
Цель
В руководстве по высокопроизводительной проверке адресов были рассмотрены различные сценарии использования такой проверки. В этом руководстве мы познакомим вас с различными шаблонами проектирования в Google Cloud Platform для выполнения высокопроизводительной проверки адресов.
Начнём с обзора выполнения высокопроизводительной проверки адресов в Google Cloud Platform с помощью Cloud Run, Compute Engine или Google Kubernetes Engine для однократного выполнения. Затем рассмотрим, как эту возможность можно интегрировать в конвейер обработки данных.
К концу этой статьи у вас должно сложиться хорошее понимание различных вариантов выполнения проверки адресов в больших объемах в вашей среде Google Cloud.
Эталонная архитектура на платформе Google Cloud
В этом разделе более подробно рассматриваются различные шаблоны проектирования для высокопроизводительной проверки адресов с использованием платформы Google Cloud Platform . Работа на платформе Google Cloud Platform позволяет интегрировать систему с существующими процессами и конвейерами обработки данных.
Однократное выполнение высокопроизводительной проверки адресов на платформе Google Cloud.
Ниже представлена типовая архитектура интеграции на платформе Google Cloud Platform, которая больше подходит для разовых операций или тестирования.

В этом случае мы рекомендуем загрузить CSV-файл в хранилище Cloud Storage . Затем скрипт проверки адресов для больших объемов данных можно запустить из среды Cloud Run . Однако вы можете запустить его в любой другой среде выполнения, например, Compute Engine или Google Kubernetes Engine . Полученный CSV-файл также можно загрузить в хранилище Cloud Storage .
Работает как конвейер обработки данных Google Cloud Platform.
Представленная в предыдущем разделе схема развертывания отлично подходит для быстрого тестирования высокопроизводительной проверки адресов при однократном использовании. Однако, если вам необходимо использовать ее регулярно в рамках конвейера обработки данных, вы можете лучше использовать встроенные возможности Google Cloud Platform для повышения ее надежности. Среди возможных изменений можно выделить следующие:
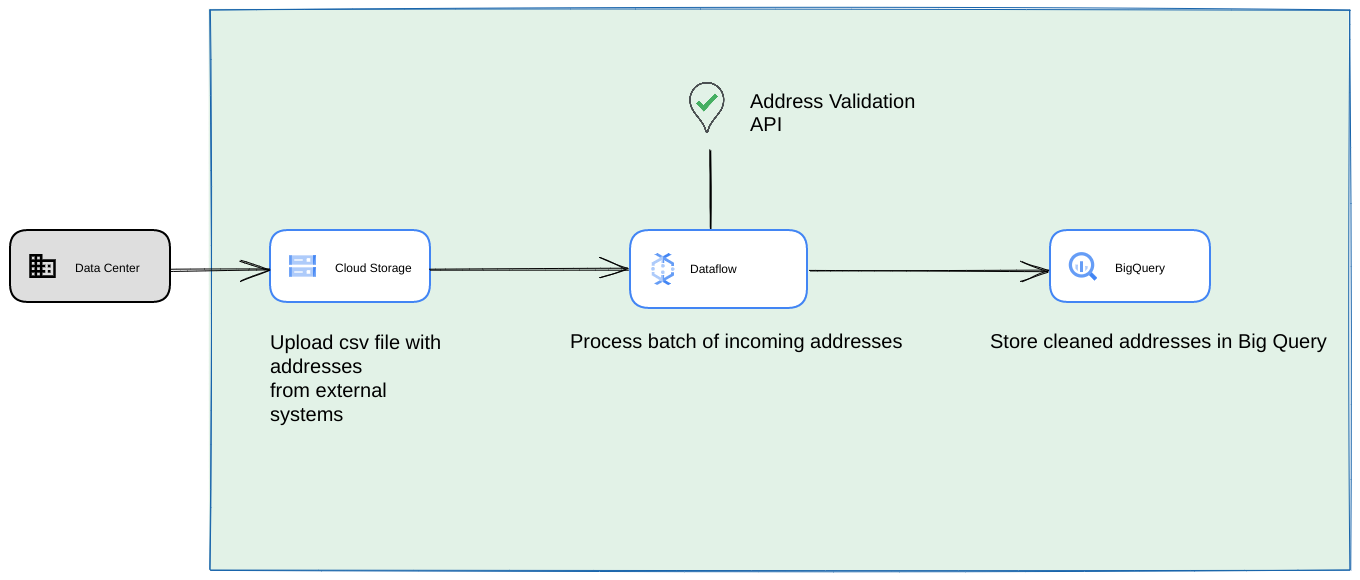
- В этом случае вы можете выгружать CSV-файлы в хранилища Cloud Storage .
- Задача Dataflow может получить адреса для обработки, а затем кэшировать их в BigQuery .
- Библиотеку Dataflow на Python можно расширить, добавив логику для проверки адресов при больших объемах данных, чтобы проверять адреса, полученные из задания Dataflow.
Запуск скрипта из конвейера обработки данных в виде длительно повторяющегося процесса.
Другой распространенный подход заключается в проверке пакета адресов в рамках потокового конвейера обработки данных в качестве повторяющегося процесса. Адреса также могут храниться в хранилище данных BigQuery. В этом подходе мы рассмотрим, как построить повторяющийся конвейер обработки данных (который должен запускаться ежедневно/еженедельно/ежемесячно).
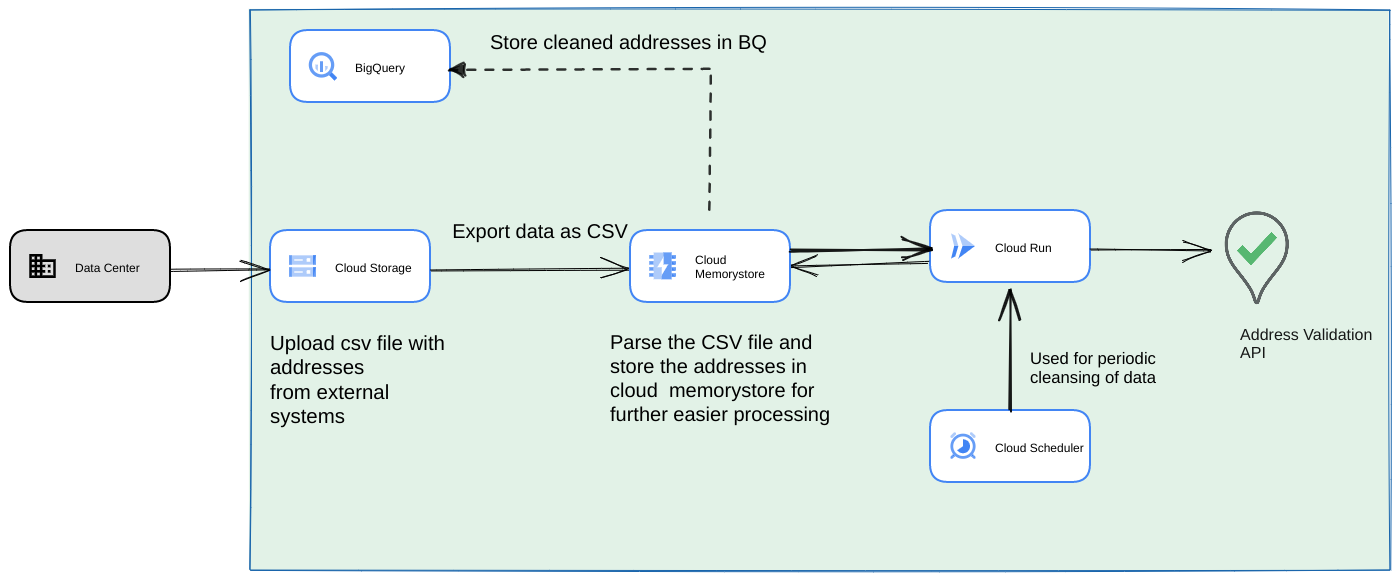
- Загрузите исходный CSV-файл в хранилище Cloud Storage .
- Используйте Memorystore в качестве постоянного хранилища данных для поддержания промежуточного состояния в течение длительного процесса.
- Кэшируйте конечные адреса в хранилище данных BigQuery .
- Настройте Cloud Scheduler для периодического запуска скрипта.
Данная архитектура обладает следующими преимуществами:
- С помощью Cloud Scheduler проверку адресов можно проводить периодически. Возможно, вам потребуется перепроверять адреса ежемесячно или проверять новые адреса ежемесячно/ежеквартально. Эта архитектура помогает решить эту задачу.
Если данные о клиентах хранятся в BigQuery , то проверенные адреса или флаги проверки могут быть кэшированы непосредственно там. Примечание: Что можно кэшировать и как это сделать, подробно описано в статье «Проверка адресов в больших объемах».
Использование Memorystore обеспечивает более высокую отказоустойчивость и возможность обработки большего количества адресов. Этот шаг добавляет состояние ко всему конвейеру обработки, что необходимо для работы с очень большими наборами данных адресов. Здесь также можно использовать другие технологии баз данных, такие как Cloud SQL [https://cloud.google.com/sql] или любой другой тип баз данных , предлагаемый облачной платформой Google. Однако мы считаем, что Memorystore идеально сочетает в себе масштабируемость и простоту, поэтому должен быть предпочтительным выбором.
Заключение
Применяя описанные здесь шаблоны, вы можете использовать API проверки адресов для различных сценариев использования и в различных контекстах на платформе Google Cloud Platform.
Мы разработали библиотеку Python с открытым исходным кодом, которая поможет вам начать работу с описанными выше сценариями использования. Ее можно запустить из командной строки на вашем компьютере, а также из Google Cloud Platform или других облачных провайдеров.
Подробнее о том, как пользоваться библиотекой, вы можете узнать из этой статьи .
Следующие шаги
Загрузите документ «Улучшение процесса оформления заказа, доставки и операций с помощью надежных адресов» и посмотрите вебинар « Улучшение процесса оформления заказа, доставки и операций с помощью проверки адресов» .
Рекомендуемая дополнительная литература:
- Документация по API проверки адресов
- Геокодирование и проверка адресов
- Ознакомьтесь с демонстрацией проверки адресов.
Авторы
Данная статья поддерживается компанией Google. Ее первоначальный автор — следующие лица.
Основные авторы:
Хенрик Вальв | Инженер по решениям
Томас Англаре | Инженер по решениям
Сартак Гангули | Инженер по решениям