
PLACES_COUNT_PER_TYPE_V2 函式會傳回 BigQuery 資料表,其中包含多個輸入地理區域的場所數量和範例地點 ID,並依場所類型細分。這個函式的設計目的是接受地理區域的輸入資料表參數,以有效率地批次處理資料。您透過輸入資料表提供地理區域,並將地點類型指定為陣列。
語法
SELECT * FROM `PROJECT_NAME.LINKED_DATASET_NAME.PLACES_COUNT_PER_TYPE_V2`( TABLE input_geographies, target_types, filters )
參數
PROJECT_NAME:Google Cloud 專案的名稱。LINKED_DATASET_NAME:包含 Places Insights 函式的 BigQuery 資料集名稱 (例如places_insights___us)。input_geographies:包含要分析地理區域的 BigQuery 資料表。這個資料表必須包含下列資料欄:target_types(ARRAY<STRING>):要取得計數的地點類型字串陣列。如果地點符合types陣列中任何類型 (不只是primary_type),就會計入。filters(JSON):JSON 物件,包含地點的鍵/值組合,可進一步篩選地點。請參閱「篩選參數」。
輸出資料表結構定義
PLACES_COUNT_PER_TYPE_V2 函式會傳回含有下列資料欄的資料表:
| 資料欄名稱 | 資料類型 | 說明 |
|---|---|---|
geo_id |
STRING | 輸入地理區域的專屬 ID,來自 input_geographies 表格。 |
input_geography |
GEOGRAPHY | input_geographies 表格中的原始 GEOGRAPHY 物件。 |
place_type |
STRING | 這個資料列代表 target_types 陣列中的地點類型。 |
place_count |
INTEGER | 符合地理區域內或附近 place_type 和其他篩選條件的地點數量。 |
sample_place_ids |
ARRAY<STRING> | 最多 250 個地點 ID 的陣列,符合此類型和地理區域的條件。 |
即使計數為零,輸出內容也會針對 target_types 陣列中指定的每個 geo_id 和 place_type 組合,包含一個資料列。
運作方式
函式會處理 input_geographies 表格中提供的每個地理位置。針對每個地理區域,系統會計算符合 任何 target_types 陣列所列類型的地點,以及滿足 filters JSON 物件中所有條件的地點。結果會依每個 geo_id 和 target_types 中的每個類型匯總及細分。
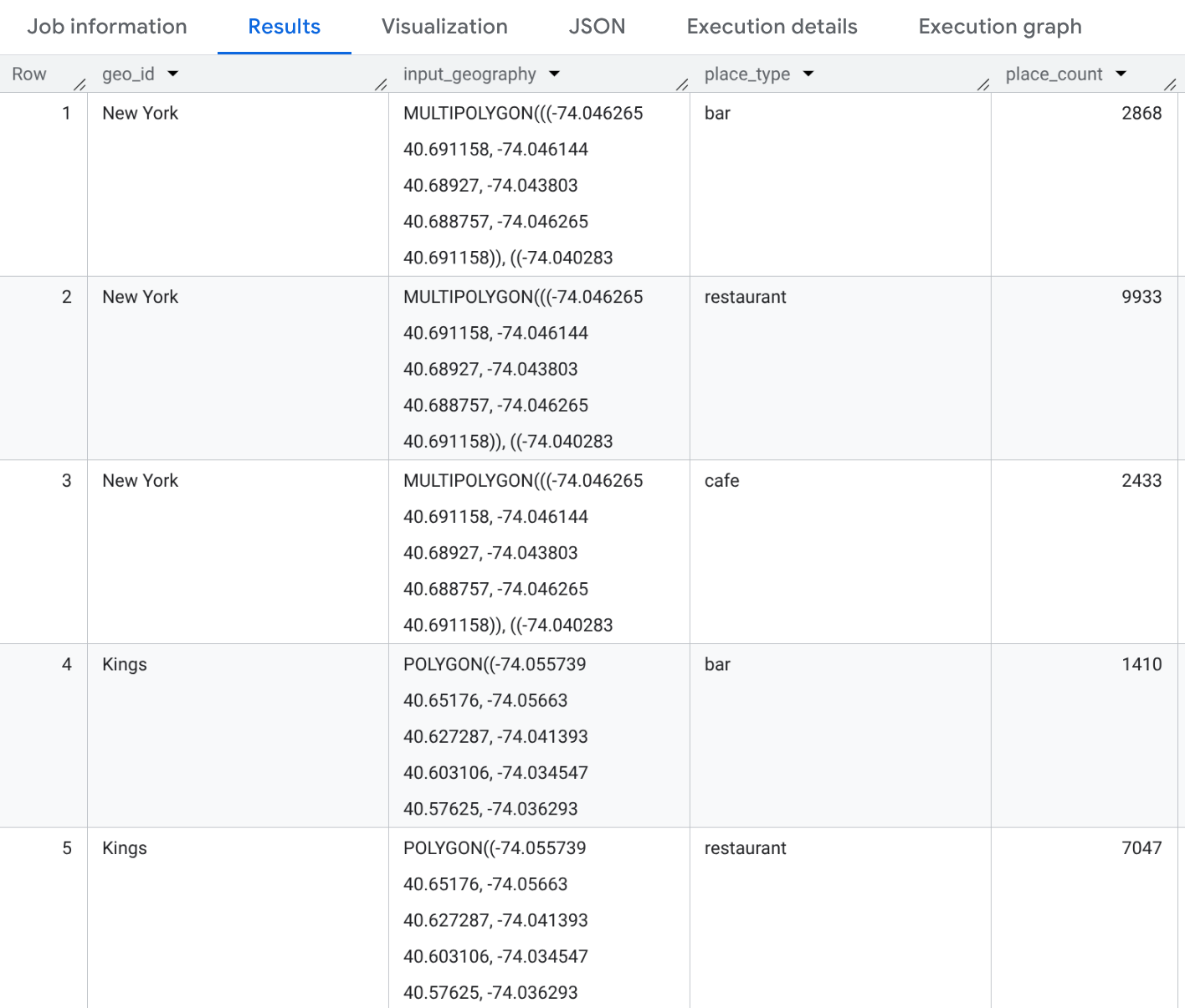
範例:計算紐約市各郡的不同類型餐廳
這個範例會產生表格,列出紐約市三個郡的「餐廳」、「咖啡廳」和「酒吧」類型數量。
SELECT geo_id, input_geography, place_type, place_count FROM `PROJECT_NAME.places_insights___us.PLACES_COUNT_PER_TYPE_V2`( ( SELECT county_name AS geo_id, ST_SIMPLIFY(county_geom, 100) AS geo FROM `bigquery-public-data.geo_us_boundaries.counties` WHERE state_fips_code = "36" -- New York State AND county_name IN ("Queens", "Kings", "New York") ), ['restaurant', 'cafe', 'bar'], -- target_types JSON_OBJECT( 'business_status', ['OPERATIONAL'] ) );
結果會是含有 9 個資料列的資料表 (3 個縣市 * 3 種類型)。每列都會顯示各郡內的「餐廳」、「咖啡廳」或「酒吧」數量。如果將地點 ID 加入 SELECT 陳述式,也可以一併提供範例。
使用 PLACES_COUNT_PER_TYPE_V2 的好處
PLACES_COUNT_PER_TYPE_V2 有幾項主要優勢,特別是與舊版 PLACES_COUNT_PER_TYPE 函式相比時:
- 批次處理地理位置:與一次處理一個地理位置的
PLACES_COUNT_PER_TYPE不同,PLACES_COUNT_PER_TYPE_V2接受TABLE輸入地理位置。這樣一來,您就能在單一查詢中分析並取得多個地理區域 (點、多邊形) 的特定類型計數,而不必進行多次函式呼叫。 - 提升效能和擴充性:只要輸入資料表,
PLACES_COUNT_PER_TYPE_V2就能利用 BigQuery 的最佳化地理空間聯結,以及所有提供地理位置的平行處理功能。這樣一來,處理大量地理區域時,效能會大幅提升,擴充性也會更好。 - 包含零計數:傳回批次中特定區域內找不到的類型,且計數為 0 的資料列,確保所有類型與地理位置組合的結果集完整無缺。