در این بخش به ساخت، آموزش و ارزیابی مدل خود خواهیم پرداخت. در مرحله 3 ، ما انتخاب کردیم که از یک مدل n-gram یا مدل توالی با استفاده از نسبت S/W استفاده کنیم. اکنون زمان آن است که الگوریتم طبقه بندی خود را بنویسیم و آن را آموزش دهیم. برای این کار از TensorFlow با tf.keras API استفاده خواهیم کرد.
ساختن مدلهای یادگیری ماشینی با Keras تماماً در مورد مونتاژ لایهها، بلوکهای ساختمانی پردازش داده است، دقیقاً شبیه به مونتاژ آجرهای لگو. این لایهها به ما اجازه میدهند تا دنباله تبدیلهایی را که میخواهیم روی ورودی خود انجام دهیم، مشخص کنیم. از آنجایی که الگوریتم یادگیری ما یک ورودی متن را می گیرد و یک طبقه بندی واحد را خروجی می دهد، می توانیم با استفاده از API مدل متوالی یک پشته خطی از لایه ها ایجاد کنیم.
شکل 9: پشته خطی لایه ها
لایه ورودی و لایه های میانی بسته به اینکه در حال ساخت یک مدل n-gram یا توالی هستیم، متفاوت ساخته می شوند. اما صرف نظر از نوع مدل، آخرین لایه برای یک مشکل مشخص یکسان خواهد بود.
ساخت آخرین لایه
هنگامی که ما فقط 2 کلاس داریم (طبقه بندی باینری)، مدل ما باید یک امتیاز احتمال منفرد را تولید کند. به عنوان مثال، خروجی 0.2 برای یک نمونه ورودی مشخص به این معنی است که "20٪ اطمینان از اینکه این نمونه در کلاس اول (کلاس 1) است، 80٪ اینکه در کلاس دوم است (کلاس 0) است." برای خروجی چنین امتیاز احتمالی، تابع فعالسازی آخرین لایه باید یک تابع سیگموئید باشد و تابع ضرر مورد استفاده برای آموزش مدل باید آنتروپی متقاطع باینری باشد. ( شکل 10 ، سمت چپ را ببینید).
هنگامی که بیش از 2 کلاس وجود دارد (طبقه بندی چند کلاسه)، مدل ما باید یک امتیاز احتمال برای هر کلاس ارائه دهد. مجموع این نمرات باید 1 باشد. برای مثال، خروجی {0: 0.2, 1: 0.7, 2: 0.1} به این معنی است که "20% اطمینان از اینکه این نمونه در کلاس 0 است، 70% که در کلاس 1 و 10 است. ٪ که در کلاس 2 قرار دارد. برای خروجی این امتیازها، تابع فعالسازی لایه آخر باید softmax باشد و تابع تلفات مورد استفاده برای آموزش مدل باید آنتروپی متقاطع طبقهای باشد. ( شکل 10 ، سمت راست را ببینید).
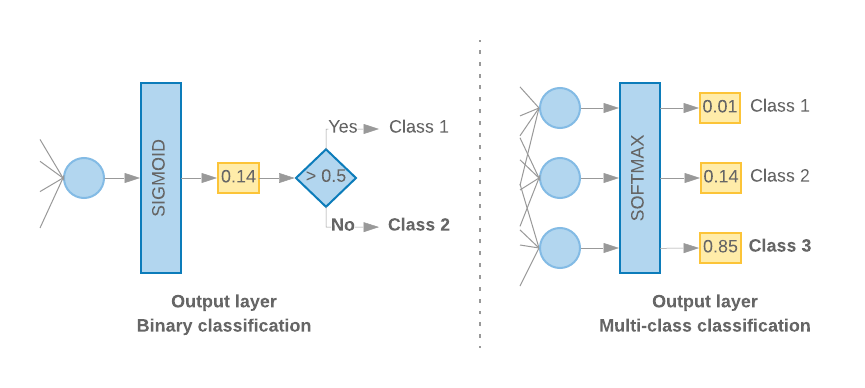
شکل 10: آخرین لایه
کد زیر تابعی را تعریف میکند که تعداد کلاسها را بهعنوان ورودی میگیرد و تعداد مناسب واحدهای لایه (۱ واحد برای طبقهبندی باینری، در غیر این صورت ۱ واحد برای هر کلاس) و تابع فعالسازی مناسب را خروجی میدهد:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
دو بخش زیر به ایجاد لایههای مدل باقیمانده برای مدلهای n-gram و مدلهای دنباله میپردازند.
وقتی نسبت S/W کوچک است، متوجه شدهایم که مدلهای n-gram بهتر از مدلهای دنبالهای عمل میکنند. مدلهای توالی زمانی بهتر هستند که تعداد زیادی بردار کوچک و متراکم وجود داشته باشد. این به این دلیل است که روابط جاسازی در فضای متراکم آموخته می شود و این در بسیاری از نمونه ها بهترین اتفاق می افتد.
ساخت مدل n-gram [گزینه A]
ما به مدل هایی که توکن ها را به طور مستقل پردازش می کنند (بدون در نظر گرفتن ترتیب کلمات) به عنوان مدل های n-gram اشاره می کنیم. پرسپترونهای چند لایه ساده (شامل ماشینهای تقویت گرادیان رگرسیون لجستیک و مدلهای ماشینهای بردار پشتیبانی ) همه در این دسته قرار میگیرند. آنها نمی توانند از هیچ اطلاعاتی در مورد سفارش متن استفاده کنند.
ما عملکرد برخی از مدلهای n-gram ذکر شده در بالا را مقایسه کردیم و مشاهده کردیم که پرسپترونهای چند لایه (MLPs) معمولاً بهتر از سایر گزینهها عمل میکنند . MLP ها برای تعریف و درک ساده هستند، دقت خوبی ارائه می دهند و به محاسبات نسبتا کمی نیاز دارند.
کد زیر یک مدل MLP دو لایه را در tf.keras تعریف میکند و چند لایه Dropout را برای منظمسازی اضافه میکند تا از برازش بیش از حد به نمونههای آموزشی جلوگیری شود.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
مدل دنباله ساخت [گزینه B]
ما به مدل هایی اشاره می کنیم که می توانند از مجاورت نشانه ها به عنوان مدل های توالی یاد بگیرند. این شامل کلاسهای مدلهای CNN و RNN است. داده ها به عنوان بردارهای توالی برای این مدل ها از قبل پردازش می شوند.
مدلهای دنبالهای معمولاً دارای تعداد بیشتری پارامتر برای یادگیری هستند. اولین لایه در این مدل ها یک لایه تعبیه شده است که رابطه بین کلمات را در یک فضای برداری متراکم یاد می گیرد. یادگیری روابط کلمات در بسیاری از نمونه ها بهترین کار را دارد.
کلمات موجود در یک مجموعه داده معین به احتمال زیاد منحصر به آن مجموعه داده نیستند. بنابراین ما میتوانیم رابطه بین کلمات موجود در مجموعه داده خود را با استفاده از سایر دادهها بیاموزیم. برای انجام این کار، میتوانیم تعبیهای را که از مجموعه داده دیگری آموختهایم به لایه جاسازی خود منتقل کنیم. به این تعبیهها، تعبیههای از پیش آموزش دیده میگویند. استفاده از تعبیه از پیش آموزش داده شده به مدل یک شروع عالی در فرآیند یادگیری می دهد.
جاسازیهای از پیش آموزشدیدهشدهای در دسترس هستند که با استفاده از اجسام بزرگ مانند GloVe آموزش داده شدهاند. GloVe در چندین مجموعه (عمدتا ویکی پدیا) آموزش دیده است. ما آموزش مدلهای دنبالهای خود را با استفاده از نسخهای از جاسازیهای GloVe آزمایش کردیم و مشاهده کردیم که اگر وزن جاسازیهای از پیش آموزشدیده را ثابت کنیم و فقط بقیه شبکه را آموزش دهیم، مدلها عملکرد خوبی ندارند. این می تواند به این دلیل باشد که زمینه ای که لایه جاسازی در آن آموزش داده شده است ممکن است با زمینه ای که ما در آن از آن استفاده می کردیم متفاوت باشد.
جاسازیهای GloVe که بر روی دادههای ویکیپدیا آموزش داده شدهاند، ممکن است با الگوهای زبان در مجموعه دادههای IMDb ما هماهنگ نباشند. روابط استنباطشده ممکن است نیاز به بهروزرسانی داشته باشند - به عنوان مثال، وزنهای تعبیهشده ممکن است نیاز به تنظیم متنی داشته باشند. ما این کار را در دو مرحله انجام می دهیم:
در اولین اجرا، با منجمد شدن وزن های لایه جاسازی، به بقیه شبکه اجازه می دهیم یاد بگیرند. در پایان این اجرا، وزنهای مدل به حالتی میرسند که بسیار بهتر از مقادیر اولیه آنها است. برای اجرای دوم، به لایه تعبیهکننده اجازه میدهیم تا یاد بگیرد و تنظیمات خوبی برای تمام وزنهای شبکه انجام دهد. ما به این فرآیند به عنوان استفاده از یک جاسازی دقیق اشاره می کنیم.
تعبیههای دقیقتر دقت بهتری را ارائه میدهند. با این حال، این به قیمت افزایش توان محاسباتی مورد نیاز برای آموزش شبکه است. با توجه به تعداد کافی نمونه، میتوانیم به همان خوبی آموزش تعبیه را از ابتدا انجام دهیم. ما مشاهده کردیم که برای
S/W > 15K، شروع از ابتدا تقریباً همان دقتی را دارد که با استفاده از جاسازی دقیق تنظیم شده است .
ما مدلهای دنبالهای مختلف مانند CNN، sepCNN ، RNN (LSTM و GRU)، CNN-RNN و RNN انباشته را مقایسه کردیم، که معماریهای مدل را تغییر میداد. ما دریافتیم که sepCNN ها، یک نوع شبکه کانولوشنال که اغلب از نظر داده کارآمدتر و از نظر محاسباتی کارآمدتر است، بهتر از مدل های دیگر عمل می کند.
کد زیر یک مدل sepCNN چهار لایه می سازد:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
مدل خود را آموزش دهید
اکنون که معماری مدل را ساخته ایم، باید مدل را آموزش دهیم. آموزش شامل پیش بینی بر اساس وضعیت فعلی مدل، محاسبه میزان نادرست بودن پیش بینی و به روز رسانی وزن ها یا پارامترهای شبکه برای به حداقل رساندن این خطا و پیش بینی بهتر مدل است. ما این روند را تا زمانی تکرار می کنیم که مدل ما همگرا شود و دیگر نتواند یاد بگیرد. سه پارامتر کلیدی برای انتخاب این فرآیند وجود دارد ( جدول 2 را ببینید.)
- متریک : چگونه عملکرد مدل خود را با استفاده از یک متریک اندازه گیری کنیم. ما از دقت به عنوان معیار در آزمایشات خود استفاده کردیم.
- تابع Loss : تابعی است که برای محاسبه مقدار تلفات استفاده میشود که فرآیند آموزش سعی میکند با تنظیم وزنهای شبکه آن را به حداقل برساند. برای مشکلات طبقه بندی، از دست دادن آنتروپی متقابل به خوبی کار می کند.
- بهینه ساز : تابعی که تصمیم می گیرد وزن شبکه بر اساس خروجی تابع از دست دادن چگونه به روز شود. ما از بهینه ساز محبوب Adam در آزمایشات خود استفاده کردیم.
در Keras میتوانیم این پارامترهای یادگیری را با استفاده از روش کامپایل به یک مدل منتقل کنیم.
جدول 2: پارامترهای یادگیری
| پارامتر یادگیری | ارزش |
|---|---|
| متریک | دقت |
| تابع از دست دادن - طبقه بندی باینری | باینری_متقابل |
| تابع ضرر - طبقه بندی چند طبقه | پراکنده_مقوله_متقابل |
| بهینه ساز | آدم |
تمرین واقعی با استفاده از روش تناسب انجام می شود. بسته به اندازه مجموعه داده شما، این روشی است که اکثر چرخه های محاسباتی در آن صرف می شود. در هر تکرار آموزشی، تعداد batch_size از نمونههای دادههای آموزشی شما برای محاسبه ضرر استفاده میشود و وزنها یک بار بر اساس این مقدار بهروزرسانی میشوند. هنگامی که مدل کل مجموعه داده آموزشی را دید، فرآیند آموزش یک epoch را کامل می کند. در پایان هر دوره، از مجموعه داده اعتبارسنجی برای ارزیابی میزان یادگیری مدل استفاده میکنیم. ما آموزش را با استفاده از مجموعه داده برای تعداد دوره های از پیش تعیین شده تکرار می کنیم. ما ممکن است این را با توقف زود هنگام، زمانی که دقت اعتبارسنجی بین دورههای متوالی تثبیت میشود، بهینه کنیم، و نشان میدهد که مدل دیگر در حال آموزش نیست.
| هایپرپارامتر آموزشی | ارزش |
|---|---|
| میزان یادگیری | 1e-3 |
| دوره ها | 1000 |
| اندازه دسته | 512 |
| توقف زودهنگام | پارامتر: val_loss، صبر: 1 |
جدول 3: فراپارامترهای آموزشی
کد Keras زیر فرآیند آموزش را با استفاده از پارامترهای انتخاب شده در جداول 2 و 3 بالا پیاده سازی می کند:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
لطفاً نمونه کدهای آموزش مدل توالی را اینجا بیابید.