
Cloud Vision API, güçlü makine öğrenimi modellerini basit bir REST API'de kapsülleyerek bir görüntünün içeriğini anlamanıza olanak tanır.
Bu laboratuvarda, Vision API'ye resimler gönderecek ve nesneleri, yüzleri ve önemli noktaları algıladığını göreceğiz.
Neler öğreneceksiniz?
- Vision API isteği oluşturma ve API'yi curl ile çağırma
- Vision API'nin etiket, web, yüz ve önemli nokta algılama yöntemlerini kullanma
Gerekenler
Bu eğitimi nasıl kullanacaksınız?
Google Cloud Platform deneyiminizi nasıl değerlendirirsiniz?
Kendi hızınızda ortam kurulumu
Henüz bir Google Hesabınız (Gmail veya Google Apps) yoksa oluşturmanız gerekir. Google Cloud Platform Console'da (console.cloud.google.com) oturum açın ve yeni bir proje oluşturun:



Proje kimliğini unutmayın. Bu kimlik, tüm Google Cloud projelerinde benzersiz bir addır (Yukarıdaki ad zaten alınmış olduğundan sizin için çalışmayacaktır). Bu codelab'in ilerleyen kısımlarında PROJECT_ID olarak adlandırılacaktır.
Ardından, Google Cloud kaynaklarını kullanmak için Cloud Console'da faturalandırmayı etkinleştirmeniz gerekir.
Bu codelab'i tamamlamak size birkaç dolardan fazla maliyet getirmemelidir. Ancak daha fazla kaynak kullanmaya karar verirseniz veya kaynakları çalışır durumda bırakırsanız maliyet daha yüksek olabilir (bu belgenin sonundaki "temizleme" bölümüne bakın).
Google Cloud Platform'un yeni kullanıcıları 300 ABD doları değerindeki ücretsiz deneme sürümünden yararlanabilir.
Ekranın sol üst kısmındaki menü simgesini tıklayın.

Açılır menüden API'ler ve hizmetler'i seçip Kontrol Paneli'ni tıklayın.
API'leri ve hizmetleri etkinleştir'i tıklayın.
Ardından, arama kutusunda "görüş"ü arayın. Google Cloud Vision API'yi tıklayın:

Cloud Vision API'yi etkinleştirmek için Etkinleştir'i tıklayın:

Etkinleşmesi için birkaç saniye bekleyin. Etkinleştirildikten sonra şunları görürsünüz:
Google Cloud Shell, Cloud'da çalışan bir komut satırı ortamıdır. Bu Debian tabanlı sanal makine, ihtiyaç duyacağınız tüm geliştirme araçları (gcloud, bq, git ve diğerleri) yüklü olarak gelir ve 5 GB kalıcı ana dizin sunar. Speech API'ye yönelik isteğimizi oluşturmak için Cloud Shell'i kullanacağız.
Cloud Shell'i kullanmaya başlamak için başlık çubuğunun sağ üst köşesindeki "Google Cloud Shell'i etkinleştir"  simgesini tıklayın.
simgesini tıklayın.

Konsolun altındaki yeni bir çerçevede Cloud Shell oturumu açılır ve komut satırı istemi görüntülenir. user@project:~$ istemi görünene kadar bekleyin.
Vision API'ye istek göndermek için curl kullanacağımızdan istek URL'sini iletmek üzere bir API anahtarı oluşturmamız gerekecektir. API anahtarı oluşturmak için Cloud Console'unuzda API'ler ve hizmetler bölümündeki Kimlik bilgileri kısmına gidin:
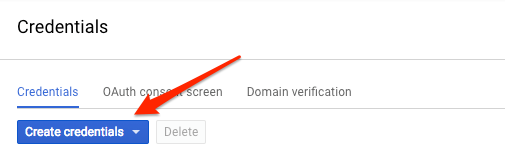
Açılır menüde, API anahtarı'nı seçin:
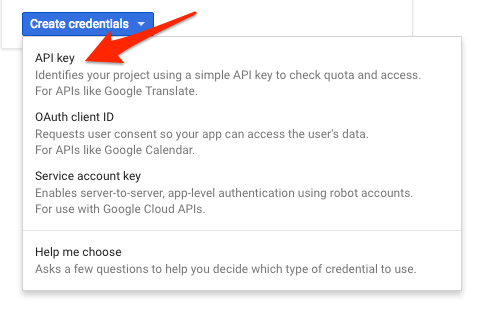
Ardından, az önce oluşturduğunuz anahtarı kopyalayın.
Artık bir API anahtarınız var. Şimdi bu anahtarı bir ortam değişkenine kaydedip her istekte API anahtarınızın değerini ekleme zahmetinden kurtulabilirsiniz. Bu işlemi Cloud Shell'de yapabilirsiniz. <your_api_key> yerine az önce kopyaladığınız anahtarı yapıştırdığınızdan emin olun.
export API_KEY=<YOUR_API_KEY>Cloud Storage paketi oluşturma
Görüntü algılama için Vision API'ye görüntü göndermenin iki yolu vardır: API'ye base64 olarak kodlanmış bir görüntü dizesi göndermek veya Google Cloud Storage'da depolanan bir dosyanın URL'sini iletmek. Cloud Storage URL'si kullanacağız. Resimlerimizi depolamak için bir Google Cloud Storage paketi oluşturacağız.
Projeniz için Cloud Console'da depolama tarayıcısına gidin:
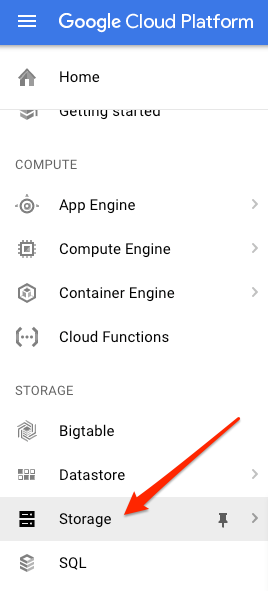
Ardından Paket oluştur'u tıklayın. Paketinize benzersiz bir ad (ör. proje kimliğiniz) verin ve Oluştur'u tıklayın.
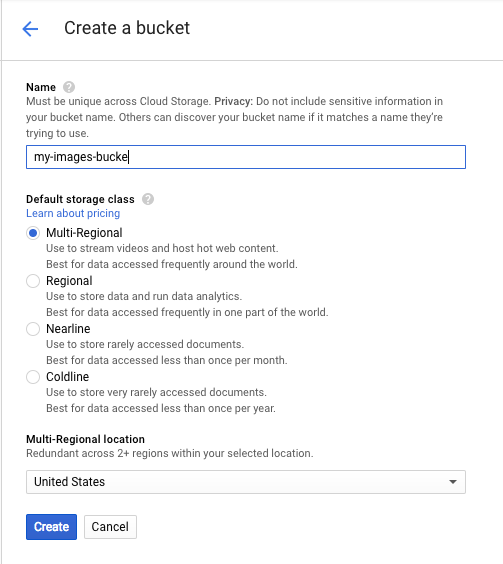
Paketinize resim yükleme
Aşağıdaki donut resmini sağ tıklayın, ardından Resmi farklı kaydet'i tıklayın ve resmi İndirilenler klasörünüze donuts.png olarak kaydedin.

Depolama tarayıcısında az önce oluşturduğunuz pakete gidin ve Dosyaları yükle'yi tıklayın. Ardından donuts.png dosyasını seçin.
Dosyayı paketinizde görmelisiniz:

Ardından, resmin iznini düzenleyin.
Öğe Ekle'yi tıklayın.
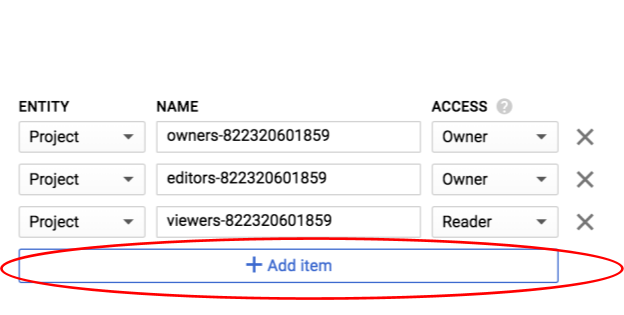
Group türünde yeni bir Varlık ve allUsers türünde bir Ad ekleyin:
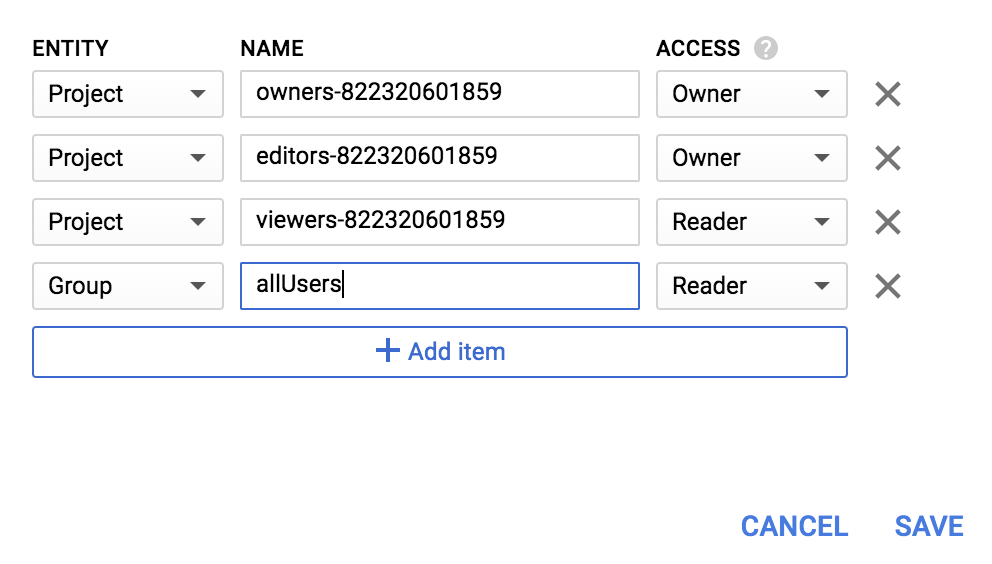
Kaydet'i tıklayın.
Dosya artık paketinizde olduğuna göre, bu donut resminin URL'sini ileterek bir Vision API isteği oluşturmaya hazırsınız.
Cloud Shell ortamınızda aşağıdaki kodu içeren bir request.json dosyası oluşturun. my-bucket-name kısmını oluşturduğunuz Cloud Storage paketinin adıyla değiştirmeyi unutmayın. Dosyayı tercih ettiğiniz komut satırı düzenleyicilerinden (nano, vim, emacs) birini kullanarak oluşturabilir veya Cloud Shell'deki yerleşik Orion düzenleyiciyi kullanabilirsiniz:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}İnceleyeceğimiz ilk Cloud Vision API özelliği, etiket algılama olacak. Bu yöntem, resminizde bulunan öğelerin etiketlerinin (kelimeler) listesini döndürür.
Artık Vision API'yi curl ile çağırmaya hazırız:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Yanıtınız aşağıdaki gibi görünmelidir:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}API, bu donutların türünü (beignets) belirleyebildi. Harika! Vision API'nin bulduğu her etiket için öğenin adını içeren bir description döndürülür. Ayrıca, açıklamanın resimdeki içerikle eşleştiğinden ne kadar emin olduğunu gösteren 0-100 arasında bir sayı olan score değerini de döndürür. mid değeri, Google'ın Bilgi Grafiği'ndeki öğenin mid'siyle eşlenir. Öğe hakkında daha fazla bilgi edinmek için Knowledge Graph API'yi çağırırken mid simgesini kullanabilirsiniz.
Vision API, resmimizde ne olduğuna dair etiketler almanın yanı sıra resmimizle ilgili ek ayrıntılar için internette de arama yapabilir. API'nin webDetection yöntemi aracılığıyla birçok ilginç veri elde ederiz:
- Benzer resimlerin bulunduğu sayfalardaki içeriklere göre, resmimizde bulunan varlıkların listesi
- Web'de bulunan tam ve kısmi eşleşen resimlerin URL'leri ve bu sayfaların URL'leri
- Tersinden görsel arama yapma gibi benzer görsellerin URL'leri
Web algılamayı denemek için yukarıdaki beignet resmini kullanacağız. Bu nedenle, request.json dosyamızda yalnızca bir satırı değiştirmemiz gerekiyor (bilinmeyene doğru yolculuğa çıkıp tamamen farklı bir resim de kullanabilirsiniz). Özellikler listesinde türü LABEL_DETECTION olarak değiştirin.WEB_DETECTION request.json artık şu şekilde görünmelidir:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}Bu isteği Vision API'ye göndermek için öncekiyle aynı curl komutunu kullanabilirsiniz (Cloud Shell'de yukarı oku basmanız yeterlidir):
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}webEntities ile başlayarak yanıta göz atalım. Bu resmin döndürdüğü bazı öğeler şunlardır:
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
Bu resim, Cloud ML API'lerimizle ilgili birçok sunumda yeniden kullanıldı. Bu nedenle API,"Makine öğrenimi", "Google Cloud Platform" ve "Bulut bilişim" öğelerini buldu.
fullMatchingImages, partialMatchingImages ve pagesWithMatchingImages altındaki URL'leri incelersek URL'lerin çoğunun bu codelab sitesine (süper meta!) yönlendirdiğini görürüz.
Diyelim ki beignets'in diğer resimlerini bulmak istiyoruz ancak tam olarak aynı resimleri değil. API yanıtının visuallySimilarImages bölümü bu noktada devreye girer. Görsel olarak benzer bulduğu resimlerden bazıları:
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]Benzer resimleri görmek için bu URL'lere gidebiliriz:




Güzel! Şimdi muhtemelen beignet yemek istiyorsunuz (üzgünüz). Bu, Google Görseller'de resimle arama yapmaya benzer:
Ancak Cloud Vision ile bu işlevselliğe kullanımı kolay bir REST API ile erişebilir ve uygulamalarımıza entegre edebiliriz.
Ardından, Vision API'nin yüz ve önemli nokta algılama yöntemlerini inceleyeceğiz. Yüz algılama yöntemi, bir resimde bulunan yüzlerle ilgili verileri (yüzlerin duyguları ve resimdeki konumları dahil) döndürür. Önemli nokta algılama, yaygın (ve belirsiz) önemli noktaları tanımlayabilir. Önemli noktanın adını, enlem ve boylam koordinatlarını ve önemli noktanın bir resimde tanımlandığı konumu döndürür.
Yeni bir resim yükleme
Bu iki yeni yöntemi kullanmak için yüzler ve önemli noktalar içeren yeni bir resmi Cloud Storage paketimize yükleyelim. Aşağıdaki resmi sağ tıklayın, ardından Resmi farklı kaydet'i tıklayın ve resmi İndirilenler klasörünüze selfie.png olarak kaydedin.

Ardından, "Herkese açık olarak paylaş" onay kutusunu işaretlediğinizden emin olarak önceki adımda yaptığınız gibi Cloud Storage paketinize yükleyin.
İsteğimizi güncelleme
Ardından, yeni resmin URL'sini eklemek ve etiket algılama yerine yüz ve önemli nokta algılama özelliğini kullanmak için request.json dosyamızı güncelleyeceğiz. my-bucket-name kısmını Cloud Storage paketimizin adıyla değiştirdiğinizden emin olun:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}Vision API'yi çağırma ve yanıtı ayrıştırma
Artık yukarıda kullandığınız curl komutunu kullanarak Vision API'yi çağırmaya hazırsınız:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Öncelikle yanıtımızdaki faceAnnotations nesnesine göz atalım. API'nin, resimde bulunan her yüz için bir nesne döndürdüğünü görürsünüz. Bu örnekte üç nesne döndürülür. Yanıtımızın kırpılmış bir sürümünü aşağıda bulabilirsiniz:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly, resimdeki yüzün etrafındaki x,y koordinatlarını verir. fdBoundingPoly, yüzün cilt kısmında kodlama yapan boundingPoly değerinden daha küçük bir kutudur. landmarks, her yüz özelliği için bir nesne dizisidir (bazılarını bilmiyor olabilirsiniz!). Bu, bize yer işaretinin türünü ve bu özelliğin 3D konumunu (x,y,z koordinatları) bildirir. Burada z koordinatı derinliği ifade eder. Kalan değerler, neşe, üzüntü, öfke ve sürpriz olasılığı da dahil olmak üzere yüz hakkında daha fazla ayrıntı verir. Yukarıdaki nesne, resimde en arkada duran kişi içindir. Bu kişinin komik bir yüz ifadesi yaptığını görebilirsiniz. Bu da POSSIBLE ifadesinin joyLikelihood olmasını açıklar.
Şimdi de yanıtımızın landmarkAnnotations kısmına bakalım:
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]Vision API, bu resmin Petra'da çekildiğini söyleyebildi. Resimdeki görsel ipuçlarının çok az olduğu göz önüne alındığında bu oldukça etkileyici. Bu yanıttaki değerler, yukarıdaki labelAnnotations yanıtına benzer olmalıdır.
Önemli yerin mid, adı (description) ve güven score değerini alırız. boundingPoly, resimde simge yapının tanımlandığı bölgeyi gösterir. locations anahtarı, bu önemli noktanın enlem ve boylam koordinatlarını gösterir.
Vision API'nin etiket, yüz ve önemli nokta algılama yöntemlerine baktık ancak incelemediğimiz üç yöntem daha var. Diğer üçü hakkında bilgi edinmek için belgeleri inceleyin:
- Logo algılama: Sık kullanılan logoları ve resimdeki konumlarını belirleyin.
- Güvenli arama algılama: Bir resmin uygunsuz içerik barındırıp barındırmadığını belirleyin. Bu, kullanıcı tarafından oluşturulan içeriğe sahip tüm uygulamalar için yararlıdır. Resimleri dört faktöre göre filtreleyebilirsiniz: yetişkinlere uygun içerik, tıbbi içerik, şiddet içeren içerik ve parodi içerik.
- Metin algılama: Resimlerdeki metinleri ayıklamak için OCR'yi çalıştırın. Bu yöntem, bir resimdeki metnin dilini bile tanımlayabilir.
Vision API ile görüntüleri nasıl analiz edeceğinizi öğrendiniz. Bu örnekte, resminizin Google Cloud Storage URL'sini API'ye ilettiniz. Alternatif olarak, resminizin base64 kodlu dizesini iletebilirsiniz.
İşlediğimiz konular
- Cloud Storage paketindeki bir görüntünün URL'sini ileterek Vision API'yi curl ile çağırma
- Vision API'nin etiket, web, yüz ve önemli nokta algılama yöntemlerini kullanma
Sonraki Adımlar
- Belgelerdeki Vision API eğitimlerine göz atın.
- En sevdiğiniz dilde Vision API örneği bulma
- Speech API ve Natural Language API codelab'lerini deneyin.