目前,我們彙整了資料集,並深入瞭解資料的重要特性。接著,根據我們在步驟 2 中收集到的指標,思考應使用哪個分類模型。也就是提出以下問題:
- 如何將文字資料提供給預期會使用數字的演算法?這稱為資料預先處理和向量化。
- 您應該使用哪一種模型?
- 您應該為模型使用哪些設定參數?
憑藉數十年的研究,我們可以使用各種資料預先處理和模型設定選項。然而,提供多樣化的可用選項,可能會大幅增加特定問題的複雜程度與範圍。由於最佳選項未必顯而易見,因此一個簡單的解決方案就是徹底嘗試所有可能的選項,透過直覺來刪減某些選項。但這樣會非常昂貴
在本指南中,我們會嘗試大幅簡化文字分類模型的選取程序。我們的目標是為特定資料集找到能達到最高準確率的演算法,同時盡量減少訓練所需的運算時間。我們針對不同類型的問題 (特別是情緒分析和主題分類問題) 進行了大量 (約 45 萬) 的實驗,使用 12 個資料集,在不同資料預先處理技術和不同模型架構之間變更每個資料集。這有助於我們找出會影響最佳選擇的資料集參數。
以下的模型選取演算法和流程圖是實驗的摘要。如果您還不瞭解當中所有的詞彙,請不要擔心,本指南的後續章節將詳細說明。
資料準備和建構模型的演算法
- 計算樣本數/每個樣本比率的字詞數。
- 如果這個比率小於 1500,請將文字代碼化為 n-grams,並使用簡單的多層感知 (MLP) 模型進行分類 (下方流程圖中的左側分支版本):
- 將樣本分割為 n-grams,將 n-grams 轉換為向量。
- 為向量評分評分,再根據分數選擇前 2 萬個題目。
- 建構 MLP 模型。
- 如果比率大於 1500,請將文字代碼化為序列,並使用 sepCNN 模型加以分類 (如下流程圖中的右側分支版本):
- 將範例拆成多個字詞,根據頻率選擇前 2 萬個字詞。
- 將範例轉換成字詞序列向量。
- 如果原始樣本數/每個樣本比率的字詞數低於 15, 000 個,使用 sepCNN 模型搭配經過微調的預先訓練嵌入,應該就能提供最準確的結果。
- 使用不同的超參數值評估模型效能,找出資料集的最佳模型設定。
在下方的流程圖中,黃色方塊表示資料和模型準備程序。灰色方塊和綠色方塊表示我們考量的各個程序選項。綠色方塊表示我們為每個程序的建議選項。
您可以使用這張流程圖做為起點,開始建構第一個實驗,因為該圖表有助於您以低廉的運算成本達到理想的準確率。然後,透過後續的疊代作業,您可以繼續改善初始模型。
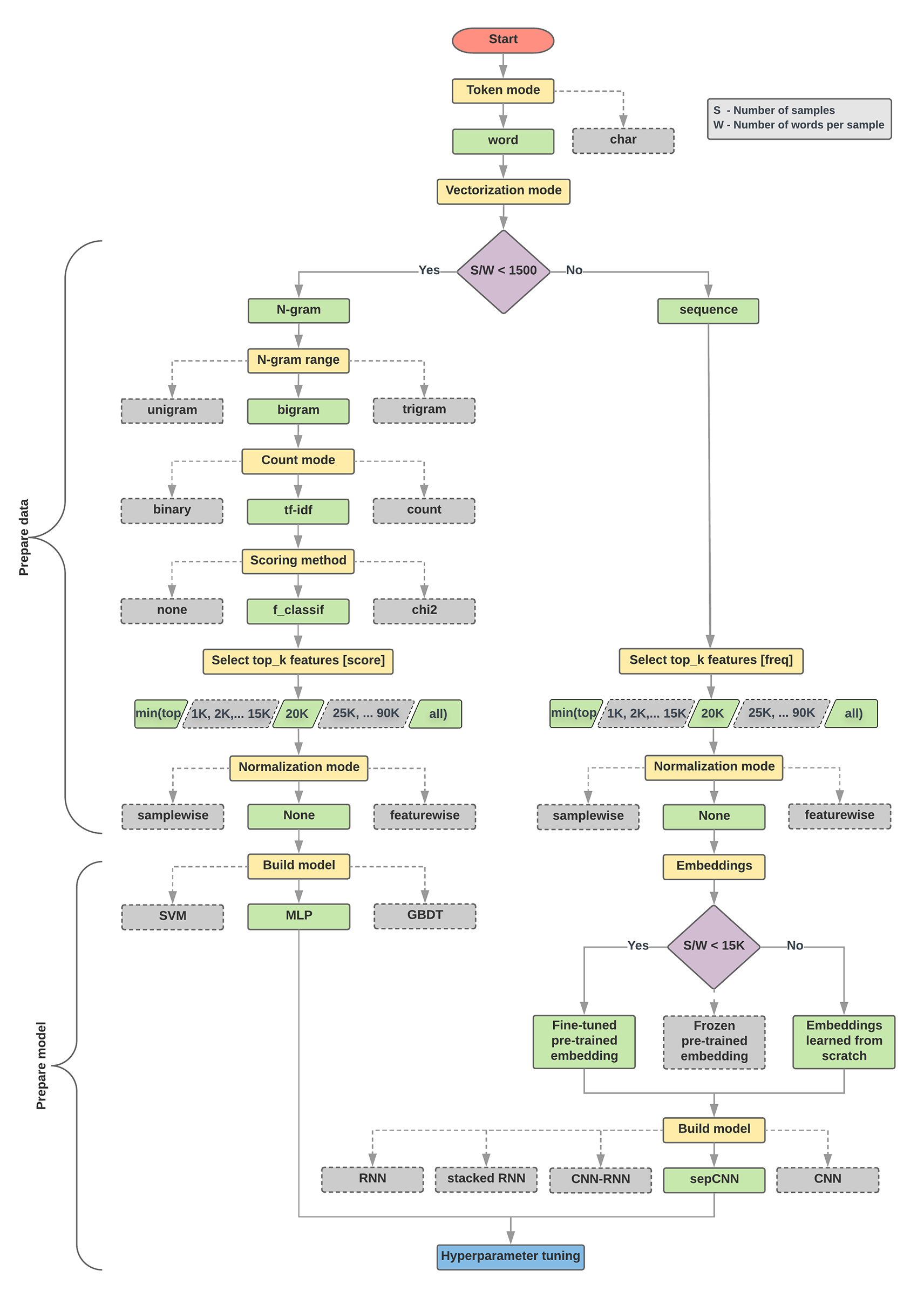
圖 5:文字分類流程圖
此流程圖可解答兩個重要問題:
- 您應該使用哪一種學習演算法或模型?
- 該如何準備資料,才能有效瞭解文字和標籤之間的關係?
第二個問題的答案取決於第一個問題的答案;將資料預先處理至模型的方式取決於我們選擇的模型。模型大致可分為兩類:使用字詞排序資訊 (序列模型) 和僅顯示為文字「包」(n-gram 模型) 的文字 (組合)。序列模型的類型包括卷積類神經網路 (CNN)、循環類神經網路 (RNN) 及其變化版本。n-gram 模型的類型包括:
根據實驗結果,我們觀察到「樣本數」(S) 與「每個樣本的字詞數」(W) 的比率與哪個模型的成效較佳。
當這個比率的值較小 (小於 1500) 時,小型多層感知型感知能力 (將 n-gram 做為輸入內容,稱為選項 A) 的效能較佳或至少會及序列模型。MLP 很容易定義和理解,且比序列模型少了許多運算時間。如果這個比率的值較大 (>= 1500),請使用序列模型 (選項 B)。在後續步驟中,您可以根據樣本/每字的比率,跳到所選模型類型的相關子區段 (已加上 A 或 B 標籤)。
就 IMDb 評論資料集而言,樣本/每個字詞的樣本比率約為 144。換句話說,我們會建立 MLP 模型。