Page Summary
-
Clustering is an unsupervised machine learning technique used to group similar unlabeled data points into clusters based on defined similarity measures.
-
Cluster analysis can be applied to various domains like market segmentation, social network analysis, and medical imaging to identify patterns and simplify complex datasets.
-
Clustering enables data compression by replacing numerous features with a single cluster ID, reducing storage and processing needs.
-
It facilitates data imputation by inferring missing feature data from other examples within the same cluster.
-
Clustering offers a degree of privacy preservation by associating user data with cluster IDs instead of individual identifiers.
Suppose you are working with a dataset that includes patient information from a healthcare system. The dataset is complex and includes both categorical and numeric features. You want to find patterns and similarities in the dataset. How might you approach this task?
Clustering is an unsupervised machine learning technique designed to group unlabeled examples based on their similarity to each other. (If the examples are labeled, this kind of grouping is called classification.) Consider a hypothetical patient study designed to evaluate a new treatment protocol. During the study, patients report how many times per week they experience symptoms and the severity of the symptoms. Researchers can use clustering analysis to group patients with similar treatment responses into clusters. Figure 1 demonstrates one possible grouping of simulated data into three clusters.
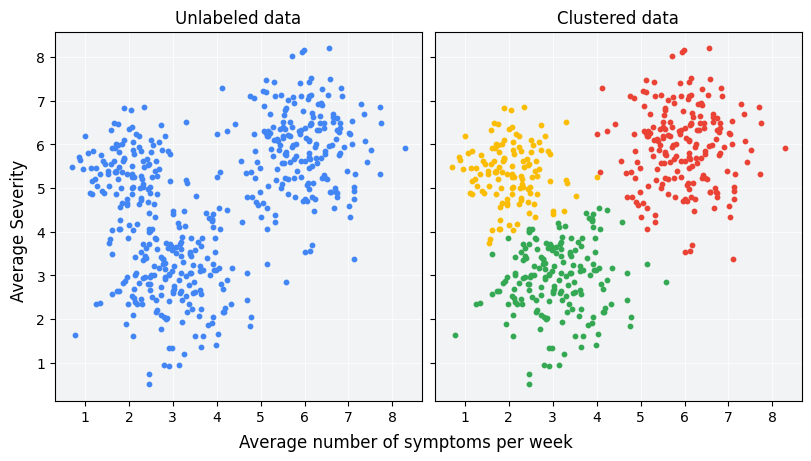
Looking at the unlabeled data on the left of Figure 1, you could guess that the data forms three clusters, even without a formal definition of similarity between data points. In real-world applications, however, you need to explicitly define a similarity measure, or the metric used to compare samples, in terms of the dataset's features. When examples have only a couple of features, visualizing and measuring similarity is straightforward. But as the number of features increases, combining and comparing features becomes less intuitive and more complex. Different similarity measures may be more or less appropriate for different clustering scenarios, and this course will address choosing an appropriate similarity measure in later sections: Manual similarity measures and Similarity measure from embeddings.
After clustering, each group is assigned a unique label called a cluster ID. Clustering is powerful because it can simplify large, complex datasets with many features to a single cluster ID.
Clustering use cases
Clustering is useful in a variety of industries. Some common applications for clustering:
- Market segmentation
- Social network analysis
- Search result grouping
- Medical imaging
- Image segmentation
- Anomaly detection
Some specific examples of clustering:
- The Hertzsprung-Russell diagram shows clusters of stars when plotted by luminosity and temperature.
- Gene sequencing that shows previously unknown genetic similarities and dissimilarities between species has led to the revision of taxonomies previously based on appearances.
- The Big 5 model of personality traits was developed by clustering words that describe personality into 5 groups. The HEXACO model uses 6 clusters instead of 5.
Imputation
When some examples in a cluster have missing feature data, you can infer the missing data from other examples in the cluster. This is called imputation. For example, less popular videos can be clustered with more popular videos to improve video recommendations.
Data compression
As discussed, the relevant cluster ID can replace other features for all examples in that cluster. This substitution reduces the number of features and therefore also reduces the resources needed to store, process, and train models on that data. For very large datasets, these savings become significant.
To give an example, a single YouTube video can have feature data including:
- viewer location, time, and demographics
- comment timestamps, text, and user IDs
- video tags
Clustering YouTube videos replaces this set of features with a single cluster ID, thus compressing the data.
Privacy preservation
You can preserve privacy somewhat by clustering users and associating user data with cluster IDs instead of user IDs. To give one possible example, say you want to train a model on YouTube users' watch history. Instead of passing user IDs to the model, you could cluster users and pass only the cluster ID. This keeps individual watch histories from being attached to individual users. Note that the cluster must contain a sufficiently large number of users in order to preserve privacy.