 Google uses AI technology to translate content into your preferred language. AI translations can contain errors.
Google uses AI technology to translate content into your preferred language. AI translations can contain errors.
公平性:评估偏差
使用集合让一切井井有条
根据您的偏好保存内容并对其进行分类。
评估模型时,根据整个测试或验证数据计算的指标
并不能准确反映模型的公平性。
在大多数样本中,模型整体性能优异可能会掩盖糟糕的模型
这可能导致出现偏差
模型预测。使用汇总效果指标,例如
精确率、
召回率、
和准确率不一定持续
来揭示这些问题
我们可以回顾一下我们的招生模式,并探索一些新方法
如何在兼顾公平性的前提下评估预测是否存在偏差。
假设招生分类模型选择 20 名学生进入
从 100 名学生中挑选出一所大学,分为两个人口统计群体:
多数群体(蓝色,80 位学生)和少数群体
(橙色,20 位学生)。
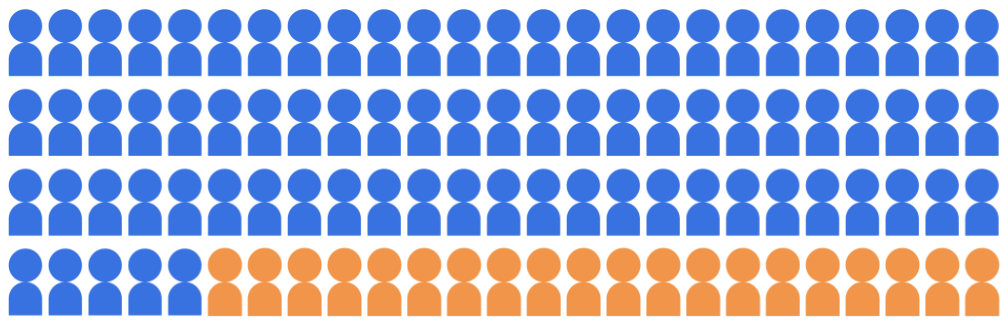 图 1. 拥有 100 名学生的候选人库:共 80 名学生
多数群体(蓝色),20 名学生属于少数群体
(橙色)。
图 1. 拥有 100 名学生的候选人库:共 80 名学生
多数群体(蓝色),20 名学生属于少数群体
(橙色)。
该模型在接纳符合要求的学生时,必须以对
两个受众特征群体中的候选人。
我们应如何评估模型预测的公平性?有很多种
每个指标都提供了不同的数学概念
“公平性”的定义在后续部分中,我们将探讨
这些深入的公平性指标:人口统计一致性、机会平等,
和反事实公平性原则。
如未另行说明,那么本页面中的内容已根据知识共享署名 4.0 许可获得了许可,并且代码示例已根据 Apache 2.0 许可获得了许可。有关详情,请参阅 Google 开发者网站政策。Java 是 Oracle 和/或其关联公司的注册商标。
最后更新时间 (UTC):2024-08-13。
[[["易于理解","easyToUnderstand","thumb-up"],["解决了我的问题","solvedMyProblem","thumb-up"],["其他","otherUp","thumb-up"]],[["没有我需要的信息","missingTheInformationINeed","thumb-down"],["太复杂/步骤太多","tooComplicatedTooManySteps","thumb-down"],["内容需要更新","outOfDate","thumb-down"],["翻译问题","translationIssue","thumb-down"],["示例/代码问题","samplesCodeIssue","thumb-down"],["其他","otherDown","thumb-down"]],["最后更新时间 (UTC):2024-08-13。"],[],[]]