 Google uses AI technology to translate content into your preferred language. AI translations can contain errors.
Google uses AI technology to translate content into your preferred language. AI translations can contain errors.
एफ़आईआर
संग्रह की मदद से व्यवस्थित रहें
अपनी प्राथमिकताओं के आधार पर, कॉन्टेंट को सेव करें और कैटगरी में बांटें.
डेटा-ड्रिवन हेल्थकेयर, भरोसेमंद और काम की अहम जानकारी को तेज़ी से जनरेट करने पर निर्भर करता है.
FHIR स्टैंडर्ड, अगली पीढ़ी के डिजिटल हेल्थ सलूशन बनाने वाले डेवलपर को कई फ़ायदे देता है. हालांकि, विश्लेषण के लिए, इसके नेस्ट किए गए स्ट्रक्चर के साथ काम करना चुनौती भरा हो सकता है.
डेवलपर को ऐसे समाधान बनाने में आसानी हो, जिनसे एफ़एचआईआर डेटा के साथ काम करने की जटिलता कम हो, इसके लिए हम एफ़एचआईआर डेटा पाइप टूल उपलब्ध कराते हैं. इसमें ये टूल शामिल हैं: रिसॉर्स को Parquet-on-FHIR स्कीमा में बदलने के लिए ईटीएल पाइपलाइन, व्यू डेफ़िनिशन लेयर, और क्वेरी इंजन कनेक्टर.
FHIR डेटा पाइप को, हॉरिज़ॉन्टल स्केलेबिलिटी और डिप्लॉयमेंट के आसान विकल्पों (ऑन-प्राइमिस या क्लाउड में) के लिए डिज़ाइन किया गया है. साथ ही, इसे एक ही मशीन पर डिप्लॉय किया जा सकता है.
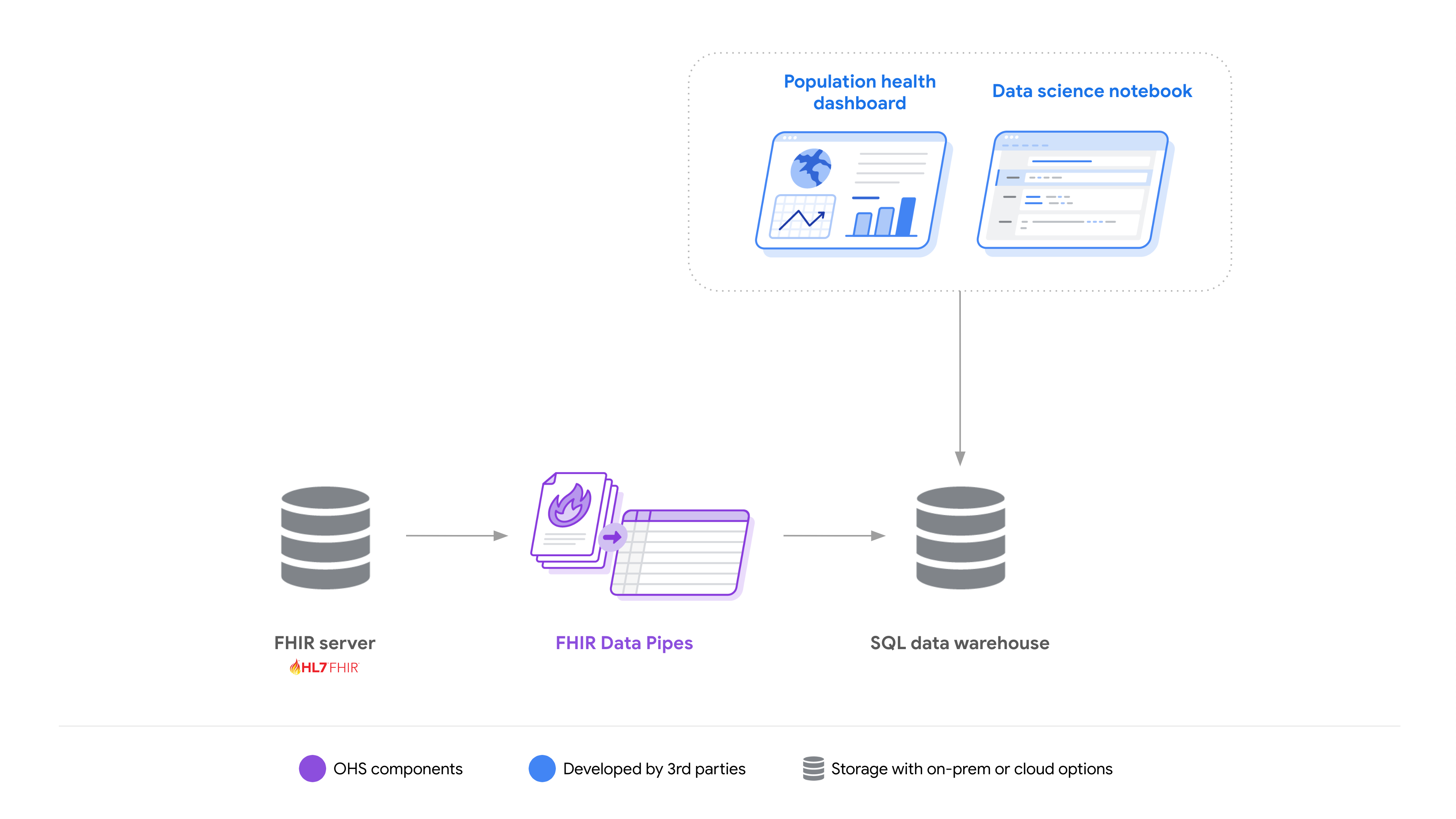
इनकी मदद से, डेवलपर अलग-अलग तरह के इस्तेमाल के उदाहरणों के लिए, अलग-अलग टेक्नोलॉजी का इस्तेमाल करके, आंकड़े जुटाने के समाधानों को आसानी से बना और डिप्लॉय कर सकते हैं.
FHIR डेटा पाइप और इसके कॉम्पोनेंट के बारे में ज़्यादा जानें:
जब तक कुछ अलग से न बताया जाए, तब तक इस पेज की सामग्री को Creative Commons Attribution 4.0 License के तहत और कोड के नमूनों को Apache 2.0 License के तहत लाइसेंस मिला है. ज़्यादा जानकारी के लिए, Google Developers साइट नीतियां देखें. Oracle और/या इससे जुड़ी हुई कंपनियों का, Java एक रजिस्टर किया हुआ ट्रेडमार्क है.
आखिरी बार 2025-07-25 (UTC) को अपडेट किया गया.
[[["समझने में आसान है","easyToUnderstand","thumb-up"],["मेरी समस्या हल हो गई","solvedMyProblem","thumb-up"],["अन्य","otherUp","thumb-up"]],[["वह जानकारी मौजूद नहीं है जो मुझे चाहिए","missingTheInformationINeed","thumb-down"],["बहुत मुश्किल है / बहुत सारे चरण हैं","tooComplicatedTooManySteps","thumb-down"],["पुराना","outOfDate","thumb-down"],["अनुवाद से जुड़ी समस्या","translationIssue","thumb-down"],["सैंपल / कोड से जुड़ी समस्या","samplesCodeIssue","thumb-down"],["अन्य","otherDown","thumb-down"]],["आखिरी बार 2025-07-25 (UTC) को अपडेट किया गया."],[],["FHIR Data Pipes addresses the complexity of analyzing FHIR data by providing tools for developers. It includes ETL pipelines that convert FHIR resources to Parquet-on-FHIR schema, a view definition layer, and query engine connectors. Designed for scalability and flexible deployment, it can run on-premises, in the cloud, or on a single machine. These tools facilitate the development and deployment of analytics solutions across diverse use cases by simplifying FHIR data handling.\n"]]