
Cloud Vision API giúp bạn hiểu nội dung của một hình ảnh bằng cách đóng gói các mô hình học máy mạnh mẽ trong một REST API đơn giản.
Trong phòng thí nghiệm này, chúng ta sẽ gửi hình ảnh đến Vision API và xem API này phát hiện các đối tượng, khuôn mặt và địa danh.
Kiến thức bạn sẽ học được
- Tạo yêu cầu Vision API và gọi API bằng curl
- Sử dụng các phương thức phát hiện nhãn, web, khuôn mặt và điểm mốc của API thị giác
What you'll need
Bạn sẽ sử dụng hướng dẫn này như thế nào?
Bạn đánh giá thế nào về trải nghiệm của mình với Google Cloud Platform?
Thiết lập môi trường theo tốc độ của riêng bạn
Nếu chưa có Tài khoản Google (Gmail hoặc Google Apps), bạn phải tạo một tài khoản. Đăng nhập vào bảng điều khiển Google Cloud Platform (console.cloud.google.com) rồi tạo một dự án mới:



Hãy nhớ mã dự án, một tên duy nhất trong tất cả các dự án trên Google Cloud (tên ở trên đã được sử dụng và sẽ không hoạt động đối với bạn, xin lỗi!). Sau này trong lớp học lập trình này, chúng ta sẽ gọi nó là PROJECT_ID.
Tiếp theo, bạn cần bật tính năng thanh toán trong Cloud Console để sử dụng các tài nguyên của Google Cloud.
Việc thực hiện lớp học lập trình này sẽ không tốn của bạn quá vài đô la, nhưng có thể tốn nhiều hơn nếu bạn quyết định sử dụng nhiều tài nguyên hơn hoặc nếu bạn để các tài nguyên đó chạy (xem phần "dọn dẹp" ở cuối tài liệu này).
Người dùng mới của Google Cloud Platform đủ điều kiện dùng thử miễn phí 300 USD.
Nhấp vào biểu tượng trình đơn ở trên cùng bên trái màn hình.

Chọn API và dịch vụ trong trình đơn thả xuống rồi nhấp vào Trang tổng quan

Nhấp vào Bật API và dịch vụ.

Sau đó, hãy tìm "thị lực" trong hộp tìm kiếm. Nhấp vào Google Cloud Vision API:

Nhấp vào Bật để bật Cloud Vision API:

Chờ vài giây để tính năng này bật. Bạn sẽ thấy thông báo này sau khi bật tính năng:

Google Cloud Shell là một môi trường dòng lệnh chạy trên Cloud. Máy ảo dựa trên Debian này được trang bị tất cả các công cụ phát triển mà bạn cần (gcloud, bq, git và các công cụ khác) và cung cấp một thư mục chính có dung lượng 5 GB. Chúng ta sẽ sử dụng Cloud Shell để tạo yêu cầu cho Speech API.
Để bắt đầu sử dụng Cloud Shell, hãy nhấp vào biểu tượng "Kích hoạt Google Cloud Shell"  ở góc trên cùng bên phải của thanh tiêu đề
ở góc trên cùng bên phải của thanh tiêu đề

Một phiên Cloud Shell sẽ mở ra trong một khung hình mới ở cuối bảng điều khiển và hiển thị một dấu nhắc dòng lệnh. Chờ cho đến khi lời nhắc user@project:~$ xuất hiện
Vì sẽ dùng curl để gửi yêu cầu đến Vision API, nên chúng ta cần tạo một khoá API để truyền vào URL yêu cầu. Để tạo khoá API, hãy chuyển đến phần Thông tin xác thực của API và dịch vụ trong bảng điều khiển Cloud:


Trong trình đơn thả xuống, hãy chọn Khoá API:

Tiếp theo, hãy sao chép khoá bạn vừa tạo.
Giờ đây, bạn đã có khoá API, hãy lưu khoá này vào một biến môi trường để không phải chèn giá trị của khoá API vào mỗi yêu cầu. Bạn có thể thực hiện việc này trong Cloud Shell. Hãy nhớ thay thế <your_api_key> bằng khoá mà bạn vừa sao chép.
export API_KEY=<YOUR_API_KEY>Tạo bộ chứa Cloud Storage
Có hai cách để gửi hình ảnh đến Vision API để phát hiện hình ảnh: bằng cách gửi cho API một chuỗi hình ảnh được mã hoá base64 hoặc truyền cho API URL của một tệp được lưu trữ trong Google Cloud Storage. Chúng ta sẽ sử dụng một URL Cloud Storage. Chúng ta sẽ tạo một bộ chứa Google Cloud Storage để lưu trữ hình ảnh.
Chuyển đến Storage browser (Trình duyệt bộ nhớ) trong Cloud Console cho dự án của bạn:

Sau đó, hãy nhấp vào Tạo vùng lưu trữ. Đặt một tên riêng biệt cho nhóm của bạn (chẳng hạn như mã dự án) rồi nhấp vào Tạo.
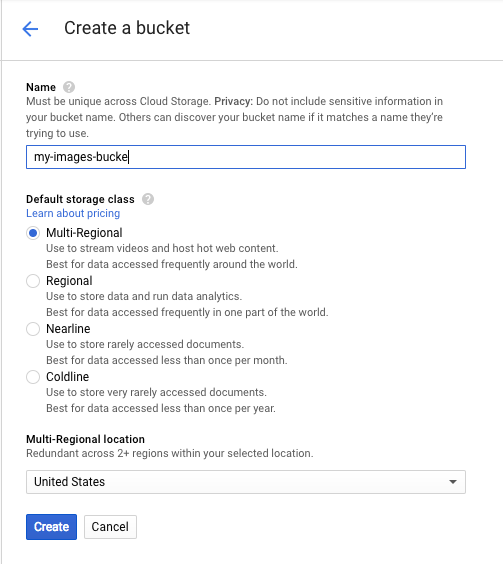
Tải hình ảnh lên nhóm của bạn
Nhấp chuột phải vào hình ảnh bánh rán sau đây, sau đó nhấp vào Lưu hình ảnh dưới dạng rồi lưu vào thư mục Tải xuống dưới dạng donuts.png.

Chuyển đến bộ chứa bạn vừa tạo trong trình duyệt bộ nhớ rồi nhấp vào Tải tệp lên. Sau đó, chọn donuts.png.

Bạn sẽ thấy tệp trong nhóm của mình:

Tiếp theo, hãy chỉnh sửa quyền đối với hình ảnh.

Nhấp vào Thêm mục.

Thêm một Thực thể mới của Group và Tên của allUsers:

Nhấp vào Lưu.
Giờ đây, khi đã có tệp trong vùng lưu trữ, bạn có thể tạo một yêu cầu Vision API, truyền cho yêu cầu đó URL của bức ảnh bánh rán này.
Trong môi trường Cloud Shell, hãy tạo một tệp request.json bằng mã bên dưới, nhớ thay thế my-bucket-name bằng tên của bộ chứa Cloud Storage mà bạn đã tạo. Bạn có thể tạo tệp bằng một trong các trình chỉnh sửa dòng lệnh mà bạn muốn (nano, vim, emacs) hoặc sử dụng trình chỉnh sửa Orion tích hợp trong Cloud Shell:

request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}Tính năng đầu tiên của Cloud Vision API mà chúng ta sẽ khám phá là tính năng phát hiện nhãn. Phương thức này sẽ trả về một danh sách nhãn (từ) về nội dung trong hình ảnh của bạn.
Giờ đây, chúng ta đã sẵn sàng gọi Vision API bằng curl:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Phản hồi của bạn sẽ có dạng như sau:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}API này có thể xác định loại bánh rán cụ thể (bánh rán có nhân) này, thật tuyệt! Đối với mỗi nhãn mà Vision API tìm thấy, API này sẽ trả về một description có tên của mục. Thao tác này cũng trả về một score, một số từ 0 đến 100 cho biết mức độ tin cậy rằng nội dung mô tả khớp với nội dung trong hình ảnh. Giá trị mid ánh xạ đến mã nhận dạng của mục trong Sơ đồ tri thức của Google. Bạn có thể sử dụng mid khi gọi Knowledge Graph API để biết thêm thông tin về mặt hàng.
Ngoài việc nhận nhãn về nội dung trong hình ảnh, Vision API cũng có thể tìm kiếm trên Internet để biết thêm thông tin chi tiết về hình ảnh của chúng ta. Thông qua phương thức webDetection của API, chúng ta sẽ nhận được nhiều dữ liệu thú vị:
- Danh sách các thực thể được tìm thấy trong hình ảnh của chúng tôi, dựa trên nội dung của những trang có hình ảnh tương tự
- URL của hình ảnh khớp chính xác và khớp một phần được tìm thấy trên web, cùng với URL của những trang đó
- URL của các hình ảnh tương tự, chẳng hạn như khi bạn tìm kiếm hình ảnh tương tự
Để thử tính năng phát hiện trên web, chúng ta sẽ sử dụng cùng một hình ảnh bánh rán ở trên, vì vậy, tất cả những gì chúng ta cần thay đổi là một dòng trong tệp request.json (bạn cũng có thể thử nghiệm và sử dụng một hình ảnh hoàn toàn khác). Trong danh sách các tính năng, chỉ cần thay đổi loại từ LABEL_DETECTION thành WEB_DETECTION. request.json hiện sẽ có dạng như sau:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}Để gửi yêu cầu này đến Vision API, bạn có thể sử dụng cùng một lệnh curl như trước (chỉ cần nhấn phím mũi tên lên trong Cloud Shell):
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Hãy cùng xem xét câu trả lời, bắt đầu bằng webEntities. Sau đây là một số thực thể mà hình ảnh này trả về:
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
Hình ảnh này đã được dùng lại trong nhiều bản trình bày về Cloud ML API của chúng tôi. Đó là lý do API tìm thấy các thực thể "Học máy", "Google Cloud Platform" và "Điện toán đám mây".
Nếu kiểm tra các URL trong fullMatchingImages, partialMatchingImages và pagesWithMatchingImages, chúng ta sẽ nhận thấy rằng nhiều URL trỏ đến trang web của lớp học lập trình này (siêu meta!).
Giả sử chúng ta muốn tìm những hình ảnh khác về bánh rán, nhưng không phải là những hình ảnh giống hệt. Đây là lúc phần visuallySimilarImages của phản hồi API phát huy tác dụng. Sau đây là một số hình ảnh tương tự về mặt thị giác mà công cụ này tìm thấy:
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]Chúng ta có thể chuyển đến những URL đó để xem các hình ảnh tương tự:




Tuyệt! Và có lẽ bây giờ bạn thực sự muốn ăn một chiếc bánh rán (xin lỗi). Điều này tương tự như việc tìm kiếm bằng hình ảnh trên Google Hình ảnh:

Nhưng với Cloud Vision, chúng ta có thể truy cập vào chức năng này bằng một API REST dễ sử dụng và tích hợp chức năng này vào các ứng dụng của mình.
Tiếp theo, chúng ta sẽ khám phá các phương thức phát hiện khuôn mặt và điểm đánh dấu của Vision API. Phương thức phát hiện khuôn mặt trả về dữ liệu về khuôn mặt được tìm thấy trong hình ảnh, bao gồm cả cảm xúc của khuôn mặt và vị trí của khuôn mặt trong hình ảnh. Tính năng phát hiện địa danh có thể xác định các địa danh phổ biến (và không rõ ràng) – tính năng này trả về tên của địa danh, toạ độ vĩ độ và kinh độ, cũng như vị trí nơi địa danh được xác định trong một hình ảnh.
Tải hình ảnh mới lên
Để sử dụng hai phương thức mới này, hãy tải một hình ảnh mới có khuôn mặt và địa danh lên vùng lưu trữ trên Cloud Storage. Nhấp chuột phải vào hình ảnh sau, sau đó nhấp vào Lưu hình ảnh dưới dạng rồi lưu vào thư mục Tải xuống dưới dạng selfie.png.

Sau đó, hãy tải tệp lên vùng lưu trữ trên đám mây theo cách bạn đã làm ở bước trước, nhớ đánh dấu vào hộp "Chia sẻ công khai".
Cập nhật yêu cầu của chúng tôi
Tiếp theo, chúng ta sẽ cập nhật tệp request.json để thêm URL của hình ảnh mới và sử dụng tính năng phát hiện khuôn mặt và địa danh thay vì tính năng phát hiện nhãn. Nhớ thay thế my-bucket-name bằng tên bộ chứa Cloud Storage của chúng tôi:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}Gọi Vision API và phân tích cú pháp phản hồi
Giờ đây, bạn đã sẵn sàng gọi Vision API bằng lệnh curl tương tự như lệnh bạn đã dùng ở trên:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Trước tiên, hãy xem xét đối tượng faceAnnotations trong phản hồi của chúng ta. Bạn sẽ nhận thấy API này trả về một đối tượng cho mỗi khuôn mặt được tìm thấy trong hình ảnh – trong trường hợp này là 3. Sau đây là phiên bản rút gọn của câu trả lời:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly cung cấp cho chúng ta toạ độ x,y xung quanh khuôn mặt trong hình ảnh. fdBoundingPoly là một hộp nhỏ hơn boundingPoly, mã hoá trên phần da của khuôn mặt. landmarks là một mảng các đối tượng cho từng đặc điểm trên khuôn mặt (có thể bạn thậm chí còn chưa biết đến một số đặc điểm!). Thông tin này cho biết loại điểm đánh dấu, cùng với vị trí 3D của đối tượng đó (toạ độ x, y, z), trong đó toạ độ z là độ sâu. Các giá trị còn lại cung cấp cho chúng ta thêm thông tin chi tiết về khuôn mặt, bao gồm cả khả năng thể hiện niềm vui, nỗi buồn, sự tức giận và sự ngạc nhiên. Đối tượng ở trên là người ở xa nhất trong bức ảnh – bạn có thể thấy người này đang làm một khuôn mặt hơi ngớ ngẩn, điều này giải thích cho joyLikelihood của POSSIBLE.
Tiếp theo, hãy xem xét phần landmarkAnnotations trong phản hồi của chúng ta:
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]Trong trường hợp này, Vision API có thể nhận biết rằng bức ảnh này được chụp ở Petra. Đây là một kết quả khá ấn tượng vì bức ảnh này có rất ít manh mối trực quan. Các giá trị trong phản hồi này phải tương tự như phản hồi labelAnnotations ở trên.
Chúng tôi nhận được mid của địa danh, tên (description) cùng với độ tin cậy score. boundingPoly cho biết khu vực trong hình ảnh nơi địa danh được xác định. Khoá locations cho chúng ta biết toạ độ vĩ độ và kinh độ của địa danh này.
Chúng tôi đã xem xét các phương thức phát hiện nhãn, khuôn mặt và địa danh của Vision API, nhưng vẫn còn 3 phương thức khác mà chúng tôi chưa khám phá. Hãy xem tài liệu để tìm hiểu về 3 loại còn lại:
- Phát hiện biểu trưng: xác định các biểu trưng phổ biến và vị trí của chúng trong hình ảnh.
- Phát hiện nội dung tìm kiếm an toàn: xác định xem một hình ảnh có chứa nội dung phản cảm hay không. Điều này hữu ích cho mọi ứng dụng có nội dung do người dùng tạo. Bạn có thể lọc hình ảnh dựa trên 4 yếu tố: nội dung người lớn, nội dung y tế, nội dung bạo lực và nội dung giả mạo.
- Phát hiện văn bản: chạy OCR để trích xuất văn bản từ hình ảnh. Phương thức này thậm chí có thể xác định ngôn ngữ của văn bản có trong hình ảnh.
Bạn đã tìm hiểu cách phân tích hình ảnh bằng Vision API. Trong ví dụ này, bạn đã truyền cho API URL Google Cloud Storage của hình ảnh. Ngoài ra, bạn có thể truyền một chuỗi được mã hoá base64 của hình ảnh.
Nội dung đã đề cập
- Gọi Vision API bằng curl bằng cách truyền cho API này URL của một hình ảnh trong một vùng chứa Cloud Storage
- Sử dụng các phương thức phát hiện nhãn, web, khuôn mặt và địa điểm nổi tiếng của Vision API
Bước tiếp theo
- Xem hướng dẫn về Vision API trong tài liệu
- Tìm mẫu Vision API bằng ngôn ngữ bạn yêu thích
- Hãy dùng thử các lớp học lập trình Speech API và Natural Language API!