
Funkcje internetowe
Chcemy wypełnić lukę w możliwości między internetem a rozwiązaniami natywnymi oraz ułatwić deweloperom tworzenie świetnych rozwiązań w otwartym internecie. Jesteśmy przekonani, że każdy deweloper powinien mieć dostęp do funkcji, które pozwalają im korzystać z komfortowego korzystania z internetu. Czujemy się zobowiązani do tworzenia bardziej zaawansowanych stron internetowych.
Istnieją jednak pewne możliwości, takie jak dostęp do systemu plików i wykrywanie bezczynności, które są dostępne w języku natywnym, ale nie są dostępne w internecie. Brak tych funkcji oznacza, że niektórych typów aplikacji nie będzie można udostępniać w sieci lub są one mniej przydatne.
Nowe funkcje będziemy projektować i rozwijać w sposób przejrzysty i przejrzysty, wykorzystując dotychczasowe standardy otwartych platform internetowych, a jednocześnie zdobywając od programistów i innych dostawców przeglądarek informacje zwrotne, co pozwoli nam zadbać o to, aby projekt działał poprawnie.
Co stworzysz
W tym ćwiczeniu z programowania poznasz różne internetowe interfejsy API, które są nowe lub dostępne tylko pod określoną flagą. Ćwiczenia z programowania skupiają się więc na samych interfejsach API oraz przypadkach użycia, które są odblokowywane przez te interfejsy, a nie na tworzeniu konkretnego produktu końcowego.
Czego się nauczysz:
W tym ćwiczeniu poznasz podstawowe informacje o kilku nowatorskich interfejsach API: Ta technika nie jest jeszcze gotowa. Bardzo dziękujemy za Twoją opinię na temat procesu programowania.
Czego potrzebujesz
Ponieważ interfejsy API używane w tym ćwiczeniu są na czasie, wymagania dotyczące każdego z nich są różne. Na początku każdej sekcji dokładnie przeczytaj informacje o zgodności.
Jak podejść do ćwiczeń z programowania
Ćwiczenia z programowania nie muszą koniecznie być wykonywane po kolei. Każda sekcja reprezentuje niezależny interfejs API, więc możesz samodzielnie wybrać to, co Cię najbardziej interesuje.
Celem interfejsu Badging API jest zwrócenie uwagi użytkowników na to, co dzieje się w tle. Aby uprościć konfigurację, przejdźmy do ćwiczeń z zakresu programowania. Użyjmy interfejsu API, aby zwrócić uwagę użytkowników na to, co dzieje się na pierwszym planie. Potem możesz przenieść zapachy do tego, co dzieje się w tle.
Zainstaluj Airhorner
Aby ten interfejs API działał, potrzebujesz aplikacji PWA zainstalowanej na ekranie głównym. Najpierw musisz zainstalować ją, np. niesławną, airhorner.com. Naciśnij przycisk Install w menu u góry 3 lub w prawym górnym rogu 3 kropek.
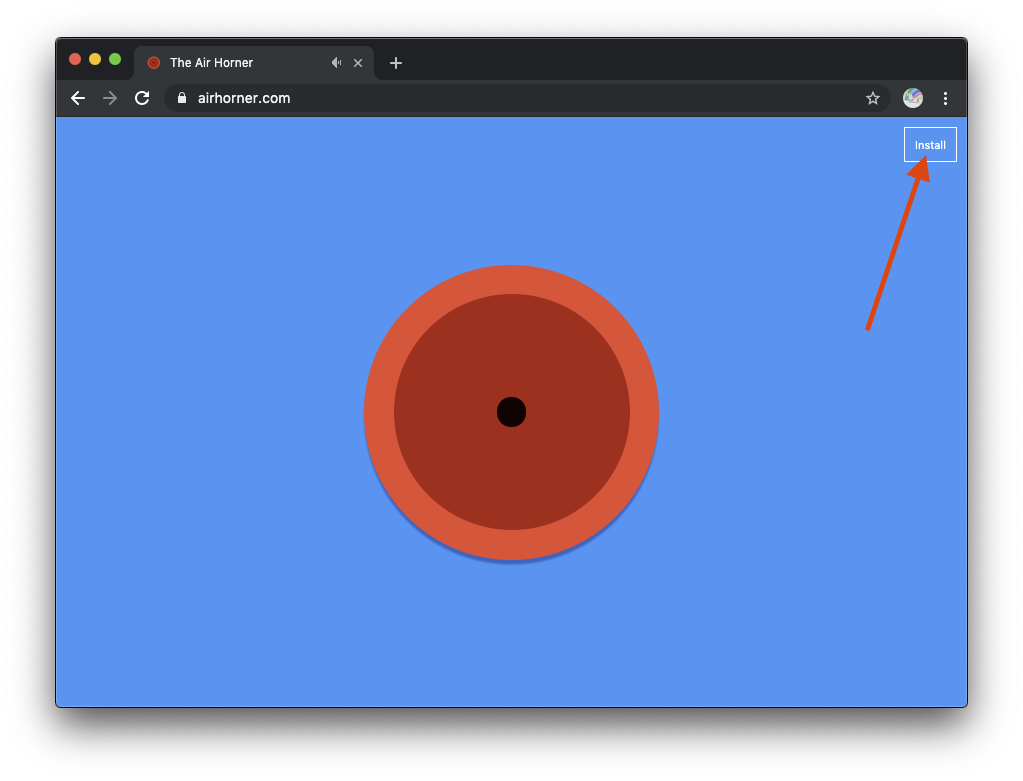
Pojawi się potwierdzenie i kliknij Zainstaluj.
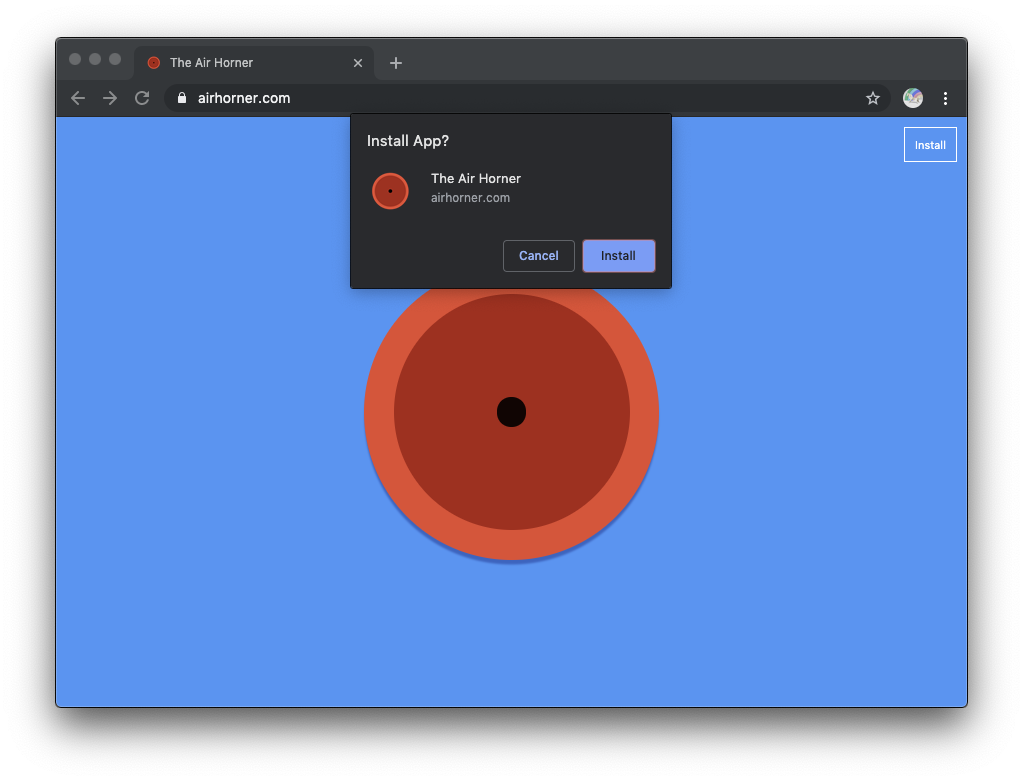
W systemie operacyjnym masz teraz nową ikonę. Kliknij go, aby uruchomić PWA. Będzie mieć własne okno aplikacji i działać w trybie samodzielnym.
|
|
Ustawianie plakietki
Po zainstalowaniu aplikacji PWA musisz mieć dane, które będą ją wyświetlać (logo może zawierać tylko cyfry). Najprostszą rzeczą, którą można zaliczyć w „The Air Horner”, jest westchnięcie, czyli ile razy zaatakowano. Spróbuj użyć klaksonu z zainstalowaną aplikacją Airhorner i sprawdź logo. Liczy się, gdy zagrasz.
Jak to działa? Zasadniczo kod jest następujący:
let hornCounter = 0;
const horn = document.querySelector('.horn');
horn.addEventListener('click', () => {
navigator.setExperimentalAppBadge(++hornCounter);
});Włącz dźwięk kilka razy i sprawdź ikonę PWA To takie proste.

Czyszczenie plakietki
Licznik rośnie do 99, a potem zaczyna się od nowa. Możesz też zresetować go ręcznie. Otwórz kartę konsoli DevTools, wklej poniższy wiersz i naciśnij Enter.
navigator.setExperimentalAppBadge(0);Logo możesz też pozbyć się, usuwając je tak, jak widać w poniższym przykładzie. Ikona PWA& powinna wyglądać jeszcze raz jak na początku, bez zakłóceń i plakietki.
navigator.clearExperimentalAppBadge();
Prześlij opinię
Jak oceniasz ten interfejs API? Odpowiedz na pytania w krótkiej ankiecie:
Czy interfejs API był intuicyjny w użyciu?
Czy udało się uruchomić przykład?
Chcesz się podzielić czymś jeszcze? Czy brakuje jakichś funkcji? Podziel się z nami swoją opinią, wypełniając tę ankietę. Dziękuję!
Interfejs Native File System API pozwala deweloperom tworzyć zaawansowane aplikacje internetowe, które współpracują z plikami na urządzeniu lokalnym użytkownika. Gdy użytkownik przyzna dostęp aplikacji internetowej, ten interfejs API umożliwia aplikacjom internetowym odczytywanie lub zapisywanie zmian bezpośrednio w plikach i folderach na urządzeniu użytkownika.
Odczytywanie pliku
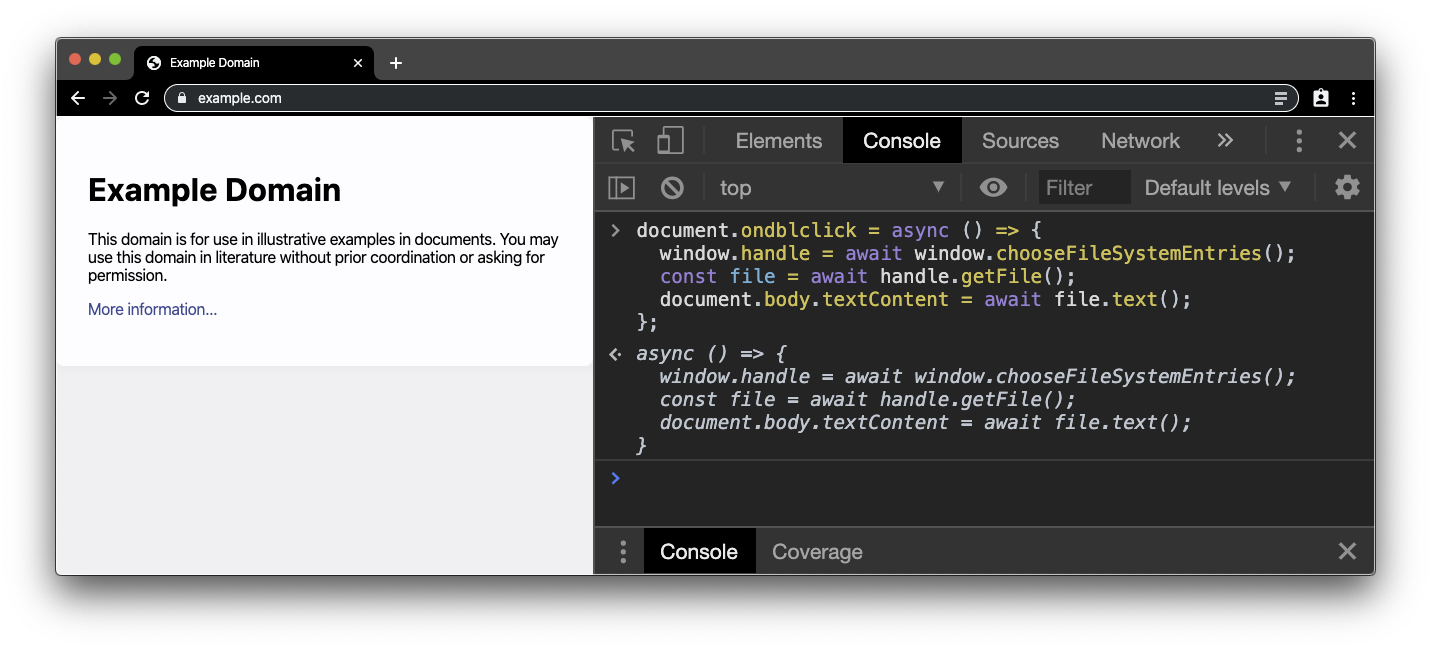
Na przykład interfejs API Native File System API służy do odczytywania pliku lokalnego i pobierania zawartości pliku. Utwórz zwykły plik .txt i wpisz tekst. Następnie przejdź do dowolnej bezpiecznej witryny (tj. takiej, która jest obsługiwana przez HTTPS), np. example.com, i otwórz konsolę Narzędzi dla programistów. Wklej poniższy fragment kodu w konsoli. Interfejs Native File System API wymaga gestu użytkownika, dlatego w dokumencie dołączamy element dwukrotnego kliknięcia. Będzie on potrzebny później, więc będzie to zmienna globalna.
document.ondblclick = async () => {
window.handle = await window.chooseFileSystemEntries();
const file = await handle.getFile();
document.body.textContent = await file.text();
};
Gdy klikniesz dwukrotnie w dowolnym miejscu na stronie example.com, pojawi się selektor plików.
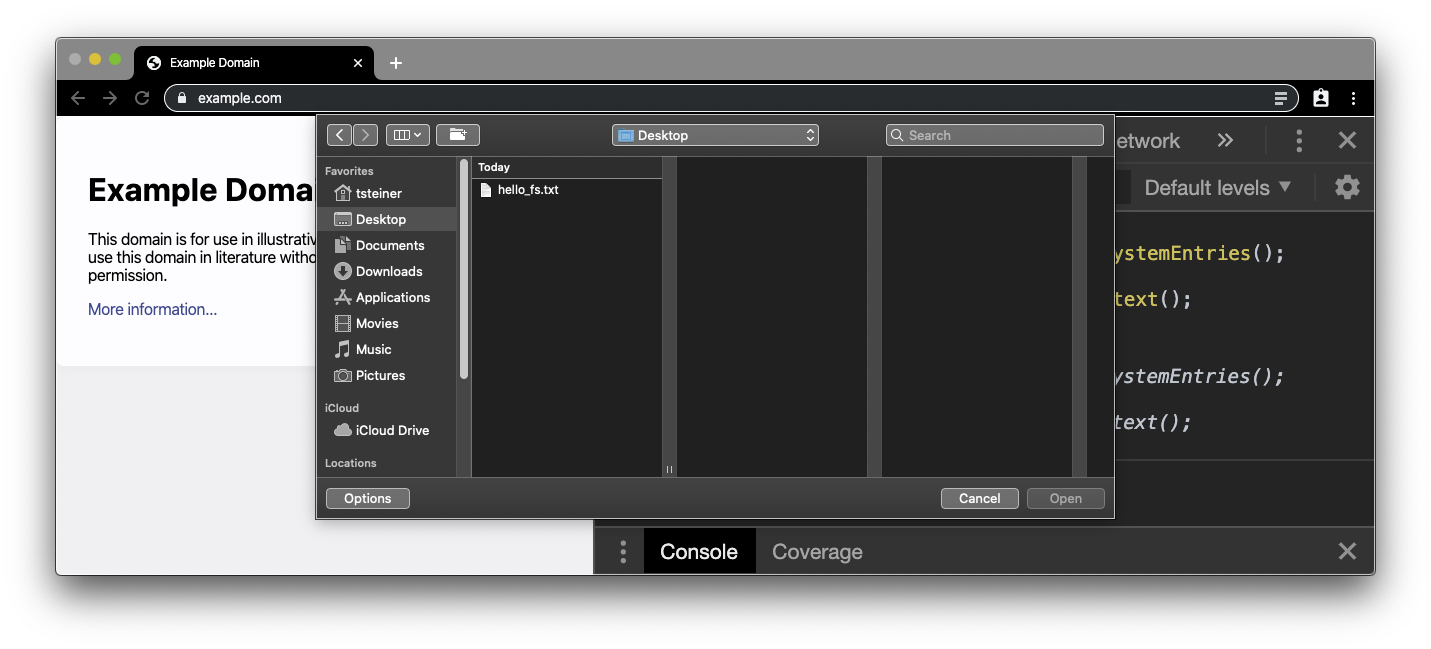
Wybierz wcześniej utworzony plik .txt. Zawartość pliku zastąpi body rzeczywistą zawartość example.com.
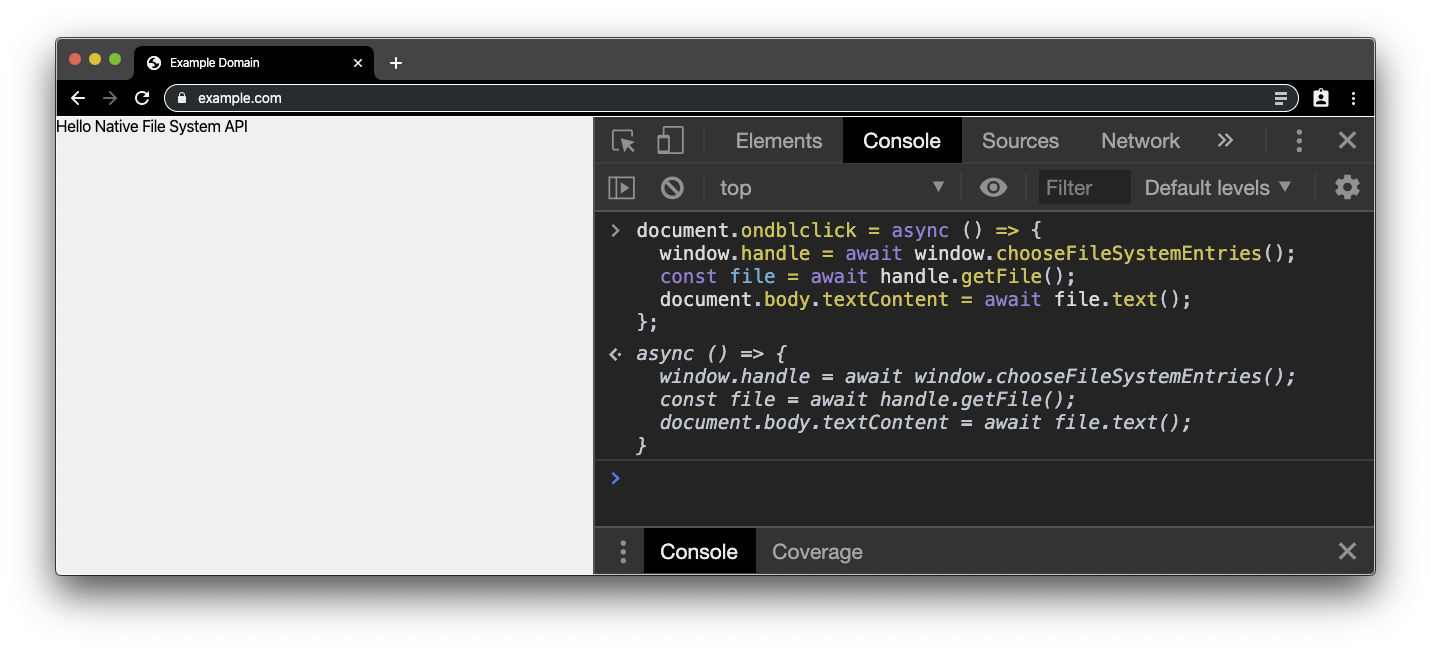
Zapisywanie pliku
Teraz chcemy wprowadzić kilka zmian. Dlatego umożliwiamy edytowanie obiektu body przez wklejenie go we fragmencie kodu. Teraz możesz edytować tekst tak, jakby przeglądarka była edytorem tekstu.
document.body.contentEditable = true;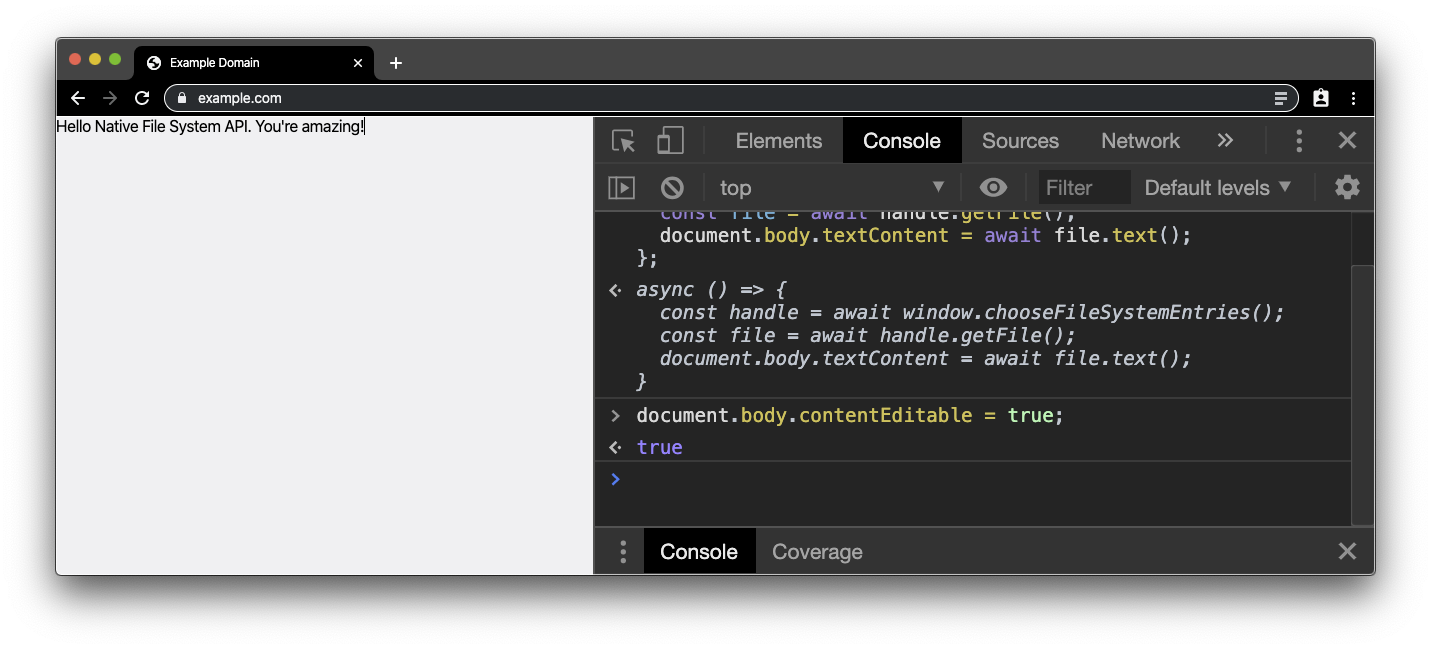
Teraz chcemy zapisać te zmiany z powrotem w pierwotnym pliku. Z tego powodu potrzebujemy zapisu na rolce pliku. Aby go uzyskać, wklej poniższy fragment w konsoli. Potrzebujemy gestu użytkownika, więc tym razem zaczekamy na kliknięcie głównego dokumentu.
document.onclick = async () => {
const writer = await handle.createWriter();
await writer.truncate(0);
await writer.write(0, document.body.textContent);
await writer.close();
};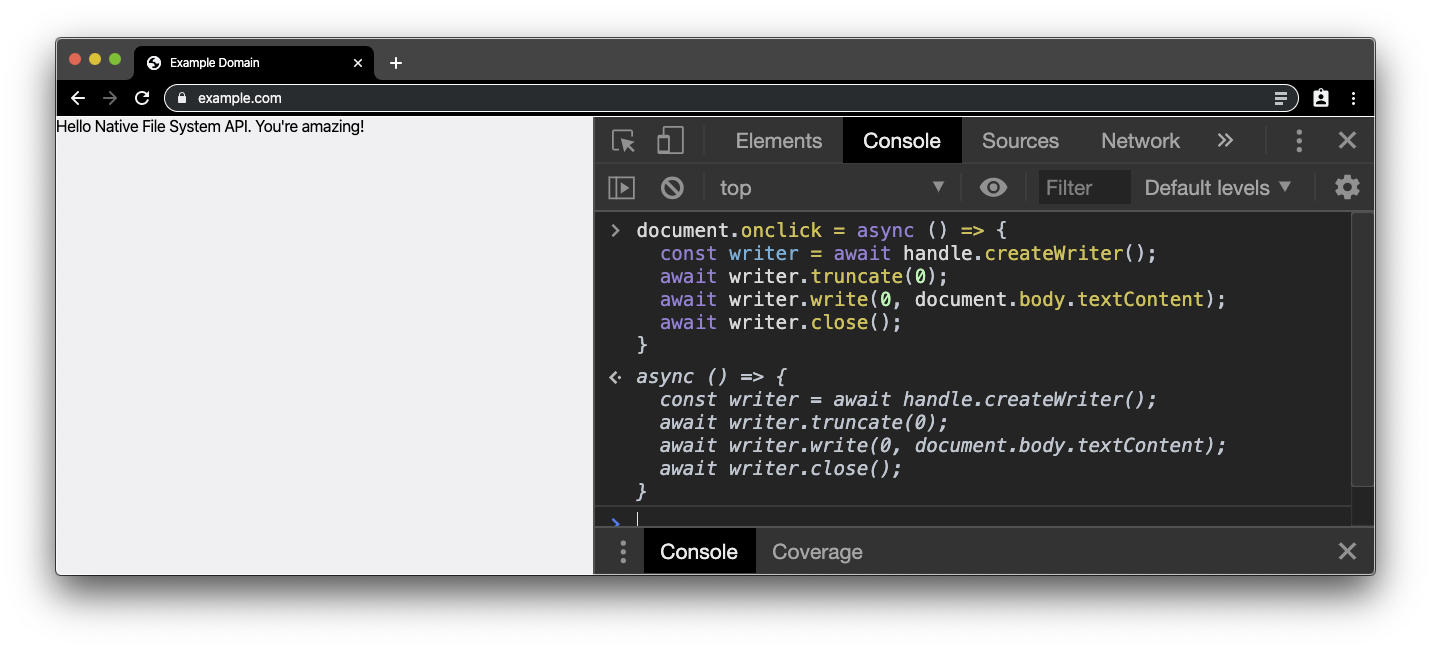
Gdy klikniesz teraz (nie dwukrotnie) dokument, pojawi się prośba o pozwolenie. Gdy przyznasz uprawnienia, zawartość pliku będzie taka sama jak treść, która była już edytowana w aplikacji body. Sprawdź zmiany, otwierając plik w innym edytorze (lub rozpocznij proces od nowa, klikając dwukrotnie dokument i ponownie otwierając plik).
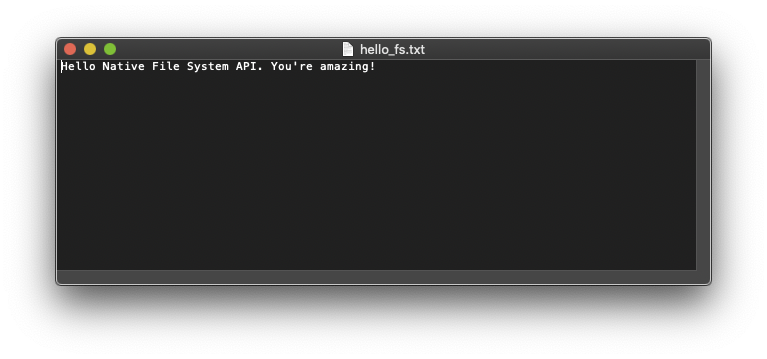
Gratulacje! Właśnie udało Ci się utworzyć najmniejszy edytor tekstu na świecie [citation needed].
Prześlij opinię
Jak oceniasz ten interfejs API? Odpowiedz na pytania w krótkiej ankiecie:
Czy interfejs API był intuicyjny w użyciu?
Czy udało się uruchomić przykład?
Chcesz się podzielić czymś jeszcze? Czy brakuje jakichś funkcji? Podziel się z nami swoją opinią, wypełniając tę ankietę. Dziękuję!
Interfejs Shape Detection API zapewnia dostęp do przyspieszonych wzorców do wykrywania kształtów (np. w przypadku twarzy) i działa w przypadku nieruchomych obrazów i/lub aktywnych obrazów. Systemy operacyjne zawierają wydajne i bardzo zoptymalizowane wzorce do wykrywania treści, takie jak Facedetector Androida. Interfejs Shape Detection API otwiera te implementacje natywne i udostępnia je za pomocą zestawu interfejsów JavaScript.
Obecnie obsługiwane funkcje to wykrywanie twarzy przez interfejs FaceDetector, wykrywanie kodu kreskowego w interfejsie BarcodeDetector oraz wykrywanie tekstu (optyczne rozpoznawanie znaków) w interfejsie TextDetector.
Wykrywanie twarzy
Ciekawą funkcją interfejsu Shape Detection API jest wykrywanie twarzy. Aby to sprawdzić, potrzebujemy strony z twarzami. Ta strona z twarzą autora jest dobrym punktem wyjścia. Będzie to wyglądać mniej więcej tak, jak na poniższym zrzucie ekranu. W obsługiwanej przeglądarce pole granicy twarzy oraz punkty orientacyjne są rozpoznawane.
Aby sprawdzić, ile miejsca wymaga ten kod, zremiksuj lub edytuj projekt Glitch, w szczególności plik script.js.
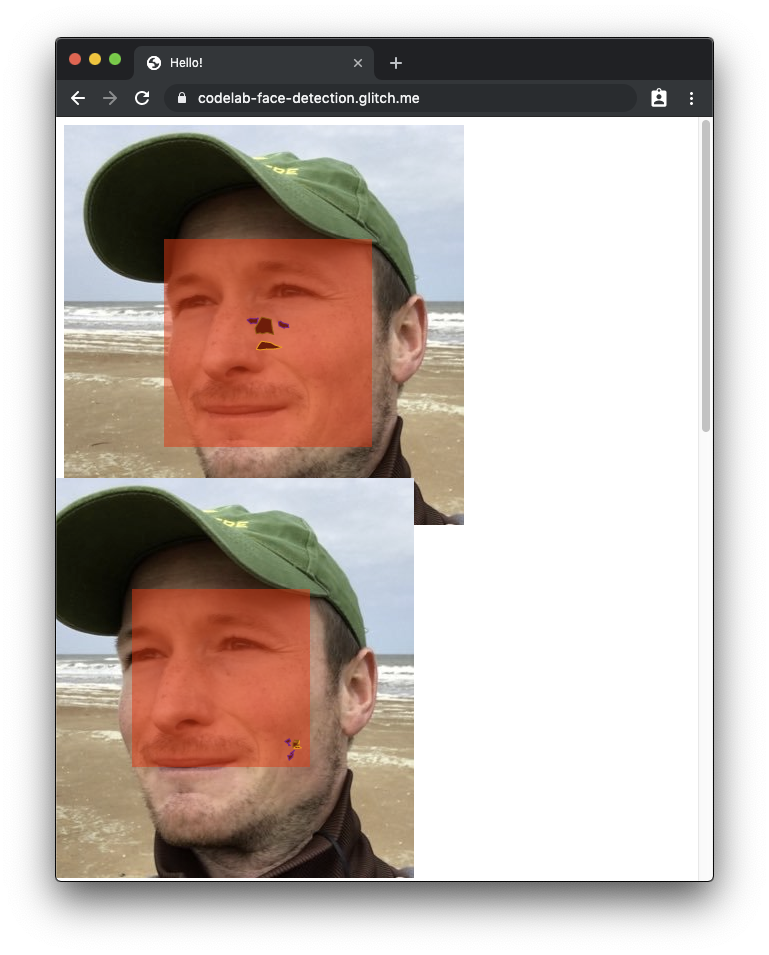
Jeśli chcesz zachować pełną dynamikę i nie tylko pracować z twarzą autora, otwórz tę stronę wyników wyszukiwania Google pełną twarzami na karcie prywatnej lub w trybie gościa. Na tej stronie otwórz Narzędzia dla deweloperów Chrome, klikając prawym przyciskiem myszy w dowolnym miejscu, a następnie kliknij Zbadaj. Następnie na karcie Konsola wklej poniższy fragment kodu. Kod będzie wyróżniać wykryte twarze z półprzezroczystym czerwonym polem.
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const faces = await new FaceDetector().detect(img);
faces.forEach(face => {
const div = document.createElement('div');
const box = face.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 0, 0, 0.5)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left + left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
img.before(div);
});
} catch(e) {
console.error(e);
}
});Zauważysz, że są pewne wiadomości w DOMException i nie wszystkie obrazy są przetwarzane. Dzieje się tak, ponieważ obrazy w części strony widocznej na ekranie są wbudowane w identyfikatory URI danych i dlatego mają do nich dostęp, podczas gdy obrazy w części strony widocznej po przewinięciu pochodzą z innej domeny i nie są skonfigurowane do obsługi CORS. Dla celów demonstracyjnych nie musimy się tym przejmować.
Wykrywanie punktów orientacyjnych na podstawie twarzy
Oprócz samej twarzy system macOS obsługuje też wykrywanie punktów orientacyjnych twarzy. Aby przetestować wykrywanie punktów orientacyjnych na twarzy, wklej do konsoli poniższy fragment kodu. Uwaga: lista punktów orientacyjnych nie jest idealna ze względu na crbug.com/914348, ale możesz sprawdzić, na czym polega ta funkcja i jakie są funkcje tej usługi.
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const faces = await new FaceDetector().detect(img);
faces.forEach(face => {
const div = document.createElement('div');
const box = face.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 0, 0, 0.5)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left + left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
img.before(div);
const landmarkSVG = document.createElementNS('http://www.w3.org/2000/svg', 'svg');
landmarkSVG.style.position = 'absolute';
landmarkSVG.classList.add('landmarks');
landmarkSVG.setAttribute('viewBox', `0 0 ${img.width} ${img.height}`);
landmarkSVG.style.width = `${img.width}px`;
landmarkSVG.style.height = `${img.height}px`;
face.landmarks.map((landmark) => {
landmarkSVG.innerHTML += `<polygon class="landmark-${landmark.type}" points="${
landmark.locations.map((point) => {
return `${scaleX * point.x},${scaleY * point.y} `;
}).join(' ')
}" /></svg>`;
});
div.before(landmarkSVG);
});
} catch(e) {
console.error(e);
}
});Wykrywanie kodów kreskowych
Drugą funkcją interfejsu Shape Detection API jest wykrywanie kodu kreskowego. Podobnie jak wcześniej potrzebujemy strony z kodami kreskowymi, np. tej. Gdy otworzysz go w przeglądarce, rozszyfrujesz różne kody QR. Zremiksuj lub zmodyfikuj projekt Glitch, w szczególności plik script.js, aby zobaczyć, jak to się robi.

Jeśli szukasz czegoś bardziej dynamicznego, możemy ponownie skorzystać z wyszukiwarki grafiki Google. Tym razem przejdź w przeglądarce do strony wyników wyszukiwania Google w trybie prywatnym lub gościa. Następnie wklej poniższy fragment kodu na karcie konsoli Chrome DevTools. Po chwili w rozpoznawanych kodach kreskowych znajdzie się informacja o wartości nieprzetworzonej i typu kodu kreskowego.
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const barcodes = await new BarcodeDetector().detect(img);
barcodes.forEach(barcode => {
const div = document.createElement('div');
const box = barcode.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 255, 255, 0.75)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left - left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
div.style.color = 'black';
div.style.fontSize = '14px';
div.textContent = `${barcode.rawValue}`;
img.before(div);
});
} catch(e) {
console.error(e);
}
});Wykrywanie tekstu
Ostatnią funkcją interfejsu Shape Detection API jest wykrywanie tekstu. Wiesz już, że musimy znać stronę. Potrzebujemy strony z obrazami zawierającymi tekst, na przykład ten z wynikami skanowania w Książkach Google. W obsługiwanych przeglądarkach zobaczysz tekst i ograniczenie wokół fragmentów tekstu. Zremiksuj lub zmodyfikuj projekt Glitch, w szczególności plik script.js, aby zobaczyć, jak to się robi.

Aby przetestować to dynamicznie, wejdź na tę stronę wyników wyszukiwania na karcie prywatnej lub w trybie gościa. Następnie wklej poniższy fragment kodu na karcie konsoli Chrome DevTools. Z niewielkim opóźnieniem część tekstu zostanie rozpoznana.
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const texts = await new TextDetector().detect(img);
texts.forEach(text => {
const div = document.createElement('div');
const box = text.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 255, 255, 0.75)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left - left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
div.style.color = 'black';
div.style.fontSize = '14px';
div.innerHTML = text.rawValue;
img.before(div);
});
} catch(e) {
console.error(e);
}
});Prześlij opinię
Jak oceniasz ten interfejs API? Odpowiedz na pytania w krótkiej ankiecie:
Czy interfejs API był intuicyjny w użyciu?
Czy udało się uruchomić przykład?
Chcesz się podzielić czymś jeszcze? Czy brakuje jakichś funkcji? Podziel się z nami swoją opinią, wypełniając tę ankietę. Dziękuję!
Interfejs Web Share Target API umożliwia zainstalowanym aplikacjom internetowym rejestrowanie się w systemie operacyjnym, który pełni funkcję współdzielenia, jako celu udostępniania. Umożliwia to odbieranie treści z interfejsu Web Share API lub zdarzeń systemowych, np. przycisku udostępniania na poziomie systemu operacyjnego.
Instalowanie aplikacji PWA
Pierwszym krokiem jest posiadanie aplikacji PWA, którą możesz udostępnić. Tym razem firma Airhorner (na szczęście) skorzystała z pomocy, ale masz jeszcze aplikację demonstracyjną Web Share Target. Zainstaluj aplikację na ekranie głównym swojego urządzenia.

Udostępnianie informacji w PWA
Następnie musisz udostępnić coś, na przykład zdjęcie ze Zdjęć Google. Przy użyciu przycisku Udostępnij wybierz PWA notatnika jako wartość docelową udostępniania.
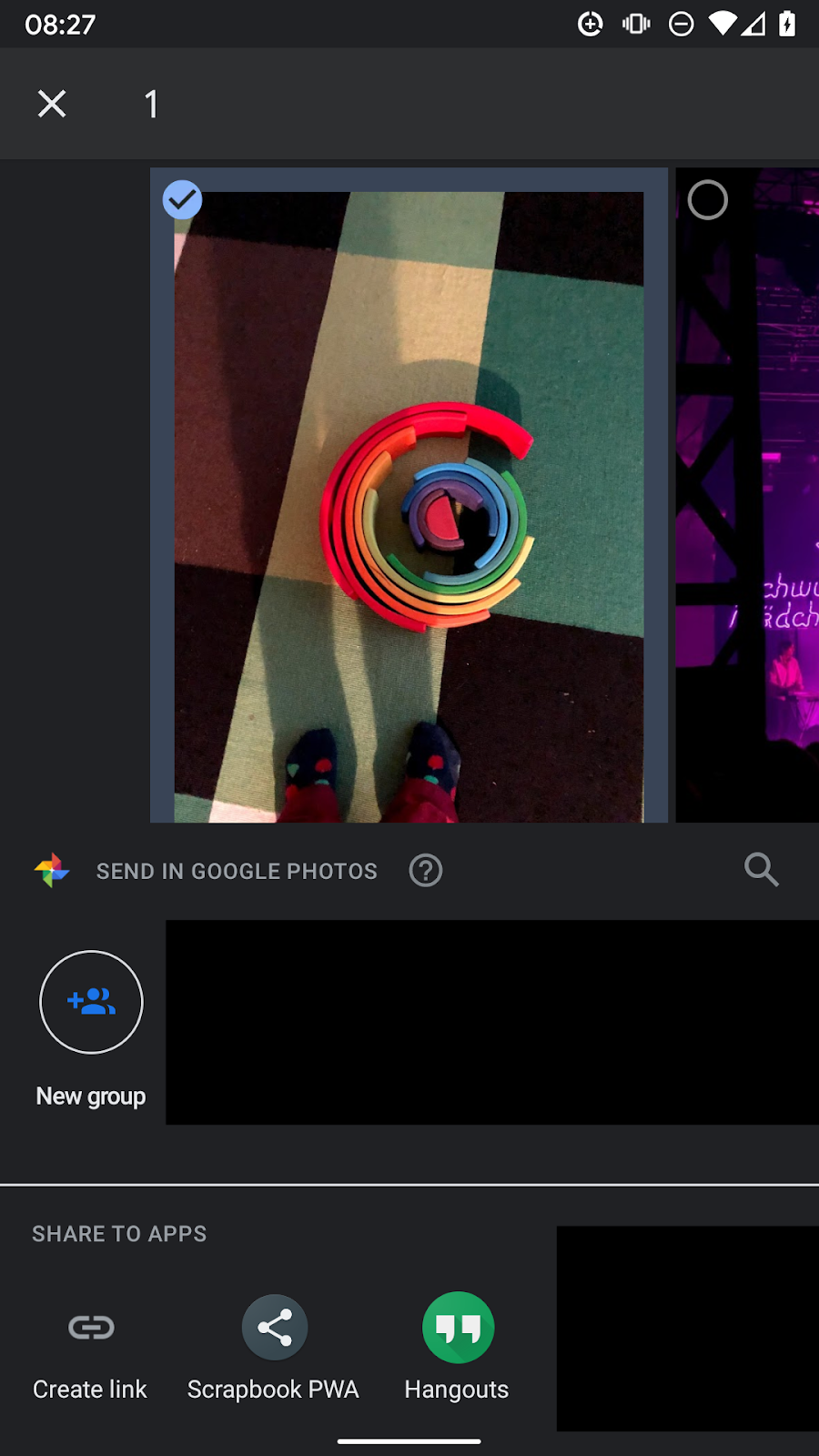
Po kliknięciu ikony aplikacji przejdziesz od razu do PWA notatnika, w którym zdjęcie będzie właśnie widoczne.
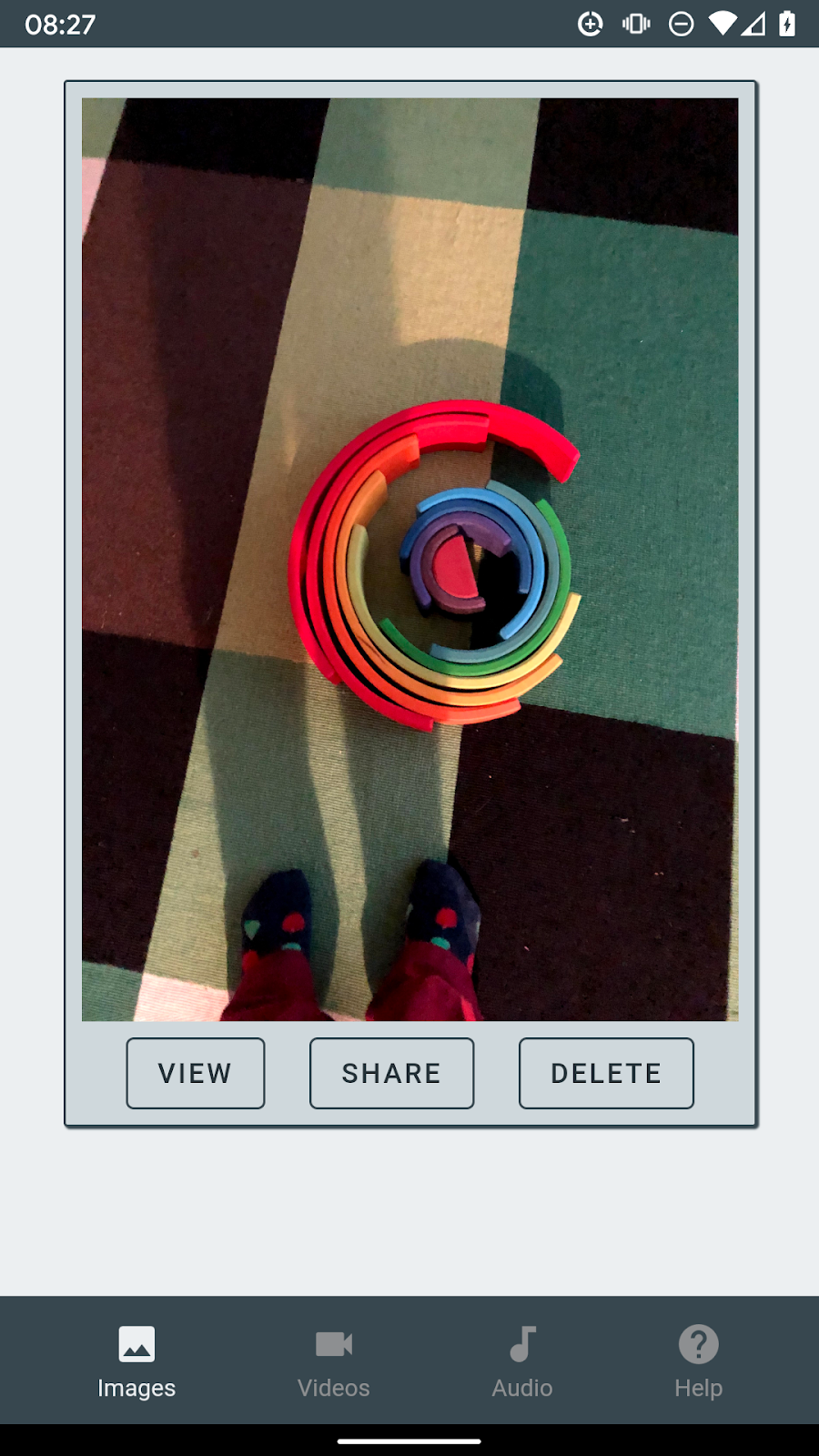
Jak to działa? Aby się tego dowiedzieć, zapoznaj się z manifestem aplikacji internetowej w notatniku. Konfiguracja interfejsu Web Share Target API znajduje się we właściwości "share_target" pliku manifestu i wskazuje w polu "action" adres URL, który jest ozdobiony parametrami podanymi w polu "params".
Strona udostępniania wypełnia ten szablon URL odpowiednio (albo za pomocą czynności udostępniania, albo kontrolowanego przez programistę za pomocą interfejsu Web Share API), aby strona odbierająca mogła wyodrębnić parametry i wykonać związane z nim działania, na przykład je wyświetlić.
{
"action": "/_share-target",
"enctype": "multipart/form-data",
"method": "POST",
"params": {
"files": [{
"name": "media",
"accept": ["audio/*", "image/*", "video/*"]
}]
}
}Prześlij opinię
Jak oceniasz ten interfejs API? Odpowiedz na pytania w krótkiej ankiecie:
Czy interfejs API był intuicyjny w użyciu?
Czy udało się uruchomić przykład?
Chcesz się podzielić czymś jeszcze? Czy brakuje jakichś funkcji? Podziel się z nami swoją opinią, wypełniając tę ankietę. Dziękuję!
Aby uniknąć wyczerpywania się baterii, większość urządzeń szybko przechodzi w tryb uśpienia, gdy jest bezczynny. Zazwyczaj jest to dobre rozwiązanie, ale niektóre aplikacje muszą utrzymywać ekran lub urządzenie w stanie uśpienia, aby dokończyć pracę. Interfejs Wake Lock API umożliwia zapobieganie przyciemnianiu i blokowaniu ekranu oraz uśpieniu urządzenia. Ta funkcja włącza nowe funkcje, które do tej pory wymagały aplikacji natywnej.
Konfigurowanie wygaszacza ekranu
Aby przetestować interfejs API Wake Lock, musisz najpierw upewnić się, że urządzenie uśpie. Dlatego w panelu ustawień Twojego systemu operacyjnego aktywuj wybrany wygaszacz ekranu i upewnij się, że rozpocznie się on po upływie 1 minuty. Upewnij się, że działa, pozostawiając urządzenie bez zmian przez pewien czas (tak, to boli mnie). Zrzuty ekranu poniżej pokazują funkcję macOS, ale możesz ją wypróbować na urządzeniu z Androidem lub na dowolnej obsługiwanej platformie komputerowej.
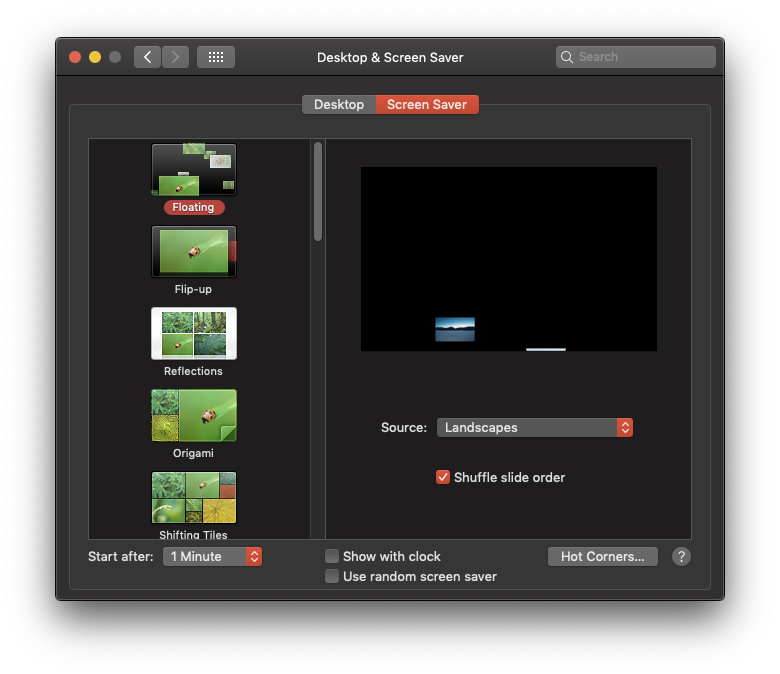
Ustawianie blokady uśpienia ekranu
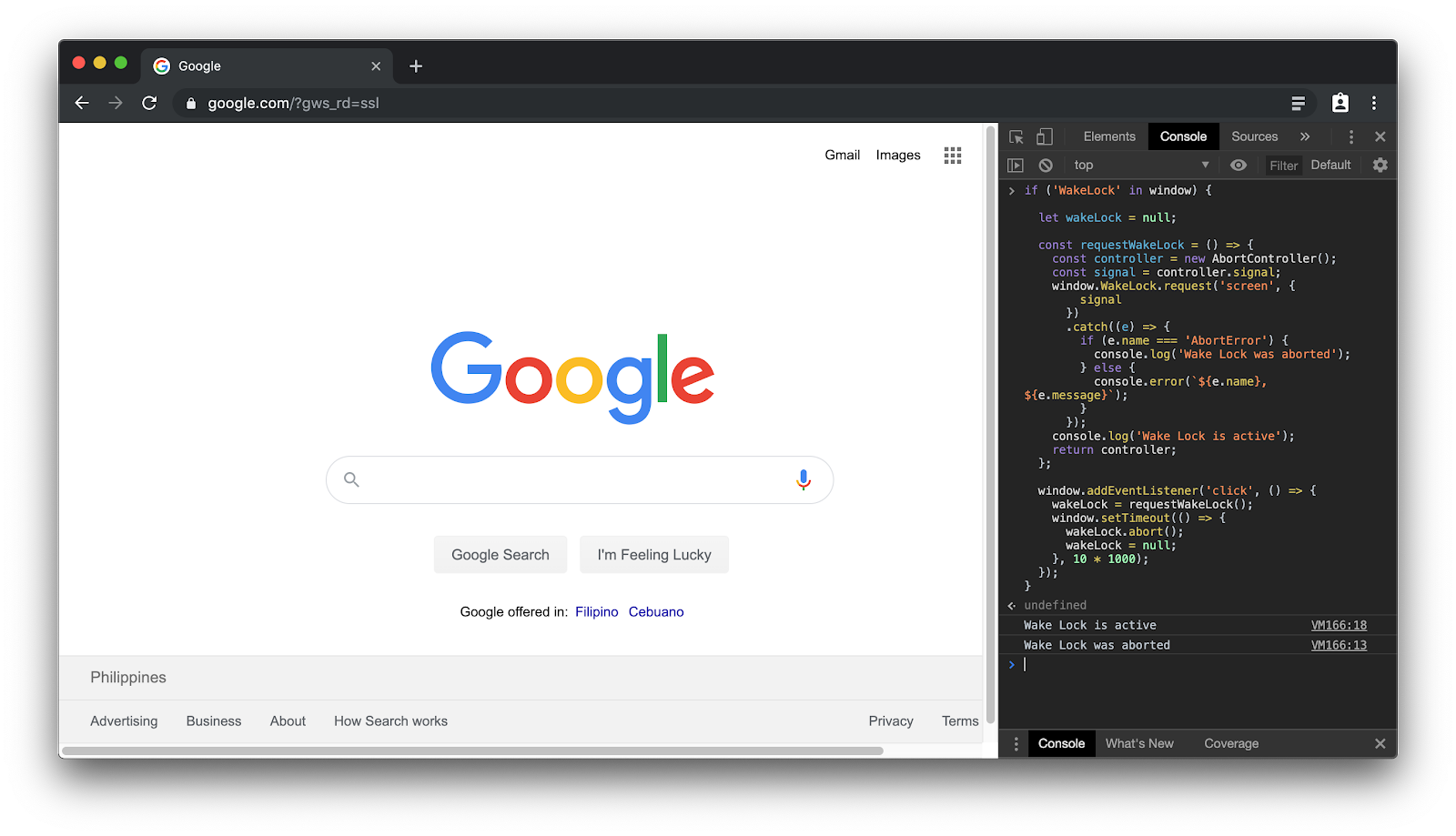
Teraz gdy już działa wygaszacz ekranu, możesz użyć blokady uśpienia typu "screen", aby zapobiec jego działaniu. Przejdź do aplikacji demonstracyjnej blokady ekranu i kliknij pole wyboru Aktywuj screen Wybudzanie blokady.
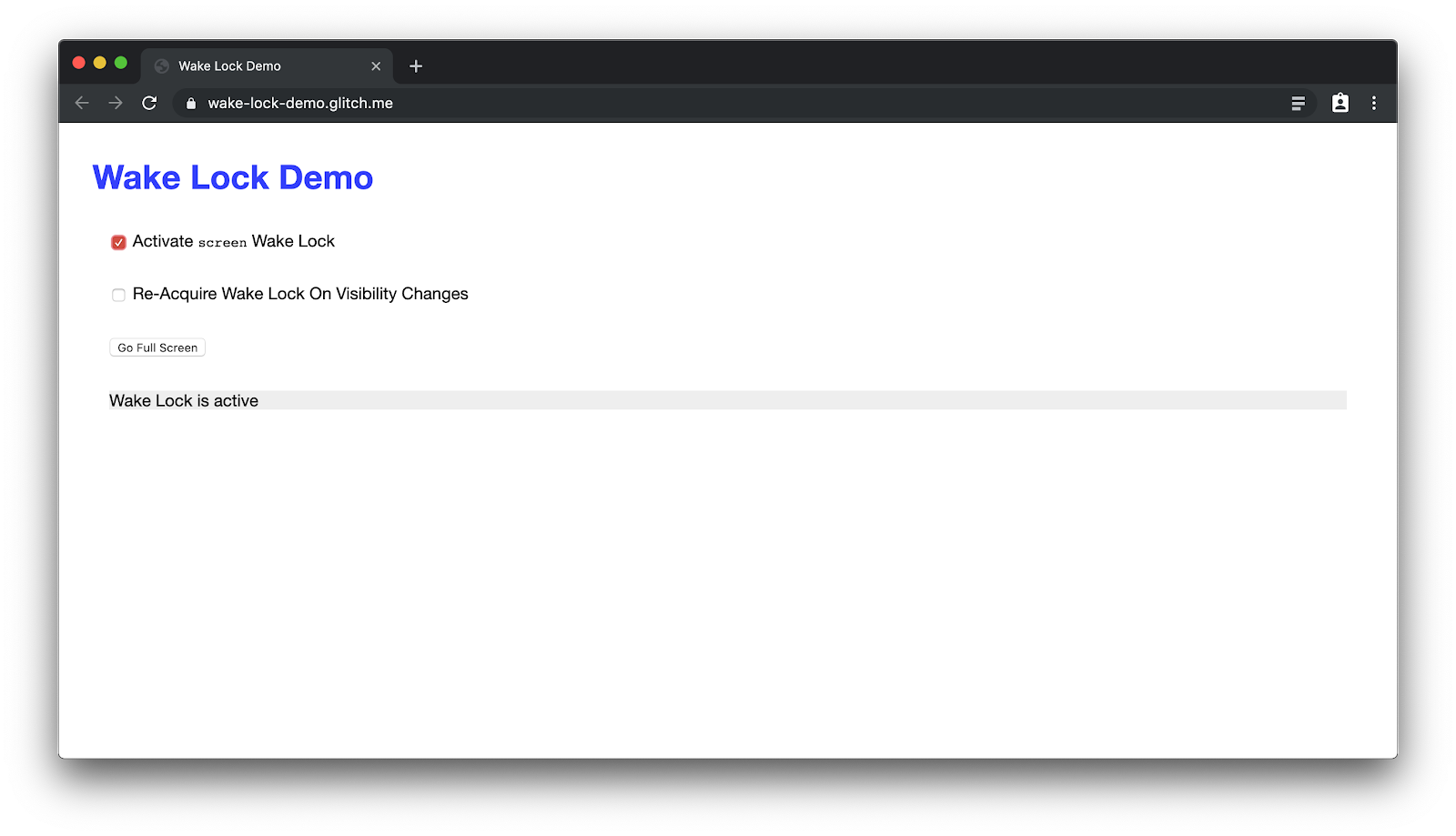
Od tego momentu aktywna będzie blokada uśpienia. Jeśli wystarczająco cierpliwie, by zostawić urządzenie bez zmian przez minutę, zobaczysz, że wygaszacz ekranu się w rzeczywistości nie uruchomił.
Jak to działa? Aby dowiedzieć się więcej, przejdź do projektu Glitch dotyczącego aplikacji demonstracyjnej Wake Lock i zapoznaj się z kodem script.js. Fragment kodu znajduje się poniżej. Otwórz nową kartę (lub użyj dowolnej otwartej karty) i wklej poniższy kod w konsoli Narzędzi dla deweloperów w Chrome. Gdy klikniesz okno, pojawi się blokada uśpienia, która będzie aktywna przez dokładnie 10 sekund (zobacz dzienniki konsoli), a wygaszacz ekranu nie powinien się uruchomić.
if ('wakeLock' in navigator && 'request' in navigator.wakeLock) {
let wakeLock = null;
const requestWakeLock = async () => {
try {
wakeLock = await navigator.wakeLock.request('screen');
wakeLock.addEventListener('release', () => {
console.log('Wake Lock was released');
});
console.log('Wake Lock is active');
} catch (e) {
console.error(`${e.name}, ${e.message}`);
}
};
requestWakeLock();
window.setTimeout(() => {
wakeLock.release();
}, 10 * 1000);
}
Prześlij opinię
Jak oceniasz ten interfejs API? Odpowiedz na pytania w krótkiej ankiecie:
Czy interfejs API był intuicyjny w użyciu?
Czy udało się uruchomić przykład?
Chcesz się podzielić czymś jeszcze? Czy brakuje jakichś funkcji? Podziel się z nami swoją opinią, wypełniając tę ankietę. Dziękuję!
Interfejs API selektora kontaktów jest dla nas bardzo ważny. Pozwala aplikacji internetowej na dostęp do kontaktów w natywnym menedżerze kontaktów na urządzeniu, dzięki czemu może ona korzystać z kontaktów, nazw, adresów e-mail i numerów telefonów. Możesz określić, czy chcesz udostępnić tylko jeden kontakt, czy wiele kontaktów i tylko niektóre pola albo tylko niektóre nazwy, adresy e-mail i numery telefonów.
Kwestie dotyczące prywatności
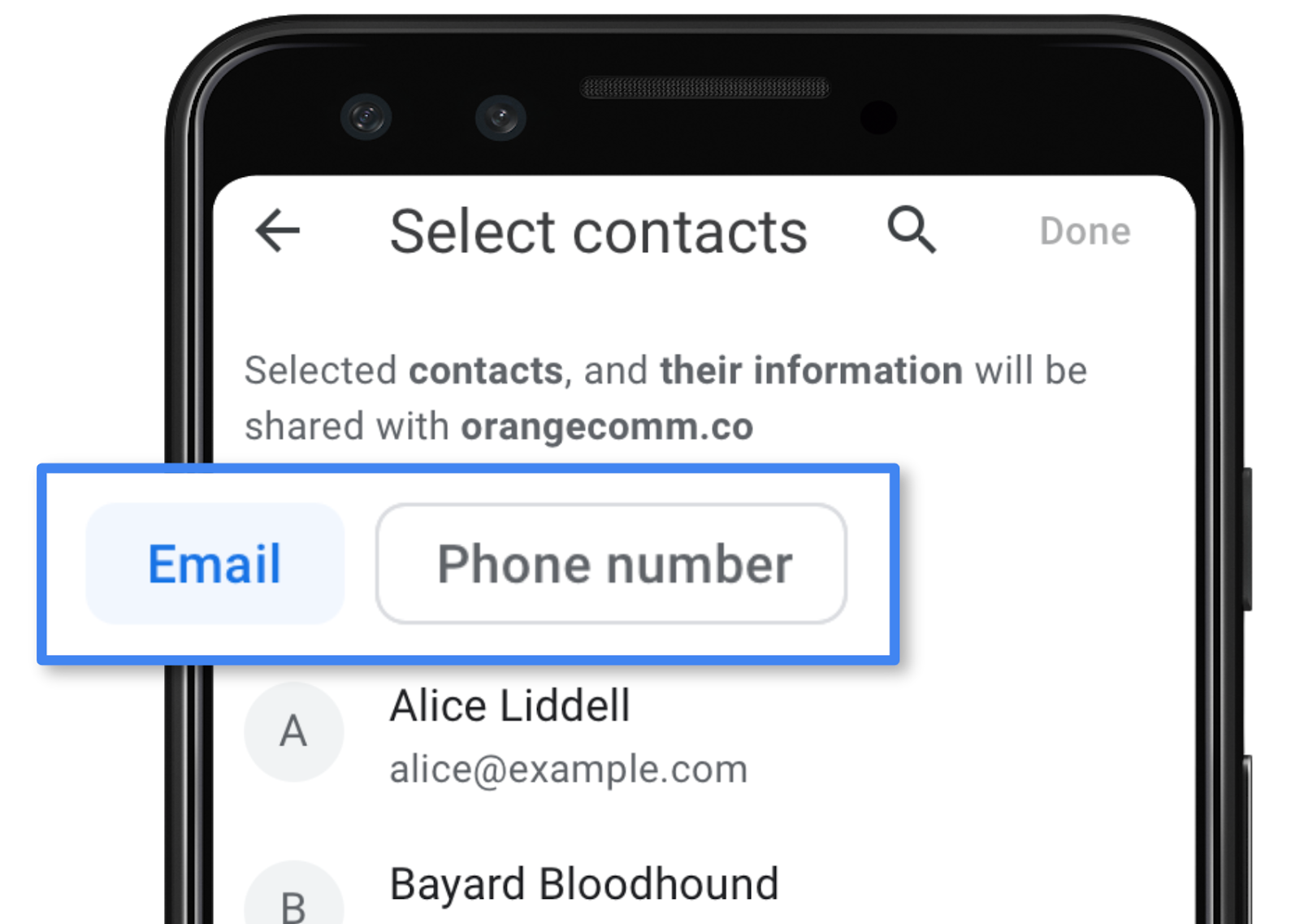
Po otwarciu selektora możesz wybrać kontakty, które chcesz udostępnić. Pamiętaj, że nie ma opcji &Zaznacz wszystko, która jest celowa: chcemy, aby udostępnianie było świadomą decyzją. Dostęp nie jest cykliczny, ale jednorazowy.
Uzyskiwanie dostępu do kontaktów
Uzyskiwanie dostępu do kontaktów to proste zadanie. Zanim otworzysz selektor, możesz określić, jakich pól chcesz używać (dostępne opcje to name, email i telephone) oraz czy chcesz uzyskać dostęp do wielu kontaktów, czy tylko do jednego. Możesz przetestować ten interfejs na urządzeniu z Androidem, otwierając aplikację demonstracyjną. Odpowiedni fragment kodu źródłowego to fragment kodu poniżej:
getContactsButton.addEventListener('click', async () => {
const contacts = await navigator.contacts.select(
['name', 'email'],
{multiple: true});
if (!contacts.length) {
// No contacts were selected, or picker couldn't be opened.
return;
}
console.log(contacts);
});
Kopiowanie i wklejanie tekstu
Do tej pory nie można było automatycznie kopiować ani wklejać obrazów do schowka systemu. Ostatnio dodaliśmy do interfejsu Async Clipboard API obsługę obrazów.
żeby można było kopiować i wklejać obrazy. Nowością jest również możliwość zapisywania obrazów w schowku. Asynchroniczny interfejs API schowka obsługuje od jakiegoś czasu kopiowanie i wklejanie tekstu. Możesz skopiować tekst do schowka, wywołując navigator.clipboard.writeText(), a następnie wklejając ten tekst, wywołując navigator.clipboard.readText().
Kopiowanie i wklejanie obrazów
Teraz możesz też zapisywać obrazy w schowku. Aby to umożliwić, dane obrazu muszą być obiektem blob, który następnie należy przekazać do konstruktora elementów w schowku. Na koniec możesz skopiować ten element do schowka, wywołując navigator.clipboard.write().
// Copy: Writing image to the clipboard
try {
const imgURL = 'https://developers.google.com/web/updates/images/generic/file.png';
const data = await fetch(imgURL);
const blob = await data.blob();
await navigator.clipboard.write([
new ClipboardItem(Object.defineProperty({}, blob.type, {
value: blob,
enumerable: true
}))
]);
console.log('Image copied.');
} catch(e) {
console.error(e, e.message);
}Wklejanie obrazu ze schowka wygląda na dość angażujące, ale polega na tym, że obiekt blob wróci ze schowka. Możliwe, że będzie ich kilka, więc trzeba je przejrzeć, aż znajdziesz to, które Cię interesuje. Ze względów bezpieczeństwa obecnie jest to ograniczone do obrazów w formacie PNG, ale w przyszłości możemy dodać więcej formatów obrazów.
async function getClipboardContents() {
try {
const clipboardItems = await navigator.clipboard.read();
for (const clipboardItem of clipboardItems) {
try {
for (const type of clipboardItem.types) {
const blob = await clipboardItem.getType(type);
console.log(URL.createObjectURL(blob));
}
} catch (e) {
console.error(e, e.message);
}
}
} catch (e) {
console.error(e, e.message);
}
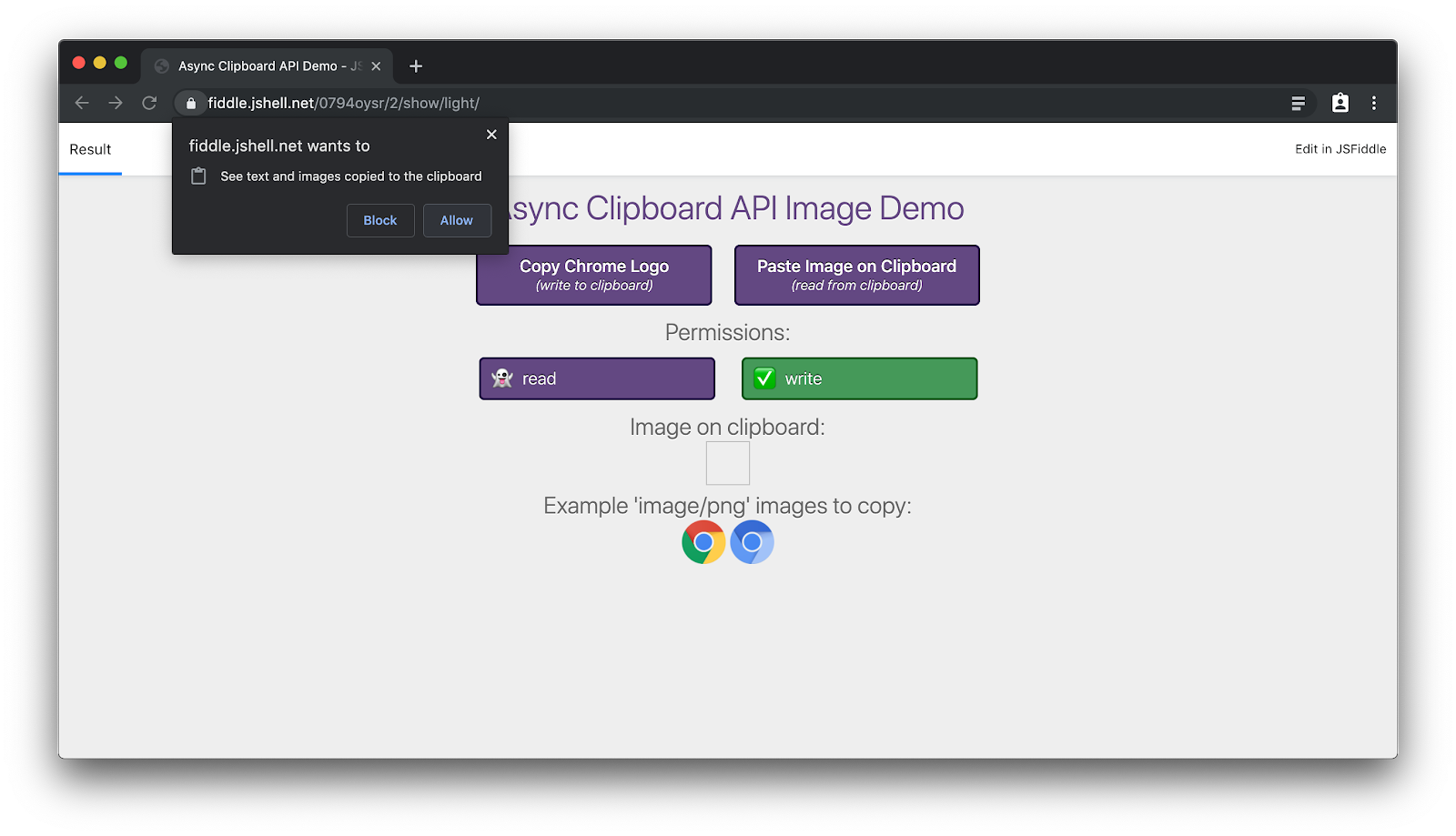
}Działanie tego interfejsu API możesz zobaczyć w aplikacji demonstracyjnej. Odpowiednie fragmenty kodu z kodu źródłowego są umieszczone powyżej. Możesz kopiować obrazy do schowka bez pozwolenia, ale musisz przyznać mu dostęp do wklejania.
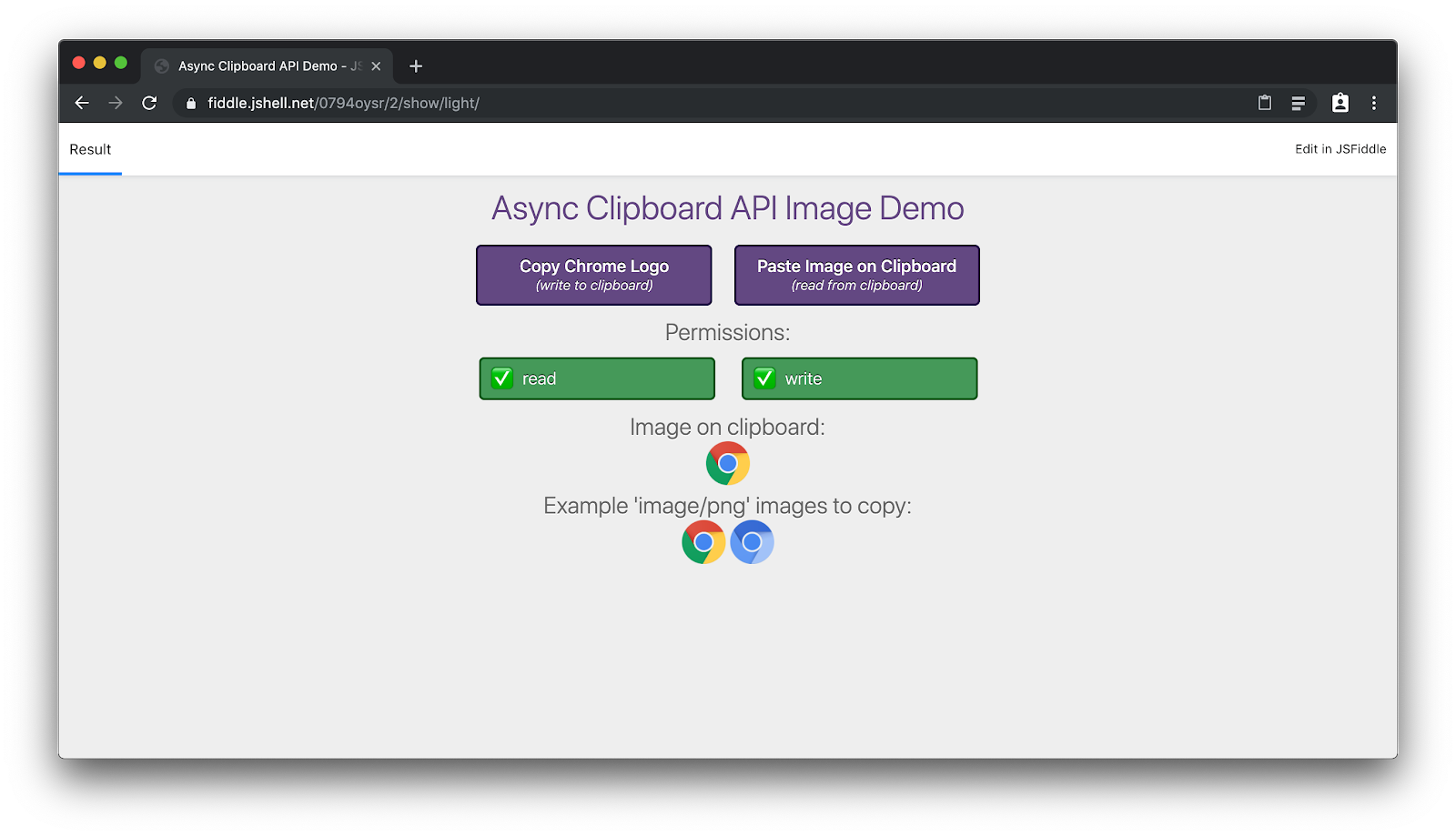
Po przyznaniu dostępu możesz odczytać obraz ze schowka i wkleić go w aplikacji:
Gratulujemy ukończenia ćwiczenia z programowania. Przypominamy, że większość interfejsów API jest nadal rozwijana i nad nimi pracuje. Nasz zespół bardzo ceni więc Twoje opinie, ponieważ tylko interakcje z osobami takimi jak Ty pomagają nam w ulepszaniu tych interfejsów API.
Zachęcamy też do częstego zaglądania na naszą stronę docelową Możliwości. Będziemy na bieżąco aktualizować tę stronę i będzie zawierać wskazówki do wszystkich szczegółowych artykułów na temat interfejsów API, nad którymi pracujemy. Dalej rockuj!
Tom i cały zespół 🐡