
資金提供の予算
Private Aggregation API に対する各呼び出しはコントリビューションと呼ばれます。ユーザーのプライバシーを保護するため、個人から収集できる寄付の数には上限があります。
すべての集計キーのすべての集計可能値を合計する場合、その合計は資金提供予算より小さくする必要があります。予算の範囲はワークレットの送信元ごと、1 日あたりであり、Protected Audience API ワークレットと共有ストレージ ワークレットで異なります。その日は、過去約 24 時間のローリング ウィンドウが使用されます。新しい集計可能レポートで予算を超過する場合、レポートは作成されません。
資金提供予算はパラメータ L1 で表され、220 のバックストップで 1 日あたり 10 分あたり 216(65,536)に設定されます。
(1,048,576)。これらのパラメータの詳細については、説明をご覧ください。
資金提供バジェットの値は任意ですが、それに応じてノイズがスケーリングされます。 この予算を使用して、サマリー値の信号対雑音比を最大化できます(ノイズとスケーリングで詳しく説明します)。
資金提供予算について詳しくは、説明をご覧ください。また、詳細なガイダンスについては、資金提供予算をご覧ください。
集計可能レポート
ユーザーが Private Aggregation API を呼び出すと、ブラウザは集計可能レポートを生成します。このレポートは、後で集計サービスによって処理され、概要レポートを生成します。集計可能レポートは JSON 形式で、それぞれが {aggregation key, aggregatable value} ペアのコントリビューションの暗号化されたリストを含みます。集計可能レポートは、ランダムな遅延で最大 1 時間送信されます。
コントリビューションは暗号化され、集計サービスの外部で読み取ることはできません。集計サービスがレポートを復号し、概要レポートを生成します。ブラウザの暗号鍵と集計サービスの復号鍵は、鍵管理サービスとして機能するコーディネーターによって発行されます。コーディネーターは、サービス イメージのバイナリハッシュのリストを保持して、呼び出し元に復号鍵の受信が許可されていることを確認します。
デバッグモードを有効にした集計可能レポートの例:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
集計可能レポートは chrome://private-aggregation-internals ページから検査できます。

テスト目的で [Send Selected Reports] ボタンを使用すると、レポートをサーバーにすぐに送信できます。
集計可能レポートの収集とバッチ処理
ブラウザは、リストされている既知のパスを使用して、Private Aggregation API の呼び出しを含むワークレットのオリジンに集計可能レポートを送信します。
- 共有ストレージの場合:
/.well-known/private-aggregation/report-shared-storage - Protected Audience の場合:
/.well-known/private-aggregation/report-protected-audience
これらのエンドポイントでは、クライアントから送信された集計可能レポートを受信するサーバー(コレクタとして機能する)を運用する必要があります。
次に、サーバーはレポートをバッチ処理し、バッチを集計サービスに送信する必要があります。集計可能レポートの暗号化されていないペイロードに含まれる情報(shared_info フィールドなど)に基づいて、バッチを作成します。理想的には、バッチにはバッチあたり 100 件以上のレポートを含める必要があります。
日単位または週単位にバッチ処理することもできます。この戦略には柔軟性があり、インプレッション数の増加が予想される特定のイベント(たとえば、インプレッション数の増加が予想される日)に合わせてバッチ処理戦略を変更できます。バッチには、同じ API バージョン、レポート元、スケジュール設定されたレポート日時のレポートを含める必要があります。
集計サービス

集計サービスは、暗号化された集計可能レポートをコレクタから受け取り、概要レポートを生成します。
レポート ペイロードを復号するために、集計サービスはコーディネーターから復号鍵を取得します。このサービスは、データの整合性、データの機密性、コードの整合性を一定レベルの保証する高信頼実行環境(TEE)で実行されます。サービスを所有して運用していますが、TEE 内で処理されるデータは可視化できません。
概要レポート
サマリー レポートでは、ノイズを加えた状態で収集したデータを確認できます。指定したキーセットの概要レポートをリクエストできます。
概要レポートには、JSON 辞書形式の Key-Value ペアのセットが含まれます。各ペアには次のものが含まれます。
bucket: 2 進数の文字列としての集計キー。使用される集計キーが「123」の場合、バケットは「1111011」です。value: 特定の測定目標の概要値。ノイズが追加されたすべての集計可能レポートから合計されます。
次に例を示します。
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
ノイズとスケーリング
ユーザーのプライバシーを保護するため、集計サービスは、概要レポートがリクエストされるたびに、各概要値にノイズを 1 回追加します。ノイズ値は、ラプラス確率分布からランダムに取得されます。ノイズを追加する方法を直接制御することはできませんが、測定データに対するノイズの影響に影響を与えることができます。
ノイズ分布は、すべての集計可能値の合計に関係なく同じです。したがって、集計可能値が高いほど、ノイズの影響が小さくなります。
たとえば、ノイズ分布の標準偏差が 100 で、中心が 0 であるとします。収集された集計可能レポートの値(または「集計可能値」)が 200 のみの場合、ノイズの標準偏差は集計値の 50% になります。ただし、集計可能値が 20,000 の場合、ノイズの標準偏差は集計値の 0.5% になります。したがって、集計可能値の 20,000 は、信号対雑音比がはるかに高くなります。
したがって、集計可能値にスケーリング ファクタを乗算すると、ノイズを減らすことができます。スケーリング ファクタは、特定の集計可能値をどの程度スケーリングするかを表します。

より大きなスケーリング ファクタを選択して値をスケールアップすると、相対ノイズが減少します。ただし、これにより、すべてのバケットにおけるすべての資金提供の合計額が、資金提供予算の上限に早く達します。小さなスケーリング ファクタの定数を選択して値をスケールダウンすると、相対的なノイズが増加しますが、予算の上限に達するリスクは低くなります。
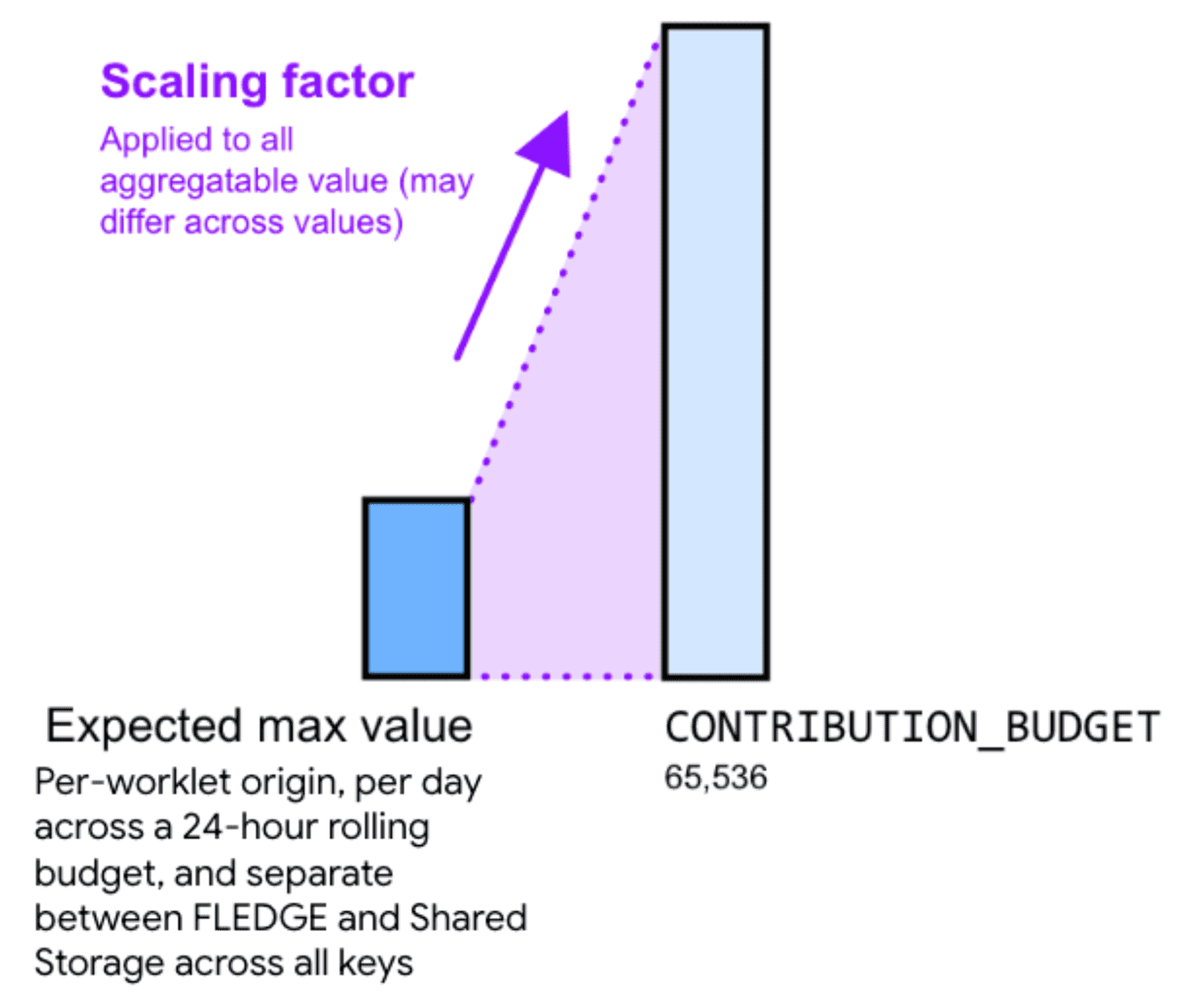
適切なスケーリング ファクタを計算するには、コントリビューション バジェットをすべてのキーの集計可能な値の最大合計で割ります。
詳しくは、資金提供予算に関するドキュメントをご覧ください。
交流とフィードバックの共有
Private Aggregation API は現在検討中で、今後変更される可能性があります。この API を試してフィードバックがございましたら、ぜひお聞かせください。
- GitHub: 説明を読み、質問を投稿し、ディスカッションに参加してください。* デベロッパー サポート: プライバシー サンドボックス デベロッパー サポート リポジトリで質問したり、ディスカッションに参加したりできます。 * プライベート アグリゲーションに関する最新のお知らせを確認するには、Shared Storage API グループと Protected Audience API グループにご参加ください。