
Cloud Vision API ช่วยให้คุณเข้าใจเนื้อหาของรูปภาพได้ด้วยการแคปซูลโมเดลแมชชีนเลิร์นนิงที่มีประสิทธิภาพใน REST API แบบง่าย
ในแล็บนี้ เราจะส่งรูปภาพไปยัง Vision API และดูว่า API ตรวจจับออบเจ็กต์ ใบหน้า และสถานที่สำคัญได้อย่างไร
สิ่งที่คุณจะได้เรียนรู้
- การสร้างคำขอ Vision API และการเรียกใช้ API ด้วย curl
- การใช้วิธีการตรวจจับป้ายกำกับ เว็บ ใบหน้า และจุดสังเกตของ Vision API
สิ่งที่ต้องมี
คุณจะใช้บทแนะนำนี้อย่างไร
คุณจะให้คะแนนประสบการณ์การใช้งาน Google Cloud Platform เท่าไร
การตั้งค่าสภาพแวดล้อมแบบเรียนรู้ด้วยตนเอง
หากยังไม่มีบัญชี Google (Gmail หรือ Google Apps) คุณต้องสร้างบัญชี ลงชื่อเข้าใช้คอนโซล Google Cloud Platform (console.cloud.google.com) แล้วสร้างโปรเจ็กต์ใหม่โดยทำดังนี้



โปรดจดจำรหัสโปรเจ็กต์ ซึ่งเป็นชื่อที่ไม่ซ้ำกันในโปรเจ็กต์ Google Cloud ทั้งหมด (ชื่อด้านบนถูกใช้ไปแล้วและจะใช้ไม่ได้ ขออภัย) ซึ่งจะเรียกว่า PROJECT_ID ในภายหลังใน Codelab นี้
จากนั้นคุณจะต้องเปิดใช้การเรียกเก็บเงินใน Cloud Console เพื่อใช้ทรัพยากร Google Cloud
การทำ Codelab นี้ไม่ควรมีค่าใช้จ่ายเกิน 2-3 ดอลลาร์ แต่ก็อาจมีค่าใช้จ่ายมากกว่านี้หากคุณตัดสินใจใช้ทรัพยากรเพิ่มเติมหรือปล่อยให้ทรัพยากรทำงานต่อไป (ดูส่วน "การล้างข้อมูล" ที่ท้ายเอกสารนี้)
ผู้ใช้ใหม่ของ Google Cloud Platform มีสิทธิ์ทดลองใช้ฟรี$300
คลิกไอคอนเมนูที่ด้านซ้ายบนของหน้าจอ

เลือก API และบริการจากเมนูแบบเลื่อนลง แล้วคลิกแดชบอร์ด
คลิกเปิดใช้ API และบริการ
จากนั้นค้นหา "การมองเห็น" ในช่องค้นหา คลิก Google Cloud Vision API

คลิกเปิดใช้เพื่อเปิดใช้ Cloud Vision API

รอสักครู่เพื่อให้ระบบเปิดใช้ คุณจะเห็นข้อความต่อไปนี้เมื่อเปิดใช้
Google Cloud Shell เป็น สภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์ เครื่องเสมือนที่ใช้ Debian นี้มาพร้อมเครื่องมือพัฒนาทั้งหมดที่คุณต้องการ (gcloud, bq, git และอื่นๆ) และมีไดเรกทอรีแรกขนาด 5 GB แบบถาวร เราจะใช้ Cloud Shell เพื่อสร้างคำขอไปยัง Speech API
หากต้องการเริ่มต้นใช้งาน Cloud Shell ให้คลิกไอคอน "เปิดใช้งาน Google Cloud Shell"  ที่มุมขวาบนของแถบส่วนหัว
ที่มุมขวาบนของแถบส่วนหัว

เซสชัน Cloud Shell จะเปิดในเฟรมใหม่ที่ด้านล่างของคอนโซลและแสดงข้อความแจ้งบรรทัดคำสั่ง รอจนกว่าพรอมต์ user@project:~$ จะปรากฏขึ้น
เนื่องจากเราจะใช้ Curl เพื่อส่งคำขอไปยัง Vision API เราจึงต้องสร้างคีย์ API เพื่อส่งใน URL ของคำขอ หากต้องการสร้างคีย์ API ให้ไปที่ส่วนข้อมูลเข้าสู่ระบบของ API และบริการใน Cloud Console โดยทำดังนี้
ในเมนูแบบเลื่อนลง ให้เลือกคีย์ API
จากนั้นคัดลอกคีย์ที่คุณเพิ่งสร้าง
ตอนนี้คุณมีคีย์ API แล้ว ให้บันทึกลงในตัวแปรสภาพแวดล้อมเพื่อหลีกเลี่ยงการต้องแทรกค่าของคีย์ API ในแต่ละคำขอ โดยทำได้ใน Cloud Shell อย่าลืมแทนที่ <your_api_key> ด้วยคีย์ที่คุณเพิ่งคัดลอก
export API_KEY=<YOUR_API_KEY>สร้างที่เก็บข้อมูล Cloud Storage
คุณส่งรูปภาพไปยัง Vision API เพื่อตรวจหาภาพได้ 2 วิธี ได้แก่ ส่งสตริงรูปภาพที่เข้ารหัส Base64 ไปยัง API หรือส่ง URL ของไฟล์ที่จัดเก็บไว้ใน Google Cloud Storage เราจะใช้ URL ของ Cloud Storage เราจะสร้างที่เก็บข้อมูล Google Cloud Storage เพื่อจัดเก็บรูปภาพ
ไปที่เบราว์เซอร์พื้นที่เก็บข้อมูลใน Cloud Console สำหรับโปรเจ็กต์ของคุณ
จากนั้นคลิกสร้างที่เก็บข้อมูล ตั้งชื่อที่ไม่ซ้ำกันให้กับที่เก็บข้อมูล (เช่น รหัสโปรเจ็กต์) แล้วคลิกสร้าง
อัปโหลดรูปภาพไปยังที่เก็บข้อมูล
คลิกขวาที่รูปโดนัทต่อไปนี้ จากนั้นคลิกบันทึกรูปภาพเป็น แล้วบันทึกลงในโฟลเดอร์ดาวน์โหลดเป็น donuts.png

ไปที่ที่เก็บข้อมูลที่คุณเพิ่งสร้างในเบราว์เซอร์ที่เก็บข้อมูล แล้วคลิกอัปโหลดไฟล์ จากนั้นเลือก donuts.png
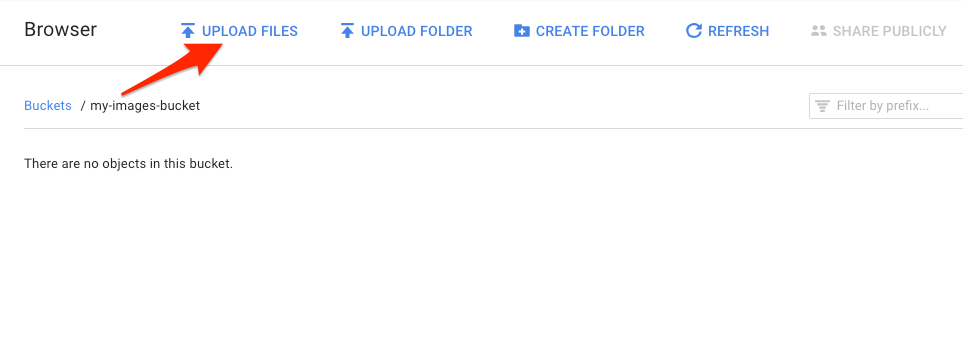
คุณควรเห็นไฟล์ในที่เก็บข้อมูล

จากนั้นแก้ไขสิทธิ์ของรูปภาพ
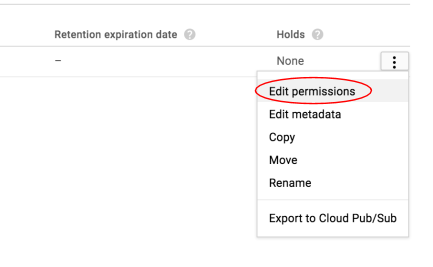
คลิกเพิ่มรายการ
เพิ่มเอนทิตีใหม่ของ Group และชื่อของ allUsers
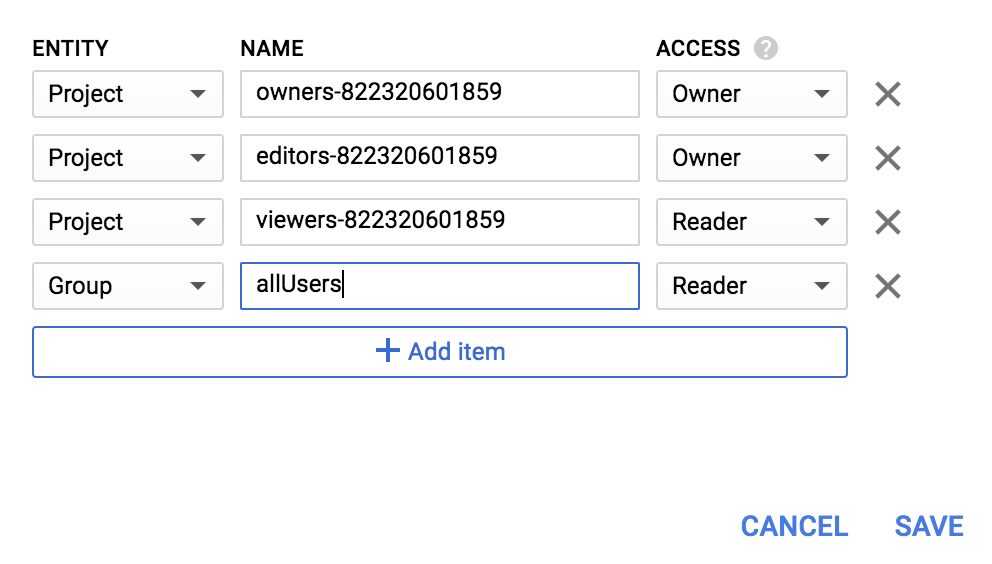
คลิกบันทึก
ตอนนี้คุณมีไฟล์ในที่เก็บข้อมูลแล้ว จึงพร้อมที่จะสร้างคำขอ Vision API โดยส่ง URL ของรูปภาพโดนัทนี้
ในสภาพแวดล้อม Cloud Shell ให้สร้างไฟล์ request.json ที่มีโค้ดด้านล่าง โดยแทนที่ my-bucket-name ด้วยชื่อของที่เก็บข้อมูล Cloud Storage ที่คุณสร้าง คุณจะสร้างไฟล์โดยใช้โปรแกรมแก้ไขบรรทัดคำสั่งที่ต้องการ (nano, vim, emacs) หรือใช้โปรแกรมแก้ไข Orion ใน Cloud Shell ก็ได้
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}ฟีเจอร์แรกของ Cloud Vision API ที่เราจะสำรวจคือการตรวจหาป้ายกำกับ เมธอดนี้จะแสดงรายการป้ายกำกับ (คำ) ของสิ่งที่อยู่ในรูปภาพ
ตอนนี้เราพร้อมที่จะเรียก Vision API ด้วย curl แล้ว
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}คำตอบของคุณควรมีลักษณะดังนี้
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}API ระบุประเภทโดนัทที่เฉพาะเจาะจงได้ (เบญเญต์) เจ๋งไปเลย! สำหรับป้ายกำกับแต่ละรายการที่ Vision API พบ ระบบจะแสดง description พร้อมชื่อของรายการ นอกจากนี้ยังแสดงผล score ซึ่งเป็นตัวเลขตั้งแต่ 0-100 ที่บ่งบอกถึงความมั่นใจว่าคำอธิบายตรงกับสิ่งที่อยู่ในรูปภาพ ค่า mid จะแมปกับ MID ของรายการในกราฟความรู้ของ Google คุณใช้ mid เมื่อเรียกใช้ Knowledge Graph API เพื่อดูข้อมูลเพิ่มเติมเกี่ยวกับรายการได้
นอกจากจะติดป้ายกำกับสิ่งที่อยู่ในรูปภาพแล้ว Vision API ยังค้นหาข้อมูลเพิ่มเติมเกี่ยวกับรูปภาพบนอินเทอร์เน็ตได้ด้วย เราได้รับข้อมูลที่น่าสนใจมากมายผ่านเมธอด webDetection ของ API ดังนี้
- รายการเอนทิตีที่พบในรูปภาพของเรา โดยอิงตามเนื้อหาจากหน้าเว็บที่มีรูปภาพคล้ายกัน
- URL ของรูปภาพที่ตรงกันทุกประการและตรงกันบางส่วนที่พบในเว็บ พร้อมด้วย URL ของหน้าเว็บเหล่านั้น
- URL ของรูปภาพที่คล้ายกัน เช่น การค้นหาจากรูปภาพ
หากต้องการลองใช้การตรวจหาบนเว็บ เราจะใช้รูปภาพบีญเยต์รูปเดียวกันจากด้านบน ดังนั้นสิ่งที่เราต้องเปลี่ยนจึงมีเพียงบรรทัดเดียวในไฟล์ request.json (คุณยังลองใช้รูปภาพอื่นที่แตกต่างกันโดยสิ้นเชิงได้ด้วย) ในรายการฟีเจอร์ ให้เปลี่ยนประเภทจาก LABEL_DETECTION เป็น WEB_DETECTION request.json ควรมีลักษณะดังนี้
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}หากต้องการส่งไปยัง Vision API คุณสามารถใช้คำสั่ง curl เดียวกันกับก่อนหน้าได้ (เพียงกดลูกศรขึ้นใน Cloud Shell)
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}มาเจาะลึกการตอบกลับโดยเริ่มจาก webEntities กัน รูปภาพนี้แสดงผลเอนทิตีต่อไปนี้
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
รูปภาพนี้ถูกนำกลับมาใช้ซ้ำในงานนำเสนอหลายครั้งเกี่ยวกับ Cloud ML API ของเรา จึงเป็นเหตุผลที่ API พบเอนทิตี "แมชชีนเลิร์นนิง" "Google Cloud Platform" และ "ระบบประมวลผลบนคลาวด์"
หากตรวจสอบ URL ในส่วน fullMatchingImages, partialMatchingImages และ pagesWithMatchingImages เราจะเห็นว่า URL จำนวนมากชี้ไปยังเว็บไซต์ Codelab นี้ (สุดยอดเมตา!)
สมมติว่าเราต้องการค้นหารูปภาพอื่นๆ ของบีญเย แต่ไม่ใช่รูปภาพที่เหมือนกันทุกประการ ซึ่งส่วน visuallySimilarImages ของการตอบกลับจาก API จะมีประโยชน์ในกรณีนี้ รูปภาพที่คล้ายกันซึ่งระบบพบมีดังนี้
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]เราสามารถไปที่ URL เหล่านั้นเพื่อดูรูปภาพที่คล้ายกันได้




เยี่ยมเลย ตอนนี้คุณอาจอยากกินบิญเญต์มากๆ (ขออภัย) ซึ่งคล้ายกับการค้นหาด้วยรูปภาพใน Google รูปภาพ ดังนี้
แต่ด้วย Cloud Vision เราสามารถเข้าถึงฟังก์ชันนี้ได้ด้วย REST API ที่ใช้งานง่ายและผสานรวมเข้ากับแอปพลิเคชันของเรา
จากนั้นเราจะมาดูวิธีการตรวจจับใบหน้าและจุดสังเกตของ Vision API วิธีการตรวจหาใบหน้าจะแสดงผลข้อมูลเกี่ยวกับใบหน้าที่พบในรูปภาพ ซึ่งรวมถึงอารมณ์ของใบหน้าและตำแหน่งของใบหน้าในรูปภาพ การตรวจหาจุดสังเกตสามารถระบุจุดสังเกตที่พบได้ทั่วไป (และไม่ค่อยเป็นที่รู้จัก) โดยจะแสดงชื่อของจุดสังเกต พิกัดละติจูดและลองจิจูด รวมถึงตำแหน่งที่ตรวจพบจุดสังเกตในรูปภาพ
อัปโหลดรูปภาพใหม่
หากต้องการใช้วิธีใหม่ทั้ง 2 วิธีนี้ ให้อัปโหลดรูปภาพใหม่ที่มีใบหน้าและสถานที่สำคัญไปยังที่เก็บข้อมูล Cloud Storage คลิกขวาที่รูปภาพต่อไปนี้ จากนั้นคลิกบันทึกรูปภาพเป็น แล้วบันทึกลงในโฟลเดอร์ดาวน์โหลดเป็น selfie.png

จากนั้นอัปโหลดไปยังที่เก็บข้อมูล Cloud Storage ในลักษณะเดียวกับที่คุณทำในขั้นตอนก่อนหน้า โดยอย่าลืมเลือกช่องทำเครื่องหมาย "แชร์แบบสาธารณะ"
การอัปเดตคำขอของเรา
จากนั้นเราจะอัปเดตไฟล์ request.json เพื่อรวม URL ของรูปภาพใหม่ และใช้การตรวจหาใบหน้าและจุดสังเกตแทนการตรวจหาป้ายกำกับ อย่าลืมแทนที่ my-bucket-name ด้วยชื่อที่เก็บข้อมูล Cloud Storage ของเรา
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}การเรียกใช้ Vision API และการแยกวิเคราะห์การตอบกลับ
ตอนนี้คุณพร้อมที่จะเรียกใช้ Vision API โดยใช้คำสั่ง curl เดียวกับที่ใช้ด้านบนแล้ว
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}มาดูออบเจ็กต์ faceAnnotations ในการตอบกลับกันก่อน คุณจะเห็นว่า API จะแสดงออบเจ็กต์สำหรับแต่ละใบหน้าที่พบในรูปภาพ ซึ่งในกรณีนี้คือ 3 ใบหน้า นี่คือเวอร์ชันที่ตัดทอนแล้วของการตอบกลับของเรา
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly จะให้พิกัด x,y รอบใบหน้าในรูปภาพ fdBoundingPoly เป็นกรอบที่เล็กกว่า boundingPoly ซึ่งเข้ารหัสในส่วนผิวหนังของใบหน้า landmarks คืออาร์เรย์ของออบเจ็กต์สำหรับลักษณะใบหน้าแต่ละอย่าง (บางอย่างคุณอาจไม่เคยรู้ด้วยซ้ำ) ซึ่งจะบอกประเภทของสถานที่สำคัญ พร้อมกับตำแหน่ง 3 มิติของฟีเจอร์นั้น (พิกัด x, y, z) โดยที่พิกัด z คือความลึก ค่าที่เหลือจะให้รายละเอียดเพิ่มเติมเกี่ยวกับใบหน้า รวมถึงความเป็นไปได้ที่จะแสดงอารมณ์ดี เศร้า โกรธ และประหลาดใจ ออบเจ็กต์ด้านบนใช้สำหรับบุคคลที่อยู่ด้านหลังสุดในรูปภาพ คุณจะเห็นว่าเขากำลังทำหน้าตลกๆ ซึ่งอธิบายถึงjoyLikelihoodของPOSSIBLE
ต่อไปมาดูส่วน landmarkAnnotations ของคำตอบกัน
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]ในที่นี้ Vision API สามารถบอกได้ว่ารูปภาพนี้ถ่ายที่เพตรา ซึ่งน่าประทับใจมากเนื่องจากคำใบ้ภาพในรูปภาพนี้มีน้อยมาก ค่าในการตอบกลับนี้ควรมีลักษณะคล้ายกับการตอบกลับ labelAnnotations ด้านบน
เราจะได้รับmidของสถานที่สำคัญ ชื่อ (description) พร้อมกับความเชื่อมั่น score boundingPoly แสดงภูมิภาคในรูปภาพที่ระบุสถานที่สำคัญ คีย์ locations จะบอกพิกัดละติจูดและลองจิจูดของสถานที่สำคัญนี้
เราได้ดูวิธีการตรวจหาป้ายกำกับ ใบหน้า และจุดสังเกตของ Vision API แล้ว แต่ยังมีอีก 3 วิธีที่เรายังไม่ได้สำรวจ ดูข้อมูลเกี่ยวกับอีก 3 รายการได้ในเอกสาร
- การตรวจหาโลโก้: ระบุโลโก้ที่พบบ่อยและตำแหน่งของโลโก้ในรูปภาพ
- การตรวจหาการค้นหาปลอดภัย: ระบุว่ารูปภาพมีเนื้อหาที่อาจไม่เหมาะสมหรือไม่ ซึ่งจะเป็นประโยชน์สำหรับแอปพลิเคชันที่มีเนื้อหาที่ผู้ใช้สร้างขึ้น คุณกรองรูปภาพตามปัจจัย 4 อย่าง ได้แก่ เนื้อหาสำหรับผู้ใหญ่ การแพทย์ ความรุนแรง และเนื้อหาที่หลอกลวง
- การตรวจหาข้อความ: เรียกใช้ OCR เพื่อดึงข้อความจากรูปภาพ วิธีนี้ยังระบุภาษาของข้อความที่อยู่ในรูปภาพได้ด้วย
คุณได้เรียนรู้วิธีวิเคราะห์รูปภาพด้วย Vision API แล้ว ในตัวอย่างนี้ คุณส่ง URL ของรูปภาพใน Google Cloud Storage ไปยัง API หรือจะส่งสตริงที่เข้ารหัส Base64 ของรูปภาพก็ได้
สิ่งที่เราได้พูดถึง
- การเรียกใช้ Vision API ด้วย curl โดยส่ง URL ของรูปภาพในที่เก็บข้อมูล Cloud Storage
- การใช้วิธีการตรวจหาป้ายกำกับ เว็บ ใบหน้า และจุดสังเกตของ Vision API
ขั้นตอนถัดไป
- ดูบทแนะนำเกี่ยวกับ Vision API ในเอกสารประกอบ
- ค้นหาตัวอย่าง Vision API ในภาษาที่คุณชื่นชอบ
- ลองใช้ Codelab ของ Speech API และ Natural Language API