이 서비스를 배포하고 관리하여 Attribution Reporting API 또는 Private Aggregation API의 요약 보고서를 생성합니다.
집계 서비스를 배포하고 관리하여 Attribution Reporting API 또는 Private Aggregation API의 집계 가능한 보고서를 처리하여 요약 보고서를 만듭니다.
구현 상태
- 집계 서비스가 이제 정식 버전으로 전환되었습니다.
- Attribution Reporting API와 Protected Audience API 및 공유 스토리지용 Private Aggegration API로 집계 서비스를 테스트할 수 있습니다.
이 설명에서는 집계 서비스를 이해하는 데 유용한 핵심 용어를 간략히 설명합니다.
지원 대상
| 제안 내용 | 상태 |
|---|---|
| Attribution Reporting API, Private Aggregation API 전반에서 Amazon Web Services (AWS)에 대한 집계 서비스 지원
Explainer |
사용 가능 |
| Attribution Reporting API, Private Aggregation API 전반에서 Google Cloud를 위한 집계 서비스 지원 Explainer |
베타 버전으로 제공 |
| 집계 서비스 사이트 등록 및 클라우드 계정 (AWS 또는 GCP)에 대한 사이트 매핑 GitHub 관련 FAQ |
사용 가능 |
| 집계 서비스의 epsilon 값은 다양한 매개변수에 대한 실험과 피드백을 용이하게 하기 위해 최대 64 범위로 유지됩니다.
ARA epsilon 의견을 제출합니다. PAA epsilon 의견을 제출합니다. |
사용 가능 epsilon 범위 값이 업데이트되기 전에 생태계에 사전 공지할 예정입니다. |
| 집계 서비스 쿼리에 대한 보다 유연한 참여 필터링
설명 |
2024년 2분기 예상 |
| 재해 발생 후 예산 복구 프로세스 (오류, 구성 오류 등)
GitHub 문제 |
2024년 2분기 예상 |
| AWS 조정 담당자 중 하나로 운영되는 Accenture
개발자 블로그 |
사용 가능 |
| Google Cloud 코디네이터 중 하나로 운영되는 독립적인 당사자
개발자 블로그 |
2024년 3분기 예상 |
안전한 데이터 처리
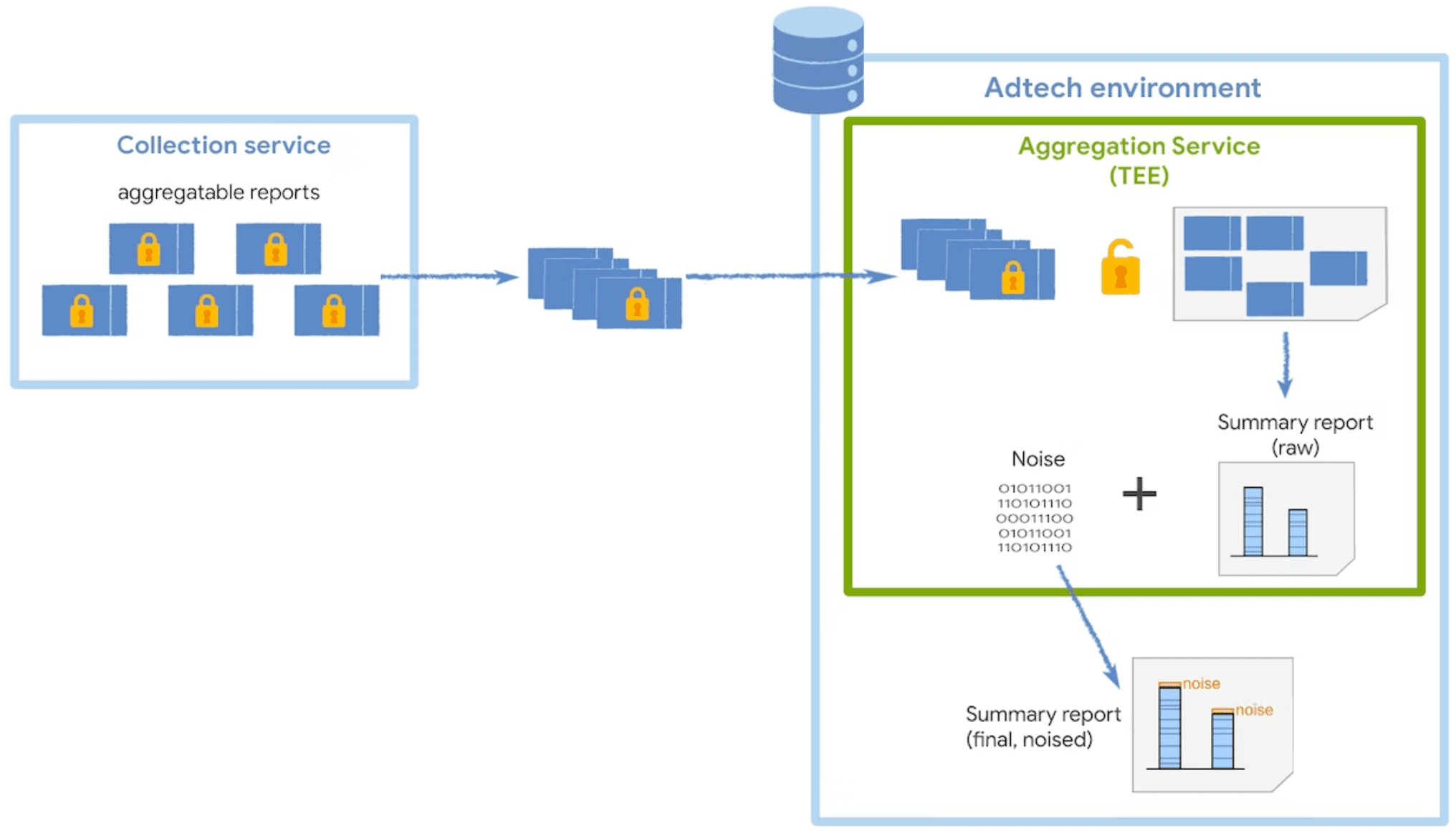
집계 서비스는 집계 가능한 보고서에서 수집된 데이터를 복호화 및 결합하여 노이즈를 추가하고 최종 요약 보고서를 반환합니다. 이 서비스는 이 데이터를 보호하는 데 필요한 보안 조치를 지원하는 클라우드 서비스에 배포되는 TEE (신뢰할 수 있는 실행 환경)에서 실행됩니다.
TEE의 코드는 집계 서비스에서 원시 보고서에 액세스할 수 있는 유일한 위치입니다. 이 코드는 보안 연구원, 개인 정보 보호 지지자, 광고 기술이 감사할 수 있습니다. TEE에서 정확히 승인된 소프트웨어를 실행하고 데이터가 안전하게 유지되는지 확인하기 위해 코디네이터가 증명을 실행합니다.
TEE의 코디네이터 증명
코디네이터는 키 관리 및 집계 가능한 보고서 계산을 담당하는 개체입니다.
조정자는 다음과 같은 여러 가지 책임을 집니다.
- 승인된 바이너리 이미지 목록을 유지합니다. 이러한 이미지는 Google에서 주기적으로 출시하는 집계 서비스 소프트웨어 빌드의 암호화 해시입니다. 이 이미지를 재현하여 어느 당사자가나 이미지가 집계 서비스 빌드와 동일한지 확인할 수 있습니다.
- 키 관리 시스템을 운영합니다. 사용자 기기의 Chrome에서 집계 가능한 보고서를 암호화하려면 암호화 키가 필요합니다. 복호화 키는 집계 서비스 코드가 바이너리 이미지와 일치하는지 확인하는 데 필요합니다.
- 집계 가능한 보고서를 추적하여 요약 보고서의 집계에서 재사용되지 않도록 합니다. 재사용으로 인해 개인 식별 정보 (PII)가 노출될 수 있습니다.
'중복 없음' 규칙
공격자는 집계 가능한 특정 보고서의 내용에 관한 유용한 정보를 얻기 위해 보고서의 여러 사본을 만들고 해당 사본을 단일 또는 여러 배치에 포함할 수 있습니다. 따라서 집계 서비스는 '중복 없음' 규칙을 적용합니다.
- 배치 내: 집계 가능한 보고서는 배치 내에서 한 번만 나타날 수 있습니다.
- 일괄 보고서: 집계 가능한 보고서는 두 개 이상의 배치에 표시되거나 두 개 이상의 요약 보고서에 기여할 수 없습니다.
이를 위해 브라우저는 집계 가능한 각 보고서에 공유 ID를 할당합니다.
브라우저는 API 버전, 보고 출처, 대상 사이트, 소스 등록 시간, 예약된 보고서 시간을 포함한 여러 데이터 포인트에서 공유 ID를 생성합니다. 이 데이터는 보고서의 shared_info 필드에서 가져옵니다.
집계 서비스는 공유 ID가 동일한 집계 가능한 모든 보고서가 동일한 배치에 있는지 확인하고 공유 ID가 처리되었음을 코디네이터에게 보고합니다. 동일한 ID로 여러 배치를 만든 경우 집계에 하나의 배치만 허용되고 다른 배치는 거부됩니다.
디버그 실행을 수행하면 '중복 없음' 규칙이 배치 간에 적용되지 않습니다. 즉, 이전 배치의 보고서가 디버그 실행에 나타날 수 있습니다. 그러나 규칙은 여전히 배치 내에서 시행됩니다. 이를 통해 프로덕션 환경에서 향후 처리를 제한하지 않고 서비스 및 다양한 일괄 처리 전략을 실험할 수 있습니다.
노이즈 및 확장
사용자 개인 정보를 보호하기 위해 집계 서비스는 집계 가능한 보고서의 원시 데이터에 추가 노이즈 메커니즘을 적용합니다. 즉, 요약 보고서에 공개되기 전에 각 집계 값에 일정량의 통계 노이즈가 추가됩니다.
노이즈가 추가되는 방식을 직접 제어할 수는 없지만 노이즈가 측정 데이터에 미치는 영향에는 영향을 줄 수 있습니다.

노이즈 값은 라플라스 확률 분포에서 무작위로 추출되며, 집계 가능한 보고서에 수집되는 데이터 양과 관계없이 분포가 동일합니다. 수집하는 데이터가 많을수록 노이즈가 요약 보고서 결과에 미치는 영향이 줄어듭니다. 집계 가능한 보고서 데이터에 배율을 곱하여 노이즈의 영향을 줄일 수 있습니다.
노이즈가 추가되는 방식, 컨트롤, 보고서에 미치는 영향을 알아보려면 노이즈 활용에서 참여 예산 및 참여 예산으로 확장을 참고하세요.
요약 보고서 생성
요약 보고서 생성은 API 사용에 따라 다릅니다. Private Aggregation API 및 Attribution Reporting API의 요약 보고서 생성에 관해 자세히 알아보세요.
집계 서비스 테스트
테스트 중인 각 API에 해당하는 가이드를 읽어보는 것이 좋습니다.
AWS에서 집계 서비스를 테스트하려면 이 안내를 참고하세요.
로컬 테스트 도구를 사용하여 Attribution Reporting 및 Private Aggregation API의 집계 가능한 보고서를 처리할 수도 있습니다.
집계 서비스 부하 테스트 프레임워크는 추천 테스트 프레임워크를 제공합니다.
참여 및 의견 공유
집계 서비스는 개인 정보 보호 샌드박스 측정 API의 핵심 요소입니다. 다른 개인 정보 보호 샌드박스 API와 마찬가지로 GitHub에 공개적으로 문서화되고 논의됩니다.
- GitHub: 설명서를 읽고 질문을 올리고 토론에 참여합니다. 집계 서비스 구현을 살펴보고 구현에 관한 의견을 제공해 주세요.
- 개발자 지원: 개인 정보 보호 샌드박스 개발자 지원 저장소에서 질문하고 토론에 참여하세요.