Page Summary
-
Quasi-random search, akin to "jittered, shuffled grid search," offers consistent exploration of hyperparameter search spaces, aiding in insightful analysis and reproducibility.
-
Its non-adaptive nature enables flexible post hoc analysis without rerunning experiments, unlike adaptive methods like Bayesian optimization.
-
While Bayesian optimization excels with sequential trials, quasi-random search shines in high-parallelism scenarios, often outperforming adaptive methods with double its budget.
-
Quasi-random search facilitates easier interpretation of results and identification of potential search space boundary issues.
-
Although the required number of trials varies depending on the problem, studies show significant impact on results, highlighting the importance of adequate budget allocation.
This unit focuses on quasi-random search.
Why use quasi-random search?
Quasi-random search (based on low-discrepancy sequences) is our preference over fancier blackbox optimization tools when used as part of an iterative tuning process intended to maximize insight into the tuning problem (what we refer to as the "exploration phase"). Bayesian optimization and similar tools are more appropriate for the exploitation phase. Quasi-random search based on randomly shifted low-discrepancy sequences can be thought of as "jittered, shuffled grid search", since it uniformly, but randomly, explores a given search space and spreads out the search points more than random search.
The advantages of quasi-random search over more sophisticated blackbox optimization tools (e.g. Bayesian optimization, evolutionary algorithms) include:
- Sampling the search space non-adaptively makes it possible to change the tuning objective in post hoc analysis without rerunning experiments. For example, we usually want to find the best trial in terms of validation error achieved at any point in training. However, the non-adaptive nature of quasi-random search makes it possible to find the best trial based on final validation error, training error, or some alternative evaluation metric without rerunning any experiments.
- Quasi-random search behaves in a consistent and statistically reproducible way. It should be possible to reproduce a study from six months ago even if the implementation of the search algorithm changes, as long as it maintains the same uniformity properties. If using sophisticated Bayesian optimization software, the implementation might change in an important way between versions, making it much harder to reproduce an old search. It isn't always possible to roll back to an old implementation (e.g. if the optimization tool is run as a service).
- Its uniform exploration of the search space makes it easier to reason about the results and what they might suggest about the search space. For example, if the best point in the traversal of quasi-random search is at the boundary of the search space, this is a good (but not foolproof) signal that the search space bounds should be changed. However, an adaptive blackbox optimization algorithm might have neglected the middle of the search space because of some unlucky early trials even if it happens to contain equally good points, since it is this exact sort of non-uniformity that a good optimization algorithm needs to employ to speed up the search.
- Running different numbers of trials in parallel versus sequentially does not produce statistically different results when using quasi-random search (or other non-adaptive search algorithms), unlike with adaptive algorithms.
- More sophisticated search algorithms may not always handle infeasible points correctly, especially if they aren't designed with neural network hyperparameter tuning in mind.
- Quasi-random search is simple and works especially well when many tuning trials are running in parallel. Anecdotally1, it is very hard for an adaptive algorithm to beat a quasi-random search that has 2X its budget, especially when many trials need to be run in parallel (and thus there are very few chances to make use of previous trial results when launching new trials). Without expertise in Bayesian optimization and other advanced blackbox optimization methods, you might not achieve the benefits they are, in principle, capable of providing. It is hard to benchmark advanced blackbox optimization algorithms in realistic deep learning tuning conditions. They are a very active area of current research, and the more sophisticated algorithms come with their own pitfalls for inexperienced users. Experts in these methods are able to get good results, but in high-parallelism conditions the search space and budget tend to matter a lot more.
That said, if your computational resources only allow a small number of trials to run in parallel and you can afford to run many trials in sequence, Bayesian optimization becomes much more attractive despite making your tuning results harder to interpret.
Where can I find an implementation of quasi-random search?
Open-Source Vizier has
an implementation of quasi-random
search.
Set algorithm="QUASI_RANDOM_SEARCH" in this Vizier usage
example.
An alternative implementation exists in this hyperparameter sweeps
example.
Both of these implementations generate a Halton sequence for a given search
space (intended to implement a shifted, scrambled Halton sequence as
recommended in
Critical Hyper-Parameters: No Random, No
Cry.
If a quasi-random search algorithm based on a low-discrepancy sequence is not available, it is possible to substitute pseudo random uniform search instead, although this is likely to be slightly less efficient. In 1-2 dimensions, grid search is also acceptable, although not in higher dimensions. (See Bergstra & Bengio, 2012).
How many trials are needed to get good results with quasi-random search?
There is no way to determine how many trials are needed to get results with quasi-random search in general, but you can look at specific examples. As Figure 3 shows, the number of trials in a study can have a substantial impact on the results:
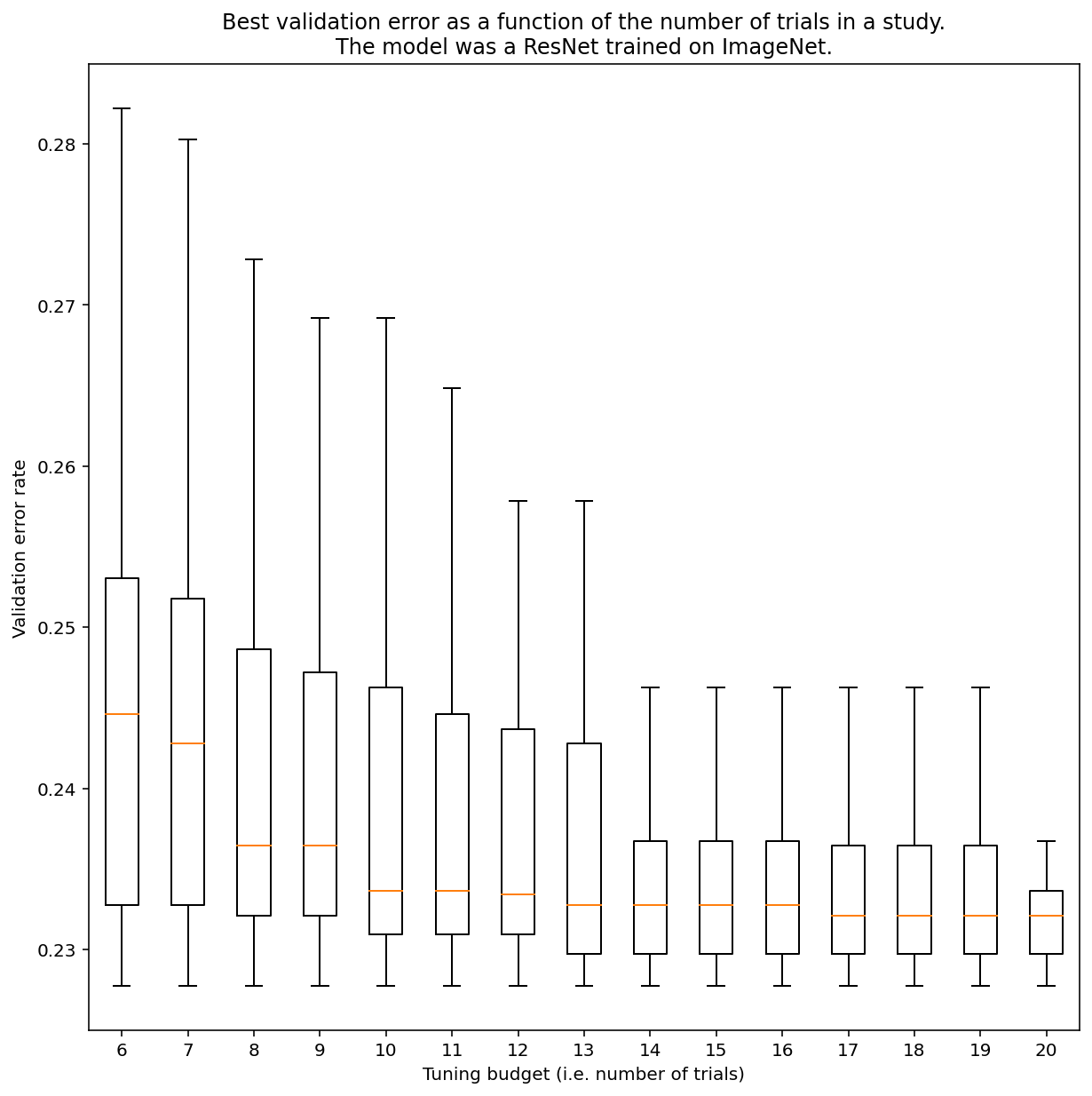
Figure 3: ResNet-50 tuned on ImageNet with 100 trials. Using bootstrapping, different amounts of tuning budget were simulated. Box plots of the best performances for each trial budget are plotted.
Notice the following about Figure 3:
- The interquartile ranges when 6 trials were sampled are much larger than when 20 trials were sampled.
- Even with 20 trials, the difference between especially lucky and unlucky studies are likely larger than the typical variation between retrains of this model on different random seeds, with fixed hyperparameters, which for this workload might be around +/- 0.1% on a validation error rate of ~23%.
-
Ben Recht and Kevin Jamieson pointed out how strong 2X-budget random search is as a baseline (the Hyperband paper makes similar arguments), but it is certainly possible to find search spaces and problems where state-of-the-art Bayesian optimization techniques crush random search that has 2X the budget. However, in our experience beating 2X-budget random search gets much harder in the high-parallelism regime since Bayesian optimization has no opportunity to observe the results of previous trials. ↩