در این مرحله، ما مجموعه دادههای خود را جمعآوری کردهایم و بینشهایی در مورد ویژگیهای کلیدی دادههای خود به دست آوردهایم. در مرحله بعد، بر اساس معیارهایی که در مرحله 2 جمع آوری کردیم، باید به این فکر کنیم که از کدام مدل طبقه بندی استفاده کنیم. یعنی پرسیدن سوالاتی از قبیل:
- چگونه داده های متنی را به الگوریتمی ارائه می کنید که انتظار ورودی عددی را دارد؟ (به این کار پیش پردازش داده و بردارسازی می گویند.)
- از چه مدلی باید استفاده کنید؟
- از چه پارامترهای پیکربندی باید برای مدل خود استفاده کنید؟
به لطف چندین دهه تحقیق، ما به مجموعه وسیعی از پیش پردازش داده ها و گزینه های پیکربندی مدل دسترسی داریم. با این حال، در دسترس بودن یک آرایه بسیار بزرگ از گزینه های قابل دوام برای انتخاب می تواند پیچیدگی و دامنه یک مشکل خاص را تا حد زیادی افزایش دهد. با توجه به اینکه بهترین گزینه ها ممکن است واضح نباشند، یک راه حل ساده لوحانه این است که همه گزینه های ممکن را به طور کامل امتحان کنید و برخی از انتخاب ها را از طریق شهود هرس کنید. با این حال، این بسیار گران خواهد بود.
در این راهنما، ما تلاش می کنیم تا فرآیند انتخاب یک مدل طبقه بندی متن را به طور قابل توجهی ساده کنیم. برای یک مجموعه داده معین، هدف ما یافتن الگوریتمی است که به حداکثر دقت نزدیک میشود و زمان محاسبات مورد نیاز برای آموزش را به حداقل میرساند. ما تعداد زیادی (~450 هزار) آزمایش را در مورد مشکلات انواع مختلف (به ویژه تجزیه و تحلیل احساسات و مشکلات طبقهبندی موضوع)، با استفاده از 12 مجموعه داده، به طور متناوب برای هر مجموعه داده بین تکنیکهای پیش پردازش دادههای مختلف و معماریهای مدل متفاوت انجام دادیم. این به ما کمک کرد تا پارامترهای مجموعه داده ای را شناسایی کنیم که بر انتخاب های بهینه تأثیر می گذارد.
الگوریتم انتخاب مدل و نمودار جریان زیر خلاصه ای از آزمایش ما است. اگر هنوز تمام اصطلاحات استفاده شده در آنها را متوجه نشده اید، نگران نباشید. بخش های بعدی این راهنما آنها را به طور عمیق توضیح می دهد.
الگوریتم آماده سازی داده و ساخت مدل
- تعداد نمونه ها / تعداد کلمات در نسبت نمونه را محاسبه کنید.
- اگر این نسبت کمتر از 1500 باشد، متن را به صورت n-گرم نشانه گذاری کنید و از یک مدل پرسپترون چند لایه ساده (MLP) برای طبقه بندی آنها استفاده کنید (شاخه سمت چپ در فلوچارت زیر):
- نمونه ها را به کلمه n-gram تقسیم کنید. n-گرم ها را به بردار تبدیل کنید.
- به اهمیت بردارها امتیاز دهید و سپس با استفاده از امتیازها، 20K برتر را انتخاب کنید.
- یک مدل MLP بسازید.
- اگر نسبت بزرگتر از 1500 باشد، متن را به صورت دنباله ای توکن کنید و از یک مدل sepCNN برای طبقه بندی آنها استفاده کنید (شاخه سمت راست در فلوچارت زیر):
- نمونه ها را به کلمات تقسیم کنید. 20 هزار کلمه برتر را بر اساس فراوانی آنها انتخاب کنید.
- نمونه ها را به بردارهای توالی کلمه تبدیل کنید.
- اگر تعداد نمونهها/تعداد واژهها در نسبت نمونه کمتر از 15K باشد، استفاده از یک جاسازی از پیش آموزشدیده دقیق با مدل sepCNN احتمالاً بهترین نتایج را ارائه میدهد.
- برای یافتن بهترین پیکربندی مدل برای مجموعه داده، عملکرد مدل را با مقادیر فراپارامترهای مختلف اندازه گیری کنید.
در فلوچارت زیر، کادرهای زرد رنگ فرآیندهای آماده سازی داده و مدل را نشان می دهند. جعبه های خاکستری و جعبه های سبز انتخاب هایی را که برای هر فرآیند در نظر گرفته ایم نشان می دهد. جعبه های سبز انتخاب پیشنهادی ما برای هر فرآیند را نشان می دهد.
شما می توانید از این نمودار جریان به عنوان نقطه شروع برای ساخت اولین آزمایش خود استفاده کنید، زیرا دقت خوبی در هزینه های محاسباتی کم به شما می دهد. سپس می توانید به بهبود مدل اولیه خود در تکرارهای بعدی ادامه دهید.
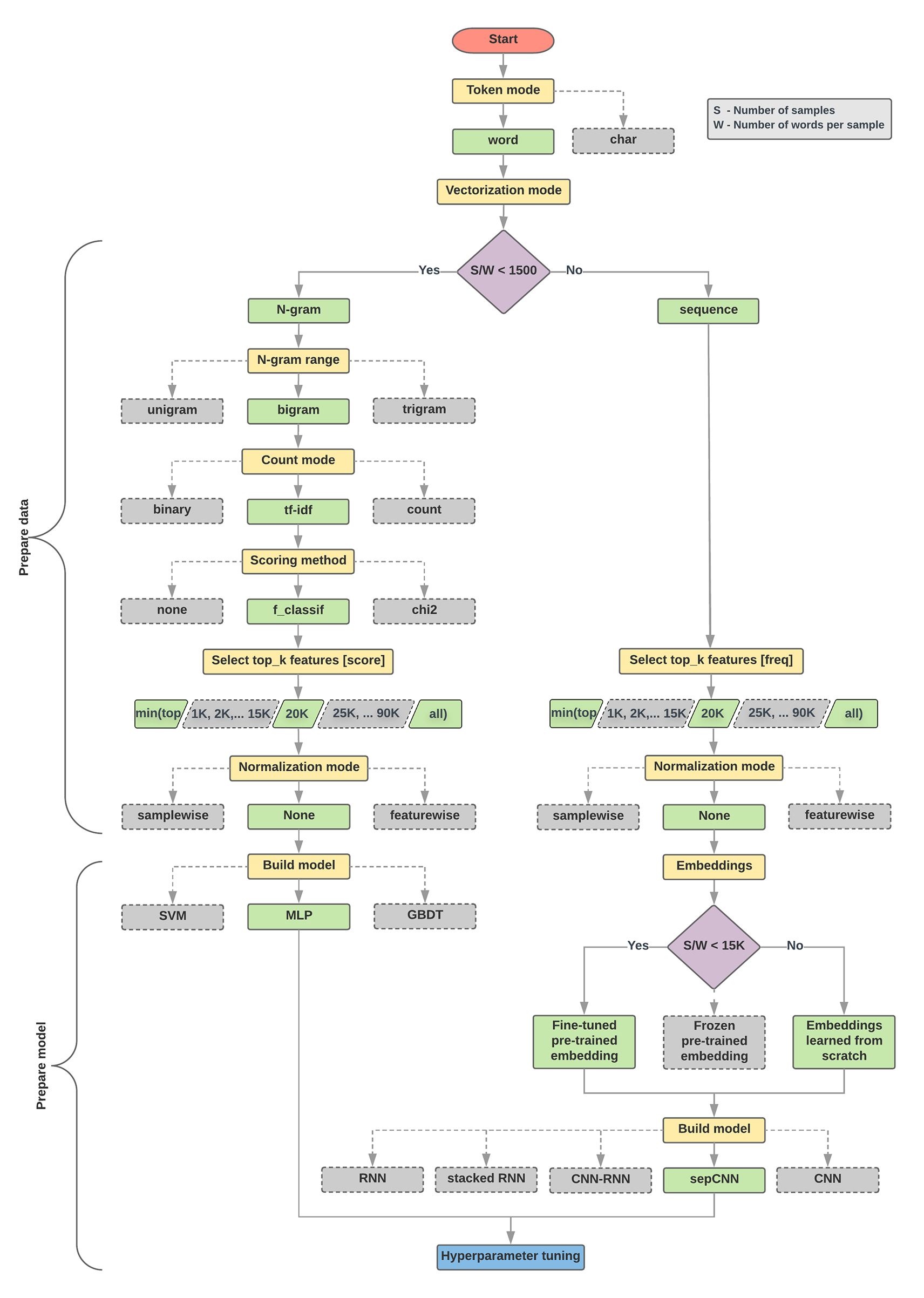
شکل 5: فلوچارت طبقه بندی متن
این فلوچارت به دو سوال کلیدی پاسخ می دهد:
- از کدام الگوریتم یا مدل یادگیری استفاده کنید؟
- چگونه باید داده ها را برای یادگیری موثر رابطه بین متن و برچسب آماده کنید؟
پاسخ به سؤال دوم بستگی به پاسخ سؤال اول دارد; روشی که ما دادهها را برای وارد کردن به یک مدل پیش پردازش میکنیم به مدلی که انتخاب میکنیم بستگی دارد. مدلها را میتوان به طور کلی به دو دسته طبقهبندی کرد: مدلهایی که از اطلاعات ترتیب کلمات استفاده میکنند (مدلهای توالی)، و مدلهایی که فقط متن را بهعنوان «کیسه» (مجموعهای) از کلمات میبینند (مدلهای n-gram). انواع مدلهای توالی شامل شبکههای عصبی کانولوشن (CNN)، شبکههای عصبی بازگشتی (RNN) و تغییرات آنهاست. انواع مدل های n-gram عبارتند از:
- رگرسیون لجستیک
- پرسپترون های چند لایه ساده (MLP یا شبکه های عصبی کاملا متصل)
- درختان شیب دار تقویت شده
- ماشین های بردار پشتیبانی
از آزمایشهایمان، مشاهده کردهایم که نسبت «تعداد نمونه» (S) به «تعداد کلمات در هر نمونه» (W) با اینکه کدام مدل خوب عمل میکند همبستگی دارد.
وقتی مقدار این نسبت کوچک است (<1500)، پرسپترون های چند لایه کوچکی که n-گرم را به عنوان ورودی می گیرند (که ما آن را گزینه A می نامیم) بهتر یا حداقل به خوبی مدل های توالی عمل می کنند. تعریف و درک MLPها ساده است و زمان محاسبه آنها بسیار کمتر از مدلهای توالی است. وقتی مقدار این نسبت بزرگ است (>= 1500)، از یک مدل توالی ( گزینه B ) استفاده کنید. در مراحل بعدی، میتوانید برای نوع مدلی که بر اساس نسبت نمونه/کلمات به نمونه انتخاب کردهاید، به زیربخشهای مربوطه (با برچسب A یا B ) بروید.
در مورد مجموعه داده بررسی IMDb ما، نسبت نمونه/کلمات به ازای نمونه ~144 است. این بدان معناست که ما یک مدل MLP ایجاد خواهیم کرد.