قبل از اینکه داده های ما به یک مدل داده شوند، باید به قالبی تبدیل شوند که مدل قابل درک باشد.
اول، نمونههای دادهای که جمعآوری کردهایم ممکن است به ترتیب خاصی باشند. ما نمی خواهیم هیچ اطلاعات مرتبط با ترتیب نمونه ها بر رابطه بین متون و برچسب ها تأثیر بگذارد. به عنوان مثال، اگر یک مجموعه داده بر اساس کلاس مرتب شده و سپس به مجموعه های آموزشی/اعتباری تقسیم شود، این مجموعه ها نماینده توزیع کلی داده ها نخواهند بود.
بهترین روش ساده برای اطمینان از اینکه مدل تحت تأثیر ترتیب داده ها قرار نمی گیرد، این است که همیشه داده ها را قبل از انجام هر کار دیگری به هم بزنید. اگر دادههای شما قبلاً به مجموعههای آموزشی و اعتبارسنجی تقسیم شدهاند، مطمئن شوید که دادههای اعتبارسنجی خود را به همان روشی که دادههای آموزشی خود را تغییر میدهید تغییر دهید. اگر قبلاً مجموعههای آموزشی و اعتبارسنجی جداگانه ندارید، میتوانید نمونهها را پس از به هم زدن تقسیم کنید. استفاده از 80 درصد از نمونه ها برای آموزش و 20 درصد برای اعتبار سنجی معمول است.
دوم، الگوریتم های یادگیری ماشین اعداد را به عنوان ورودی می گیرند. این بدان معنی است که ما باید متن ها را به بردارهای عددی تبدیل کنیم. دو مرحله برای این فرآیند وجود دارد:
Tokenization : متون را به کلمات یا زیرمتن های کوچکتر تقسیم کنید، که باعث تعمیم خوب رابطه بین متون و برچسب ها می شود. این "واژگان" مجموعه داده (مجموعه ای از نشانه های منحصر به فرد موجود در داده ها) را تعیین می کند.
برداری : یک معیار عددی خوب برای مشخص کردن این متون تعریف کنید.
بیایید ببینیم که چگونه این دو مرحله را برای بردارهای n-gram و بردارهای دنباله انجام دهیم، و همچنین نحوه بهینه سازی نمایش های برداری را با استفاده از تکنیک های انتخاب ویژگی و نرمال سازی.
بردارهای N گرم [گزینه A]
در پاراگراف های بعدی، نحوه انجام توکن سازی و برداری را برای مدل های n-gram خواهیم دید. همچنین نحوه بهینه سازی نمایش ngram را با استفاده از تکنیک های انتخاب ویژگی و عادی سازی پوشش خواهیم داد.
در یک بردار n-gram، متن به عنوان مجموعه ای از n-gram های منحصر به فرد نشان داده می شود: گروه هایی از n نشانه مجاور (معمولاً، کلمات). متن را در نظر بگیرید. The mouse ran up the clock . اینجا:
- کلمه unigrams (n = 1)
['the', 'mouse', 'ran', 'up', 'clock']است. - کلمه بیگرام (n = 2) عبارتند از
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - و غیره.
توکن سازی
ما متوجه شدهایم که توکن کردن به یونیگرامهای کلمه + بیگرام دقت خوبی را فراهم میکند در حالی که زمان محاسبه کمتری را میگیرد.
برداری
هنگامی که نمونههای متن خود را به n-گرم تقسیم کردیم، باید این n-گرمها را به بردارهای عددی تبدیل کنیم که مدلهای یادگیری ماشینی ما بتوانند آنها را پردازش کنند. مثال زیر نمایه های اختصاص داده شده به یونیگرام ها و بیگرام های تولید شده برای دو متن را نشان می دهد.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
هنگامی که شاخص ها به n-gram اختصاص داده می شوند، ما معمولاً با استفاده از یکی از گزینه های زیر بردار می کنیم.
رمزگذاری تک داغ : هر متن نمونه به عنوان یک بردار نشان داده می شود که وجود یا عدم وجود یک نشانه در متن را نشان می دهد.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
رمزگذاری شمارش : هر متن نمونه به عنوان یک بردار نشان داده می شود که تعداد یک نشانه در متن را نشان می دهد. توجه داشته باشید که عنصر مربوط به unigram 'the' اکنون به صورت 2 نشان داده می شود زیرا کلمه "the" دو بار در متن ظاهر می شود.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
رمزگذاری Tf-idf : مشکل دو رویکرد بالا این است که کلمات رایجی که در فرکانسهای مشابه در همه اسناد رخ میدهند (یعنی کلماتی که مخصوصاً منحصر به نمونههای متن در مجموعه داده نیستند) جریمه نمیشوند. به عنوان مثال، کلماتی مانند "الف" در همه متون بسیار تکرار می شوند. بنابراین تعداد نشانه های بالاتر برای "the" نسبت به سایر کلمات معنی دارتر چندان مفید نیست.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(به TfidfTransformer Scikit-learn مراجعه کنید)
بازنمودهای برداری دیگری نیز وجود دارد، اما سه مورد قبلی بیشترین استفاده را دارند.
ما مشاهده کردیم که رمزگذاری tf-idf از نظر دقت بسیار بهتر از دو مورد دیگر است (به طور متوسط: 0.25-15٪ بیشتر)، و استفاده از این روش را برای بردار کردن n-گرم توصیه می کنیم. با این حال، به خاطر داشته باشید که حافظه بیشتری را اشغال می کند (زیرا از نمایش ممیز شناور استفاده می کند) و زمان بیشتری برای محاسبه نیاز دارد، به خصوص برای مجموعه داده های بزرگ (در برخی موارد ممکن است دو برابر بیشتر طول بکشد).
انتخاب ویژگی
وقتی همه متون موجود در یک مجموعه داده را به توکن های کلمه uni+bigram تبدیل می کنیم، ممکن است ده ها هزار توکن داشته باشیم. همه این نشانهها/ویژگیها به پیشبینی برچسب کمک نمیکنند. بنابراین میتوانیم توکنهای خاصی را رها کنیم، برای مثال آنهایی که به ندرت در مجموعه دادهها رخ میدهند. همچنین میتوانیم اهمیت ویژگی را اندازهگیری کنیم (چقدر هر نشانه در پیشبینی برچسبها نقش دارد)، و فقط آموزندهترین توکنها را شامل شود.
توابع آماری زیادی وجود دارند که ویژگی ها و برچسب های مربوطه را می گیرند و امتیاز اهمیت ویژگی را به دست می آورند. دو تابع متداول f_classif و chi2 هستند. آزمایشهای ما نشان میدهد که هر دوی این عملکردها به یک اندازه خوب عمل میکنند.
مهمتر از آن، دیدیم که دقت در حدود 20000 ویژگی برای بسیاری از مجموعه داده ها به اوج می رسد ( شکل 6 را ببینید). افزودن ویژگیهای بیشتر بیش از این آستانه کمک بسیار کمی میکند و گاهی اوقات حتی منجر به تطبیق بیش از حد و کاهش عملکرد میشود.

شکل 6: ویژگی های برتر K در مقابل دقت . در میان مجموعه دادهها، دقت در حدود 20 هزار ویژگی برتر است.
عادی سازی
عادی سازی تمام مقادیر ویژگی/نمونه را به مقادیر کوچک و مشابه تبدیل می کند. این امر همگرایی نزولی گرادیان را در الگوریتم های یادگیری ساده می کند. با توجه به آنچه دیده ایم، به نظر نمی رسد نرمال سازی در طول پیش پردازش داده ها ارزش زیادی در مسائل طبقه بندی متن بیافزاید. توصیه می کنیم از این مرحله صرف نظر کنید.
کد زیر تمامی مراحل فوق را در کنار هم قرار می دهد:
- نمونههای متن را به شکل کلمه uni+bigram تبدیل کنید،
- بردار سازی با استفاده از رمزگذاری tf-idf،
- تنها 20000 ویژگی برتر را از بردار توکن ها با دور انداختن نشانه هایی که کمتر از 2 بار ظاهر می شوند و استفاده از f_classif برای محاسبه اهمیت ویژگی انتخاب کنید.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
با نمایش برداری n-gram، ما بسیاری از اطلاعات مربوط به ترتیب کلمات و دستور زبان را کنار می گذاریم (در بهترین حالت، می توانیم برخی از اطلاعات ترتیب جزئی را زمانی که n> 1 نگه داریم). به این رویکرد کیسه ای از کلمات می گویند. این نمایش همراه با مدلهایی استفاده میشود که ترتیب را در نظر نمیگیرند، مانند رگرسیون لجستیک، پرسپترونهای چند لایه، ماشینهای تقویت گرادیان، ماشینهای بردار پشتیبان.
بردارهای دنباله [گزینه B]
در پاراگراف های بعدی، نحوه انجام توکن سازی و برداری برای مدل های دنباله را خواهیم دید. ما همچنین نحوه بهینه سازی نمایش دنباله را با استفاده از تکنیک های انتخاب ویژگی و نرمال سازی پوشش خواهیم داد.
برای برخی از نمونه های متن، ترتیب کلمات برای معنای متن بسیار مهم است. به عنوان مثال، جملات «من از رفت و آمدم متنفر بودم. دوچرخه جدید من آن را کاملاً تغییر داد» فقط زمانی قابل درک است که به ترتیب خوانده شود. مدلهایی مانند CNN/RNN میتوانند از ترتیب کلمات در یک نمونه معنا را استنتاج کنند. برای این مدلها، متن را بهعنوان دنبالهای از نشانهها با حفظ نظم نشان میدهیم.
توکن سازی
متن را می توان به صورت دنباله ای از کاراکترها یا دنباله ای از کلمات نشان داد. ما دریافتیم که استفاده از نمایش در سطح کلمه عملکرد بهتری نسبت به نشانه های کاراکتر ارائه می دهد. این نیز هنجار عمومی است که توسط صنعت دنبال می شود. استفاده از نشانه های کاراکتر فقط در صورتی منطقی است که متون دارای اشتباهات تایپی زیادی باشند، که معمولاً اینطور نیست.
برداری
هنگامی که نمونه های متن خود را به دنباله ای از کلمات تبدیل کردیم، باید این توالی ها را به بردارهای عددی تبدیل کنیم. مثال زیر نمایه های تخصیص داده شده به یونیگرام های تولید شده برای دو متن و سپس توالی شاخص های نشانه ای را نشان می دهد که اولین متن به آن تبدیل می شود.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
شاخص اختصاص داده شده برای هر نشانه:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
نکته: کلمه "the" اغلب به کار می رود، بنابراین مقدار شاخص 1 به آن اختصاص داده می شود. برخی از کتابخانهها برای توکنهای ناشناخته 0 را ذخیره میکنند، همانطور که در اینجا وجود دارد.
توالی شاخص های نشانه:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
دو گزینه برای بردار کردن دنباله های نشانه وجود دارد:
رمزگذاری تک داغ : دنباله ها با استفاده از بردارهای کلمه در فضای n بعدی نشان داده می شوند که در آن n = اندازه واژگان است. این نمایش زمانی که به عنوان شخصیتها نشانهگذاری میکنیم عالی عمل میکند، و بنابراین دایره واژگان کوچک است. هنگامی که ما در حال توکن سازی به عنوان کلمات هستیم، واژگان معمولاً ده ها هزار نشانه دارد، که بردارهای یک داغ را بسیار پراکنده و ناکارآمد می کند. مثال:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
تعبیه کلمات : کلمات دارای معنی(های) مرتبط با آنها هستند. در نتیجه، میتوانیم نشانههای کلمه را در یک فضای برداری متراکم (تقریبا چند صد عدد واقعی) نشان دهیم، جایی که مکان و فاصله بین کلمات نشان میدهد که چقدر از نظر معنایی مشابه هستند ( شکل 7 را ببینید). این نمایش را تعبیه کلمه می نامند.
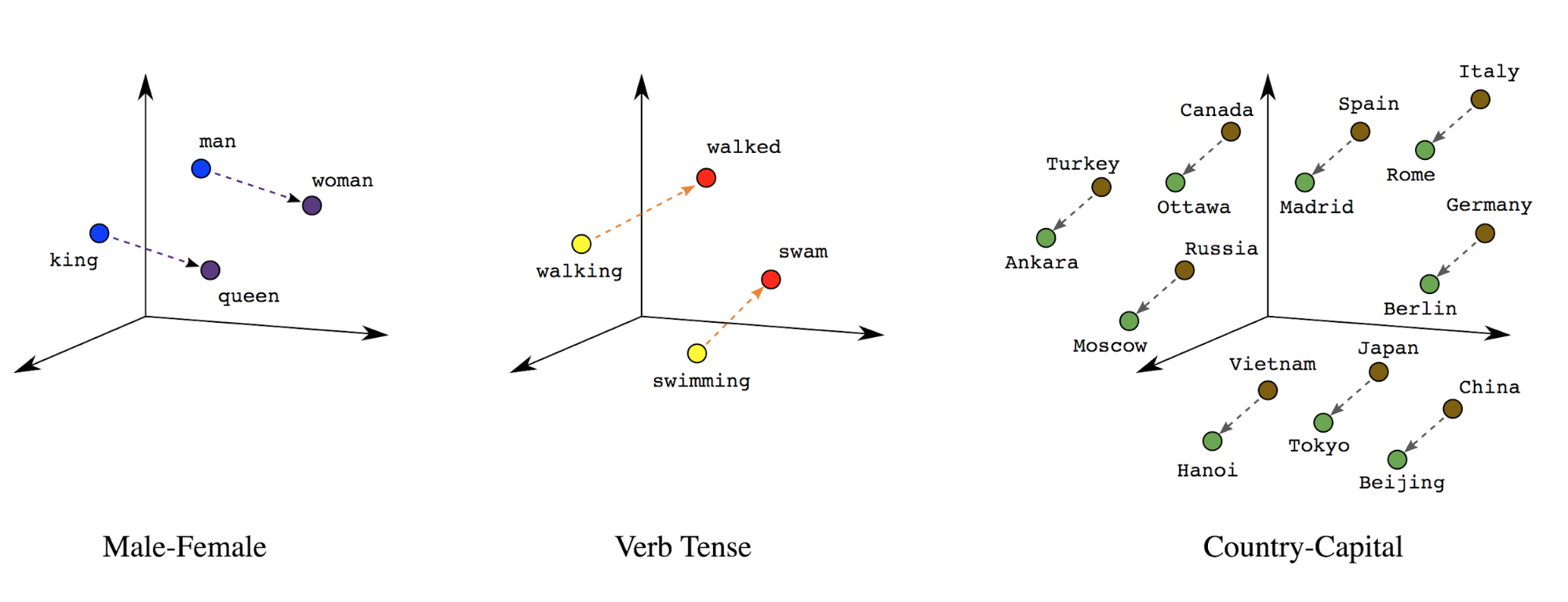
شکل 7: جاسازی کلمات
مدلهای دنبالهای اغلب دارای چنین لایهای به عنوان لایه اول هستند. این لایه یاد میگیرد که در طول فرآیند آموزش، توالیهای فهرست کلمات را به بردارهای جاسازی کلمه تبدیل کند، به طوری که هر فهرست واژه به بردار متراکمی از مقادیر واقعی نشاندهنده مکان آن کلمه در فضای معنایی نگاشت میشود ( شکل 8 را ببینید).
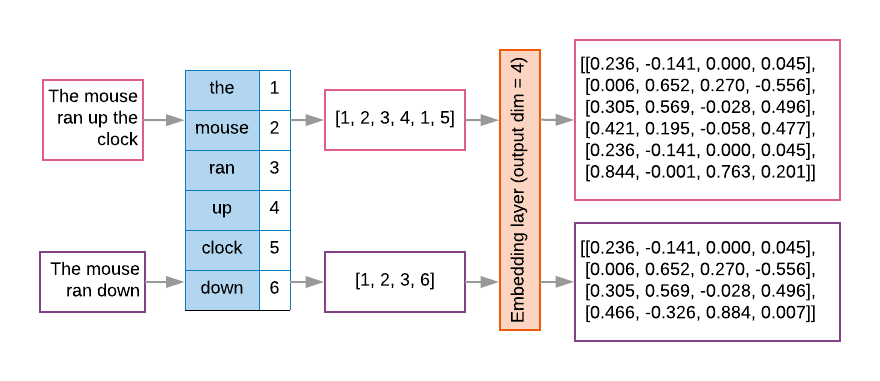
شکل 8: لایه جاسازی
انتخاب ویژگی
همه کلمات در داده های ما به پیش بینی برچسب کمک نمی کنند. ما می توانیم فرآیند یادگیری خود را با حذف کلمات کمیاب یا نامربوط از دایره لغات خود بهینه کنیم. در واقع، مشاهده می کنیم که استفاده از متداول ترین 20000 ویژگی به طور کلی کافی است. این برای مدل های n-gram نیز صادق است ( شکل 6 را ببینید).
بیایید تمام مراحل بالا را در بردارسازی ترتیبی با هم قرار دهیم. کد زیر این وظایف را انجام می دهد:
- متون را به کلمات تبدیل می کند
- با استفاده از 20000 توکن برتر واژگان ایجاد می کند
- توکن ها را به بردارهای دنباله ای تبدیل می کند
- دنباله ها را به طول دنباله ثابتی اضافه می کند
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
بردارسازی برچسب
ما دیدیم که چگونه داده های متن نمونه را به بردارهای عددی تبدیل کنیم. فرآیند مشابهی باید روی برچسب ها اعمال شود. ما به سادگی می توانیم برچسب ها را به مقادیر در محدوده [0, num_classes - 1] تبدیل کنیم. به عنوان مثال، اگر 3 کلاس وجود دارد، می توانیم فقط از مقادیر 0، 1 و 2 برای نمایش آنها استفاده کنیم. در داخل، شبکه از بردارهای یک داغ برای نمایش این مقادیر استفاده می کند (برای جلوگیری از استنتاج رابطه نادرست بین برچسب ها). این نمایش به تابع از دست دادن و تابع فعال سازی آخرین لایه ای که در شبکه عصبی خود استفاده می کنیم بستگی دارد. در بخش بعدی با این موارد بیشتر آشنا خواهیم شد.