Stellen Sie diesen Dienst bereit und verwalten Sie ihn, um zusammenfassende Berichte für die Attribution Reporting API oder die Private Aggregation API zu erstellen.
Stellen Sie einen Aggregationsdienst bereit und verwalten Sie ihn, um aggregierte Berichte über die Attribution Reporting API oder die Private Aggregation API zu verarbeiten und einen zusammenfassenden Bericht zu erstellen.
Implementierungsstatus
- Der Aggregationsdienst ist jetzt allgemein verfügbar.
- Der Aggregationsdienst kann mit der Attribution Reporting API und der Private Agration API für die Protected Audience API und freigegebenen Speicher getestet werden.
In der Erläuterung werden die Schlüsselbegriffe beschrieben, die für das Verständnis des Aggregationsdienstes hilfreich sind.
Verfügbarkeit
| Vorschlag | Status |
|---|---|
| Unterstützung des Aggregation Service für Amazon Web Services (AWS) in der Attribution Reporting API und der Private Aggregation API
Erläuterung |
Verfügbar |
| Unterstützung von Aggregation Service für Google Cloud in der Attribution Reporting API, Private Aggregation API Erläuterung |
In der Betaversion verfügbar |
| Aggregation Service: Websiteregistrierung und Zuordnung einer Website zu Cloud-Konten (AWS oder GCP) FAQs auf GitHub |
Verfügbar |
| Der Wert für epsilon des Aggregation Service wird in einem Bereich von bis zu 64 beibehalten, um Tests und Feedback zu verschiedenen Parametern zu erleichtern.
Senden Sie uns ARA Epsilon-Feedback. Senden Sie PAA Epsilon-Feedback. |
Verfügbar Wir informieren das System im Voraus, bevor die Werte für den Epsilon-Bereich aktualisiert werden. |
| Flexiblere Beitragsfilterung für Abfragen des Aggregationsdienstes
Erläuterung |
Voraussichtlich im 2. Quartal 2024 |
| Prozess zur Wiederherstellung des Budgets nach Katastrophen (Fehler, Fehlkonfigurationen usw.)
GitHub-Problem |
Voraussichtlich im 2. Quartal 2024 |
| Accenture ist einer der Koordinatoren bei AWS. Entwicklerblog |
Verfügbar |
| Unabhängige Partei, die als Koordinator bei Google Cloud agiert
Entwicklerblog |
Voraussichtlich im 3. Quartal 2024 |
Sichere Datenverarbeitung
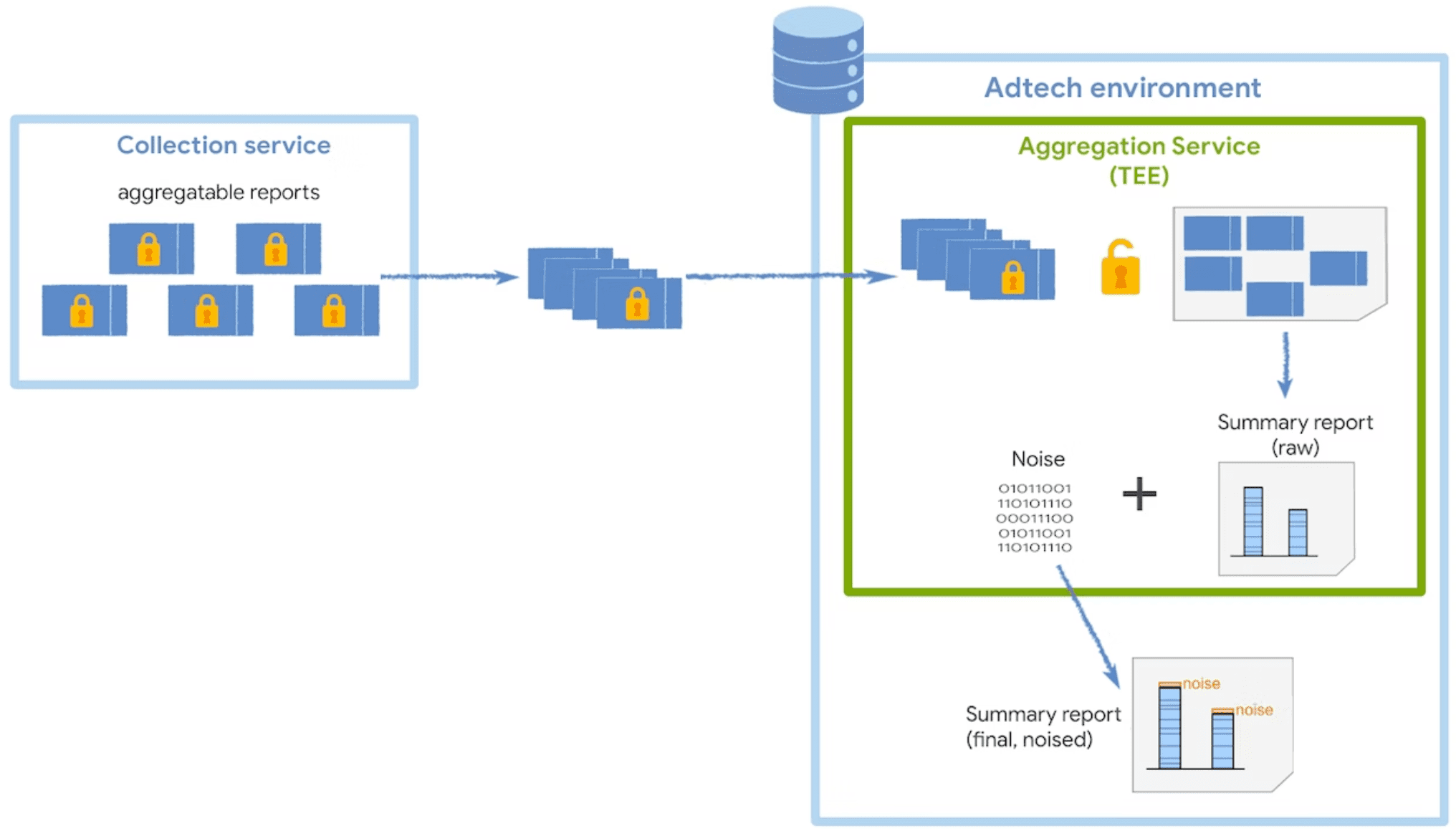
Der Aggregationsdienst entschlüsselt und kombiniert die erhobenen Daten aus den aggregierten Berichten, fügt Rauschen hinzu und gibt den endgültigen zusammenfassenden Bericht zurück. Dieser Dienst wird in einer vertrauenswürdigen Ausführungsumgebung (Trusted Execution Environment, TEE) ausgeführt, die in einem Cloud-Dienst bereitgestellt wird, der die erforderlichen Sicherheitsmaßnahmen zum Schutz dieser Daten unterstützt.
Der TEE-Code ist der einzige Ort im Aggregation Service, der Zugriff auf Rohdatenberichte hat. Dieser Code kann von Sicherheitsexperten, Datenschutzbeauftragten und AdTech-Teams geprüft werden. Ein Koordinator führt eine Attestierung durch, um zu bestätigen, dass das TEE genau die genehmigte Software ausführt und die Daten sicher bleiben.
Nachweis der Koordination des TEE
Der Koordinator ist eine Entität, die für die Schlüsselverwaltung und die Buchhaltung aggregierter Berichte verantwortlich ist.
Koordinatoren haben mehrere Verantwortlichkeiten:
- Pflegen Sie eine Liste autorisierter Binär-Images. Diese Images sind kryptografische Hashes der Software-Builds des Aggregationsdienstes, die von Google regelmäßig veröffentlicht werden. Dieser Vorgang ist reproduzierbar, sodass jede Partei prüfen kann, ob die Images mit den Builds des Aggregationsdienstes identisch sind.
- Sie betreiben ein Schlüsselverwaltungssystem. Verschlüsselungsschlüssel sind erforderlich, damit Chrome auf dem Gerät eines Nutzers aggregierte Berichte verschlüsseln kann. Entschlüsselungsschlüssel sind erforderlich, um nachzuweisen, dass der Code des Aggregationsdienstes mit den Binär-Images übereinstimmt.
- Verfolgen Sie die aggregierten Berichte, um die Wiederverwendung in der Aggregation für zusammenfassende Berichte zu verhindern, da bei der Wiederverwendung personenbezogene Daten offengelegt werden können.
Regel „Keine Duplikate“
Um Einblick in den Inhalt eines bestimmten aggregierten Berichts zu erhalten, kann ein Angreifer mehrere Kopien des Berichts erstellen und diese Kopien in einen oder mehrere Batches aufnehmen. Aus diesem Grund erzwingt der Aggregationsdienst die Regel "Keine Duplikate":
- Im Batch: Ein aggregierbarer Bericht kann in einem Batch nur einmal angezeigt werden.
- Batch-übergreifend: Aggregierte Berichte können nicht in mehreren Batches angezeigt oder zu mehr als einem zusammenfassenden Bericht beitragen.
Zu diesem Zweck weist der Browser jedem aggregierten Bericht eine gemeinsame ID zu.
Der Browser generiert die freigegebene ID aus verschiedenen Datenpunkten, darunter API-Version, Ursprung der Berichterstellung, Zielwebsite, Registrierungszeit der Quelle und geplanter Berichtszeit. Diese Daten stammen aus dem Feld shared_info im Bericht.
Der Aggregationsdienst bestätigt, dass sich alle aggregierten Berichte mit derselben gemeinsamen ID im selben Batch befinden, und meldet dem Koordinator, dass die gemeinsame ID verarbeitet wurde. Wenn mehrere Batches mit derselben ID erstellt werden, kann nur ein Batch für die Aggregation akzeptiert werden und andere Batches werden abgelehnt.
Wenn Sie eine Fehlerbehebungsausführung ausführen, wird die Regel „Keine Duplikate“ nicht für mehrere Batches erzwungen. Mit anderen Worten: Berichte aus vorherigen Batches können in einem Debug-Vorgang angezeigt werden. Die Regel wird jedoch innerhalb eines Batchs erzwungen. So können Sie mit dem Dienst und verschiedenen Batchstrategien experimentieren, ohne die zukünftige Verarbeitung in einer Produktionsumgebung einzuschränken.
Rauschen und Skalierung
Um die Privatsphäre der Nutzer zu schützen, wendet der Aggregationsdienst einen additiven Rauschmechanismus auf die Rohdaten aus aggregierten Berichten an. Dies bedeutet, dass jedem aggregierten Wert eine gewisse Menge an statistischem Rauschen hinzugefügt wird, bevor er in einem zusammenfassenden Bericht veröffentlicht wird.
Sie haben zwar keine direkte Kontrolle darüber, wie Rauschen hinzugefügt wird, können aber die Auswirkungen von Rauschen auf die Messdaten beeinflussen.

Der Rauschwert wird nach dem Zufallsprinzip aus einer Laplace-Wahrscheinlichkeitsverteilung bezogen. Die Verteilung ist unabhängig von der Menge der in aggregierten Berichten erfassten Daten gleich. Je mehr Daten Sie sammeln, desto weniger Auswirkungen hat das Rauschen auf die Ergebnisse des zusammenfassenden Berichts. Sie können die aggregierbaren Berichtsdaten mit einem Skalierungsfaktor multiplizieren, um die Auswirkungen des Rauschens zu reduzieren.
Informationen dazu, wie Rauschen hinzugefügt wird, Ihre Steuerelemente und die Auswirkungen auf Ihre Berichte finden Sie unter Mit Rauschen arbeiten unter Beitragsbudget und Auf Beitragsbudget hochskalieren.
Zusammenfassungsberichte erstellen
Die Erstellung des zusammenfassenden Berichts hängt von Ihrer API-Nutzung ab. Weitere Informationen zum Erstellen von Zusammenfassungsberichten für die Private Aggregation API und die Attribution Reporting API
Aggregationsdienst testen
Es empfiehlt sich, für jede API, die Sie testen, die entsprechende Anleitung zu lesen:
In dieser Anleitung erfahren Sie, wie Sie den Aggregation Service in AWS testen.
Mit einem lokalen Testtool können Sie zusammengefasste Berichte für Attribution Reporting und die Private Aggregation API verarbeiten.
Ein empfohlenes Test-Framework wird vom Aggregation Service Load Testing Framework bereitgestellt.
Reagieren und Feedback geben
Der Aggregation Service ist ein wichtiges Element der Privacy Sandbox-Mess-APIs. Wie bei anderen Privacy Sandbox APIs wird dies auf GitHub dokumentiert und öffentlich diskutiert.
- GitHub: Lesen Sie die Erklärung, stellen Sie Fragen und beteiligen Sie sich an der Diskussion. Sehen Sie sich auch die Implementierung des Aggregationsdienstes an und geben Sie uns Feedback zur Implementierung.
- Entwicklersupport: Hier können Sie Fragen stellen und sich an Diskussionen zum Privacy Sandbox-Entwicklersupport-Repository beteiligen.