Page Summary
-
Text data is preprocessed by shuffling, splitting into training and validation sets, and converting it into numerical vectors for machine learning algorithms.
-
Two primary methods for vectorization are N-gram vectors (using techniques like TF-IDF) and sequence vectors (often utilizing word embeddings).
-
Feature selection, typically involving the top 20,000 most frequent words, is crucial to prevent overfitting and optimize model performance.
-
Sequence vectorization involves tokenization, vocabulary creation, sequence conversion, and padding to ensure uniform sequence length.
-
Labels are also numerically represented to facilitate model training and prediction.
Before our data can be fed to a model, it needs to be transformed to a format the model can understand.
First, the data samples that we have gathered may be in a specific order. We do not want any information associated with the ordering of samples to influence the relationship between texts and labels. For example, if a dataset is sorted by class and is then split into training/validation sets, these sets will not be representative of the overall distribution of data.
A simple best practice to ensure the model is not affected by data order is to always shuffle the data before doing anything else. If your data is already split into training and validation sets, make sure to transform your validation data the same way you transform your training data. If you don’t already have separate training and validation sets, you can split the samples after shuffling; it’s typical to use 80% of the samples for training and 20% for validation.
Second, machine learning algorithms take numbers as inputs. This means that we will need to convert the texts into numerical vectors. There are two steps to this process:
Tokenization: Divide the texts into words or smaller sub-texts, which will enable good generalization of relationship between the texts and the labels. This determines the “vocabulary” of the dataset (set of unique tokens present in the data).
Vectorization: Define a good numerical measure to characterize these texts.
Let’s see how to perform these two steps for both n-gram vectors and sequence vectors, as well as how to optimize the vector representations using feature selection and normalization techniques.
N-gram vectors [Option A]
In the subsequent paragraphs, we will see how to do tokenization and vectorization for n-gram models. We will also cover how we can optimize the n- gram representation using feature selection and normalization techniques.
In an n-gram vector, text is represented as a collection of unique n-grams:
groups of n adjacent tokens (typically, words). Consider the text The mouse ran
up the clock. Here:
- The word unigrams (n = 1) are
['the', 'mouse', 'ran', 'up', 'clock']. - The word bigrams (n = 2) are
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - And so on.
Tokenization
We have found that tokenizing into word unigrams + bigrams provides good accuracy while taking less compute time.
Vectorization
Once we have split our text samples into n-grams, we need to turn these n-grams into numerical vectors that our machine learning models can process. The example below shows the indexes assigned to the unigrams and bigrams generated for two texts.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
Once indexes are assigned to the n-grams, we typically vectorize using one of the following options.
One-hot encoding: Every sample text is represented as a vector indicating the presence or absence of a token in the text.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
Count encoding: Every sample text is represented as a vector indicating the
count of a token in the text. Note that the element corresponding to the
unigram 'the' is now represented as 2 because the word "the"
appears twice in the text.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Tf-idf encoding: The problem with the above two approaches is that common words that occur in similar frequencies in all documents (i.e., words that are not particularly unique to the text samples in the dataset) are not penalized. For example, words like “a” will occur very frequently in all texts. So a higher token count for “the” than for other more meaningful words is not very useful.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(See Scikit-learn TfidfTransformer)
There are many other vector representations, but the preceding three are the most commonly used.
We observed that tf-idf encoding is marginally better than the other two in terms of accuracy (on average: 0.25-15% higher), and recommend using this method for vectorizing n-grams. However, keep in mind that it occupies more memory (as it uses floating-point representation) and takes more time to compute, especially for large datasets (can take twice as long in some cases).
Feature selection
When we convert all of the texts in a dataset into word uni+bigram tokens, we may end up with tens of thousands of tokens. Not all of these tokens/features contribute to label prediction. So we can drop certain tokens, for instance those that occur extremely rarely across the dataset. We can also measure feature importance (how much each token contributes to label predictions), and only include the most informative tokens.
There are many statistical functions that take features and the corresponding labels and output the feature importance score. Two commonly used functions are f_classif and chi2. Our experiments show that both of these functions perform equally well.
More importantly, we saw that accuracy peaks at around 20,000 features for many datasets (See Figure 6). Adding more features over this threshold contributes very little and sometimes even leads to overfitting and degrades performance.

Figure 6: Top K features versus Accuracy. Across datasets, accuracy plateaus at around top 20K features.
Normalization
Normalization converts all feature/sample values to small and similar values. This simplifies gradient descent convergence in learning algorithms. From what we have seen, normalization during data preprocessing does not seem to add much value in text classification problems; we recommend skipping this step.
The following code puts together all of the above steps:
- Tokenize text samples into word uni+bigrams,
- Vectorize using tf-idf encoding,
- Select only the top 20,000 features from the vector of tokens by discarding tokens that appear fewer than 2 times and using f_classif to calculate feature importance.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
With n-gram vector representation, we discard a lot of information about word order and grammar (at best, we can maintain some partial ordering information when n > 1). This is called a bag-of-words approach. This representation is used in conjunction with models that don’t take ordering into account, such as logistic regression, multi-layer perceptrons, gradient boosting machines, support vector machines.
Sequence Vectors [Option B]
In the subsequent paragraphs, we will see how to do tokenization and vectorization for sequence models. We will also cover how we can optimize the sequence representation using feature selection and normalization techniques.
For some text samples, word order is critical to the text’s meaning. For example, the sentences, “I used to hate my commute. My new bike changed that completely” can be understood only when read in order. Models such as CNNs/RNNs can infer meaning from the order of words in a sample. For these models, we represent the text as a sequence of tokens, preserving order.
Tokenization
Text can be represented as either a sequence of characters, or a sequence of words. We have found that using word-level representation provides better performance than character tokens. This is also the general norm that is followed by industry. Using character tokens makes sense only if texts have lots of typos, which isn’t normally the case.
Vectorization
Once we have converted our text samples into sequences of words, we need to turn these sequences into numerical vectors. The example below shows the indexes assigned to the unigrams generated for two texts, and then the sequence of token indexes to which the first text is converted.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Index assigned for every token:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
NOTE: The word "the" occurs most frequently, so the index value of 1 is assigned to it. Some libraries reserve index 0 for unknown tokens, as is the case here.
Sequence of token indexes:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
There are two options available to vectorize the token sequences:
One-hot encoding: Sequences are represented using word vectors in n- dimensional space where n = size of vocabulary. This representation works great when we are tokenizing as characters, and the vocabulary is therefore small. When we are tokenizing as words, the vocabulary will usually have tens of thousands of tokens, making the one-hot vectors very sparse and inefficient. Example:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
Word embeddings: Words have meaning(s) associated with them. As a result, we can represent word tokens in a dense vector space (~few hundred real numbers), where the location and distance between words indicates how similar they are semantically (See Figure 7). This representation is called word embeddings.
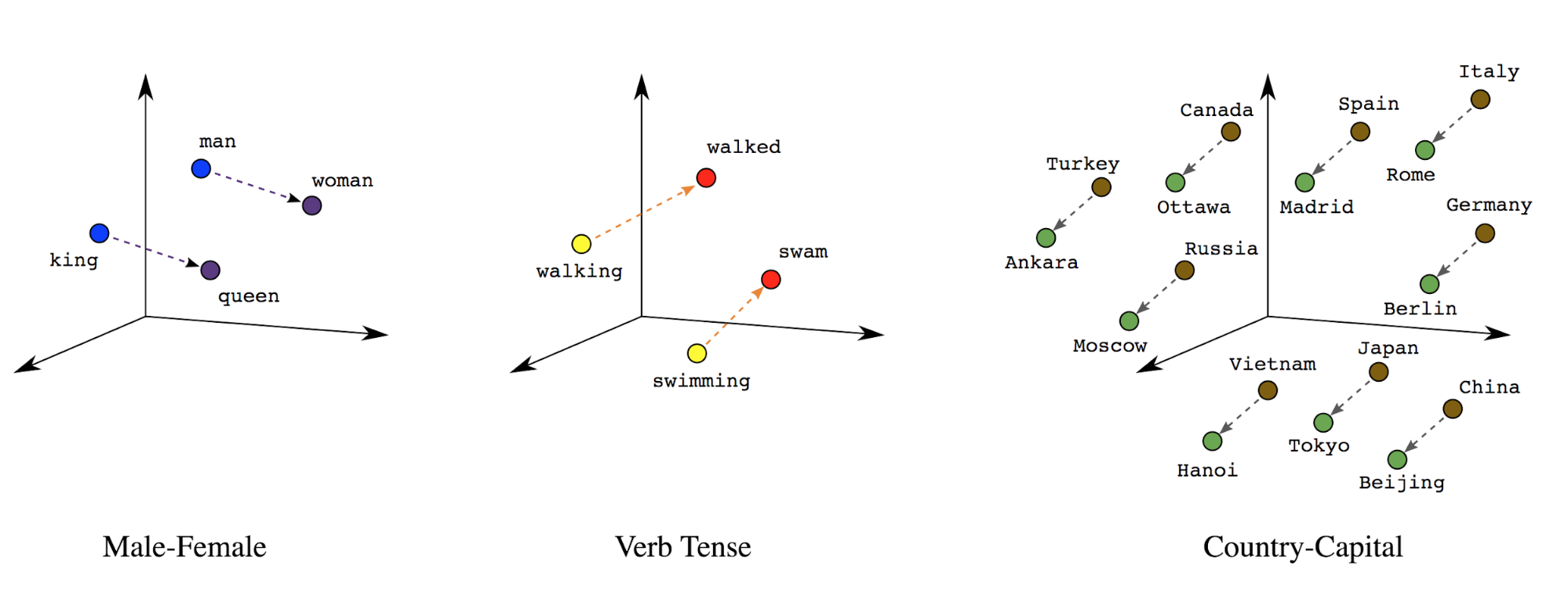
Figure 7: Word embeddings
Sequence models often have such an embedding layer as their first layer. This layer learns to turn word index sequences into word embedding vectors during the training process, such that each word index gets mapped to a dense vector of real values representing that word’s location in semantic space (See Figure 8).
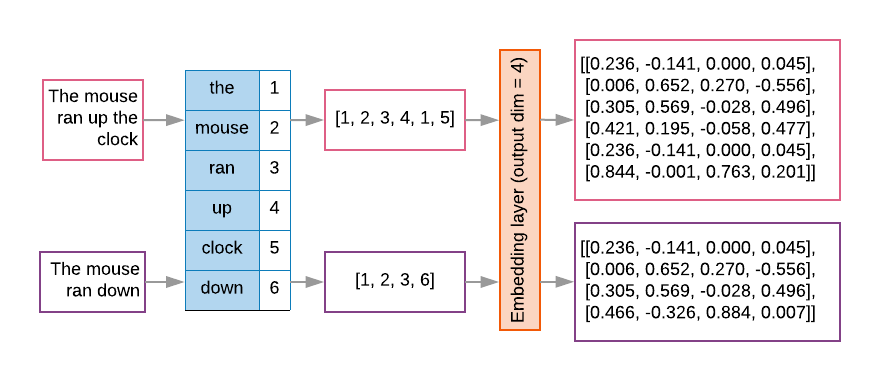
Figure 8: Embedding layer
Feature selection
Not all words in our data contribute to label predictions. We can optimize our learning process by discarding rare or irrelevant words from our vocabulary. In fact, we observe that using the most frequent 20,000 features is generally sufficient. This holds true for n-gram models as well (See Figure 6).
Let’s put all of the above steps in sequence vectorization together. The following code performs these tasks:
- Tokenizes the texts into words
- Creates a vocabulary using the top 20,000 tokens
- Converts the tokens into sequence vectors
- Pads the sequences to a fixed sequence length
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
Label vectorization
We saw how to convert sample text data into numerical vectors. A similar process
must be applied to the labels. We can simply convert labels into values in range
[0, num_classes - 1]. For example, if there are 3 classes we can just use
values 0, 1 and 2 to represent them. Internally, the network will use one-hot
vectors to represent these values (to avoid inferring an incorrect relationship
between labels). This representation depends on the loss function and the last-
layer activation function we use in our neural network. We will learn more about
these in the next section.